基于人类偏好的大语言模型评价与奖励模型构建
项目背景
随着大语言模型的迅速发展,模型不仅需要具备强大的功能,更需要使其回复能符合人类的偏好。本项目通过分析真实对话数据,开发能够模拟人类真实偏好的偏好预测模型。这是基于人类反馈的强化学习(RLHF) 过程中的关键环节,旨在让 AI 通过学习人类的选择偏好来持续优化自身性能。
数据
项目使用数据集为Chatbot Arena开源的人机交互数据集(50000+),数据集文件链接如下:
https://www.kaggle.com/competitions/llm-classification-finetuning/data
平台与配置
本项目于autodl云服务器平台完成,配置如下:
---------------------------------------------------------------------------------------------------------------------------------
镜像:Miniconda conda3 Python 3.10(ubuntu22.04) CUDA 11.8
GPU: RTX 4090D(24GB) * 1
CPU: 16 vCPU Intel(R) Xeon(R) Platinum 8352V CPU @ 2.10GHz
内存: 60GB
系统盘:30 GB
数据盘:免费:50GB SSD 付费:0GB
---------------------------------------------------------------------------------------------------------------------------------
项目代码
1、环境配置
导入环境配置请点击下方链接下载environment.yml文件
import os
os.environ['USE_MODELSCOPE_HUB'] = '1'
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from typing import Dict, List, Optional, Tuple
from datasets import Dataset
import json
import torch
import torch.nn as nn
from torch.nn import functional as F
import modelscope
from modelscope import AutoModel, AutoTokenizer, Trainer, TrainingArguments, TrainerCallback, BitsAndBytesConfig
from modelscope.metainfo import Trainers
import swift
from swift.llm import get_template, TemplateType
from modelscope.hub.api import HubApi
#from modelscope.trainers import TorchModelTrainer
from modelscope import AutoModelForCausalLM
from modelscope.utils.constant import Tasks, ModelFile
from modelscope.utils.config import Config
from modelscope import Model
from swift.trainers import TrainerCallback
from typing import Optional
from modelscope.models import TorchModel
import wandb
from peft import (
LoraConfig,
get_peft_model,
prepare_model_for_kbit_training,
)
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# Backbone model name
MODEL_NAME = "microsoft/deberta-v3-base"
# Max sequence length for input
MAX_SEQUENCE_LENGTH = 512Transformer模型可以分为两大类:encoder模型(代表模型:BERT)与decoder模型(代表模型:ChatGPT、deepseek等)。目前decoder在使用率上远超过encoder模型,这是因为:1、Decoder 模型通过增加参数规模展现出了“涌现”能力,在任务通用性方面远超encoder模型。一个 Llama-3 不仅能做分类,还能翻译、写代码、推理,这种通用性是 Encoder 无法企及的。2、在大规模预训练下,Decoder 架构的扩展性更好。3、现代工业界更倾向于通过 Prompt Engineering(给指令)来解决问题,而不是为每个小任务单独训练一个 Encoder。4、RLHF 的闭环: 最终的对话模型本身就是 Decoder,直接用同架构的模型做奖励模型(Reward Model)在工程对齐上更方便。
导致两者性能表现迥异的最底层原因:注意力机制的差异:双向 vs. 单向
Encoder (以 BERT/DeBERTa 为例):双向观察 (Bidirectional) 在计算每一个词的特征时,Encoder 可以同时看到它左边和右边的所有词。
比喻: 就像做阅读理解,你可以反复翻看全文,根据下文来推断上文某个词的精确含义。
结果: 对语义的理解极其深刻、精准,非常擅长分类、标注和相似度计算。
Decoder (以 GPT/Llama 为例):单向/因果观察 (Causal/Unidirectional) 由于 Decoder 的目标是“预测下一个词”,它在训练时被施加了严格的掩码(Masking),每个词只能看到它之前的词。
比喻: 就像蒙着眼睛写字,写到当前这个词时,你根本不知道后面会发生什么。
结果: 这种“致盲”训练虽然限制了局部信息的获取,却完美契合了生成任务的逻辑。
在本项目中,我们的目的仅是开发能够模拟人类真实偏好的偏好预测模型,任务目标是分类/回归(预测概率),而不是生成文本。而encoder模型由于双向注意力机制。模型能同时看到上下文的所有词,全局理解力强。天生适合判别式任务(分类、相似度、排序)。因此在这里,我们选择deberta-v3-base作为我们的基座模型。
DeBERTa(Decoding-enhanced BERT with disentangled attention)目前被公认为 NLU(自然语言理解)任务的王者。
解耦注意力机制(Disentangled Attention): 传统的 Transformer 将内容和位置向量相加,而 DeBERTa 将其分开处理。这让模型能更精准地理解词汇在句中的逻辑角色和相对位置,对捕捉对话中的微弱语义差异非常有效。DeBERTa 认为,猜一个词不仅要看它的内容(周围是什么词),还要看它的相对位置。普通 BERT: 将词向量(Content)和位置向量(Position)直接相加。这会导致内容和位置信息在模型深层产生“混淆”。DeBERTa 的解耦注意力(Disentangled Attention): 它把内容和位置分开了。计算两个词的关系时,会分别计算:内容对内容、内容对位置、位置对内容。
增强型掩码预测(EMF): 它在预训练阶段比 BERT 或 RoBERTa 效率更高,拥有更强的上下文建模能力。在预训练的最后阶段,DeBERTa 加入了 绝对位置信息。 因为解耦注意力只知道相对位置(比如“我”在“你”左边两个位置),但不知道“我”是否是句子的开头。EMF 在模型输出层之前引入绝对位置,帮助模型在预测被掩盖的 Token 时,拥有上帝视角般的定位能力。为什么效率更高?信息利用率高: 同样的预训练步数,DeBERTa 能够比 BERT 捕捉到更复杂的结构依赖(比如长距离的语法对应)。收敛快: 由于这种解耦的设计,模型不需要花大量的参数去学习如何“区分内容和位置”,它天生就懂,因此在微调(Fine-tuning)小数据集(如你的竞赛数据)时,表现极其稳健。
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# Backbone model name
MODEL_NAME = "microsoft/deberta-v3-base"
# Max sequence length for input
MAX_SEQUENCE_LENGTH = 512读取train、test数据,并做数据预处理
raw_df = pd.read_csv("autodl-tmp/data/train.csv")
test_df = pd.read_csv("autodl-tmp/data/test.csv")
import json
def safe_parse_json(x):
#类型检查:如果输入 x 本身就不是字符串(比如已经是列表或空值 NaN),直接返回原值
if not isinstance(x,str):
return x
#try 尝试将 JSON 字符串转为 Python 对象
try:
val=json.loads(x)
#如果解析出来是列表
if isinstance(val,list):
if val:
# 将列表中的 None 替换为空字符串,防止后续模型处理时报错
return[item if item is not None else '' for item in val]
# 如果列表为空,返回空字符串
else:
return ''
return val
#容错处理:如果 JSON 格式非法(报错),返回空字符串避免程序崩溃
except json.JSONDecodeError:
return ""
raw_df["response_a_processed"] = raw_df["response_a"].apply(safe_parse_json)
raw_df["response_b_processed"] = raw_df["response_b"].apply(safe_parse_json)
raw_df["prompt_processed"] = raw_df["prompt"].apply(safe_parse_json)
test_df["response_a_processed"] = test_df["response_a"].apply(safe_parse_json)
test_df["response_b_processed"] = test_df["response_b"].apply(safe_parse_json)
test_df["prompt_processed"] = test_df["prompt"].apply(safe_parse_json)
def format_conversation(query_list, response_list):
parts = []
for q,r in zip(query_list, response_list):
parts.append(f"query:\n{q}\n\nresponse:\n{r}")
#使用两个换行符作为分隔符,将 parts 列表中的所有元素连接成一个单一的巨大字符串
#join() 功能:负责将一个可迭代对象(如列表、元组)中的多个字符串元素,连接成一个单一的字符串
return '\n\n'.join(parts)
#axis=1告诉 Pandas横向读取每一行
#取值:从当前行取出 prompt_processed(问题列表)和 response_a_processed(回答 A 列表)。
