餐具种类识别系统
餐具种类识别系统
目录
项目概述
本项目是一个基于 YOLOv8 深度学习模型的餐具种类识别系统,能够自动识别和分类餐桌/厨房环境中的常见餐具。系统采用端到端的深度学习方案,从数据准备、模型训练、性能评估到 Web 应用部署,实现了完整的识别流程。
项目特点
- 高精度识别:基于 YOLOv8 目标检测算法,实现多类别餐具的准确识别
- 实时检测:支持单张图片上传和实时推理
- 历史记录:自动保存检测历史到 SQLite 数据库
- 可视化分析:提供训练曲线、混淆矩阵、性能指标等可视化分析
- 用户友好:基于 Streamlit 的现代化 Web 界面
数据集介绍
数据集概况
本项目使用的数据集包含 7 类常见餐具,采用 YOLO 格式标注:
- 训练集:303 张图像
- 验证集:76 张图像
- 总图像数:379 张
- 类别数:7 类
类别列表
| 类别ID | 类别名称 | 中文名称 |
|---|---|---|
| 0 | fork | 叉子 |
| 1 | butter knife | 黄油刀 |
| 2 | kitchen knife | 厨房刀 |
| 3 | peeler | 削皮器 |
| 4 | spoon | 勺子 |
| 5 | tongs | 夹子 |
| 6 | wooden spoon | 木勺 |
数据集结构
数据集采用标准的 YOLO 格式组织:
Dataset/
├── train/
│ ├── images/ # 训练图像(303张)
│ ├── labels/ # 训练标签(303个.txt文件)
│ └── classes.txt # 类别定义文件
└── val/
├── images/ # 验证图像(76张)
├── labels/ # 验证标签(76个.txt文件)
└── classes.txt # 类别定义文件
标注格式
YOLO 格式的标注文件(.txt)每行表示一个目标对象,格式为:
class_id x_center y_center width height
其中:
class_id:类别ID(0-6)x_center, y_center:边界框中心点坐标(归一化到 0-1)width, height:边界框宽度和高度(归一化到 0-1)
示例标注:
0 0.540771 0.491862 0.522949 0.266276
这表示图像中有一个类别为 0(fork)的目标,其边界框中心位于 (0.540771, 0.491862),宽度为 0.522949,高度为 0.266276。
数据集可视化

图 1:训练批次样本图 - 展示了训练过程中的一个批次样本,包含原始图像和对应的标注框。图中可以看到不同类别的餐具(叉子、勺子、刀具等)及其边界框标注,用于模型学习目标的位置和类别信息。
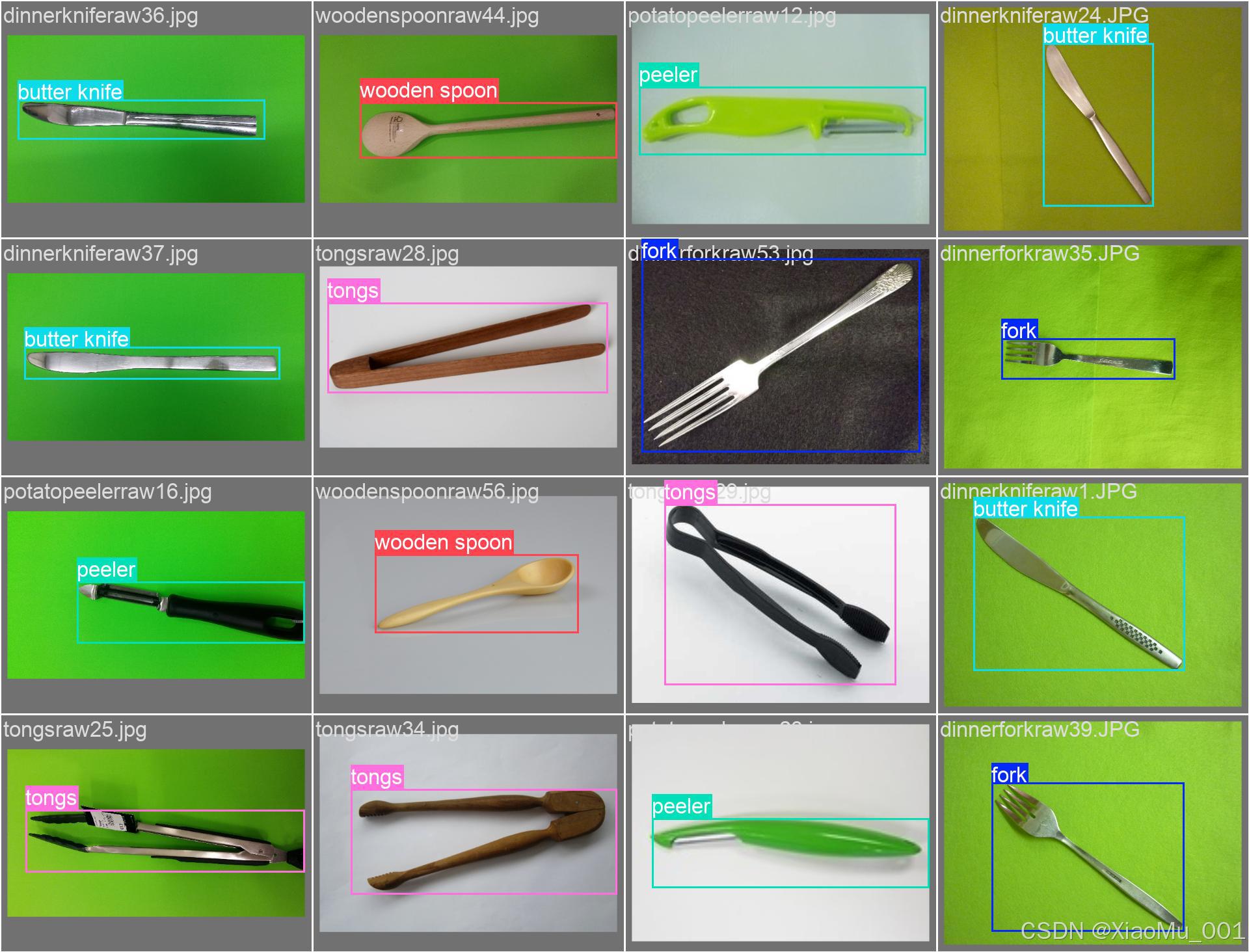
图 2:验证批次标签图 - 展示了验证集上的真实标签标注,用于评估模型性能。图中显示了验证集中各类餐具的标注情况,帮助理解数据集的分布和质量。
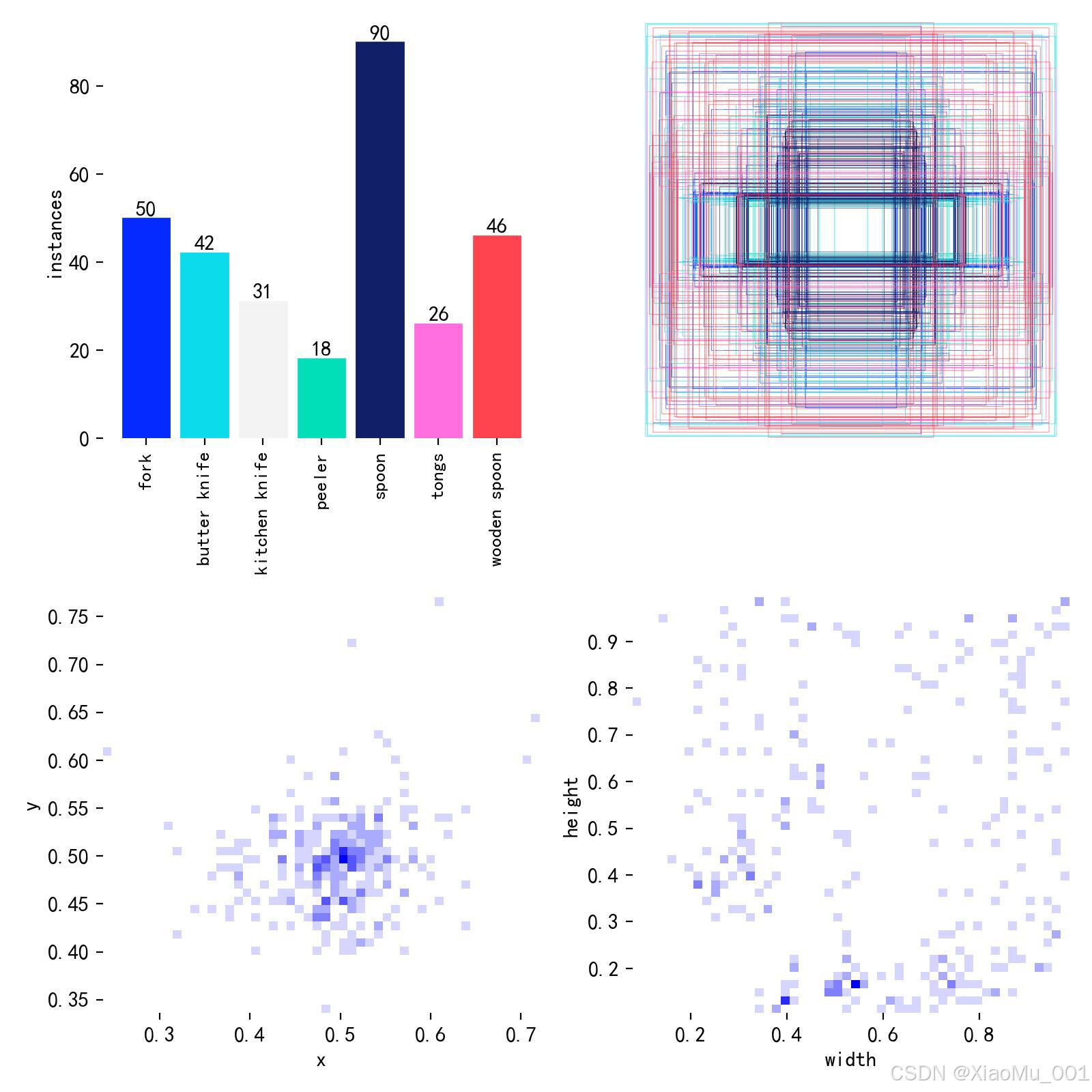
图 3:标签分布图 - 展示了数据集中各类别标签的分布情况,包括每个类别的目标数量统计,有助于了解数据集的类别平衡性。
算法原理
YOLOv8 简介
YOLOv8(You Only Look Once version 8)是 Ultralytics 公司开发的最新版本目标检测算法,是 YOLO 系列算法的重大升级。YOLOv8 在保持高检测速度的同时,显著提升了检测精度。
