训练系统系列(五)《强化学习及 DeepSeek》
目录
第一部分讲强化学习基础概念,第二部分介绍 DeepSeek 的一些主要架构以及涉及到的训练方法。
强化学习基础概念
监督学习与强化学习的对比
1. 监督学习:
-
• 如同在老师指导下学习,提供大量带标签数据。
-
• 特点:数据现成、样本独立、任务预测性。
2. 强化学习:
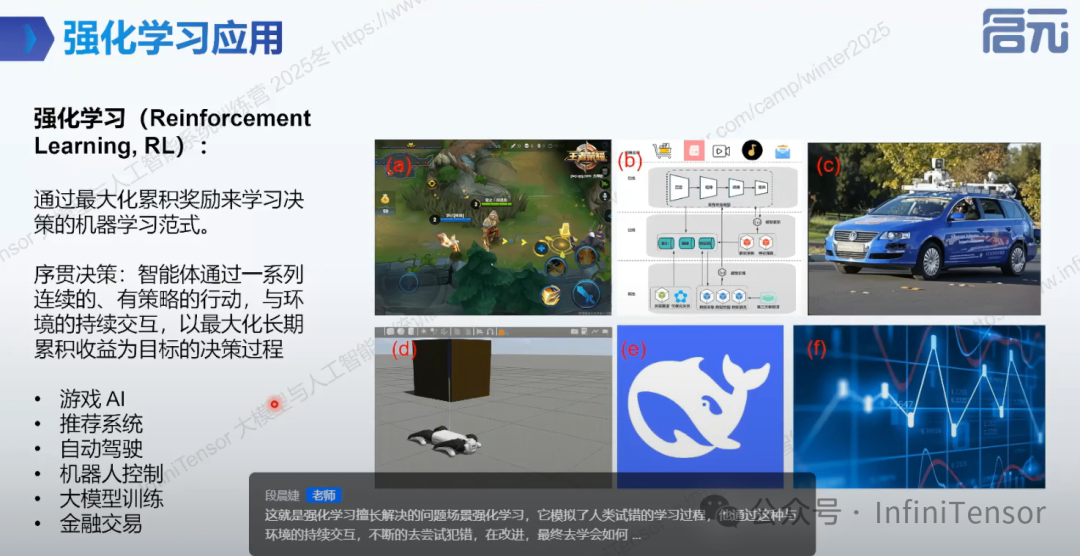
强化学习
1.要素:环境、智能体、状态、动作、奖励
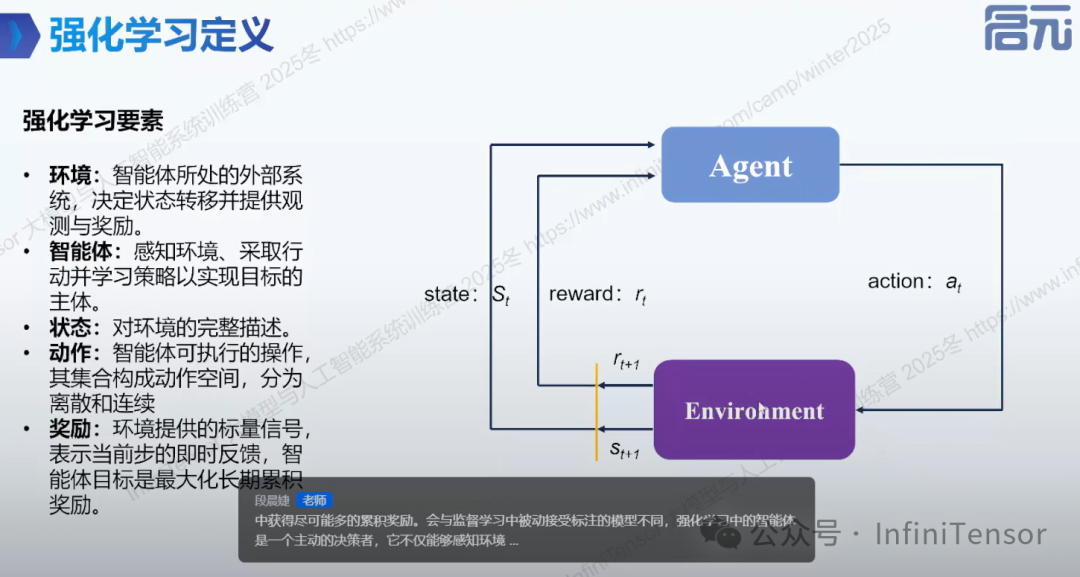
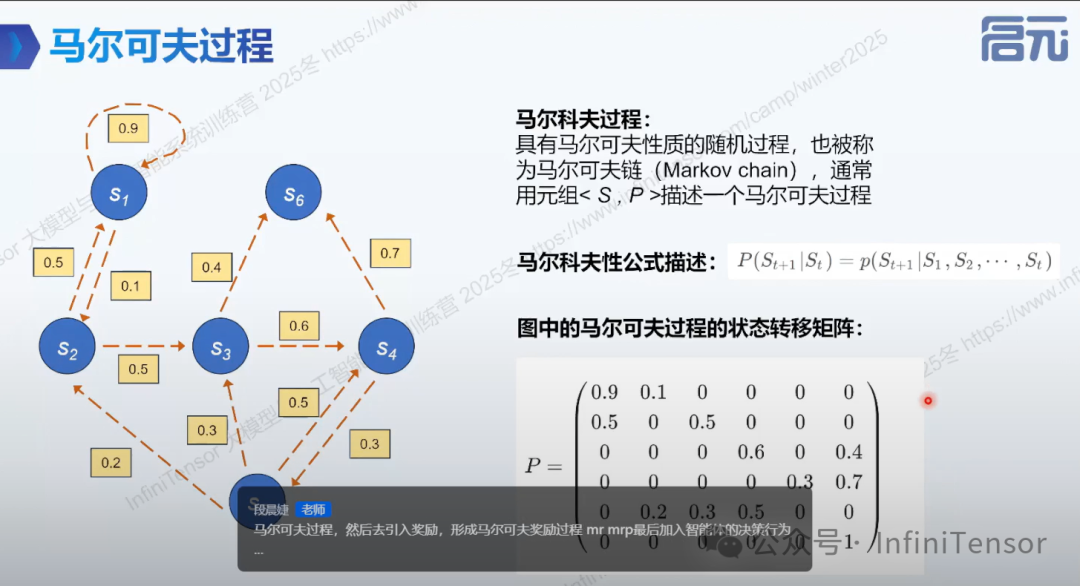
2.马尔可夫决策过程(MDP):