#调用:将这两个列表丢进 format_conversation 函数。
#加工:函数内部使用 zip 和 join 把列表拼成format_conversation函数规定的格式
#赋值:把拼接好的长字符串存入新生成的 text_a 列
raw_df['text_a'] = raw_df.apply(lambda x: format_conversation(x['prompt_processed'], x['response_a_processed']), axis=1)
raw_df['text_b'] = raw_df.apply(lambda x: format_conversation(x['prompt_processed'], x['response_b_processed']), axis=1)
test_df['text_a'] = test_df.apply(lambda x: format_conversation(x['prompt_processed'], x['response_a_processed']), axis=1)
test_df['text_b'] = test_df.apply(lambda x: format_conversation(x['prompt_processed'], x['response_b_processed']), axis=1)
#决定训练时的 max_length(最大截断长度)
#切分单词:将对应列中的每一行字符串按空格拆分成列表
word_split = raw_df["text_a"].apply(lambda x: x.split(' '))
word_split.apply(lambda x: len(x)).describe(percentiles=[0.05, 0.25, 0.5, 0.75, 0.90])
word_split = raw_df["text_b"].apply(lambda x: x.split(' '))
word_split.apply(lambda x: len(x)).describe(percentiles=[0.05, 0.25, 0.5, 0.75, 0.90])
def create_target_col(encoding):
"""
Create column for target labels
"""
if encoding == [0, 0, 1]:
return 'tie'
elif encoding == [0, 1, 0]:
return 'model_b'
elif encoding == [1, 0, 0]:
return 'model_a'
else:
return np.nan
raw_df['target'] = raw_df[['winner_model_a', 'winner_model_b', 'winner_tie']].apply(lambda x: create_target_col(list(x)), axis=1)
raw_df['label'] = raw_df['target'].map({'model_a': 0, 'model_b': 1, 'tie': 2})
#使用 stratify=raw_df["label"]:强制要求训练集和验证集中的类别比例与原始数据保持一致
#否则可能导致验证集里全是 model_a,或者完全没有 tie。这样得到的验证集得分是不可靠的
train_df, eval_df = train_test_split(raw_df, test_size=0.2, random_state=42, stratify=raw_df["label"])from dataclasses import dataclass
from typing import Dict, List, Any
def tokenize_pairwise(batch):
a_encodings = tokenizer(
batch["text_a"],
padding="max_length",
truncation=True,#防止超长文本导致模型报错,严格控制序列长度
max_length=MAX_SEQUENCE_LENGTH,
)
b_encodings = tokenizer(
batch["text_b"],
padding="max_length",
truncation=True,
max_length=MAX_SEQUENCE_LENGTH,
)
#构造输出字典(out_dict)
#函数将分词结果重新包装。input_ids: 文本对应的数字索引序列。
#attention_mask: 告诉模型哪些位置是真实文字(1)哪些位置是填充的废话(0)模型在计算时会忽略0的#位置。
out_dict = {
"a_input_ids": a_encodings["input_ids"],
"a_attention_mask": a_encodings["attention_mask"],
"b_input_ids": b_encodings["input_ids"],
"b_attention_mask": b_encodings["attention_mask"]
}
#如果是训练集,会将之前生成的 0, 1, 2 标签也带上;如果是预测测试集(没有标签),则不添加这一项
if "label" in batch:
out_dict["labels"] = batch["label"]
return out_dicttrain_dataset = Dataset.from_pandas(train_df)
eval_dataset = Dataset.from_pandas(eval_df)#格式化train/eval data
tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME,
use_fast=False,
model_max_length=MAX_SEQUENCE_LENGTH # 显式指定模型最大序列长度,适配后续padding/truncation
)
train_dataset = Dataset.from_pandas(train_df)
eval_dataset = Dataset.from_pandas(eval_df)
train_dataset = train_dataset.map(tokenize_pairwise, batched=True, remove_columns=list(train_df.columns))
eval_dataset = eval_dataset.map(tokenize_pairwise, batched=True, remove_columns=list(eval_df.columns))
train_dataset.set_format(
#将 Hugging Face Dataset 数据集中的指定特征列,从 Python 原生列表格式批量转换为 PyTorch 张量(torch.Tensor)格式
type="torch",
columns=["a_input_ids","a_attention_mask","b_input_ids","b_attention_mask","labels"]
)
eval_dataset.set_format(
type="torch",
columns=["a_input_ids","a_attention_mask","b_input_ids","b_attention_mask","labels"]
)# 格式化test data
test_dataset = Dataset.from_pandas(test_df)
test_dataset = test_dataset.map(tokenize_pairwise, batched=True, remove_columns=list(test_df.columns))
test_dataset.set_format(
type="torch",
columns=["a_input_ids","a_attention_mask","b_input_ids","b_attention_mask"]
)定义双塔编码器分类模型(Pairwise Bi-Encoder Classifier)
双塔模型 (Bi-Encoder) 的核心思想是:将两个不同的输入(比如问题 A 和回答 B)分别输入到两个结构完全相同、权重共享的编码器(Encoder)中,提取出各自的特征向量,最后再将这两个向量放在一起进行对比或分类。权重共享:这是关键。两个塔其实是同一个模型。这样可以保证模型对 A 和 B 的评价标准是统一的。用途:最常用于语义相似度计算(判断两句话意思是否接近)和重排序任务(判断哪一个搜索结果更好)。
import inspect
#该任务归属于语义相似度、主题分类任务,更需要保留了句子整体的语义结构,更适合使用平均池化。
#最大池化更倾向于保留最显眼的特征,丢失背景。更适合关键词提取、情感极性分析
def mean_pool(last_hidden_state: torch.Tensor, attention_mask: torch.Tensor) -> torch.Tensor:
mask = attention_mask.unsqueeze(-1).type_as(last_hidden_state)
summed = (last_hidden_state * mask).sum(dim=1) #Mask中有效文字的位置是1,填充位是0。相乘后,所有补零位置的特征向量全部变成0
count = mask.sum(dim=1).clamp(min=1e-9)
return summed / count
class PairwiseBiEncoderClassifierConfig(PretrainedConfig):
model_type = "pairwise-biencoder-classifier"
def __init__(
self,
base_model_name: Optional[str] = None,
hidden_size: int = 768,
num_labels: int = 3,
dropout: float = 0.2,
**kwargs,
):
super().__init__(**kwargs)
self.base_model_name = base_model_name
self.hidden_size = hidden_size
self.num_labels = num_labels
self.hidden_dropout_prob = dropout
self.eos_token_id = kwargs.get("eos_token_id", None)
self.pad_token_id = kwargs.get("pad_token_id", None)
self.bos_token_id = kwargs.get("bos_token_id", None)
class PairwiseBiEncoderForSequenceClassification(TorchModel):
config_class = PairwiseBiEncoderClassifierConfig
def __init__(self, config: PairwiseBiEncoderClassifierConfig, encoder: Optional[nn.Module] = None):
"""
If `encoder` is provided, it will be used; otherwise AutoModel.from_pretrained(config.base_model_name)
is used to construct the encoder.