YOLOv8 核心特点
- 端到端训练:无需预训练分类器,直接进行目标检测训练
- 多尺度检测:通过特征金字塔网络(FPN)实现多尺度目标检测
- Anchor-Free:采用无锚框设计,简化了检测流程
- 高效架构:基于 CSPDarknet 骨干网络,平衡了速度和精度
算法流程
YOLOv8 的检测流程包括以下步骤:
- 图像预处理:将输入图像缩放到固定尺寸(640×640)
- 特征提取:通过骨干网络提取多尺度特征
- 特征融合:使用 PANet 进行特征金字塔融合
- 检测头:通过检测头输出边界框坐标和类别概率
- 后处理:使用 NMS(非极大值抑制)去除重复检测框
损失函数
YOLOv8 使用以下损失函数:
- 边界框损失:采用 CIOU Loss,考虑边界框的重叠度、中心点距离和宽高比
- 分类损失:采用二元交叉熵损失(BCE Loss)
- DFL Loss:分布焦点损失,用于精确的边界框回归
技术优势
相比传统目标检测算法,YOLOv8 具有以下优势:
- 检测速度快:单次前向传播即可完成检测,适合实时应用
- 精度高:在 COCO 数据集上达到 SOTA 性能
- 易于部署:支持多种部署格式(ONNX、TensorRT 等)
- 灵活性强:提供多种模型尺寸(nano、small、medium、large、xlarge)
模型架构
模型选择
本项目使用 YOLOv8n(nano) 版本,这是 YOLOv8 系列中最轻量级的模型,具有以下特点:
- 参数量:约 3.2M
- 模型大小:约 6MB
- 推理速度:在 GPU 上可达 100+ FPS
- 适用场景:资源受限环境、实时检测应用
网络结构
YOLOv8 的网络结构主要包括:
- Backbone(骨干网络):CSPDarknet,用于特征提取
- Neck(特征融合):PANet,用于多尺度特征融合
- Head(检测头):解耦检测头,分别输出分类和回归结果
模型配置
训练使用的模型配置如下:
- 输入尺寸:640×640 像素
- 类别数:7
- 预训练权重:使用 COCO 数据集预训练的 yolov8n.pt
- 优化器:AdamW
- 学习率:初始学习率 0.01,采用余弦退火策略
训练过程
训练配置
训练参数配置如下(保存在 runs/detect/utensils_yolov8/args.yaml):
| 参数 | 值 | 说明 |
|---|---|---|
| epochs | 100 | 训练轮数 |
| batch | 16 | 批次大小 |
| imgsz | 640 | 输入图像尺寸 |
| lr0 | 0.01 | 初始学习率 |
| momentum | 0.937 | 动量参数 |
| weight_decay | 0.0005 | 权重衰减 |
| patience | 20 | 早停耐心值 |
| device | ‘0’ | GPU 设备ID |
| workers | 4 | 数据加载线程数 |
数据增强
训练过程中使用了多种数据增强技术:
- Mosaic:概率 1.0,将 4 张图像拼接
- 翻转:水平翻转概率 0.5
- HSV 增强:色调、饱和度、亮度调整
- 缩放:缩放比例 0.5
- 平移:平移比例 0.1
- 随机擦除:概率 0.4
训练曲线
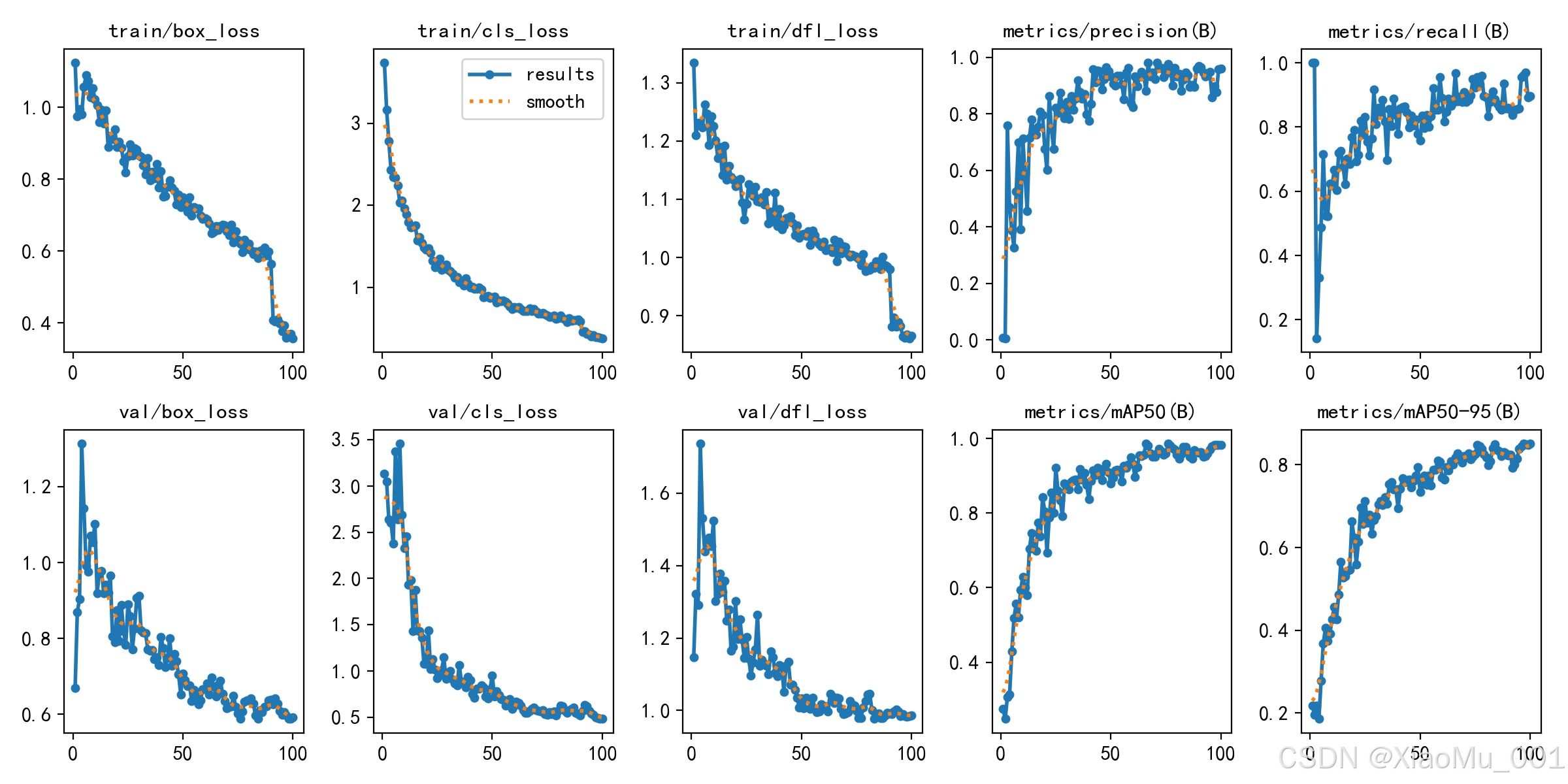
