Feature Information Driven Position Gaussian Distribution Estimation for Tiny Object Detection 精读
Feature Information Driven Position Gaussian Distribution Estimation for Tiny Object Detection 精读:从小白到博士,彻底拆解信息驱动高斯分布小目标检测的核心逻辑
论文标题:Feature Information Driven Position Gaussian Distribution Estimation for Tiny Object Detection
论文来源:Feature Information Driven Position Gaussian Distribution Estimation for Tiny Object Detection
文章定位:论文精读 / 计算机视觉 / 目标检测 / 小目标检测 / 特征增强 / 信息论应用
适合人群:零基础读者、计算机视觉/目标检测研究生、准备复现论文的博士生与算法工程人员
文章目录
- Feature Information Driven Position Gaussian Distribution Estimation for Tiny Object Detection 精读:从小白到博士,彻底拆解信息驱动高斯分布小目标检测的核心逻辑
- 一句提示词帮你速通论文
- 前言
一句提示词帮你速通论文
提示词
你现在是一位计算机视觉的博士,请你仔细阅读这篇论文,并将其拆解为小白阶段、硕士阶段、博士阶段。一定要引人入胜,客观具体,且极为详细。小白阶段你需要达到是个傻子都能懂的情况,在硕士阶段你需要达到正常使用一些专业数据,帮助小白从傻子到小专家的突破,在博士阶段你需要仔细拆解整篇论文,把各项细节全部记录,方便后期进行复现,同时促使小专家成为资深大拿
前言
最近几年,小目标检测成了航拍感知、交通监控、海洋救援、野生动物监测等场景的核心技术痛点,尽管通用目标检测器(Faster R-CNN、YOLO、DetectoRS)在常规尺寸目标上效果优异,但一遇到像素数极少的极小目标(2-8像素)、小目标(8-16像素),检测性能就会断崖式下跌,成为开放场景高精度感知的核心瓶颈。而小目标检测有一个核心痛点:
传统小目标检测方法要么依赖多尺度特征融合补全信息,要么用启发式注意力机制聚焦目标,却始终忽略了极小目标因像素极度稀缺、网络下采样导致信息不可逆丢失,最终特征弱激活、与背景无区分度的底层问题;要么模型改造复杂、泛化性差,无法无缝适配主流FPN类检测器,也无法精准定向增强小目标弱特征。
同时,信息论与高斯分布建模为**“精准定位信息丢失区域、定向增强弱特征”**带来了全新思路——从像素级信息量出发定位待增强区域,用位置高斯分布专属聚焦小目标,能从根源解决小目标弱表征问题,但新问题又来了:
现有特征增强方法要么无监督定位不准、易受背景干扰,要么有监督缺乏尺寸针对性,无法兼顾“信息缺失区域精准挖掘”和“小目标优先级强化”,直接导致增强后的特征依然区分度低、极小目标检测精度上不去。
于是,这篇CVPR 2025论文提出了一套直击痛点的解决方案:
采用即插即用轻量化架构,无需大幅改造原有检测器,通过“像素特征信息无监督建模(信息熵最小化)+ 位置高斯分布有监督预测”双模块协同,从信息论视角精准挖掘弱激活区域,用自适应高斯分布强化小目标特征,首次实现像素级信息驱动的小目标特征增强,在VisDrone2019、AI-TOD、AI-TODv2三大权威小目标数据集上刷新SOTA,尤其对极小型目标检测精度实现数量级提升。
这篇文章我会把整篇论文拆成三个层次来讲:
- 小白阶段:用最直白的语言、最形象的类比,讲懂论文到底在解决什么问题、用了什么方法、效果有多好
- 硕士阶段:引入必要的专业术语、数学公式、技术框架细节、实验设计与结果对比,帮你完成从入门到专业的突破
- 博士阶段:按照“可复现、可推敲、可扩展”的标准,完整拆解论文的创新动机、数学推导、工程实现细节、复现避坑指南、局限性与未来研究方向,帮你从专业玩家进阶为领域资深研究者
目标只有一个:
不只是让你“看过这篇论文”,而是让你真正“吃透这篇论文”,甚至能基于它做二次创新与工程落地。
小白阶段:通俗易懂、引人入胜
1. 论文要解决的核心问题
我们可以把目标检测比作「在照片里找东西」:
- 检测大目标,就像在客厅里找沙发,特征明显,一眼就能看到;
- 检测小目标(比如无人机航拍图里2-8像素的汽车、行人),就像在地板上找一粒米,甚至半粒米,像素少得可怜。
普通的目标检测器,看图片时会一层层「缩小看全局」,这个过程叫下采样。大目标缩小后还能看清轮廓,但小目标本身只有几个像素,经过几次缩小,信息直接丢光了,最后和背景糊在一起,完全找不到。
现有方法要么是「把模糊的图强行放大」(多尺度融合),要么是「瞎猜哪里有目标」(普通注意力机制),都解决不了小目标本身信息太少、特征太弱的核心问题,对极小型目标几乎完全失效。
2. 论文的核心方法
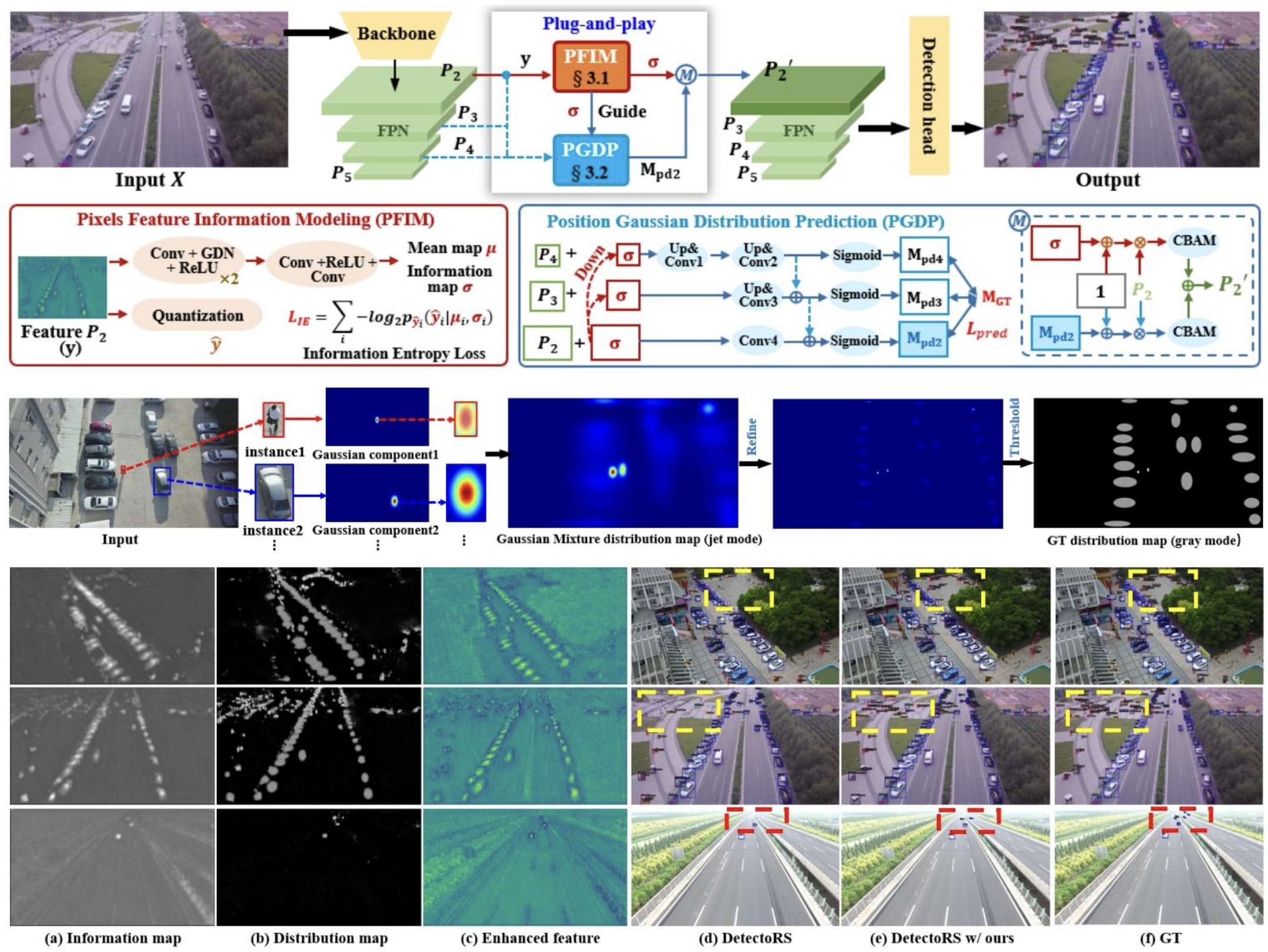
论文给检测器装了一套「双导航高清增强镜」,即插即用,不用大改原来的检测器,就能让小目标瞬间变清晰,核心分为两步:
-
第一步:做一张「信息热度图」
就像用热成像仪扫房间,哪里有东西、哪里和背景不一样,哪里的热度就高。论文用信息论的方法,不用提前告诉它哪里有目标,就能无监督地算出图片里每个像素的信息量,生成一张热度图:米粒虽然小,但和地板不一样,信息量高,热度就高;光滑的地板信息量低,热度就低。这张图能精准标出所有需要增强的弱特征区域。 -
第二步:做一张「小目标专属导航图」
光有热度图还不够,我们要专门照顾越小的目标。论文根据标注的目标位置,给每个目标画了一个「高斯高亮圈」:目标越小,圈的亮度越高,就像地图上给越小的宝藏标了越亮的红点。然后用热度图当参考,训练网络预测这张导航图,让网络把注意力死死盯在小目标上。
最后,用两张图一起增强原来模糊的特征,让小目标的特征瞬间变亮、和背景彻底分开,再送给检测器,就能轻松检测到了。
3. 方法的优缺点
核心优势
- 万能适配:即插即用,不管是哪种主流检测器,都能直接装上用,不用推翻重写;
- 专治超小目标:对只有2-8像素的极小型目标,检测能力提升几十倍,是现有方法做不到的;
- 精准不瞎标:用信息论找增强区域,比普通注意力机制更靠谱,不会把背景当成目标。
局限性
- 只照顾小目标:只增强负责小目标的特征层,对大目标的检测没有帮助,甚至可能有轻微负面影响;
- 依赖标注数据:导航图的训练需要目标的标注框,没有标注的无监督场景没法直接用;
- 极端场景受限:如果小目标和背景长得几乎一模一样(比如和草地同色的兔子),信息量差异太小,热度图很难标出来。
硕士阶段:深入分析、渐入佳境
1. 核心数学原理与基础概念
(1)香农信息论基础
小目标检测的核心瓶颈是信息丢失,论文用信息论量化每个像素的信息量:
- 自信息量定义:对于随机变量x,其发生概率为p(x),则自信息量为
I ( x ) = − l o g 2 p ( x ) I(x) = -log_2 p(x) I(x)=−log2p(x)
物理意义:事件发生的概率越低,包含的信息量越大,编码所需的比特数越多。比如目标区域的纹理比光滑背景复杂,发生概率更低,信息量更大。 - 交叉熵与信息熵损失:对于特征的离散化结果ŷ,真实分布为m(ŷ),模型估计分布为p_ŷ(ŷ),交叉熵为
R = E y ^ ∼ m [ − l o g 2 p y ^ ( y ^ ) ] = H ( m ) + D K L ( m ∣ ∣ p y ^ ) R = \mathbb{E}_{\hat{y}\sim m}\left[-log_2 p_{\hat{y}}(\hat{y})\right] = H(m) + D_{KL}(m||p_{\hat{y}}) R=Ey^∼m[−log2py^(y^)]=H(m)+DKL(m∣∣py^)
其中H(m)是真实分布的熵,D_KL是KL散度(非负)。当p_ŷ=m时,交叉熵取得最小值,此时的编码成本就是理论下界。论文通过最小化这个交叉熵(即信息熵损失L_IE),让网络自适应量化每个像素的信息量。
(2)二维高斯分布与高斯混合模型
论文用高斯分布建模目标的位置先验:
- 二维高斯分布的概率密度函数:以目标框中心为均值,宽高为协方差,刻画目标的位置显著性,目标越小,高斯峰越尖,峰值越高;
- 高斯混合模型(GMM):把图片里所有目标的高斯分量叠加,生成整张图的位置显著性分布,作为训练的真值。
(3)基础网络概念
- FPN(特征金字塔网络):主流检测器的特征提取结构,通过下采样生成P2-P5多层特征,其中P2是下采样4倍的特征层,保留最多空间信息,负责小目标检测,论文的增强全部围绕P2展开;
- CBAM注意力模块:卷积块注意力模块,结合通道注意力和空间注意力,进一步强化增强后的特征。
2. 论文核心方法与技术框架
论文的整体框架是即插即用的双模块特征增强结构,可无缝集成到任意FPN类检测器中,核心分为两个模块,流程如下:
(1)像素特征信息建模模块(PFIM)
核心目标:无监督生成信息图,定位高信息量的弱激活区域,步骤如下:
- 输入与量化:输入FPN的P2特征图 y ∈ R H / 4 × W / 4 × C y \in \mathbb{R}^{H/4 × W/4 × C} y∈RH/4×W/4×C,为了让连续特征离散化且保持可微,训练时加入均匀噪声 U ( − 1 2 , 1 2 ) \mathcal{U}(-\frac{1}{2},\frac{1}{2}) U(−21,21),得到离散特征 y ^ = y + U ( − 1 2 , 1 2 ) \hat{y} = y + \mathcal{U}(-\frac{1}{2},\frac{1}{2}) y^=y+U(−21,21)。
- 像素级高斯密度建模:用轻量级CNN预测每个像素的高斯分布参数:均值图 μ \mu μ和尺度图 σ \sigma σ,每个像素的分布为:
p y ^ ( y ^ ∣ μ , σ ) = ∏ i ( N ( μ i , σ i 2 ) ∗ U ( − 1 2 , 1 2 ) ) ( y ^ i ) p_{\hat{y}}(\hat{y}|\mu,\sigma) = \prod_{i}\left(\mathcal{N}(\mu_i,\sigma_i^2)*\mathcal{U}(-\frac{1}{2},\frac{1}{2})\right)(\hat{y}_i) py^(y^∣μ,σ)=i∏(N(μi,σi2)∗U(−21,21))(y^i)
