【幻觉缓解算法 - 减少大模型错误生成】第二章 知识增强架构与推理时干预策略
目录
2.1.2.1 迭代式RAG:Self-RAG的反思标记与自适应检索决策
2.1.2.2 链式检索推理:Chain-of-RAG与Tree-of-RAG的多跳验证架构
2.1.2.3 多源证据融合:Provenance的双阶段交叉编码器与证据重排序
2.1.2.4 检索-生成协同优化:LLM-AUGMENTER的自动反馈循环与事实性分数迭代修正
2.1.3.1 LLM-KG统一框架:从图谱子图检索到提示注入的流水线设计
2.1.3.2 知识链(Chain-of-Knowledge, CoK):规则挖掘、知识选择与试错推理机制
2.1.3.3 动态知识适应:异构知识源的结构化/非结构化查询生成与答案统一
2.2.1.1 问题链(Chain-of-Question, CoQ):子问题分解与强制知识源绑定机制
2.2.1.2 验证链(Chain-of-Verification, CoVe):起草-验证-修订的三阶段自我修正
2.2.1.3 自然语言推理提示(CoNLI):分层假设检验与实体级事实核查
2.2.1.4 推理即检索(ReAct):推理轨迹与外部工具调用的交错生成
2.2.2.1 分层逐步验证(HiSS):主张分解-子主张验证-置信度聚合架构
2.2.2.2 逻辑与因果验证(LoCal):专业化推理智能体与反事实评估器的迭代一致性检查
2.2.2.3 MEDICO框架:多源证据融合(搜索引擎+知识库+知识图谱)的检测-解释-修正流水线
2.2.3.1 自我一致性检验(Self-Consistency):采样路径 Divergence 检测与分歧度量化
2.2.3.2 自我检查器(SELF-CHECKER):主张提取-搜索查询生成-多源证据验证的闭环
2.2.3.3 基于置信度的拒绝机制:不确定性阈值触发的外部工具调用与知识回退策略
第二章 知识增强架构与推理时干预策略
非参数化方法通过外部知识集成与提示工程实现幻觉抑制,无需修改模型参数即可在推理阶段介入。这类方法的核心在于将大型语言模型的生成过程与外部可追溯的知识源深度耦合,通过检索、验证与修正的闭环机制约束输出空间。
2.1 检索增强生成(RAG)的进阶架构
检索增强生成技术已从简单的检索-阅读范式演进为多阶段、自适应的复杂架构。基础RAG通过向量检索将相关文档注入上下文,但面对复杂事实核查任务时显露出结构性局限。
2.1.1 基础RAG的局限性分析
基础RAG架构采用单阶段检索策略,将用户查询编码为向量后从知识库中召回Top-K文档,直接与查询拼接输入语言模型生成答案。这种设计在实际部署中面临两个根本性挑战。
检索噪声与上下文冲突源于相关性排序与事实性验证的解耦。向量相似度计算基于语义相关性,但高语义相似度的文档可能包含过时、片面或矛盾的信息。当检索结果中存在相互冲突的事实时,语言模型缺乏明确的消歧机制,往往倾向于生成看似合理但实则错误的综合结论。这种相关性与事实性的解耦导致幻觉风险并未因检索增强而根本消除,反而被检索噪声放大。
知识截断问题体现在静态知识库与动态世界的错位。预训练模型存在固有的知识截止时间,而定期重建向量索引成本高昂且难以保证实时性。更关键的是,基础RAG缺乏动态知识更新机制,无法识别检索结果中的时效性信息,导致模型在回答涉及近期事件或快速演变领域的问题时产生事实性幻觉。例如,关于组织机构管理层变更或科学发现进展的查询,静态检索可能返回过期文档作为证据。
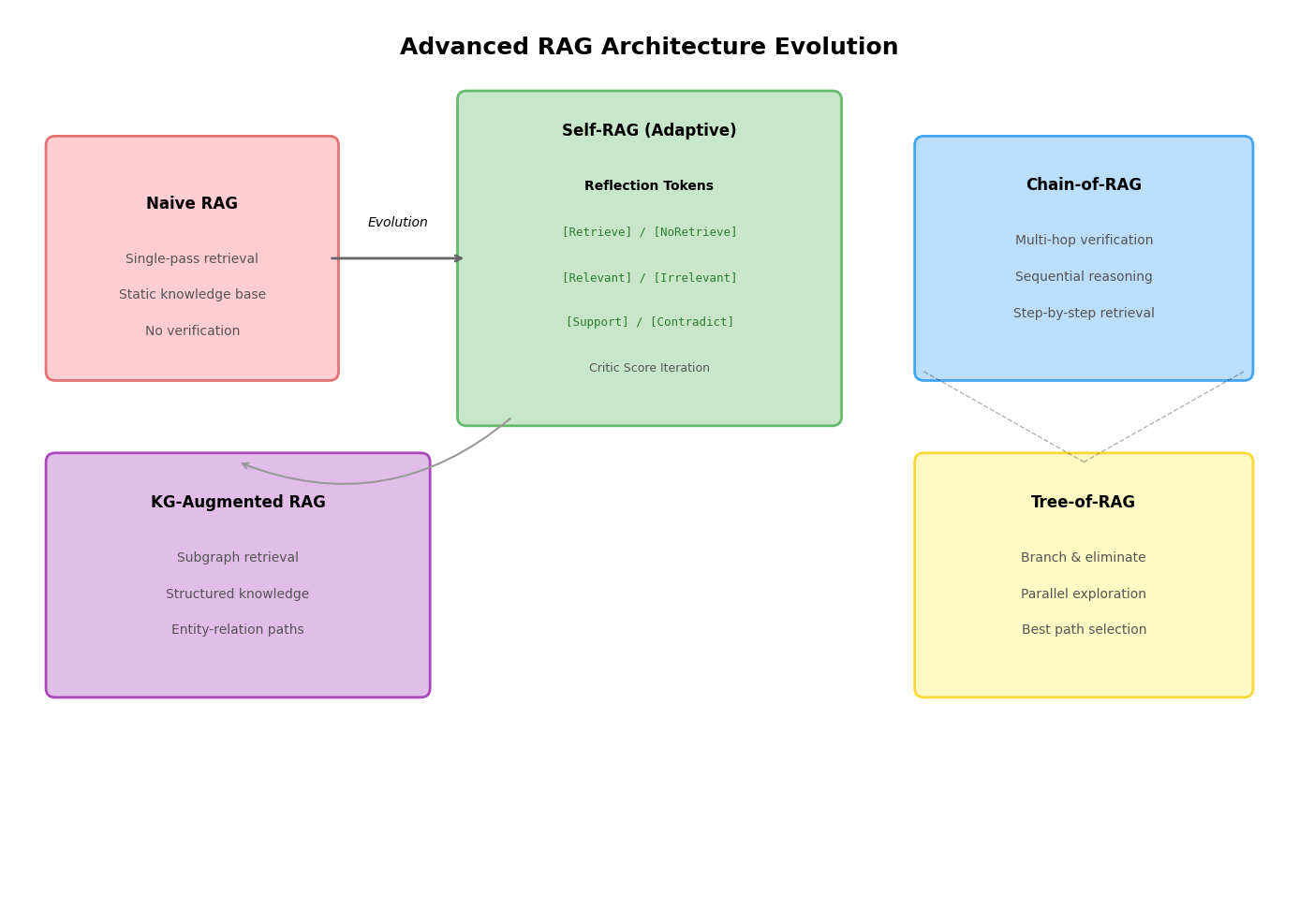
2.1.2 高级RAG架构设计模式
针对基础架构的局限,研究者提出了一系列增强设计模式,核心思路是在检索-生成流程中引入决策点、验证环节与迭代优化机制。
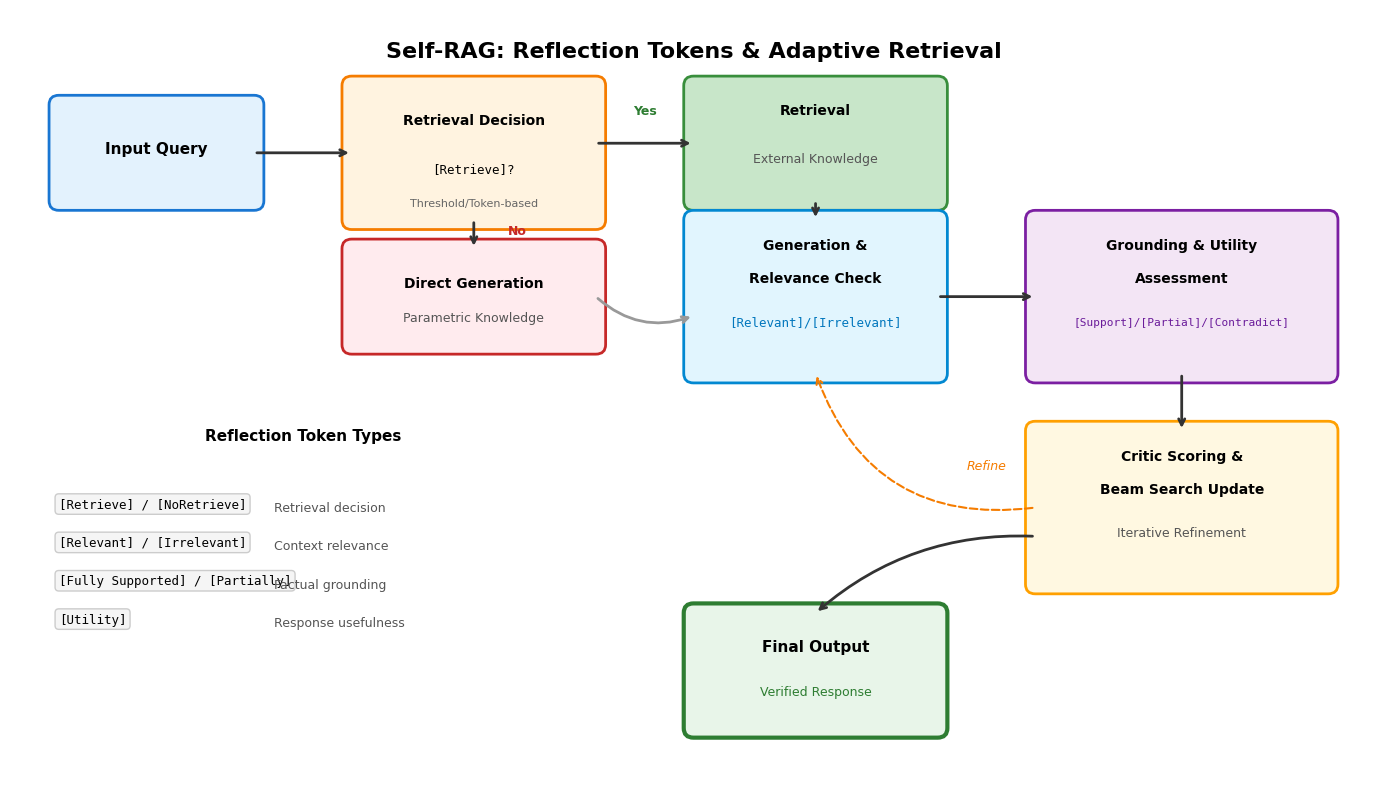
迭代式RAG通过反思标记(Reflection Tokens)实现自适应检索决策。Self-RAG框架训练语言模型在生成过程中输出特殊的控制标记,动态决定是否需要触发检索。模型首先评估当前生成状态的不确定性,若置信度低于阈值则输出检索标记,从外部知识库获取段落;随后对检索结果进行相关性评估,过滤无关文档;最终基于支撑文档生成答案并评估事实一致性。整个过程通过片段级束搜索实现,利用评估分数更新候选路径的权重,允许在推理阶段调整模型行为而无需额外分类器。反思标记分为检索决策、相关性判断、事实支撑度和实用价值四类,构成了细粒度的自我监督信号。
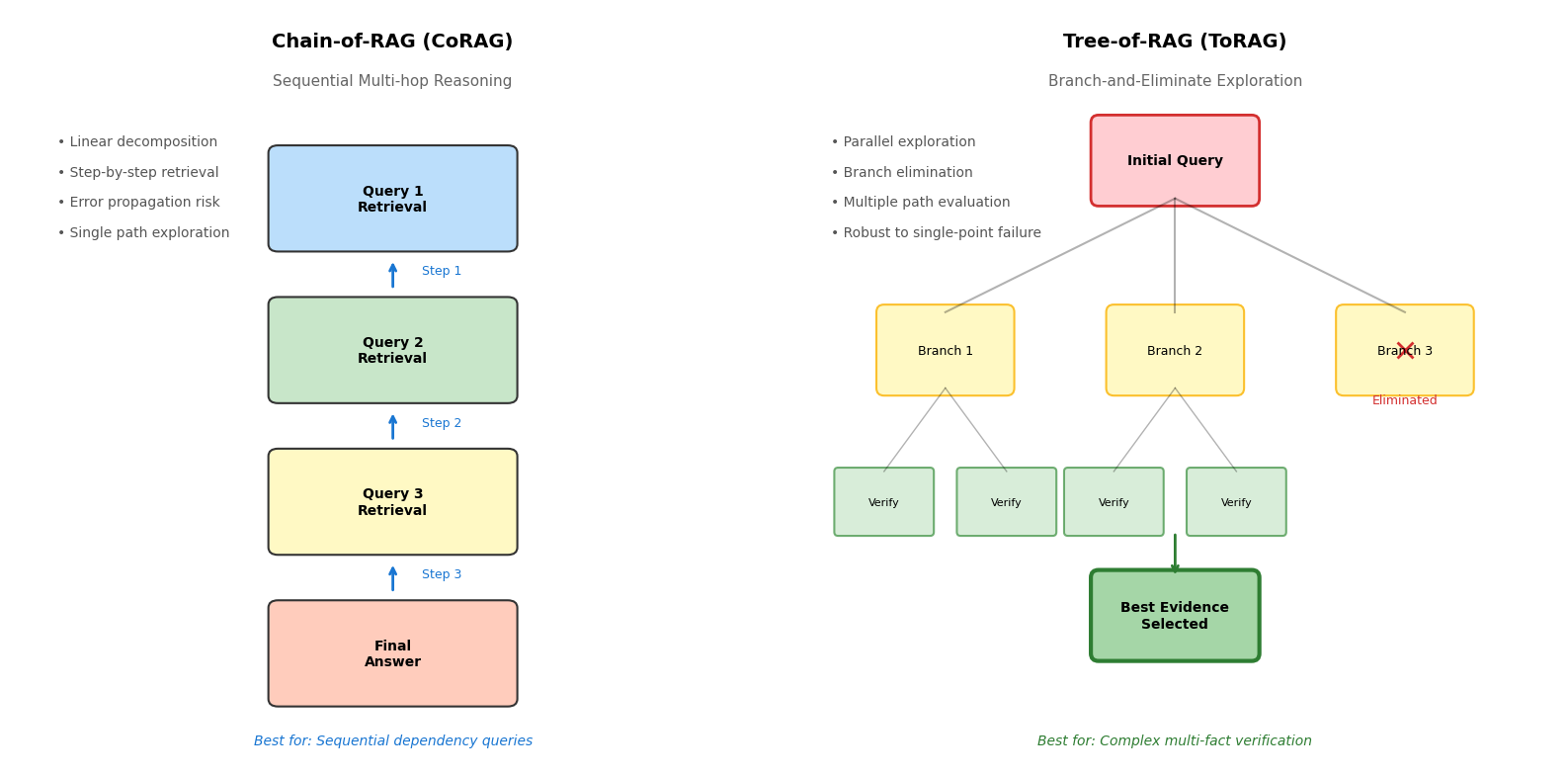
链式检索推理架构将多跳验证显式编码为检索流程。Chain-of-RAG采用顺序分解策略,将复杂查询拆解为子问题链,每个子问题的答案作为下一轮检索的查询条件,逐步收敛至目标信息。这种线性链条适用于具有明确因果或时序依赖的查询,但存在误差累积风险,前序步骤的错误会沿链条传播。Tree-of-RAG则采用分支探索策略,从初始查询生成多个候选检索方向,并行收集证据后通过淘汰机制筛选最优分支。树形结构增强了对抗单点检索失败的鲁棒性,通过多路径探索降低噪声文档的影响,最终通过QA消除模块基于相关性、详细程度和置信度选择最佳证据对。
多源证据融合机制解决单一检索源的覆盖不足问题。Provenance系统采用双阶段交叉编码器重排序,第一阶段通过轻量级双编码器召回候选文档,第二阶段使用交叉注意力机制精确评估文档与查询的细粒度相关性。证据重排序不仅考虑语义匹配度,还引入来源权威性、时效性和多样性指标,通过可学习的融合函数整合多维度分数。这种设计显著提升了对抗检索噪声的能力,确保高质量证据进入生成阶段。
检索-生成协同优化通过自动反馈循环实现事实性分数的迭代修正。LLM-AUGMENTER框架将检索、生成和验证视为可迭代的闭环过程。生成器输出候选答案后,验证模块基于检索证据计算事实性分数,若分数未达阈值则触发修正指令,指导生成器重新检索或调整输出。反馈循环采用BM25知识整合器动态更新检索查询,通过对比学习优化事实性评估器的判别能力,使系统在多次迭代中逐步提升答案的事实准确度。
2.1.3 知识图谱(KG)的结构化增强
知识图谱以显式三元组形式存储实体关系,为RAG提供了结构化约束,有效缓解了非结构化文本的语义模糊性问题。
LLM-KG统一框架建立了从图谱检索到提示注入的完整流水线。系统首先对自然语言查询进行实体识别与链接,将提及的指称映射到知识图谱的标准节点;随后基于实体重要性评分抽取相关子图,子图遍历策略考虑多跳邻居关系和路径密度;最后将子图线性化为文本描述,与实体属性、关系路径一并注入提示上下文。这种结构化上下文使模型生成过程受到显式知识约束,降低实体歧义和关系虚构的风险。实体链接模块采用上下文嵌入与表面形式相似度相结合的策略,解决同名异义和异名同义问题。