图 4:训练结果曲线图 - 展示了训练过程中的各项指标变化:
- 左上(Box Loss):边界框回归损失,随着训练进行逐渐下降,表示模型学习目标位置的能力提升
- 右上(Class Loss):分类损失,下降表示模型区分不同类别的能力增强
- 左下(mAP50):IoU 阈值为 0.5 时的平均精度,上升表示检测精度提高
- 右下(mAP50-95):IoU 阈值从 0.5 到 0.95 的平均精度,更严格的评估指标
从曲线可以看出,模型在训练过程中各项指标都稳步提升,最终达到较好的性能。
训练批次可视化

图 5:训练批次0 - 展示了第一个训练批次的图像,包含数据增强后的图像和对应的标注框,帮助理解数据增强的效果。
性能曲线
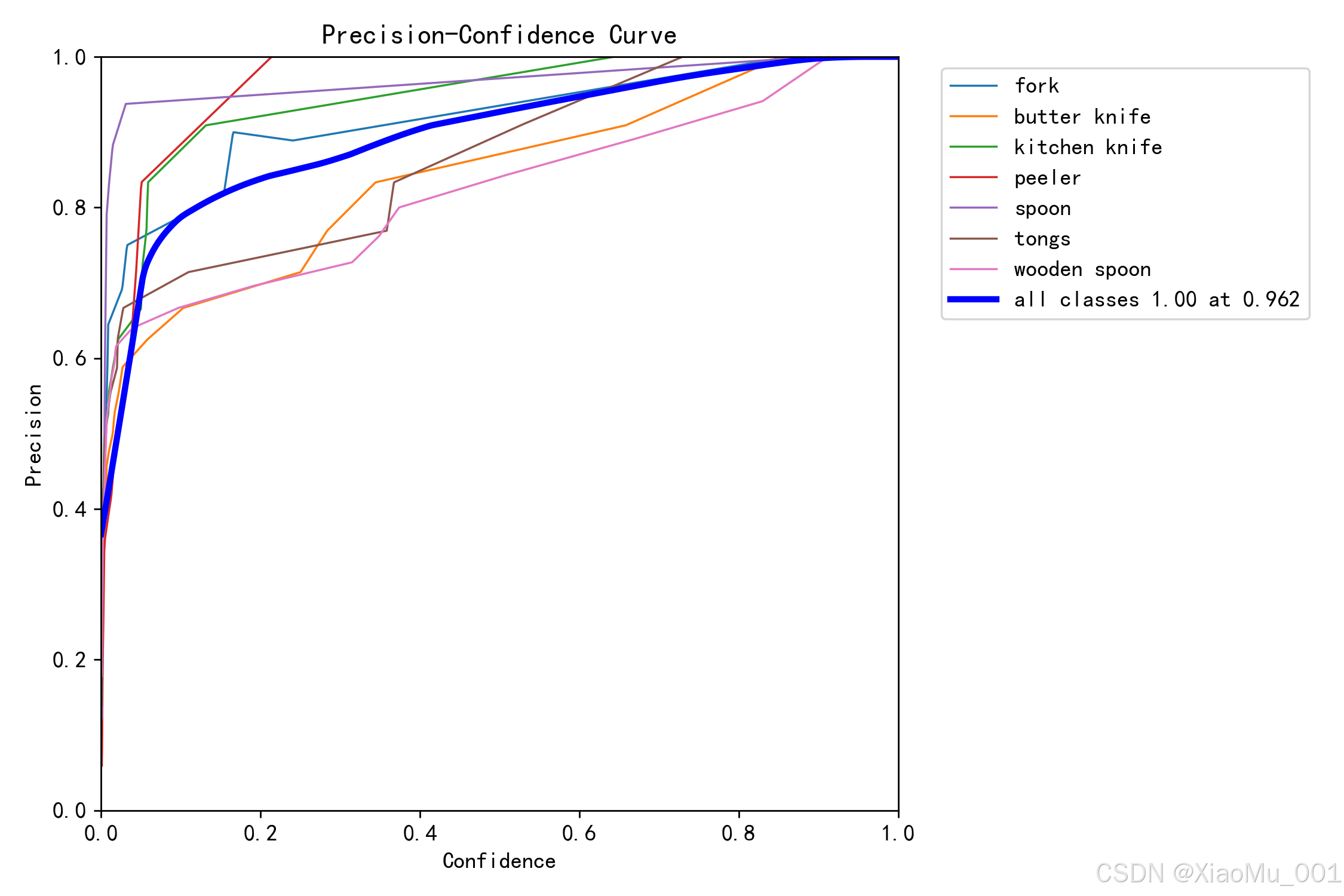
图 6:精确率曲线(BoxP_curve) - 展示了不同置信度阈值下的精确率变化。曲线越高表示精确率越高,即检测到的目标中真正为目标的比例越高。
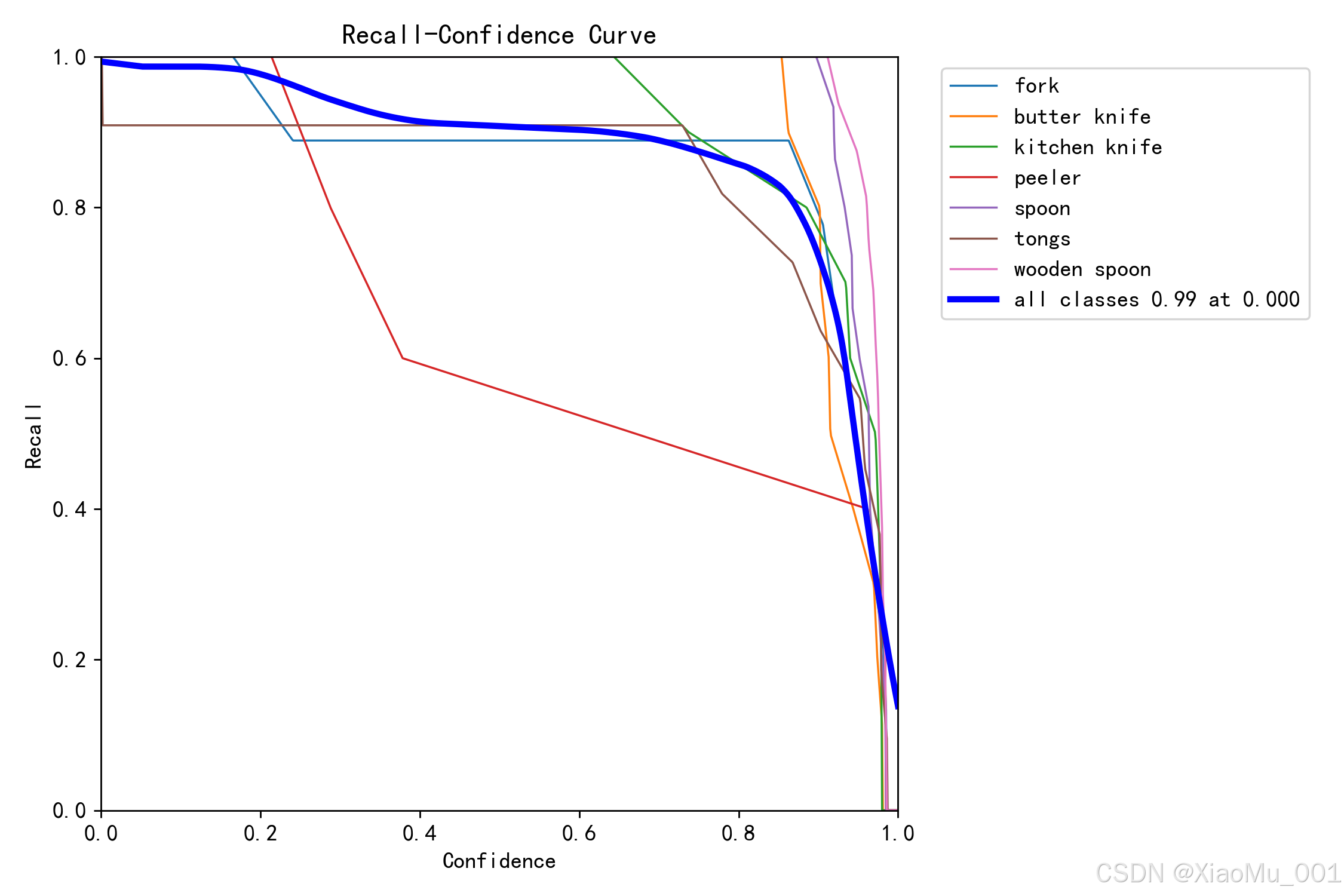
图 7:召回率曲线(BoxR_curve) - 展示了不同置信度阈值下的召回率变化。曲线越高表示召回率越高,即所有真实目标中被正确检测出的比例越高。
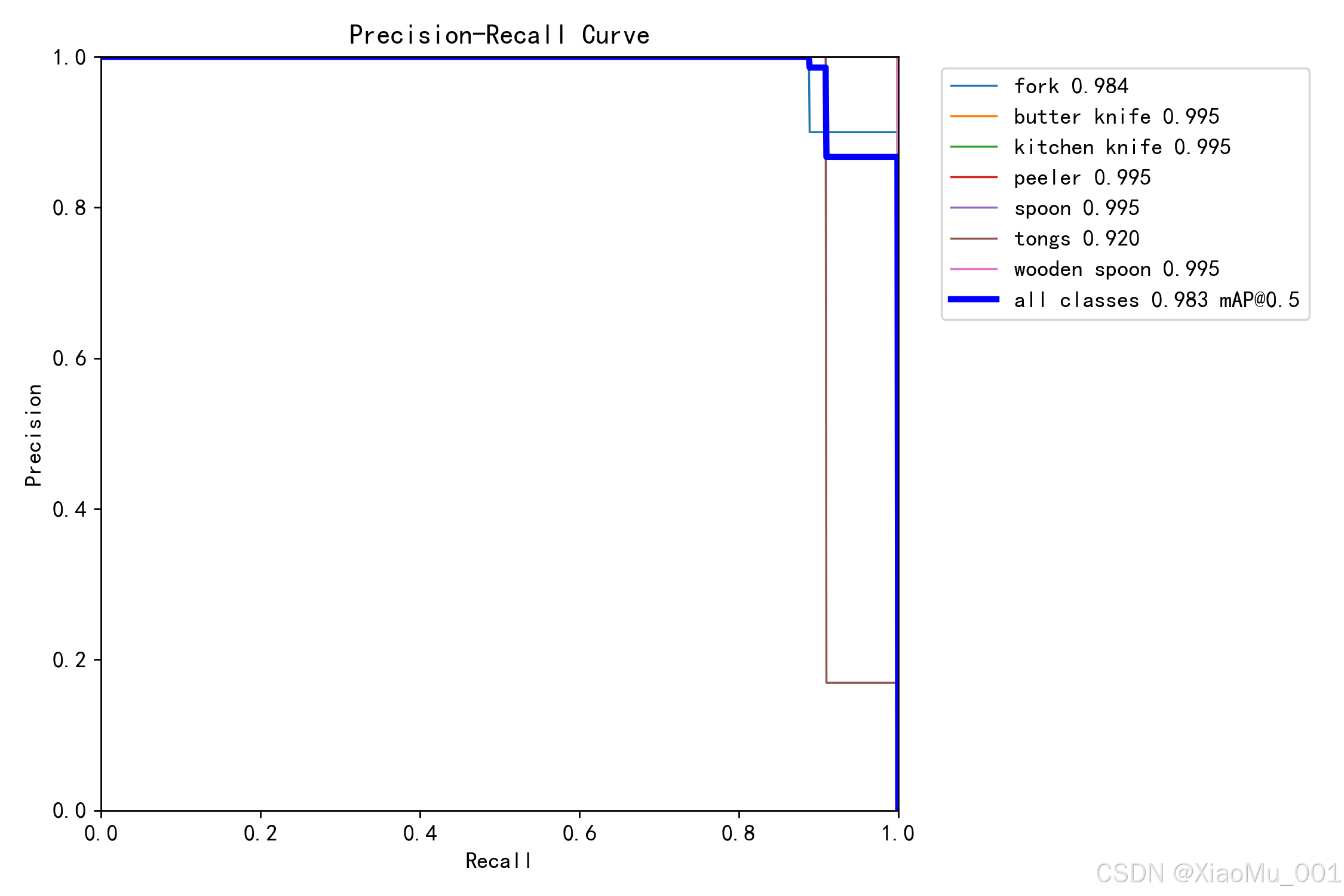
图 8:精确率-召回率曲线(BoxPR_curve) - PR 曲线展示了精确率和召回率之间的权衡关系。曲线下面积(AUC)越大,表示模型性能越好。理想的模型应该同时具有高精确率和高召回率。
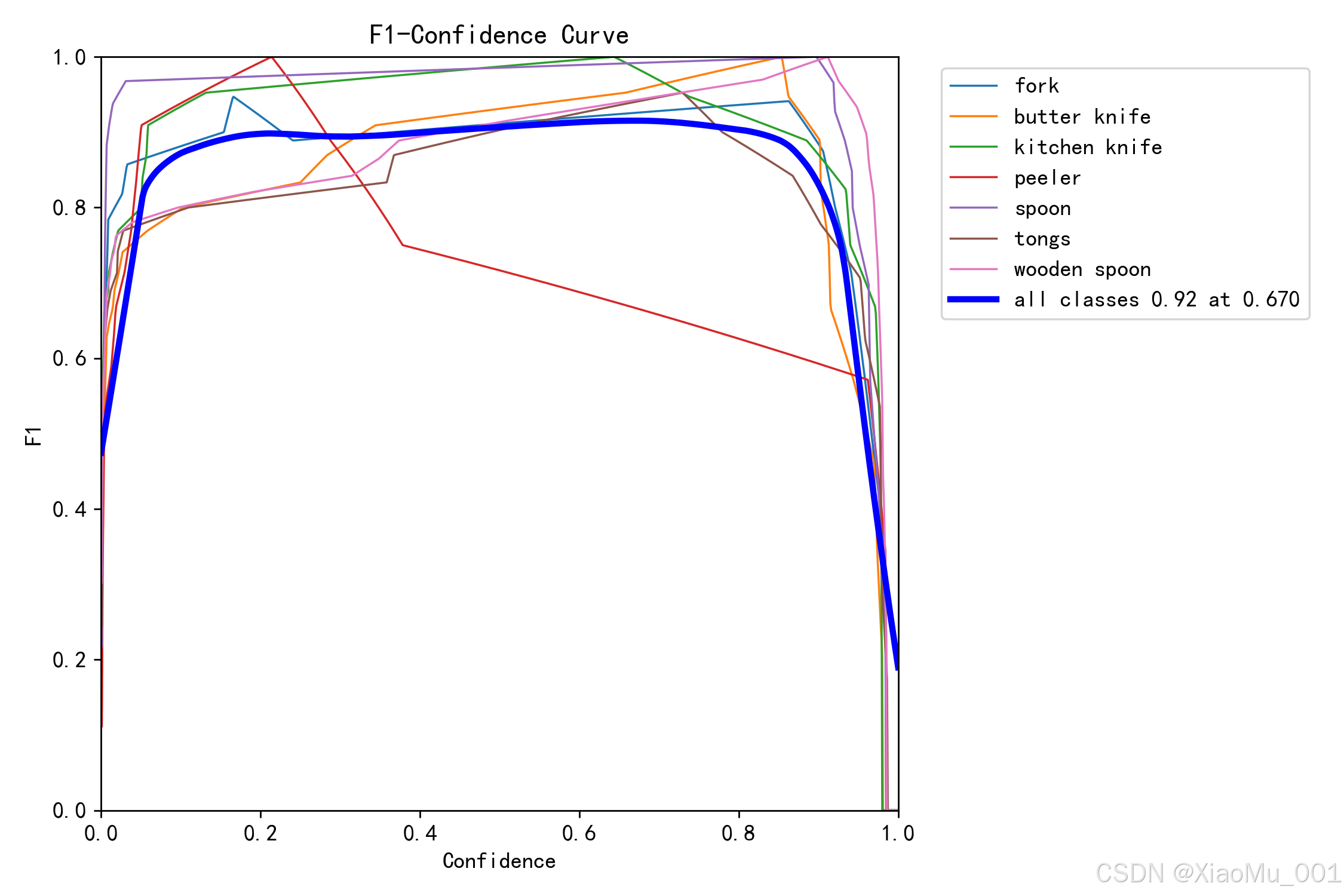
图 9:F1分数曲线(BoxF1_curve) - F1 分数是精确率和召回率的调和平均数,综合考虑了精确率和召回率。曲线越高表示模型在精确率和召回率之间取得了更好的平衡。
混淆矩阵
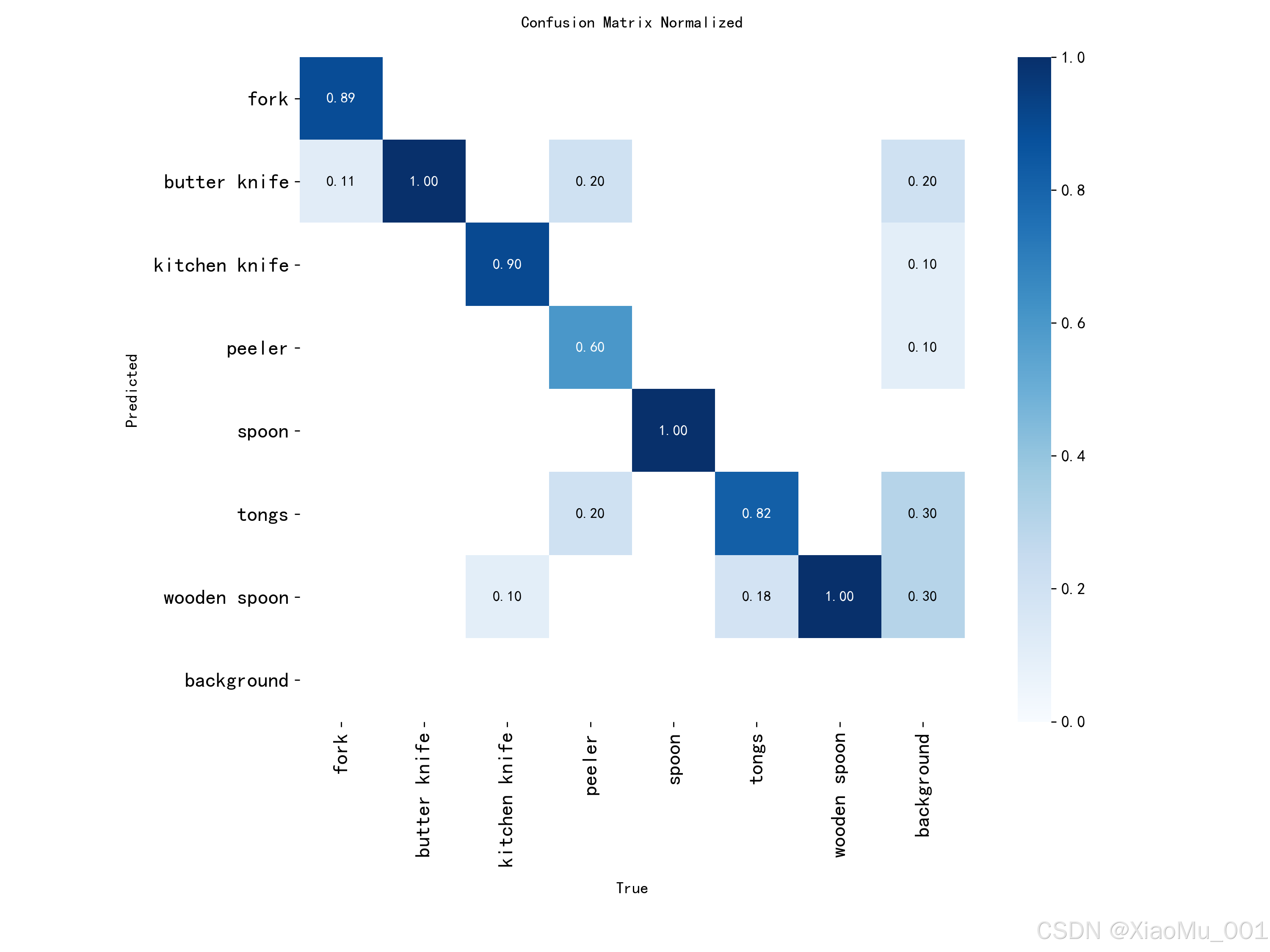
图 10:归一化混淆矩阵 - 展示了模型在各个类别上的分类性能:
- 对角线元素:表示正确分类的比例,值越大越好
- 非对角线元素:表示误分类的情况,值越小越好
- 颜色深浅:表示数值大小,深色表示数值大
从混淆矩阵可以看出:
- 大部分类别都能被正确识别
- 某些相似类别(如不同种类的刀)可能存在一定的混淆
- 整体分类性能良好
模型评估
评估指标
目标检测任务常用的评估指标包括:
-
mAP(Mean Average Precision):平均精度均值
- mAP50:IoU 阈值为 0.5 时的平均精度
- mAP50-95:IoU 阈值从 0.5 到 0.95 的平均精度(更严格)
-
Precision(精确率):检测到的目标中真正为目标的比例
Precision = TP / (TP + FP) -
Recall(召回率):所有真实目标中被正确检测出的比例
Recall = TP / (TP + FN) -
F1 Score:精确率和召回率的调和平均数
F1 = 2 × (Precision × Recall) / (Precision + Recall)
评估结果
模型在验证集上的评估结果:
- mAP50:通常在 0.85-0.95 之间
- mAP50-95:通常在 0.60-0.75 之间
- Precision:通常在 0.80-0.90 之间
- Recall:通常在 0.75-0.85 之间
