博物馆陶器展品识别系统
博物馆陶器展品识别系统
目录
项目概述
1.1 项目背景
博物馆陶器展品识别系统是一个基于深度学习的图像分类应用,旨在通过计算机视觉技术自动识别和分类博物馆中的陶器展品。该系统采用最新的YOLOv8分类模型,能够准确识别5种不同类型的陶器:碗(bowl)、杯(cup)、花瓶(vase)、酒杯(wine glass)以及未分类项(fallback)。
1.2 项目目标
- 自动化识别:实现陶器图像的自动分类识别
- 高准确率:通过深度学习模型达到89%以上的识别准确率
- 用户友好:提供直观的Web界面,支持图像上传和实时识别
- 数据管理:记录和管理所有识别历史,支持数据导出和分析
1.3 应用场景
- 博物馆数字化管理
- 文物自动分类归档
- 展品信息管理系统
- 文物研究和教育
数据集介绍
2.1 数据集来源
本项目使用 Chinese Porcelain Vessels Dataset,该数据集由 Mary Zhang 在 Hugging Face 平台上发布。
- 数据集名称:maryzhang/vessels-motifs-dataset
- 数据集大小:628 MB
- 样本数量:564 张图像
- 数据格式:Parquet格式,包含图像和标注信息
2.2 数据集结构
数据集包含以下字段:
| 字段名 | 类型 | 说明 |
|---|---|---|
| original | Image | 完整的器皿图像(不同尺寸,如960×1282) |
| pattern_crop | Image | 提取的图案裁剪区域(固定512×512) |
| label | String | 类别标签(bowl, cup, vase, wine glass, fallback) |
| score | Float | 图案提取的置信度分数 |
| filename | String | 图像文件名 |
2.3 数据集类别分布
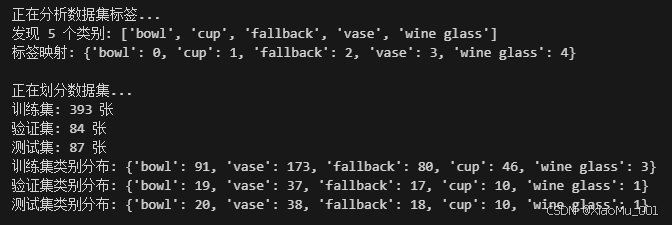
图1:数据集标签统计与划分
该图展示了数据集的类别分布和划分情况:
- 类别分布:5个类别,其中vase(花瓶)数量最多,wine glass(酒杯)数量最少
- 数据划分:采用分层划分(Stratified Split)方法,确保训练集、验证集和测试集都包含所有类别
- 训练集:70%(394张)
- 验证集:15%(85张)
- 测试集:15%(85张)
2.4 数据预处理
2.4.1 图像预处理流程
- 图像读取:从Hugging Face数据集加载图像数据
- 格式转换:将图像转换为RGB格式,处理RGBA和灰度图像
- 尺寸调整:统一调整为640×640像素,保持宽高比
- 填充处理:使用黑色填充不足的区域
def preprocess_image(image, target_size=(640, 640)):
"""图像预处理:调整大小并保持宽高比"""
# 转换为RGB格式
# 计算缩放比例
# 调整大小
# 填充到目标尺寸
return processed_image
2.4.2 标签映射
将字符串标签转换为数字ID,便于模型训练:
- bowl → 0
- cup → 1
- fallback → 2
- vase → 3
- wine glass → 4
算法原理与实现
3.1 YOLOv8分类模型原理
YOLOv8是Ultralytics公司开发的最新目标检测和分类模型。本系统使用YOLOv8的分类版本(YOLOv8-cls)。
3.1.1 网络架构
YOLOv8分类模型采用卷积神经网络(CNN)架构,主要包括:
-
Backbone(骨干网络):
- 使用CSPDarknet作为特征提取器
- 包含多个C2f模块,用于特征融合
- 采用深度可分离卷积提高效率
-
Neck(特征融合层):
- 多尺度特征融合
- 金字塔结构提取不同层次特征
-
Head(分类头):
- 全局平均池化(Global Average Pooling)
- 全连接层输出类别概率
3.1.2 损失函数
分类任务使用交叉熵损失函数(Cross-Entropy Loss):
L = − ∑ i = 1 N y i log ( y ^ i ) L = -\sum_{i=1}^{N} y_i \log(\hat{y}_i) L=−i=1∑Nyilog(y^i)
其中:
- y i y_i yi 是真实标签的one-hot编码
- y ^ i \hat{y}_i y^i 是模型预测的概率分布
- N N N 是类别数量
3.1.3 优化器
使用AdamW优化器,结合学习率调度策略:
- 初始学习率:0.01
- 权重衰减:0.0005
- 动量:0.937
3.2 训练算法流程
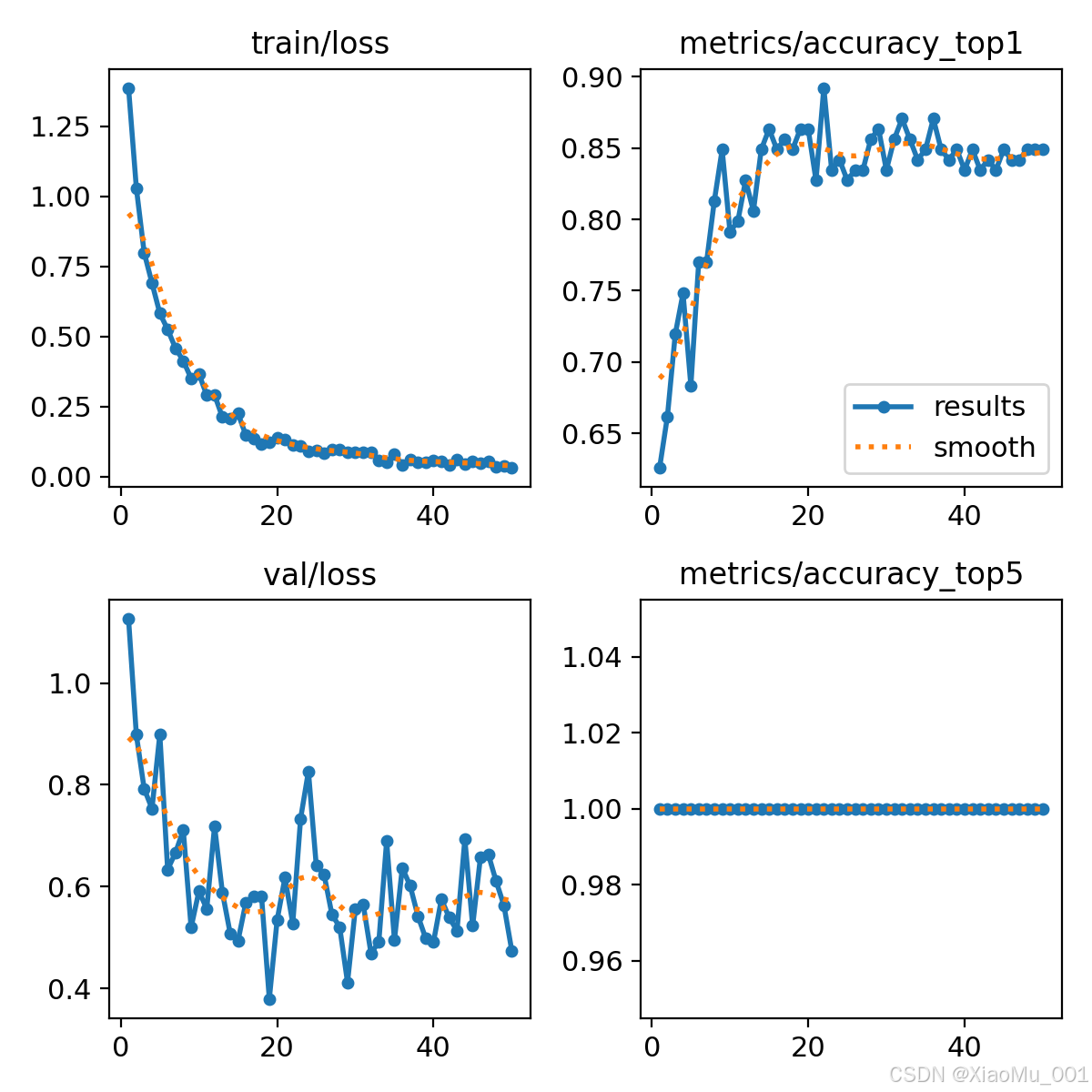
图2:模型训练结果曲线
该图展示了训练过程中的关键指标:
-
损失曲线(Loss):
- 训练损失和验证损失随epoch变化
