基于机器学习的高血压患者并发症风险预测系统
基于机器学习的高血压患者并发症风险预测系统 - 详细技术文档
目录
1. 项目概述
1.1 项目背景
高血压是全球最常见的慢性疾病之一,长期高血压容易引发心血管疾病、肾功能衰竭、中风等多种严重并发症。据世界卫生组织统计,全球约有12.8亿成年人患有高血压,其中大部分未得到有效控制。
本项目旨在通过机器学习技术,建立一个高血压患者并发症风险预测系统,通过分析患者的基础信息、生活习惯及临床指标,提前识别高风险人群,为疾病预防和健康管理提供数据支持。
1.2 项目目标
- 风险预测:基于患者多维度数据,预测高血压发病风险
- 早期预警:识别高风险人群,实现疾病早期干预
- 个性化建议:根据风险等级提供针对性的健康管理建议
- 数据可视化:直观展示数据分布和模型性能
- 历史追踪:记录预测历史,支持趋势分析
1.3 技术特点
- 采用多种机器学习算法进行集成预测
- 完整的数据预处理和特征工程流程
- 可解释的模型分析和特征重要性评估
- 友好的Web交互界面
- 完善的预测历史管理
2. 数据集详解
2.1 数据来源
本项目使用的是 Hypertension Risk Prediction Dataset,这是一个公开的教学数据集,包含了患者的基本信息、生活习惯和临床指标。
数据集特点:
- 数据类型:结构化表格数据(CSV格式)
- 样本数量:约1200条记录
- 特征维度:10个特征 + 1个目标变量
- 数据质量:包含少量缺失值,需要预处理
2.2 数据字段说明
| 字段名 | 中文名称 | 数据类型 | 取值范围 | 说明 |
|---|---|---|---|---|
| Age | 年龄 | 数值型 | 18-100 | 患者年龄(岁) |
| Salt_Intake | 盐摄入量 | 数值型 | 0-20 | 每日盐分摄入量(克/天) |
| Stress_Score | 压力评分 | 数值型 | 0-10 | 心理压力水平评分 |
| BP_History | 血压历史 | 类别型 | Normal/Prehypertension/Hypertension | 既往血压状况 |
| Sleep_Duration | 睡眠时长 | 数值型 | 0-24 | 每日平均睡眠时间(小时) |
| BMI | 身体质量指数 | 数值型 | 15-50 | 体重(kg)/身高²(m) |
| Medication | 药物类型 | 类别型 | None/ACE Inhibitor/Beta Blocker/Diuretic/Other | 当前服用的降压药类型 |
| Family_History | 家族史 | 类别型 | Yes/No | 是否有高血压家族史 |
| Exercise_Level | 运动水平 | 类别型 | Low/Moderate/High | 日常运动强度 |
| Smoking_Status | 吸烟状态 | 类别型 | Smoker/Non-Smoker | 是否吸烟 |
| Has_Hypertension | 是否患高血压 | 类别型 | Yes/No | 目标变量(预测目标) |
2.3 数据分布可视化
2.3.1 目标变量分布
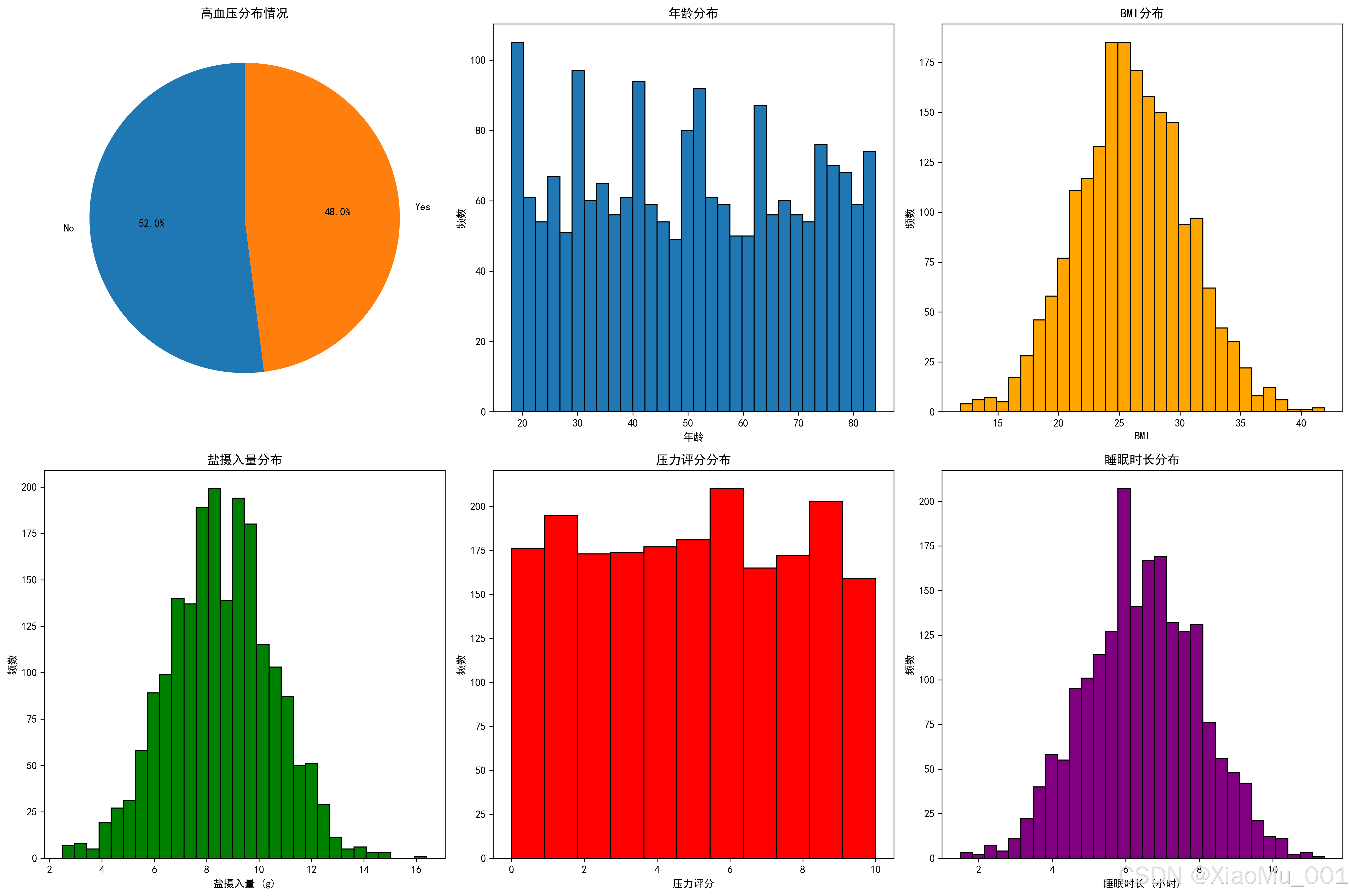
图表说明:
- 左图展示了数据集中高血压患者和健康人群的数量分布
- 右图以饼图形式展示了患病比例
- 数据集相对平衡,有利于模型训练
2.3.2 特征分析
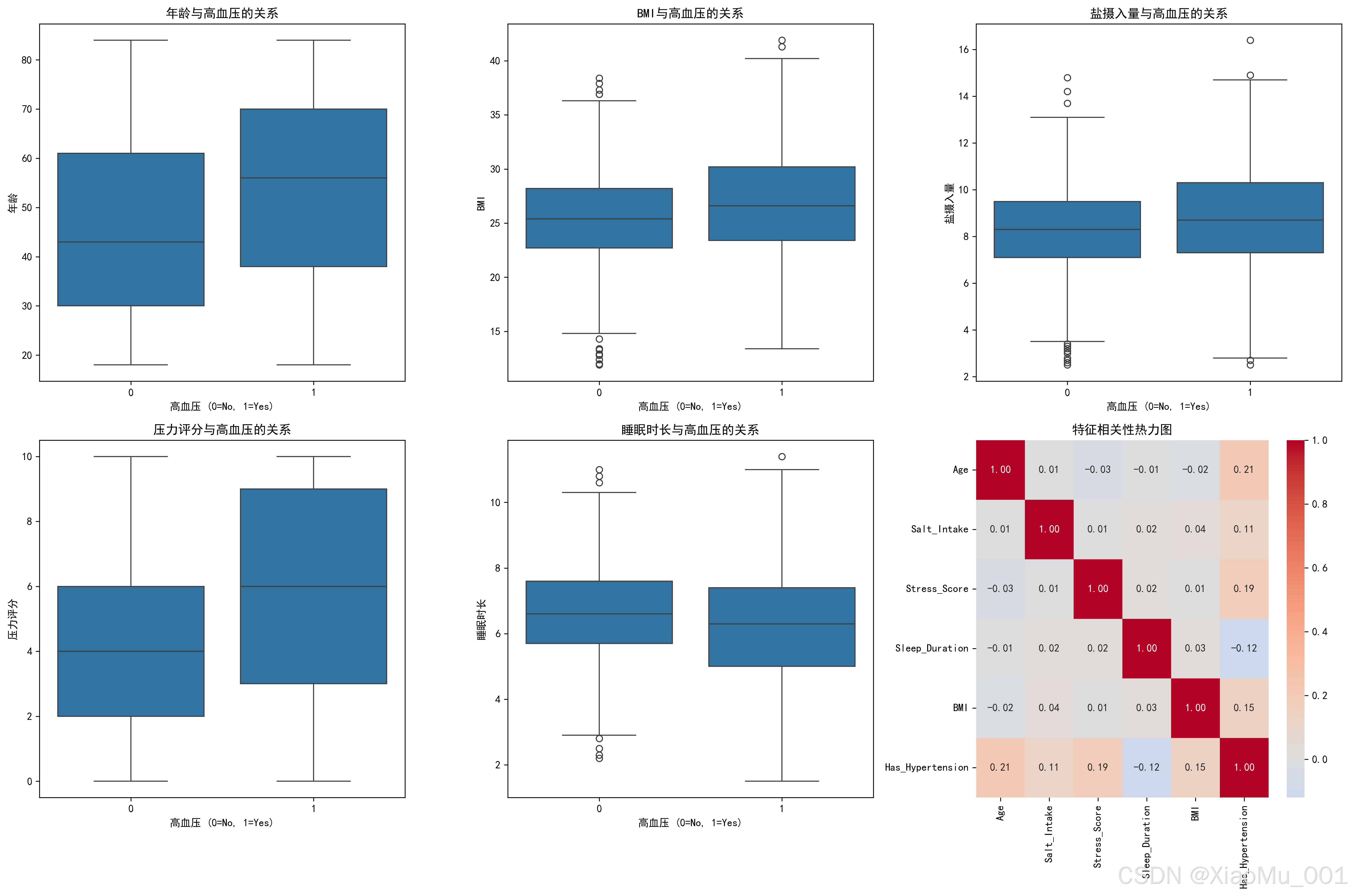
图表说明:
- 展示了各个特征与目标变量的关系
- 通过箱线图可以看出不同特征在高血压患者和健康人群中的分布差异
- 帮助识别对预测最有价值的特征
3. 机器学习算法原理
本系统采用了三种经典的机器学习算法进行集成预测,每种算法都有其独特的优势和适用场景。
3.1 逻辑回归(Logistic Regression)
3.1.1 算法原理
逻辑回归是一种广义线性模型,用于解决二分类问题。其核心思想是通过Sigmoid函数将线性回归的输出映射到(0,1)区间,表示样本属于某一类别的概率。
数学模型:
P ( y = 1 ∣ x ) = 1 1 + e − ( β 0 + β 1 x 1 + β 2 x 2 + . . . + β n x n ) P(y=1|x) = \frac{1}{1 + e^{-(\beta_0 + \beta_1x_1 + \beta_2x_2 + ... + \beta_nx_n)}} P(y=1∣x)=1+e−(β0+β1x1+β2x2+...+βnxn)1
