基于深度学习的农产品价格智能预测系统
基于深度学习的农产品价格智能预测系统
目录
项目概述
1.1 项目背景
农产品价格预测是农业市场分析的核心问题之一。准确的价格预测可以帮助:
- 农户:合理安排种植和销售时机
- 经销商:优化采购和库存管理
- 政府:制定农业政策和市场调控措施
- 消费者:了解价格趋势,合理消费
1.2 项目目标
本项目旨在构建一个基于深度学习的农产品价格智能预测系统,实现:
- 多维度数据分析:对农产品价格数据进行全面探索性分析
- 深度学习预测:使用 LSTM 和 GRU 模型进行价格预测
- 可视化展示:提供直观的数据分析和预测结果展示
- 历史记录管理:保存和管理预测历史记录
1.3 技术特点
- ✅ 采用时间序列深度学习模型(LSTM/GRU)
- ✅ 支持多农产品、多市场的价格预测
- ✅ 交互式可视化大屏展示
- ✅ SQLite 数据库管理预测历史
- ✅ 完整的模型评估指标体系
数据集介绍
2.1 数据集来源
数据集名称:Nigerian Agriculture Commodity Market Prices Dataset
数据来源:Hugging Face 开源数据集
数据集链接:https://huggingface.co/datasets/electricsheepafrica/nigerian_agriculture_commodity_market_prices
2.2 数据集特点
- 数据规模:180,000+ 条记录
- 时间跨度:2022-01-01 至 2025-03-30
- 数据格式:CSV/Parquet
- 数据性质:合成数据(基于 FAO、NBS、NiMet、FMARD 等真实数据生成)
2.3 数据字段说明
| 字段名 | 类型 | 说明 | 示例值 |
|---|---|---|---|
market |
string | 交易市场名称 | “Dawanau”, “Ariaria”, “Mile 12” |
commodity |
string | 农产品名称 | “rice”, “maize”, “beans” |
date |
string | 交易日期 | “2022-01-01” |
price_ngn_kg |
float | 价格(奈拉/公斤) | 507.21 |
volume_kg |
float | 交易量(公斤) | 6978.1 |
2.4 数据统计信息
- 农产品种类:12 种(rice, maize, beans, cassava, yam, tomato, onion, groundnut, sorghum, millet, cocoa, oil_palm)
- 市场数量:5 个(Dawanau, Ariaria, Mile 12, Bodija, Wuse)
- 价格范围:50.00 ~ 1,767.58 NGN/kg
- 平均价格:509.28 NGN/kg
- 价格标准差:282.68 NGN/kg
系统架构设计
3.1 系统架构图
┌─────────────────────────────────────────────────────────────┐
│ 用户界面层 (Streamlit) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │系统介绍 │ │数据概览 │ │数据分析 │ │预测界面 │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │历史记录 │ │模型分析 │ │结论总结 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 业务逻辑层 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │数据管理模块 │ │预测模块 │ │可视化模块 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │模型加载模块 │ │评估模块 │ │历史管理模块 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 数据层 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │CSV 数据文件 │ │SQLite 数据库 │ │模型文件(.h5) │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │JSON 配置文件 │ │图片文件 │ │Scaler 文件 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────┘
3.2 核心模块说明
3.2.1 数据管理模块
- 数据加载与清洗
- 多维度数据筛选(农产品、市场、时间范围)
- 数据统计与概览
3.2.2 预测模块
- LSTM/GRU 模型加载
- 时间序列数据预处理
- 多步长预测(1-7天)
3.2.3 可视化模块
- 交互式图表展示(Plotly)
- 数据分析大屏
- 预测结果可视化
3.2.4 历史管理模块
- SQLite 数据库操作
- 预测记录保存与查询
- 历史趋势分析
项目目录结构
program/
├── algorithm/ # 算法与模型目录
│ ├── algorithm.ipynb # Jupyter Notebook:数据分析和模型训练
│ ├── streamlit_app.py # Streamlit 应用主程序
│ └── artifacts/ # 模型和数据处理产物目录
│ ├── raw_prices.csv # 原始数据
│ ├── processed_prices.csv # 处理后的数据
│ ├── lstm_model.h5 # LSTM 模型文件
│ ├── gru_model.h5 # GRU 模型文件
│ ├── scaler.pkl # 数据归一化器
│ ├── metrics.json # 模型评估指标
│ ├── train_history.json # 训练历史记录
│ ├── train_meta.json # 训练元数据
│ ├── predictions.csv # 预测结果
│ ├── history.db # SQLite 历史记录数据库
│ ├── price_distribution.png # 价格分布图
│ ├── price_trend.png # 价格趋势图
│ ├── eda_comparison.png # EDA 对比分析图
│ ├── prediction_compare.png # 预测对比图
│ ├── metrics_bar.png # 指标柱状图
│ └── train_history_curve.png # 训练历史曲线图
│
└── explaination/ # 文档说明目录
├── 详解.md # 本文档
└── images/ # 图片资源目录
├── algorithm/ # 算法相关图片
│ ├── price_distribution.png
│ ├── price_trend.png
│ ├── eda_comparison.png
│ ├── prediction_compare.png
│ ├── metrics_bar.png
│ └── train_history_curve.png
└── system/ # 系统界面截图
├── 系统介绍.png
├── 数据概览.png
├── 数据分析.png
├── 预测界面.png
├── 历史记录.png
├── 模型分析.png
└── 结论总结.png
数据库设计
5.1 数据库概述
系统使用 SQLite 作为轻量级数据库,用于存储预测历史记录。SQLite 是一个嵌入式数据库,无需单独的服务器进程,非常适合中小型应用。
5.2 数据表设计
5.2.1 预测历史表(predict_history)
表名:predict_history
表说明:存储用户每次进行价格预测的记录,包括预测时间、农产品、市场、使用的模型、预测步长和预测结果。
表结构:
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
id |
INTEGER | - | ✅ | ✅ | ✅ | 自增主键,唯一标识每条记录 |
created_at |
TEXT | - | ✅ | ❌ | ❌ | 预测创建时间,ISO 格式字符串 |
commodity |
TEXT | - | ✅ | ❌ | ❌ | 农产品名称,如 “rice”, “maize” |
market |
TEXT | - | ✅ | ❌ | ❌ | 市场名称,如 “Dawanau”, “Ariaria” |
model |
TEXT | - | ✅ | ❌ | ❌ | 使用的模型,值为 “LSTM” 或 “GRU” |
horizon |
INTEGER | - | ✅ | ❌ | ❌ | 预测步长(天数),范围 1-7 |
prediction |
REAL | - | ✅ | ❌ | ❌ | 预测价格值(NGN/kg),浮点数 |
字段详细说明:
-
id (INTEGER PRIMARY KEY AUTOINCREMENT)
- 类型:整数
- 约束:主键,自增
- 说明:每条记录的唯一标识符,系统自动生成
-
created_at (TEXT)
- 类型:文本字符串
- 格式:ISO 8601 格式(如 “2026-01-15T10:30:00”)
- 约束:非空
- 说明:记录预测操作的时间戳
-
commodity (TEXT)
- 类型:文本字符串
- 约束:非空
- 说明:预测的农产品名称,与数据集中的 commodity 字段对应
-
market (TEXT)
- 类型:文本字符串
- 约束:非空
- 说明:预测的市场名称,与数据集中的 market 字段对应
-
model (TEXT)
- 类型:文本字符串
- 约束:非空
- 取值:只能是 “LSTM” 或 “GRU”
- 说明:用于预测的深度学习模型类型
-
horizon (INTEGER)
- 类型:整数
- 约束:非空
- 范围:1-7
- 说明:预测未来多少天的价格
-
prediction (REAL)
- 类型:浮点数
- 约束:非空
- 单位:NGN/kg(奈拉/公斤)
- 说明:模型预测的价格值
SQL 建表语句:
CREATE TABLE IF NOT EXISTS predict_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
created_at TEXT NOT NULL,
commodity TEXT NOT NULL,
market TEXT NOT NULL,
model TEXT NOT NULL,
horizon INTEGER NOT NULL,
prediction REAL NOT NULL
);
索引设计:
为了提高查询性能,建议创建以下索引:
-- 按创建时间倒序查询(用于显示最新记录)
CREATE INDEX IF NOT EXISTS idx_created_at ON predict_history(created_at DESC);
-- 按农产品和市场查询
CREATE INDEX IF NOT EXISTS idx_commodity_market ON predict_history(commodity, market);
-- 按模型类型查询
CREATE INDEX IF NOT EXISTS idx_model ON predict_history(model);
数据示例:
| id | created_at | commodity | market | model | horizon | prediction |
|---|---|---|---|---|---|---|
| 1 | 2026-01-15T10:30:00 | rice | Dawanau | LSTM | 1 | 507.23 |
| 2 | 2026-01-15T10:30:00 | rice | Dawanau | GRU | 1 | 508.45 |
| 3 | 2026-01-15T11:15:00 | maize | Ariaria | LSTM | 3 | 650.12 |
5.3 数据库操作
5.3.1 初始化数据库
def init_db():
"""初始化数据库,创建表结构"""
with sqlite3.connect(DB_PATH) as conn:
conn.execute("""
CREATE TABLE IF NOT EXISTS predict_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
created_at TEXT NOT NULL,
commodity TEXT NOT NULL,
market TEXT NOT NULL,
model TEXT NOT NULL,
horizon INTEGER NOT NULL,
prediction REAL NOT NULL
)
""")
conn.commit()
5.3.2 插入预测记录
def save_history(commodity, market, model, horizon, prediction):
"""保存预测记录到数据库"""
with sqlite3.connect(DB_PATH) as conn:
conn.execute("""
INSERT INTO predict_history
(created_at, commodity, market, model, horizon, prediction)
VALUES (?, ?, ?, ?, ?, ?)
""", (
datetime.now().isoformat(timespec="seconds"),
commodity, market, model, horizon, float(prediction)
))
conn.commit()
5.3.3 查询历史记录
def fetch_history(limit=200):
"""从数据库查询历史记录"""
with sqlite3.connect(DB_PATH) as conn:
rows = conn.execute("""
SELECT created_at, commodity, market, model, horizon, prediction
FROM predict_history
ORDER BY id DESC
LIMIT ?
""", (limit,)).fetchall()
return pd.DataFrame(rows, columns=[
"created_at", "commodity", "market", "model", "horizon", "prediction"
])
算法原理与实现
6.1 时间序列预测问题
农产品价格预测本质上是一个时间序列预测问题。时间序列是指按时间顺序排列的数据点序列,具有以下特点:
- 时间依赖性:当前价格受历史价格影响
- 趋势性:价格可能呈现上升或下降趋势
- 季节性:价格可能受季节因素影响
- 波动性:价格存在随机波动
6.2 深度学习模型选择
6.2.1 LSTM(长短期记忆网络)
LSTM 原理:
LSTM 是循环神经网络(RNN)的一种变体,专门设计用于解决传统 RNN 的梯度消失问题。LSTM 通过三个门控机制(遗忘门、输入门、输出门)来控制信息的流动。
LSTM 结构:
输入 → 遗忘门 → 输入门 → 输出门 → 输出
↓ ↓ ↓
细胞状态 ← 细胞状态 ← 细胞状态
关键组件:
-
遗忘门(Forget Gate):决定从细胞状态中丢弃哪些信息
f_t = σ(W_f · [h_{t-1}, x_t] + b_f) -
输入门(Input Gate):决定存储哪些新信息
i_t = σ(W_i · [h_{t-1}, x_t] + b_i) C̃_t = tanh(W_C · [h_{t-1}, x_t] + b_C) -
细胞状态更新:
C_t = f_t * C_{t-1} + i_t * C̃_t -
输出门(Output Gate):决定输出哪些信息
o_t = σ(W_o · [h_{t-1}, x_t] + b_o) h_t = o_t * tanh(C_t)
LSTM 优势:
- ✅ 能够学习长期依赖关系
- ✅ 有效解决梯度消失问题
- ✅ 适合处理时间序列数据
本系统 LSTM 架构:
def build_lstm(input_shape):
model = Sequential([
LSTM(64, return_sequences=True, input_shape=input_shape), # 第一层 LSTM,64 个单元
Dropout(0.2), # 20% Dropout 防止过拟合
LSTM(32), # 第二层 LSTM,32 个单元
Dense(16, activation="relu"), # 全连接层,16 个神经元
Dense(1) # 输出层,预测未来 1 天价格
])
model.compile(optimizer="adam", loss="mse")
return model
架构说明:
- 输入层:接收 30 天的历史价格序列(窗口大小)
- 第一层 LSTM:64 个单元,
return_sequences=True返回完整序列 - Dropout 层:0.2 的丢弃率,防止过拟合
- 第二层 LSTM:32 个单元,提取高级特征
- 全连接层:16 个神经元,ReLU 激活
- 输出层:1 个神经元,输出预测价格
6.2.2 GRU(门控循环单元)
GRU 原理:
GRU 是 LSTM 的简化版本,将 LSTM 的三个门(遗忘门、输入门、输出门)简化为两个门(重置门、更新门),计算效率更高。
GRU 结构:
输入 → 重置门 → 更新门 → 输出
↓ ↓
隐藏状态 ← 隐藏状态
关键组件:
-
重置门(Reset Gate):决定如何将新的输入与之前的记忆结合
r_t = σ(W_r · [h_{t-1}, x_t] + b_r) -
更新门(Update Gate):决定保留多少旧信息
z_t = σ(W_z · [h_{t-1}, x_t] + b_z) -
候选隐藏状态:
h̃_t = tanh(W_h · [r_t * h_{t-1}, x_t] + b_h) -
隐藏状态更新:
h_t = (1 - z_t) * h_{t-1} + z_t * h̃_t
GRU 优势:
- ✅ 结构更简单,参数更少
- ✅ 训练速度更快
- ✅ 在某些任务上性能与 LSTM 相当
本系统 GRU 架构:
def build_gru(input_shape):
model = Sequential([
GRU(64, return_sequences=True, input_shape=input_shape), # 第一层 GRU,64 个单元
Dropout(0.2), # 20% Dropout
GRU(32), # 第二层 GRU,32 个单元
Dense(16, activation="relu"), # 全连接层
Dense(1) # 输出层
])
model.compile(optimizer="adam", loss="mse")
return model
6.3 模型对比
| 特性 | LSTM | GRU |
|---|---|---|
| 参数数量 | 较多 | 较少 |
| 计算复杂度 | 较高 | 较低 |
| 训练速度 | 较慢 | 较快 |
| 长期记忆能力 | 强 | 较强 |
| 适用场景 | 复杂时间序列 | 简单到中等复杂度 |
数据预处理流程
7.1 数据加载
步骤 1:从 Hugging Face 加载数据集
from datasets import load_dataset
ds = load_dataset("electricsheepafrica/nigerian_agriculture_commodity_market_prices")
df = ds["train"].to_pandas()
步骤 2:字段映射与清洗
由于数据集字段可能因版本而异,系统实现了智能字段映射:
def pick_col(col_set, primary, alternatives):
"""智能选择字段名"""
if primary in col_set:
return primary
for alt in alternatives:
if alt in col_set:
return alt
return None
# 字段映射
commodity_col = pick_col(cols, "commodity", ["product", "item"])
market_col = pick_col(cols, "market", ["market_name", "location"])
price_col = pick_col(cols, "price_ngn_kg", ["price", "price_ngn"])
7.2 数据清洗
步骤 1:类型转换
clean_df["date"] = pd.to_datetime(clean_df["date"], errors="coerce")
clean_df["price"] = pd.to_numeric(clean_df["price"], errors="coerce")
步骤 2:异常值过滤
# 过滤无效价格(<= 0 或过大异常值)
clean_df = clean_df[(clean_df["price"] > 0) & (clean_df["price"] < 1e6)].copy()
步骤 3:缺失值处理
# 删除关键字段缺失的记录
clean_df = clean_df.dropna(subset=["date", "price", "commodity", "market"]).copy()
7.3 数据归一化
为什么需要归一化?