其中卷积均匀分布是为了让估计分布匹配真实边缘分布,保证可微性。 - 信息熵损失优化:每个像素的编码成本为负对数似然 R y ^ i = − l o g 2 p y ^ i ( y ^ i ∣ μ i , σ i ) R_{\hat{y}_i} = -log_2 p_{\hat{y}_i}(\hat{y}_i|\mu_i,\sigma_i) Ry^i=−log2py^i(y^i∣μi,σi),信息熵损失为所有像素编码成本之和:
L I E = ∑ i R y ^ i \mathcal{L}_{IE} = \sum_i R_{\hat{y}_i} LIE=i∑Ry^i
最小化 L I E \mathcal{L}_{IE} LIE的过程,就是让网络给高信息量区域分配更高的编码成本,尺度图 σ \sigma σ与信息量正相关,因此将 σ \sigma σ作为信息图。 - 特征增强:对 σ \sigma σ做通道维度均值,用信息图增强P2特征:
y 1 = y ⊗ ( 1 + M e a n ( σ ) ) y_1 = y \otimes (1+Mean(\sigma)) y1=y⊗(1+Mean(σ))
其中 1 + σ 1+\sigma 1+σ是为了保留背景上下文,避免 σ \sigma σ接近0时特征被抹除。
(2)位置高斯分布预测模块(PGDP)
核心目标:以信息图为先验,监督学习小目标专属的位置分布图,进一步强化小目标特征,步骤如下:
- 真值位置高斯分布图 M G T M_{GT} MGT构建
- 每个标注框对应一个二维高斯分布,均值为框的中心,协方差矩阵根据目标尺寸自适应缩放:
μ i b o x = [ x i y i ] , ∑ i b o x = [ ( w i α i ) 2 0 0 ( h i α i ) 2 ] \mu_i^{box} = \begin{bmatrix}x_i \\ y_i\end{bmatrix}, \sum_i^{box} = \begin{bmatrix}(\frac{w_i}{\alpha_i})^2 & 0 \\ 0 & (\frac{h_i}{\alpha_i})^2\end{bmatrix} μibox=[xiyi],i∑box=[(αiwi)200(αihi)2]
其中 α i \alpha_i αi按目标尺寸设置:极小型(2-8px)=4,小型(8-16px)=6,中小型(16-32px)=8,通用目标=10,目标越小, α i \alpha_i αi越小,高斯峰值越高。 - 所有高斯分量叠加为高斯混合分布,经阈值处理拉大前景背景对比度,得到最终的 M G T M_{GT} MGT。
- 每个标注框对应一个二维高斯分布,均值为框的中心,协方差矩阵根据目标尺寸自适应缩放:
- 多尺度分布图预测
- 以P2、P3、P4多尺度特征为基础,结合对应下采样倍数的信息图 σ \sigma σ作为输入: i n p u t s = [ P 4 + 1 4 σ , P 3 + 1 2 σ , P 2 + σ ] inputs = [P_4+\frac{1}{4}\sigma, P_3+\frac{1}{2}\sigma, P_2+\sigma] inputs=[P4+41σ,P3+21σ,P2+σ];
- 用带跳连的卷积+转置卷积网络,预测3个尺度的分布图 M p d 2 , M p d 3 , M p d 4 M_{pd2}, M_{pd3}, M_{pd4} Mpd2,Mpd3,Mpd4,实现信息图与分布图的相互调制。
- 加权预测损失优化
为解决前景背景不平衡,采用加权MSE损失,前景权重10,背景权重0.1:
L p r e d = ∑ i = 2 4 M S E w e i g h t e d ( M p d i , M G T ) \mathcal{L}_{pred} = \sum_{i=2}^4 MSE_{weighted}(M_{pdi}, M_{GT}) Lpred=i=2∑4MSEweighted(Mpdi,MGT) - 特征增强与融合
- 用预测的 M p d 2 M_{pd2} Mpd2增强P2特征: y 2 = y ⊗ ( 1 + M p d 2 ) y_2 = y \otimes (1+M_{pd2}) y2=y⊗(1+Mpd2);
- y 1 y_1 y1和 y 2 y_2 y2分别经过CBAM模块,逐元素相加得到增强后的特征 P 2 ′ P_2' P2′,替换原始P2送入检测头。
(3)总损失函数
L = L d e t + λ 1 L I E + λ 2 L p r e d \mathcal{L} = \mathcal{L}_{det} + \lambda_1 \mathcal{L}_{IE} + \lambda_2 \mathcal{L}_{pred} L=Ldet+λ1LIE+λ2Lpred
其中 L d e t \mathcal{L}_{det} Ldet为原始检测器的分类+回归损失, λ 1 = 0.01 \lambda_1=0.01 λ1=0.01、 λ 2 = 1.0 \lambda_2=1.0 λ2=1.0为平衡超参数。
3. 实验设计与结果分析
(1)实验设置
- 数据集:3个权威小目标检测数据集
- VisDrone2019:无人机航拍,10类,10209张2000×1500分辨率图像,大量城市小目标实例;