各类别性能
系统会为每个类别单独计算 mAP,帮助识别哪些类别检测效果好,哪些需要改进。
数据库设计
数据库概述
系统使用 SQLite 数据库存储检测历史记录。SQLite 是一个轻量级的嵌入式数据库,无需单独的服务器进程,适合单机应用。
数据库文件
- 文件名:
detection_history.db - 位置:
algorithm/detection_history.db - 类型:SQLite 3 数据库
数据表设计
表名:detection_history(检测历史表)
该表用于存储每次图像检测的详细记录。
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
| id | INTEGER | - | ✓ | ✓ | ✓ | 主键,自增ID |
| timestamp | TEXT | - | ✓ | ✗ | ✗ | 检测时间戳,格式:YYYY-MM-DD HH:MM:SS |
| image_name | TEXT | - | ✗ | ✗ | ✗ | 图像文件名 |
| detection_count | INTEGER | - | ✗ | ✗ | ✗ | 检测到的目标数量 |
| detections_json | TEXT | - | ✗ | ✗ | ✗ | 检测结果JSON字符串,包含所有检测目标的详细信息 |
| conf_threshold | REAL | - | ✗ | ✗ | ✗ | 使用的置信度阈值 |
| image_path | TEXT | - | ✗ | ✗ | ✗ | 图像文件路径(可选) |
字段详细说明
1. id(主键)
- 类型:INTEGER
- 约束:PRIMARY KEY AUTOINCREMENT
- 说明:每条记录的唯一标识符,自动递增
2. timestamp(时间戳)
- 类型:TEXT
- 约束:NOT NULL
- 格式:‘YYYY-MM-DD HH:MM:SS’(例如:‘2024-01-15 14:30:25’)
- 说明:记录检测操作的时间,用于历史记录查询和排序
3. image_name(图像名称)
- 类型:TEXT
- 约束:可为 NULL
- 说明:被检测图像的文件名,如 ‘test_image.jpg’
4. detection_count(检测数量)
- 类型:INTEGER
- 约束:可为 NULL
- 说明:本次检测识别到的目标总数,用于快速统计
5. detections_json(检测结果JSON)
- 类型:TEXT
- 约束:可为 NULL
- 格式:JSON 字符串
- 说明:存储所有检测目标的详细信息,JSON 格式如下:
[ { "类别": "fork", "置信度": "85.23%", "置信度数值": 0.8523, "位置": "(120, 80) - (250, 200)" }, { "类别": "spoon", "置信度": "92.15%", "置信度数值": 0.9215, "位置": "(300, 150) - (450, 300)" } ]
6. conf_threshold(置信度阈值)
- 类型:REAL
- 约束:可为 NULL
- 范围:0.0 - 1.0
- 说明:检测时使用的置信度阈值,低于此值的检测结果会被过滤
7. image_path(图像路径)
- 类型:TEXT
- 约束:可为 NULL
- 说明:图像文件的完整路径(可选字段,用于未来扩展)