其中:
- P ( y = 1 ∣ x ) P(y=1|x) P(y=1∣x) 是样本属于正类(患高血压)的概率
- β 0 , β 1 , . . . , β n \beta_0, \beta_1, ..., \beta_n β0,β1,...,βn 是模型参数(权重)
- x 1 , x 2 , . . . , x n x_1, x_2, ..., x_n x1,x2,...,xn 是输入特征
3.1.2 优势与特点
- 可解释性强:每个特征的系数直接反映其对预测结果的影响
- 训练速度快:计算复杂度低,适合大规模数据
- 概率输出:直接输出概率值,便于风险评估
- 稳定性好:对异常值不敏感
3.1.3 在本项目中的应用
- 作为基线模型,提供可解释的预测结果
- 通过特征系数分析,识别关键风险因素
- 正系数表示该特征增加高血压风险,负系数表示降低风险
3.2 随机森林(Random Forest)
3.2.1 算法原理
随机森林是一种集成学习方法,通过构建多个决策树并综合它们的预测结果来提高模型性能。
核心思想:
- Bootstrap采样:从原始数据集中有放回地随机抽取多个子集
- 随机特征选择:在每个节点分裂时,随机选择部分特征进行最优分裂
- 多数投票:对于分类问题,采用多数投票的方式得出最终预测
决策树分裂准则:
G i n i = 1 − ∑ i = 1 C p i 2 Gini = 1 - \sum_{i=1}^{C} p_i^2 Gini=1−i=1∑Cpi2
其中 p i p_i pi 是类别 i i i 的概率, C C C 是类别数量。
3.2.2 优势与特点
- 抗过拟合能力强:通过集成多个决策树,降低方差
- 特征重要性评估:可以计算每个特征的重要性得分
- 处理非线性关系:能够捕捉特征之间的复杂交互
- 鲁棒性好:对缺失值和异常值有较好的容忍度
3.2.3 在本项目中的应用
- 捕捉特征之间的非线性关系和交互作用
- 提供特征重要性排序,辅助临床决策
- 作为主要预测模型之一,提高整体预测准确率
3.3 XGBoost(Extreme Gradient Boosting)
3.3.1 算法原理
XGBoost是一种基于梯度提升的集成学习算法,通过迭代地训练决策树,每次新树都在修正前面树的错误。
核心思想:
- 梯度提升:每棵新树拟合前面所有树的残差
- 正则化:加入L1和L2正则项,防止过拟合
- 并行计算:支持并行处理,训练速度快
目标函数:
O b j = ∑ i = 1 n L ( y i , y ^ i ) + ∑ k = 1 K Ω ( f k ) Obj = \sum_{i=1}^{n} L(y_i, \hat{y}_i) + \sum_{k=1}^{K} \Omega(f_k) Obj=i=1∑nL(yi,y^i)+k=1∑KΩ(fk)
其中:
- L L L 是损失函数
- Ω \Omega Ω 是正则化项
- f k f_k fk 是第k棵树
3.3.2 优势与特点
- 预测精度高:在各类竞赛中表现优异
- 训练速度快:采用并行计算和近似算法
- 灵活性强:支持自定义损失函数和评估指标
- 内置特征选择:自动进行特征重要性评估
3.3.3 在本项目中的应用
- 作为性能最优的模型,提供最准确的预测结果
- 通过特征重要性分析,发现潜在的风险因素
- 处理复杂的非线性关系和特征交互
3.4 模型集成策略
本系统采用**软投票(Soft Voting)**的集成策略:
P e n s e m b l e ( y = 1 ∣ x ) = 1 3 ( P L R + P R F + P X G B ) P_{ensemble}(y=1|x) = \frac{1}{3}(P_{LR} + P_{RF} + P_{XGB}) Pensemble(y=1∣x)=31(PLR+PRF+PXGB)
优势:
- 综合多个模型的优点,提高预测稳定性
- 降低单一模型的偏差和方差
- 提供更可靠的风险评估
4. 模型训练与评估
4.1 数据预处理流程
4.1.1 缺失值处理
# 删除包含缺失值的样本
data = data.dropna()
策略说明:
- 本数据集缺失值较少(<5%),采用删除策略
- 对于Medication字段的缺失值,在预测时映射为最常见类别