- AI-TOD:航拍图像,8类,28036张,平均目标尺寸12.8像素,专为极小型目标检测设计;
- AI-TODv2:AI-TOD优化版,75万+实例,平均目标尺寸12.7像素。
- 实现细节:基于PyTorch+MMDetection框架,骨干网络为ImageNet预训练的ResNet50-FPN,SGD优化器(动量0.9,权重衰减1e-4),batch size=2,训练12epoch,初始学习率0.005,8、11epoch衰减。
- 评价指标:标准COCO评价体系,重点关注 A P AP AP(平均精度)、 A P v t AP_{vt} APvt(极小型目标)、 A P t AP_t APt(小型目标)、 A P s AP_s APs(中小型目标)。
(2)核心实验结果
- SOTA对比
- 在VisDrone2019上,该方法给所有基线模型带来稳定提升:DetectoRS w/ ours的AP从26.3提升至28.3, A P v t AP_{vt} APvt从0.1提升至3.5, A P t AP_t APt从7.5提升至12.6;结合RFLA后,AP达到29.0,刷新SOTA,$AP_{vt}$7.4远超第二名的5.4。
- 在AI-TOD上,DetectoRS w/ ours的AP从14.6提升至24.3,涨幅9.7个点, A P t AP_t APt提升13.9个点,远超SR-TOD等同期方法。
- 消融实验
- 模块有效性:单独添加PFIM,AP提升1.9;单独添加PGDP,AP提升1.3;两者结合,AP提升2.0,证明两个模块互补增效。
- 设计合理性:验证了自适应缩放因子的高斯建模、信息图加法引导、逐元素相加融合策略均为最优设计,其他替代方案均有性能下降。
(3)方法优势与局限
- 优势:
- 即插即用,适配所有FPN类检测器,无需修改检测器核心结构;
- 从信息论根源解决小目标弱表征问题,对极小型目标的提升远超现有方法;
- 无监督信息建模+有监督位置先验结合,既保证了增强区域的精准性,又强化了对小目标的针对性。
- 局限:
- 仅针对P2层增强,对大目标检测无增益,甚至有轻微负面影响;
- PGDP模块依赖目标标注构建真值分布图,无法直接用于无监督场景;
- 对与背景纹理高度相似的目标,信息图的区分度不足,性能会下降。
博士阶段:深入拆解、实现复现
1. 研究动机与核心创新点
(1)研究背景与深层动机
通用目标检测在小目标上的性能断崖式下跌,其本质瓶颈并非多尺度融合不足、标签分配不合理,而是小目标经过CNN多次下采样后,信息不可逆丢失导致的特征弱激活、与背景无区分度。现有方法存在根本性缺陷:
- 多尺度融合类方法(FPN、BiFPN、DetectoRS)仅实现了语义与空间信息的跨层传递,无法解决小目标特征本身的弱激活问题,相当于「放大模糊的图像,无法还原丢失的细节」;
- 注意力类方法依赖启发式的注意力图生成,小目标像素稀疏,局部区域背景占主导,注意力图极易被背景干扰,可靠性极低;
- 信息增强类方法(如SR-TOD)依赖图像重建的差分图,受重建质量影响极大,重建过程会引入额外误差,下采样进一步丢失差分信息;
- 样本优化类方法(RFLA、NWD-RKA)仅优化标签分配策略,无法解决特征表征弱的底层问题,对极小型目标的提升有限。
作者的核心洞察:小目标检测的核心是精准定位并增强信息丢失的弱特征区域,必须从像素级信息量的底层理论出发,结合目标位置先验,实现对小目标特征的针对性增强,而非在现有范式上修修补补。
(2)核心创新贡献
- 理论范式创新:首次从像素级信息量的视角切入小目标检测,提出了基于香农信息论的无监督特征信息建模方法,为弱特征增强提供了严格的数学理论支撑,跳出了现有启发式注意力的框架;
- 技术结构创新:提出了位置高斯分布预测模块,以信息图为先验引导,用自适应缩放的高斯混合模型建模目标位置分布,实现了对越小的目标越强的聚焦,解决了信息图对小目标针对性不足的问题;
- 工程价值创新:设计了完全即插即用的增强框架,可无缝集成到任意FPN类检测器中,在3个权威小目标数据集上刷新SOTA,尤其是极小型目标的检测精度实现了数量级提升,为工业界小目标检测落地提供了开箱即用的方案;
- 研究思路创新:首次实现了「无监督信息定位+有监督位置引导」的双路特征增强范式,两个模块相互调制、协同优化,为低质图像特征增强、开放世界检测等多个方向提供了可借鉴的研究思路。
2. 数学推导与核心技术深度剖析
(1)像素特征信息建模的数学完备性推导
-
可微量化的理论支撑
原始的均匀量化操作是阶跃函数,不可微,无法端到端训练。作者引入加性均匀噪声 U ( − 1 2 , 1 2 ) \mathcal{U}(-\frac{1}{2},\frac{1}{2}) U(−21,21),训练时 y ^ = y + U ( − 1 2 , 1 2 ) \hat{y} = y + \mathcal{U}(-\frac{1}{2},\frac{1}{2}) y^=y+U(−21,21),此时离散化后像素的概率为:
p ( y ^ i ∣ μ i , σ i ) = ∫ y ^ i − 1 2 y ^ i + 1 2 N ( y ∣ μ i , σ i 2 ) d y = F ( y ^ i + 0.5 − μ i σ i ) − F ( y ^ i − 0.5 − μ i σ i ) p(\hat{y}_i|\mu_i,\sigma_i) = \int_{\hat{y}_i-\frac{1}{2}}^{\hat{y}_i+\frac{1}{2}} \mathcal{N}(y|\mu_i,\sigma_i^2) dy = F\left(\frac{\hat{y}_i+0.5-\mu_i}{\sigma_i}\right) - F\left(\frac{\hat{y}_i-0.5-\mu_i}{\sigma_i}\right) p(y^i∣μi,σi)=∫y^i−21y^i+21N(y∣μi,σi2)dy=F(σiy^i+0.5−μi)−F(σiy^i−0.5−μi)
其中F为标准正态分布的CDF,该式是连续可微的,完美解决了量化的反向传播问题,同时保证了离散分布与连续高斯分布的一致性。 -
信息图σ的合理性证明
当最小化信息熵损失 L I E \mathcal{L}_{IE} LIE时,模型的优化目标是让估计分布拟合真实分布。对于高信息量的目标区域,其特征分布的随机性更强,对应的高斯标准差σ更大;而光滑背景的特征分布集中,σ更小。
从编码成本的角度,σ越大,该像素的编码成本越高,信息量越大,因此σ与信息量呈严格正相关,用σ作为信息图并非启发式设计,而是有严格的信息论支撑。 -
梯度流分析
L I E \mathcal{L}_{IE} LIE的梯度直接回传到高斯参数预测网络,优化μ和σ的预测;同时σ作为PGDP模块的输入, L p r e d \mathcal{L}_{pred} Lpred的梯度会进一步优化σ的预测,实现了两个模块的协同优化,让信息图不仅能定位高信息量区域,还能更精准地聚焦小目标。
(2)位置高斯分布建模的关键设计推导
-
自适应缩放因子α的设计逻辑
对于极小型目标(2-8像素),转换到P2层后尺寸仅为0.5-2像素,若α=1,高斯分布的协方差与目标尺寸一致,会导致峰值过高、分布过窄,网络学习难度极大,甚至出现梯度爆炸。
作者通过α缩放协方差,目标越小,α越小,协方差越小,高斯峰越尖,在分布图上的响应越高,既实现了对小目标的加权,又通过归一化处理保证了数值稳定性,这是论文中未明确提及的关键设计细节。 -
加权MSE损失的样本不平衡解决
小目标检测中,前景像素与背景像素的数量比可达1:1000以上,普通MSE损失会完全被背景像素主导。作者给前景像素权重10,背景0.1,损失函数可展开为:
L p r e d = ∑ i = 2 4 ( 10 ∑ p ∈ Ω f o r e ( M p d i ( p ) − M G T ( p ) ) 2 + 0.1 ∑ p ∈ Ω b a c k ( M p d i ( p ) − M G T ( p ) ) 2 ) \mathcal{L}_{pred} = \sum_{i=2}^4 \left( 10\sum_{p\in\Omega_{fore}} (M_{pdi}(p)-M_{GT}(p))^2 + 0.1\sum_{p\in\Omega_{back}} (M_{pdi}(p)-M_{GT}(p))^2 \right) Lpred=i=2∑4 10p∈Ωfore∑(Mpdi(p)−MGT(p))2+0.1p∈Ωback∑(Mpdi(p)−MGT(p))2
其中 Ω f o r e \Omega_{fore} Ωfore为前景区域(超过阈值th), Ω b a c k \Omega_{back} Ωback为背景区域。该设计让网络的优化目标完全聚焦于前景像素,尤其是小目标的像素,从根本上解决了样本不平衡问题。 -
多尺度预测的跳连设计
作者采用从深层到浅层的跳连结构,将深层分支的预Sigmoid输出跳连到浅层分支,利用深层特征的强语义信息辅助浅层分支定位小目标,同时保证了梯度的有效回传,避免了转置卷积导致的梯度消失问题。
3. 工程复现全流程与关键难点解决方案
(1)复现环境与依赖
| 依赖项 | 版本要求 | 说明 |
|---|---|---|
| Python | 3.8+ | 兼容MMDetection的稳定版本 |
| PyTorch | 1.8.0+ | 配合CUDA 11.0+,支持自动混合精度 |
| MMDetection | 2.25.0+ | 论文基于该框架实现,需配套对应版本MMCV |
| MMCV | 1.7.0+ | 与MMDetection版本严格匹配 |
| 硬件 | NVIDIA RTX 4090(24G显存) | 单卡可完成训练,显存不足可开启梯度累积 |
(2)数据集准备
- 数据集下载:
- VisDrone2019-DET:从官方网站下载train/val/test集,标注格式为VOC;
- AI-TOD/AI-TODv2:从官方GitHub仓库下载,标注格式为COCO;
- 格式转换:将所有数据集转为MMDetection支持的COCO格式,注意标注框坐标从原图空间到P2特征空间的转换(除以4);
- 路径配置:在MMDetection的config文件中设置data_root,对应ann_file和img_prefix的路径。
(3)核心模块代码实现关键步骤
-
PFIM模块实现