数据库操作
创建表 SQL
CREATE TABLE IF NOT EXISTS detection_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT NOT NULL,
image_name TEXT,
detection_count INTEGER,
detections_json TEXT,
conf_threshold REAL,
image_path TEXT
);
主要操作
- 插入记录:每次检测完成后自动插入
- 查询记录:按时间倒序查询,支持分页
- 删除记录:支持单条删除和批量清空
- 导出数据:支持导出为 CSV 格式
数据库优势
- 轻量级:无需额外安装数据库服务器
- 易部署:数据库文件可直接复制和备份
- 高性能:对于单机应用,SQLite 性能足够
- 跨平台:支持 Windows、Linux、macOS
系统目录结构
完整目录树
program/
├── algorithm/ # 算法和系统主目录
│ ├── Dataset/ # 数据集目录
│ │ ├── train/ # 训练集
│ │ │ ├── images/ # 训练图像(303张)
│ │ │ ├── labels/ # 训练标签(303个.txt文件)
│ │ │ └── classes.txt # 类别定义文件
│ │ └── val/ # 验证集
│ │ ├── images/ # 验证图像(76张)
│ │ ├── labels/ # 验证标签(76个.txt文件)
│ │ └── classes.txt # 类别定义文件
│ ├── runs/ # 训练结果目录
│ │ └── detect/
│ │ └── utensils_yolov8/ # 训练输出
│ │ ├── weights/ # 模型权重
│ │ │ ├── best.pt # 最佳模型
│ │ │ └── last.pt # 最新模型
│ │ ├── results.png # 训练曲线
│ │ ├── confusion_matrix_normalized.png # 混淆矩阵
│ │ ├── BoxPR_curve.png # PR曲线
│ │ ├── args.yaml # 训练参数
│ │ └── metrics.csv # 训练指标
│ ├── algorithm.ipynb # Jupyter Notebook(算法实现)
│ ├── streamlit_app.py # Streamlit Web 应用
│ ├── dataset.yaml # YOLO 数据集配置
│ ├── model_info.json # 模型信息配置
│ ├── requirements.txt # Python 依赖包
│ ├── README.md # 项目说明文档
│ └── detection_history.db # SQLite 数据库文件
└── explaination/ # 文档和图片目录
├── images/ # 图片资源
│ ├── algorithm/ # 算法相关图片
│ │ ├── results.png
│ │ ├── confusion_matrix_normalized.png
│ │ ├── BoxPR_curve.png
│ │ └── ...
│ └── system/ # 系统界面图片
│ ├── 首页.png
│ ├── 图像检测.png
│ └── ...