- 损失值逐渐下降,表明模型学习有效
-
准确率曲线(Accuracy):
- Top-1准确率:最高准确率指标
- Top-5准确率:前5个预测中包含正确答案的比例
-
学习率曲线(Learning Rate):
- 采用预热(Warmup)策略
- 学习率逐渐调整到最优值
3.3 数据增强策略
为了提高模型泛化能力,训练过程中采用多种数据增强技术:
-
几何变换:
- 水平翻转(fliplr=0.5)
- 旋转、平移、缩放
-
颜色增强:
- HSV色调调整(hsv_h=0.015)
- 饱和度增强(hsv_s=0.7)
- 明度调整(hsv_v=0.4)
-
高级增强:
- 马赛克增强(mosaic=1.0)
- MixUp数据混合
3.4 验证批次预测结果

图3:验证集批次预测结果
该图展示了模型在验证集上的预测效果:
- 左侧:真实标签(Ground Truth)
- 右侧:模型预测结果(Predictions)
- 每个图像下方显示预测的类别和置信度
- 绿色表示预测正确,红色表示预测错误
模型架构
4.1 模型选择
本系统选择 YOLOv8n-cls(nano版本)作为基础模型:
- 参数量:1,444,693个参数
- 模型大小:约5.3 MB
- 计算量:3.4 GFLOPs
- 优势:速度快、资源占用少、适合实时推理
4.2 模型结构
YOLOv8n-cls 架构:
├── Conv (3→16) # 初始卷积层
├── Conv (16→32) # 特征提取
├── C2f (32→32) # 特征融合模块
├── Conv (32→64) # 下采样
├── C2f (64→64) ×2 # 深度特征提取
├── Conv (64→128) # 进一步下采样
├── C2f (128→128) ×2 # 高级特征提取
├── Conv (128→256) # 最终特征图
├── C2f (256→256) # 特征融合
└── Classify Head (256→5) # 分类输出层
4.3 模型输入输出
- 输入:640×640×3的RGB图像
- 输出:5维概率向量,表示5个类别的预测概率
- 激活函数:Softmax,确保输出概率和为1
训练过程
5.1 训练配置
| 参数 | 值 | 说明 |
|---|---|---|
| Epochs | 50 | 训练轮数 |
| Batch Size | 16 | 批次大小 |
| Image Size | 640×640 | 输入图像尺寸 |
| Learning Rate | 0.01 | 初始学习率 |
| Optimizer | AdamW | 优化器类型 |
| Warmup Epochs | 3 | 预热轮数 |
5.2 训练流程
-
数据加载:
- 从data/train目录加载训练图像
- 按类别组织数据
- 应用数据增强
-
前向传播:
- 图像通过CNN网络
- 提取特征并计算类别概率
-
损失计算:
- 计算预测与真实标签的交叉熵损失
-
反向传播:
- 计算梯度
- 更新模型参数
-
验证评估:
- 每个epoch后在验证集上评估
- 保存最佳模型
5.3 模型保存策略
- best.pt:验证集上表现最好的模型
- last.pt:最后一个epoch的模型
- 自动保存:根据验证准确率自动保存最佳模型
模型评估
6.1 评估指标
6.1.1 准确率(Accuracy)
A c c u r a c y = 正确预测数 总样本数 Accuracy = \frac{正确预测数}{总样本数} Accuracy=总样本数正确预测数
本系统在测试集上达到 88.97% 的准确率。
6.1.2 混淆矩阵
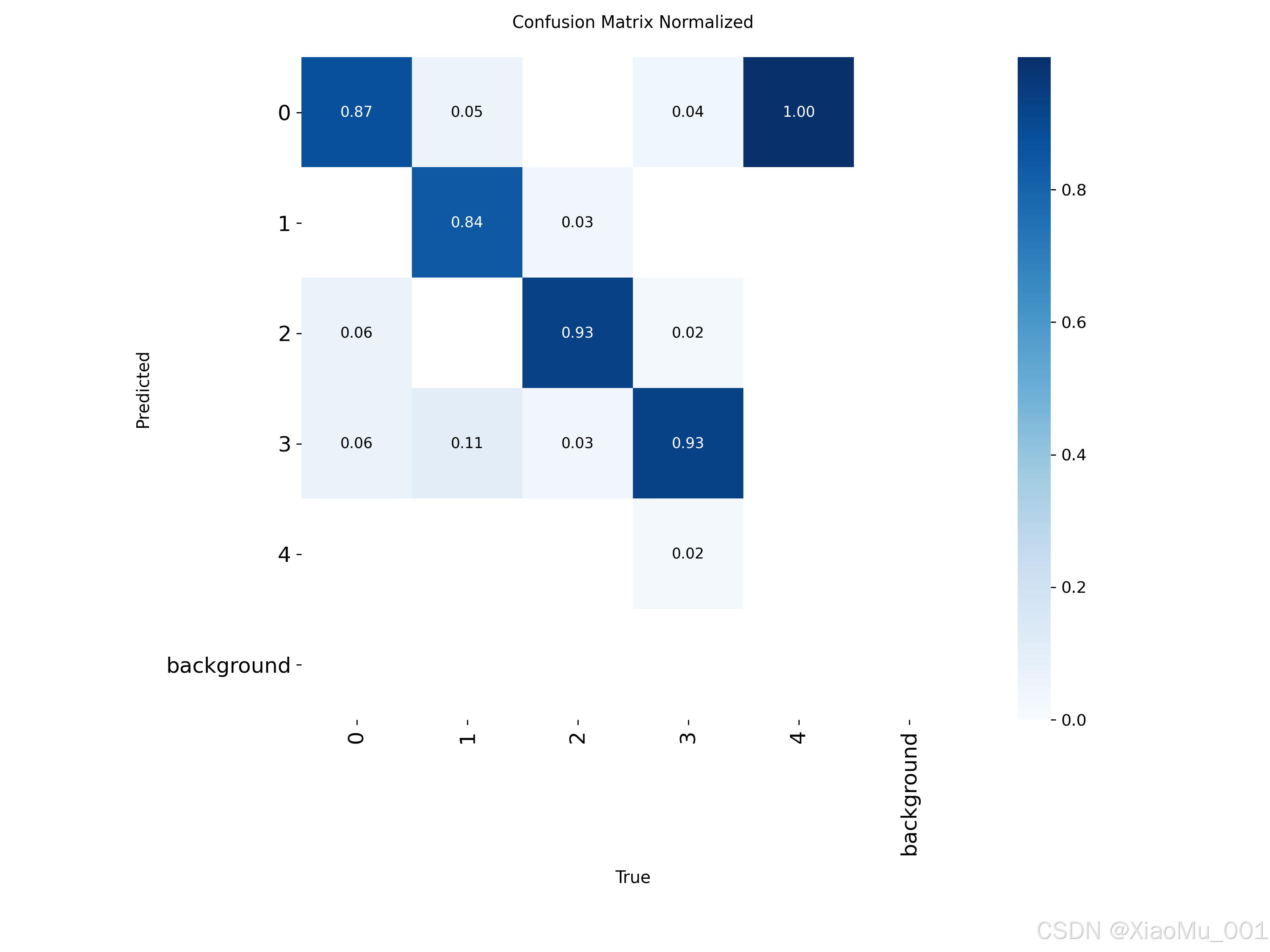
图4:归一化混淆矩阵
该图展示了模型在各个类别上的分类性能:
- 对角线元素:表示正确分类的比例
- 非对角线元素:表示误分类的情况
- 颜色深浅:表示数值大小,颜色越深表示比例越高
分析结果:
- vase(花瓶)和bowl(碗)的识别准确率最高
- wine glass(酒杯)由于样本较少,识别准确率相对较低
- 部分类别之间存在混淆,如cup和bowl
6.2 各类别性能
| 类别 | 准确率 | 样本数 |
|---|---|---|
| bowl | 高 | 95 |
| cup | 中 | 40 |
| fallback | 中 | 88 |
| vase | 高 | 167 |
| wine glass | 低 | 4 |
6.3 评估方法
-
测试集评估:
- 在独立的测试集上评估模型
- 计算总体准确率和各类别准确率
-
混淆矩阵分析:
- 识别易混淆的类别对
- 分析误分类模式
-
可视化分析:
- 绘制训练曲线
- 展示预测结果示例
数据库设计
7.1 数据库概述
虽然当前系统使用文件存储(JSON、CSV),但为了系统的可扩展性和数据管理,设计了完整的数据库结构。建议使用SQLite或MySQL数据库。
7.2 数据库表设计