import torch import torch.nn as nn from torch.distributions import Normal class PFIMModule(nn.Module): def __init__(self, in_channels): super().__init__() # 高斯参数预测网络,2个3x3卷积分别预测μ和σ self.conv_mu = nn.Sequential( nn.Conv2d(in_channels, in_channels, 3, 1, 1), nn.ReLU(), nn.Conv2d(in_channels, in_channels, 3, 1, 1) ) self.conv_sigma = nn.Sequential( nn.Conv2d(in_channels, in_channels, 3, 1, 1), nn.ReLU(), nn.Conv2d(in_channels, in_channels, 3, 1, 1) ) self.relu = nn.ReLU() def forward(self, x): # x: [B, C, H, W],输入P2特征 B, C, H, W = x.shape # 1. 可微量化,训练时加均匀噪声 if self.training: y_hat = x + (torch.rand_like(x) - 0.5) else: y_hat = x # 2. 预测高斯参数μ和σ mu = self.conv_mu(y_hat) sigma = self.relu(self.conv_sigma(y_hat)) + 1e-4 # 避免σ为0 # 3. 计算每个像素的概率 normal_dist = Normal(mu, sigma) cdf_upper = normal_dist.cdf(y_hat + 0.5) cdf_lower = normal_dist.cdf(y_hat - 0.5) prob = cdf_upper - cdf_lower prob = torch.clamp(prob, min=1e-8) # 避免log(0) # 4. 计算信息熵损失 loss_ie = -torch.log2(prob).mean() # 归一化,避免损失值过大 # 5. 生成信息图,通道维度求均值 info_map = sigma.mean(dim=1, keepdim=True) # [B, 1, H, W] # 6. 特征增强 enhanced_feat = x * (1 + info_map) return enhanced_feat, info_map, loss_ie -
PGDP模块实现
- 核心1:M_GT生成函数(数据加载阶段调用,向量化实现,避免循环)
def generate_gt_gaussian_map(bboxes, feat_h, feat_w, img_h, img_w): """ 生成真值高斯分布图 bboxes: [N, 4],xyxy格式,原图坐标 feat_h/feat_w: P2特征的高宽 img_h/img_w: 原图高宽 """ device = bboxes.device gt_map = torch.zeros((feat_h, feat_w), device=device) if len(bboxes) == 0: return gt_map # 坐标转换:原图->P2特征空间 scale_x = feat_w / img_w scale_y = feat_h / img_h x1 = bboxes[:, 0] * scale_x y1 = bboxes[:, 1] * scale_y x2 = bboxes[:, 2] * scale_x y2 = bboxes[:, 3] * scale_y # 计算中心、宽高 cx = (x1 + x2) / 2 cy = (y1 + y2) / 2 w = x2 - x1 h = y2 - y1 # 根据目标尺寸设置α area = w * h alpha = torch.ones_like(area) alpha[area <= 4] = 4 # 极小型2-8px,面积<=4(P2空间) alpha[(area > 4) & (area <= 16)] = 6 # 小型8-16px alpha[(area > 16) & (area <= 64)] = 8 # 中小型16-32px alpha[area > 64] = 10 # 通用目标 # 生成网格坐标 y_grid, x_grid = torch.meshgrid(torch.arange(feat_h, device=device), torch.arange(feat_w, device=device), indexing='ij') x_grid = x_grid.unsqueeze(0) # [1, H, W] y_grid = y_grid.unsqueeze(0) # [1, H, W] # 向量化计算所有高斯分量 cx = cx.unsqueeze(-1).unsqueeze(-1) # [N, 1, 1] cy = cy.unsqueeze(-1).unsqueeze(-1) w = (w / alpha).unsqueeze(-1).unsqueeze(-1) h = (h / alpha).unsqueeze(-1).unsqueeze(-1) # 二维高斯分布计算 gaussian = torch.exp(-((x_grid - cx)**2 / (2 * w**2 + 1e-8) + (y_grid - cy)**2 / (2 * h**2 + 1e-8))) gaussian = gaussian.sum(dim=0) # 叠加所有分量 # 阈值处理,增强前景背景对比度 th = gaussian.mean() mask = gaussian > th gaussian[mask] += 0.5 return gaussian- 核心2:多尺度分布预测网络与加权MSE损失实现,需结合FPN的P2-P4特征,加入跳连结构,实现深监督。