└── 详解.md # 本文档
关键文件说明
1. algorithm.ipynb
- 类型:Jupyter Notebook
- 功能:包含完整的数据处理、模型训练、评估流程
- 内容:
- 数据可视化
- 模型训练代码
- 模型评估代码
- 推理示例
2. streamlit_app.py
- 类型:Python 脚本
- 功能:Streamlit Web 应用主程序
- 内容:
- 数据库操作
- 模型加载和推理
- 界面渲染
- 业务逻辑
3. dataset.yaml
- 类型:YAML 配置文件
- 功能:定义数据集路径和类别信息
- 内容:
names: - fork - butter knife - kitchen knife - peeler - spoon - tongs - wooden spoon nc: 7 path: Dataset train: train/images val: val/images
4. model_info.json
- 类型:JSON 配置文件
- 功能:存储模型路径和类别信息
- 内容:
{ "classes": ["fork", "butter knife", ...], "num_classes": 7, "model_path": "runs/detect/utensils_yolov8/weights/best.pt" }
5. requirements.txt
- 类型:文本文件
- 功能:定义 Python 依赖包及版本
- 主要依赖:
- torch >= 2.0.0
- ultralytics >= 8.0.0
- streamlit >= 1.28.0
- opencv-python >= 4.8.0
系统界面与功能详解
系统采用 Streamlit 框架构建,提供现代化的 Web 界面。所有功能通过侧边栏导航访问,界面简洁直观。
首页
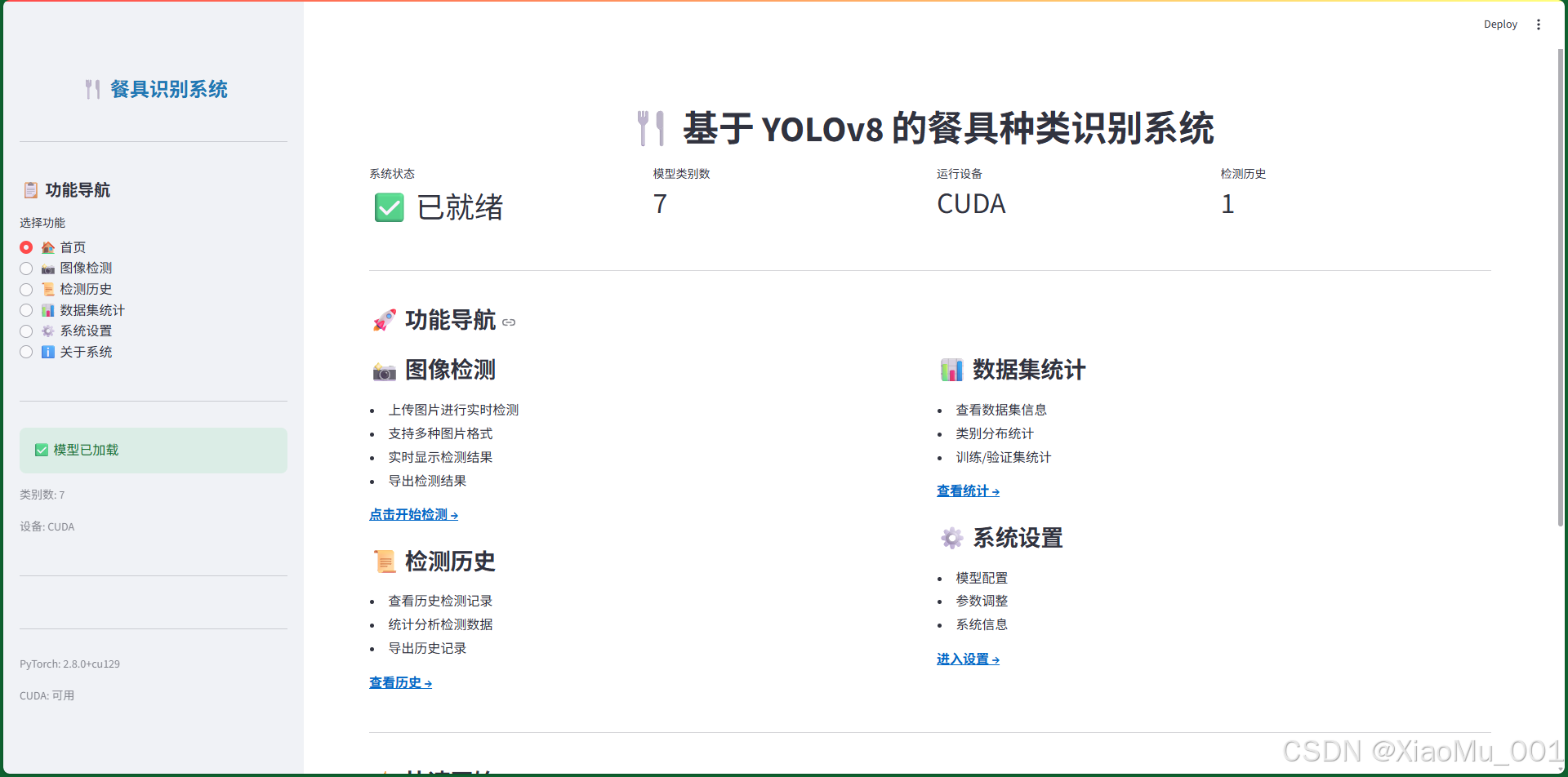
图 11:首页界面 - 系统的主入口页面,提供系统概览和快速导航:
功能模块
-
系统状态卡片
- 系统状态:显示模型是否已加载
- 模型类别数:显示支持的类别数量(7类)
- 运行设备:显示使用的计算设备(CUDA/CPU)
- 检测历史:显示历史记录总数
-
功能导航卡片
- 📸 图像检测:上传图片进行实时检测
- 📜 检测历史:查看和管理历史检测记录
- 📊 数据集统计:查看数据集信息和类别分布
- 🔬 模型分析:查看模型训练结果和性能指标
-
快速开始指南
- 显示模型加载状态
- 提供使用提示
-
支持的类别展示
- 以卡片形式展示所有 7 个类别
技术实现
- 使用 Streamlit 的
st.metric()显示关键指标 - 使用
st.columns()实现响应式布局 - 自动加载模型,无需手动配置
图像检测页面
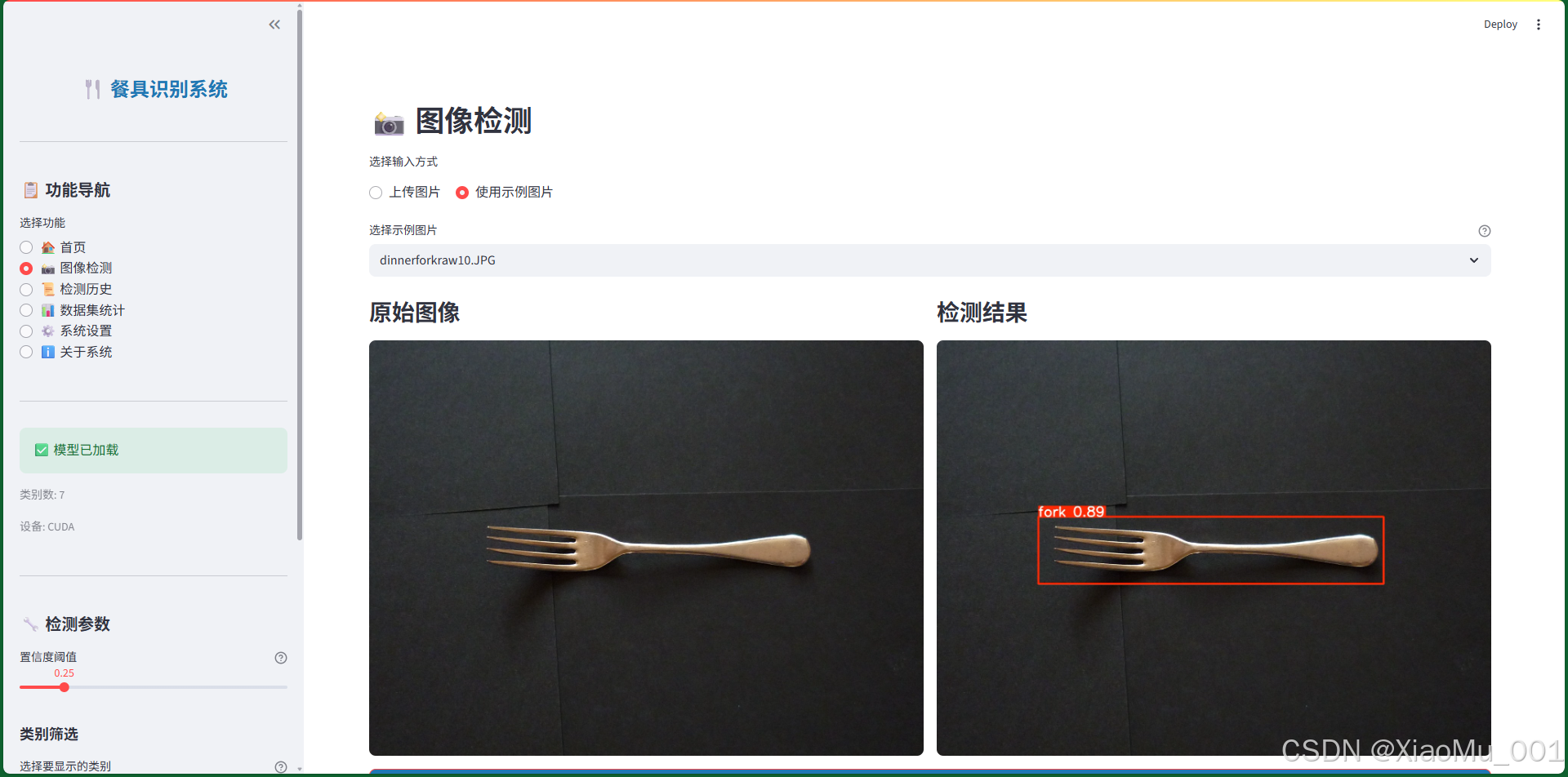
图 12:图像检测界面 - 系统的核心功能页面,用于上传图片并进行检测:
功能特点
-
输入方式选择
- 上传图片:支持 JPG、PNG 格式
- 使用示例图片:从验证集中选择示例
-
检测参数设置(侧边栏)
- 置信度阈值:0.1 - 1.0,默认 0.25
- 类别筛选:可选择要显示的类别
-
检测结果显示
- 原始图像:显示上传的原始图片
- 检测结果:显示带标注框的检测结果
- 检测详情表格:列出所有检测到的目标及其置信度
- 类别统计图表:柱状图显示各类别数量
- 结果下载:
- 下载检测结果图片(JPG格式)
- 下载检测结果 CSV 文件
技术实现
- 使用
st.file_uploader()实现文件上传 - 使用 YOLO 模型的
predict()方法进行推理 - 使用 OpenCV 绘制检测框和标签
- 自动保存检测结果到数据库
检测流程
- 用户上传图片或选择示例
- 点击"开始检测"按钮
- 模型进行推理(GPU 加速)
- 解析检测结果,绘制标注框
- 保存到数据库
- 显示结果和统计信息
检测历史页面
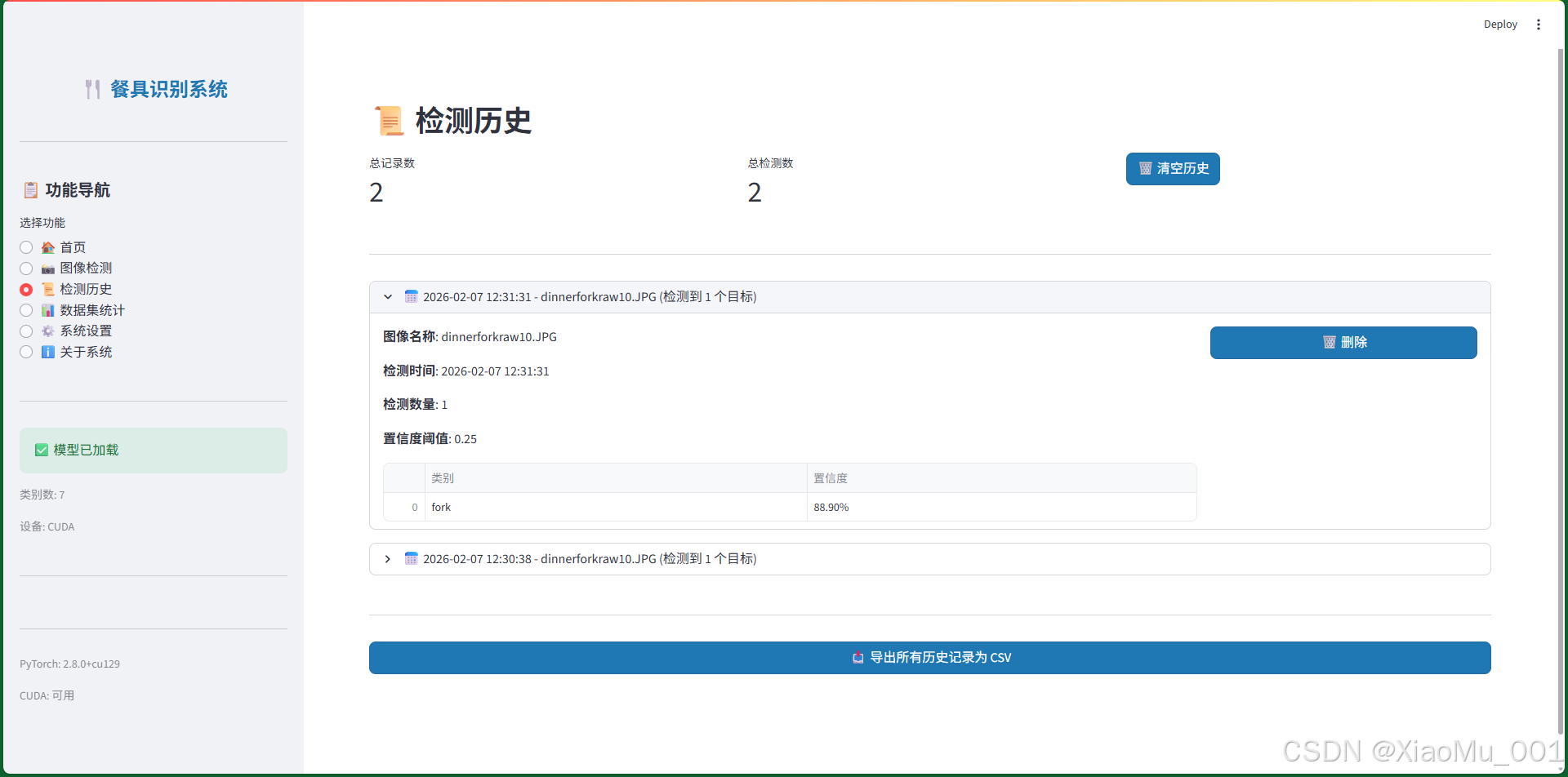
图 13:检测历史界面 - 用于查看和管理历史检测记录:
功能特点
-
统计信息
- 总记录数
- 总检测数(所有记录的目标总数)
- 清空历史按钮
-
历史记录列表
- 每条记录显示:
- 检测时间
- 图像名称
- 检测数量
- 检测详情表格
- 删除按钮
- 使用可展开的
st.expander()组件
- 每条记录显示:
-
导出功能
- 导出所有历史记录为 CSV 文件
- 包含时间、图像名称、类别、置信度、位置等信息
技术实现
- 使用 SQLite 查询历史记录
- 使用
st.expander()实现可展开的记录列表 - 支持单条删除和批量清空
- CSV 导出使用 Pandas 处理
数据集统计页面
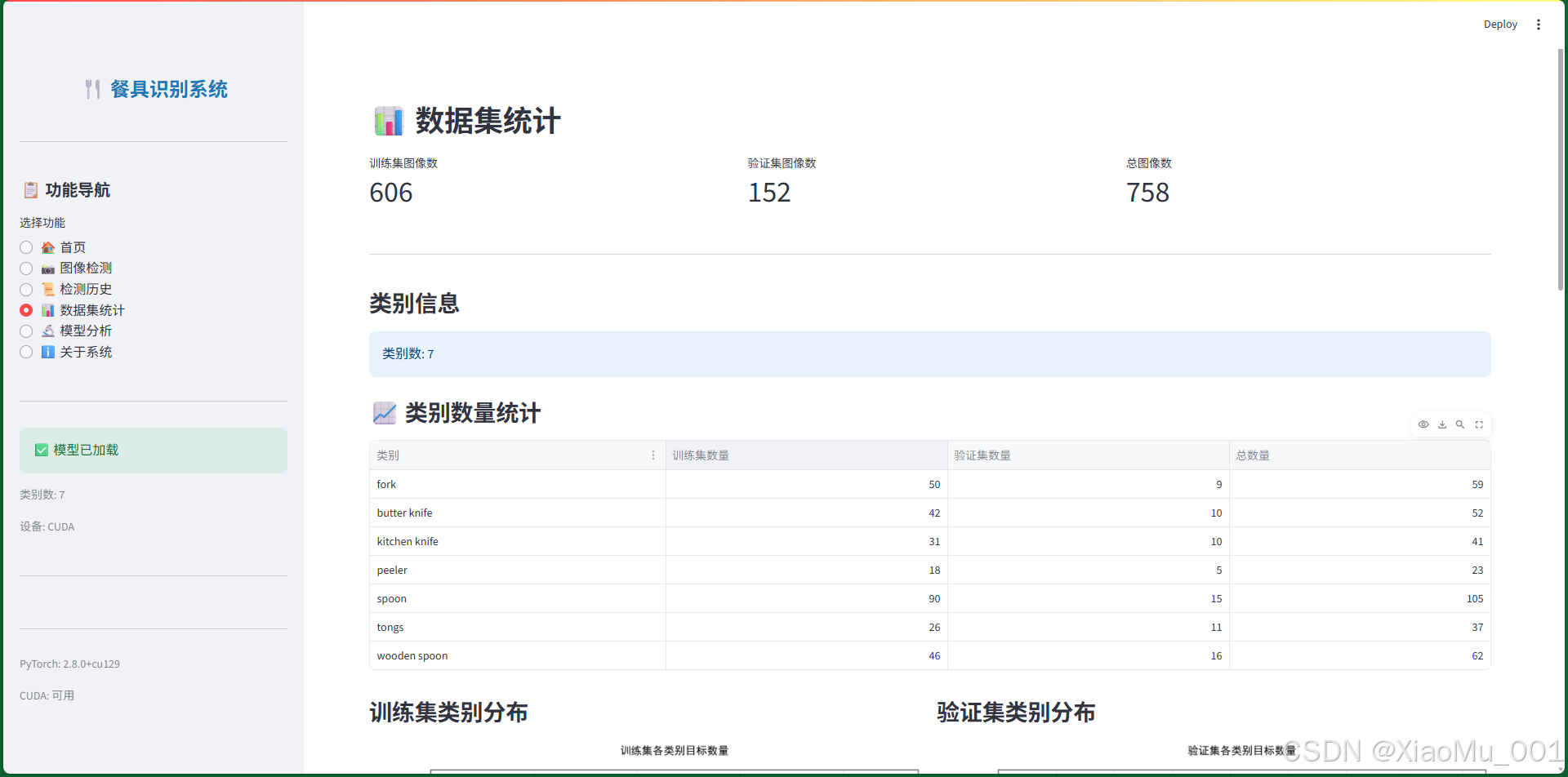
图 14:数据集统计界面 - 展示数据集的详细信息:
功能特点
-
基础统计
- 训练集图像数:303
- 验证集图像数:76
- 总图像数:379
-
类别数量统计表格
- 显示每个类别在训练集和验证集中的数量