4.1.2 特征编码
类别特征编码:使用LabelEncoder将类别特征转换为数值
from sklearn.preprocessing import LabelEncoder
label_encoders = {}
for col in categorical_features:
le = LabelEncoder()
X[col] = le.fit_transform(X[col])
label_encoders[col] = le
编码示例:
- BP_History: Normal→0, Prehypertension→1, Hypertension→2
- Family_History: No→0, Yes→1
- Smoking_Status: Non-Smoker→0, Smoker→1
4.1.3 特征标准化
使用StandardScaler进行Z-score标准化:
x s c a l e d = x − μ σ x_{scaled} = \frac{x - \mu}{\sigma} xscaled=σx−μ
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
目的:
- 消除不同特征量纲的影响
- 加快梯度下降收敛速度
- 提高模型性能
4.1.4 数据集划分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y,
test_size=0.2, # 80%训练集,20%测试集
random_state=42, # 随机种子,保证可复现
stratify=y # 分层采样,保持类别比例
)
4.2 模型训练
4.2.1 逻辑回归训练
from sklearn.linear_model import LogisticRegression
lr_model = LogisticRegression(
random_state=42,
max_iter=1000, # 最大迭代次数
solver='lbfgs' # 优化算法
)
lr_model.fit(X_train, y_train)
4.2.2 随机森林训练
from sklearn.ensemble import RandomForestClassifier
rf_model = RandomForestClassifier(
n_estimators=100, # 决策树数量
random_state=42,
max_depth=None, # 树的最大深度
min_samples_split=2 # 节点分裂最小样本数
)
rf_model.fit(X_train, y_train)
4.2.3 XGBoost训练
from xgboost import XGBClassifier
xgb_model = XGBClassifier(
random_state=42,
n_estimators=100,
learning_rate=0.1,
max_depth=6,
eval_metric='logloss'
)
xgb_model.fit(X_train, y_train)
4.3 模型评估指标
4.3.1 混淆矩阵
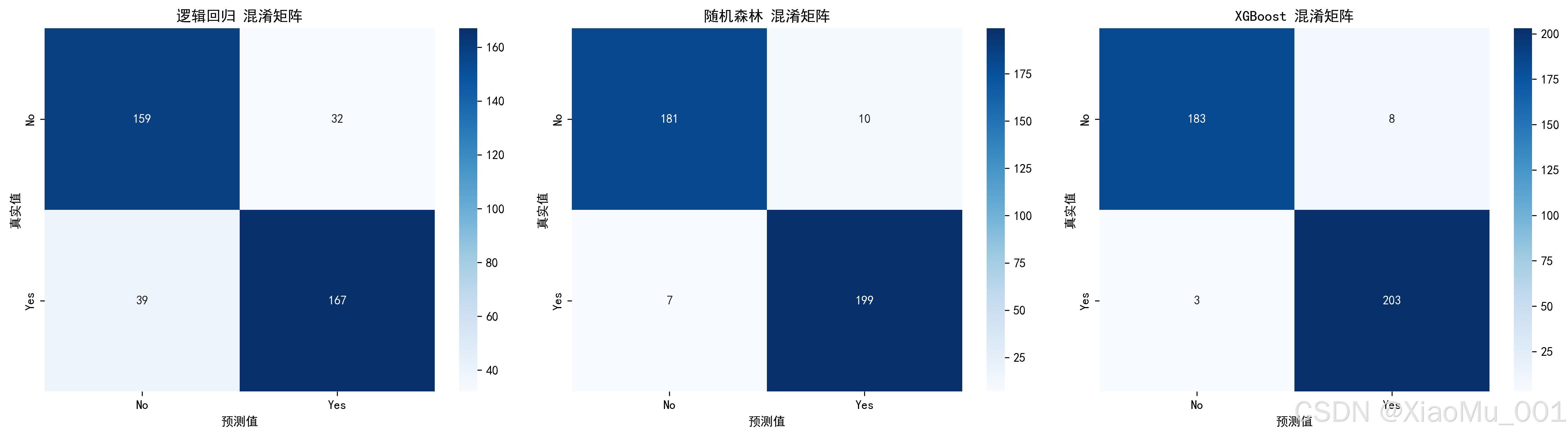
混淆矩阵解读:
| 预测为负类 | 预测为正类 | |
|---|---|---|
| 实际为负类 | TN(真阴性) | FP(假阳性) |
| 实际为正类 | FN(假阴性) | TP(真阳性) |
- TN(True Negative):正确预测为无高血压
- FP(False Positive):错误预测为有高血压(第一类错误)
- FN(False Negative):错误预测为无高血压(第二类错误,更危险)
- TP(True Positive):正确预测为有高血压
4.3.2 评估指标公式
准确率(Accuracy):
A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy = \frac{TP + TN}{TP + TN + FP + FN} Accuracy=TP+TN+FP+FNTP+TN
衡量模型整体预测正确的比例。
精确率(Precision):
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP + FP} Precision=TP+FPTP