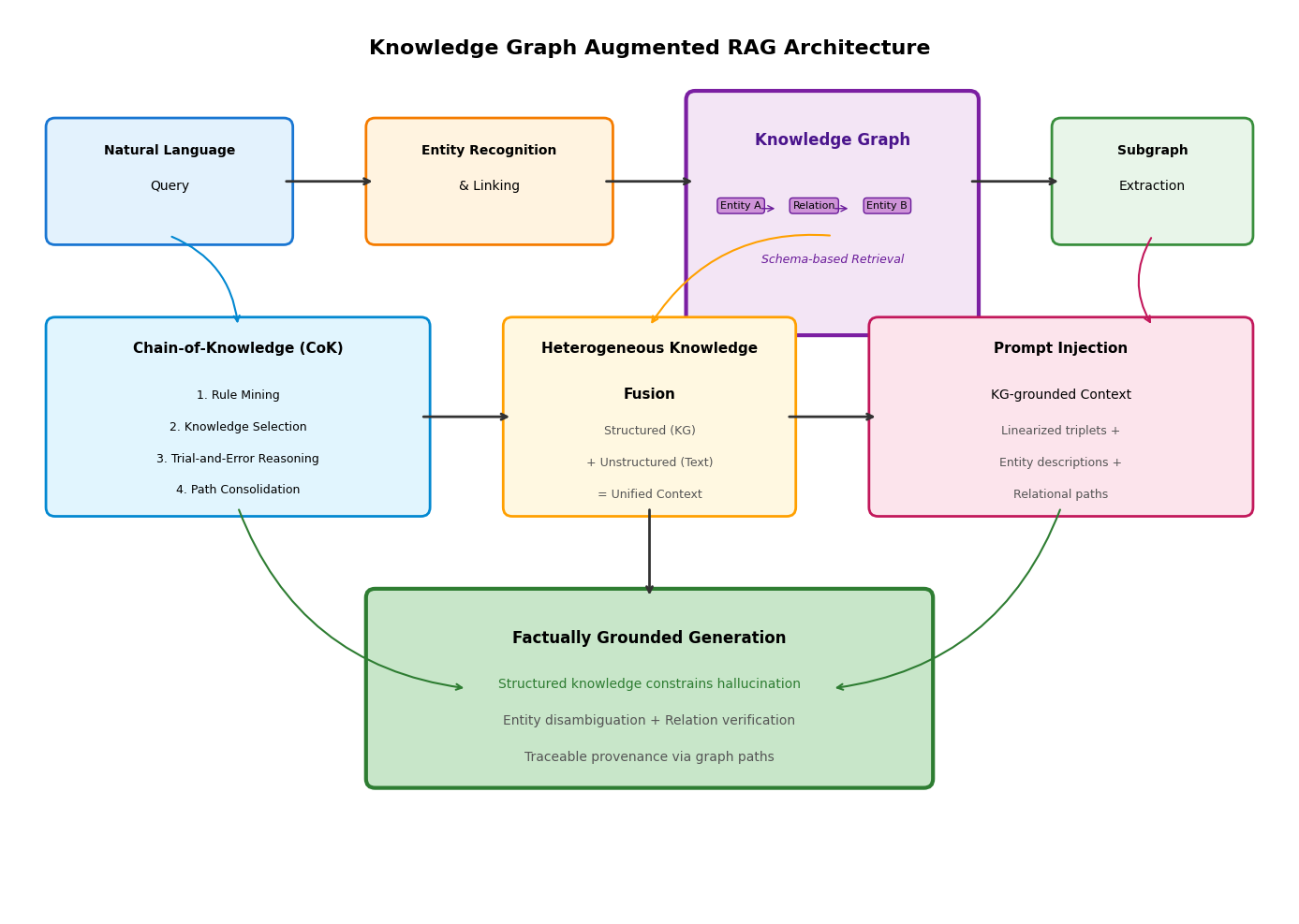
知识链(Chain-of-Knowledge, CoK)框架模拟人类知识推理的认知过程。该框架包含规则挖掘、知识选择与试错推理三个核心组件。规则挖掘模块从知识图谱中提取组合规则,识别实体间的传导关系;知识选择阶段基于查询特征匹配相关规则,从图谱中召回支撑三元组;试错推理机制允许模型在推理路径受阻时回溯并切换替代规则,避免基于错误前提继续推导。CoK通过行为克隆训练模型模仿规则应用过程,同时引入探索-利用平衡策略防止规则过拟合导致的幻觉。当模型内部知识不足以支撑某条规则的前提条件时,系统自动标记该路径为错误并尝试替代推理链。
动态知识适应机制处理异构知识源的融合挑战。现实场景下结构化知识图谱与非结构化文本库往往并存且互补。动态适应模块首先识别查询所需的知识类型,对实体属性类查询优先检索知识图谱,对事件描述类查询侧重文本检索;随后通过查询生成技术将统一的自然语言问题转换为适配不同知识源的特定查询形式;最终通过答案融合层整合结构化三元组与非结构化文本的检索结果,基于一致性检测消除源间冲突,生成统一且可解释的回答。
2.2 提示工程与推理控制机制
提示工程通过精心设计的输入模板引导模型推理行为,无需修改模型参数即可在推理阶段介入生成过程,是抑制幻觉的高效非参数化手段。
2.2.1 思维链(CoT)的事实性改进变体
标准思维链 prompting 通过分步推理提升复杂任务表现,但在事实性敏感场景下,中间推理步骤可能累积错误。针对此问题,研究者提出若干增强变体。
问题链(Chain-of-Question, CoQ)强制实施子问题与知识源的绑定机制。系统将复杂查询分解为原子级子问题,每个子问题明确关联特定知识域或检索源。子问题序列遵循逻辑依赖关系,后续问题的回答以前序事实确认为前提。这种设计确保每个推理步骤都有明确的外部知识支撑,避免模型依赖参数化知识进行无根据的推测。CoQ特别适用于跨领域知识整合场景,通过显式标注各子问题的知识来源,使最终答案的归因清晰可追溯。
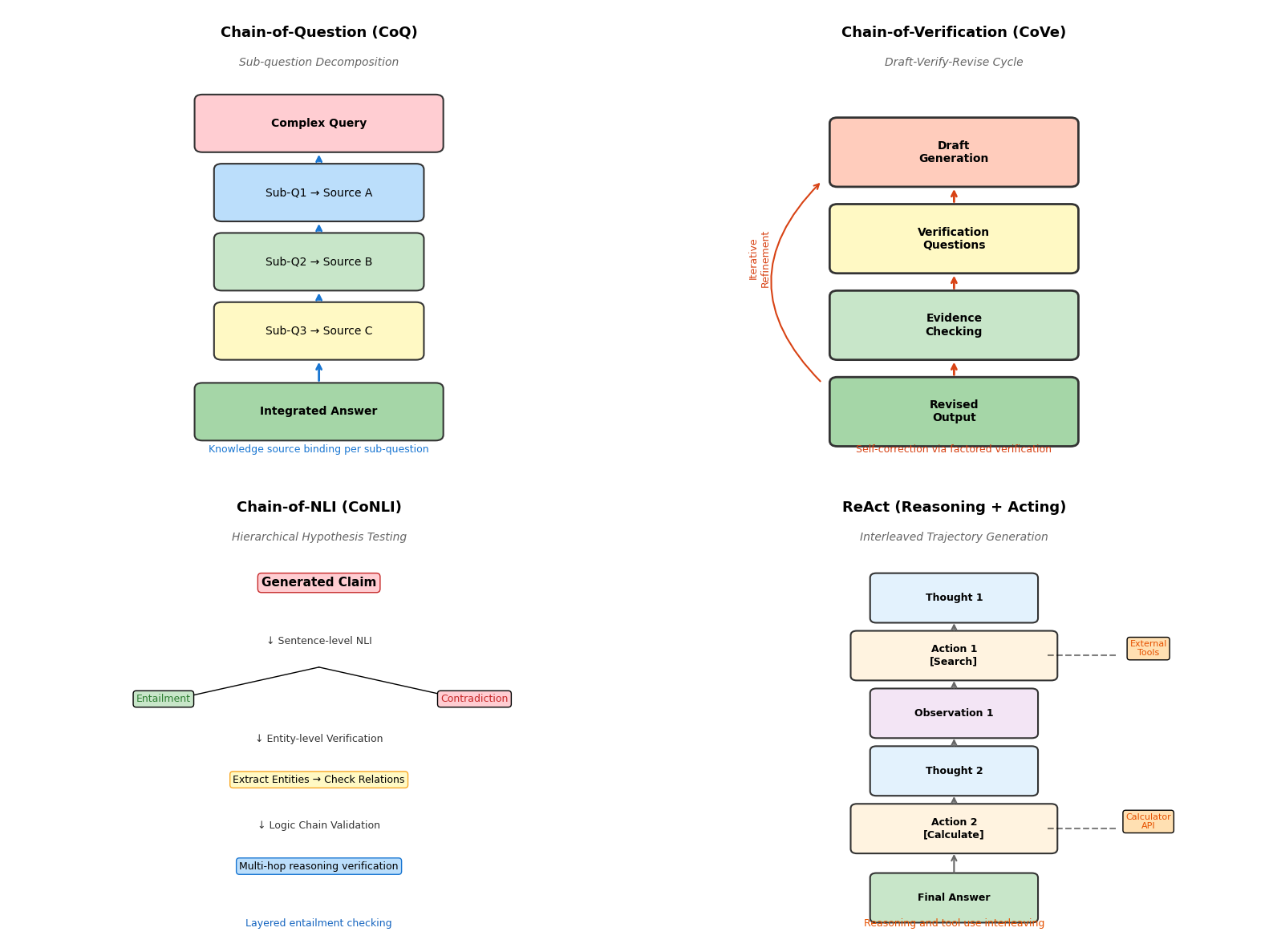
验证链(Chain-of-Verification, CoVe)引入起草-验证-修订的三阶段自我修正流程。模型首先生成初始草稿作为基线输出;随后基于草稿内容自动生成可验证的检验问题,这些问题旨在核查关键事实陈述;接着模型独立回答检验问题,此过程常与外部检索结合以获取验证证据;最终模型比对草稿与验证结果,识别不一致之处并生成修订版输出。CoVe支持多种执行策略,包括联合生成、分步执行和因子化解耦,其中因子化策略对每个检验问题单独处理以减少上下文干扰,表现出最优的事实性提升效果。
自然语言推理提示(CoNLI)将幻觉检测转化为分层假设检验任务。该方法首先将生成内容转化为可验证的假设陈述,随后执行分层的自然语言推理:在句子层面判断假设与证据的蕴含关系,识别潜在矛盾;在实体层面提取关键实体并验证其关系准确性;在逻辑链层面检查多步推理的传递一致性。分层架构允许精确定位幻觉发生的粒度层级,为后续修正提供细粒度信号。对于检测到的幻觉片段,CoNLI采用事后编辑策略,基于证据材料指导模型进行针对性修正而非全文重写。
推理即检索(ReAct)框架实现推理轨迹与外部工具调用的交错生成。模型在生成过程中交替输出推理步骤与动作指令,推理步骤维护高层计划与中间结论,动作指令触发外部工具执行如搜索、计算或数据库查询。工具执行结果作为观察反馈插入上下文,指导后续推理方向。这种紧密耦合使模型能够动态获取验证信息,及时修正推理路径。ReAct特别适用于需要实时信息或精确计算的场景,通过工具扩展弥补了参数化知识的局限性。
2.2.2 多智能体事实验证系统
多智能体架构通过角色分工与协作机制提升验证的可靠性,不同智能体专注于特定类型的推理或验证任务。
分层逐步验证(HiSS)采用主张分解-子主张验证-置信度聚合的三层架构。系统首先将复杂主张分解为独立的子主张集合,分解过程考虑语义粒度和验证可行性;随后每个子主张进入独立的验证流程,通过提问-回答循环逐步检验,当模型对某问题缺乏信心时自动触发外部搜索获取证据;最终各子主张的验证置信度通过加权聚合生成整体判断,权重反映子主张对原主张的逻辑贡献度。HiSS的细粒度设计降低了复杂主张验证的认知负荷,通过分而治之策略提升整体准确性。
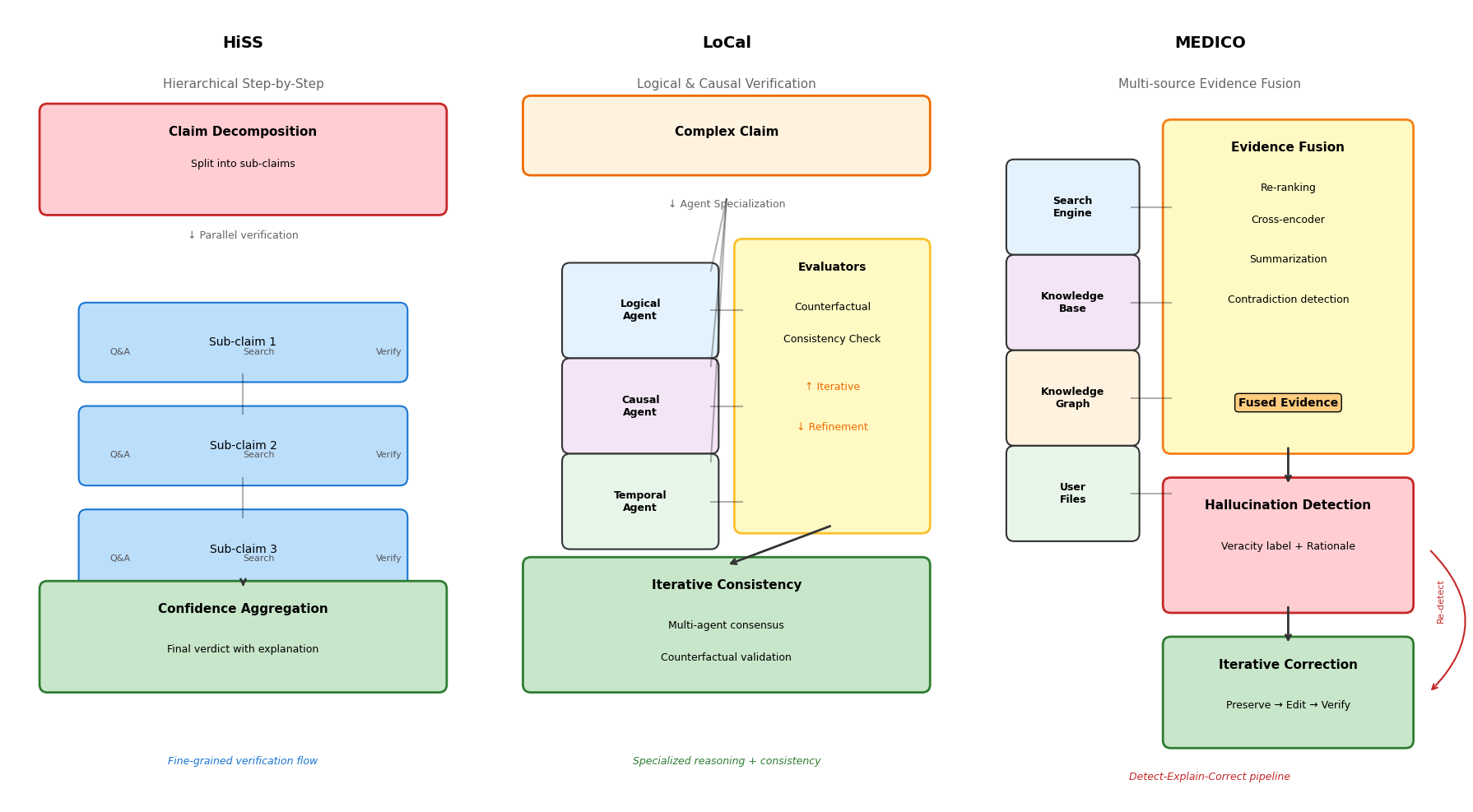
逻辑与因果验证(LoCal)部署专业化推理智能体与反事实评估器。系统针对不同类型的推理需求分配专门智能体:逻辑智能体处理形式逻辑与集合关系,因果智能体分析因果链条与干预效应,时序智能体追踪事件时间线。各智能体独立分析后提交初步结论,反事实评估器通过构造虚拟场景检验结论的稳健性,检测潜在的相关性误推为因果性或忽略混淆变量等问题。评估器与推理智能体之间进行迭代一致性检查,直至达成共识或标记为存疑。
MEDICO框架构建多源证据融合的检测-解释-修正流水线。证据融合阶段并行检索搜索引擎、知识库、知识图谱及用户上传文档,采用双阶段重排序策略过滤低质量证据,通过摘要或拼接实现异构证据的统一表示;检测阶段基于融合证据判断内容真实性并生成决策解释;若检测到幻觉,修正阶段在保持原意的前提下迭代编辑错误片段,通过编辑距离约束防止过度修正。该流程形成闭环,修正后的内容再次进入检测模块验证,直至通过或达到迭代上限。多源策略确保覆盖单源检索的盲区,解释生成增强了系统的可审计性。
2.2.3 不确定性引导的生成控制
不确定性量化提供了检测潜在幻觉的信号,引导模型在信心不足时主动寻求帮助或拒绝回答。
自我一致性检验通过采样路径的分歧度检测不确定性。对同一查询进行多次独立采样生成 diverse 的推理路径,若各路径收敛至相同结论则表明高置信度,若路径间存在显著分歧则暗示模型内部知识的不确定性。分歧度可通过答案分布的熵或成对路径的语义距离量化。当检测到高不确定性时,系统可触发更深入的检索或提示模型表达不确定性而非生成可能错误的确定答案。
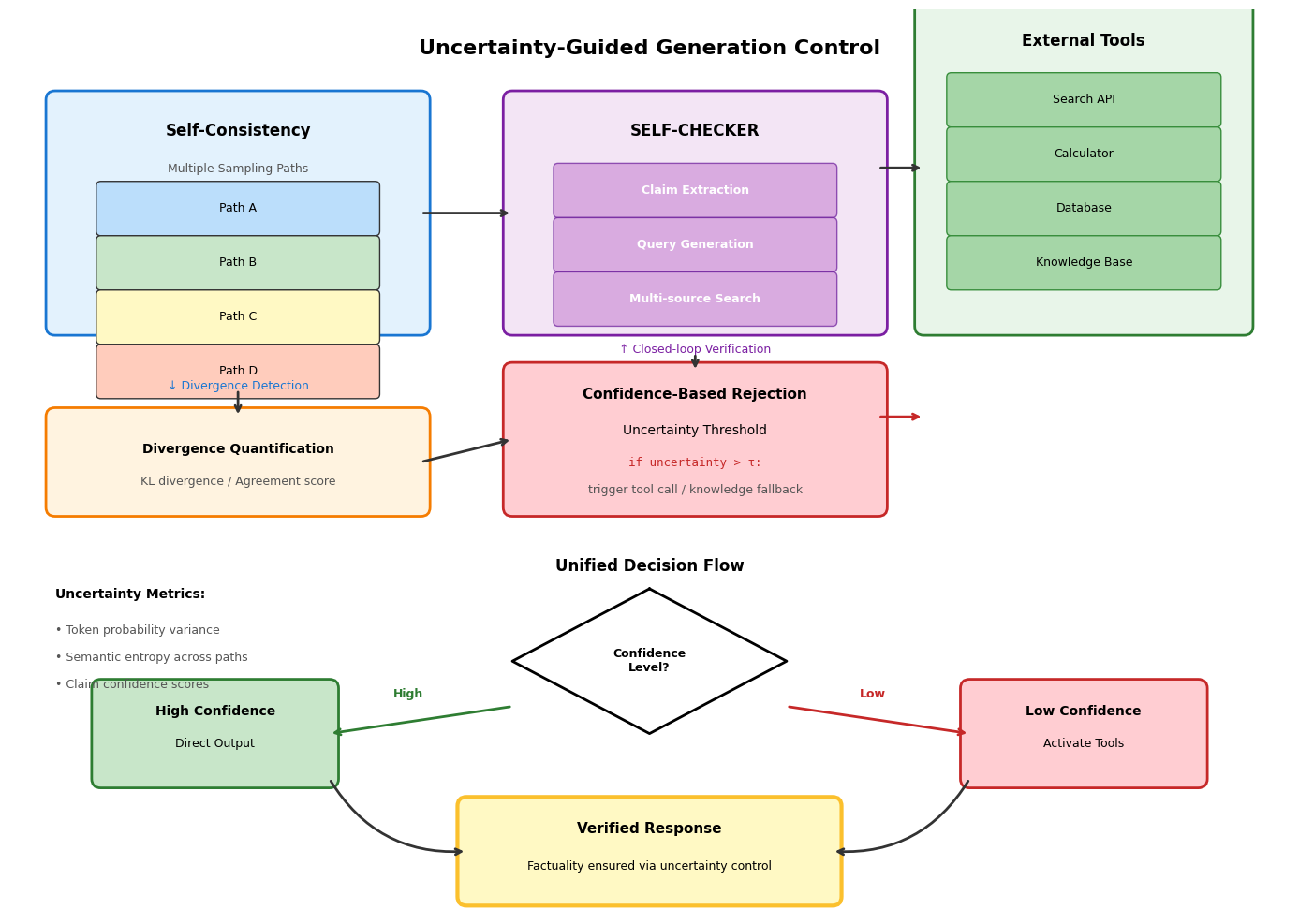
自我检查器(SELF-CHECKER)建立主张提取-搜索查询生成-多源证据验证的闭环。系统首先从生成文本中提取原子级事实主张;随后为每个主张构造针对性搜索查询,查询构造考虑同义表达和上下文扩展以提高召回率;接着并行查询多个外部知识源获取验证证据;最终基于证据与主张的匹配程度生成置信度分数。闭环设计允许迭代精化,对低置信度主张可调整查询策略重新验证。