"""
super().__init__(config)
# Use provided encoder (useful when you loaded quantized backbone) or build from config.base_model_name
self.config = config
self.model_meta = Config({"model_type": "custom", "model_arch": "encoder"})
if encoder is not None:
self.encoder = encoder
# try to sync config.hidden_size if not already set
if getattr(self.config, "hidden_size", None) is None and getattr(self.encoder, "config", None):
self.config.hidden_size = self.encoder.config.hidden_size
else:
if not getattr(self.config, "base_model_name", None):
raise ValueError("Either pass `encoder` or set config.base_model_name.")
# load from base model name; allow user to pass quantization via from_pretrained external call if desired
self.encoder = AutoModel.from_pretrained(self.config.base_model_name)
hidden_size = self.config.hidden_size
self.dropout = nn.Dropout(self.config.hidden_dropout_prob)
# classifier sized from config.hidden_size and config.num_labels
# 4 * hidden_size 因为 hA, hB, abs(hA - hB), hA * hB
self.classifier = nn.Sequential(
nn.Linear(4 * hidden_size, 2 * hidden_size),
nn.GELU(),
nn.Linear(2 * hidden_size, hidden_size),
nn.GELU(),
nn.Dropout(0.2),
nn.Linear(hidden_size, hidden_size // 2),
nn.GELU(),
nn.Dropout(0.2),
nn.Linear(hidden_size // 2, self.config.num_labels),
)
# Initialize weights and apply final HF hooks
""" self.post_init() """
self.init_weights()
# ----------------- pooling + encoding (same robust logic) -----------------
def _encode(self, input_ids, attention_mask):
while True:
if hasattr(raw_model, "encoder") and "modelscope" in str(type(raw_model)):
raw_model = raw_model.encoder
elif hasattr(raw_model, "model") and "modelscope" in str(type(raw_model)):
raw_model = raw_model.model
else:
break
# 2. 准备参数
candidate_inputs = {
"input_ids": input_ids,
"attention_mask": attention_mask,
"return_dict": True
}
# 3. 动态检查底层 forward 支持哪些参数
forward_params = inspect.signature(raw_model.forward).parameters
inputs = {k: v for k, v in candidate_inputs.items() if k in forward_params}
# 4. 【关键】显式调用底层 forward,跳过所有包装类的逻辑
out = raw_model.forward(**inputs)
# 5. 提取特征
if hasattr(out, "last_hidden_state"):
last_hidden_state = out.last_hidden_state
elif isinstance(out, (tuple, list)):
last_hidden_state = out[0]
else:
last_hidden_state = getattr(out, "last_hidden_state", None)
if last_hidden_state is not None:
return mean_pool(last_hidden_state, attention_mask)
raise ValueError(f"无法提取特征。模型类路径: {type(raw_model)}")
# ----------------- forward (compatible with HF Trainer / PEFT) -----------------
def forward(
self,
a_input_ids: torch.Tensor,
a_attention_mask: torch.Tensor,
b_input_ids: torch.Tensor,
b_attention_mask: torch.Tensor,
labels: Optional[torch.Tensor] = None,
**kwargs,
):
#self._encode 被调用了两次,但使用的是同一个encoder权重。这保证了模型对回答A和回答B的“审美标准”是完全一致的
hA = self._encode(a_input_ids, a_attention_mask)
hB = self._encode(b_input_ids, b_attention_mask)
#为了让模型能精准对比 A 和 B,仅仅把它们拼接在一起是不够的。这里引入了额外的相互作用项:
#hA, hB:让分类器知道两个回答各自的“绝对水平”。
#torch.abs(hA - hB):计算曼哈顿距离。它告诉模型这两个回答在语义空间中离得有多远。如果两段话完全一样,这一项就是 0。
#hA * hB:哈达玛积(逐元素乘法)。它捕捉两个回答之间的相似性或共性。
#结果:comb 的维度变成了原始维度的 4 倍
comb = torch.cat([hA, hB, torch.abs(hA - hB), hA * hB], dim=-1)
logits = self.classifier(self.dropout(comb))
loss = None
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss_fct = loss_fct.to(logits.device)
loss = loss_fct(logits.view(-1, self.config.num_labels), labels.view(-1))
# return HF-style outputs: for Trainer it's OK to return a dict with 'loss' and 'logits'
return {"loss": loss, "logits": logits}
# ----------------- freeze/unfreeze adapted for k-bit params -----------------
def freeze_backbone(self):
for name, param in self.encoder.named_parameters():
dt = getattr(param, "dtype", None)
if dt is None or not dt.is_floating_point:
continue
param.requires_grad = False
def unfreeze_backbone(self):
skipped = []
for name, param in self.encoder.named_parameters():
dt = getattr(param, "dtype", None)
if dt is None or not dt.is_floating_point:
skipped.append(name)
continue
param.requires_grad = True
if skipped:
print(f"Warning: skipped unfreezing {len(skipped)} non-float params (examples): {skipped[:6]}")
def is_backbone_frozen(self) -> bool:
float_params = [p for _, p in self.encoder.named_parameters() if getattr(p, "dtype", None) is not None and p.dtype.is_floating_point]
return not any(p.requires_grad for p in float_params)
# ---- place inside PairwiseBiEncoderForSequenceClassification ----
def get_input_embeddings(self):
"""
Return the input embeddings module. PEFT/transformers call this to
enable input-require-grads behavior for gradient checkpointing.
"""
# Try direct encoder, then encoder.base_model, then self.encoder (fallback)
for cand in (getattr(self, "encoder", None), getattr(self.encoder, "base_model", None)):
if cand is None:
continue
get_emb = getattr(cand, "get_input_embeddings", None)
if callable(get_emb):
return get_emb()
# fallback: delegate to PreTrainedModel (will raise if not available)
""" return super().get_input_embeddings() """
raise NotImplementedError(
"Failed to set input embeddings! "
"Please check if `self.encoder` is a valid ModelScope pre-trained model."
)
def set_input_embeddings(self, value):
"""
Allow setting of the input embeddings module (delegated to encoder).
"""
for cand in (getattr(self, "encoder", None), getattr(self.encoder, "base_model", None)):
if cand is None:
continue
set_emb = getattr(cand, "set_input_embeddings", None)
if callable(set_emb):
return set_emb(value)
""" return super().set_input_embeddings(value) """
raise NotImplementedError(
"Failed to set input embeddings! "
"Please check if `self.encoder` is a valid ModelScope pre-trained model."