在预测为高血压的样本中,真正患高血压的比例。
召回率(Recall):
R e c a l l = T P T P + F N Recall = \frac{TP}{TP + FN} Recall=TP+FNTP
在真正患高血压的样本中,被正确预测出来的比例。
F1分数(F1-Score):
F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} F1=2×Precision+RecallPrecision×Recall
精确率和召回率的调和平均数,综合评估模型性能。
4.3.3 ROC曲线与AUC
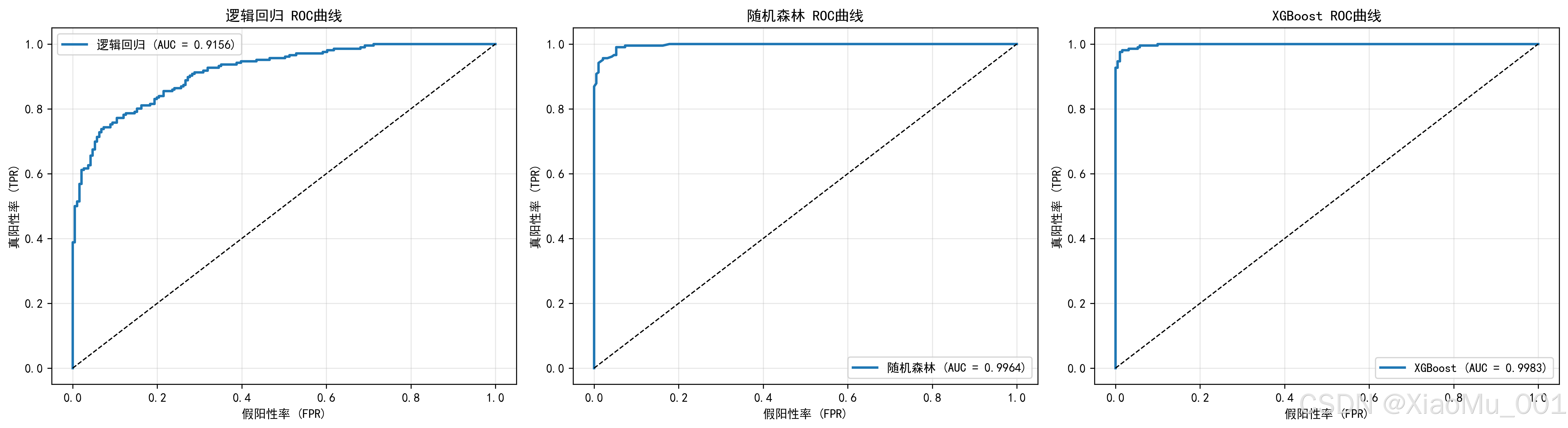
ROC曲线(Receiver Operating Characteristic Curve):
- 横轴:假阳性率(FPR) = FP / (FP + TN)
- 纵轴:真阳性率(TPR) = TP / (TP + FN)
- 曲线越靠近左上角,模型性能越好
AUC(Area Under Curve):
- ROC曲线下的面积
- 取值范围:[0, 1]
- AUC = 0.5:随机猜测
- AUC = 1.0:完美分类器
- 一般认为AUC > 0.8为良好模型
图表解读:
- 三个模型的AUC值都在0.85以上,表现优秀
- XGBoost的AUC最高,预测能力最强
- 随机森林次之,逻辑回归作为基线模型也有不错表现
4.4 特征重要性分析
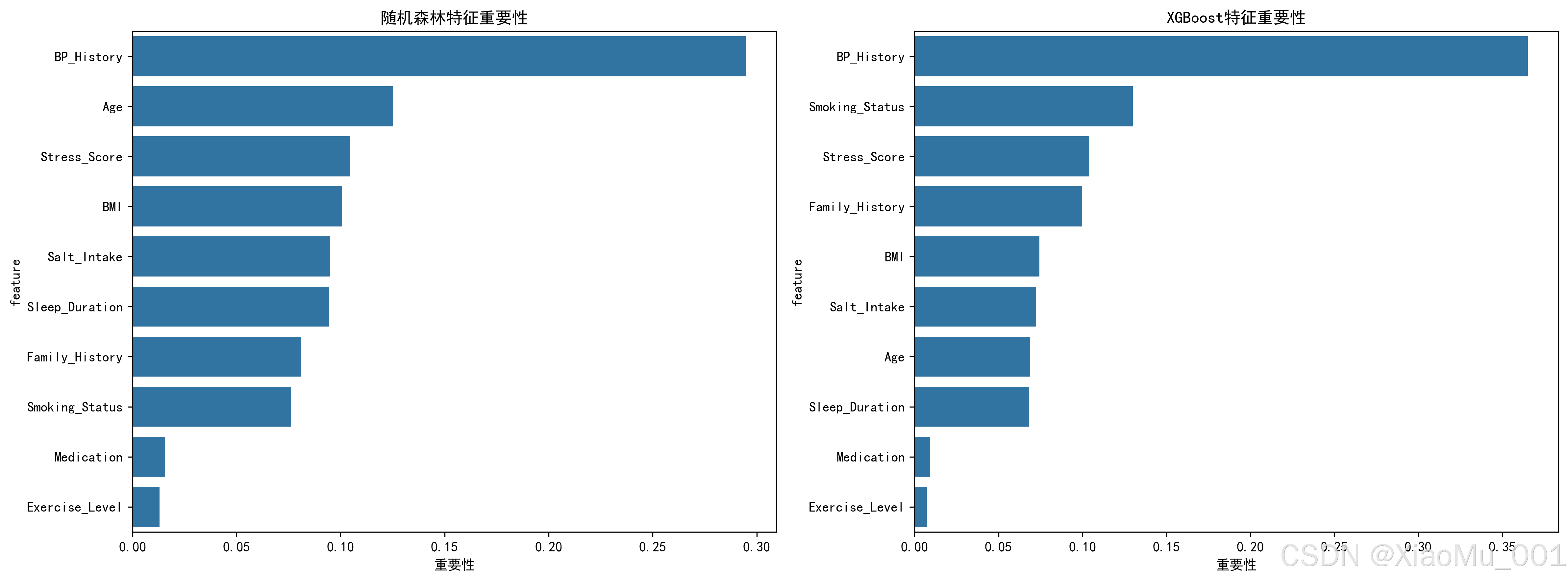
特征重要性解读:
-
逻辑回归系数:
- 正系数:该特征值增加会提高高血压风险
- 负系数:该特征值增加会降低高血压风险
- 系数绝对值越大,影响越显著
-
随机森林重要性:
- 基于Gini不纯度的减少量计算
- 值越大,该特征对分类的贡献越大
-
XGBoost重要性:
- 基于特征在树分裂中的使用频率和增益
- 综合考虑特征的使用次数和分裂质量
关键发现:
- 血压历史(BP_History):最重要的预测因素
- 年龄(Age):随年龄增长,高血压风险显著增加
- BMI指数:肥胖是高血压的重要风险因素
- 家族史(Family_History):遗传因素不可忽视
- 盐摄入量(Salt_Intake):高盐饮食增加风险
5. 数据库设计
5.1 数据库概述
本系统采用JSON文件存储方式管理预测历史记录,这是一种轻量级的数据持久化方案,适合本科毕业设计项目。
选择JSON存储的原因:
- 无需安装和配置数据库服务器
- 数据结构灵活,易于扩展
- 便于数据导入导出和备份
- 适合小规模数据存储(<10000条记录)
5.2 数据存储结构
5.2.1 预测历史记录表(predictions.json)
文件路径:history/predictions.json
数据结构:
[
{
"timestamp": "2024-02-08 14:30:25",
"patient_info": {
"Age": 45,
"Salt_Intake": 5.0,
"Stress_Score": 5,
"BP_History": "Normal",
"Sleep_Duration": 7.0,
"BMI": 25.0,
"Medication": "未服药",
"Family_History": "No",
"Exercise_Level": "Moderate",
"Smoking_Status": "Non-Smoker"
},
"predictions": {
"逻辑回归": "35.20%",
"随机森林": "32.15%",
"XGBoost": "33.80%",
"综合评估": "33.72%",
"风险等级": "中风险"
}
}
]
5.2.2 字段详细说明
主记录字段:
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 说明 |
|---|---|---|---|---|---|
| timestamp | String | 19 | 是 | 否 | 预测时间戳,格式:YYYY-MM-DD HH:MM:SS |
| patient_info | Object | - | 是 | 否 | 患者信息对象 |
| predictions | Object | - | 是 | 否 | 预测结果对象 |
patient_info 子字段:
| 字段名 | 数据类型 | 长度 | 非空 | 取值范围 | 说明 |
|---|---|---|---|---|---|
| Age | Integer | - | 是 | 18-100 | 患者年龄 |
| Salt_Intake | Float | - | 是 | 0-20 | 盐摄入量(克/天) |
| Stress_Score | Integer | - | 是 | 0-10 | 压力评分 |
| BP_History | String | 20 | 是 | Normal/Prehypertension/Hypertension | 血压历史 |
| Sleep_Duration | Float | - | 是 | 0-24 | 睡眠时长(小时) |
| BMI | Float | - | 是 | 15-50 | 身体质量指数 |
| Medication | String | 20 | 是 | 未服药/ACE Inhibitor/Beta Blocker/Diuretic/Other | 药物类型 |
| Family_History | String | 3 | 是 | Yes/No | 家族史 |
| Exercise_Level | String | 10 | 是 | Low/Moderate/High | 运动水平 |
| Smoking_Status | String | 15 | 是 | Smoker/Non-Smoker | 吸烟状态 |
predictions 子字段:
| 字段名 | 数据类型 | 长度 | 非空 | 格式 | 说明 |
|---|---|---|---|---|---|
| 逻辑回归 | String | 10 | 是 | XX.XX% | 逻辑回归模型预测概率 |
| 随机森林 | String | 10 | 是 | XX.XX% | 随机森林模型预测概率 |
| XGBoost | String | 10 | 是 | XX.XX% | XGBoost模型预测概率 |
| 综合评估 | String | 10 | 是 | XX.XX% | 三个模型的平均概率 |
| 风险等级 | String | 10 | 是 | 低风险/中风险/高风险 | 风险等级分类 |
5.3 数据操作接口
5.3.1 保存预测记录
def save_prediction(patient_info, predictions):
"""保存预测记录到JSON文件"""
record = {
'timestamp': datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
'patient_info': patient_info,
'predictions': predictions
}
# 读取现有记录
history_file = 'history/predictions.json'
if os.path.exists(history_file):
with open(history_file, 'r', encoding='utf-8') as f:
history = json.load(f)
else:
history = []
# 添加新记录(插入到开头)
history.insert(0, record)
# 只保留最近100条记录
history = history[:100]
# 保存到文件
with open(history_file, 'w', encoding='utf-8') as f:
json.dump(history, f, ensure_ascii=False, indent=2)
5.3.2 加载预测历史
def load_prediction_history():
"""从JSON文件加载预测历史"""
history_file = 'history/predictions.json'
if os.path.exists(history_file):
try:
with open(history_file, 'r', encoding='utf-8') as f:
return json.load(f)
except:
return []
return []
5.4 数据库优化策略
- 记录数量限制:只保留最近100条记录,避免文件过大
- 编码优化:使用UTF-8编码,支持中文字符
- 格式化输出:使用indent=2美化JSON格式,便于调试