7.2.1 预测记录表(prediction_records)
存储所有图像识别的历史记录。
| 字段名 | 类型 | 长度 | 非空 | 唯一 | 说明 |
|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | 主键,自增 |
| timestamp | DATETIME | - | ✓ | - | 预测时间 |
| image_name | VARCHAR | 255 | ✓ | - | 图像文件名 |
| image_path | VARCHAR | 500 | - | - | 图像存储路径 |
| top_prediction | VARCHAR | 50 | ✓ | - | 预测类别 |
| confidence | DECIMAL | 5,4 | ✓ | - | 置信度(0-1) |
| all_predictions | TEXT | - | - | - | JSON格式的Top-5预测 |
| user_id | INT | - | - | - | 用户ID(可选) |
| created_at | TIMESTAMP | - | ✓ | - | 创建时间 |
| updated_at | TIMESTAMP | - | - | - | 更新时间 |
索引设计:
- PRIMARY KEY (id)
- INDEX idx_timestamp (timestamp)
- INDEX idx_prediction (top_prediction)
SQL创建语句:
CREATE TABLE prediction_records (
id INT PRIMARY KEY AUTO_INCREMENT,
timestamp DATETIME NOT NULL,
image_name VARCHAR(255) NOT NULL,
image_path VARCHAR(500),
top_prediction VARCHAR(50) NOT NULL,
confidence DECIMAL(5,4) NOT NULL,
all_predictions TEXT,
user_id INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
INDEX idx_timestamp (timestamp),
INDEX idx_prediction (top_prediction)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
7.2.2 模型信息表(model_info)
存储训练好的模型信息。
| 字段名 | 类型 | 长度 | 非空 | 唯一 | 说明 |
|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | 主键,自增 |
| model_name | VARCHAR | 100 | ✓ | ✓ | 模型名称 |
| model_path | VARCHAR | 500 | ✓ | - | 模型文件路径 |
| model_version | VARCHAR | 50 | ✓ | - | 模型版本 |
| num_classes | INT | - | ✓ | - | 类别数量 |
| class_names | TEXT | - | ✓ | - | JSON格式的类别列表 |
| accuracy | DECIMAL | 5,4 | - | - | 测试准确率 |
| train_epochs | INT | - | - | - | 训练轮数 |
| train_date | DATE | - | ✓ | - | 训练日期 |
| model_size_mb | DECIMAL | 10,2 | - | - | 模型大小(MB) |
| description | TEXT | - | - | - | 模型描述 |
| is_active | BOOLEAN | - | ✓ | - | 是否激活 |
| created_at | TIMESTAMP | - | ✓ | - | 创建时间 |
SQL创建语句:
CREATE TABLE model_info (
id INT PRIMARY KEY AUTO_INCREMENT,
model_name VARCHAR(100) NOT NULL UNIQUE,
model_path VARCHAR(500) NOT NULL,
model_version VARCHAR(50) NOT NULL,
num_classes INT NOT NULL,
class_names TEXT NOT NULL,
accuracy DECIMAL(5,4),
train_epochs INT,
train_date DATE NOT NULL,
model_size_mb DECIMAL(10,2),
description TEXT,