3. 马尔可夫奖励过程(MRP)
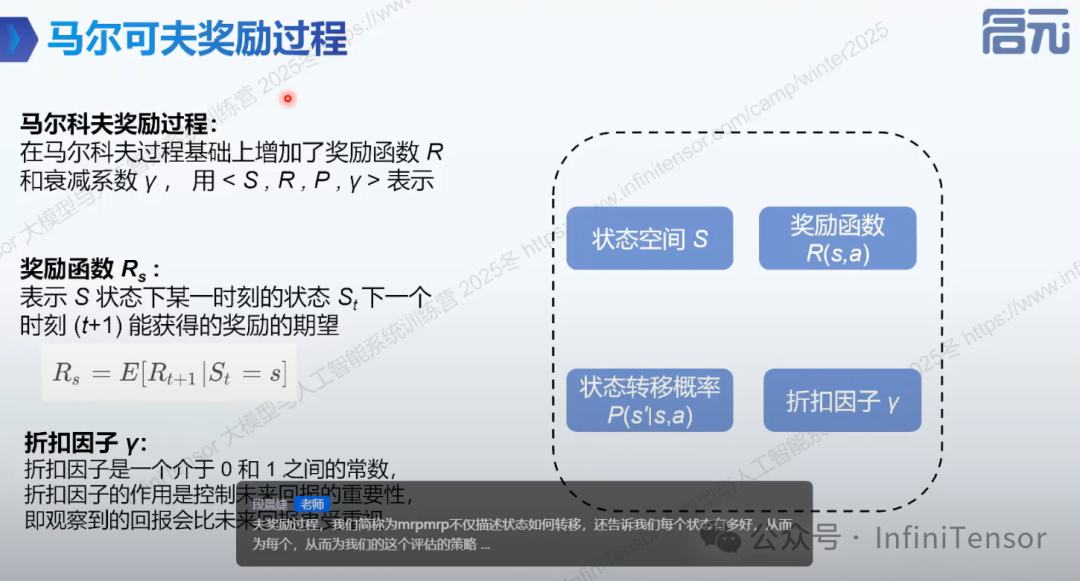
-
• 要素:四元组(S, P, R, γ),R 为奖励函数,γ 为折扣因子。
4. 价值函数:
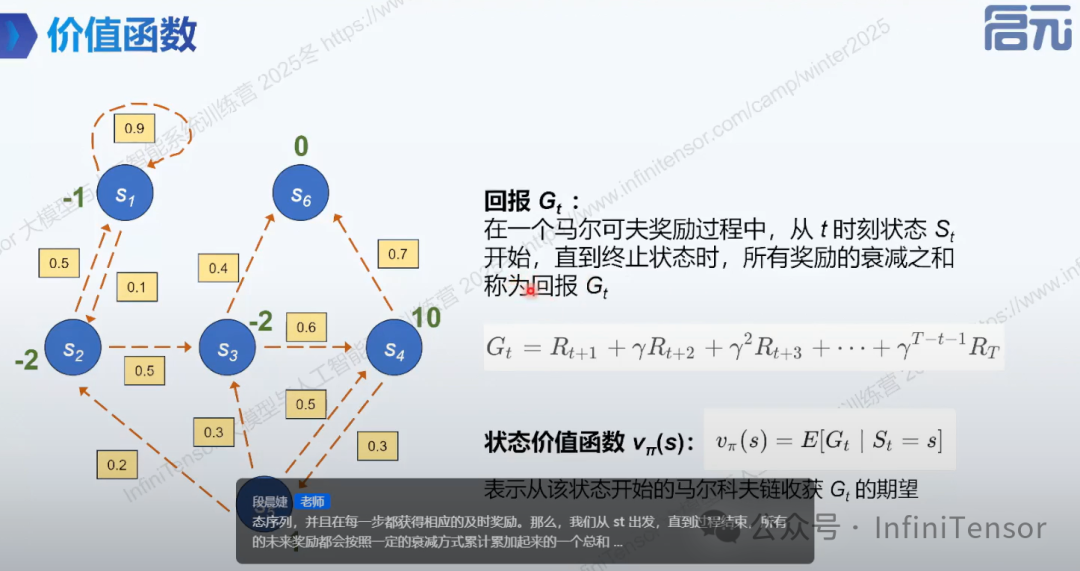
4. 贝尔曼方程:
-
• 定义:价值函数的递归结构。
-
• 应用:强化学习算法的理论基础。

5. 马尔可夫决策过程(MDP)
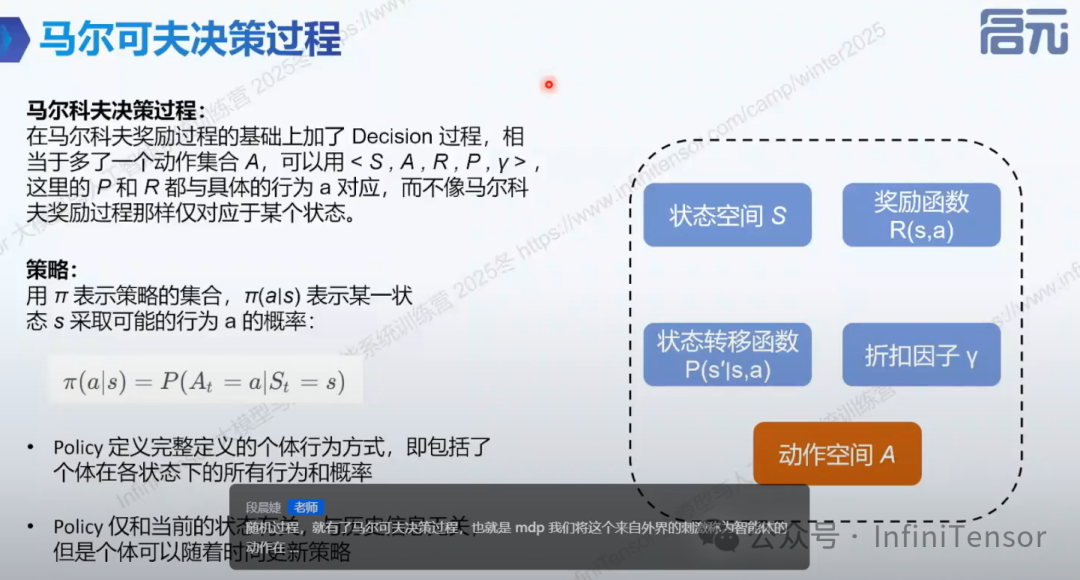
(1)定义:引进动作的马尔可夫奖励过程。
(2)要素:五元组(S, A, P, R, γ),A 为动作集合。
(3)策略与价值函数:
-
• 策略:智能体根据当前状态选择动作的函数。