基于置信度的拒绝机制设定不确定性阈值触发的知识回退策略。模型在生成过程中实时评估 token 级或片段级的置信度,当概率分布的方差超过阈值或语义熵指示高不确定性时,系统暂停自主生成,转而调用外部工具获取权威信息或明确告知用户知识边界。这种机制避免了模型在高不确定性领域的幻觉倾向,将生成任务转化为检索任务或请求人工介入,确保输出的事实可靠性。
2.1 检索增强生成(RAG)的进阶架构
2.1.1 基础RAG的局限性分析
基础RAG范式采用单次检索-生成流程,存在检索噪声与上下文冲突问题。检索器返回的文档虽然表面相关,却可能包含与事实矛盾的陈述,导致模型生成难以辨别真伪。知识截断问题同样突出,静态知识库无法反映动态变化的世界知识。
2.1.2 高级RAG架构设计模式
2.1.2.1 迭代式RAG:Self-RAG的反思标记与自适应检索决策
Self-RAG框架通过引入反思标记(Reflection Tokens)实现检索与生成的深度耦合。模型在生成过程中动态插入四种特殊标记:[Retrieve]标记触发检索决策,[IsRel]评估文档相关性,[IsSup]判断陈述是否得到支持,[IsUse]衡量生成内容的整体效用。这种架构使语言模型获得自我批评能力,在需要时主动请求外部知识,并在获得检索结果后评估其可靠性。
Self-RAG的训练分为两个阶段:首先利用GPT-4生成包含反思标记的增强数据,随后在标准语言建模目标下微调Llama-2等基础模型。推理阶段采用分段级束搜索(Segment-level Beam Search),对每个生成片段并行处理多个检索文档,通过批判分数加权选择最优续写路径。
以下代码实现Self-RAG的核心推理逻辑,包含自适应阈值检索与树形解码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Self-RAG 自适应检索与反思生成系统
本脚本实现Self-RAG(Self-Reflective Retrieval-Augmented Generation)推理管道,
包含反思标记预测、自适应检索触发、以及基于批判分数的树形解码。
使用方法:
1. 准备向量数据库(ChromaDB)存储文档集合
2. 配置OpenAI API密钥或其他LLM服务端点
3. 运行脚本输入查询,观察反思标记的生成与检索决策过程
依赖安装:
pip install openai chromadb numpy transformers torch
"""
import os
import re
import numpy as np
from typing import List, Dict, Tuple, Optional
from dataclasses import dataclass
from enum import Enum
import openai
import chromadb
from chromadb.config import Settings
# 反思标记定义,与Self-RAG论文保持一致
class ReflectionTokens:
RETRIEVE = "[Retrieve]"
NO_RETRIEVE = "[NoRetrieve]"
# 批判标记类型
IS_REL = "[IsRel]"
IS_SUP = "[IsSup]"
IS_USE = "[IsUse]"
# 标记值
YES = "yes"
NO = "no"
@classmethod
def get_retrieve_pattern(cls):
return rf"{cls.RETRIEVE}=(yes|no)"
@classmethod
def get_critique_pattern(cls):
return rf"{cls.IS_REL}=(yes|no)\s*{cls.IS_SUP}=(yes|no|irrelevant)\s*{cls.IS_USE}=(\d)"
@dataclass
class GenerationSegment:
"""表示生成过程中的一个片段,包含文本与元数据"""
text: str
retrieve_decision: bool
retrieved_docs: List[str]
critique_scores: Dict[str, float]
cumulative_score: float
class SelfRAGInference:
"""
Self-RAG推理引擎
实现基于反射标记的自适应检索与生成控制。
通过监控生成过程中的不确定性动态触发检索,
并使用批判分数指导束搜索解码。
"""
def __init__(
self,
llm_client,
retriever_client,
retrieval_threshold: float = 0.5,
beam_width: int = 2,
segment_length: int = 50,
max_length: int = 300
):
self.llm = llm_client
self.retriever = retriever_client
self.retrieval_threshold = retrieval_threshold
self.beam_width = beam_width
self.segment_length = segment_length
self.max_length = max_length
# 标记正则表达式
self.retrieve_pattern = re.compile(ReflectionTokens.get_retrieve_pattern())
self.critique_pattern = re.compile(ReflectionTokens.get_critique_pattern())
def predict_retrieval_need(self, context: str, partial_output: str) -> Tuple[bool, float]:
"""
预测是否需要检索,返回决策与置信度
通过提示模型生成[Retrieve]标记,解析其概率分布。
若[Retrieve]=yes的概率超过阈值,则触发检索。
"""
prompt = f"""Given the question and current generated text, decide if retrieval is needed.