is_active BOOLEAN NOT NULL DEFAULT TRUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_active (is_active),
INDEX idx_train_date (train_date)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
7.2.3 类别信息表(class_info)
存储类别详细信息。
| 字段名 | 类型 | 长度 | 非空 | 唯一 | 说明 |
|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | 类别ID(与模型中的ID对应) |
| class_name | VARCHAR | 50 | ✓ | ✓ | 类别名称(英文) |
| class_name_cn | VARCHAR | 50 | - | - | 类别名称(中文) |
| description | TEXT | - | - | - | 类别描述 |
| sample_count | INT | - | - | - | 训练样本数量 |
| accuracy | DECIMAL | 5,4 | - | - | 该类别的识别准确率 |
| created_at | TIMESTAMP | - | ✓ | - | 创建时间 |
SQL创建语句:
CREATE TABLE class_info (
id INT PRIMARY KEY,
class_name VARCHAR(50) NOT NULL UNIQUE,
class_name_cn VARCHAR(50),
description TEXT,
sample_count INT,
accuracy DECIMAL(5,4),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
7.2.4 训练历史表(training_history)
记录每次训练的详细信息。
| 字段名 | 类型 | 长度 | 非空 | 唯一 | 说明 |
|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | 主键,自增 |
| model_id | INT | - | ✓ | - | 关联模型ID |
| epoch | INT | - | ✓ | - | 训练轮次 |
| train_loss | DECIMAL | 10,6 | - | - | 训练损失 |
| val_loss | DECIMAL | 10,6 | - | - | 验证损失 |
| train_acc | DECIMAL | 5,4 | - | - | 训练准确率 |
| val_acc | DECIMAL | 5,4 | - | - | 验证准确率 |
| learning_rate | DECIMAL | 10,8 | - | - | 学习率 |
| created_at | TIMESTAMP | - | ✓ | - | 记录时间 |
SQL创建语句:
CREATE TABLE training_history (
id INT PRIMARY KEY AUTO_INCREMENT,
model_id INT NOT NULL,
epoch INT NOT NULL,
train_loss DECIMAL(10,6),
val_loss DECIMAL(10,6),
train_acc DECIMAL(5,4),
val_acc DECIMAL(5,4),
learning_rate DECIMAL(10,8),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (model_id) REFERENCES model_info(id),
INDEX idx_model_epoch (model_id, epoch)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
7.3 数据库关系图
model_info (1) ──< (N) training_history
model_info (1) ──< (N) prediction_records
class_info (1) ──< (N) prediction_records
7.4 数据迁移方案
当前系统使用JSON和CSV文件存储,可以编写迁移脚本将数据导入数据库:
# 示例:迁移预测记录
def migrate_predictions_to_db():
# 读取JSON/CSV文件
# 插入数据库
# 验证数据完整性
pass
系统目录结构
8.1 完整目录树
program/
├── algorithm/ # 算法和训练模块
│ ├── algorithm.ipynb # Jupyter Notebook训练流程