- • 状态价值函数与动作价值函数:评估策略好坏的指标。

(4)最优策略与贝尔曼最优方程:
-
• 最优策略:最大化长期累积奖励的策略。
-
• 贝尔曼最优方程:描述最优价值函数的递归结构。

6. Q-Learning 算法
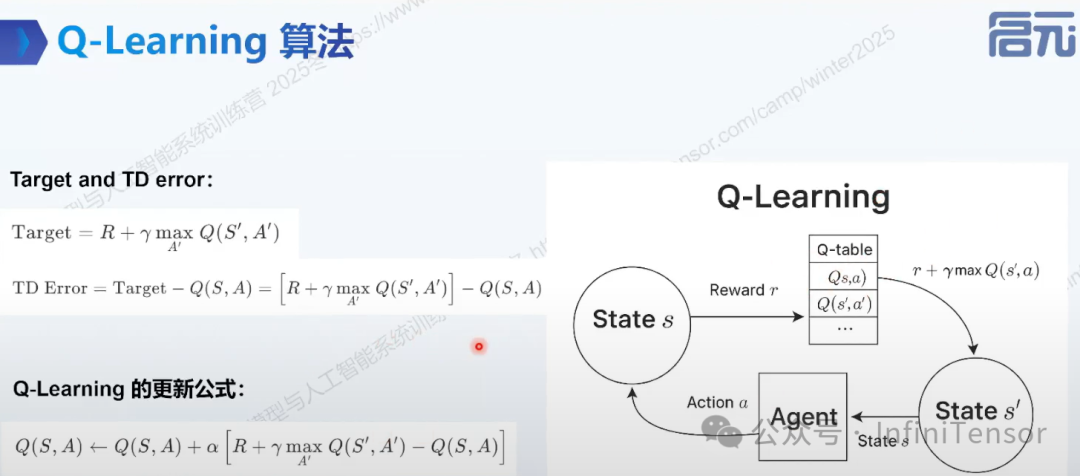
-
• 定义:帮助智能体学会最优策略的经典强化学习算法。
-
• 核心思想:学会 Q 表,存储状态下做动作的长期奖励。
-
• 更新公式:使用目标值与 TD 误差更新 Q 值。
-
• 学习过程:初始化 Q 表、观察状态、选择动作、更新 Q 值。
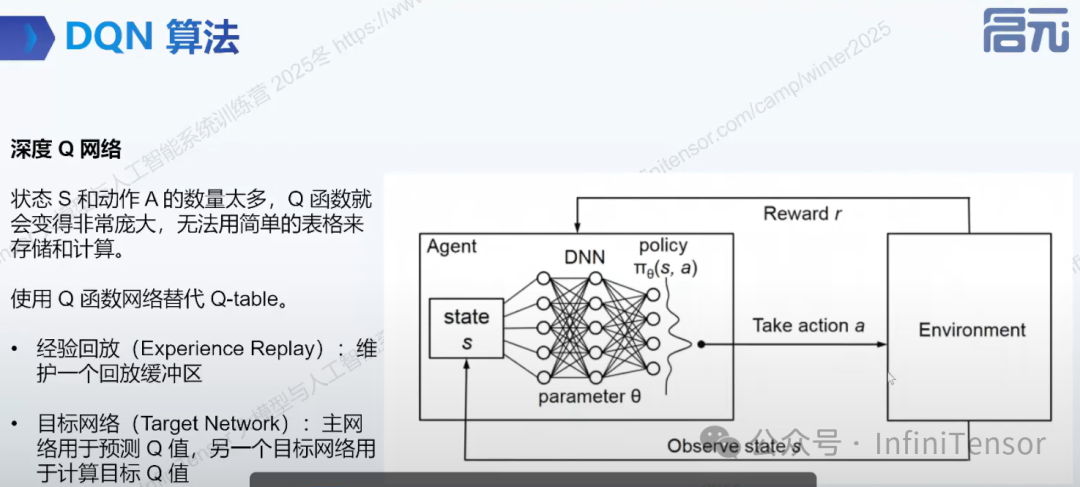
7. DQN 算法
-