- 价格数据范围较大(50-1767 NGN/kg)
- 神经网络对输入数据的尺度敏感
- 归一化可以加速训练收敛
归一化方法:MinMaxScaler(最小-最大归一化)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaled_prices = scaler.fit_transform(model_df[["price"]])
归一化公式:
X_scaled = (X - X_min) / (X_max - X_min)
归一化范围:[0, 1]
7.4 时间序列样本构造
滑动窗口法:
将时间序列数据转换为监督学习问题,使用前 N 天的价格预测未来 M 天的价格。
窗口大小:30 天(WINDOW_SIZE = 30)
预测步长:1 天(HORIZON = 1)
样本构造函数:
def create_sequences(values, window_size=30, horizon=1):
"""
构造时间序列样本
参数:
values: 归一化后的价格序列
window_size: 输入窗口大小(历史天数)
horizon: 预测步长(未来天数)
返回:
X: 输入序列 (样本数, 窗口大小, 特征数)
y: 目标值 (样本数, 预测步长)
"""
X, y = [], []
for i in range(len(values) - window_size - horizon + 1):
X.append(values[i : i + window_size]) # 输入:30 天历史价格
y.append(values[i + window_size : i + window_size + horizon]) # 输出:未来 1 天价格
return np.array(X), np.array(y)
示例:
假设有 100 天的价格数据,窗口大小为 30,预测步长为 1:
- 样本 1:X = [第1-30天], y = [第31天]
- 样本 2:X = [第2-31天], y = [第32天]
- …
- 样本 70:X = [第70-99天], y = [第100天]
数据形状:
- X: (样本数, 30, 1) - 每个样本包含 30 天的价格序列
- y: (样本数, 1) - 每个样本对应未来 1 天的价格
7.5 数据集划分
划分比例:
- 训练集:70% - 用于模型训练
- 验证集:15% - 用于超参数调优和早停
- 测试集:15% - 用于最终模型评估
train_size = int(len(X) * 0.7)
val_size = int(len(X) * 0.15)
X_train, y_train = X[:train_size], y[:train_size]
X_val, y_val = X[train_size : train_size + val_size], y[train_size + val_size :]
X_test, y_test = X[train_size + val_size :], y[train_size + val_size :]
划分原则:
- 按时间顺序划分(不随机打乱)
- 保持时间序列的连续性
- 训练集用于学习,验证集用于调参,测试集用于评估
模型训练过程
8.1 训练参数设置
| 参数 | 值 | 说明 |
|---|---|---|
| 优化器 | Adam | 自适应学习率优化算法 |
| 损失函数 | MSE (均方误差) | 回归问题的标准损失函数 |
| 训练轮次 | 8 | Epochs |
| 批次大小 | 32 | Batch Size |
| 学习率 | 默认(Adam 自适应) | 由优化器自动调整 |
| Dropout 率 | 0.2 | 防止过拟合 |
8.2 训练流程
步骤 1:模型初始化
lstm_model = build_lstm(INPUT_SHAPE)
gru_model = build_gru(INPUT_SHAPE)
步骤 2:模型训练
lstm_history = lstm_model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=EPOCHS,
batch_size=BATCH_SIZE,
verbose=1
)
步骤 3:模型保存
lstm_model.save(LSTM_MODEL_PATH)
gru_model.save(GRU_MODEL_PATH)
8.3 训练过程监控
训练指标:
- 训练损失(loss):模型在训练集上的误差
- 验证损失(val_loss):模型在验证集上的误差
训练历史曲线:
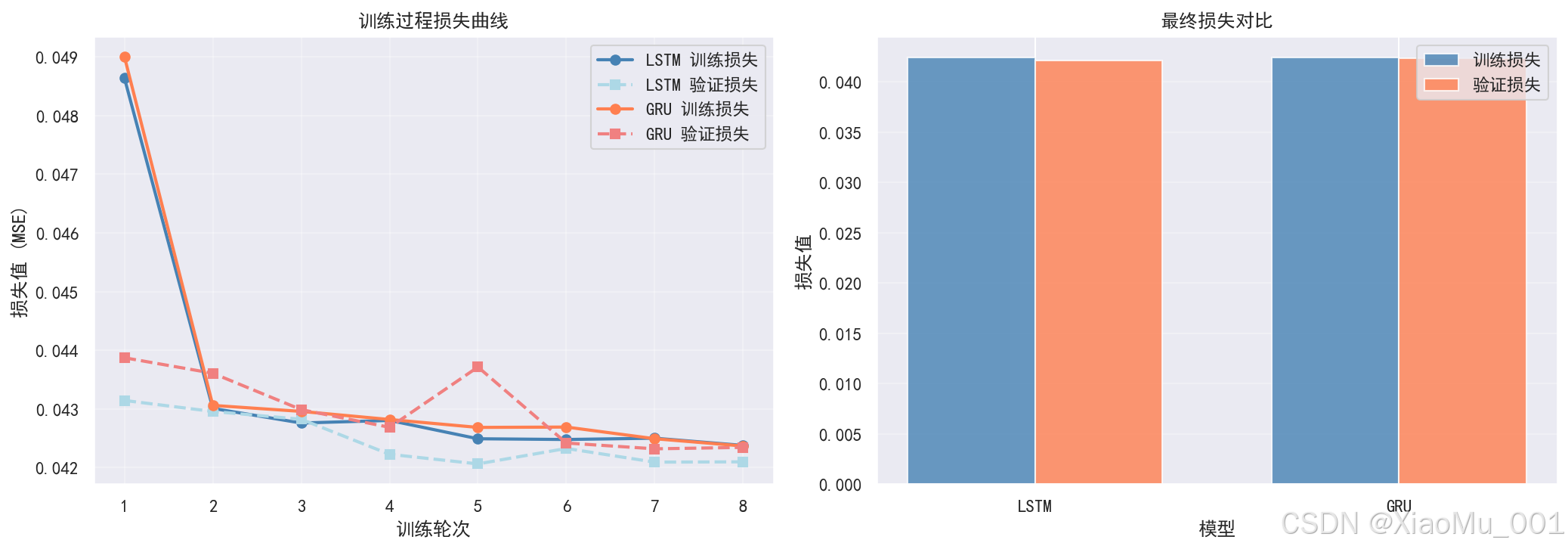
图表说明:
- 左图:展示 LSTM 和 GRU 的训练损失和验证损失随训练轮次的变化
- 右图:对比两个模型的最终损失值
- 观察要点:
- 损失值应随训练轮次下降
- 训练损失和验证损失应保持合理差距(避免过拟合)
- 两个模型的性能对比
模型评估方法
9.1 评估指标
