为什么我的 16 核 CPU 跑并行计算反而慢了?—— Java 并行性能陷阱全解析
目录
一、引言:AI后端不只是调包
AI 开发不只是 Python 调包,高性能的预处理和复杂的指令解析离不开编译原理(结构)和并行计算(速度)。
二、代码是如何“被理解”的?(编译原理)
🧩乔姆斯基体系的“降维打击”
- 3 型文法 (Regex): 效率之王,用于大规模数据清洗(ETL)和 Tokenizer 分词。
- 2 型文法 (CFG): 结构之王,处理 JSON、SQL 和代码嵌套的底座。
- 1 型/0 型: 逻辑之王,负责静态代码安全审计。
🧩工业级流水线:从 String 到 Executable
- 展示链路:String ➔ Lexer ➔ Parser ➔ AST ➔ Backend。
- 核心沉淀: 为什么要用 AST(抽象语法树)?
它是代码的“逻辑骨架”。在 AI Agent 开发中,我们可以通过遍历 AST 来拦截危险指令(如 rm -rf),实现沙箱安全。
三、 并行算法及代价
1. 大规模矩阵元素并行处理
我们将模拟一个 AI 激活函数(如 ReLU)的并行计算。在一个巨大的矩阵中,把每个元素进行非线性变换。
// ParallelMatrixProcessor.java
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.ForkJoinPool;
import java.util.Random;
public class ParallelMatrixProcessor extends RecursiveAction {
private static final int THRESHOLD = 100_000; // 任务切分阈值(根据 L3 缓存调整)
private float[] data;
private int start;
private int end;
public ParallelMatrixProcessor(float[] data, int start, int end) {
this.data = data;
this.start = start;
this.end = end;
}
@Override
protected void compute() {
if (end - start <= THRESHOLD) {
// 任务足够小,直接进行“炼丹”:模拟 ReLU 激活函数
for (int i = start; i < end; i++) {
data[i] = Math.max(0, data[i]);
}
} else {
// 任务太大,执行“细胞分裂”
int mid = (start + end) / 2;
ParallelMatrixProcessor leftTask = new ParallelMatrixProcessor(data, start, mid);
ParallelMatrixProcessor rightTask = new ParallelMatrixProcessor(data, mid, end);
// 并行执行:放入 ForkJoin 队列
invokeAll(leftTask, rightTask);
}
}
public static void main(String[] args) {
int size = 10_000_000; // 一千万个神经元输出
float[] matrix = new float[size];
Random rand = new Random();
for (int i = 0; i < size; i++) matrix[i] = rand.nextFloat() - 0.5f;
ForkJoinPool pool = new ForkJoinPool(); // 默认线程数为 CPU 核心数
long startTime = System.currentTimeMillis();
pool.invoke(new ParallelMatrixProcessor(matrix, 0, size));
long endTime = System.currentTimeMillis();
System.out.println("--- [并行计算报告] ---");
System.out.println("处理元素数量: " + size);
System.out.println("耗时: " + (endTime - startTime) + " ms");
System.out.println("系统并行度: " + pool.getParallelism());
}
}
结果: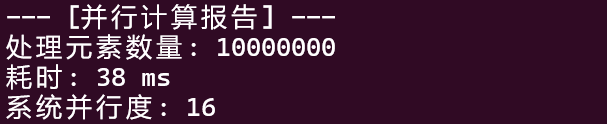
系统并行度 16:意味着 CPU 有 16 个逻辑核心(可能是 8 核 16 线程)。ForkJoinPool 自动识别并创建了 16 条“流水线”同时开工。
后端内功:
- 为什么不用
new Thread()?
线程创建是重量级操作(涉及内核态切换)。ForkJoinPool 复用线程,像池塘里的水,循环使用,效率极高。- THRESHOLD(阈值)的意义:
如果任务切得太细,线程切换的开销会大于计算本身。- Work-Stealing 机制:
如果线程 A 忙完了,它会去线程 B 的队列末尾“偷”一个任务来做。这是 Java 并行计算能榨干多核性能的神技。
2. 验证“并行代价”(Amdahl’s Law)
并行不是越多越快。如果任务太小,线程切换的开销反而会让它变慢。
// SerialVsParallel.java
import java.util.Arrays;
public class SerialVsParallel {
public static void main(String[] args) {
int size = 10_000_000;
// 修改点:float[] -> double[]
double[] data = new double[size];
// 初始化数据
for (int i = 0; i < size; i++) {
data[i] = Math.random() - 0.5;
}
// 1. 串行测试 (单线程)
long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
data[i] = Math.max(0, data[i]);
}
System.out.println("串行耗时: " + (System.currentTimeMillis() - start) + " ms");
// 2. 并行测试 (利用 .parallelStream 思想)
// Arrays.stream(double[]) 会返回 DoubleStream,支持并行
start = System.currentTimeMillis();
Arrays.stream(data).parallel().map(x -> Math.max(0, x)).toArray();
System.out.println("并行(Stream)耗时: " + (System.currentTimeMillis() - start) + " ms");
}
}
结果:
- 为什么不把所有任务都并行化?