• 定义:在 Q-Learning 基础上引入神经网络的算法。
-
• 特点:使用神经网络近似 Q 函数,适用于连续或大规模状态空间。
-
• 关键模块:经验回放与目标网络。
8. 基于策略的方法与策略梯度

-
• 定义:直接学习目标策略的方法。
-
• 策略梯度:参数化策略,通过优化参数最大化期望回报。
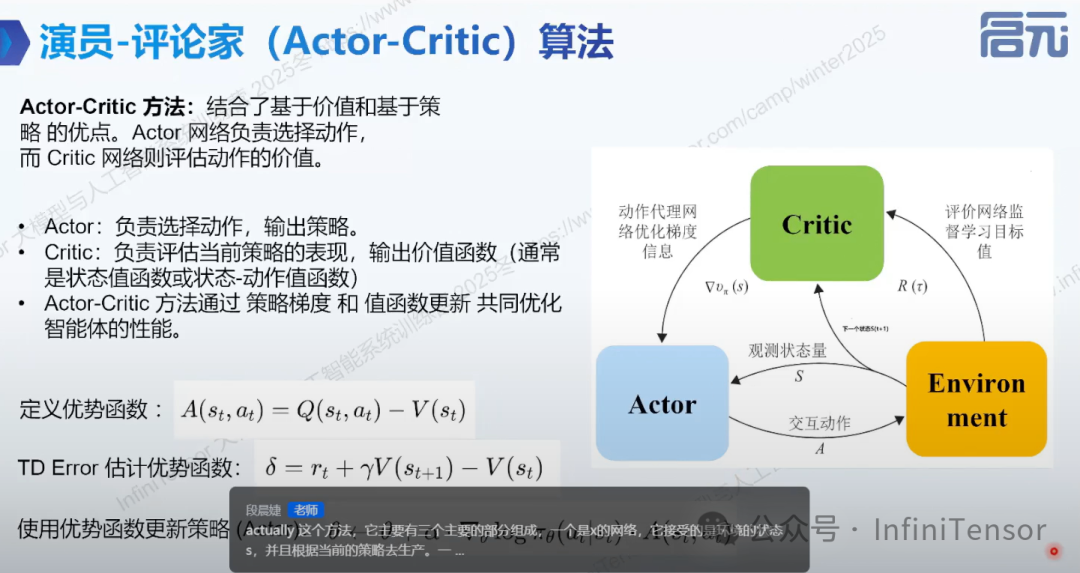
9. Actor-Critic 算法
-
• 定义:结合基于价值与基于策略的方法。
-
• 核心:Actor 负责选择动作,Critic 负责评估策略表现。
-
• 关键概念:优势函数、TD 误差、策略更新方式。
10. PPO 算法
-
• 定义:限制梯度更新幅度的策略优化算法。
-
• 核心思想:裁剪机制与"小步快跑"策略更新方式。