9.1.1 MSE(均方误差)
公式:
MSE = (1/n) * Σ(y_true - y_pred)²
说明:
- 衡量预测值与真实值之间的平均平方差
- 值越小越好
- 对异常值敏感(平方放大误差)
9.1.2 RMSE(均方根误差)
公式:
RMSE = √MSE
说明:
- MSE 的平方根,与目标变量同单位
- 更直观地反映预测误差
- 值越小越好
9.1.3 MAE(平均绝对误差)
公式:
MAE = (1/n) * Σ|y_true - y_pred|
说明:
- 预测值与真实值之间的平均绝对差
- 对异常值不敏感
- 值越小越好
9.1.4 MAPE(平均绝对百分比误差)
公式:
MAPE = (100/n) * Σ|(y_true - y_pred) / y_true|
说明:
- 以百分比形式表示误差
- 便于理解误差的相对大小
- 值越小越好
9.1.5 R²(决定系数)
公式:
R² = 1 - (SS_res / SS_tot)
其中:
- SS_res = Σ(y_true - y_pred)²(残差平方和)
- SS_tot = Σ(y_true - y_mean)²(总平方和)
说明:
- 衡量模型对数据方差的解释程度
- 取值范围:(-∞, 1]
- R² = 1:完美预测
- R² = 0:模型预测等于均值
- R² < 0:模型预测比均值还差
9.2 评估结果可视化
9.2.1 预测对比图
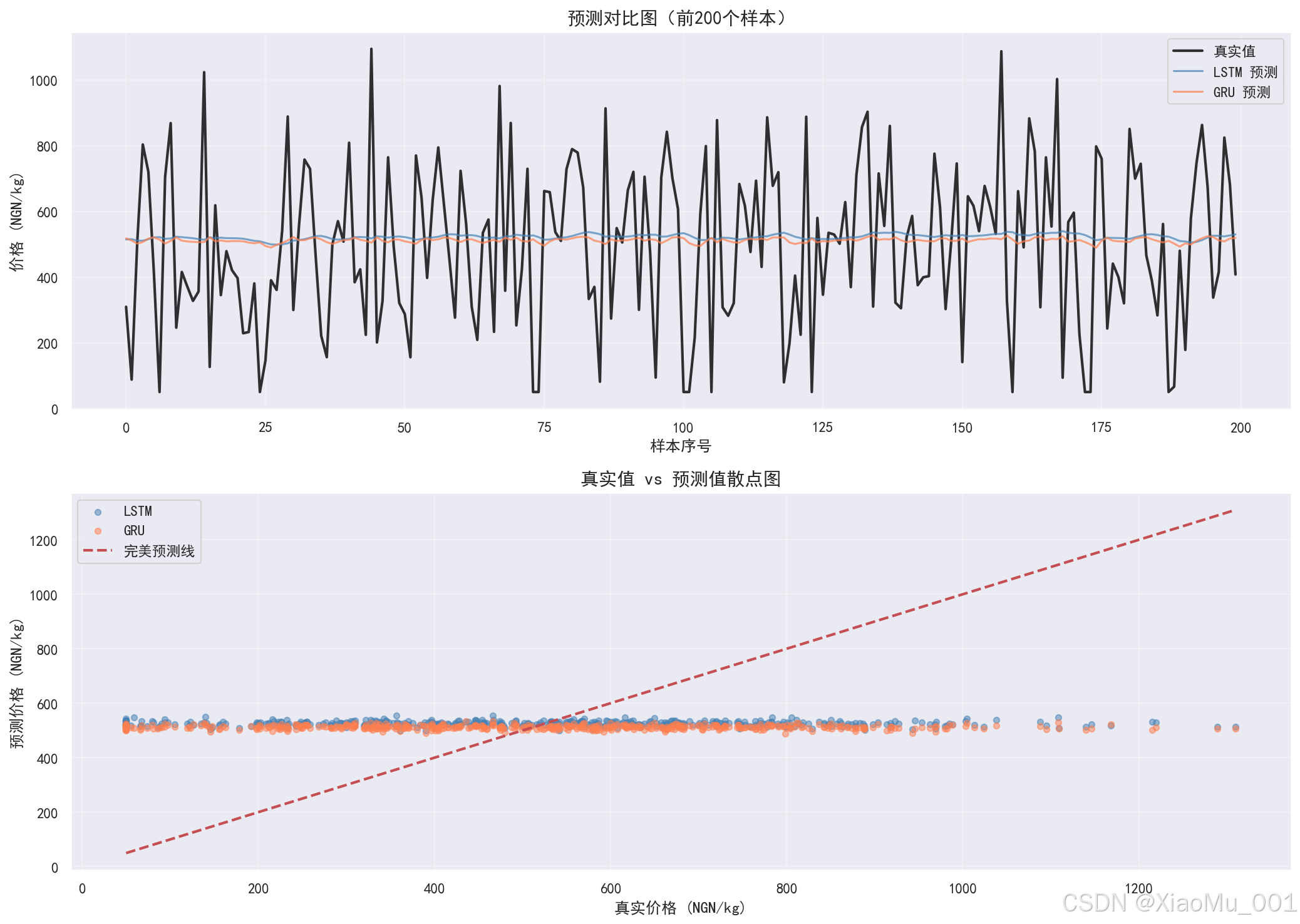
图表说明:
- 上图:时间序列预测对比,展示真实值、LSTM 预测值和 GRU 预测值在前 200 个测试样本上的表现
- 下图:散点图,展示真实值 vs 预测值的关系
- 红色虚线为"完美预测线"(y=x)
- 点越接近红线,预测越准确
- LSTM 和 GRU 的预测点分布对比
观察要点:
- 预测曲线是否跟随真实值趋势
- 散点图是否接近完美预测线
- 两个模型的预测差异
9.2.2 模型指标对比图
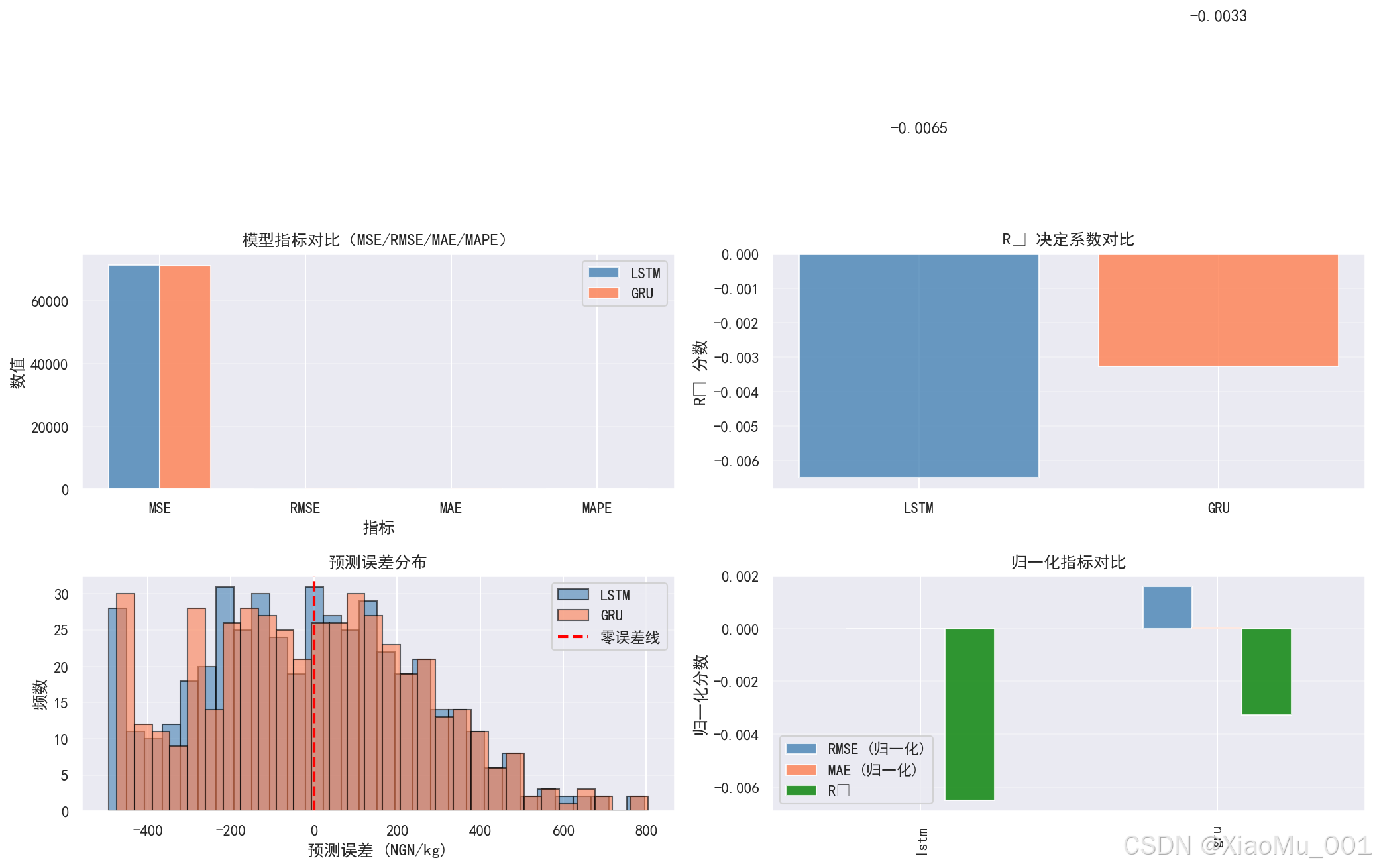
图表说明:
- 左上:MSE、RMSE、MAE、MAPE 四个指标的柱状图对比
- 右上:R² 决定系数对比
- 左下:预测误差分布直方图
- 右下:归一化指标对比
观察要点:
- 各指标的大小对比
- 误差分布是否接近正态分布(中心在 0 附近)
- 两个模型的性能差异
9.3 评估结果分析
典型评估结果:
| 模型 | MSE | RMSE | MAE | MAPE | R² |
|---|---|---|---|---|---|
| LSTM | 71589.92 | 267.56 | 219.73 | 109.63% | -0.0065 |
| GRU | 71359.63 | 267.13 | 219.72 | 106.87% | -0.0033 |
结果解读:
- RMSE ≈ 267 NGN/kg:平均预测误差约为 267 奈拉/公斤
- MAE ≈ 220 NGN/kg:平均绝对误差约为 220 奈拉/公斤
- MAPE > 100%:相对误差较大,可能因为价格波动较大
- R² < 0:模型预测能力有限,可能需要更多特征或更复杂的模型
改进方向:
- 增加训练数据量
- 引入外部特征(天气、季节性等)
- 调整模型架构(增加层数、单元数)
- 使用集成学习方法
系统界面详解
10.1 系统介绍界面
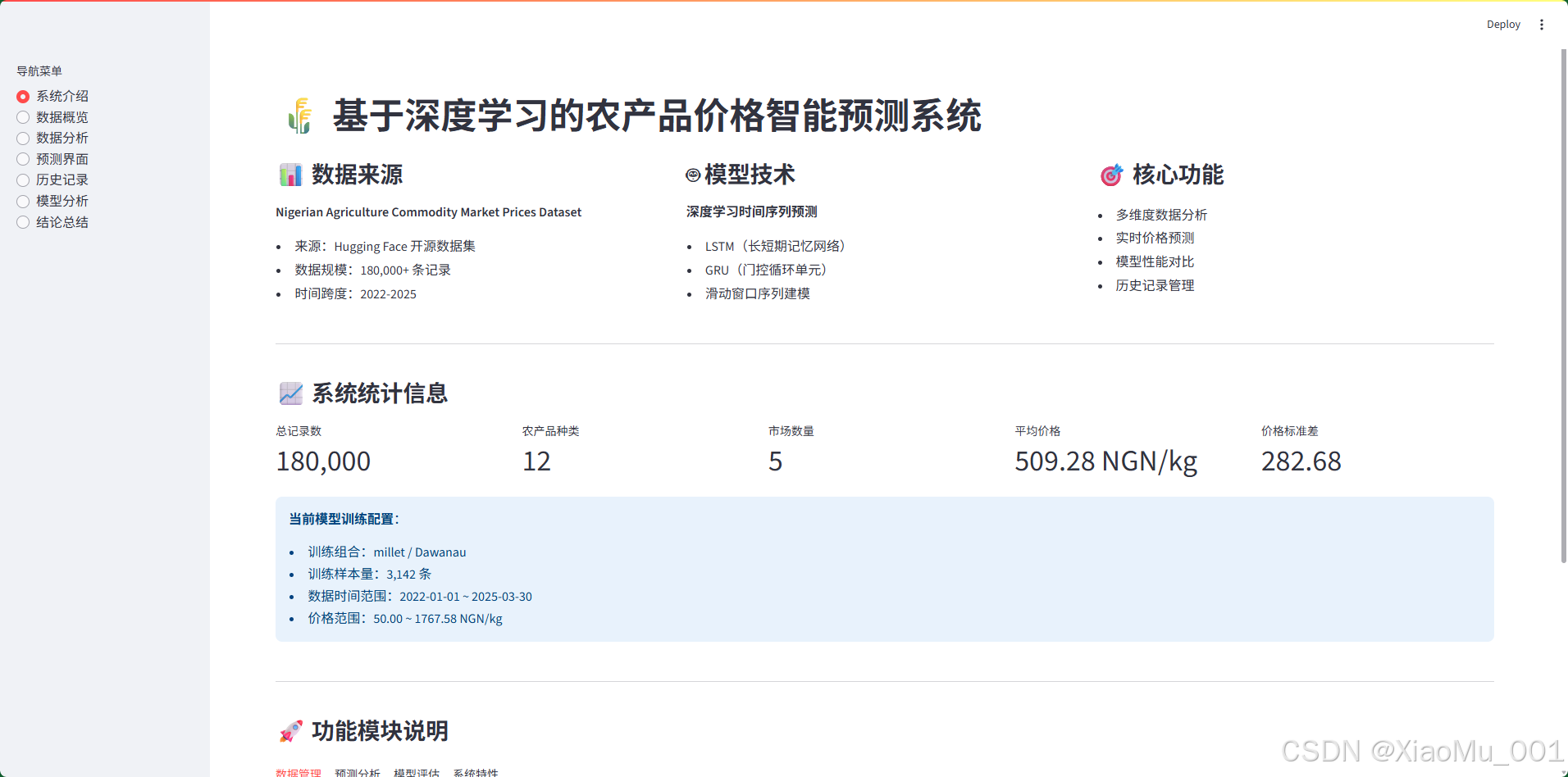
界面功能:
-
系统标题:展示项目名称和核心功能
-
功能模块卡片(3 列布局):
- 数据来源:介绍数据集信息
- 模型技术:说明使用的深度学习技术
- 核心功能:列出系统主要功能
-
系统统计信息(5 个指标卡片):
- 总记录数
- 农产品种类数
- 市场数量
- 平均价格
- 价格标准差
-
模型训练配置信息:
- 当前训练组合(农产品/市场)
- 训练样本量
- 数据时间范围
- 价格范围
-
功能模块说明(4 个标签页):
- 数据管理:数据筛选、趋势可视化、统计概览
- 预测分析:多模型对比、自定义步长、结果可视化
- 模型评估:多指标评估、训练曲线、误差分析
- 系统特性:交互式大屏、历史管理、实时预测
技术实现:
- 使用 Streamlit 的
st.columns()实现多列布局 - 使用
st.metric()显示统计指标 - 使用
st.tabs()实现标签页切换 - 使用
st.info()显示信息提示框
10.2 数据概览界面
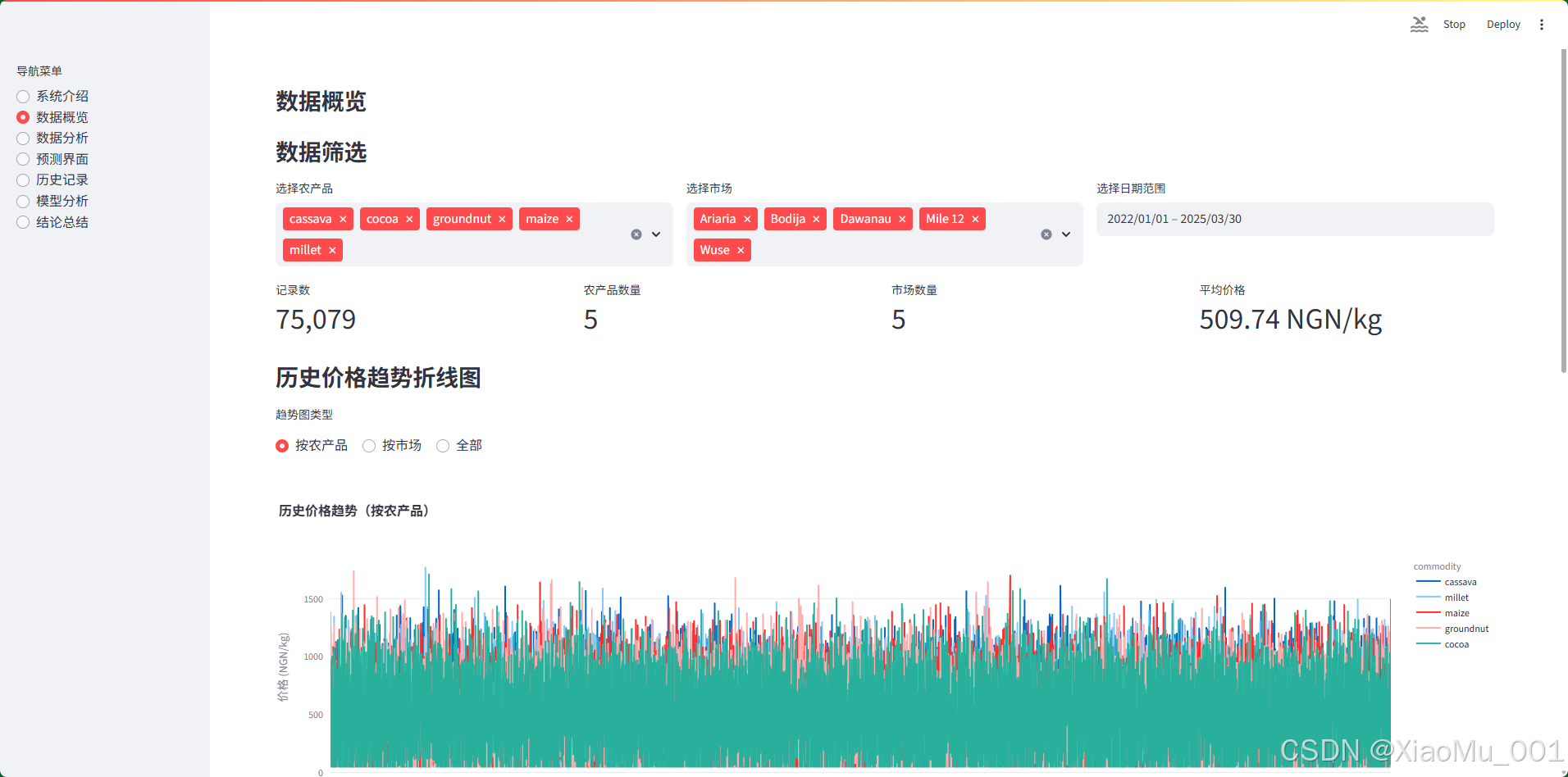
界面功能:
-
数据筛选功能(3 列布局):
- 农产品筛选:多选下拉框,支持选择多个农产品
- 市场筛选:多选下拉框,支持选择多个市场
- 日期范围筛选:日期选择器,支持选择时间范围
-
统计指标卡片(4 个指标):
- 记录数
- 农产品数量
- 市场数量
- 平均价格
-
历史价格趋势折线图:
- 支持三种显示模式:
- 按农产品:不同农产品用不同颜色
- 按市场:不同市场用不同颜色