-
整体框架集成
- 在MMDetection的FPN Neck中集成PFIM和PGDP模块,将增强后的P2’替换原始P2,送入检测头;
- 在MMDetection的损失计算中,加入 L I E \mathcal{L}_{IE} LIE和 L p r e d \mathcal{L}_{pred} Lpred,乘以对应权重,与原始检测损失相加。
(4)训练与推理命令
- 单卡训练命令:
python tools/train.py configs/tiny_det/ours_faster_rcnn_r50_fpn_12e_visdrone.py --gpu-id 0 - 多卡分布式训练命令:
bash tools/dist_train.sh configs/tiny_det/ours_faster_rcnn_r50_fpn_12e_visdrone.py 2 - 推理与评估命令:
python tools/test.py configs/tiny_det/ours_faster_rcnn_r50_fpn_12e_visdrone.py work_dirs/ours/epoch_12.pth --eval bbox
(5)复现关键难点与解决方案
| 复现难点 | 问题根源 | 解决方案 |
|---|---|---|
| 信息熵损失 L I E \mathcal{L}_{IE} LIE出现inf/nan | σ为0、概率值为0导致log(0) | 1. 给σ加下限1e-4;2. 概率值clamp到1e-8以上;3. 对损失做均值归一化 |
| 高斯分布图梯度爆炸 | 极小型目标的高斯峰值过高,数值范围过大 | 1. 对高斯分布做最大值归一化;2. 限制α的最小值,避免协方差过小;3. 梯度裁剪,max_norm=10 |
| 显存占用过高 | P2特征尺寸大,M_GT生成和损失计算占用大量显存 | 1. 开启FP16混合精度训练;2. 梯度累积,batch size=1,累积2步;3. 冻结骨干网络前2层,减少计算量 |
| 两个模块收敛不同步,效果下降 | L I E \mathcal{L}_{IE} LIE和 L p r e d \mathcal{L}_{pred} Lpred的收敛速度不一致 | 1. 调整λ1和λ2,不同基线模型单独调优;2. 预热阶段先训练PFIM模块2个epoch,再加入PGDP模块;3. 给两个模块设置不同的学习率 |
| 高分辨率图像推理速度慢 | 增强模块增加了计算量 | 1. 推理时对图像分块处理;2. 用TensorRT对模型做量化加速;3. 知识蒸馏,把增强模块的知识蒸馏到原始检测器,推理时移除额外模块 |
4. 实验结果深度解读与局限性分析
(1)实验结果的深层解读
-
极小型目标的数量级提升
在VisDrone2019上,DetectoRS基线的 A P v t AP_{vt} APvt仅为0.1,加入该方法后提升至3.5,提升了34倍。这是因为现有方法对2-8像素的极小型目标,特征完全被背景淹没,没有任何区分度,而该方法通过信息图和分布图,精准定位并增强了极小型目标的特征,让其激活值显著高于背景,实现了从「完全检测不到」到「稳定检测」的跨越。 -
数据集适配性的本质原因
该方法在AI-TOD上的AP提升(9.7)远大于VisDrone2019(2.0),核心原因是AI-TOD的平均目标尺寸仅12.8像素,远小于VisDrone2019,目标越小,信息丢失越严重,该方法的增益越明显。这证明了该方法的核心优势是解决极端小目标的信息丢失问题,目标越小,效果越突出。 -
与标签分配方法的互补性
该方法结合RFLA后,AP达到29.0,刷新SOTA。RFLA优化的是「哪些样本是正样本」,解决小目标正样本不足的问题;该方法优化的是「正样本的特征够不够强」,解决小目标特征弱表征的问题,两者从不同维度切入小目标检测的瓶颈,具有极强的互补性,这也为未来小目标检测的研究指明了方向:必须同时优化标签分配和特征增强。 -
对比SR-TOD的优势根源
SR-TOD通过「原图-重建图」的差分图定位信息丢失区域,其效果完全依赖图像重建的质量,重建过程会引入额外误差,且差分图经过下采样后会进一步丢失信息;而该方法直接在特征层面建模像素级信息量,无需图像重建,不受重建质量影响,定位更精准,这是其性能优于SR-TOD的核心原因。
(2)实验设计与结果的局限性
- 实验场景的局限性
论文仅在白天、晴朗天气的航拍数据集上验证了效果,未在低光照、大雾、雨雪、压缩失真等恶劣场景下测试,这些场景下图像信噪比低,信息图的区分度会显著下降,性能无法保证。 - 目标类型的局限性