-
• 应用:大语言模型微调,通过生成响应、获取反馈、调整模型流程优化性能。

DeepSeek 架构及训练方法
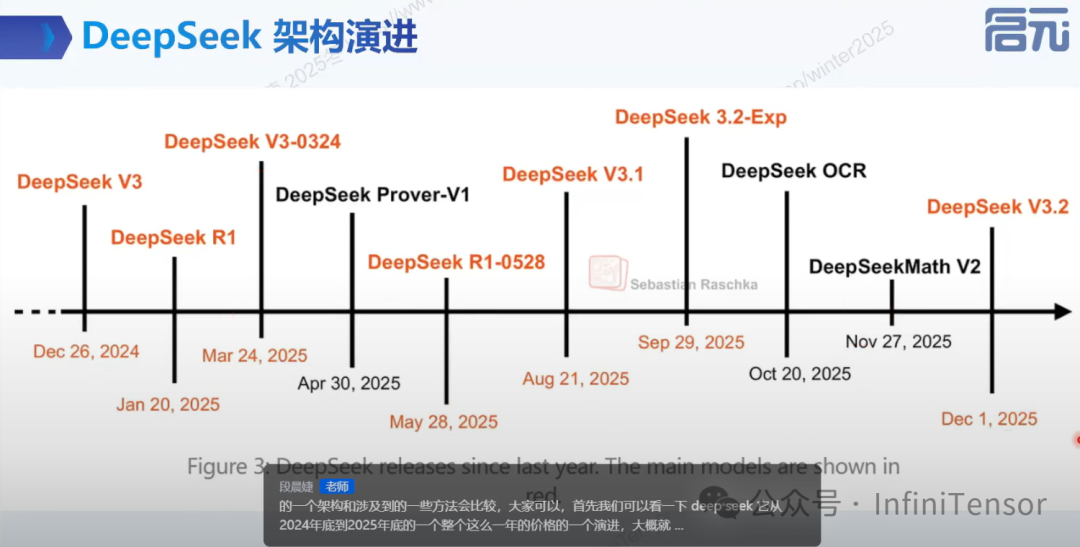
DeepSeek 架构演进概述
-
• 时间线:从 2024 年底到 2025 年底的架构版本演进。
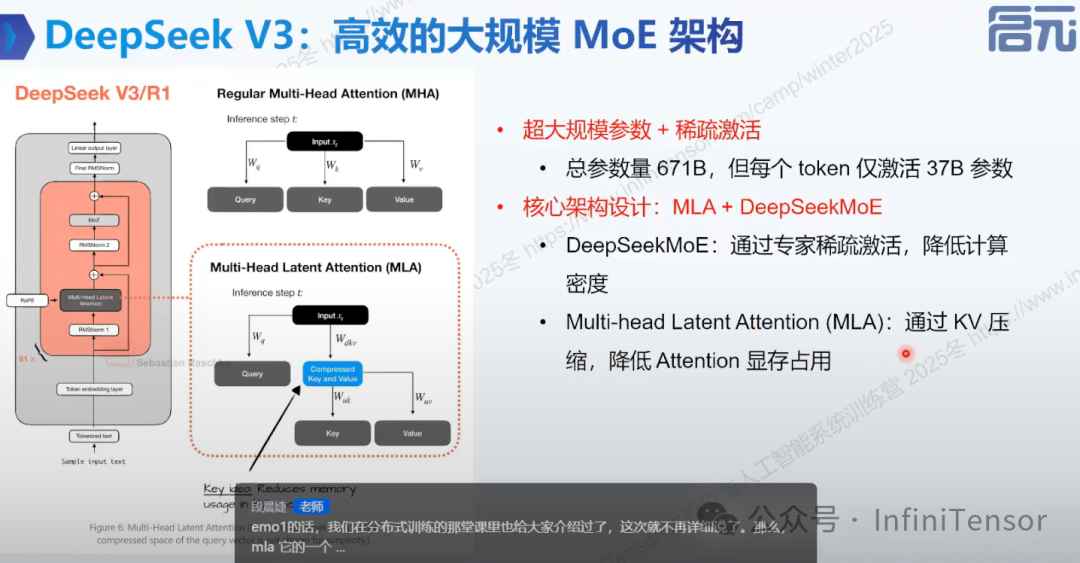
DeepSeek V3 架构
-
• 特点:MoE 架构,超大规模参数但稀疏激活。
-
• 核心设计:MLA 与 MoE,降低 Attention 计算显存占用。
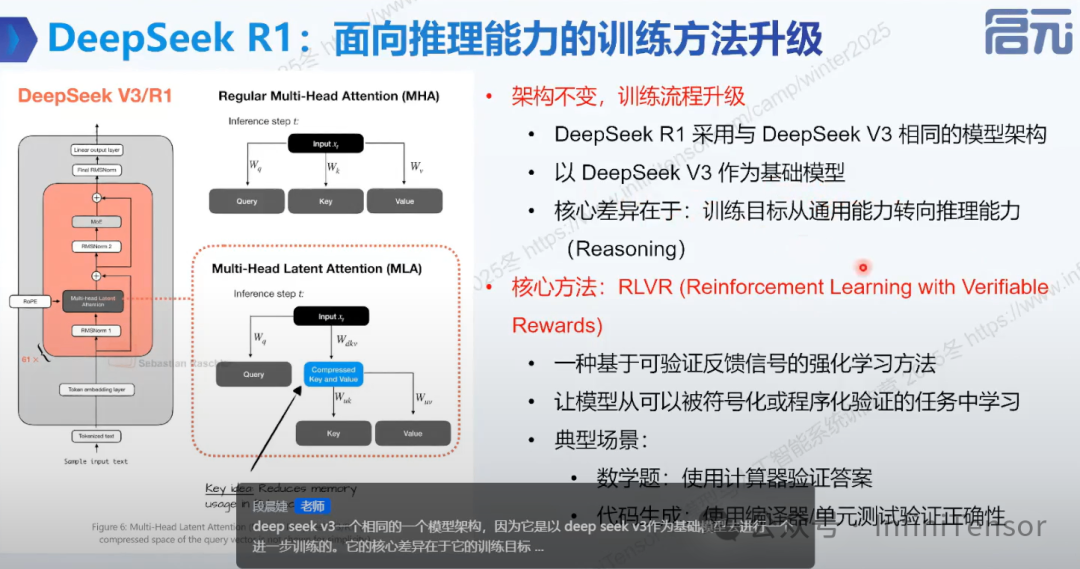
DeepSeek R1 架构
-