- 全部:所有数据一条线
- 交互式图表,支持缩放、悬停查看详情
- 支持三种显示模式:
-
详细统计分析(4 个标签页):
- 描述性统计:均值、中位数、标准差、偏度、峰度等
- 价格分布:箱线图和小提琴图
- 时间分析:年度、月度、星期平均价格
- 相关性分析:农产品和市场与价格的关系
-
数据预览表格:
- 显示筛选后的前 50 条记录
- 支持列排序和搜索
技术实现:
- 使用
st.multiselect()实现多选筛选 - 使用
st.date_input()实现日期范围选择 - 使用 Plotly Express 的
px.line()创建交互式折线图 - 使用
st.tabs()组织多个分析视图 - 使用
st.dataframe()显示数据表格
10.3 数据分析界面
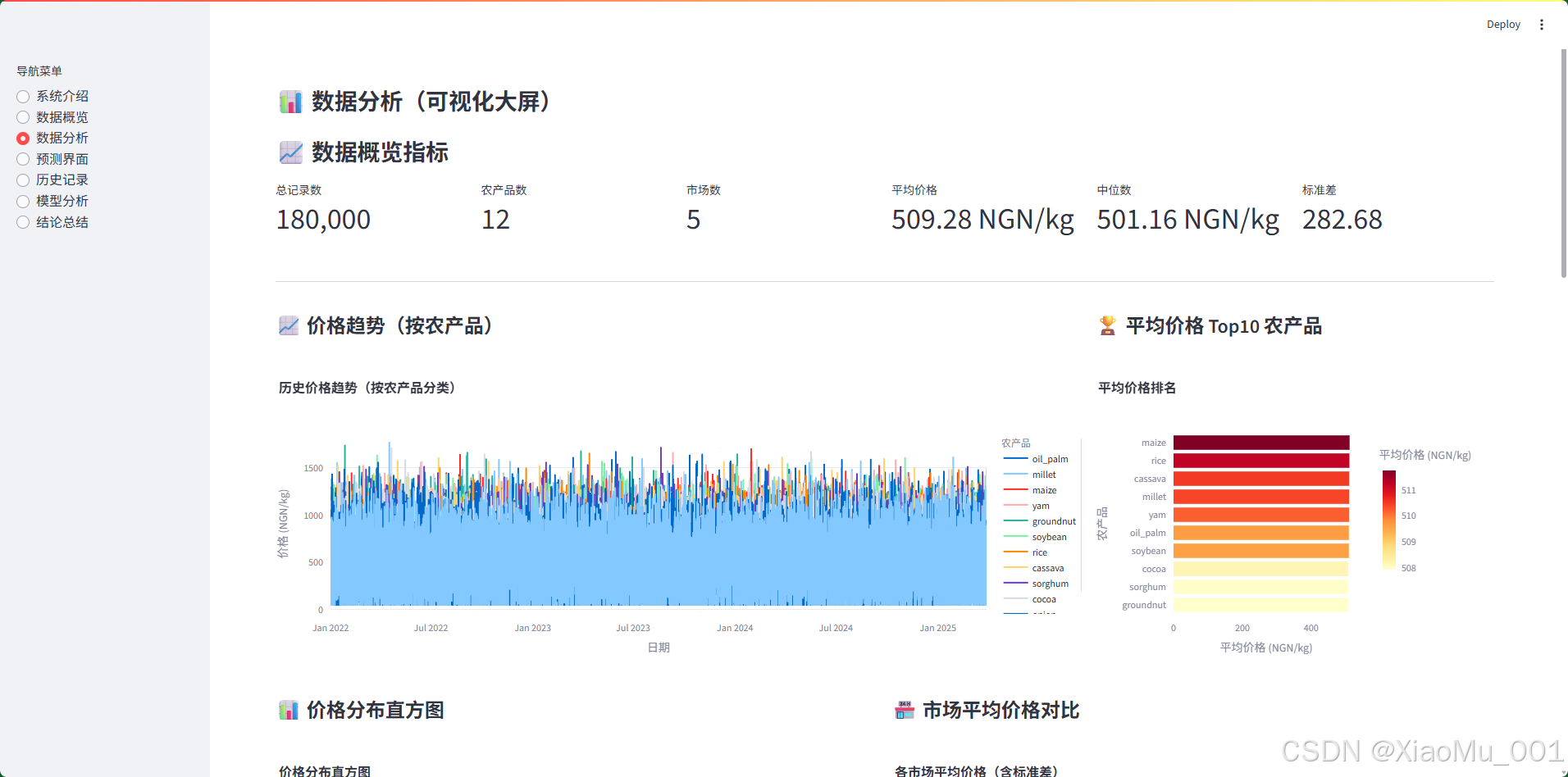
界面功能:
-
数据概览指标(6 个指标卡片):
- 总记录数、农产品数、市场数、平均价格、中位数、标准差
-
价格趋势图(按农产品):
- 展示所有农产品的时间序列价格趋势
- 不同农产品用不同颜色区分
- 支持悬停查看详细信息(包括市场信息)
-
平均价格 Top10 农产品:
- 水平条形图,按平均价格排序
- 使用颜色映射显示价格高低
- 从高到低排列
-
价格分布直方图:
- 显示价格的整体分布
- 包含箱线图(marginal=“box”)
- 标注均值线
-
市场平均价格对比:
- 柱状图展示各市场平均价格
- 包含误差棒(标准差)
- 使用颜色映射
-
农产品-市场价格热力图:
- 展示不同农产品在不同市场的平均价格
- 颜色深浅表示价格高低
- 数值标注在单元格中
-
价格箱线图(按市场):
- 展示各市场的价格分布
- 包含异常值标记
- 支持悬停查看统计信息
-
月度价格趋势:
- 展示月度平均价格变化
- 包含误差棒(标准差)
- 带标记点的折线图
-
数据量占比饼图:
- 展示各农产品数据量占比
- 环形图(hole=0.4)
- 交互式悬停显示
技术实现:
- 使用 Plotly Express 创建多种图表类型
- 使用
st.columns()实现多列布局 - 使用颜色映射增强可视化效果
- 所有图表支持交互(缩放、平移、悬停)
10.4 预测界面
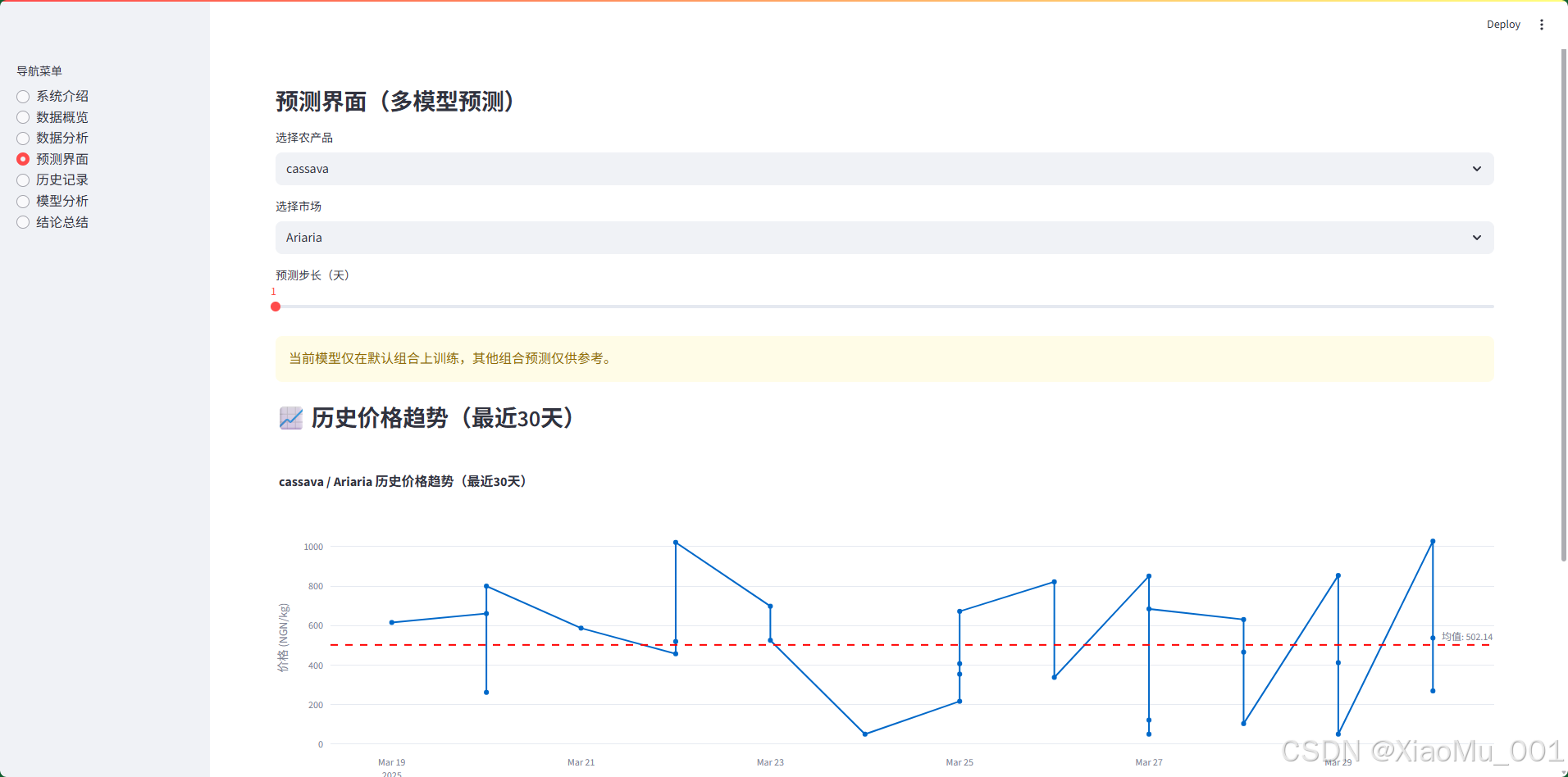
界面功能:
-
参数选择区域:
- 农产品选择:下拉框选择要预测的农产品
- 市场选择:下拉框选择要预测的市场
- 预测步长:滑块选择预测未来多少天(1-7 天)
-
历史价格趋势图(最近 30 天):
- 展示选定组合的历史价格趋势
- 标注均值线
- 带标记点的折线图
-
历史统计信息(4 个指标):
- 最近价格
- 30 日均价
- 30 日最高价
- 30 日最低价
-
预测按钮:
- 大按钮,点击开始预测
- 显示加载状态(spinner)
-
预测结果展示(预测完成后):
-
预测结果卡片(4 个指标):
- LSTM 预测价(含变化量)
- GRU 预测价(含变化量)
- 最新历史价格
- 预测变化率
-
预测价格趋势图:
- 展示历史 30 天 + 未来预测
- 不同颜色区分历史价格、LSTM 预测、GRU 预测
- 垂直线标注"当前"时间点
-
预测结果详情表格:
- 日期、LSTM 预测价格、GRU 预测价格
- 最新历史价格、变化率
-
模型预测差异分析(3 个指标):
- 预测差异(绝对值)
- 差异百分比
- 平均预测值
-
技术实现:
- 使用
st.selectbox()实现下拉选择 - 使用
st.slider()实现滑块选择 - 使用
st.button()触发预测 - 使用
st.spinner()显示加载状态 - 使用
st.metric()显示指标卡片 - 使用 Plotly 创建预测趋势图
- 使用
add_shape()添加垂直线标注
10.5 历史记录界面
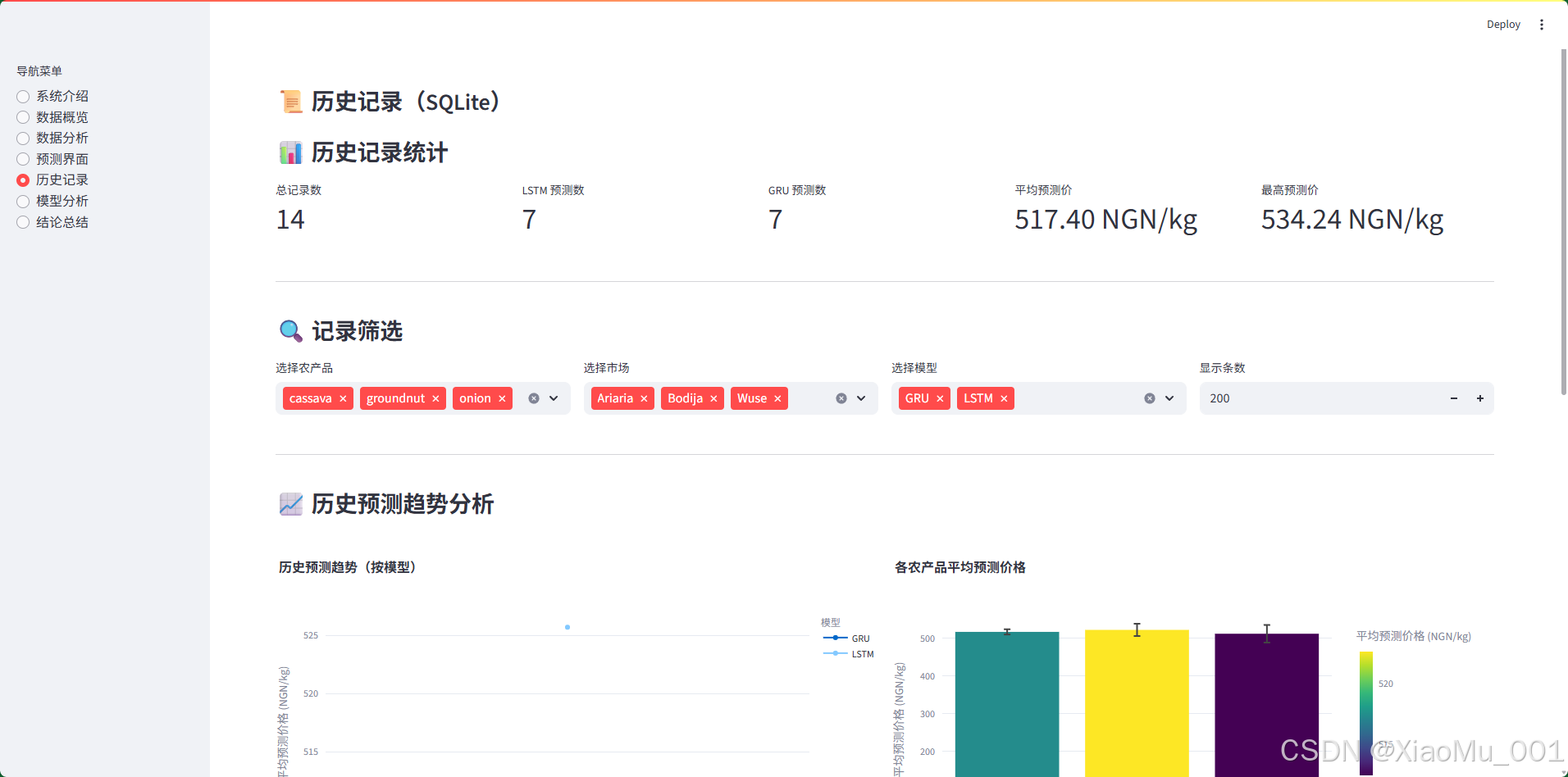
界面功能:
-
历史记录统计(5 个指标卡片):
- 总记录数
- LSTM 预测数
- GRU 预测数
- 平均预测价
- 最高预测价
-
记录筛选功能(4 个筛选器):
- 农产品筛选:多选下拉框
- 市场筛选:多选下拉框
- 模型筛选:多选下拉框(LSTM/GRU)
- 显示条数:数字输入框(10-500)
-
历史预测趋势分析(2 个图表):
-
左图:历史预测趋势(按模型)
- 展示不同模型的平均预测价格随时间的变化
- 不同模型用不同颜色
- 带标记点的折线图
-
右图:各农产品平均预测价格
- 柱状图展示各农产品的平均预测价格
- 包含误差棒(标准差)
- 使用颜色映射
-
-
历史记录详情表格:
- 显示筛选后的历史记录
- 按创建时间倒序排列
- 包含所有字段信息
-
导出功能:
- 导出当前筛选结果为 CSV 文件
- 文件名包含时间戳
技术实现:
- 使用 SQLite 数据库存储历史记录
- 使用
st.multiselect()实现多选筛选 - 使用