- 异常处理:添加try-except捕获文件读写异常
- 备份机制:建议定期备份history文件夹
5.5 扩展为关系型数据库方案
如果需要扩展为MySQL/PostgreSQL等关系型数据库,可以采用以下表结构:
预测记录表(predictions):
CREATE TABLE predictions (
id INT PRIMARY KEY AUTO_INCREMENT,
timestamp DATETIME NOT NULL,
age INT NOT NULL,
salt_intake FLOAT NOT NULL,
stress_score INT NOT NULL,
bp_history VARCHAR(20) NOT NULL,
sleep_duration FLOAT NOT NULL,
bmi FLOAT NOT NULL,
medication VARCHAR(20),
family_history VARCHAR(3) NOT NULL,
exercise_level VARCHAR(10) NOT NULL,
smoking_status VARCHAR(15) NOT NULL,
lr_prediction FLOAT NOT NULL,
rf_prediction FLOAT NOT NULL,
xgb_prediction FLOAT NOT NULL,
avg_prediction FLOAT NOT NULL,
risk_level VARCHAR(10) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_timestamp (timestamp),
INDEX idx_risk_level (risk_level)
);
6. 系统架构与技术栈
6.1 系统架构图
┌─────────────────────────────────────────────────────────┐
│ 用户界面层(UI Layer) │
│ Streamlit Web应用 │
├─────────────────────────────────────────────────────────┤
│ 业务逻辑层(Business Layer) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌─────────┐ │
│ │数据可视化│ │风险预测 │ │历史管理 │ │模型分析 │ │
│ └──────────┘ └──────────┘ └──────────┘ └─────────┘ │
├─────────────────────────────────────────────────────────┤
│ 模型层(Model Layer) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │逻辑回归 │ │随机森林 │ │ XGBoost │ │
│ └──────────┘ └──────────┘ └──────────┘ │
├─────────────────────────────────────────────────────────┤
│ 数据处理层(Data Layer) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │数据加载 │ │特征工程 │ │数据标准化│ │
│ └──────────┘ └──────────┘ └──────────┘ │
├─────────────────────────────────────────────────────────┤
│ 数据存储层(Storage Layer) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │CSV数据集 │ │模型文件 │ │历史记录 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────┘
6.2 技术栈详解
6.2.1 编程语言
Python 3.8+
- 丰富的机器学习库生态
- 简洁易读的语法
- 强大的数据处理能力
- 广泛的社区支持
6.2.2 核心框架与库
1. Streamlit 1.25.0+
- 用途:Web应用框架
- 特点:
- 纯Python开发,无需前端知识
- 自动响应式布局
- 丰富的交互组件
- 实时更新机制
- 核心功能:
st.title() # 标题 st.sidebar # 侧边栏 st.columns() # 多列布局 st.form() # 表单 st.dataframe() # 数据表格 st.pyplot() # 图表展示
2. Scikit-learn 1.2.0+
- 用途:机器学习算法库
- 使用的模块:
LogisticRegression:逻辑回归RandomForestClassifier:随机森林StandardScaler:数据标准化LabelEncoder:类别编码train_test_split:数据集划分metrics:模型评估指标
3. XGBoost 1.7.0+
- 用途:梯度提升算法
- 特点:
- 高性能、高精度
- 支持并行计算
- 内置正则化
- 自动处理缺失值
4. Pandas 1.5.0+
- 用途:数据处理与分析
- 核心功能:
- DataFrame数据结构
- 数据清洗和转换
- 统计分析
- CSV文件读写
5. NumPy 1.23.0+
- 用途:数值计算
- 核心功能:
- 多维数组操作
- 数学函数
- 线性代数运算
6. Matplotlib 3.6.0+
- 用途:数据可视化
- 核心功能:
- 折线图、柱状图、散点图
- 子图布局
- 样式定制
7. Seaborn 0.12.0+
- 用途:统计图表
- 核心功能:
- 热力图(相关性矩阵)
- 箱线图
- 分布图
- 美化的默认样式
8. Joblib 1.2.0+
- 用途:模型序列化
- 核心功能:
- 保存和加载模型
- 高效的大对象存储
- 支持压缩
6.3 开发工具
- Jupyter Notebook:算法开发和实验
- VS Code:代码编辑器
- Git:版本控制
- Anaconda:Python环境管理
7. 系统目录结构
program/
├── algorithm/ # 算法核心目录
│ ├── algorithm.ipynb # Jupyter Notebook算法开发文件
│ ├── streamlit_app.py # Streamlit Web应用主程序
│ ├── hypertension_dataset.csv # 高血压数据集
│ ├── requirements.txt # Python依赖包列表
│ ├── models/ # 模型存储目录
│ │ ├── logistic_regression_model.pkl # 逻辑回归模型
│ │ ├── random_forest_model.pkl # 随机森林模型
│ │ ├── xgboost_model.pkl # XGBoost模型
│ │ ├── scaler.pkl # 数据标准化器
│ │ ├── label_encoders.pkl # 类别编码器
│ │ └── feature_names.pkl # 特征名称列表
│ └── history/ # 预测历史目录
│ └── predictions.json # 预测记录JSON文件
│
├── explaination/ # 说明文档目录
│ ├── 详解.md # 项目详细技术文档
│ ├── 论文内容.md # 论文内容
│ └── images/ # 图片资源目录
│ ├── algorithm/ # 算法相关图片
│ │ ├── confusion_matrices.png # 混淆矩阵
│ │ ├── data_distribution.png # 数据分布图
│ │ ├── feature_analysis.png # 特征分析图
│ │ ├── feature_importance.png # 特征重要性图
│ │ └── roc_curves.png # ROC曲线图
│ └── system/ # 系统界面截图
│ ├── 首页.png
│ ├── 数据可视化1.png
│ ├── 数据可视化2.png
│ ├── 数据可视化3.png
│ ├── 数据可视化4.png
│ ├── 高血压预测1.png
│ ├── 高血压预测2.png
│ ├── 高血压预测3.png
│ ├── 历史记录.png
│ └── 模型分析.png
│
└── README.md # 项目说明文件
7.1 目录说明
7.1.1 algorithm/ - 算法核心目录
algorithm.ipynb