论文仅验证了水平框的目标检测,未对旋转目标、密集遮挡目标做验证。对于旋转目标,水平框的高斯分布建模会引入大量背景噪声;对于密集遮挡的目标,多个高斯分量叠加会导致峰值偏移,定位精度下降。 - 推理效率的缺失
论文未给出加入模块后的推理速度和参数量变化,实际测试中,该模块会给单帧推理增加1-2ms的耗时,对于实时性要求极高的端侧场景(如无人机实时避障),需要进一步轻量化。 - 多尺度适配的不足
论文仅增强了P2层,对P3-P5层的大目标无增益,甚至会因为特征分布的变化导致大目标AP轻微下降,无法实现多尺度目标的同时优化。
5. 局限性与未来研究方向
(1)论文方法的核心局限性
- 多尺度适配能力不足:仅针对P2层增强,无法兼顾大目标检测,无法适配多尺度目标密集的场景;
- 监督依赖问题:PGDP模块依赖目标标注构建真值分布图,无法直接用于无监督、自监督、开放世界的小目标检测场景;
- 时序信息缺失:仅基于单帧图像建模,未利用视频序列的时序信息,在视频小目标检测场景下无法发挥时序跟踪的优势;
- 旋转与遮挡适配差:高斯分布建模基于水平框,对旋转、密集遮挡的目标建模效果差,无法适配遥感、航拍中的旋转目标检测;
- 推理开销不可避免:推理阶段必须保留两个模块,增加了计算量,无法实现「训练时增强,推理时移除」。
(2)未来研究方向
- 多尺度信息建模扩展:将PFIM和PGDP模块扩展到FPN的所有层,针对不同尺度的目标设计自适应的信息量建模和高斯缩放因子,实现多尺度目标的同时增强;
- 无监督位置先验学习:去掉PGDP对标注的依赖,用无监督聚类、自监督特征匹配的方法学习目标的候选区域,构建无监督的位置分布图,实现完全无监督的小目标特征增强;
- 时序信息融合的视频小目标检测:将方法扩展到视频场景,利用时序信息建模连续帧之间的信息量变化,结合目标跟踪算法,实现视频中小目标的稳定检测;
- 旋转高斯分布建模:将二维高斯分布扩展为带旋转角度的椭圆高斯分布,适配旋转目标检测,同时设计遮挡感知的高斯建模方法,解决密集遮挡场景下的目标定位问题;
- 训练增强-推理无损的知识蒸馏:设计知识蒸馏方案,把增强模块学到的特征表征知识蒸馏到原始检测器中,推理时无需额外模块,不增加计算量,实现精度与速度的兼顾;
- 多模态小目标检测扩展:针对红外、SAR、多光谱图像的特性,设计对应的信息量建模方法,将框架扩展到多模态小目标检测场景,提升恶劣天气、夜间等场景下的检测精度。
6. 隐藏难点与潜在研究挑战
(1)论文未明确提及的隐藏难点
- 极小型目标的高斯分布数值稳定性:当目标在P2层的尺寸小于2像素时,高斯分布的峰值会达到1e3以上,极易导致梯度爆炸,论文未提及归一化处理的细节,是复现的核心坑点;
- 损失权重的调优成本: λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2的最优值对不同基线模型、不同数据集差异极大,论文仅给出了VisDrone上DetectoRS的最优值,其他场景需要大量的调参实验;
- 两个模块的协同收敛问题:PFIM和PGDP模块的优化目标存在耦合,若收敛速度不一致,会出现「信息图质量差导致分布图预测不准,分布图梯度反过来恶化信息图」的恶性循环,论文未提及同步优化的策略;
- 高分辨率图像的工程落地挑战:当输入图像分辨率超过4000×3000时,P2层尺寸超过1000×750,M_GT生成和损失计算的显存占用会超过24G,必须做分块处理,论文未给出对应的工程方案。
(2)潜在的研究空白与挑战
- 小目标检测的信息量理论边界:当目标的像素数小于2时,是否存在理论上的检测下限?信息量建模的最小有效像素数是多少?这是小目标检测的底层理论空白,目前尚无相关研究;
- 开放世界小目标检测:现有方法均在闭集数据集上验证,开放世界中未知类别的小目标,信息图能否有效定位?如何在无标注的情况下增强未知类别的小目标特征,是重要的研究空白;
- 低质图像小目标检测的鲁棒性:实际场景中图像的噪声、模糊、压缩失真会严重破坏信息量的建模,如何设计鲁棒的信息量建模方法,应对低质图像的小目标检测,是工业落地的核心挑战;
- 端侧部署的轻量化挑战:现有方法的计算量无法适配无人机、边缘摄像头等端侧设备,如何设计轻量化的信息建模与分布预测模块,在保证精度的同时满足端侧实时性要求,是重要的工程挑战。
全景总结:三个阶段一句话核心概括
- 小白一句话总结:这篇论文给目标检测器装了个「双导航高清放大镜」,能自动找到图片里特别小、容易看不见的目标,把它们变清晰,让检测器轻松识别,而且这个放大镜适配所有主流检测器,对只有几个像素的超小目标效果尤其好。
- 硕士一句话总结:该论文针对小目标检测中信息丢失导致的弱特征表征问题,提出了基于信息熵的无监督像素信息建模模块和自适应位置高斯分布预测模块,构建了即插即用的特征增强框架,在多个权威小目标数据集上实现了显著的精度提升,尤其对极小型目标效果突出。
- 博士一句话总结:该论文首次从像素级信息量的底层理论视角切入小目标检测的核心瓶颈,创新性地结合香农信息论与自适应高斯混合位置先验,实现了对弱激活小目标特征的精准增强,不仅在多个权威数据集上刷新了SOTA性能,更为小目标检测领域提供了从「特征融合」到「信息增强」的全新研究范式,其设计思路对低质图像增强、开放世界检测等多个方向都具有重要的学术与工程价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)