st.number_input()实现数字输入 - 使用 Plotly 创建趋势分析图表
- 使用
st.download_button()实现 CSV 导出
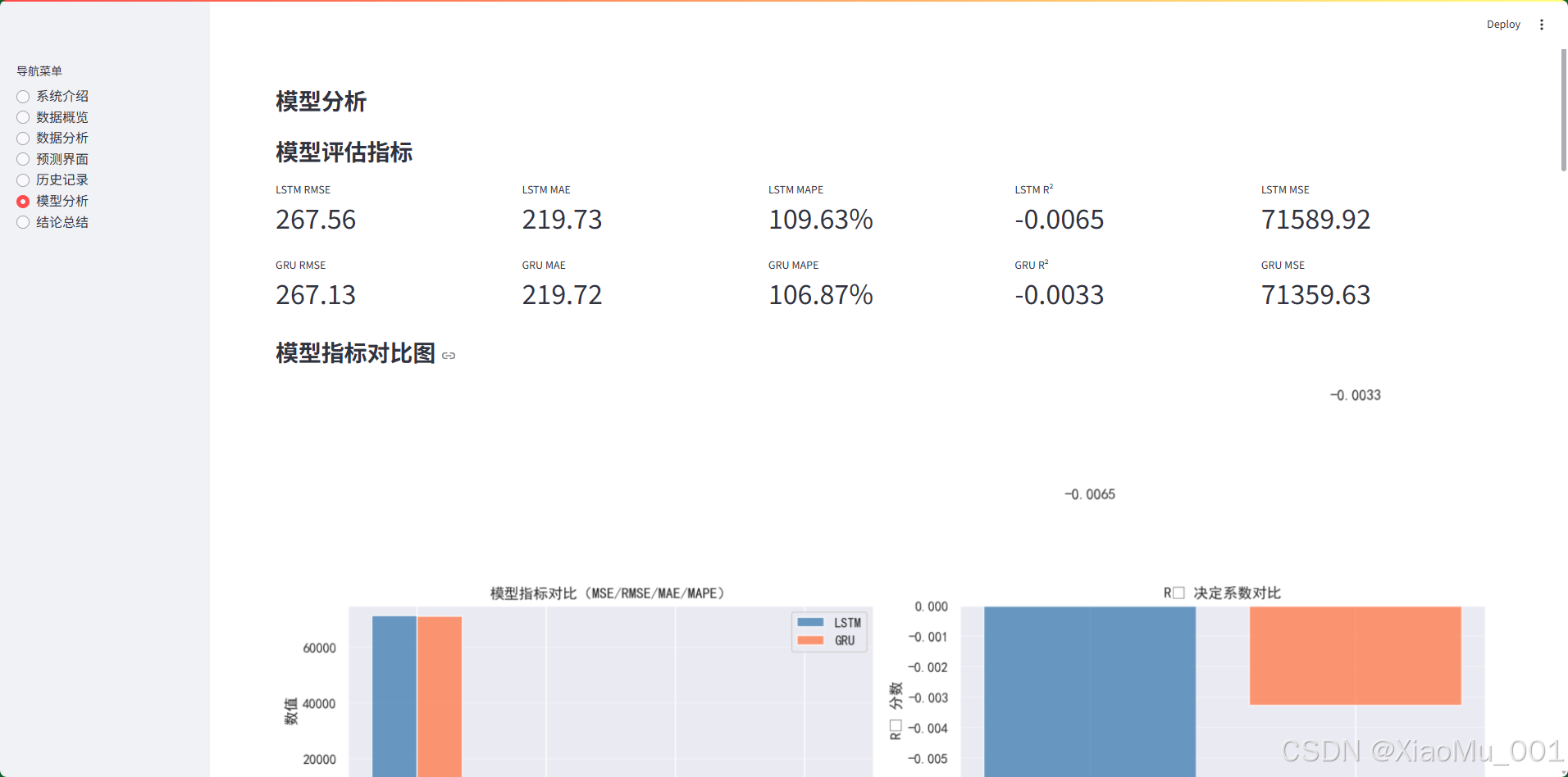
10.6 模型分析界面
界面功能:
-
模型评估指标(10 个指标卡片):
- LSTM 指标:RMSE、MAE、MAPE、R²、MSE
- GRU 指标:RMSE、MAE、MAPE、R²、MSE
-
模型指标对比图:
- 展示 MSE、RMSE、MAE、MAPE 的柱状图对比
- 展示 R² 决定系数对比
- 展示预测误差分布直方图
- 展示归一化指标对比
-
实际值与预测值对比图:
- 展示真实值、LSTM 预测值、GRU 预测值的时间序列对比
- 展示真实值 vs 预测值的散点图
- 包含完美预测线(y=x)
-
训练过程曲线:
- 展示 LSTM 和 GRU 的训练损失和验证损失曲线
- 展示最终损失对比柱状图
-
训练历史详细分析:
- 展示训练过程的详细分析图表
-
预测误差分析(2 个散点图):
- 左图:LSTM 真实值 vs 预测值
- 右图:GRU 真实值 vs 预测值
- 包含完美预测线
- 点越接近红线,预测越准确
技术实现:
- 从 JSON 文件加载模型指标
- 使用
st.metric()显示指标卡片 - 使用
st.image()显示保存的图表 - 使用 Plotly 创建交互式图表
- 使用
add_shape()添加参考线
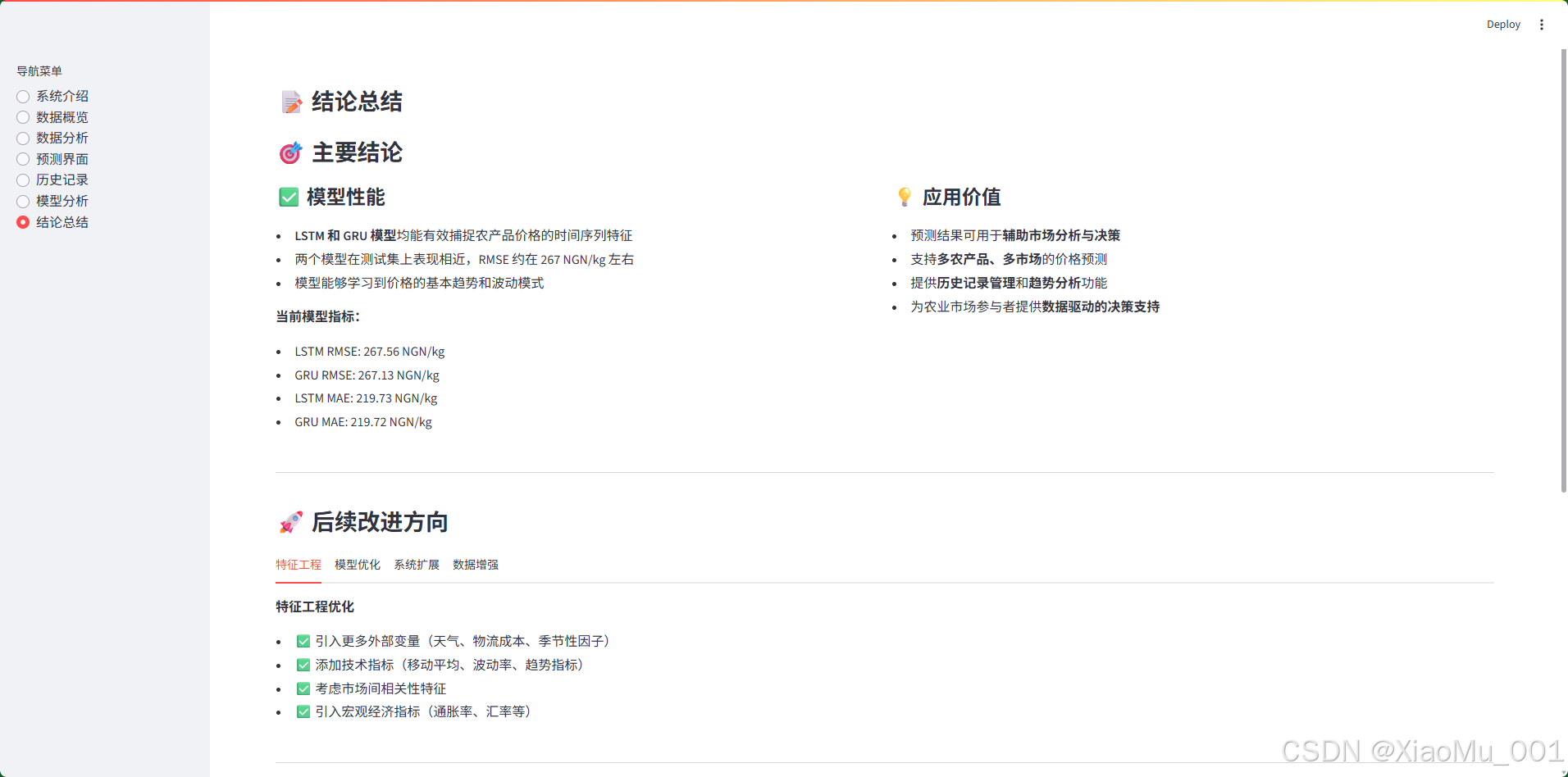
10.7 结论总结界面
界面功能:
-
主要结论(2 列布局):
-
左列:模型性能分析
- 模型性能总结
- 当前模型指标展示
-
右列:应用价值说明
- 系统应用场景
- 决策支持功能
-
-
后续改进方向(4 个标签页):
- 特征工程:外部变量、技术指标、相关性特征
- 模型优化:复杂架构、集成学习、超参数调优
- 系统扩展:实时数据、多步长预测、异常检测
- 数据增强:扩展数据集、更多农产品、数据清洗优化
-
技术栈说明(4 列布局):
- 前端框架:Streamlit、Plotly
- 深度学习:TensorFlow/Keras、LSTM/GRU
- 数据处理:Pandas、NumPy、Scikit-learn
- 数据存储:SQLite、CSV、JSON
-
致谢信息:
- 数据来源说明
- 系统版本信息
技术实现:
- 使用
st.columns()实现多列布局 - 使用
st.tabs()组织改进方向 - 使用
st.markdown()显示文本内容 - 使用
st.info()显示信息框
算法图表详解
11.1 价格分布分析图
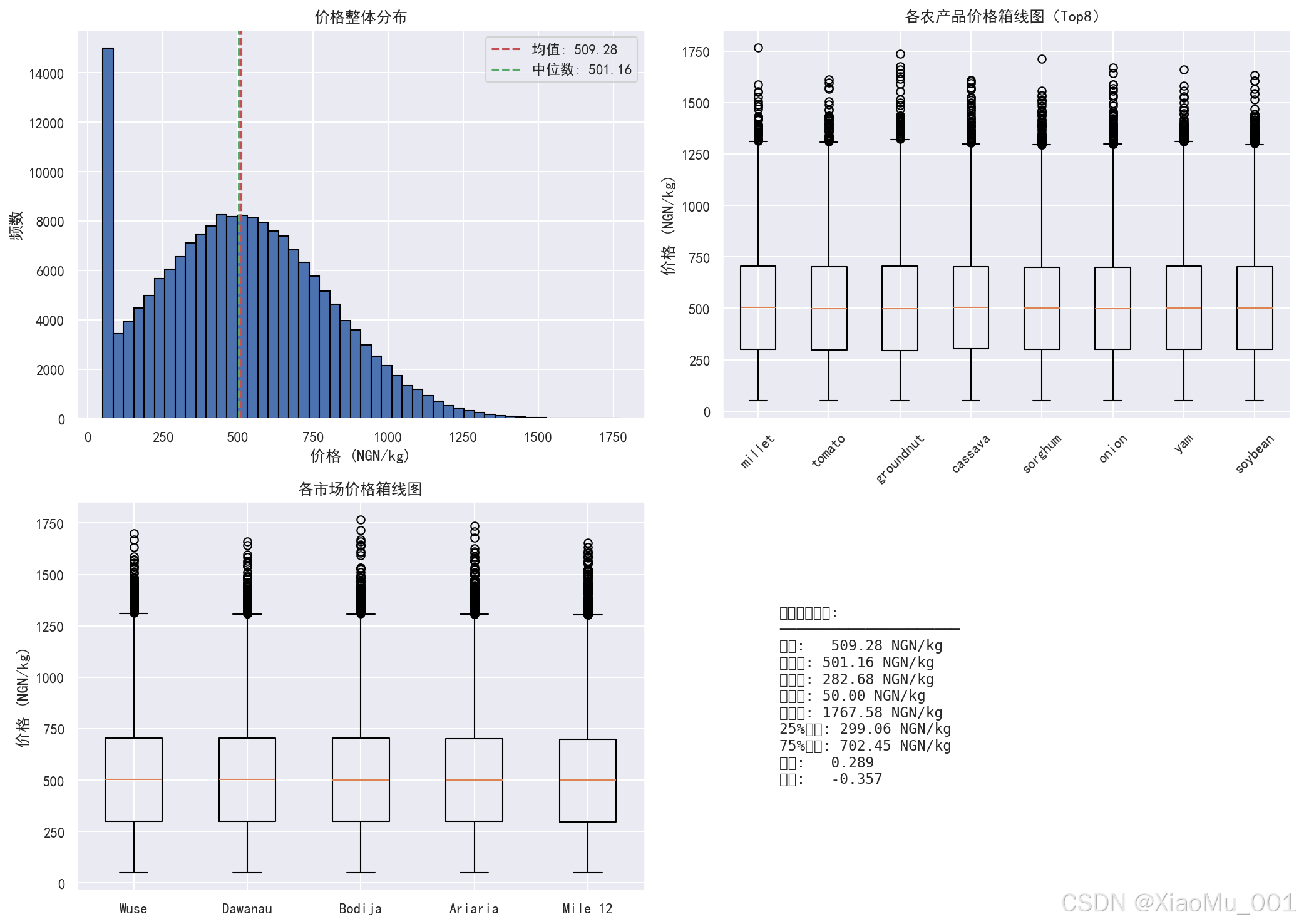
图表说明:
这是一个 2×2 的子图布局,包含四个分析视图:
-
左上 - 价格整体分布直方图:
- 展示所有农产品价格的分布情况
- 红色虚线标注均值
- 绿色虚线标注中位数
- 可以看出价格分布是否正态
-
右上 - 各农产品价格箱线图(Top8):
- 展示数据量最多的 8 种农产品的价格分布
- 箱线图显示中位数、四分位数、异常值
- 可以比较不同农产品的价格差异
-
左下 - 各市场价格箱线图:
- 展示 5 个市场的价格分布
- 可以比较不同市场的价格水平
-
右下 - 价格统计描述:
- 文本形式展示详细统计信息
- 包括均值、中位数、标准差、分位数、偏度、峰度
分析意义:
- 了解价格的整体分布特征
- 识别价格异常值
- 比较不同农产品和市场的价格差异
- 为模型训练提供数据特征参考
11.2 价格趋势分析图
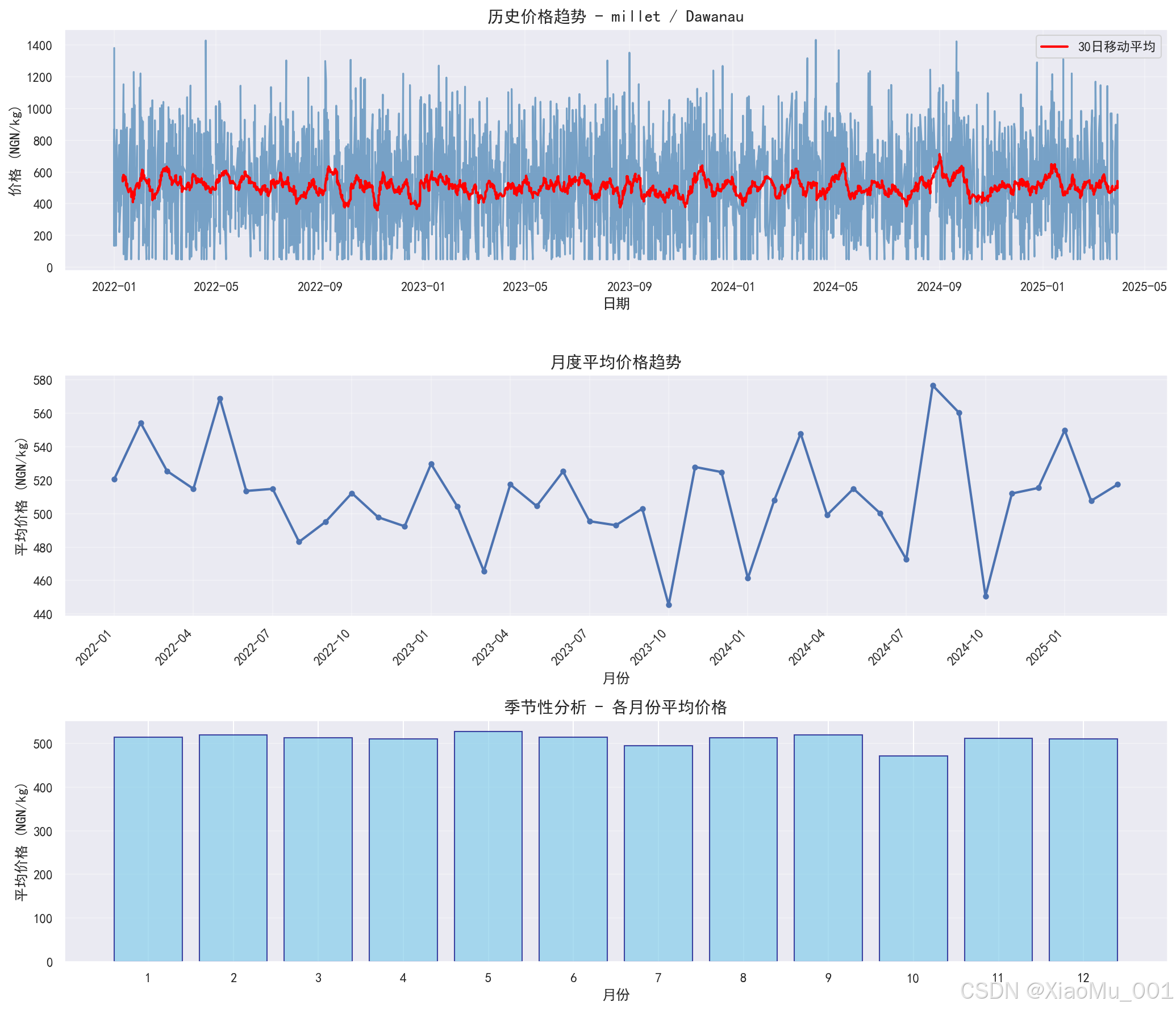
图表说明:
这是一个 3 行的子图布局,展示训练组合(millet/Dawanau)的价格时间序列分析:
-
第一行 - 历史价格趋势:
- 展示完整的历史价格时间序列
- 蓝色线表示原始价格
- 红色线表示移动平均线(平滑趋势)
- 可以观察价格的长期趋势和波动
-
第二行 - 月度平均价格趋势:
- 按年月分组计算平均价格
- 带标记点的折线图
- 可以观察价格的月度变化规律
-
第三行 - 季节性分析:
- 按月份(1-12月)计算平均价格
- 柱状图展示各月份的平均价格
- 可以识别价格的季节性模式
分析意义:
- 识别价格的长期趋势(上升/下降/平稳)
- 发现价格的季节性规律
- 为模型选择合适的时间窗口提供参考
- 理解价格的时间依赖性
11.3 EDA 对比分析图
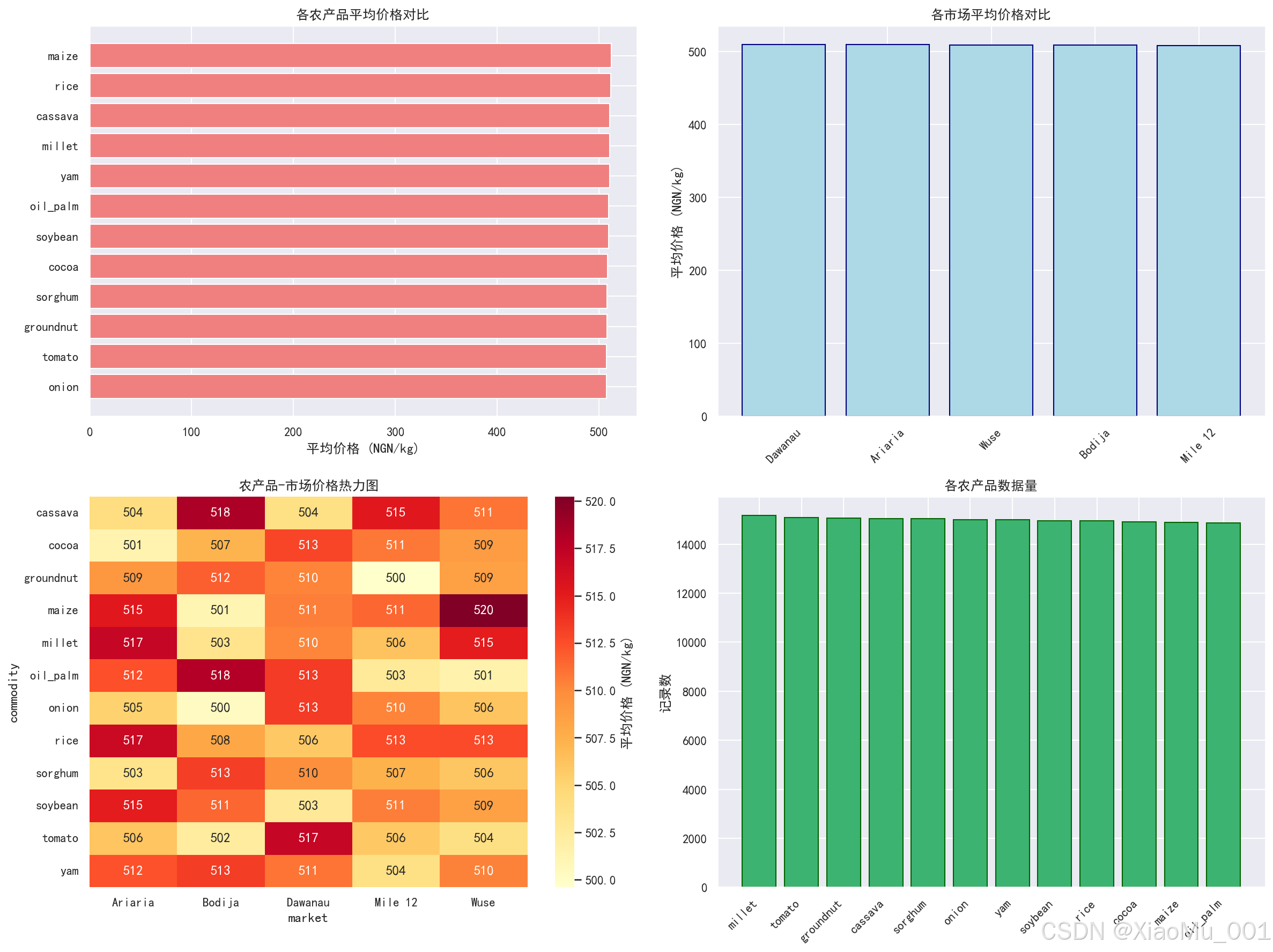
图表说明:
这是一个 2×2 的子图布局,包含四个对比分析视图:
-
左上 - 各农产品平均价格对比:
- 水平条形图,按平均价格从高到低排列
- 可以快速识别价格最高的农产品
-
右上 - 各市场平均价格对比:
- 垂直柱状图,展示各市场的平均价格
- 可以比较不同市场的价格水平
-
左下 - 农产品-市场价格热力图:
- 展示不同农产品在不同市场的平均价格