)
def gradient_checkpointing_enable(self, **kwargs):
# 明确要尝试的模块列表(不包含 self)
target_modules = []
# 优先尝试 encoder
if hasattr(self, "encoder") and self.encoder is not None:
target_modules.append(self.encoder)
# 如果是 ModelScope 的包装类,把里面的真实模型也加进去
if hasattr(self.encoder, "model"):
target_modules.append(self.encoder.model)
# 执行搜索和调用逻辑
for module in target_modules:
if hasattr(module, "gradient_checkpointing_enable"):
# 获取该模块的方法
fn = getattr(module, "gradient_checkpointing_enable")
# 检查该方法是否就是当前正在执行的这个方法(防止间接递归)
if fn.__func__ is self.gradient_checkpointing_enable.__func__:
continue
try:
fn(**kwargs)
return
except TypeError:
fn()
return
# 最终回退方案:遍历所有子模块(排除 self)
for module in self.modules():
# 跳过 self 自身,只处理真正的子模块
if module is self:
continue
if hasattr(module, "gradient_checkpointing_enable"):
fn = getattr(module, "gradient_checkpointing_enable")
try:
fn(**kwargs)
return
except TypeError:
fn()
return
def gradient_checkpointing_disable(self, **kwargs):
target_modules = []
if hasattr(self, "encoder") and self.encoder is not None:
target_modules.append(self.encoder)
if hasattr(self.encoder, "model"):
target_modules.append(self.encoder.model)
for module in target_modules:
if hasattr(module, "gradient_checkpointing_disable"):
fn = getattr(module, "gradient_checkpointing_disable")
if fn.__func__ is self.gradient_checkpointing_disable.__func__:
continue
try:
fn(**kwargs)
return
except TypeError:
fn()
return
for module in self.modules():
if module is self:
continue
if hasattr(module, "gradient_checkpointing_disable"):
fn = getattr(module, "gradient_checkpointing_disable")
try:
fn(**kwargs)
return
except TypeError:
fn()
return
for module in self.modules():
if module is self:
continue
if hasattr(module, "gradient_checkpointing_disable"):
fn = getattr(module, "gradient_checkpointing_disable")
try:
fn(**kwargs)
# print(f"[gradient_checkpointing_disable] called on child {module} with kwargs={kwargs}")
return
except TypeError:
fn()
# print(f"[gradient_checkpointing_disable] called on child {module} without kwargs")
return
# print("[gradient_checkpointing_disable] no module found to disable gradient checkpointing")
class FreezeUnfreezeCallback(TrainerCallback):
"""
Freezes backbone for initial epochs, then unfreezes later.
"""
def __init__(self, unfreeze_at_epoch: int = 1):
self.unfreeze_at_epoch = unfreeze_at_epoch
self.has_unfrozen = False
def on_epoch_begin(self, args, state, control, model=None, **kwargs):
if state.epoch < self.unfreeze_at_epoch:
if not model.is_backbone_frozen():
print(f"Epoch {int(state.epoch)}: Freezing backbone.")
model.freeze_backbone()
elif not self.has_unfrozen:
print(f"Epoch {int(state.epoch)}: Unfreezing backbone.")
model.unfreeze_backbone()
self.has_unfrozen = True将多个单独的数据样本组合成一个可以被模型处理的Batch
from dataclasses import dataclass
from typing import List, Any, Dict
import torch
@dataclass
class PairwiseDataCollator:
tokenizer: Any
padding: str = "longest" # "longest" or "max_length"
max_length: int = 128
def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, torch.Tensor]:
# defensive: filter out None
features = [f for f in features if f is not None and isinstance(f, dict)]
if len(features) == 0:
raise ValueError("Empty batch after filtering None features in collator.")
# ensure required keys exist
for i, f in enumerate(features):
for k in ("a_input_ids", "a_attention_mask", "b_input_ids", "b_attention_mask"):
if k not in f:
raise ValueError(f"Missing key {k} in feature at batch pos {i}: keys={list(f.keys())}")
a_feats = [{"input_ids": f["a_input_ids"], "attention_mask": f["a_attention_mask"]} for f in features]
b_feats = [{"input_ids": f["b_input_ids"], "attention_mask": f["b_attention_mask"]} for f in features]
# NOTE: truncation should have been done during tokenization (when creating the dataset).
# pad() does not take `truncation` argument on many tokenizers, so we remove it here.
pad_kwargs = {"padding": self.padding, "return_tensors": "pt"}
if self.padding == "max_length":
pad_kwargs["max_length"] = self.max_length
a_batch = self.tokenizer.pad(a_feats, **pad_kwargs)
b_batch = self.tokenizer.pad(b_feats, **pad_kwargs)
out = {
"a_input_ids": a_batch["input_ids"],
"a_attention_mask": a_batch["attention_mask"],
"b_input_ids": b_batch["input_ids"],
"b_attention_mask": b_batch["attention_mask"],
}
# optional labels
if "labels" in features[0]:
labels = [int(f["labels"]) for f in features]
out["labels"] = torch.tensor(labels, dtype=torch.long)
# carry ids if present (not tensorized)
if "id" in features[0]:
out["ids"] = [f.get("id") for f in features]
return outbackbone = Model.from_pretrained(MODEL_NAME) #quantization_config=quant_config, device_map="auto"
temp_backbone = backbone
while hasattr(temp_backbone, "model") and "modelscope" in str(type(temp_backbone)):
temp_backbone = temp_backbone.model
real_config = temp_backbone.config
backbone = temp_backbone
hidden_size = getattr(real_config, "hidden_size", getattr(real_config, "d_model", 768))
max_pos = getattr(real_config, "max_position_embeddings", 512)
assert MAX_SEQUENCE_LENGTH <= max_pos, f"MAX_SEQUENCE_LENGTH ({MAX_SEQUENCE_LENGTH}) 超过模型上限 ({max_pos})"
# Build config (hidden_size will be inferred if you want)
cfg = PairwiseBiEncoderClassifierConfig(base_model_name=MODEL_NAME, hidden_size=hidden_size, num_labels=3)
cfg.eos_token_id = getattr(real_config, "eos_token_id", None)
cfg.pad_token_id = getattr(real_config, "pad_token_id", None)
cfg.sep_token_id = getattr(backbone.config, "sep_token_id", None)
# Create wrapper model using prebuilt backbone
model = PairwiseBiEncoderForSequenceClassification(cfg, encoder=backbone)模型预训练,并通过wandb监测模型训练过程
from transformers import AutoTokenizer, AutoModel, AutoConfig
AutoConfig.register("pairwise-biencoder-classifier", PairwiseBiEncoderClassifierConfig)
AutoModel.register(PairwiseBiEncoderClassifierConfig, PairwiseBiEncoderForSequenceClassification)
import wandb
wandb.login(key="") # <-替换为你的key
# find last checkpoint path (example)
from transformers.trainer_utils import get_last_checkpoint
import os
from modelscope.hub.api import HubApi
from modelscope.hub.file_download import model_file_download
from modelscope.utils.constant import ModelFile
api = HubApi()
api.login("") # <-替换为你的key
data_collator = PairwiseDataCollator(tokenizer=tokenizer)
training_args = TrainingArguments(
output_dir="autodl-tmp/pretrain/v20260202",
num_train_epochs=2,
per_device_train_batch_size=64,
eval_strategy="steps",
eval_steps=200,
learning_rate=5e-5,
lr_scheduler_type="cosine",
warmup_ratio=0.05,
report_to='wandb',
save_strategy="steps",
save_steps=200,
save_total_limit=3, # keep last n checkpoints (optional)
load_best_model_at_end=True, # optional
save_safetensors=False, # recommended
gradient_checkpointing=True,
gradient_checkpointing_kwargs={"use_reentrant": False},
logging_steps=200, # 每200步打印一次日志(包含train_loss)
logging_first_step=True, # 可选:打印第一步的损失
logging_dir="autodl-tmp/pretrain/logs"
)
training_args.max_epochs = training_args.num_train_epochs
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
processing_class=tokenizer,
data_collator=data_collator,
callbacks=[FreezeUnfreezeCallback(unfreeze_at_epoch=0)], # add callback here
)
if os.path.exists(training_args.output_dir):
ckpt_path = get_last_checkpoint(training_args.output_dir)
else:
ckpt_path = None
print("Resolved checkpoint path:", ckpt_path)
# If checkpoint found, disable gradient checkpointing on wrapped modules before resuming
if ckpt_path is not None:
# prefer delegators on model (add these if you haven't already)
if hasattr(model, "gradient_checkpointing_disable"):
model.gradient_checkpointing_disable()
else:
# try encoder and all submodules as fallback
if hasattr(model, "encoder") and hasattr(model.encoder, "gradient_checkpointing_disable"):
model.encoder.gradient_checkpointing_disable()
else:
for module in model.modules():
if hasattr(module, "gradient_checkpointing_disable"):
module.gradient_checkpointing_disable()
# sanity checks: list files in checkpoint
print("Checkpoint files:", os.listdir(ckpt_path))
# resume+
trainer.train(resume_from_checkpoint=ckpt_path)
else:
print("No checkpoint found, starting fresh training.")