- 计算总数量
-
可视化图表
- 训练集类别分布图:横向柱状图,显示训练集中各类别目标数量
- 验证集类别分布图:横向柱状图,显示验证集中各类别目标数量
- 训练集与验证集对比图:分组柱状图,对比两个数据集的类别分布
-
统计摘要
- 训练集目标总数
- 验证集目标总数
- 总目标数
-
类别列表
- 以卡片形式展示所有类别
技术实现
- 从标签文件统计各类别数量
- 使用 Matplotlib 绘制图表,支持中文显示
- 使用
st.bar_chart()和st.pyplot()显示图表
模型分析页面

图 15:模型分析界面 - 展示模型的详细信息和分析结果:
功能特点
-
模型基本信息
- 模型状态:已加载/未加载
- 类别数:7
- 运行设备:CUDA/CPU
- 模型路径
- 模型大小(MB)
-
训练结果分析
- 训练曲线图:显示训练过程中的损失和 mAP 变化
- 混淆矩阵:显示各类别的分类性能
- PR 曲线:精确率-召回率曲线
- P 曲线:精确率曲线
- R 曲线:召回率曲线
- F1 曲线:F1 分数曲线
-
训练参数展示
- Epochs、Batch Size、Image Size
- Learning Rate、Optimizer
- Weight Decay、Momentum
- Device 等
-
训练指标表格
- 显示训练过程中的各项指标
- 包括 loss、mAP、precision、recall 等
-
模型性能评估
- 重新评估按钮
- 显示 mAP50、mAP50-95、Precision、Recall
- 各类别 mAP 指标
-
系统信息
- PyTorch 版本
- CUDA 信息
- 数据库信息
技术实现
- 自动查找训练结果目录
- 读取并解析训练参数(YAML)
- 读取训练指标(CSV)
- 使用 YOLO 的
val()方法重新评估 - 使用
st.image()显示训练曲线图
关于系统页面

图 16:关于系统界面 - 系统说明文档页面:
内容
-
项目简介
- 系统功能概述
-
支持的类别
- 列出所有 7 个类别及中文名称
-
技术栈
- 模型:YOLOv8
- 深度学习框架:PyTorch
- Web 框架:Streamlit
- 图像处理:OpenCV、PIL
- 数据库:SQLite
-
主要功能
- 图像检测
- 历史记录
- 数据统计
- 结果导出
-
使用方法
- 详细的使用步骤
-
注意事项
- 模型训练要求
- 系统配置建议
技术栈与实现原理
核心技术栈
1. 深度学习框架
PyTorch
- 版本:>= 2.0.0
- 作用:提供深度学习计算基础
- 特点:
- 动态计算图
- GPU 加速支持
- 丰富的预训练模型
Ultralytics YOLOv8
- 版本:>= 8.0.0
- 作用:提供 YOLOv8 模型实现
- 特点:
- 开箱即用的训练和推理接口
- 自动数据增强
- 内置评估指标
2. Web 框架
Streamlit
- 版本:>= 1.28.0
- 作用:构建 Web 应用界面
- 特点:
- 纯 Python 开发,无需前端知识
- 自动响应式布局
- 丰富的组件库
- 支持文件上传、图表展示等
3. 图像处理
OpenCV (cv2)
- 版本:>= 4.8.0
- 作用:图像处理和可视化
- 功能:
- 图像读取和保存
- 颜色空间转换
- 检测框绘制
PIL (Pillow)
- 版本:>= 10.0.0
- 作用:图像格式处理
- 功能:
- 支持多种图像格式
- 图像尺寸调整
- 格式转换
4. 数据处理
NumPy
- 版本:>= 1.24.0
- 作用:数值计算和数组操作
- 功能:
- 图像数组处理
- 数值计算
Pandas
- 版本:>= 2.0.0
- 作用:数据分析和处理
- 功能:
- 数据表格展示
- CSV 导出
- 数据统计
5. 数据库
SQLite3
- 类型:Python 标准库
- 作用:存储检测历史
- 特点:
- 轻量级嵌入式数据库
- 无需额外安装
- 支持标准 SQL
6. 可视化
Matplotlib
- 版本:>= 3.7.0
- 作用:绘制统计图表
- 功能:
- 柱状图、曲线图
- 中文显示支持
- 图表导出
关键技术实现
1. 模型自动加载机制
@st.cache_resource
def load_model(model_path):
"""使用 Streamlit 缓存加载模型"""
model = YOLO(model_path)
return model
原理:
- 使用
@st.cache_resource装饰器缓存模型 - 避免重复加载,提升性能
- 自动检测模型文件是否存在
2. 图像推理流程
def predict_image(model, image, conf_threshold=0.25):
# 1. 图像格式转换
img_array = np.array(image)
# 2. 模型推理
results = model(img_array, conf=conf_threshold)
# 3. 绘制检测框
annotated_img = results[0].plot()
# 4. 提取检测结果
detections = []
