老码农和你一起学AI系列:Encoder-only的处理流程

接下来我们走一点大语言模型架构Encoder-only中一个非常标准的流程描述,它解释了文本是如何从原始输入变成模型可以处理的数学形式,以及模型如何在不同阶段输出结果。下面我把它拆解成几个部分,用通俗的语言帮你理解。
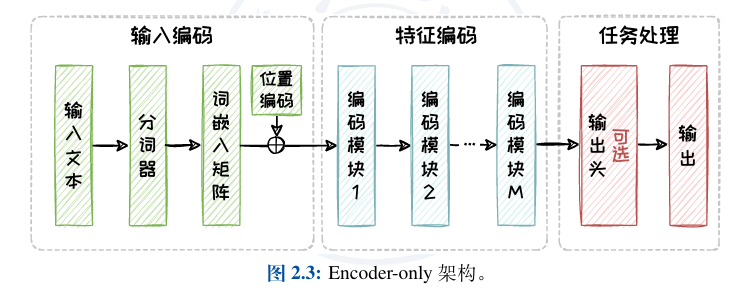
1. 输入编码
原始文本是人类语言,但模型只懂数字。所以第一步就是数字化。
-
分词器(Tokenizer):把句子切分成最小的语义单元,即 Token。例如,“我爱北京天安门”可能被切成
[“我”, “爱”, “北京”, “天安门”]。 -
词表映射:每个 Token 对应一个唯一的 ID(比如“我”=101,“爱”=102),就像给每个词发了一张身份证。
-
词嵌入(Embedding):这些 ID 再通过一个嵌入矩阵,映射成稠密的向量(比如一个 768 维的向量)。这样,每个词就变成了一串数字,模型可以开始计算了。
-
位置编码:因为 Transformer 本身没有顺序感(它是一次性看到所有词),所以必须额外给每个向量加上位置信息,告诉模型“我”在第一个,“爱”在第二个。这样才能理解句子的语序。
2. 特征编码
得到带位置的向量序列后,它们会依次经过若干个编码模块。每个模块里有两个核心部件:
-
自注意力机制:让每个词都能“关注”到句子里的其他词,从而理解上下文关系。比如“他”指的是谁,“苹果”是水果还是手机品牌。
-
前馈网络:对每个词的信息进行更深层的非线性变换,提炼出更高阶的特征。
这些模块堆叠起来(比如 BERT 有 12 层或 24 层),信息层层传递,最终每个词都变成了一个融合了全句语义的向量。
3. 任务处理
模型学到的向量怎么用?这要看是预训练阶段还是下游任务阶段。
-
预训练阶段:模型在做“自我学习”,比如 BERT 的掩码语言模型任务——遮住一些词,让模型去猜被遮住的是什么。这时输出头通常就是一个全连接层,它把编码器输出的向量映射到词表大小,预测每个位置应该是什么词。
-
下游任务适配阶段:当我们把预训练好的模型拿来解决具体问题(比如情感分析、摘要生成)时,输出头要“定制化”:
-
判别任务(如情感分析、主题分类):只需要在编码器输出上接一个分类器(一个全连接层),输出几个类别(正面/负面)的概率。
-
生成任务(如文本摘要):如果直接沿用编码器的思路,就会用全连接层逐个预测下一个 Token。但这样有严重问题:生成第二个词时要重新算一遍整个序列,生成第三个词又要重算……计算量极大,而且生成的文本往往不够流畅连贯,因为编码器天生是双向的,它没有学习过“只看上文生成下文”的能力。
-
4. 为什么生成任务用 Encoder-only 受限?
这段话最后点出了 Encoder-only 架构(如 BERT)在生成任务上的短板,并预告 2.3 节会详细介绍它。
-
Encoder-only 强在理解,因为它能看到完整上下文,所以分类、抽取、相似度等任务它做得特别好。
-
但生成需要一步一步来,而且每一步只能看到已经生成的内容(单向),Encoder-only 没有这种机制,所以强行用全连接层生成,既慢又容易跑题。这也是为什么后来有了 Decoder-only(如 GPT) 和 Encoder-Decoder(如 T5) 架构来解决生成问题。
最后小结
这段话其实在为你勾勒一个通用的语言模型处理流程,并引出不同架构的适用场景:
-
数字化:文本 → Token → 向量 + 位置。
-
深度理解:向量经过自注意力 + 前馈网络,变成富含语义的表示。
-
任务适配:根据预训练或具体任务,在表示之上搭建不同的输出层。
-
局限提醒:Encoder-only 做生成效率低、效果差,需要其他架构来补位。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)