trainer.train()将预训练的模型推送到modelscope
def upload_to_modelscope(model_dir, modelscope_repo_id, private=False):
"""
使用 push_model 一键上传整个模型目录
"""
from modelscope.hub.constants import ModelVisibility
# 1. 尝试创建仓库(如果不存在)
try:
api.create_model(
model_id=modelscope_repo_id,
visibility=ModelVisibility.PRIVATE if private else ModelVisibility.PUBLIC
)
print(f"仓库 {modelscope_repo_id} 创建成功或已存在")
except Exception as e:
print(f"检查仓库状态: {e}")
# 2. 一键上传目录
print(f"正在上传目录: {model_dir} ...")
api.push_model(
model_id=modelscope_repo_id,
model_dir=model_dir,
commit_message="Upload my fine-tuned model"
)
print(f"✅ 上传完成!地址: https://www.modelscope.cn/models/{modelscope_repo_id}")
# 调用上传函数
# 注意:替换为你的ModelScope用户名和自定义模型名
MODEL_SCOPE_REPO_ID = "Altorious/llm_classication_finetuning_classifier"
upload_to_modelscope(
model_dir=ckpt_path,
modelscope_repo_id=MODEL_SCOPE_REPO_ID,
private=False # 公开仓库设为False,私有设为True
)
print("finish")微调参数配置
# Trained model name from above step
PAIRWISE_BIENCODER_MODEL_NAME = "autodl-tmp/llmclassifier/Altorious/llm_classication_finetuning_classifier"
# Use quantization
USE_4BIT = True
# PEFT/LoRA Params
LORA_TARGETS = ["query_proj", "key_proj", "value_proj", "dense"]
LORA_R = 8
LORA_ALPHA = 16
LORA_DROPOUT = 0.05
QLoRA(4-bit)
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(
load_in_4bit=USE_4BIT,
load_in_8bit=not USE_4BIT,
bnb_4bit_quant_type="nf4" if USE_4BIT else None,
bnb_4bit_use_double_quant=True if USE_4BIT else None,
bnb_4bit_compute_dtype=torch.bfloat16 if USE_4BIT and torch.cuda.is_available() else None,
)
# Apply LoRA
lora_cfg = LoraConfig(
r=LORA_R,
lora_alpha=LORA_ALPHA,
lora_dropout=LORA_DROPOUT,
target_modules=LORA_TARGETS,
bias="none",
task_type="SEQ_CLS",
base_model_name_or_path = PAIRWISE_BIENCODER_MODEL_NAME,
)
from modelscope import AutoTokenizer, AutoModel, AutoConfig
config = AutoConfig.from_pretrained(PAIRWISE_BIENCODER_MODEL_NAME, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("microsoft/deberta-v3-base", trust_remote_code=True)
model = AutoModel.from_pretrained(PAIRWISE_BIENCODER_MODEL_NAME, config=config, trust_remote_code=True)
quant_encoder = AutoModel.from_pretrained(
model.config.base_model_name,
quantization_config=quant_config,
trust_remote_code=True,
)
model.encoder = quant_encoder
# Prepare backbone for k-bit training
model = prepare_model_for_kbit_training(model)
model.config._name_or_path = PAIRWISE_BIENCODER_MODEL_NAME
model.config.base_model_name_or_path = PAIRWISE_BIENCODER_MODEL_NAME
model.freeze_backbone()
# Prepare model for quantization and LoRA
model = get_peft_model(model, lora_cfg)
查看可训练参数,降至3.8087%
model.print_trainable_parameters()查看lora成功挂载到了哪些层上
print(model.targeted_module_names)lora微调训练
from transformers import Trainer
# find last checkpoint path (example)
from transformers.trainer_utils import get_last_checkpoint
import os
data_collator = PairwiseDataCollator(tokenizer=tokenizer)
training_args = TrainingArguments(
output_dir="autodl-tmp/v20260304",
num_train_epochs=4,
per_device_train_batch_size=80,
eval_strategy="steps",
eval_steps=200,
learning_rate=2e-4,
lr_scheduler_type="cosine",
warmup_ratio=0.05,
report_to="wandb",
push_to_hub=False,
save_strategy="steps",
save_steps=200,
save_total_limit=1,
load_best_model_at_end=True,
save_safetensors=True,
gradient_checkpointing=True,
gradient_checkpointing_kwargs={"use_reentrant": False},
logging_steps=200, # 每100步打印一次日志(包含train_loss)
logging_first_step=True, # 可选:打印第一步的损失
logging_dir="autodl-tmp/peft_logs"
)
training_args.max_epochs = training_args.num_train_epochs
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
#callbacks=[FreezeUnfreezeCallback(unfreeze_at_epoch=2)], # ⬅️ add callback here
)
if os.path.exists(training_args.output_dir):
ckpt_path = get_last_checkpoint(training_args.output_dir)
else:
ckpt_path = None
print("Resolved checkpoint path:", ckpt_path)
# If checkpoint found, disable gradient checkpointing on wrapped modules before resuming
if ckpt_path is not None:
# prefer delegators on model (add these if you haven't already)
if hasattr(model, "gradient_checkpointing_disable"):
model.gradient_checkpointing_disable()
else:
# try encoder and all submodules as fallback
if hasattr(model, "encoder") and hasattr(model.encoder, "gradient_checkpointing_disable"):
model.encoder.gradient_checkpointing_disable()
else:
for module in model.modules():
if hasattr(module, "gradient_checkpointing_disable"):
module.gradient_checkpointing_disable()
# sanity checks: list files in checkpoint
print("Checkpoint files:", os.listdir(ckpt_path))
# resume
trainer.train(resume_from_checkpoint=ckpt_path)
else:
print("No checkpoint found, starting fresh training.")