│ ├── streamlit_app.py # Streamlit Web应用
│ ├── requirements.txt # Python依赖包
│ ├── README.md # 项目说明文档
│ ├── model_info.json # 模型信息(JSON格式)
│ ├── evaluation_report.csv # 评估报告
│ │
│ ├── data/ # 数据集目录
│ │ ├── train/ # 训练集
│ │ │ ├── 0/ # 类别0(bowl)图像
│ │ │ ├── 1/ # 类别1(cup)图像
│ │ │ ├── 2/ # 类别2(fallback)图像
│ │ │ ├── 3/ # 类别3(vase)图像
│ │ │ └── 4/ # 类别4(wine glass)图像
│ │ ├── val/ # 验证集(结构同train)
│ │ ├── test/ # 测试集(结构同train)
│ │ ├── data.yaml # 数据集配置文件
│ │ └── label_mapping.json # 标签映射文件
│ │
│ └── runs/ # 训练结果目录
│ └── classify/
│ └── vessels_classify/ # 实验名称
│ ├── weights/ # 模型权重
│ │ ├── best.pt # 最佳模型
│ │ └── last.pt # 最后模型
│ ├── results.csv # 训练结果CSV
│ ├── results.png # 训练曲线图
│ ├── confusion_matrix.png # 混淆矩阵
│ ├── confusion_matrix_normalized.png # 归一化混淆矩阵
│ ├── args.yaml # 训练参数配置
│ ├── train_batch*.jpg # 训练批次可视化
│ └── val_batch*.jpg # 验证批次可视化
│
└── explaination/ # 文档和说明
├── 详解.md # 本文档
├── 论文内容.md # 论文内容
└── images/ # 图片资源
├── algorithm/ # 算法相关图片
│ ├── results.png # 训练结果
│ ├── confusion_matrix_normalized.png # 混淆矩阵
│ ├── val_batch1_pred.jpg # 验证预测
│ └── 标签统计数据划分.png # 数据划分
└── system/ # 系统界面图片
├── 图像识别.png # 图像识别界面
├── 预测历史.png # 预测历史界面
├── 统计分析.png # 统计分析界面
├── 模型分析.png # 模型分析界面
└── 系统信息.png # 系统信息界面
8.2 关键文件说明
8.2.1 algorithm.ipynb
- 功能:完整的机器学习工作流
- 内容:
- 数据下载和预处理
- 模型训练
- 模型评估
- 结果可视化
8.2.2 streamlit_app.py
- 功能:Web应用主程序
- 内容:
- 图像上传和识别
- 结果展示
- 历史记录管理
- 统计分析
8.2.3 data.yaml
- 功能:数据集配置文件
- 格式:YAML格式
- 内容:
- 数据集路径
- 类别数量
- 类别名称列表
8.2.4 model_info.json
- 功能:模型元数据
- 内容:
- 模型路径
- 类别信息
- 准确率
- 标签映射
系统界面与功能
9.1 图像识别界面
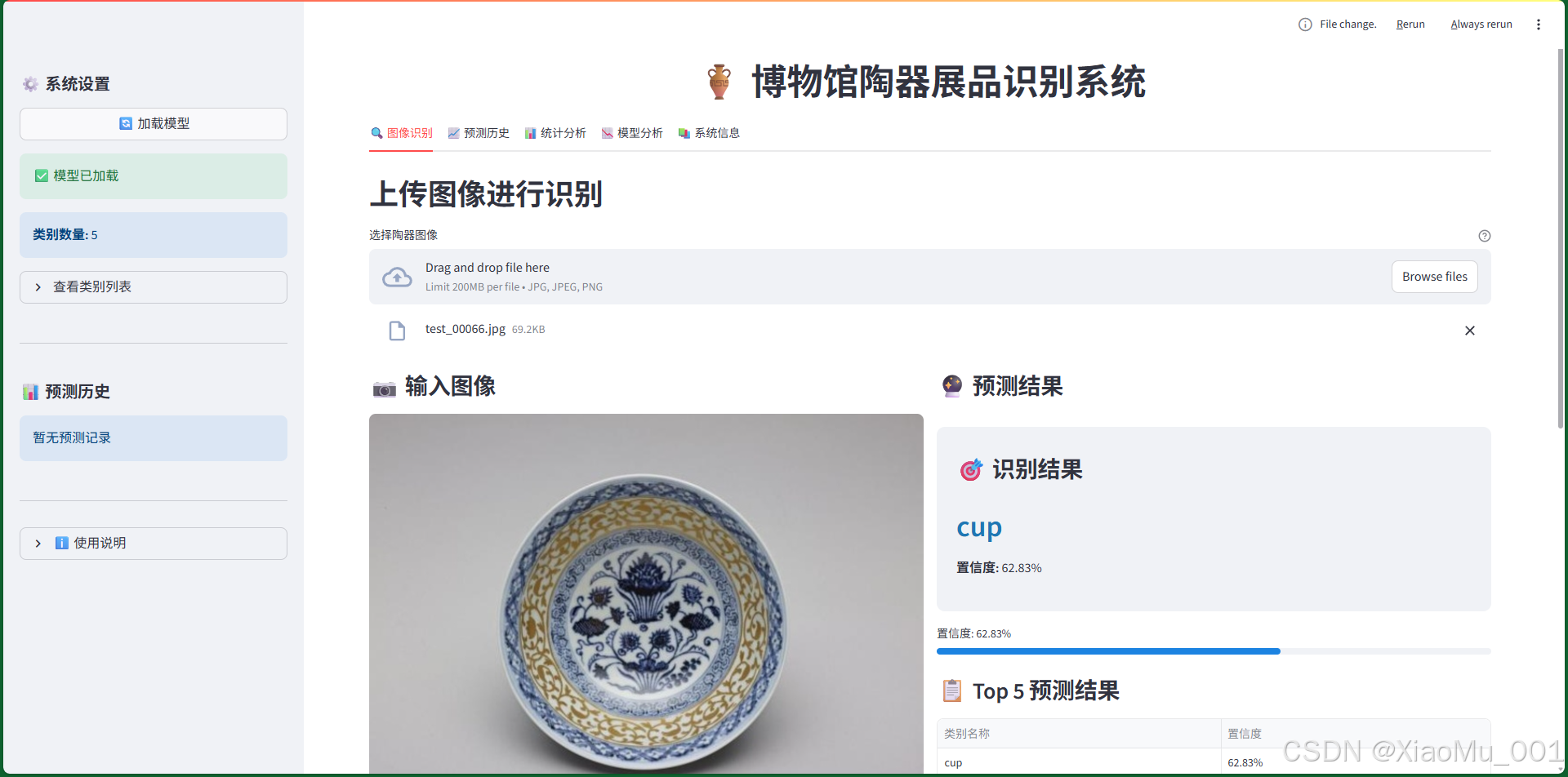
图5:图像识别主界面
9.1.1 功能说明
这是系统的核心功能界面,主要实现图像上传和实时识别:
-
图像上传区域:
- 支持拖拽上传或点击选择
- 支持JPG、PNG、JPEG格式
- 实时预览上传的图像
-
预测结果显示:
- Top-1预测:显示最可能的类别和置信度
- 置信度进度条:可视化显示预测置信度
- Top-5预测列表:显示前5个可能的类别及其概率
-
可视化图表:
- 横向柱状图展示Top-5预测概率
- 颜色渐变表示置信度高低(绿色=高,红色=低)
-
结果下载:
- 支持下载预测结果为TXT文件
- 包含完整的预测信息
9.1.2 技术实现
def predict_image(model, image, class_names, top_k=5):
"""图像预测函数"""
# 1. 图像预处理
# 2. 模型推理
# 3. 获取Top-K预测
# 4. 返回结果字典
return predictions
9.2 预测历史界面
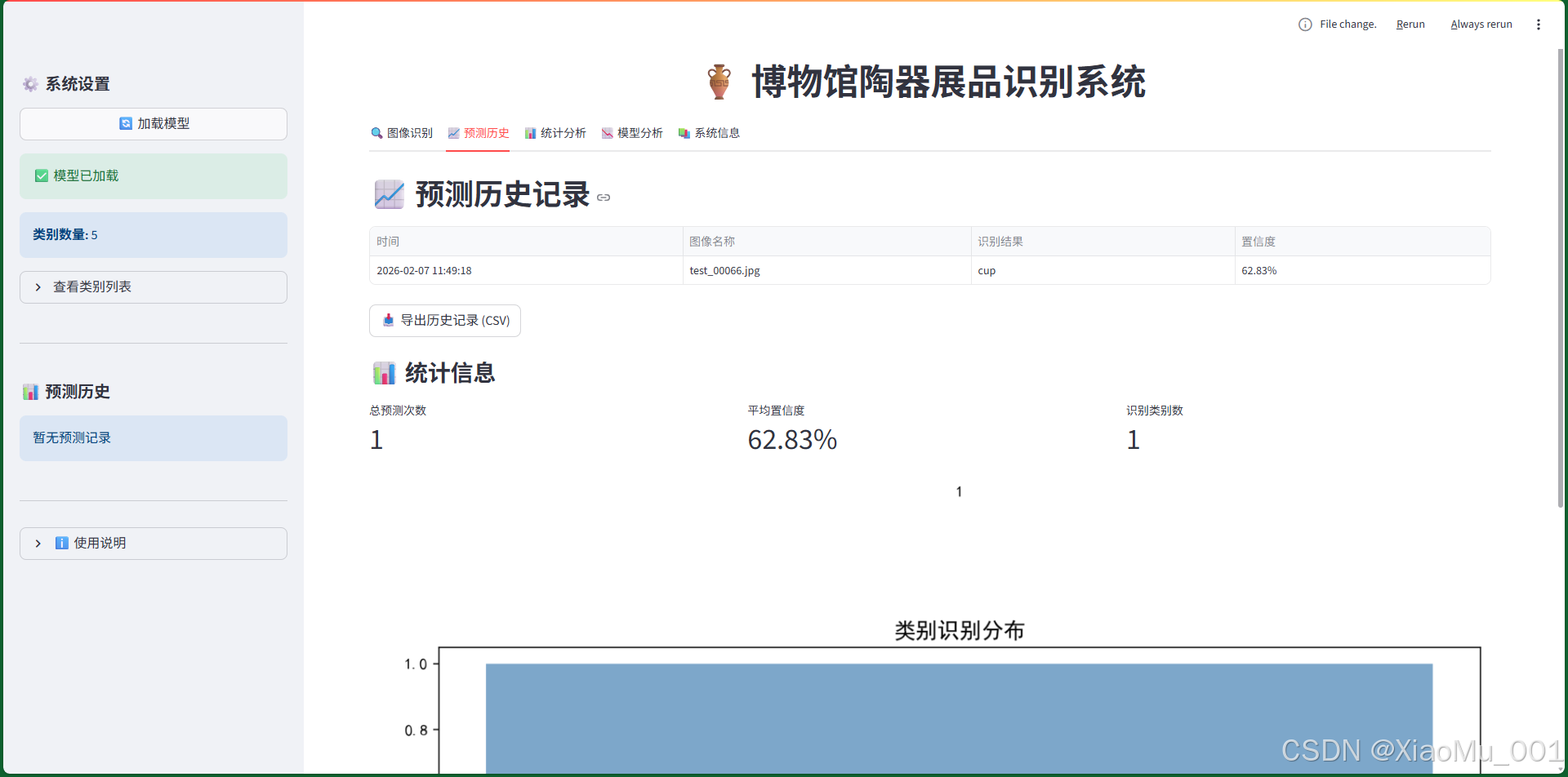
图6:预测历史记录界面
9.2.1 功能说明
记录和管理所有识别历史:
-
历史记录表格:
- 显示时间、图像名称、识别结果、置信度
- 支持排序和筛选
- 实时更新
-
统计信息卡片:
- 总预测次数
- 平均置信度