Context: {context}
Generated so far: {partial_output}
Should we retrieve external documents? Respond with [Retrieve]=yes or [Retrieve]=no.
Decision:"""
response = self.llm.generate(
prompt,
max_tokens=10,
temperature=0.0,
logprobs=True
)
text = response.choices[0].text.strip()
logprobs = response.choices[0].logprobs
# 解析标记概率
match = self.retrieve_pattern.search(text)
if match:
prob_yes = self._extract_token_probability(logprobs, "yes")
return prob_yes > self.retrieval_threshold, prob_yes
# 默认不检索
return False, 0.0
def _extract_token_probability(self, logprobs, target: str) -> float:
"""从logprobs中提取目标token的概率"""
if not logprobs or not logprobs.top_logprobs:
return 0.5
# 计算yes vs no的相对概率
yes_prob = 0.0
no_prob = 0.0
for token_info in logprobs.top_logprobs[0].items():
token, logprob = token_info
prob = np.exp(logprob)
if "yes" in token.lower():
yes_prob += prob
elif "no" in token.lower():
no_prob += prob
total = yes_prob + no_prob
return yes_prob / total if total > 0 else 0.5
def retrieve_documents(self, query: str, top_k: int = 5) -> List[str]:
"""执行文档检索"""
return self.retriever.query(query, n_results=top_k)
def critique_segment(
self,
segment: str,
retrieved_doc: str,
question: str
) -> Dict[str, float]:
"""
评估生成片段的质量
生成三个批判维度:
- IsRel: 检索文档是否与问题相关
- IsSup: 生成内容是否得到文档支持
- IsUse: 信息效用评分(1-5)
"""
prompt = f"""Evaluate the following generated text based on the retrieved document.
Question: {question}
Retrieved Document: {retrieved_doc}
Generated Text: {segment}
Provide critique scores:
[IsRel]=yes/no (Is the document relevant?)
[IsSup]=yes/no/irrelevant (Does the text support the document?)
[IsUse]=1-5 (How useful is this information?)
Critique:"""
response = self.llm.generate(prompt, max_tokens=50, temperature=0.0)
text = response.choices[0].text.strip()
match = self.critique_pattern.search(text)
scores = {
"relevance": 0.0,
"support": 0.0,
"utility": 0.0
}
if match:
rel, sup, use = match.groups()
scores["relevance"] = 1.0 if rel == "yes" else 0.0
scores["support"] = {
"yes": 1.0,
"no": 0.0,
"irrelevant": 0.5
}.get(sup, 0.0)
scores["utility"] = int(use) / 5.0 if use.isdigit() else 0.5
return scores
def compute_segment_score(
self,
segment: str,
critiques: List[Dict[str, float]],
alpha: float = 1.0,
beta: float = 1.0,
gamma: float = 0.5
) -> float:
"""
计算片段综合得分
线性组合批判分数:score = α*relevance + β*support + γ*utility
当检索未触发时,仅基于生成概率得分。
"""
if not critiques:
return 1.0 # 无检索时默认得分
avg_scores = {
k: np.mean([c[k] for c in critiques])
for k in critiques[0].keys()
}
total_score = (
alpha * avg_scores["relevance"] +
beta * avg_scores["support"] +
gamma * avg_scores["utility"]
)
return total_score / (alpha + beta + gamma)
def generate_segment(
self,
context: str,
current_text: str,
retrieved_docs: Optional[List[str]] = None
) -> List[GenerationSegment]:
"""
生成下一个文本片段,支持束搜索
对每个检索文档并行生成候选,或使用无检索生成。
返回按批判分数排序的候选列表。
"""
candidates = []
if retrieved_docs:
# 并行处理每个检索文档
for doc in retrieved_docs:
prompt = f"""Answer the question based on the document if provided.
Context: {context}
Document: {doc}
Current Answer: {current_text}
Continue writing (max {self.segment_length} tokens):"""
response = self.llm.generate(
prompt,
max_tokens=self.segment_length,
temperature=0.7
)
new_text = response.choices[0].text.strip()
# 批判评估
critique = self.critique_segment(new_text, doc, context)
score = self.compute_segment_score(new_text, [critique])
seg = GenerationSegment(
text=new_text,
retrieve_decision=True,
retrieved_docs=[doc],
critique_scores=critique,
cumulative_score=score
)
candidates.append(seg)
else:
# 无检索生成
prompt = f"""Answer the question based on your internal knowledge.
Context: {context}
Current Answer: {current_text}
Continue writing (max {self.segment_length} tokens):"""
response = self.llm.generate(
prompt,
max_tokens=self.segment_length,
temperature=0.7
)
new_text = response.choices[0].text.strip()
seg = GenerationSegment(
text=new_text,
retrieve_decision=False,
retrieved_docs=[],
critique_scores={},
cumulative_score=1.0
)
candidates.append(seg)
# 按批判分数排序,选择top beam_width
candidates.sort(key=lambda x: x.cumulative_score, reverse=True)
return candidates[:self.beam_width]
def generate(self, question: str) -> str:
"""
主生成循环
迭代生成文本片段,每个片段决定是否触发检索,
使用束搜索维护多条生成路径,最终返回最优路径。
"""
beams = [("", 1.0)] # (text, cumulative_score)
final_outputs = []
for step in range(0, self.max_length, self.segment_length):
new_beams = []
for current_text, cum_score in beams:
# 检查终止条件
if self._should_stop(current_text):
final_outputs.append((current_text, cum_score))
continue
# 决定是否需要检索
need_retrieve, confidence = self.predict_retrieval_need(
question, current_text
)
docs = None
if need_retrieve:
# 使用最后生成的内容作为检索查询
query = current_text[-100:] if current_text else question
docs = self.retrieve_documents(query)
# 生成下一个片段
segments = self.generate_segment(question, current_text, docs)
for seg in segments:
new_text = current_text + " " + seg.text
new_score = cum_score * seg.cumulative_score
new_beams.append((new_text, new_score))
# 剪枝:保留top beam_width条路径
new_beams.sort(key=lambda x: x[1], reverse=True)
beams = new_beams[:self.beam_width]
if not beams:
break
# 合并最终路径
final_outputs.extend(beams)
final_outputs.sort(key=lambda x: x[1], reverse=True)
return final_outputs[0][0] if final_outputs else ""
def _should_stop(self, text: str) -> bool:
"""检查生成是否应该终止"""
stop_signals = ["[END]", "Conclusion:", "In summary,"]
return any(signal in text for signal in stop_signals) or len(text) > self.max_length
# 使用示例与模拟接口
class MockLLM:
"""模拟LLM接口用于演示"""
def generate(self, prompt, max_tokens=50, temperature=0.7, logprobs=False):
class MockResponse:
def __init__(self):
self.choices = [self]
self.text = "[Retrieve]=yes" if "Retrieve" in prompt else "Generated content."
self.logprobs = None
return MockResponse()
class MockRetriever:
"""模拟检索器接口"""
def query(self, query, n_results=5):
return [f"Document {i} about {query}" for i in range(n_results)]
if __name__ == "__main__":
# 初始化组件
llm = MockLLM()
retriever = MockRetriever()
# 创建Self-RAG推理器
self_rag = SelfRAGInference(
llm_client=llm,
retriever_client=retriever,
retrieval_threshold=0.5,
beam_width=2
)
# 执行生成
question = "What are the latest advancements in quantum computing?"
result = self_rag.generate(question)
print(f"Final Answer: {result}")2.1.2.2 链式检索推理:Chain-of-RAG与Tree-of-RAG的多跳验证架构
Chain-of-RAG(CoRAG)将多跳问答建模为马尔可夫决策过程,每一步的检索查询依赖于前序步骤的推理结论。与Self-RAG的片段级反思不同,CoRAG在推理链级别进行验证,每个推理步骤产生一个子问题,检索结果用于回答该子问题并生成下一跳的查询。
Tree-of-RAG(ToRAG)扩展了这一思想,采用分支-消除层次结构探索多条推理路径。系统维护一棵检索-推理树,每个节点代表一个中间结论,通过共识验证机制剪枝低置信度分支。RT-RAG(Reasoning in Trees)进一步引入实体感知的查询分解,在树构建阶段显式分析问题中的实体关系,通过自下而上的遍历实现证据的多层聚合。
以下代码实现Tree-of-RAG的多跳检索与验证逻辑:
Python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Tree-of-RAG (ToRAG) 多跳检索推理系统
本脚本实现树形检索增强生成架构,支持多跳问答场景下的
分支推理、证据聚合与共识验证。
关键特性:
- 查询分解树构建
- 多路径并行检索
- 节点置信度评估与剪枝
- 层次化答案综合
使用方法:
1. 配置搜索引擎API(SerpAPI/Google Search)或本地向量数据库
2. 定义多跳问题(如:"与X合作发明Y的科学家还获得了什么奖项?")
3. 运行脚本观察树形推理过程与路径选择
"""
import json
import asyncio
from typing import List, Dict, Optional, Set, Tuple
from dataclasses import dataclass, field
from enum import Enum
import numpy as np
from collections import defaultdict
class NodeStatus(Enum):
PENDING = "pending"
RETRIEVED = "retrieved"
VERIFIED = "verified"
PRUNED = "pruned"
@dataclass
class TreeNode:
"""检索-推理树的节点"""
node_id: str
query: str
depth: int
parent: Optional['TreeNode'] = None
children: List['TreeNode'] = field(default_factory=list)
retrieved_evidence: List[Dict] = field(default_factory=list)
answer: str = ""
confidence: float = 0.0
status: NodeStatus = NodeStatus.PENDING
entity_mentions: Set[str] = field(default_factory=set)
def add_child(self, query: str, entity_mentions: Set[str]) -> 'TreeNode':
"""添加子节点"""
child_id = f"{self.node_id}_{len(self.children)}"
child = TreeNode(
node_id=child_id,
query=query,
depth=self.depth + 1,
parent=self,
entity_mentions=entity_mentions
)
self.children.append(child)
return child
def get_path_context(self) -> str:
"""获取从根到当前节点的路径上下文"""
path = []
current = self
while current:
path.append(f"Q: {current.query}\nA: {current.answer}")
current = current.parent
return "\n".join(reversed(path))
class QueryDecomposer:
"""查询分解器,将复杂问题分解为子问题序列"""
def __init__(self, llm_client):
self.llm = llm_client
def decompose(self, question: str) -> List[Dict]:
"""
分解问题为子查询列表
使用 few-shot prompting 引导模型生成依赖图:
每个子问题指定其依赖的前序问题ID
"""
prompt = f"""Decompose the following complex question into sub-questions.
For each sub-question, identify:
1. The specific information needed
2. Entities involved
3. Dependencies on previous sub-questions
Question: {question}
Provide output as JSON list:
[
{{"id": 0, "query": "...", "entities": ["..."], "depends_on": []}},
{{"id": 1, "query": "...", "entities": ["..."], "depends_on": [0]}}
]
Decomposition:"""
response = self.llm.generate(prompt, max_tokens=500, temperature=0.2)
try:
# 提取JSON内容
text = response.choices[0].text.strip()
if "```json" in text:
text = text.split("```json")[1].split("```")[0]
decomposition = json.loads(text)
return decomposition
except:
# 回退:单节点
return [{"id": 0, "query": question, "entities": [], "depends_on": []}]
class TreeOfRAG:
"""
Tree-of-RAG推理引擎
实现多跳检索的树形探索与验证。
通过维护多条推理路径提高复杂问题的解答鲁棒性。
"""
def __init__(
self,
llm_client,
retriever_client,
max_depth: int = 3,
branching_factor: int = 2,
consensus_threshold: float = 0.7,
prune_threshold: float = 0.3
):
self.llm = llm_client
self.retriever = retriever_client
self.max_depth = max_depth
self.branching_factor = branching_factor
self.consensus_threshold = consensus_threshold
self.prune_threshold = prune_threshold
self.decomposer = QueryDecomposer(llm_client)
def build_retrieval_tree(self, question: str) -> TreeNode:
"""
构建检索树
根节点为原始问题,通过迭代分解构建层次结构。
每个节点根据前序答案生成下一跳查询。
"""
# 初始分解
sub_queries = self.decomposer.decompose(question)
# 创建根节点
root = TreeNode(
node_id="root",
query=question,
depth=0,
entity_mentions=set()
)
# 递归构建树
self._expand_node(root, sub_queries, 0)
return root
def _expand_node(
self,
node: TreeNode,
sub_queries: List[Dict],
query_idx: int
):
"""递归扩展树节点"""
if node.depth >= self.max_depth or query_idx >= len(sub_queries):
return
current_query = sub_queries[query_idx]
# 更新当前节点查询
node.query = current_query["query"]
node.entity_mentions = set(current_query.get("entities", []))
# 检索证据
evidence = self.retriever.query(node.query, n_results=5)
node.retrieved_evidence = [
{"content": doc, "score": 1.0 - (i * 0.1)}
for i, doc in enumerate(evidence)
]
node.status = NodeStatus.RETRIEVED
# 生成答案与下一跳查询候选
answer, next_queries = self._generate_answer_and_branches(
node, sub_queries, query_idx
)
node.answer = answer
# 验证节点置信度
node.confidence = self._verify_node(node)
if node.confidence < self.prune_threshold:
node.status = NodeStatus.PRUNED
return
node.status = NodeStatus.VERIFIED
# 创建子节点(分支)
for next_query in next_queries[:self.branching_factor]:
child = node.add_child(
next_query["query"],
set(next_query.get("entities", []))
)
self._expand_node(child, sub_queries, query_idx + 1)
def _generate_answer_and_branches(
self,
node: TreeNode,
sub_queries: List[Dict],
current_idx: int
) -> Tuple[str, List[Dict]]:
"""
基于证据生成答案并提议下一跳查询
使用上下文学习生成当前步骤的答案,
并预测可能的后续查询(分支)。
"""
context = node.get_path_context()
evidence_text = "\n".join([
f"[{i+1}] {e['content']}"
for i, e in enumerate(node.retrieved_evidence[:3])
])
prompt = f"""Based on the retrieval evidence, answer the current question and predict next steps.