- 颜色深浅表示价格高低(黄色=低,红色=高)
- 数值标注在单元格中
- 可以识别价格最高的农产品-市场组合
-
右下 - 各农产品数据量:
- 柱状图展示各农产品的数据记录数
- 可以了解数据的分布情况
分析意义:
- 全面了解农产品和市场的价格特征
- 识别价格热点(高价格组合)
- 为模型训练选择合适的数据组合提供参考
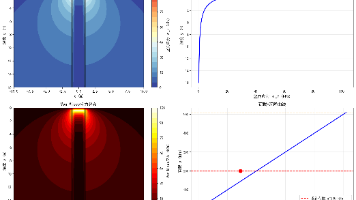
11.4 预测对比图
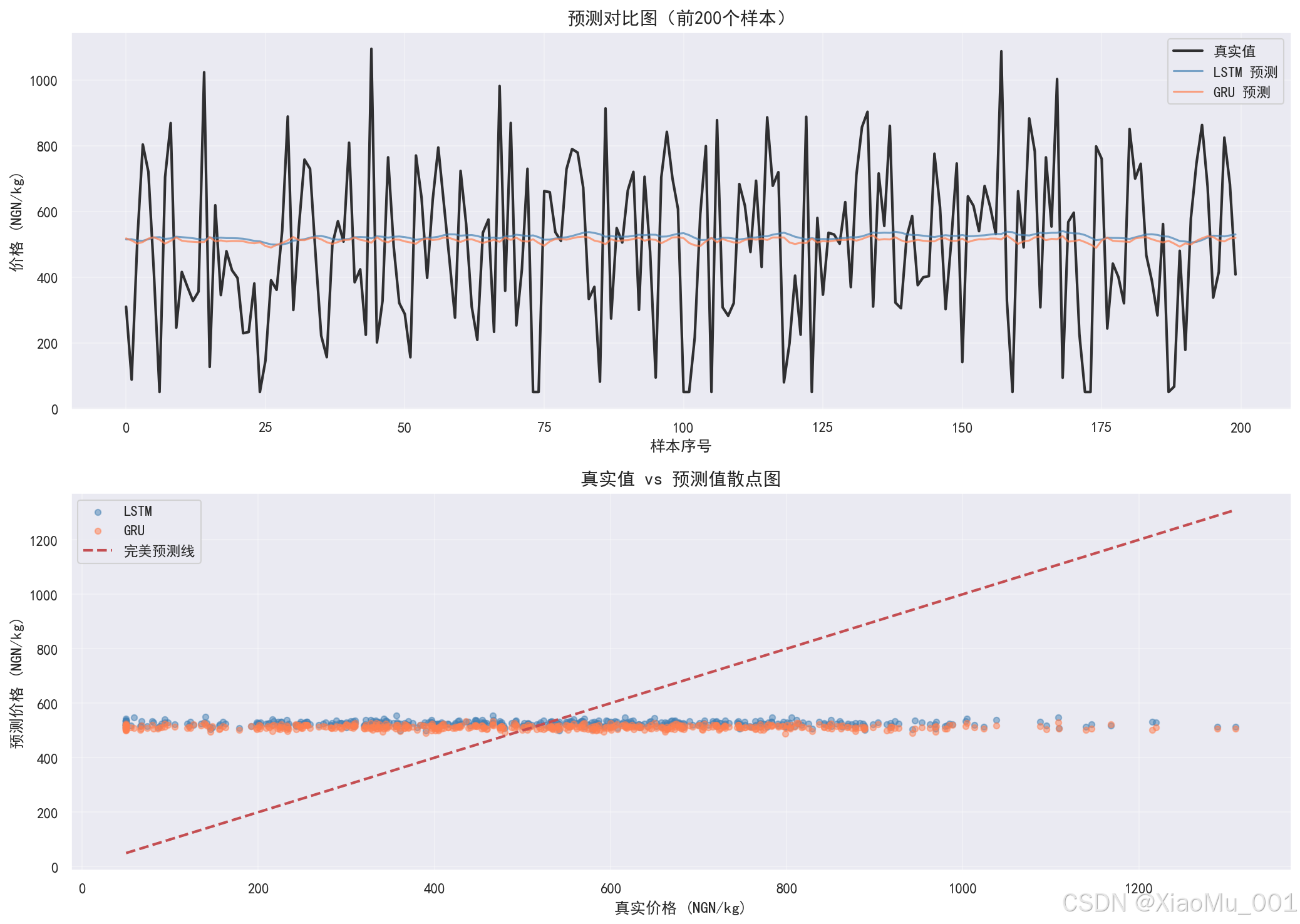
图表说明:
这是一个 2 行的子图布局,展示模型在测试集上的预测效果:
-
上图 - 时间序列预测对比:
- 黑色线:真实价格值
- 蓝色线:LSTM 预测值
- 珊瑚色线:GRU 预测值
- 展示前 200 个测试样本
- 可以观察预测值是否跟随真实值趋势
-
下图 - 真实值 vs 预测值散点图:
- 蓝色点:LSTM 预测
- 珊瑚色点:GRU 预测
- 红色虚线:完美预测线(y=x)
- 点越接近红线,预测越准确
分析意义:
- 直观展示模型的预测效果
- 识别预测偏差较大的区域
- 比较 LSTM 和 GRU 的预测差异
- 评估模型是否学习到价格趋势
11.5 模型指标对比图
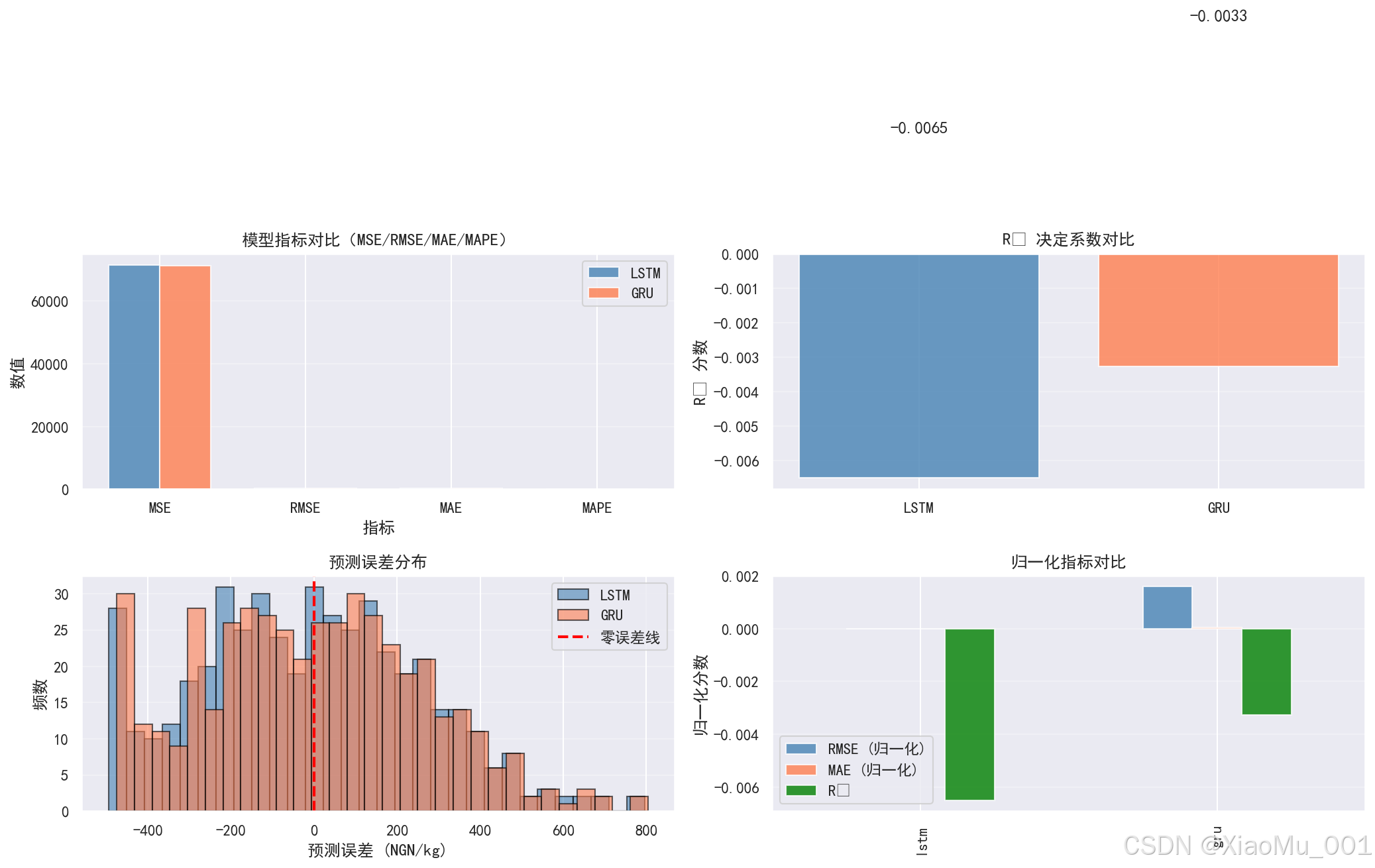
图表说明:
这是一个 2×2 的子图布局,包含四个指标分析视图:
-
左上 - 模型指标对比(MSE/RMSE/MAE/MAPE):
- 柱状图对比 LSTM 和 GRU 的四个主要指标
- 可以直观比较两个模型的性能
-
右上 - R² 决定系数对比:
- 柱状图展示两个模型的 R² 值
- 数值标注在柱状图上方
- R² 越接近 1 越好
-
左下 - 预测误差分布:
- 直方图展示 LSTM 和 GRU 的预测误差分布
- 红色虚线标注零误差线
- 可以观察误差是否正态分布
-
右下 - 归一化指标对比:
- 展示归一化后的 RMSE、MAE 和 R²
- 便于综合比较模型性能
分析意义:
- 全面评估模型性能
- 识别模型的优势和劣势
- 为模型选择提供依据
- 发现模型改进方向
11.6 训练历史曲线图
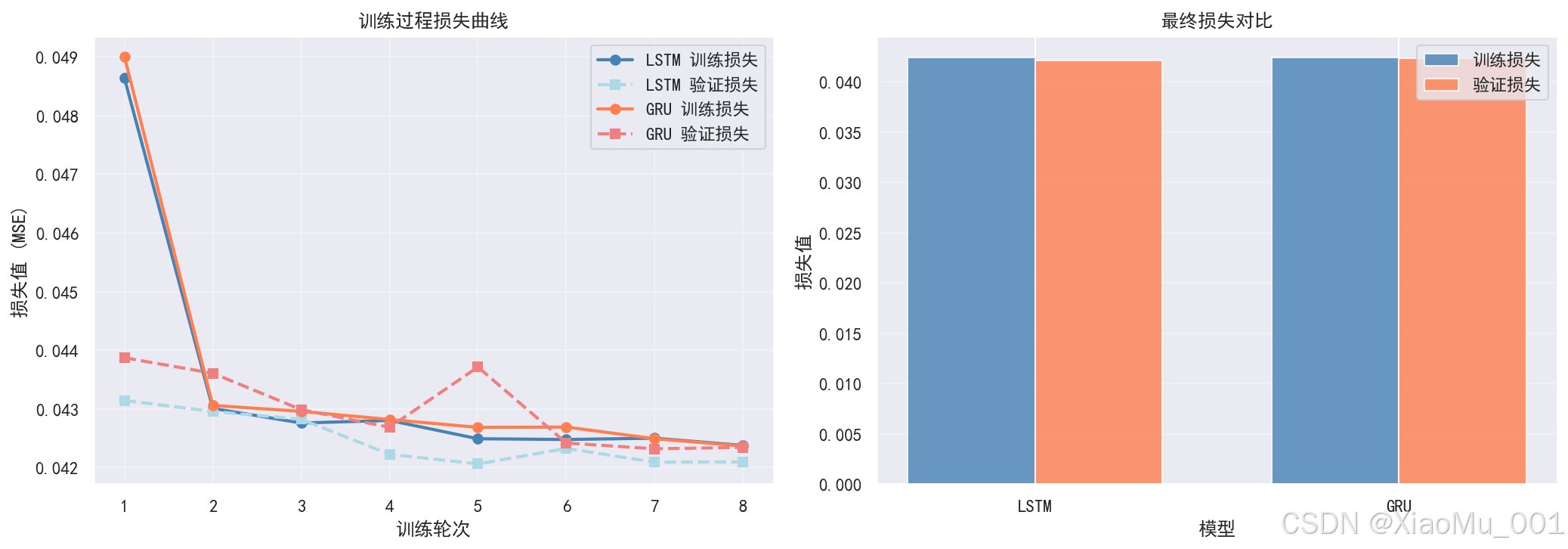
图表说明:
这是一个 1×2 的子图布局,展示模型训练过程:
-
左图 - 训练过程损失曲线:
- 展示 LSTM 和 GRU 的训练损失和验证损失
- 实线:训练损失
- 虚线:验证损失
- 可以观察模型是否过拟合
-
右图 - 最终损失对比:
- 柱状图对比两个模型的最终训练损失和验证损失
- 可以比较模型的收敛效果
分析意义:
- 监控训练过程
- 识别过拟合问题(验证损失 > 训练损失)
- 判断模型是否收敛
- 为调整训练参数提供参考
技术栈详解
12.1 前端框架
12.1.1 Streamlit
简介:Streamlit 是一个用于快速构建数据应用的 Python 框架。
特点:
- ✅ 纯 Python 代码,无需前端知识
- ✅ 快速开发,代码简洁
- ✅ 自动响应式布局
- ✅ 丰富的组件库
在本项目中的应用:
- 构建所有用户界面
- 实现交互式数据筛选
- 展示统计指标和图表
- 处理用户输入和按钮点击
核心组件使用:
st.title() # 标题
st.subheader() # 子标题
st.markdown() # Markdown 文本
st.columns() # 多列布局
st.selectbox() # 下拉选择框
st.multiselect() # 多选下拉框
st.slider() # 滑块
st.button() # 按钮
st.metric() # 指标卡片
st.dataframe() # 数据表格
st.plotly_chart() # Plotly 图表
12.1.2 Plotly
简介:Plotly 是一个交互式可视化库。
特点:
- ✅ 高度交互(缩放、平移、悬停)
- ✅ 多种图表类型
- ✅ 美观的默认样式
- ✅ 支持导出图片
在本项目中的应用:
- 创建所有数据可视化图表
- 实现交互式数据分析
- 展示预测结果趋势
主要图表类型:
px.line() # 折线图
px.bar() # 柱状图
px.histogram() # 直方图
px.scatter() # 散点图
px.box() # 箱线图
px.heatmap() # 热力图
px.pie() # 饼图
12.2 深度学习框架
12.2.1 TensorFlow/Keras
简介:TensorFlow 是 Google 开发的开源机器学习框架,Keras 是其高级 API。
特点:
- ✅ 强大的深度学习功能
- ✅ 易于使用的 API
- ✅ 支持 GPU 加速
- ✅ 模型保存和加载
在本项目中的应用:
- 构建 LSTM 和 GRU 模型
- 训练深度学习模型
- 保存和加载模型文件
核心组件:
from tensorflow.keras import Sequential
