【幻觉缓解算法 - 减少大模型错误生成】第一章 幻觉的本质、形式化定义与评估体系
目录
第一章 幻觉的本质、形式化定义与评估体系
大型语言模型的幻觉现象表征为生成内容在表面上呈现语言连贯性与语法正确性,却在事实准确性或语境忠实度层面与真实世界知识或输入上下文产生系统性偏离。这种现象并非随机噪声,而是深层架构特性、训练目标函数与推理机制交互作用的涌现结果。
1.1 幻觉问题的形式化定义与分类学
1.1.1 概念边界与形式化表示
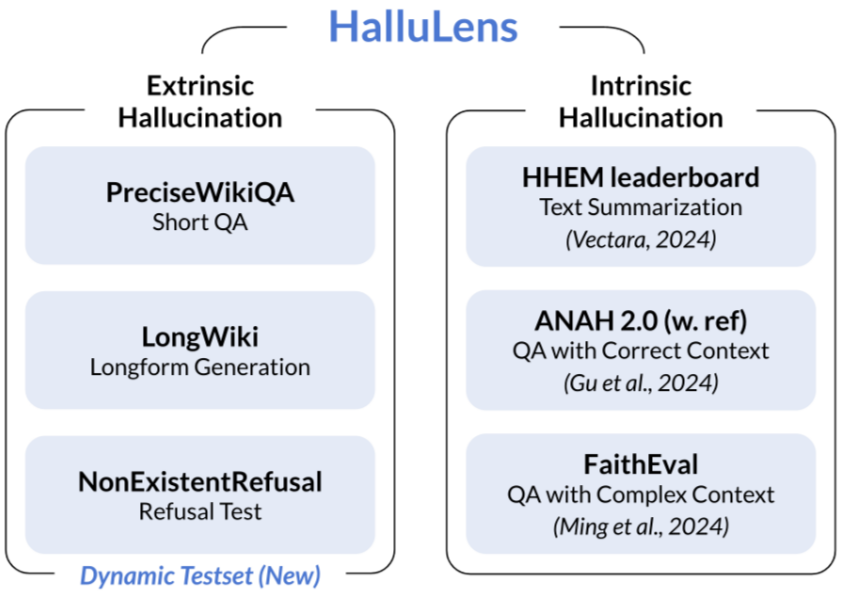
幻觉的分类体系建立在两个核心维度的正交划分之上。内在幻觉描述的是生成内容与输入上下文之间的逻辑冲突,即模型输出中包含与源文本明确矛盾的信息片段。这类幻觉在机器翻译与文本摘要等任务中表现显著,其检测依赖于源文本与生成内容之间的显式比对。外在幻觉则指向模型输出超越了输入上下文所提供的信息边界,引入无法被源材料验证的外部陈述。在开放域问答与创造性写作场景中,此类幻觉尤为常见,其判定需要依赖外部知识库或世界知识进行交叉验证。
事实性幻觉与忠实性 hallucination 构成另一组关键区分。事实性幻觉关注的是生成内容与客观世界知识之间的一致性,表现为对历史事件、科学常识或实体属性的错误陈述。忠实性幻觉则强调模型输出对用户指令意图的遵循程度以及在多轮交互中的自我一致性。前者涉及模型参数化知识的准确性边界,后者反映模型对语境约束的敏感度和逻辑推理的严密性。
幻觉风险的可量化模型将生成过程视为概率分布采样序列。在该框架下,风险度量涵盖两个层面:一是模型对其错误输出赋予的置信度与真实正确率之间的校准误差,二是在自回归生成链条中误差传播的概率累积效应。理论分析表明,当模型处于分布外区域或面对长尾知识查询时,幻觉风险呈现指数级增长趋势,其数学边界受限于训练数据的覆盖度与模型容量之间的基本张力。
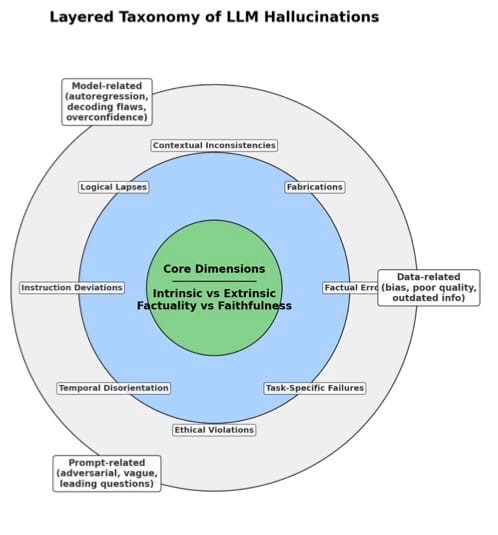
1.1.2 产生根源的多层级分析
预训练阶段的幻觉根源深植于数据分布的统计特性。网络爬取数据固有的噪声模式、事实性错误与过时信息构成了模型知识表示的基础偏差。长尾分布问题导致稀有实体与边缘事实在训练信号中被高频模式淹没,模型对低资源知识的表征呈现系统性稀疏。知识边界划定了模型能力的外延极限,参数化记忆机制在存储容量与检索精度之间存在不可调和的权衡,致使模型在面对训练语料覆盖盲区时倾向于基于高频模式进行概率插值而非不确定性表达。