因为「管理代价」。当 数据量 < 阈值 时,唤醒线程、分配任务的时间(Overhead)会超过计算时间。这叫“不划算”。- 注意:
- 内存对齐:Java 的 float 是 32 位,double 是 64 位。虽然 double 兼容性好,但在处理上亿级模型参数时,用 double 会导致内存占用翻倍。
- 高性能库:如果非要用 float[] 进行高性能计算,大厂通常会跳过原生 Stream,改用 ND4J(Java 版的 NumPy)或直接通过 JNI 调用 C++/CUDA 算子。
🧩结论
- 任务粒度 (Granularity):只有当单次计算足够重(例如:复杂的矩阵运算、网络请求、大文件 I/O)时,才考虑并行。
- Amdahl 定律:程序能跑多快,取决于它必须串行执行的那部分。并行的管理逻辑就是“不得不跑的串行部分”。
- 不要盲目 Stream:在追求极致性能的 AI 算子层(如自定义 Loss 函数),永远优先使用原生 for 循环或高性能张量库(ND4J/PyTorch),而不是 Java Stream。
四、ThreadPoolExecutor VS ForkJoinPool
1. 核心本质:池化思想
创建线程(Thread)极其昂贵(需要向系统申请栈空间、上下文切换)。ThreadPoolExecutor 的核心就是复用。
-
类比: 你开了一家外卖店。
核心员工 (corePoolSize):无论有没有单,都给发工资的正式工。
订单队列 (workQueue):生意火爆时,挂在墙上的待办小票。
临时工 (maximumPoolSize):小票挂满了,赶紧雇几个兼职。
下班走人 (keepAliveTime):没单了,临时工等一会儿就叫他们滚蛋。
拒绝策略 (handler):小票满了,临时工也满了,直接告诉客人“接不了单了”。 -
后端关联:
这是 API 网关/推理服务器 的核心。当 1000 个用户同时请求你的 AI 接口时,你不可能开 1000 个线程(内存会爆),必须用线程池限制并发数,让请求排队。
2. 写一个AI推理任务调度器
// AIInferencePool.java
import java.util.concurrent.*;
public class AIInferencePool {
public static void main(String[] args) {
// 七大核心参数实战配置
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, // corePoolSize: 2个核心“推理员”
4, // maximumPoolSize: 最多扩展到4个
60, TimeUnit.SECONDS, // 临时工空闲60秒就辞退
new ArrayBlockingQueue<>(5), // 等待队列:最多存5个任务
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy() // 拒绝策略:满了就报错
);
// 模拟 10 个用户同时发起推理请求
for (int i = 1; i <= 10; i++) {
final int taskId = i;
try {
executor.execute(() -> {
System.out.println("用户 " + taskId + " 的任务正在由 " +
Thread.currentThread().getName() + " 处理...");
try { Thread.sleep(2000); } catch (InterruptedException e) {}
});
} catch (RejectedExecutionException e) {
System.err.println("❌ 警告:任务 " + taskId + " 被拒绝,服务器满载!");
}
}
executor.shutdown();
}
}
运行结果:
- 意义:通过控制 corePoolSize 和 maximumPoolSize,你可以精准限制 AI 后端消耗的 CPU 资源,防止因为请求过多导致系统宕机(OOM)。
- 为什么任务 10 被拒绝了?(核心公式)
线程池的承载能力计算公式如下: 承载量 = maximumPoolSize (4) + workQueue容量 (5) = 9
- 任务 1,2:直接交给 corePoolSize (2个核心线程) 处理。
- 任务 3, 4, 5, 6, 7:核心线程满了,它们进入 ArrayBlockingQueue (容量5) 排队。
- 任务 8,9:队列也满了!于是线程池紧急开启“临时工”,把线程数从核心(2)扩容到 maximumPoolSize (4)。这两个任务交给新开的thread-3 和 thread-4。
- 任务 10:核心线程(2)在忙,队列(5)满了,临时工(2)也满了(总共4个线程都在忙)。第 10个任务没地方放了,直接触发 AbortPolicy 拒绝策略。
🧩 现象:为什么任务 8 和 9 比任务 3、4 还要早执行?
从截图里可以看到,thread-3 处理了任务 8,thread-4 处理了任务 9,而任务 3 还在排队等 thread-1 空闲。
直击本质: 在线程池眼里,队列里的任务(3-7)是“存货”,而触发扩容的任务(8-9)是“急件”。
一旦开启了最大线程(临时工),它会直接抢过当前进来的任务去跑,而不会先去队列里拿。队列里的任务必须等有任何一个线程忙完后,去“勾”出来才能执行。
🧩对比 🧩如何配置参数?
🧩如何配置参数?
1. CPU 密集型(如:本地跑模型推理、加密):
corePoolSize 设为 CPU核心数 + 1(你的并行度是 16,那就设 17)。
理由: 核心多了反而会因为上下文切换变慢。
2. IO 密集型(如:调用外部 OpenAI 接口、读写数据库):
corePoolSize 设为 CPU核心数 * 2 甚至更多。
理由: 线程大部分时间在等网络返回,多开点线程能提高吞吐量。
3. 拒绝策略的选择:
本次实验用了 AbortPolicy(直接抛错),这在金融系统中常见。
在 AI 场景,通常建议改用 CallerRunsPolicy(让调用者自己执行),这样能起到自动限流的作用,防止后端被冲垮。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)