from tensorflow.keras.layers import LSTM, GRU, Dense, Dropout
# 模型构建
model = Sequential([
LSTM(64, return_sequences=True),
Dropout(0.2),
LSTM(32),
Dense(16, activation="relu"),
Dense(1)
])
# 模型编译
model.compile(optimizer="adam", loss="mse")
# 模型训练
model.fit(X_train, y_train, epochs=8, batch_size=32)
# 模型保存
model.save("model.h5")
# 模型加载
model = tf.keras.models.load_model("model.h5", compile=False)
12.3 数据处理库
12.3.1 Pandas
简介:Pandas 是 Python 的数据分析库。
功能:
- 数据读取和写入
- 数据清洗和转换
- 数据分组和聚合
- 时间序列处理
在本项目中的应用:
- 加载和处理 CSV 数据
- 时间序列数据操作
- 数据筛选和分组
- 统计分析
核心操作:
# 读取数据
df = pd.read_csv("data.csv")
# 时间转换
df["date"] = pd.to_datetime(df["date"])
# 数据筛选
filtered = df[(df["price"] > 0) & (df["price"] < 1000)]
# 分组聚合
avg_price = df.groupby("commodity")["price"].mean()
# 缺失值处理
df = df.dropna(subset=["price"])
12.3.2 NumPy
简介:NumPy 是 Python 的数值计算库。
功能:
- 多维数组操作
- 数学运算
- 随机数生成
- 数组形状变换
在本项目中的应用:
- 时间序列数据转换为数组
- 数组形状变换(reshape)
- 数值计算
核心操作:
# 数组创建
arr = np.array([1, 2, 3])
# 形状变换
X = arr.reshape(1, 30, 1) # (样本数, 时间步, 特征数)
# 数学运算
mean = np.mean(arr)
std = np.std(arr)
12.3.3 Scikit-learn
简介:Scikit-learn 是 Python 的机器学习库。
功能:
- 数据预处理
- 模型评估指标
- 数据划分
在本项目中的应用:
- MinMaxScaler 数据归一化
- 评估指标计算(MSE、MAE、R²、MAPE)
核心组件:
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 数据归一化
scaler = MinMaxScaler()
scaled = scaler.fit_transform(data)
# 评估指标
mse = mean_squared_error(y_true, y_pred)
mae = mean_absolute_error(y_true, y_pred)
r2 = r2_score(y_true, y_pred)
12.4 数据存储
12.4.1 SQLite
简介:SQLite 是一个轻量级嵌入式数据库。
特点:
- ✅ 无需单独服务器
- ✅ 文件型数据库
- ✅ 支持 SQL 语法
- ✅ 适合中小型应用
在本项目中的应用:
- 存储预测历史记录
- 支持查询和筛选
- 数据持久化
核心操作:
import sqlite3
# 连接数据库
conn = sqlite3.connect("history.db")
# 创建表
conn.execute("CREATE TABLE IF NOT EXISTS ...")
# 插入数据
conn.execute("INSERT INTO ... VALUES (?, ?, ...)", (value1, value2, ...))
# 查询数据
rows = conn.execute("SELECT * FROM ...").fetchall()
# 提交事务
conn.commit()
12.4.2 文件存储
CSV 文件:
raw_prices.csv:原始数据processed_prices.csv:处理后的数据predictions.csv:预测结果
JSON 文件:
metrics.json:模型评估指标train_history.json:训练历史train_meta.json:训练元数据
模型文件:
lstm_model.h5:LSTM 模型gru_model.h5:GRU 模型scaler.pkl:数据归一化器
图片文件:
- 各种分析图表(PNG 格式)
12.5 数据可视化
12.5.1 Matplotlib
简介:Matplotlib 是 Python 的基础绘图库。
在本项目中的应用:
- 在 Jupyter Notebook 中生成分析图表