架构层面的局限体现在注意力机制的设计偏置。自注意力模块在处理长距离依赖时呈现位置偏置,对文档初始段与末尾段的信息赋予非对称权重,导致关键约束条件的表征稀释。固定长度的上下文窗口构成了信息处理的硬边界,超出该范围的语境线索被截断处理,破坏了事实核查所需的完整证据链。位置编码的周期性特征在特定相位点引入系统性不确定性波动,这种与语义内容无关的方差调制增加了幻觉发生的结构性风险。
对齐阶段的优化冲突集中体现为真实性遵循与指令跟随之间的帕累托前沿张力。基于人类反馈的强化学习优化目标往往偏好有用性、参与度与对话流畅性,这些指标在统计意义上与事实准确性存在弱相关性甚至负相关。当用户指令暗示错误前提或要求创造性虚构时,模型在拒绝回答与满足需求之间面临价值对齐困境,这种优化权衡在推理阶段表现为对提示词风格的过度敏感。
推理阶段的暴露偏置源于训练与生成阶段的条件分布差异。教师强制训练机制使模型仅接触真实历史序列的条件分布,而自回归生成必须依赖模型自身的先前输出作为后续预测的上下文。这种分布偏移在迭代过程中产生误差累积效应,早期生成的微小事实偏差在后续 token 生成中被条件化放大。采样策略中的温度参数与核采样机制在提升输出多样性的同时,也增加了低概率幻觉路径的探索几率。
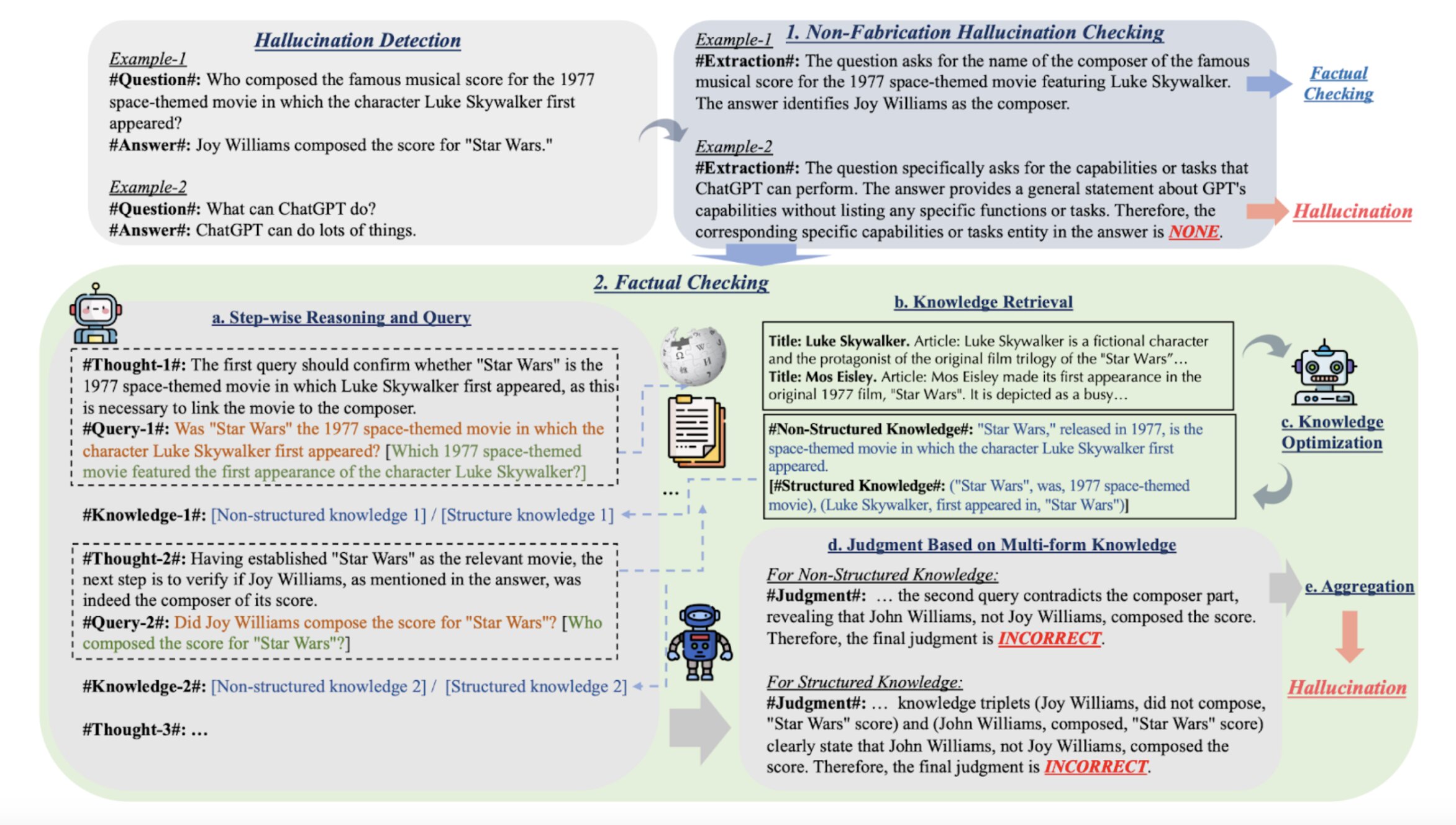
1.2 幻觉检测的评估框架与基准测试
1.2.1 自动化评估指标的分类体系
基于自然语言推理的忠实度评估通过判别生成陈述与源材料之间的蕴涵关系来量化幻觉程度。 entailment 关系判定将文本对映射为支持、矛盾或中立三类逻辑关系,事实一致性分数则通过聚合原子陈述的验证结果计算宏观准确率。这类指标的优势在于无需人工标注即可实现大规模评估,但其性能受限于推理模型的自身幻觉倾向与对细微语义差别的敏感度。
检索增强的评估范式通过外部知识库验证生成内容的事实基础。RAGAS 框架将评估解构为上下文精确率、上下文召回率、忠实度与答案相关性四个维度,形成对检索-生成链条的全链路质量监控。LEAF Score 引入多文档证据的加权聚合机制,依据检索片段的相关性排序计算知识来源的分散度与一致性。Knowledge F1 则衡量生成实体与关系三元组在外部知识图谱中的覆盖率与准确率,特别适用于结构化知识密集型任务的评估。
不确定性量化指标试图通过模型的内部状态预测幻觉发生概率。基于困惑度的校准方法分析模型输出概率分布的集中程度与锐度,低困惑度与事实错误并存的案例被标记为过度自信幻觉。语义熵通过测量模型在多样化采样路径下输出语义内容的离散程度来捕捉认知不确定性,高语义熵通常对应模型处于知识边界或面对模糊查询的状态。 token 级概率衰减模式分析可识别幻觉发生的临界区域,在生成序列中出现概率断崖式下降的片段往往预示事实性偏离。