trainer.train()推送到modelscope
def upload_to_modelscope(model_dir, modelscope_repo_id, private=False):
"""
使用 push_model 一键上传整个模型目录
"""
from modelscope.hub.constants import ModelVisibility
# 1. 尝试创建仓库(如果不存在)
try:
api.create_model(
model_id=modelscope_repo_id,
visibility=ModelVisibility.PRIVATE if private else ModelVisibility.PUBLIC
)
print(f"仓库 {modelscope_repo_id} 创建成功或已存在")
except Exception as e:
print(f"检查仓库状态: {e}")
# 2. 一键上传目录
print(f"正在上传目录: {model_dir} ...")
api.push_model(
model_id=modelscope_repo_id,
model_dir=model_dir,
commit_message="Upload my fine-tuned model"
)
print(f"✅ 上传完成!地址: https://www.modelscope.cn/models/{modelscope_repo_id}")
# 调用上传函数
# 注意:替换为你的ModelScope用户名和自定义模型名
MODEL_SCOPE_REPO_ID = "Altorious/llm_classication_finetuning_peft_finetuned"
upload_to_modelscope(
model_dir=ckpt_path,
modelscope_repo_id=MODEL_SCOPE_REPO_ID,
private=False # 公开仓库设为False,私有设为True
)
print("finish")SAVE_DIR = "autodl-tmp/save"
model.save_pretrained(
SAVE_DIR,
safe_serialization=True, # 新增:生成 safetensors 而非 bin 文件
push_to_hub=False # 新增:避免自动推送到HF,仅保存到本地
)
tokenizer.save_pretrained(SAVE_DIR)
# 步骤1:把模型配置转为字典
config_dict = model.config.to_dict()
# 步骤2:补充 ModelScope 必需字段(确保平台能识别模型)
config_dict["model_type"] = "deberta-v2" # DeBERTa-v3 属于 deberta-v2 类型
config_dict["task"] = "text-classification" # 你的任务是文本分类
config_dict["framework"] = "pytorch" # 框架类型