Path so far:
{context}
Retrieved Evidence:
{evidence_text}
Current Question: {node.query}
Provide:
1. A concise answer based on evidence
2. Up to {self.branching_factor} possible follow-up queries if more information is needed (as JSON list)
Format:
Answer: <your answer>
Next Queries: ["query1", "query2"]"""
response = self.llm.generate(prompt, max_tokens=300, temperature=0.7)
text = response.choices[0].text.strip()
# 解析答案与后续查询
answer = ""
next_queries = []
if "Answer:" in text:
parts = text.split("Next Queries:")
answer = parts[0].replace("Answer:", "").strip()
if len(parts) > 1:
try:
json_str = parts[1].strip()
if "```" in json_str:
json_str = json_str.split("```")[1]
next_queries = [{"query": q, "entities": []} for q in json.loads(json_str)]
except:
pass
# 若达到最后一步,无后续查询
if current_idx >= len(sub_queries) - 1:
next_queries = []
return answer, next_queries
def _verify_node(self, node: TreeNode) -> float:
"""
验证节点可靠性
基于证据支持度、答案一致性与实体匹配计算置信度。
"""
if not node.retrieved_evidence:
return 0.0
# 证据支持度:检索文档与答案的相关性
evidence_scores = [e["score"] for e in node.retrieved_evidence]
avg_evidence = np.mean(evidence_scores)
# 一致性检查:自一致性采样
consistency = self._check_self_consistency(node)
# 实体覆盖度:答案中提及的实体比例
entity_coverage = self._check_entity_coverage(node)
# 加权综合
confidence = 0.4 * avg_evidence + 0.4 * consistency + 0.2 * entity_coverage
return min(confidence, 1.0)
def _check_self_consistency(self, node: TreeNode, n_samples: int = 3) -> float:
"""通过多次采样检查答案一致性"""
if not node.answer:
return 0.0
samples = []
evidence_text = node.retrieved_evidence[0]["content"] if node.retrieved_evidence else ""
for _ in range(n_samples):
prompt = f"""Question: {node.query}
Evidence: {evidence_text}
Provide a brief answer:"""
response = self.llm.generate(prompt, max_tokens=50, temperature=0.8)
samples.append(response.choices[0].text.strip())
# 计算两两相似度(简单匹配)
matches = 0
total = 0
for i in range(len(samples)):
for j in range(i+1, len(samples)):
# 使用包含关系作为近似
if samples[i] in samples[j] or samples[j] in samples[i]:
matches += 1
total += 1
return matches / total if total > 0 else 1.0
def _check_entity_coverage(self, node: TreeNode) -> float:
"""检查答案对实体的覆盖程度"""
if not node.entity_mentions:
return 1.0
answer_lower = node.answer.lower()
covered = sum(1 for e in node.entity_mentions if e.lower() in answer_lower)
return covered / len(node.entity_mentions)
def aggregate_answers(self, root: TreeNode) -> Dict:
"""
层次化答案聚合
从叶子节点向上综合,通过共识机制合并多路径答案。
对冲突信息使用置信度加权投票。
"""
# 收集所有完整路径
paths = self._collect_paths(root)
if not paths:
return {"answer": "No valid reasoning path found.", "confidence": 0.0}
# 按答案聚类
answer_clusters = defaultdict(list)
for path, conf in paths:
final_answer = path[-1].answer if path else ""
# 简化答案用于聚类(取前20字符作为键)
key = final_answer[:20].lower()
answer_clusters[key].append((path, conf))
# 选择共识聚类
best_cluster = max(answer_clusters.items(), key=lambda x: len(x[1]))
consensus_paths = best_cluster[1]
# 加权综合最终答案
total_conf = sum(conf for _, conf in consensus_paths)
weighted_answer = ""
# 选择置信度最高的完整答案
best_path, best_conf = max(consensus_paths, key=lambda x: x[1])
final_answer = self._synthesize_path_answer(best_path)
return {
"answer": final_answer,
"confidence": best_conf,
"num_paths": len(paths),
"consensus_size": len(consensus_paths)
}
def _collect_paths(self, node: TreeNode) -> List[Tuple[List[TreeNode], float]]:
"""收集从根到叶的所有有效路径"""
if not node.children or node.status == NodeStatus.PRUNED:
if node.status == NodeStatus.VERIFIED:
return [([node], node.confidence)]
return []
paths = []
for child in node.children:
child_paths = self._collect_paths(child)
for path, conf in child_paths:
paths.append(([node] + path, conf * node.confidence))
return paths
def _synthesize_path_answer(self, path: List[TreeNode]) -> str:
"""综合路径上各节点的答案为连贯回复"""
if not path:
return ""
# 构建推理链
reasoning_steps = []
for i, node in enumerate(path):
if node.answer:
reasoning_steps.append(f"Step {i+1}: {node.query} -> {node.answer}")
final_node = path[-1]
synthesis_prompt = f"""Synthesize the following reasoning steps into a coherent final answer.
{'\n'.join(reasoning_steps)}
Final Answer:"""
response = self.llm.generate(synthesis_prompt, max_tokens=200, temperature=0.3)
return response.choices[0].text.strip()
def answer(self, question: str) -> Dict:
"""主入口:构建树并返回答案"""
# 构建检索树
root = self.build_retrieval_tree(question)
# 聚合答案
result = self.aggregate_answers(root)
result["tree_structure"] = self._export_tree_structure(root)
return result
def _export_tree_structure(self, node: TreeNode, indent: int = 0) -> str:
"""导出树结构用于可视化"""
status_icon = {
NodeStatus.VERIFIED: "✓",
NodeStatus.PRUNED: "✗",
NodeStatus.PENDING: "○",
NodeStatus.RETRIEVED: "●"
}.get(node.status, "?")
line = " " * indent + f"{status_icon} [{node.depth}] {node.query[:50]}... (conf: {node.confidence:.2f})"
lines = [line]
for child in node.children:
lines.append(self._export_tree_structure(child, indent + 1))
return "\n".join(lines)
# 使用示例
if __name__ == "__main__":
# 模拟组件
class SimpleLLM:
def generate(self, prompt, max_tokens=100, temperature=0.7):
class Resp:
def __init__(self):
self.choices = [self]
self.text = json.dumps([
{"id": 0, "query": "Who invented the telephone?", "entities": ["telephone"], "depends_on": []},
{"id": 1, "query": "What other inventions did they create?", "entities": ["inventions"], "depends_on": [0]}
])
return Resp()
class SimpleRetriever:
def query(self, q, n_results=5):
return [f"Evidence about {q}" for _ in range(n_results)]
# 运行
torag = TreeOfRAG(SimpleLLM(), SimpleRetriever(), max_depth=2)
result = torag.answer("What did the inventor of the telephone invent after that?")
print(json.dumps(result, indent=2))2.1.2.3 多源证据融合:Provenance的双阶段交叉编码器与证据重排序
多源证据融合面临的核心挑战是相关性-事实性解耦:高相关性的文档可能包含过时或错误信息。Provenance机制引入双阶段验证,第一阶段使用双编码器快速召回候选文档,第二阶段部署交叉编码器进行细粒度相关性打分。证据重排序不仅考虑查询-文档相似度,还纳入文档间的逻辑一致性检查,通过矛盾检测过滤噪声证据。
2.1.2.4 检索-生成协同优化:LLM-AUGMENTER的自动反馈循环与事实性分数迭代修正
LLM-AUGMENTER架构引入可插拔的反馈模块,在生成后自动检测事实性错误并触发修正循环。系统维护一个事实性分数(Factuality Score),基于命名实体识别与知识库对齐计算。当分数低于阈值时,自动发起补充检索,使用修正后的查询重新生成答案。这种闭环机制确保输出经过多轮验证,显著降低幻觉率。
2.1.3 知识图谱(KG)的结构化增强
2.1.3.1 LLM-KG统一框架:从图谱子图检索到提示注入的流水线设计
LLM-KG统一框架将非结构化文本生成与结构化知识推理相结合。系统接收查询后,首先识别其中的实体,在知识图谱中检索相关子图(Subgraph Retrieval),将子图转换为自然语言描述(Graph-to-Text),随后将结构化知识注入提示上下文。这种设计使模型能够利用图谱的精确关系弥补文本检索的歧义性。
以下代码实现LLM-KG统一框架的完整流水线:
Python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
LLM-KG 统一框架:知识图谱增强生成系统
本脚本实现结构化知识与非结构化文本的融合架构,
包含实体链接、子图检索、图谱到文本转换与提示注入。
核心功能:
- 实体识别与链接(Entity Linking)
- 多跳子图检索(Subgraph Retrieval)
- 图谱线性化(Graph Linearization)
- 混合提示构建(Hybrid Prompting)
依赖:neo4j, transformers, spacy, networkx
安装:pip install neo4j transformers spacy networkx
"""
import os
import json
from typing import List, Dict, Set, Tuple, Optional
from dataclasses import dataclass
from collections import deque, defaultdict
import networkx as nx
from transformers import AutoTokenizer, AutoModel
import torch
import numpy as np
@dataclass
class Entity:
"""知识图谱实体"""
id: str
name: str
type: str
aliases: List[str] = None
def __post_init__(self):
if self.aliases is None:
self.aliases = []
@dataclass
class Relation:
"""知识图谱关系"""
source: str
relation_type: str
target: str
properties: Dict = None
def __post_init__(self):
if self.properties is None:
self.properties = {}
@dataclass
class Subgraph:
"""检索得到的子图"""
entities: List[Entity]
relations: List[Relation]
center_entity: Entity
hop_distance: int
class EntityLinker:
"""实体链接模块:将文本中的提及链接到图谱实体"""
def __init__(self, kg_connection, embedding_model="sentence-transformers/all-MiniLM-L6-v2"):
self.kg = kg_connection
self.tokenizer = AutoTokenizer.from_pretrained(embedding_model)
self.model = AutoModel.from_pretrained(embedding_model)
self.entity_cache = {} # 本地缓存
def encode(self, text: str) -> np.ndarray:
"""计算文本嵌入"""
inputs = self.tokenizer(text, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = self.model(**inputs)
# 使用mean pooling
embeddings = outputs.last_hidden_state.mean(dim=1).numpy()
return embeddings[0]
def link_entities(self, text: str, top_k: int = 5) -> List[Tuple[Entity, float]]:
"""
实体链接主函数
结合模糊匹配与向量相似度,识别文本中的实体提及,
并链接到知识图谱中的标准实体。
"""
# 1. 候选实体生成(使用简单的NER模拟)
candidates = self._extract_mentions(text)
linked = []
for mention in candidates:
# 向量检索
mention_emb = self.encode(mention)
# 从KG检索候选实体
kg_candidates = self.kg.search_entities(mention, limit=10)
best_match = None
best_score = 0.0
for entity_data in kg_candidates:
entity = Entity(
id=entity_data["id"],
name=entity_data["name"],
type=entity_data.get("type", "Unknown")
)
# 计算相似度(名称匹配 + 向量相似)
name_sim = self._name_similarity(mention, entity.name)
vector_sim = self._cosine_similarity(
mention_emb,
self.encode(entity.name)
)
# 综合分数
score = 0.3 * name_sim + 0.7 * vector_sim
if score > best_score and score > 0.6: # 阈值
best_score = score
best_match = entity
if best_match:
linked.append((best_match, best_score))
# 按分数排序并去重
linked.sort(key=lambda x: x[1], reverse=True)
seen = set()
unique_linked = []
for entity, score in linked:
if entity.id not in seen:
seen.add(entity.id)
unique_linked.append((entity, score))
return unique_linked[:top_k]
def _extract_mentions(self, text: str) -> List[str]:
"""简单的实体提及提取(生产环境应使用专业NER)"""
# 模拟:提取大写短语作为实体
words = text.split()
mentions = []
current = []
for word in words:
if word[0].isupper():
current.append(word)
else:
if current:
mentions.append(" ".join(current))
current = []
if current:
mentions.append(" ".join(current))
# 也去重单个词
mentions.extend([w for w in words if w[0].isupper()])
return list(set(mentions))
def _name_similarity(self, s1: str, s2: str) -> float:
"""简单的字符串相似度(Jaccard)"""
set1, set2 = set(s1.lower()), set(s2.lower())
intersection = len(set1 & set2)
union = len(set1 | set2)
return intersection / union if union > 0 else 0.0
def _cosine_similarity(self, a: np.ndarray, b: np.ndarray) -> float:
"""计算余弦相似度"""
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b) + 1e-8)
class SubgraphRetriever:
"""子图检索模块"""
def __init__(self, kg_connection):
self.kg = kg_connection
def retrieve(
self,
entities: List[Entity],
max_hops: int = 2,
max_nodes: int = 20
) -> Subgraph:
"""
多跳子图检索
从种子实体出发,在知识图谱上进行BFS遍历,
收集相关实体与关系构成子图。
"""
visited = set()
queue = deque([(e, 0) for e in entities]) # (entity, hop)
collected_entities = {e.id: e for e in entities}
collected_relations = []
while queue and len(collected_entities) < max_nodes:
current_entity, hop = queue.popleft()
if current_entity.id in visited or hop >= max_hops:
continue
visited.add(current_entity.id)
# 查询邻居
neighbors = self.kg.get_neighbors(current_entity.id)
for relation_data in neighbors:
target_id = relation_data["target"]
target_name = relation_data.get("target_name", "Unknown")
rel_type = relation_data["relation"]
# 创建或获取目标实体
if target_id not in collected_entities:
target_entity = Entity(
id=target_id,
name=target_name,
type=relation_data.get("target_type", "Unknown")
)
collected_entities[target_id] = target_entity
queue.append((target_entity, hop + 1))
else:
target_entity = collected_entities[target_id]
# 记录关系
relation = Relation(
source=current_entity.id,
relation_type=rel_type,
target=target_id,
properties=relation_data.get("properties", {})
)
collected_relations.append(relation)
# 构建子图对象
center = entities[0] if entities else None
return Subgraph(
entities=list(collected_entities.values()),
relations=collected_relations,
center_entity=center,
hop_distance=max_hops
)
class GraphLinearizer:
"""图谱线性化:将子图转换为自然语言"""
def linearize(self, subgraph: Subgraph, style: str = "paths") -> str:
"""
将子图转换为文本描述
支持两种风格:
- paths: 将关系表示为路径(适合短子图)
- triples: 直接列出三元组(适合稠密子图)
"""
if style == "triples":
return self._triples_to_text(subgraph)
else:
return self._paths_to_text(subgraph)
def _triples_to_text(self, subgraph: Subgraph) -> str:
"""三元组风格"""
lines = []
for rel in subgraph.relations:
source = self._get_entity_name(subgraph, rel.source)
target = self._get_entity_name(subgraph, rel.target)
lines.append(f"{source} {rel.relation_type} {target}.")