细粒度原子评估将复杂生成内容解构为最小可验证单元。FActScore 将长文本分割为独立原子事实,通过逐一验证每个单元的准确性计算精细化的幻觉比例。SAFE 采用多步验证机制,首先提取待验证主张,随后生成针对性检索查询,最后基于检索结果进行逻辑判断,这种流水线设计降低了复杂陈述验证中的复合错误风险。原子化评估提供了比整体文本评分更精确的诊断信息,有助于定位特定知识域的脆弱性。
1.2.2 领域特定基准测试集
通用事实性评估侧重于开放域知识问答的正确性。TruthfulQA 采用对抗性设计构造 questions,这些问题针对人类常见的误解模式与错误观念,测试模型是否能抵抗模仿训练数据中虚假相关性的诱惑。HaluEval 提供大规模生成与人工标注的幻觉样本,涵盖问答、知识增强对话与文本摘要任务,其细粒度标注区分了事实性错误、上下文不一致与逻辑谬误等多种失效模式。FACTOR 框架通过将事实语料库自动转换为忠实度评估基准,实现了从维基百科与新闻文档到测试实例的可扩展映射。
长文本忠实性评估关注摘要生成与文档问答中的信息保持。SummEval 提供多文档摘要的人工评估数据,涵盖一致性、相关性与流畅性维度,特别针对长输入中的细节保留能力进行压力测试。QAGS 采用问答作为摘要忠实性的代理任务,通过检验基于摘要生成的答案与基于原文生成的答案之间的一致性来间接测量信息失真。FactCC 引入基于编辑的幻觉检测,通过比对原文与摘要之间的语义差异识别引入的虚构信息。
多模态事实性评估跨越文本与视觉模态的交叉验证。Mocheg 针对图文匹配任务设计,测试模型在生成图像描述或回答视觉问题时是否产生与视觉内容不符的文本陈述。VisualFactChecker 构建跨模态证据检索系统,要求模型不仅生成文本回答,还需提供支持其陈述的图像区域证据,这种可追溯性要求显著提高了幻觉的检测精度与可解释性。
专业领域基准强调高风险场景下的精确性要求。PubMedQA 聚焦生物医学文献的问答,测试模型对临床研究发现、药物相互作用与疾病机制的理解准确性,其问题设计涉及需要精确理解实验方法与统计结果的复杂推理。法律领域基准评估模型对判例引用、法规条款与程序性知识的掌握,特别关注模型在处理法律解释歧义与 jurisdiction 特异性规则时的边界意识。低资源语言场景测试模型在语料稀缺的非英语语种中的事实准确性,揭示跨语言知识迁移中的幻觉放大效应。
上述评估体系构成了从理论定义到实践检测的完整技术链条,为后续章节的缓解策略与对齐方法奠定了方法论基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)