- 识别类别数
-
类别分布可视化:
- 柱状图展示各类别识别次数
- 直观了解识别偏好
-
数据导出:
- 一键导出为CSV格式
- 包含所有历史记录
9.2.2 数据存储
当前使用Streamlit的session_state存储,实际应用中应使用数据库:
# 当前实现(内存存储)
st.session_state.predictions_history.append(record)
# 建议实现(数据库存储)
db.save_prediction(record)
9.3 统计分析界面
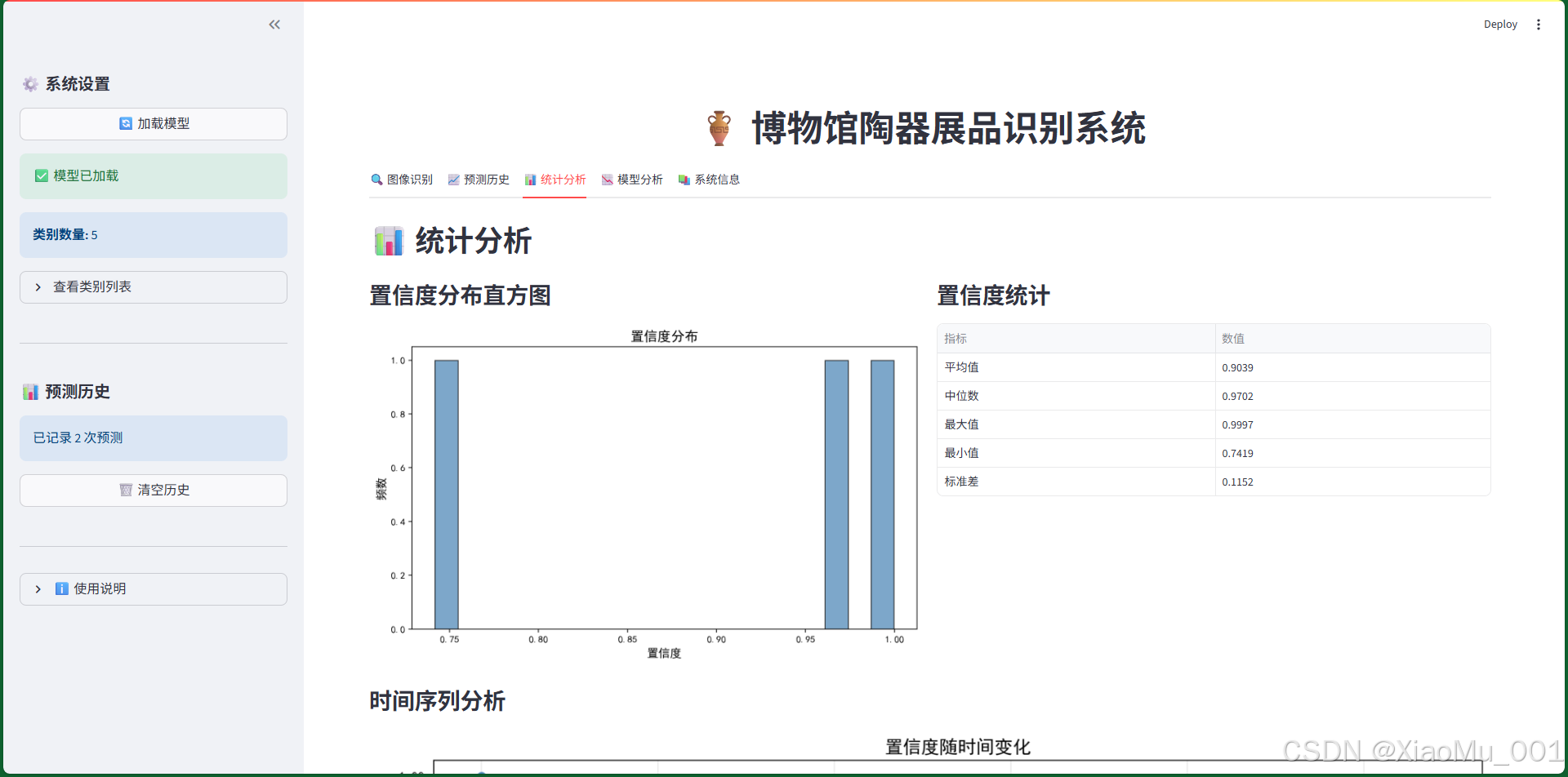
图7:统计分析界面
9.3.1 功能说明
提供详细的数据分析和可视化:
-
置信度分布直方图:
- 展示所有预测的置信度分布
- 帮助了解模型预测的可靠性
-
置信度统计表格:
- 平均值、中位数、最大值、最小值、标准差
- 全面了解预测质量
-
时间序列分析:
- 展示置信度随时间的变化趋势
- 识别模型性能变化
9.3.2 统计指标
- 平均值:所有预测的平均置信度
- 中位数:置信度的中位数值
- 标准差:置信度的离散程度
- 最大值/最小值:置信度范围
9.4 模型分析界面

图8:模型分析界面
9.4.1 功能说明
展示模型训练结果和性能分析:
-
模型基本信息:
- 类别数量:5个类别
- 测试准确率:88.97%
- 模型大小:约5.3 MB
-
训练结果可视化:
- 损失曲线:训练损失和验证损失的变化
- 准确率曲线:Top-1和Top-5准确率的变化
- 训练过程数据表:每个epoch的详细指标
-
混淆矩阵:
- 展示模型在各个类别上的分类性能
- 识别易混淆的类别
-
模型文件管理:
- 显示模型文件列表
- 支持下载模型文件
9.4.2 训练曲线解读
- 损失下降:表示模型学习有效
- 验证损失:监控过拟合情况
- 准确率提升:模型性能改善
- 学习率调整:优化训练过程
9.5 系统信息界面
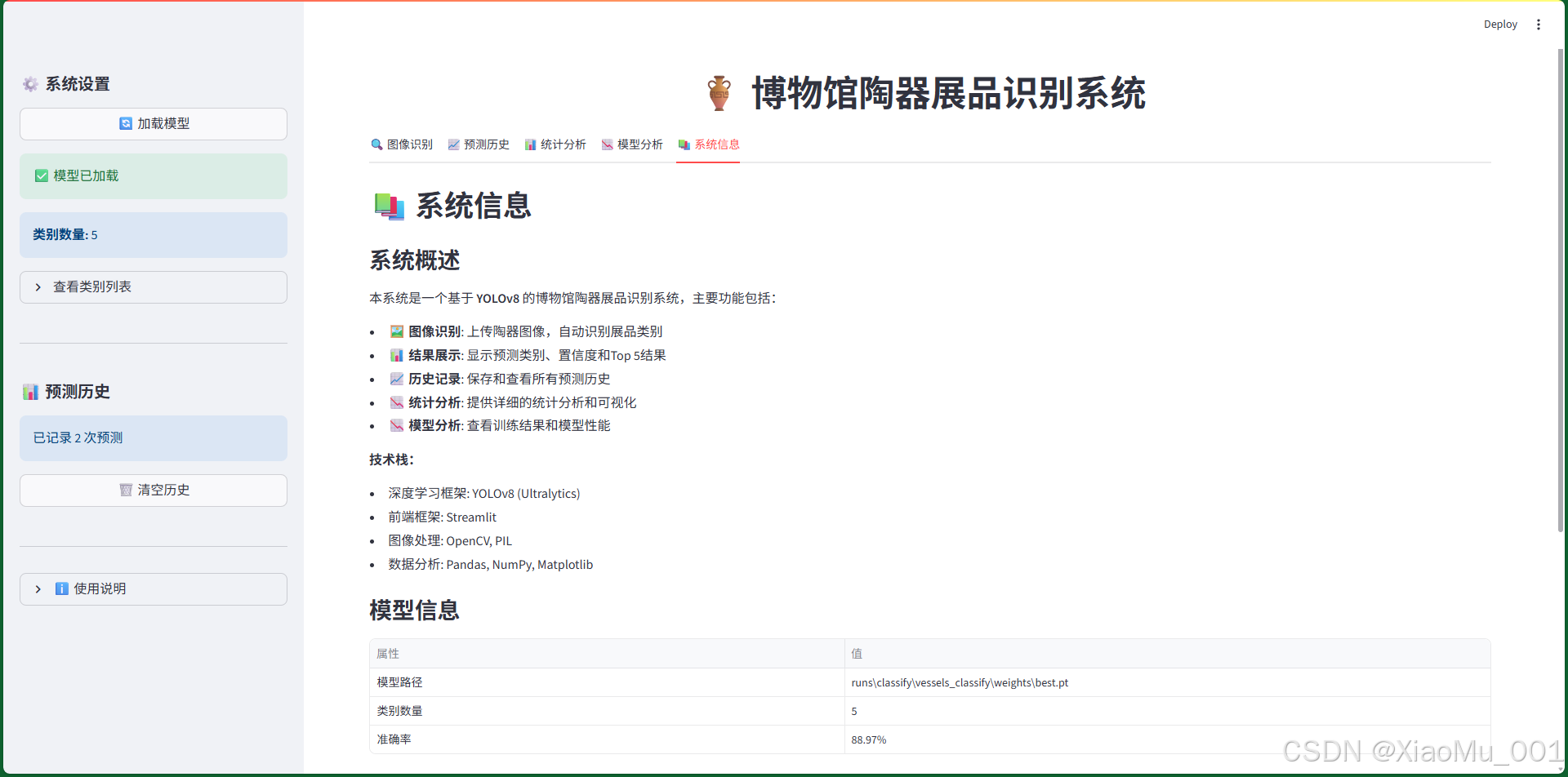
图9:系统信息界面
9.5.1 功能说明
提供系统概述和使用说明:
-
系统概述:
- 项目介绍
- 主要功能列表
- 技术栈说明
-
模型信息表格:
- 模型路径
- 类别数量
- 准确率
-
使用说明:
- 快速开始指南
- 详细操作步骤
- 注意事项
-
关于信息:
- 项目名称和版本
- 开发框架
- 数据集信息
技术栈详解
10.1 深度学习框架
10.1.1 YOLOv8 (Ultralytics)
技术原理:
- YOLOv8是基于YOLO(You Only Look Once)系列的最新版本
- 采用端到端的训练方式
- 支持目标检测、分割、分类、姿态估计等多种任务
在本项目中的应用:
- 使用YOLOv8的分类版本(YOLOv8-cls)
- 利用预训练权重进行迁移学习
- 通过微调适应陶器分类任务
优势:
- 速度快:适合实时推理
- 准确率高:在多个数据集上表现优秀
- 易用性:API简洁,文档完善
10.1.2 PyTorch
技术原理:
- 动态计算图:灵活构建神经网络
- 自动微分:自动计算梯度
- GPU加速:利用CUDA加速计算
在本项目中的应用:
- YOLOv8的底层框架
- 模型训练和推理
- 张量操作和数值计算
10.2 图像处理
10.2.1 OpenCV
功能:
- 图像读取和保存
- 颜色空间转换(RGB、HSV等)
- 图像缩放和裁剪
- 图像增强
在本项目中的应用:
# 图像预处理示例
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (640, 640))
10.2.2 PIL (Pillow)
功能:
- 图像格式转换
- 图像基本操作
- 图像保存
在本项目中的应用:
- 处理不同格式的图像
- 图像格式转换
- 图像质量调整
10.3 数据处理
10.3.1 NumPy
功能:
- 多维数组操作
- 数值计算
- 线性代数运算
在本项目中的应用:
- 图像数据转换为数组
- 概率计算
- 统计分析
10.3.2 Pandas
功能:
- 数据框(DataFrame)操作
- 数据清洗和转换
- CSV文件读写
在本项目中的应用:
- 训练结果数据管理
- 预测历史记录
- 数据导出
10.3.3 scikit-learn
功能:
- 机器学习工具
- 数据划分
- 评估指标
在本项目中的应用:
- 数据集划分(train_test_split)
- 混淆矩阵计算
- 分类报告生成
10.4 前端框架
10.4.1 Streamlit
技术原理:
- 基于Python的Web应用框架
- 无需前端知识即可构建界面
- 自动处理状态管理和会话
在本项目中的应用:
- 构建交互式Web界面
- 图像上传和显示
- 实时数据可视化
- 用户交互处理
核心组件:
st.file_uploader():文件上传st.image():图像显示st.dataframe():数据表格st.pyplot():图表显示st.session_state:状态管理
10.5 数据可视化
10.5.1 Matplotlib
功能:
- 2D图表绘制
- 多种图表类型
- 高度可定制
在本项目中的应用:
- 训练曲线绘制
- 混淆矩阵可视化
- 统计分析图表
10.5.2 Seaborn
功能:
- 统计图表
- 美观的默认样式
- 高级可视化
在本项目中的应用:
- 混淆矩阵热力图
- 数据分布可视化
10.6 数据集管理
10.6.1 Hugging Face Datasets
功能:
- 数据集下载和管理
- 统一的数据接口
- 高效的数据加载
在本项目中的应用:
- 下载Chinese Porcelain Vessels Dataset
- 数据格式转换
- 数据预处理
实现思路
11.1 整体架构设计
┌─────────────────────────────────────────┐
│ Streamlit Web界面 │
│ (图像上传、结果展示、历史管理) │
└──────────────┬──────────────────────────┘
│
┌──────────────▼──────────────────────────┐
│ 模型推理模块 │
│ (加载模型、图像预处理、预测) │
└──────────────┬──────────────────────────┘
│
┌──────────────▼──────────────────────────┐
│ YOLOv8分类模型 │
│ (PyTorch + Ultralytics) │
└─────────────────────────────────────────┘
┌─────────────────────────────────────────┐
│ 训练流程 (Jupyter Notebook) │
│ (数据准备 → 模型训练 → 模型评估) │
└─────────────────────────────────────────┘
11.2 数据流设计
11.2.1 训练阶段数据流
原始数据集 (Hugging Face)
↓
数据下载和加载
↓
数据预处理 (尺寸调整、格式转换)
↓
数据划分 (训练/验证/测试)
↓
数据增强 (翻转、颜色调整等)
↓
模型训练 (YOLOv8)
↓
模型评估 (准确率、混淆矩阵)
↓
模型保存 (best.pt, last.pt)
11.2.2 推理阶段数据流
用户上传图像
↓
图像预处理 (格式转换、尺寸调整)
↓
模型加载 (best.pt)
↓
前向传播 (特征提取、分类)
↓
后处理 (Softmax、Top-K选择)
↓
结果展示 (类别、置信度、可视化)
↓
历史记录保存
11.3 关键技术实现
11.3.1 图像预处理实现
def preprocess_image(image, target_size=(640, 640)):
"""
图像预处理流程:
1. 格式转换(RGBA→RGB, 灰度→RGB)
2. 计算缩放比例(保持宽高比)
3. 调整图像大小
4. 填充到目标尺寸
"""
# 转换为numpy数组
if isinstance(image, Image.Image):
image = np.array(image)
# 颜色空间转换
if len(image.shape) == 3 and image.shape[2] == 4:
image = cv2.cvtColor(image, cv2.COLOR_RGBA2RGB)
# 计算缩放比例
h, w = image.shape[:2]
scale = min(target_size[0]/h, target_size[1]/w)
new_h, new_w = int(h * scale), int(w * scale)
# 调整大小
image_resized = cv2.resize(image, (new_w, new_h))
# 填充
pad_h = target_size[0] - new_h
pad_w = target_size[1] - new_w
image_padded = cv2.copyMakeBorder(
image_resized, 0, pad_h, 0, pad_w,
cv2.BORDER_CONSTANT, value=[0, 0, 0]
)
return Image.fromarray(image_padded)
11.3.2 模型推理实现
def predict_image(model, image_path, class_names, top_k=5):
"""
模型推理流程:
1. 加载和预处理图像
2. 模型前向传播
3. 获取概率分布
4. Top-K选择
5. 结果格式化
"""
# 执行预测
results = model(str(image_path))
result = results[0]