# 步骤3:写入 configuration.json 文件(ModelScope 强制要求的文件名)
config_path = os.path.join(SAVE_DIR, "configuration.json")
with open(config_path, "w", encoding="utf-8") as f:
json.dump(config_dict, f, indent=2, ensure_ascii=False)
print("end")加载lora训练后的最终模型,用测试集测试,生成测试结果文件
from modelscope import snapshot_download
model_dir = snapshot_download('Altorious/llm_classication_finetuning_peft_finetuned', cache_dir ="autodl-tmp/adapter")
from peft import PeftModel, PeftConfig
from modelscope import snapshot_download
base_model_dir = snapshot_download(MODEL_NAME)
ADAPTER_REPO = "autodl-tmp/adapter"
classifier_path = "autodl-tmp/classifier"
adapter_config = PeftConfig.from_pretrained(ADAPTER_REPO, local_files_only=True)
tokenizer = AutoTokenizer.from_pretrained(classifier_path, fix_mistral_regex=True, local_files_only=True)
base_model_config = AutoConfig.from_pretrained(classifier_path, trust_remote_code=True, local_files_only=True)
base_model = AutoModel.from_pretrained(classifier_path, config=base_model_config, trust_remote_code=True, local_files_only=True)
# Load the Lora model
inference_model = PeftModel.from_pretrained(base_model, ADAPTER_REPO, local_files_only=True)
print("end")
import torch
from tqdm import tqdm
from torch.utils.data import DataLoader
import torch.nn.functional as F
dataloader = DataLoader(
test_dataset,