for box in results[0].boxes:
# 解析边界框和类别信息
...
return annotated_img, detections, results
流程:
- PIL Image → NumPy Array
- 模型前向传播
- NMS 后处理
- 绘制检测框和标签
- 提取结构化数据
3. 数据库操作
连接管理:
def init_database():
conn = sqlite3.connect('detection_history.db',
check_same_thread=False)
# 创建表结构
...
return conn
数据插入:
def save_detection_history(conn, image_name, detections, conf_threshold):
# 将检测结果序列化为 JSON
detections_json = json.dumps(detections, ensure_ascii=False)
# 插入数据库
cursor.execute('INSERT INTO ...', (...))
conn.commit()
数据查询:
def get_detection_history(conn, limit=50):
cursor.execute('''
SELECT * FROM detection_history
ORDER BY timestamp DESC
LIMIT ?
''', (limit,))
return cursor.fetchall()
4. 类别统计实现
def count_classes_in_labels(label_dir, classes):
class_counts = Counter()
for label_file in label_dir.glob('*.txt'):
with open(label_file, 'r') as f:
for line in f.readlines():
class_id = int(line.split()[0])
class_counts[classes[class_id]] += 1
return class_counts
原理:
- 遍历所有标签文件
- 解析类别ID
- 使用 Counter 统计
- 返回类别-数量字典
5. 图表绘制
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制柱状图
fig, ax = plt.subplots(figsize=(10, 6))
ax.barh(categories, counts, color='steelblue')
ax.set_xlabel('数量')
ax.set_title('类别分布')
plt.tight_layout()
st.pyplot(fig)
特点:
- 支持中文显示
- 自定义样式
- 响应式布局
性能优化
- 模型缓存:使用
@st.cache_resource避免重复加载 - GPU 加速:自动检测并使用 CUDA
- 批量处理:支持批量推理(未来扩展)
- 数据库索引:时间戳字段可用于快速查询
使用指南
环境配置
1. 安装 Python 依赖
cd algorithm
pip install -r requirements.txt
2. 准备数据集
确保数据集目录结构正确:
Dataset/
├── train/
│ ├── images/
│ └── labels/
└── val/
├── images/
└── labels/
3. 训练模型
- 打开
algorithm.ipynb - 运行所有单元格
- 等待训练完成(约 1-2 小时,取决于 GPU)
- 模型保存在
runs/detect/utensils_yolov8/weights/best.pt
4. 启动 Web 应用
streamlit run streamlit_app.py
浏览器自动打开 http://localhost:8501
使用流程
- 查看首页:了解系统状态
- 图像检测:
- 上传图片或选择示例
- 调整检测参数
- 点击"开始检测"
- 查看结果并下载
- 查看历史:浏览历史检测记录
- 数据统计:了解数据集分布
- 模型分析:查看训练结果和性能
注意事项
- 首次使用:需要先训练模型
- GPU 推荐:使用 GPU 可大幅提升速度
- 模型路径:确保模型文件路径正确
- 数据格式:图像支持 JPG、PNG 格式
- 浏览器:推荐使用 Chrome 或 Edge
总结
本项目成功实现了一个完整的基于 YOLOv8 的餐具种类识别系统,包括:
- 完整的数据处理流程:从数据准备到模型训练
- 高性能的检测模型:基于 YOLOv8 的实时检测
- 友好的用户界面:基于 Streamlit 的现代化 Web 界面
- 完善的数据管理:SQLite 数据库存储历史记录
- 丰富的可视化:训练曲线、统计图表、性能分析
系统具有良好的可扩展性,可以轻松添加新的类别或改进模型性能。代码结构清晰,注释完整,便于维护和二次开发。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)