• 基础:基于 DeepSeek V3。
-
• 核心差异:训练目标转向推理能力,引入 RLVR 训练方法。
-
• RLVR:基于可验证反馈信号的强化学习方法。
DeepSeek V3.2 架构
-
• 基础:保留 MLA 与 MOE 基本架构。
-
• 新增模块:DSA(DeepSeek Sparse Attention),降低长上下文推理计算与显存成本。

-
• DSA 计算流程:
Token embeddings 输入
Lighting Indexer 模块计算相关性
Top-K Selector 保留得分最高历史 token
构建 Sparse Attention Mask
在稀疏 mark 上执行注意力计算。
总结
本文介绍了强化学习基础概念和DeepSeek架构演进。强化学习部分对比了监督学习与强化学习,阐述了马尔可夫决策过程、价值函数、贝尔曼方程等核心概念,并详解了Q-Learning、DQN、策略梯度、Actor-Critic和PPO等算法。DeepSeek架构部分概述了从V3到R1再到V3.2的演进历程,重点介绍了MoE架构、MLA模块、RLVR训练方法和新增的DSA模块,后者通过稀疏注意力机制显著降低了长上下文推理的计算和显存成本。全文系统性地梳理了强化学习理论基础与DeepSeek架构的关键技术创新。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 22
22 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)