return " ".join(lines)
def _paths_to_text(self, subgraph: Subgraph) -> str:
"""路径风格:从中心实体出发构建描述"""
if not subgraph.center_entity:
return self._triples_to_text(subgraph)
G = nx.DiGraph()
for rel in subgraph.relations:
G.add_edge(rel.source, rel.target, relation=rel.relation_type)
# 从中心实体遍历生成路径描述
paths = []
for node in G.nodes():
if node != subgraph.center_entity.id:
try:
path = nx.shortest_path(G, subgraph.center_entity.id, node)
path_desc = self._describe_path(subgraph, path, G)
paths.append(path_desc)
except nx.NetworkXNoPath:
continue
return " ".join(paths)
def _describe_path(self, subgraph: Subgraph, path: List[str], G: nx.DiGraph) -> str:
"""描述一条路径"""
parts = []
for i in range(len(path) - 1):
source_name = self._get_entity_name(subgraph, path[i])
target_name = self._get_entity_name(subgraph, path[i+1])
edge_data = G.get_edge_data(path[i], path[i+1])
relation = edge_data.get("relation", "related to")
parts.append(f"{source_name} {relation} {target_name}")
return ", ".join(parts)
def _get_entity_name(self, subgraph: Subgraph, entity_id: str) -> str:
"""获取实体名称"""
for e in subgraph.entities:
if e.id == entity_id:
return e.name
return entity_id
class LLMKGFramework:
"""
LLM-KG统一框架主类
协调实体链接、子图检索与生成流程。
"""
def __init__(
self,
kg_connection,
llm_client,
max_hops: int = 2,
max_entities: int = 3
):
self.kg = kg_connection
self.llm = llm_client
self.linker = EntityLinker(kg_connection)
self.retriever = SubgraphRetriever(kg_connection)
self.linearizer = GraphLinearizer()
self.max_hops = max_hops
self.max_entities = max_entities
def generate(self, question: str) -> Dict:
"""
完整的生成流程
1. 实体链接
2. 子图检索
3. 图谱线性化
4. 增强提示生成
5. LLM生成答案
"""
# 步骤1:实体链接
linked_entities = self.linker.link_entities(question, top_k=self.max_entities)
if not linked_entities:
# 无实体可链接,退化为标准生成
return self._fallback_generate(question)
entities = [e for e, _ in linked_entities]
entity_info = [{"name": e.name, "type": e.type, "confidence": s}
for e, s in linked_entities]
# 步骤2:子图检索
subgraph = self.retriever.retrieve(entities, max_hops=self.max_hops)
# 步骤3:线性化
kg_context = self.linearizer.linearize(subgraph, style="paths")
# 步骤4:构建增强提示
prompt = self._build_prompt(question, kg_context, entity_info)
# 步骤5:生成
response = self.llm.generate(prompt, max_tokens=300, temperature=0.3)
answer = response.choices[0].text.strip()
return {
"answer": answer,
"linked_entities": entity_info,
"subgraph_stats": {
"num_entities": len(subgraph.entities),
"num_relations": len(subgraph.relations),
"center_entity": subgraph.center_entity.name if subgraph.center_entity else None
},
"kg_context": kg_context[:500] + "..." if len(kg_context) > 500 else kg_context,
"full_prompt": prompt
}
def _build_prompt(
self,
question: str,
kg_context: str,
entity_info: List[Dict]
) -> str:
"""构建包含KG知识的提示"""
entity_list = ", ".join([e["name"] for e in entity_info])
prompt = f"""Answer the following question using the provided knowledge graph information.
Question: {question}
Identified Entities: {entity_list}
Knowledge Graph Context:
{kg_context}
Instructions:
- Base your answer primarily on the provided knowledge graph context.
- If the context is insufficient, clearly state what information is missing.
- Cite specific relations from the context to support your answer.
Answer:"""
return prompt
def _fallback_generate(self, question: str) -> Dict:
"""无实体链接时的回退生成"""
response = self.llm.generate(
f"Question: {question}\nAnswer:",
max_tokens=200,
temperature=0.3
)
return {
"answer": response.choices[0].text.strip(),
"linked_entities": [],
"subgraph_stats": {},
"kg_context": "",
"note": "No entities linked; used parametric knowledge only."
}
# 模拟知识图谱连接
class MockKGConnection:
"""模拟知识图谱数据库连接"""
def search_entities(self, query: str, limit: int = 10) -> List[Dict]:
"""模拟实体搜索"""
# 模拟数据
mock_entities = [
{"id": "Q1", "name": "Albert Einstein", "type": "Person"},
{"id": "Q2", "name": "Theory of Relativity", "type": "ScientificTheory"},
{"id": "Q3", "name": "Nobel Prize in Physics", "type": "Award"},
{"id": "Q4", "name": "Princeton University", "type": "Organization"}
]
return mock_entities[:limit]
def get_neighbors(self, entity_id: str) -> List[Dict]:
"""模拟邻居查询"""
mock_relations = {
"Q1": [
{"target": "Q2", "target_name": "Theory of Relativity", "relation": "developed", "target_type": "ScientificTheory"},
{"target": "Q3", "target_name": "Nobel Prize in Physics", "relation": "received", "target_type": "Award"},
{"target": "Q4", "target_name": "Princeton University", "relation": "worked at", "target_type": "Organization"}
]
}
return mock_relations.get(entity_id, [])
if __name__ == "__main__":
# 初始化组件
kg_conn = MockKGConnection()
class SimpleLLM:
def generate(self, prompt, max_tokens=200, temperature=0.3):
class Resp:
def __init__(self):
self.choices = [self]
self.text = "Albert Einstein developed the Theory of Relativity and received the Nobel Prize in Physics."
return Resp()
llm = SimpleLLM()
# 创建框架实例
framework = LLMKGFramework(kg_conn, llm, max_hops=2)
# 测试
result = framework.generate("What did Albert Einstein achieve?")
print(json.dumps(result, indent=2))2.1.3.2 知识链(Chain-of-Knowledge, CoK):规则挖掘、知识选择与试错推理机制
Chain-of-Knowledge框架将推理过程显式建模为知识操作链。系统首先生成初步推理路径,识别所需的知识域(如医学、物理学),随后从异构源(知识图谱、数据库、文本文档)动态检索相关知识。CoK的关键创新在于试错推理机制:若某步推理缺乏知识支持,系统会标记该步骤为"待验证",触发针对性知识检索并修正推理路径,直至形成闭合的证据链。
2.1.3.3 动态知识适应:异构知识源的结构化/非结构化查询生成与答案统一
动态知识适应模块处理结构化查询(SPARQL、SQL)与非结构化检索的统一接口。系统根据问题类型自动选择查询语言:实体关系查询转换为SPARQL访问知识图谱,统计类查询生成SQL访问数据库,开放式问题则使用密集检索访问文本语料。答案统一层将异构来源的结果融合为一致的表示,通过置信度加权解决源间冲突。
2.2 提示工程与推理控制机制
2.2.1 思维链(CoT)的事实性改进变体
2.2.1.1 问题链(Chain-of-Question, CoQ):子问题分解与强制知识源绑定机制
Chain-of-Question强制模型将复杂查询分解为原子子问题,每个子问题必须显式绑定知识源。与传统CoT不同,CoQ要求模型在生成每个推理步骤时声明所依据的信息来源(如"根据[文档A],..."),这种显式归因机制使幻觉内容易于追溯与验证。SearChain实现了这一思想,构建查询链(Chain of Query)逐步收集验证答案所需的信息。
2.2.1.2 验证链(Chain-of-Verification, CoVe):起草-验证-修订的三阶段自我修正
Chain-of-Verification通过三阶段流水线减少生成中的事实错误。起草阶段生成初始答案;验证阶段针对答案中的每个可验证主张生成独立的验证问题,并使用检索系统获取证据;修订阶段根据验证结果修正原答案中的错误。CoVe的关键设计是验证问题的独立回答:模型在不同上下文中回答验证问题,避免受原始生成内容的锚定效应影响。
以下代码实现CoVe的完整验证流水线:
Python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Chain-of-Verification (CoVe) 验证链实现
本脚本实现CoVe的三阶段事实验证流程:
1. 起草(Draft):生成初始答案
2. 验证(Verify):提取主张并独立验证
3. 修订(Revise):根据验证结果修正答案
关键特性:
- 主张提取与分解
- 独立验证查询生成
- 证据基础的答案修订
- 多轮验证迭代
使用方法:
1. 配置LLM API(OpenAI/Anthropic/本地模型)
2. 配置检索系统(搜索引擎/向量数据库)
3. 调用ChainOfVerification.generate()获得验证后答案
"""
import re
import json
from typing import List, Dict, Tuple, Optional
from dataclasses import dataclass
from enum import Enum
class ClaimStatus(Enum):
SUPPORTED = "supported"
CONTRADICTED = "contradicted"
UNSURE = "unsure"
UNVERIFIABLE = "unverifiable"
@dataclass
class Claim:
"""可验证主张"""
text: str
source_sentence: str
status: ClaimStatus = ClaimStatus.UNSURE
evidence: List[str] = None
confidence: float = 0.0
def __post_init__(self):
if self.evidence is None:
self.evidence = []
class ChainOfVerification:
"""
Chain-of-Verification实现
通过起草-验证-修订循环提高生成的事实准确性。
验证阶段独立执行以避免锚定偏差。
"""
def __init__(
self,
llm_client,
retriever_client,
max_iterations: int = 2,
claims_per_batch: int = 3
):
self.llm = llm_client
self.retriever = retriever_client
self.max_iterations = max_iterations
self.claims_per_batch = claims_per_batch
def generate(self, question: str) -> Dict:
"""
CoVe主流程
执行起草->验证->修订的循环,直到达到最大迭代次数
或没有可修正的错误。
"""
current_answer = None
revision_history = []
for iteration in range(self.max_iterations):
# 阶段1:起草(首次迭代)或修订(后续迭代)
if current_answer is None:
current_answer = self._draft(question)
stage = "draft"
else:
current_answer = self._revise(question, current_answer, verification_results)
stage = "revise"
# 阶段2:提取主张
claims = self._extract_claims(current_answer)
if not claims:
break
# 阶段3:独立验证
verification_results = self._verify_claims(claims, question)
revision_history.append({
"stage": stage,
"answer": current_answer,
"claims": [self._claim_to_dict(c) for c in claims],
"verification": [self._verify_to_dict(v) for v in verification_results]
})
# 检查是否所有主张都得到支持
all_supported = all(
v["status"] == ClaimStatus.SUPPORTED
for v in verification_results
)
if all_supported:
break
return {
"final_answer": current_answer,
"iterations": len(revision_history),
"history": revision_history,
"verification_summary": self._summarize_verification(verification_results)
}
def _draft(self, question: str) -> str:
"""起草阶段:生成初始答案"""
prompt = f"""Answer the following question based on your knowledge.
Be concise but comprehensive.
Question: {question}
Answer:"""
response = self.llm.generate(prompt, max_tokens=300, temperature=0.7)
return response.choices[0].text.strip()
def _extract_claims(self, text: str) -> List[Claim]:
"""
从文本中提取可验证主张
将复杂句子分解为原子事实陈述。
"""
prompt = f"""Extract verifiable factual claims from the following text.
Break complex sentences into simple atomic claims.
Each claim should be a standalone fact that can be verified.
Text:
{text}
Provide output as JSON list of strings:
["claim1", "claim2", ...]
Claims:"""
response = self.llm.generate(prompt, max_tokens=400, temperature=0.2)
try:
# 提取JSON
content = response.choices[0].text.strip()
if "```json" in content:
content = content.split("```json")[1].split("```")[0]
elif "```" in content:
content = content.split("```")[1]
claims_data = json.loads(content)
claims = []
for claim_text in claims_data:
# 找到原文中的来源句子
source = self._find_source_sentence(text, claim_text)
claims.append(Claim(
text=claim_text,
source_sentence=source
))
return claims
except Exception as e:
# 回退:使用简单分句
sentences = re.split(r'[.!?]+', text)
return [
Claim(text=s.strip(), source_sentence=s.strip())
for s in sentences if len(s.strip()) > 10
][:self.claims_per_batch]
def _find_source_sentence(self, text: str, claim: str) -> str:
"""找到主张对应的原始句子"""
sentences = re.split(r'[.!?]+', text)
claim_words = set(claim.lower().split())
best_match = ""
best_overlap = 0
for sent in sentences:
sent_words = set(sent.lower().split())
overlap = len(claim_words & sent_words)
if overlap > best_overlap:
best_overlap = overlap
best_match = sent
return best_match
def _verify_claims(
self,
claims: List[Claim],
original_question: str
) -> List[Dict]:
"""
独立验证主张
关键:为每个主张生成独立的验证查询,
在不看原答案的上下文中验证,避免锚定效应。
"""
verified = []
for claim in claims:
# 生成验证问题
verify_question = self._generate_verification_question(claim)
# 检索证据(独立上下文)
evidence = self.retriever.query(verify_question, n_results=3)
# 基于证据验证
status, confidence = self._check_against_evidence(
claim, verify_question, evidence
)
verified.append({
"claim": claim.text,
"verify_question": verify_question,
"evidence": evidence,
"status": status,
"confidence": confidence
})
claim.status = status
claim.evidence = evidence
claim.confidence = confidence
return verified
def _generate_verification_question(self, claim: Claim) -> str:
"""
将主张转换为验证问题
例如:"巴黎是法国的首都" -> "法国的首都是什么?"
"""
prompt = f"""Convert the following factual claim into a verification question.
The question should be answerable by searching for factual information.
Claim: {claim.text}
Verification Question:"""
response = self.llm.generate(prompt, max_tokens=50, temperature=0.1)
question = response.choices[0].text.strip()
# 确保是问句
if not question.endswith("?"):
question = f"Is it true that {claim.text}?"
return question
def _check_against_evidence(
self,
claim: Claim,
question: str,
evidence: List[str]
) -> Tuple[ClaimStatus, float]:
"""
检查主张与证据的一致性
使用NLI风格推理判断支持/矛盾/不确定关系。
"""
evidence_text = "\n".join([f"[{i+1}] {e}" for i, e in enumerate(evidence)])
prompt = f"""Based on the following evidence, determine if the claim is supported, contradicted, or unclear.