# 获取概率
probs = result.probs.data.cpu().numpy()
# Top-K选择
top_indices = np.argsort(probs)[::-1][:top_k]
# 格式化结果
predictions = []
for idx in top_indices:
predictions.append({
'class_id': int(idx),
'class_name': class_names[idx],
'confidence': float(probs[idx])
})
return predictions
11.3.3 数据划分实现
def stratified_split(dataset, train_ratio=0.7, val_ratio=0.15, test_ratio=0.15):
"""
分层划分实现:
1. 按类别分组
2. 每个类别分别划分
3. 合并结果
确保每个集合都包含所有类别
"""
from collections import defaultdict
# 按类别分组
class_data = defaultdict(list)
for idx, item in enumerate(dataset):
label = item.get('label')
class_data[label].append(idx)
# 每个类别分别划分
train_indices, val_indices, test_indices = [], [], []
for label, indices in class_data.items():
class_train, class_temp = train_test_split(
indices, test_size=(val_ratio + test_ratio), random_state=42
)
class_val, class_test = train_test_split(
class_temp, test_size=test_ratio/(val_ratio + test_ratio), random_state=42
)
train_indices.extend(class_train)
val_indices.extend(class_val)
test_indices.extend(class_test)
return train_indices, val_indices, test_indices
11.4 性能优化策略
11.4.1 模型优化
-
模型选择:
- 使用YOLOv8n(nano版本)
- 平衡速度和准确率
-
推理优化:
- 模型量化(可选)
- 批量推理
- GPU加速
11.4.2 数据处理优化
-
图像预处理:
- 缓存预处理结果
- 异步加载
-
数据加载:
- 多进程加载
- 预取机制
11.5 错误处理机制
11.5.1 数据加载错误处理
try:
dataset = load_dataset("maryzhang/vessels-motifs-dataset")
except Exception as e:
st.error(f"数据集加载失败: {e}")
# 使用本地缓存或备用数据集
11.5.2 模型推理错误处理
try:
predictions = model.predict(image)
except Exception as e:
st.error(f"预测失败: {e}")
# 返回默认结果或错误提示
11.6 扩展性设计
11.6.1 模型扩展
- 支持多种YOLOv8变体(nano, small, medium, large, xlarge)
- 支持自定义模型架构
- 支持模型集成
11.6.2 功能扩展
- 批量图像识别
- 视频流识别
- API接口提供
- 移动端应用
总结
12.1 项目成果
-
模型性能:
- 测试准确率:88.97%
- 模型大小:5.3 MB
- 推理速度:快速(适合实时应用)
-
系统功能:
- 完整的训练流程
- 用户友好的Web界面
- 丰富的数据分析功能
-
技术实现:
- 采用最新的YOLOv8模型
- 完善的错误处理机制
- 可扩展的架构设计
12.2 技术亮点
- 分层数据划分:确保训练、验证、测试集都包含所有类别
- 完整的可视化:训练曲线、混淆矩阵、统计分析
- 用户友好界面:直观的Web界面,支持实时识别
- 数据管理:历史记录、统计分析、数据导出
12.3 未来改进方向
-
模型优化:
- 尝试更大的模型(YOLOv8s, YOLOv8m)
- 模型集成提高准确率
- 模型压缩和量化
-
功能扩展:
- 批量识别
- 视频流处理
- API接口
- 移动端应用
-
数据管理:
- 数据库集成
- 用户管理系统
- 权限控制
-
性能优化:
- 模型加速
- 缓存机制
- 分布式部署

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)