batch_size=16, # or whatever fits GPU
shuffle=False
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
all_logits = []
for step, batch in enumerate(tqdm(dataloader)):
# batch.to(device)
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(
a_input_ids=batch["a_input_ids"],
a_attention_mask=batch["a_attention_mask"],
b_input_ids=batch["b_input_ids"],
b_attention_mask=batch["b_attention_mask"],
)
all_logits.append(outputs['logits'].cpu())
logits = torch.cat(all_logits, dim=0)
probs = F.softmax(logits, dim=-1).cpu().numpy()
preds = logits.argmax(dim=-1)
print("Softmax概率值:")
print(probs)
sub = pd.DataFrame()
sub['id'] = test_df['id']
sub['winner_model_a']=probs[:,0]
sub['winner_model_b']=probs[:,1]
sub['winner_tie']=probs[:,2]
sub
sub.to_csv('submission.csv', index=False)
pd.read_csv("submission.csv")初次训练,设定学习率2e-4,lora训练4轮,预热0.05
发现eval_loss存在震荡,不稳定的问题,kaggle得分1.24186
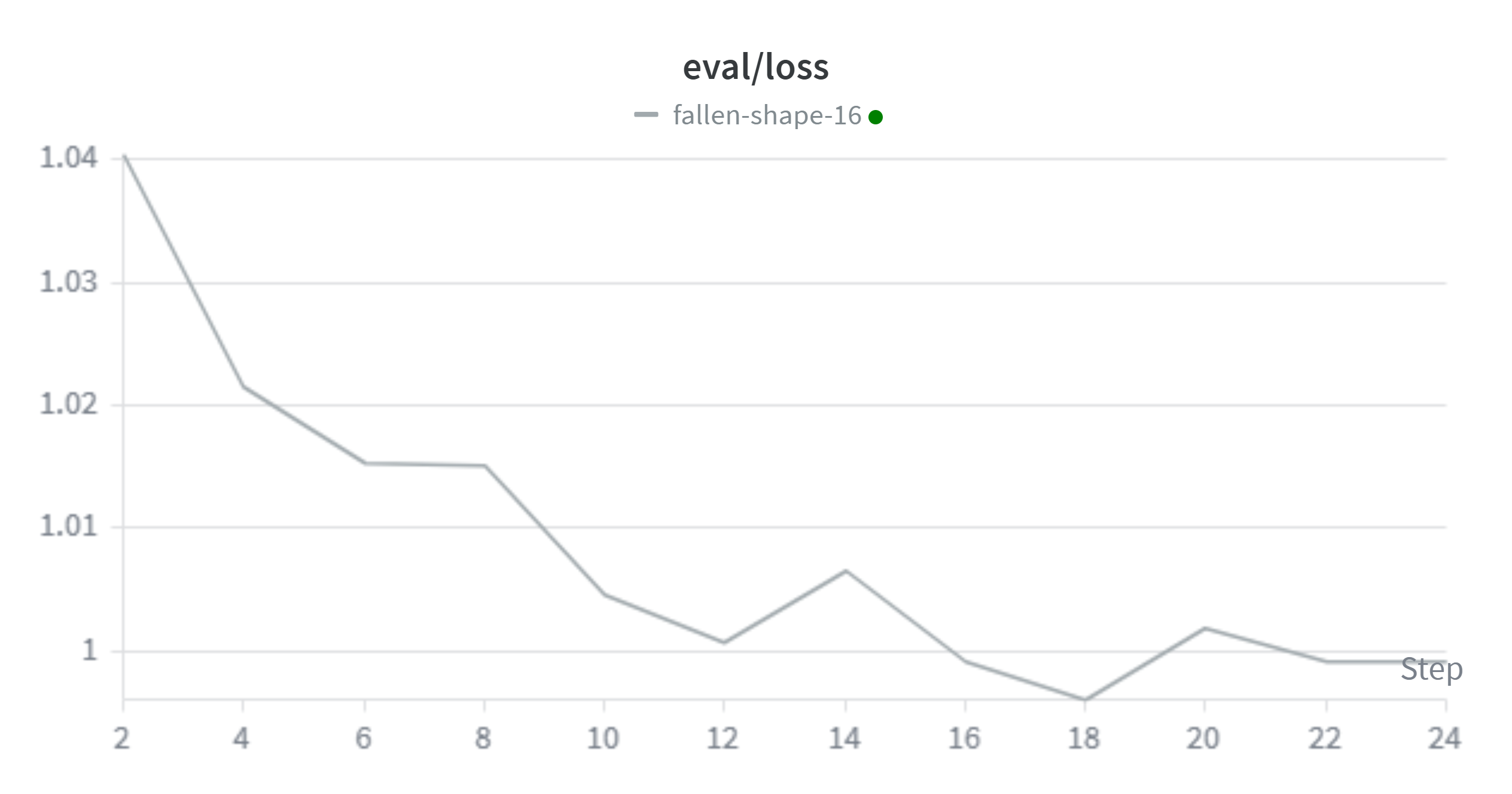
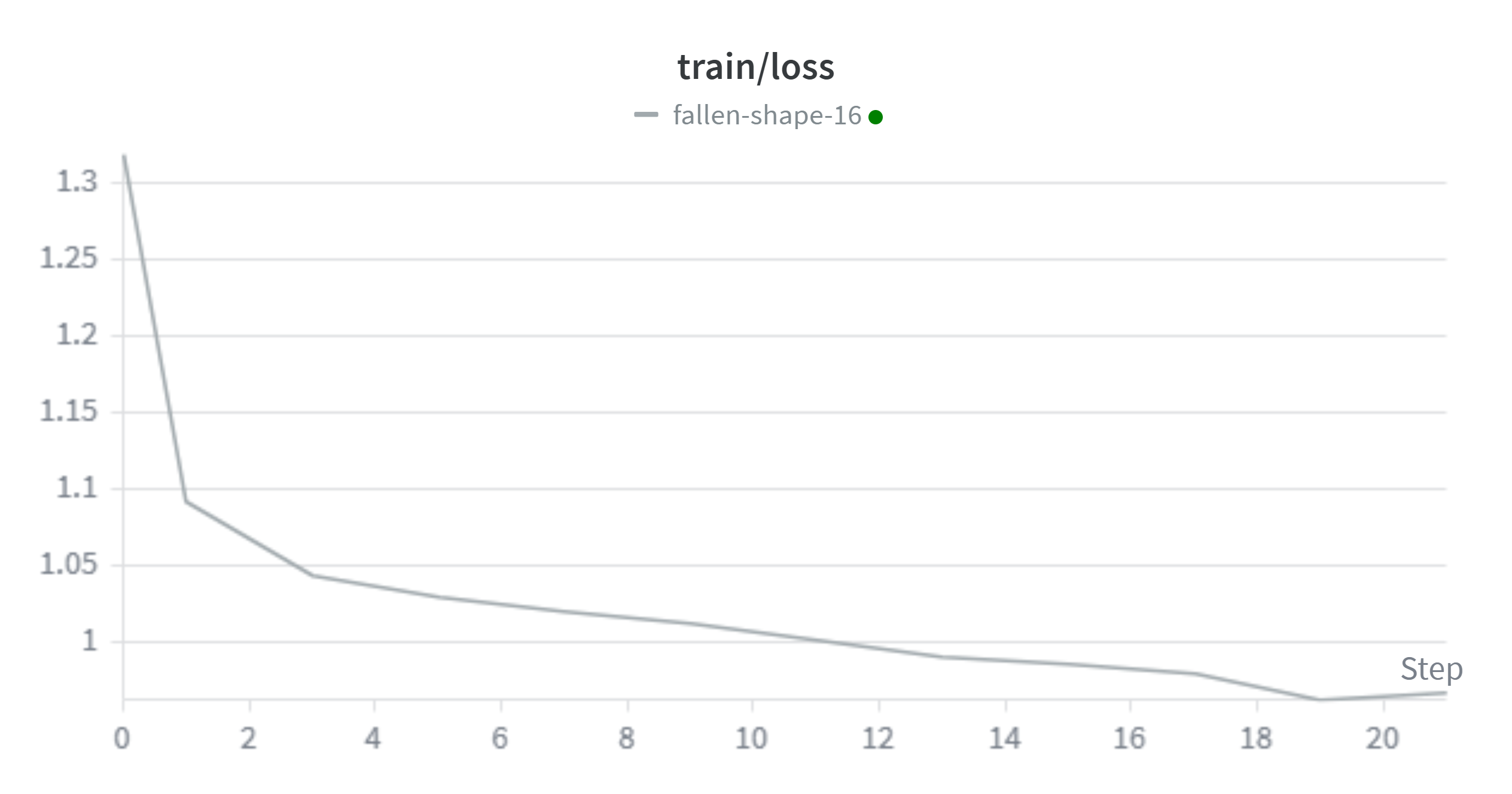
多轮调整后,设定学习率2e-5,lora训练8轮,预热0.1
发现eval_loss震荡现象改善,kaggle得分1.17475
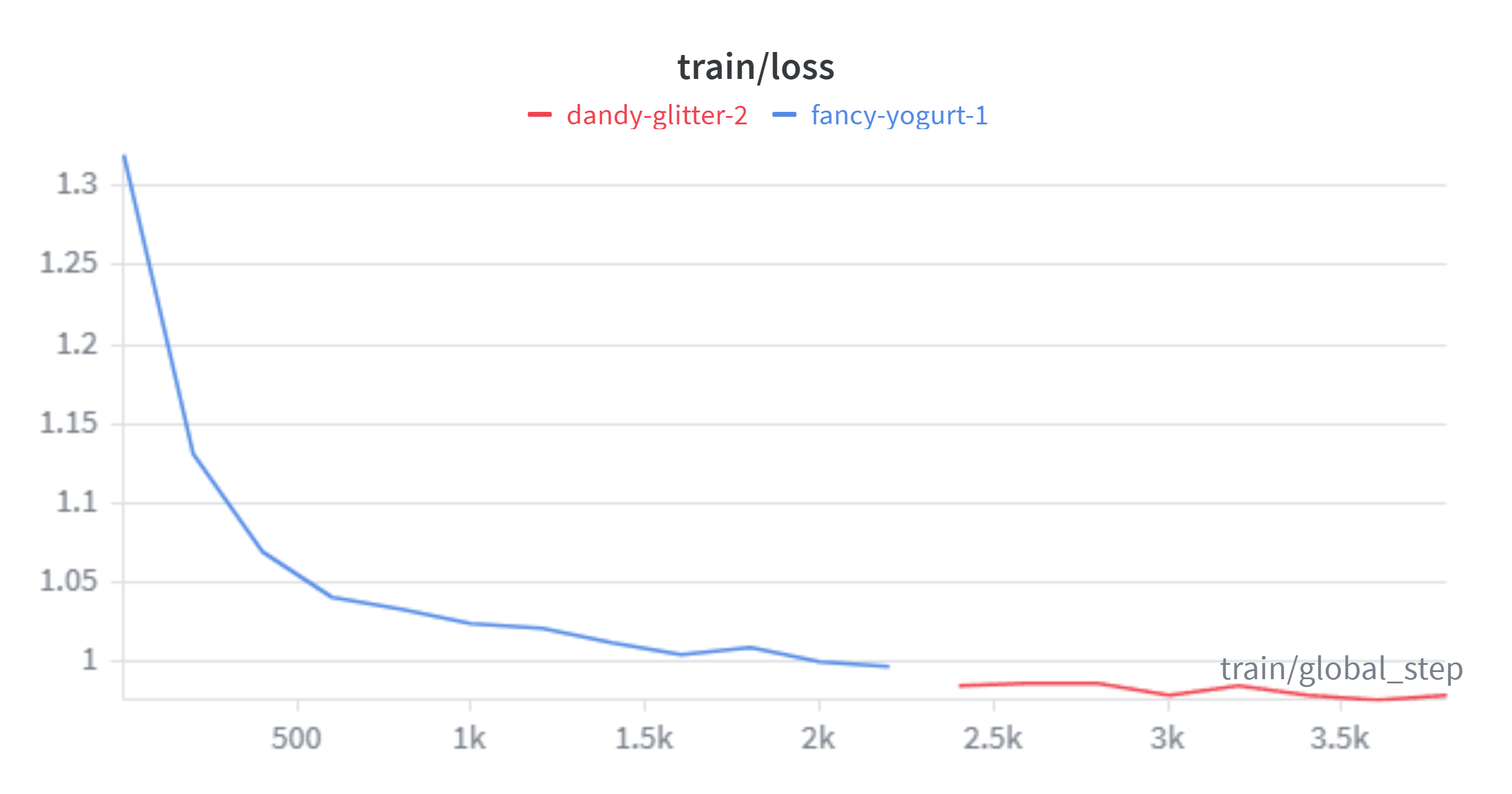
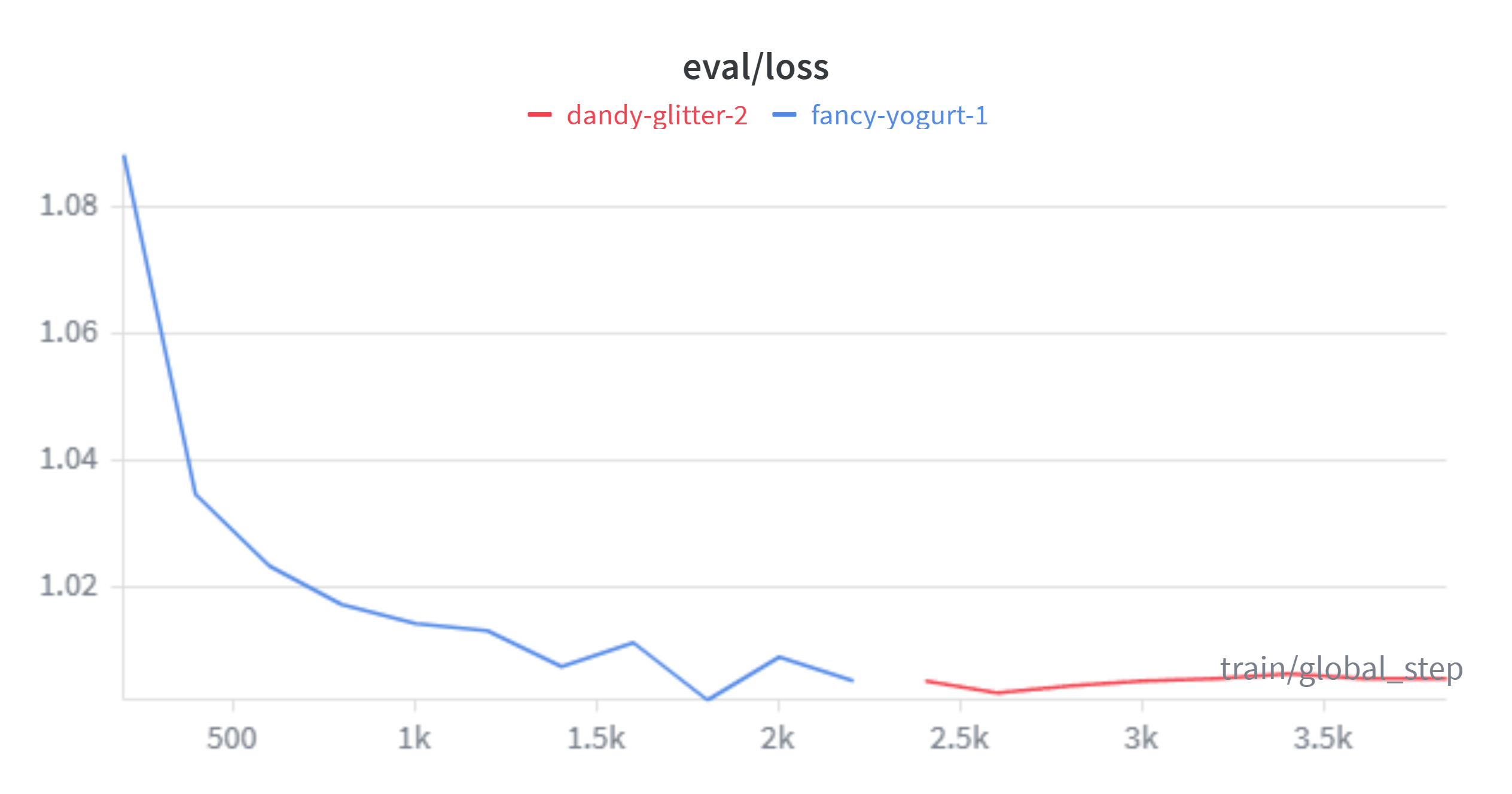
测试样例
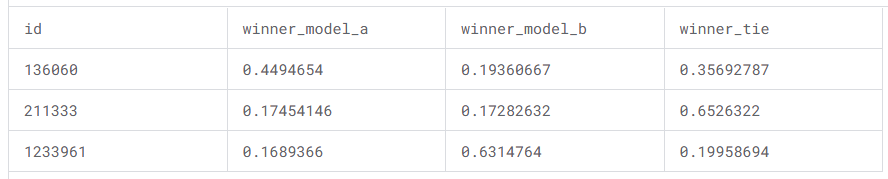
实验结果说明,模型之前对于response与标注结果之间的关系的学习仍不够充分。后续可以尝试使用更大的模型以及增加训练次数,调小学习率。
在调参的过程中,调小学习率后曾出现过过拟合的现象。在增大lora dropout(0.05 ->0.1)后情况改善。
后续可以尝试模型白盒蒸馏的方法改善模型性能

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)