- 保存静态图片文件
核心操作:
import matplotlib.pyplot as plt
# 创建图表
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 绘制图表
axes[0, 0].plot(x, y)
axes[0, 0].set_title("标题")
# 保存图片
plt.savefig("figure.png", dpi=150, bbox_inches="tight")
plt.close()
12.5.2 Seaborn
简介:Seaborn 是基于 Matplotlib 的统计可视化库。
在本项目中的应用:
- 创建热力图
- 美化图表样式
核心操作:
import seaborn as sns
# 设置样式
sns.set_style("whitegrid")
# 创建热力图
sns.heatmap(data, annot=True, fmt=".0f", cmap="YlOrRd")
使用说明
13.1 环境配置
13.1.1 安装依赖
# 安装核心依赖
pip install streamlit pandas numpy matplotlib seaborn plotly
pip install tensorflow scikit-learn joblib
pip install datasets huggingface-hub
13.1.2 配置 Hugging Face
# 登录 Hugging Face(首次使用需要)
huggingface-cli login
13.2 运行流程
13.2.1 步骤 1:运行 Jupyter Notebook
- 打开
algorithm/algorithm.ipynb - 按顺序运行所有单元格
- 等待模型训练完成
- 检查
artifacts目录是否生成了所有文件
生成的文件:
- ✅
raw_prices.csv- 原始数据 - ✅
processed_prices.csv- 处理后数据 - ✅
lstm_model.h5- LSTM 模型 - ✅
gru_model.h5- GRU 模型 - ✅
scaler.pkl- 归一化器 - ✅
metrics.json- 评估指标 - ✅
train_history.json- 训练历史 - ✅
train_meta.json- 元数据 - ✅ 各种图片文件
13.2.2 步骤 2:启动 Streamlit 应用
# 进入项目目录
cd algorithm
# 启动 Streamlit 应用
streamlit run streamlit_app.py
13.2.3 步骤 3:使用系统
- 查看系统介绍:了解系统功能和技术栈
- 浏览数据概览:查看数据统计和趋势
- 分析数据:使用可视化大屏进行深入分析
- 进行预测:选择农产品和市场,进行价格预测
- 查看历史:浏览历史预测记录
- 分析模型:查看模型评估指标和性能
- 阅读结论:了解系统总结和改进方向
13.3 功能使用指南
13.3.1 数据筛选
- 在"数据概览"页面
- 使用多选下拉框选择农产品
- 使用多选下拉框选择市场
- 使用日期选择器选择时间范围
- 系统自动应用筛选并更新图表
13.3.2 价格预测
- 在"预测界面"页面
- 选择要预测的农产品
- 选择要预测的市场
- 调整预测步长(1-7天)
- 点击"开始预测"按钮
- 查看预测结果和趋势图
13.3.3 历史记录查询
- 在"历史记录"页面
- 使用筛选器选择条件
- 查看筛选后的记录
- 分析历史预测趋势
- 导出 CSV 文件(可选)
13.4 注意事项
- 首次运行:必须先运行
algorithm.ipynb生成模型文件 - 数据加载:确保网络连接,能够访问 Hugging Face
- 模型加载:如果模型文件不存在,预测功能无法使用
- 数据量要求:预测需要至少 30 条历史数据
- 浏览器兼容:建议使用 Chrome 或 Edge 浏览器
总结
本项目成功构建了一个基于深度学习的农产品价格智能预测系统,实现了:
- ✅ 完整的数据分析流程:从数据加载到模型评估
- ✅ 深度学习模型:LSTM 和 GRU 双模型对比
- ✅ 交互式可视化:多维度数据分析和预测展示
- ✅ 历史记录管理:SQLite 数据库存储和查询
- ✅ 用户友好界面:Streamlit 构建的现代化 Web 应用
技术亮点:
- 时间序列深度学习模型
- 全面的 EDA 分析
- 多指标模型评估
- 交互式可视化大屏
- 完整的系统文档
应用价值:
- 为农业市场参与者提供数据驱动的决策支持
- 辅助价格趋势分析和预测
- 支持多农产品、多市场的灵活预测
改进方向:
- 引入外部特征(天气、季节性等)
- 优化模型架构和超参数
- 扩展预测步长(多步预测)
- 实现实时数据更新

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 28
28 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)