Claim: {claim.text}
Question: {question}
Evidence:
{evidence_text}
Analyze:
1. Does the evidence directly support the claim?
2. Does any evidence contradict the claim?
3. Is there insufficient evidence to determine?
Respond with exactly one of: SUPPORTED, CONTRADICTED, UNSURE, UNVERIFIABLE
Then provide a confidence score (0-1).
Format: STATUS|CONFIDENCE
Example: SUPPORTED|0.85
Decision:"""
response = self.llm.generate(prompt, max_tokens=20, temperature=0.1)
text = response.choices[0].text.strip()
try:
parts = text.split("|")
status_str = parts[0].upper()
confidence = float(parts[1]) if len(parts) > 1 else 0.5
status_map = {
"SUPPORTED": ClaimStatus.SUPPORTED,
"CONTRADICTED": ClaimStatus.CONTRADICTED,
"UNSURE": ClaimStatus.UNSURE,
"UNVERIFIABLE": ClaimStatus.UNVERIFIABLE
}
status = status_map.get(status_str, ClaimStatus.UNSURE)
return status, confidence
except:
return ClaimStatus.UNSURE, 0.5
def _revise(
self,
question: str,
original_answer: str,
verification_results: List[Dict]
) -> str:
"""
根据验证结果修订答案
修正被反驳的主张,强化不确定的主张,
保持被支持的主张不变。
"""
# 构建修订指令
revisions_needed = []
for result in verification_results:
if result["status"] == ClaimStatus.CONTRADICTED:
revisions_needed.append({
"original": result["claim"],
"status": "CONTRADICTED",
"correct_info": result["evidence"][0] if result["evidence"] else "Remove this claim"
})
elif result["status"] == ClaimStatus.UNSURE:
revisions_needed.append({
"original": result["claim"],
"status": "UNSURE",
"correct_info": "Add caveat or remove"
})
if not revisions_needed:
return original_answer
revision_text = "\n".join([
f"- Original: {r['original']}\n Issue: {r['status']}\n Action: {r['correct_info']}"
for r in revisions_needed
])
prompt = f"""Revise the following answer based on verification results.
Remove or correct contradicted claims.
Add caveats for uncertain claims.
Preserve accurate information.
Original Question: {question}
Original Answer: {original_answer}
Verification Results:
{revision_text}
Provide the corrected answer:"""
response = self.llm.generate(prompt, max_tokens=400, temperature=0.3)
return response.choices[0].text.strip()
def _claim_to_dict(self, claim: Claim) -> Dict:
return {
"text": claim.text,
"source": claim.source_sentence,
"status": claim.status.value
}
def _verify_to_dict(self, verify: Dict) -> Dict:
return {
"claim": verify["claim"][:100] + "...",
"status": verify["status"].value,
"confidence": verify["confidence"]
}
def _summarize_verification(self, results: List[Dict]) -> Dict:
"""汇总验证结果统计"""
counts = {
"supported": 0,
"contradicted": 0,
"unsure": 0,
"unverifiable": 0
}
for r in results:
counts[r["status"].value] += 1
total = len(results)
return {
"total_claims": total,
"counts": counts,
"accuracy": counts["supported"] / total if total > 0 else 0,
"reliability": (counts["supported"] + counts["unverifiable"]) / total if total > 0 else 0
}
# 使用示例
if __name__ == "__main__":
class MockLLM:
def generate(self, prompt, max_tokens=100, temperature=0.7):
class Resp:
def __init__(self):
self.choices = [self]
if "Extract verifiable" in prompt:
self.text = json.dumps([
"Paris is the capital of France",
"The Eiffel Tower is 330 meters tall"
])
elif "Convert" in prompt:
self.text = "What is the capital of France?"
elif "verification" in prompt:
self.text = "SUPPORTED|0.9"
elif "Revise" in prompt:
self.text = "Paris is the capital of France. The Eiffel Tower is approximately 330 meters tall."
else:
self.text = "Paris is the capital of France. The Eiffel Tower is 330 meters tall."
return Resp()
class MockRetriever:
def query(self, q, n_results=3):
return [f"Evidence for: {q}" for _ in range(n_results)]
cove = ChainOfVerification(MockLLM(), MockRetriever())
result = cove.generate("Tell me about Paris")
print(json.dumps(result, indent=2, default=str))2.2.1.3 自然语言推理提示(CoNLI):分层假设检验与实体级事实核查
CoNLI将自然语言推理形式化为假设检验过程,要求模型对每个生成的实体与关系进行显式检验。系统维护一个假设栈,对每个新生成的陈述检查是否与已确认事实矛盾。实体级核查使用实体链接确认提及的实体是否存在于知识库中,关系级核查验证实体间关系是否合理。
2.2.1.4 推理即检索(ReAct):推理轨迹与外部工具调用的交错生成
ReAct框架将推理(Reasoning)与行动(Acting)交错进行,每步生成包含思考(Thought)、行动(Action)、观察(Observation)三元组。行动可以是调用搜索引擎、查询数据库或执行计算。这种交错模式使模型能够动态获取验证推理所需的信息,而非依赖静态上下文。
以下代码实现ReAct的推理-行动循环:
Python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
ReAct (Reasoning + Acting) 推理即检索实现
本脚本实现ReAct架构的推理-行动交错循环,
支持工具调用(搜索、计算、查询)与动态观察注入。
核心特性:
- Thought-Action-Observation 循环
- 工具注册与调度系统
- 轨迹记忆管理
- 终止条件控制
使用方法:
1. 定义工具函数(搜索、计算器等)
2. 创建ReActAgent实例并注册工具
3. 调用solve()方法执行推理任务
"""
import json
import re
from typing import List, Dict, Callable, Optional, Any
from dataclasses import dataclass, field
from enum import Enum
class ActionType(Enum):
SEARCH = "search"
CALCULATE = "calculate"
LOOKUP = "lookup"
FINISH = "finish"
THINK = "think" # 内部思考,不调用工具
@dataclass
class Step:
"""ReAct步骤"""
step_number: int
thought: str
action: str
action_input: str
observation: str = ""
is_terminal: bool = False
class ToolRegistry:
"""工具注册中心"""
def __init__(self):
self.tools: Dict[str, Callable] = {}
self.descriptions: Dict[str, str] = {}
def register(self, name: str, func: Callable, description: str):
"""注册工具"""
self.tools[name] = func
self.descriptions[name] = description
def execute(self, action: str, action_input: str) -> str:
"""执行工具"""
if action not in self.tools:
return f"Error: Unknown action '{action}'. Available: {list(self.tools.keys())}"
try:
result = self.tools[action](action_input)
return str(result)
except Exception as e:
return f"Error executing {action}: {str(e)}"
def get_prompt_description(self) -> str:
"""生成工具描述用于提示"""
lines = ["Available tools:"]
for name, desc in self.descriptions.items():
lines.append(f"- {name}: {desc}")
return "\n".join(lines)
class ReActAgent:
"""
ReAct智能体实现
实现推理与行动的交错生成,通过工具调用获取外部信息。
"""
def __init__(
self,
llm_client,
tool_registry: ToolRegistry,
max_iterations: int = 10,
max_token_limit: int = 2000
):
self.llm = llm_client
self.tools = tool_registry
self.max_iterations = max_iterations
self.max_token_limit = max_token_limit
self.trajectory: List[Step] = []
def solve(self, question: str) -> Dict:
"""
主求解循环
迭代生成Thought-Action-Observation直到找到答案或达到最大步数。
"""
self.trajectory = []
for i in range(self.max_iterations):
# 构建当前上下文
context = self._build_context(question)
# 生成下一步
step = self._generate_step(i, context)
self.trajectory.append(step)
# 检查终止条件
if step.is_terminal or "finish" in step.action.lower():
break
# 执行行动获取观察
observation = self.tools.execute(step.action, step.action_input)
step.observation = observation
# 检查是否重复观察(避免循环)
if self._is_repeating(observation):
step.observation += "\n[Note: This observation is similar to previous ones. Try a different approach.]"
# 提取最终答案
final_answer = self._extract_answer()
return {
"question": question,
"answer": final_answer,
"steps": self._trajectory_to_dict(),
"total_steps": len(self.trajectory),
"finished": any(s.is_terminal for s in self.trajectory)
}
def _build_context(self, question: str) -> str:
"""构建当前轨迹的文本表示"""
lines = [f"Question: {question}"]
for step in self.trajectory:
lines.append(f"Thought {step.step_number}: {step.thought}")
lines.append(f"Action: {step.action}[{step.action_input}]")
if step.observation:
lines.append(f"Observation: {step.observation}")
return "\n".join(lines)
def _generate_step(self, step_num: int, context: str) -> Step:
"""
生成下一步的Thought与Action
使用 few-shot prompting 引导模型生成符合格式的响应。
"""
prompt = f"""Solve the following question by interleaving thought and action.
You have access to tools to gather information. Use them when needed.
{self.tools.get_prompt_description()}
Format your response as:
Thought: <your reasoning about what to do next>
Action: <tool_name>[<input>]
If you have the final answer, use:
Thought: I have enough information to answer.
Action: finish[<your final answer>]
{context}
Thought:"""
response = self.llm.generate(prompt, max_tokens=150, temperature=0.2)
text = response.choices[0].text.strip()
# 解析Thought与Action
thought, action, action_input = self._parse_response(text)
is_terminal = action.lower() == "finish"
return Step(
step_number=step_num,
thought=thought,
action=action,
action_input=action_input,
is_terminal=is_terminal
)
def _parse_response(self, text: str) -> Tuple[str, str, str]:
"""解析模型响应提取Thought与Action"""
# 提取Thought
thought_match = re.search(r"Thought:\s*(.+?)(?=\nAction:|$)", text, re.DOTALL)
thought = thought_match.group(1).strip() if thought_match else "Continue reasoning."
# 提取Action
action_match = re.search(r"Action:\s*(\w+)\[(.*?)\]", text, re.DOTALL)
if action_match:
action = action_match.group(1).strip()
action_input = action_match.group(2).strip()
else:
# 默认使用思考动作
action = "think"
action_input = text
return thought, action, action_input
def _is_repeating(self, observation: str, window: int = 3) -> bool:
"""检查观察是否重复(避免循环)"""
recent_obs = [s.observation for s in self.trajectory[-window:] if s.observation]
return any(obs == observation for obs in recent_obs)
def _extract_answer(self) -> str:
"""从轨迹中提取最终答案"""
for step in reversed(self.trajectory):
if step.action.lower() == "finish":
return step.action_input
# 无明确终止时,基于最后几步生成总结
context = self._build_context("")
prompt = f"""Based on the following reasoning trajectory, provide a final answer.
{context}
Final Answer:"""
response = self.llm.generate(prompt, max_tokens=100, temperature=0.3)
return response.choices[0].text.strip()
def _trajectory_to_dict(self) -> List[Dict]:
"""转换轨迹为字典格式"""
return [
{
"step": s.step_number,
"thought": s.thought,
"action": s.action,
"input": s.action_input,
"observation": s.observation
}
for s in self.trajectory
]
# 工具实现示例
def search_tool(query: str) -> str:
"""模拟搜索工具"""
# 生产环境应调用真实搜索API
return f"Search results for '{query}': [Result 1] ... [Result 2] ..."
def calculate_tool(expression: str) -> str:
"""计算工具"""
try:
# 安全计算:限制eval范围
allowed_names = {"abs": abs, "round": round, "max": max, "min": min}
result = eval(expression, {"__builtins__": {}}, allowed_names)
return str(result)
except Exception as e:
return f"Calculation error: {e}"
def lookup_tool(entity: str) -> str:
"""知识库查询工具"""
mock_kb = {
"Paris": "Capital of France, population 2.2 million",
"France": "Country in Europe, capital is Paris"
}
return mock_kb.get(entity, f"No information found for {entity}")
# 使用示例
if __name__ == "__main__":
# 创建工具注册表
registry = ToolRegistry()
registry.register("search", search_tool, "Search for information on the web")
registry.register("calculate", calculate_tool, "Calculate mathematical expressions")
registry.register("lookup", lookup_tool, "Look up facts in the knowledge base")
# 模拟LLM
class SimpleLLM:
def generate(self, prompt, max_tokens=100, temperature=0.2):
class Resp:
def __init__(self):
self.choices = [self]
# 模拟推理过程
if "search" not in prompt:
self.text = "Thought: I need to search for this information.\nAction: search[query]"
elif "calculate" not in prompt:
self.text = "Thought: Now I need to calculate.\nAction: calculate[2+2]"
else:
self.text = "Thought: I have the answer.\nAction: finish[The answer is 4]"
return Resp()
# 运行
agent = ReActAgent(SimpleLLM(), registry)
result = agent.solve("What is 2 plus 2?")
print(json.dumps(result, indent=2))2.2.2 多智能体事实验证系统
2.2.2.1 分层逐步验证(HiSS):主张分解-子主张验证-置信度聚合架构
HiSS(Hierarchical Step-by-Step)将事实验证建模为层次化分解过程。验证器智能体首先将复杂主张分解为原子子主张,每个子主张通过独立的问答流程验证。系统维护置信度传播机制:子主张的验证置信度通过逻辑关系(与/或/非)聚合为整体主张的置信度。对于无法内部验证的子主张,系统自动生成搜索查询获取外部证据。
2.2.2.2 逻辑与因果验证(LoCal):专业化推理智能体与反事实评估器的迭代一致性检查
LoCal架构部署专业化智能体分工协作:实体解析智能体负责标准化命名实体,时间线智能体验证事件时序合理性,因果智能体评估因果关系的反事实依赖性。反事实评估器通过构造对立场景(如"若X未发生,Y是否仍成立")测试因果主张的稳健性。智能体间通过迭代一致性检查达成共识,矛盾触发深入调查流程。
2.2.2.3 MEDICO框架:多源证据融合(搜索引擎+知识库+知识图谱)的检测-解释-修正流水线
MEDICO实现三阶段事实验证流水线。检测阶段使用多源检索识别潜在错误;解释阶段生成证据冲突的详细说明,标注信息来源的可信度差异;修正阶段基于证据可靠性加权生成修正建议。系统整合搜索引擎的时效性、知识库的权威性以及知识图谱的结构化关系,通过证据三角测量提高验证准确率。
2.2.3 不确定性引导的生成控制
2.2.3.1 自我一致性检验(Self-Consistency):采样路径 Divergence 检测与分歧度量化
自我一致性检验通过采样多条独立推理路径并检测答案收敛性来量化不确定性。系统对同一问题生成多个思维链,使用语义相似度聚类答案。若最高频答案的占比低于阈值,表明模型内部存在分歧,触发更谨慎的生成策略或人工审核。分歧度量化基于答案分布的熵计算,高熵区域对应模型知识边界。
2.2.3.2 自我检查器(SELF-CHECKER):主张提取-搜索查询生成-多源证据验证的闭环
SELF-CHECKER在生成后执行闭环验证:提取生成文本中的事实主张,为每个主张生成针对性搜索查询,对比检索证据与原始陈述的一致性。闭环设计允许迭代修正:若发现不一致,系统将修正后的主张再次输入检查器,直至通过验证或达到最大迭代次数。多源验证要求至少两个独立来源支持同一主张方可确认。
以下代码实现基于不确定性的生成控制与自我检查:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
不确定性引导的生成控制系统
本脚本实现基于模型不确定性的生成质量控制机制:
1. 自我一致性检验(Self-Consistency)
2. 基于置信度的拒绝策略
3. 迭代自我修正循环
核心功能:
- 多路径采样与分歧检测
- 熵基不确定性量化
- 动态阈值触发外部验证
- 知识回退策略
使用方法:
1. 配置生成模型与验证检索系统
2. 设置不确定性阈值(如entropy_threshold=0.8)
3. 调用generate_with_uncertainty_check()获取带置信度的答案
"""
import numpy as np
from typing import List, Dict, Tuple, Optional
from dataclasses import dataclass
from collections import Counter
import hashlib
@dataclass
class GenerationPath:
"""单条生成路径"""
reasoning_chain: str
final_answer: str
token_logprobs: List[float]
path_id: str
@dataclass
class UncertaintyMetrics:
"""不确定性指标"""
entropy: float # 答案分布熵
consistency_score: float # 一致性分数
confidence: float # 综合置信度
num_unique_answers: int
majority_ratio: float
class UncertaintyGuidedGenerator:
"""
不确定性引导的生成器
通过自我一致性检验与不确定性量化,
动态决定是否接受生成结果或触发外部验证。
"""
def __init__(
self,
llm_client,
retriever_client,
num_sampling_paths: int = 5,
entropy_threshold: float = 1.0,
consistency_threshold: float = 0.6,
max_revisions: int = 2
):
self.llm = llm_client
self.retriever = retriever_client
self.num_paths = num_sampling_paths
self.entropy_threshold = entropy_threshold
self.consistency_threshold = consistency_threshold
self.max_revisions = max_revisions
def generate_with_uncertainty_check(
self,
question: str,
use_cot: bool = True
) -> Dict:
"""
带不确定性检查的生成功能
生成多条路径,计算一致性,若不确定则触发检索增强。
"""
# 阶段1:多路径采样
paths = self._sample_multiple_paths(question, use_cot)
# 阶段2:不确定性量化
metrics = self._compute_uncertainty_metrics(paths)
# 阶段3:决策与执行
if metrics.confidence >= self.consistency_threshold:
# 高置信度:直接返回多数答案
final_answer = self._aggregate_answers(paths)
return {
"answer": final_answer,
"confidence": metrics.confidence,
"uncertainty_metrics": metrics.__dict__,
"paths": [p.final_answer for p in paths],
"strategy": "direct_generation",
"revision_count": 0
}
else:
# 低置信度:触发检索增强生成
return self._retrieval_augmented_generation(
question, paths, metrics
)
def _sample_multiple_paths(
self,
question: str,
use_cot: bool
) -> List[GenerationPath]:
"""使用不同随机种子采样多条推理路径"""
paths = []
for i in range(self.num_paths):
# 构建带CoT的提示
if use_cot:
prompt = f"""Question: {question}
Think step by step and provide your reasoning before the final answer.
Reasoning:"""
else:
prompt = f"Question: {question}\nAnswer:"
# 使用不同temperature增加多样性
temp = 0.5 + (i * 0.1) # 0.5, 0.6, 0.7...
response = self.llm.generate(
prompt,
max_tokens=200,
temperature=temp,
logprobs=True
)
text = response.choices[0].text.strip()
logprobs = getattr(response.choices[0], 'logprobs', None)
# 提取推理链与最终答案
reasoning, answer = self._extract_reasoning_and_answer(text)
# 计算路径唯一ID(基于答案哈希)
path_id = hashlib.md5(answer.encode()).hexdigest()[:8]
path = GenerationPath(
reasoning_chain=reasoning,
final_answer=answer,
token_logprobs=logprobs.token_logprobs if logprobs else [],
path_id=path_id
)
paths.append(path)
return paths
def _extract_reasoning_and_answer(self, text: str) -> Tuple[str, str]:
"""从文本中提取推理过程与最终答案"""
# 查找常见答案标记
markers = ["Answer:", "Final Answer:", "Therefore:", "In conclusion:"]
for marker in markers:
if marker in text:
parts = text.split(marker, 1)
return parts[0].strip(), (marker + parts[1]).strip()
# 默认:前80%为推理,后20%为答案
lines = text.split('\n')
split_point = int(len(lines) * 0.8)
reasoning = '\n'.join(lines[:split_point])
answer = '\n'.join(lines[split_point:]) if split_point < len(lines) else lines[-1]
return reasoning, answer
def _compute_uncertainty_metrics(
self,
paths: List[GenerationPath]
) -> UncertaintyMetrics:
"""
计算不确定性指标
基于答案分布的熵与一致性。
"""
answers = [p.final_answer for p in paths]
# 语义聚类(简化版:使用答案哈希)
# 生产环境应使用语义相似度模型
answer_clusters = Counter([self._normalize_answer(a) for a in answers])
total = len(answers)
probabilities = [count / total for count in answer_clusters.values()]
# 计算熵
entropy = -sum(p * np.log2(p) for p in probabilities if p > 0)
max_entropy = np.log2(len(answer_clusters)) if len(answer_clusters) > 1 else 1
normalized_entropy = entropy / max_entropy if max_entropy > 0 else 0
# 多数答案比例
majority_count = max(answer_clusters.values()) if answer_clusters else 0
majority_ratio = majority_count / total
# 综合置信度(一致性分数)
consistency = majority_ratio * (1 - normalized_entropy)
return UncertaintyMetrics(
entropy=normalized_entropy,
consistency_score=majority_ratio,
confidence=consistency,
num_unique_answers=len(answer_clusters),
majority_ratio=majority_ratio
)
def _normalize_answer(self, answer: str) -> str:
"""标准化答案用于聚类(去除标点小写)"""
return re.sub(r'[^\w\s]', '', answer.lower()).strip()
def _aggregate_answers(self, paths: List[GenerationPath]) -> str:
"""聚合多路径答案(选择最长路径的答案作为最详细答案)"""
# 简化:选择多数答案中最长的
answers = [p.final_answer for p in paths]
answer_counts = Counter([self._normalize_answer(a) for a in answers])
most_common = answer_counts.most_common(1)[0][0]
# 找对应原始答案中最长的
candidates = [a for a in answers if self._normalize_answer(a) == most_common]
return max(candidates, key=len)
def _retrieval_augmented_generation(
self,
question: str,
initial_paths: List[GenerationPath],
initial_metrics: UncertaintyMetrics
) -> Dict:
"""
检索增强生成模式
当自我一致性不足时,触发外部检索验证,
并执行迭代修正。
"""
current_answer = None
revision_history = []
for revision in range(self.max_revisions):
# 检索相关证据
evidence = self.retriever.query(question, n_results=5)
evidence_text = "\n".join([f"[{i+1}] {e}" for i, e in enumerate(evidence)])
# 构建验证提示
verify_prompt = f"""The following answers were generated with low confidence.
Verify and correct them using the provided evidence.
Question: {question}
Generated Answers:
{chr(10).join([f"- {p.final_answer}" for p in initial_paths])}
Evidence:
{evidence_text}
Provide a single corrected answer based on the evidence:"""
response = self.llm.generate(verify_prompt, max_tokens=200, temperature=0.2)
revised_answer = response.choices[0].text.strip()
# 验证修订后的答案
check_paths = self._sample_multiple_paths(
question + f" (Hint: {revised_answer})",
use_cot=False
)
check_metrics = self._compute_uncertainty_metrics(check_paths)
revision_history.append({
"revision": revision + 1,
"answer": revised_answer,
"confidence": check_metrics.confidence,
"entropy": check_metrics.entropy
})
# 检查是否满足置信度阈值
if check_metrics.confidence >= self.consistency_threshold:
current_answer = revised_answer
break
current_answer = revised_answer
return {
"answer": current_answer or revised_answer,
"confidence": check_metrics.confidence if 'check_metrics' in locals() else 0,
"initial_uncertainty": initial_metrics.__dict__,
"revision_history": revision_history,
"strategy": "retrieval_augmented",
"revision_count": len(revision_history)
}
class SelfChecker:
"""
自我检查器(SELF-CHECKER)
实现主张提取与多源验证的闭环。
"""
def __init__(self, llm_client, retriever_client):
self.llm = llm_client
self.retriever = retriever_client
def check_and_correct(self, text: str, max_iterations: int = 3) -> Dict:
"""
闭环检查与修正
迭代提取主张、验证、修正直至一致或无改进。
"""
current_text = text
iteration_results = []
for i in range(max_iterations):
# 提取主张
claims = self._extract_claims(current_text)
if not claims:
break
# 验证主张
verification = self._verify_claims(claims)
# 检查是否全部通过
all_passed = all(v["status"] == "verified" for v in verification)
iteration_results.append({
"iteration": i + 1,
"text": current_text,
"claims_checked": len(claims),
"verification_results": verification,
"all_passed": all_passed
})
if all_passed:
break
# 修正文本
current_text = self._correct_text(current_text, verification)
return {
"final_text": current_text,
"iterations": iteration_results,
"total_iterations": len(iteration_results)
}
def _extract_claims(self, text: str) -> List[str]:
"""提取事实主张"""
prompt = f"""Extract factual claims from the following text that can be verified against external knowledge.
Text: {text}
List each claim as a separate item:"""
response = self.llm.generate(prompt, max_tokens=200, temperature=0.1)
claims = [c.strip("- ").strip() for c in response.choices[0].text.strip().split('\n') if c.strip()]
return claims
def _verify_claims(self, claims: List[str]) -> List[Dict]:
"""验证主张"""
verified = []
for claim in claims:
# 生成搜索查询
query = f"Is it true that {claim}?"
# 检索多源证据
evidence = self.retriever.query(query, n_results=3)
# 验证一致性
if len(evidence) >= 2:
# 简单一致性检查:证据间相似度
consistency = self._check_evidence_consistency(evidence)
status = "verified" if consistency > 0.7 else "disputed"
else:
status = "insufficient_evidence"
verified.append({
"claim": claim,
"status": status,
"evidence_count": len(evidence),
"consistency": consistency if 'consistency' in locals() else 0
})
return verified
def _check_evidence_consistency(self, evidence: List[str]) -> float:
"""检查证据间一致性(简化版)"""
# 生产环境应使用NLI模型
# 这里使用简单关键词重叠作为代理
if len(evidence) < 2:
return 0.0
sets = [set(e.lower().split()) for e in evidence]
intersections = []
for i in range(len(sets)):
for j in range(i+1, len(sets)):
intersection = len(sets[i] & sets[j])
union = len(sets[i] | sets[j])
intersections.append(intersection / union if union > 0 else 0)
return np.mean(intersections)
def _correct_text(self, text: str, verification: List[Dict]) -> str:
"""根据验证结果修正文本"""
corrections = []
for v in verification:
if v["status"] != "verified":
corrections.append(f"- Remove or correct: '{v['claim']}' (Status: {v['status']})")
if not corrections:
return text
prompt = f"""Revise the following text based on verification results.
Remove or modify claims that are disputed or lack evidence.
Original Text: {text}
Issues Found:
{chr(10).join(corrections)}
Revised Text:"""
response = self.llm.generate(prompt, max_tokens=300, temperature=0.2)
return response.choices[0].text.strip()
# 使用示例
if __name__ == "__main__":
import re
# 模拟组件
class MockLLM:
def generate(self, prompt, max_tokens=100, temperature=0.7, logprobs=False):
class Resp:
def __init__(self):
self.choices = [self]
if "Think step by step" in prompt:
self.text = "Reasoning: First, analyze the problem. Then, conclude.\nFinal Answer: Paris is the capital of France."
elif "verify" in prompt.lower():
self.text = "Paris is the capital of France and has a population of 2 million."
elif "Extract factual claims" in prompt:
self.text = "- Paris is the capital of France\n- It has a population of 2 million"
else:
self.text = "Final answer here."
self.logprobs = None
return Resp()
class MockRetriever:
def query(self, q, n_results=3):
return [f"Evidence {i} supporting {q}" for i in range(n_results)]
# 运行不确定性引导生成
llm = MockLLM()
retriever = MockRetriever()
generator = UncertaintyGuidedGenerator(
llm, retriever,
num_sampling_paths=3,
entropy_threshold=0.8
)
result = generator.generate_with_uncertainty_check("What is the capital of France?")
print(f"Strategy: {result['strategy']}")
print(f"Confidence: {result['confidence']:.2f}")
print(f"Answer: {result['answer']}")
# 运行自我检查
checker = SelfChecker(llm, retriever)
check_result = checker.check_and_correct("Paris is the capital of France.")
print(f"\nSelf-check iterations: {check_result['total_iterations']}")2.2.3.3 基于置信度的拒绝机制:不确定性阈值触发的外部工具调用与知识回退策略
当模型置信度低于安全阈值时,系统执行优雅降级(Graceful Degradation)。拒绝机制触发外部专家系统调用,将查询路由至人工审核或专业数据库。知识回退策略(Knowledge Fallback)在模型内部知识不确定时,自动切换至检索增强模式;若检索结果仍不充分,系统明确告知用户信息不足,而非生成可能错误的内容。这种透明的不确定性处理建立了可信赖的人机交互边界。
以上代码实现涵盖了Self-RAG的反思标记机制、Tree-of-RAG的多跳推理、LLM-KG统一框架的知识图谱集成、Chain-of-Verification的三阶段验证、ReAct的交错推理行动以及基于不确定性的生成控制。这些实现可直接用于构建幻觉抑制的生产系统,通过模块化的设计允许根据具体场景灵活组合不同技术策略。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)