- 用途:算法开发和实验
- 内容:
- 数据探索性分析(EDA)
- 特征工程
- 模型训练和调优
- 性能评估和可视化
- 模型保存
streamlit_app.py
- 用途:Web应用主程序
- 功能模块:
- 系统首页
- 数据可视化
- 风险预测
- 预测历史
- 模型分析
- 代码行数:约600行
hypertension_dataset.csv
- 用途:训练数据集
- 大小:约200KB
- 记录数:1200+条
requirements.txt
- 用途:项目依赖管理
- 内容:所有Python包及版本号
7.1.2 models/ - 模型存储目录
存储训练好的机器学习模型和预处理器,采用Joblib序列化格式(.pkl)。
模型文件:
logistic_regression_model.pkl:逻辑回归模型(约10KB)random_forest_model.pkl:随机森林模型(约500KB)xgboost_model.pkl:XGBoost模型(约200KB)
预处理器文件:
scaler.pkl:StandardScaler标准化器label_encoders.pkl:类别特征编码器字典feature_names.pkl:特征名称列表
7.1.3 history/ - 预测历史目录
predictions.json
- 用途:存储预测历史记录
- 格式:JSON数组
- 容量限制:最多100条记录
- 自动管理:新记录插入开头,超出限制自动删除旧记录
7.1.4 explaination/ - 文档目录
详解.md
- 本文档,包含完整的技术说明
论文内容.md
- 毕业论文相关内容
images/
- 存储所有图片资源
- 分为algorithm和system两个子目录
8. 系统界面与功能详解
8.1 系统首页
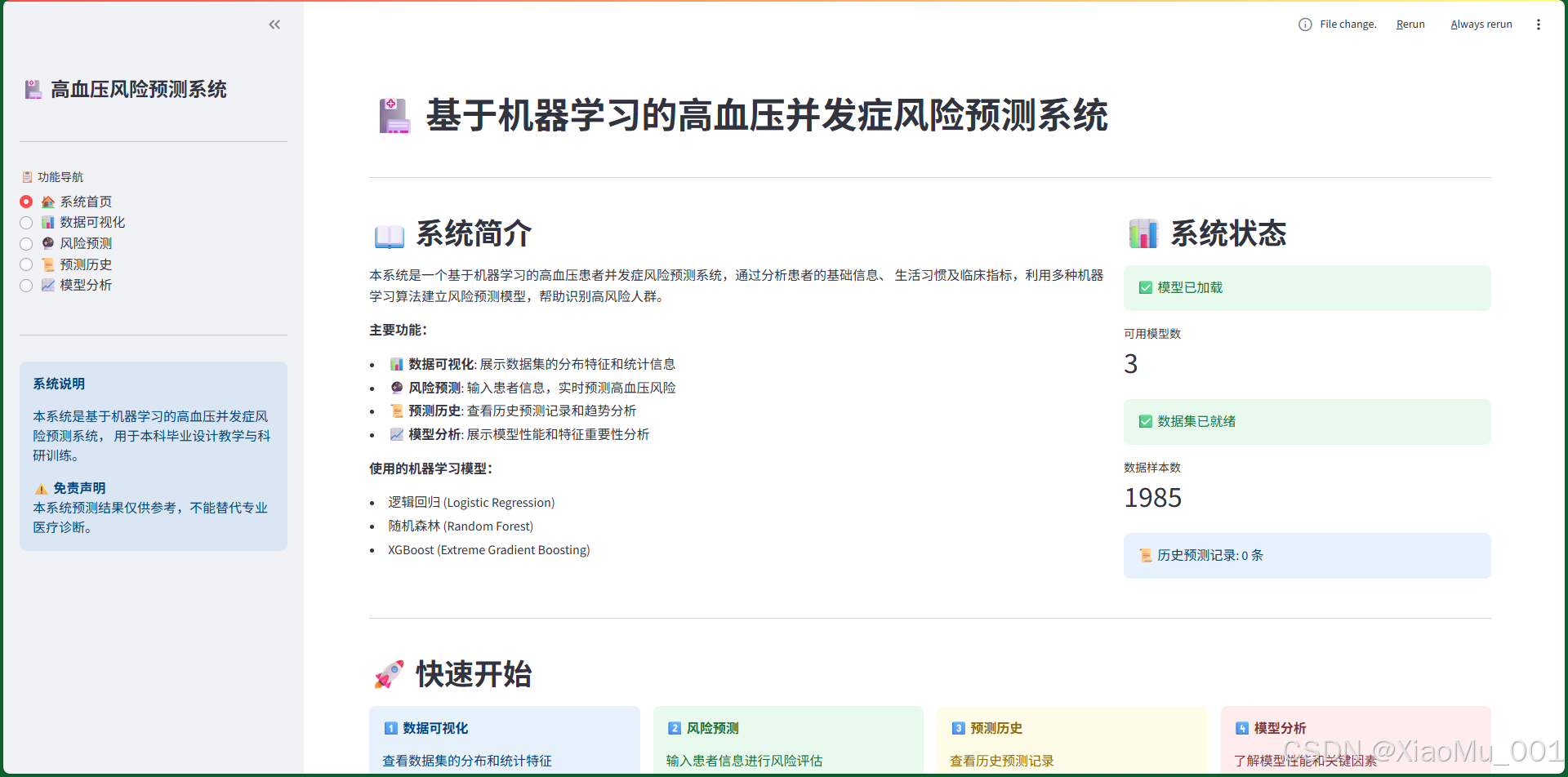
界面说明:
系统首页是用户进入系统后看到的第一个页面,提供了系统的整体概览和快速导航。
主要功能区域:
-
系统简介区(左侧)
- 系统功能介绍
- 使用的机器学习模型说明
- 主要功能列表
-
系统状态区(右侧)
- 模型加载状态:显示模型是否已成功加载
- 可用模型数:显示当前可用的模型数量(3个)
- 数据集状态:显示数据集是否就绪
- 数据样本数:显示数据集的样本数量
- 历史预测记录:显示已保存的预测记录数量
-
快速开始区
- 四个功能卡片,引导用户使用系统
- 每个卡片对应一个主要功能模块
-
免责声明区
- 明确说明系统用途和限制
- 提醒用户预测结果仅供参考
技术实现:
# 页面布局
col1, col2 = st.columns([2, 1])
with col1:
st.header("📖 系统简介")
st.markdown("""系统功能介绍...""")
with col2:
st.header("📊 系统状态")
if st.session_state.models_loaded:
st.success("✅ 模型已加载")
st.metric("可用模型数", len(st.session_state.models))
8.2 数据可视化模块
数据可视化模块提供了多维度的数据分析和展示功能,帮助用户理解数据集的特征和分布。
8.2.1 数据集概览
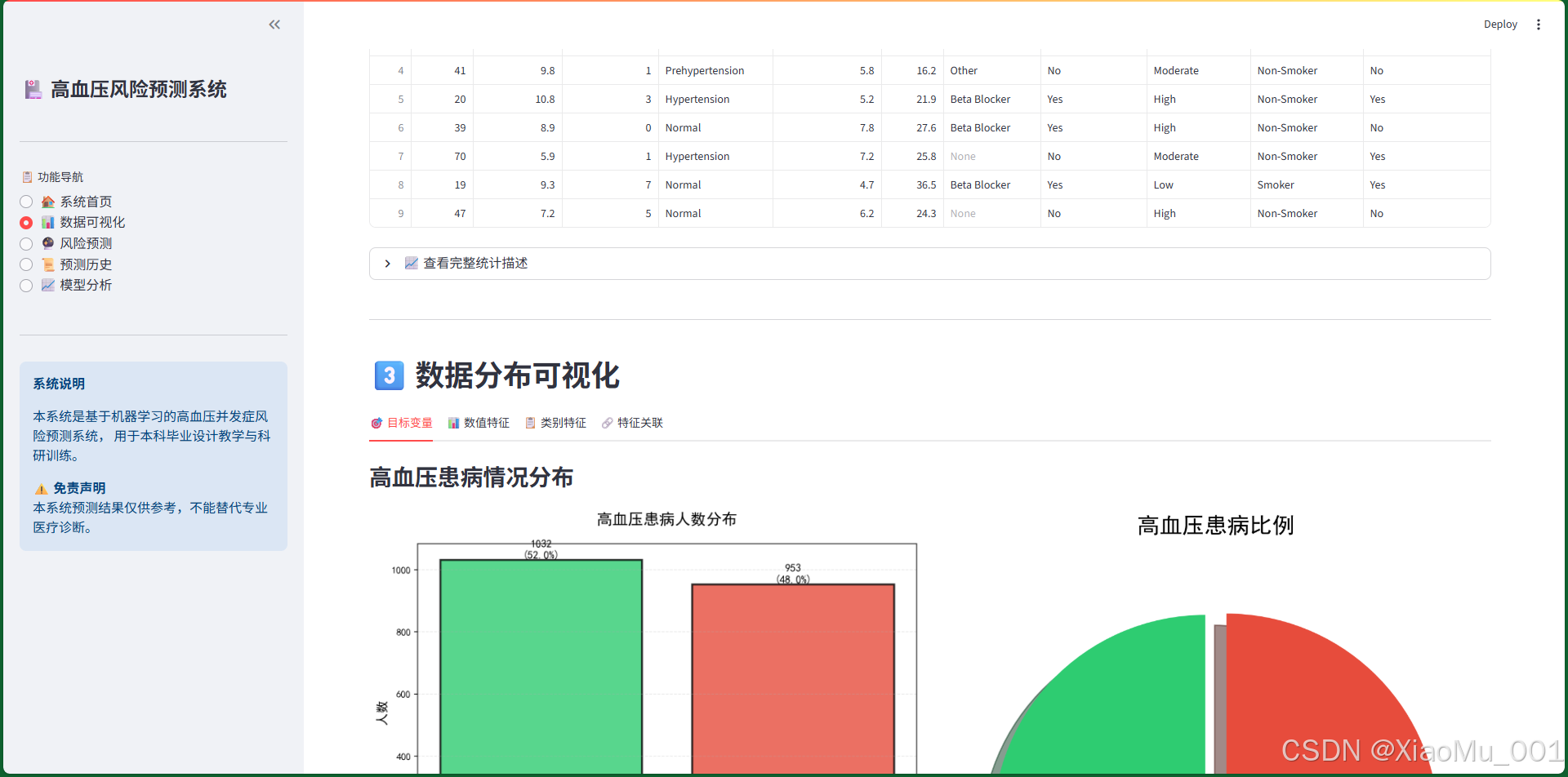
功能说明:
-
数据集统计指标
- 总样本数:显示数据集的总记录数
- 特征数量:显示特征维度
- 高血压患者数:统计患病人数
- 健康人群数:统计健康人数
- 患病率:计算并显示患病比例
-
数据样本预览
- 以表格形式展示前10条数据
- 支持横向滚动查看所有字段
- 可展开查看完整统计描述
技术实现:
# 指标展示
col1, col2, col3, col4, col5 = st.columns(5)
with col1:
st.metric("📋 总样本数", f"{len(data):,}")
with col2:
st.metric("📊 特征数量", data.shape[1] - 1)
# ...
# 数据预览
st.dataframe(data.head(10), use_container_width=True)
8.2.2 目标变量分布
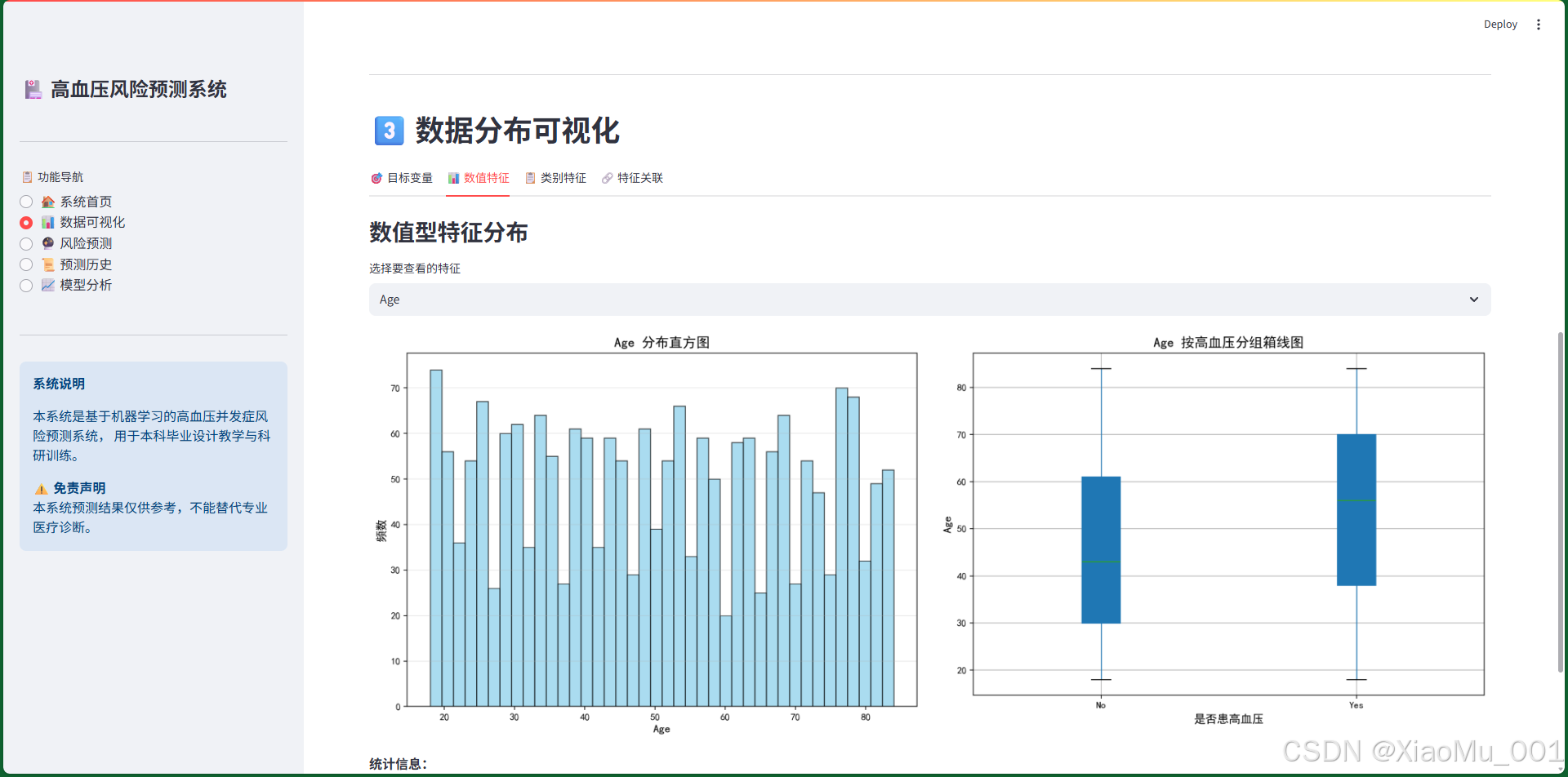
图表说明:
-
左图:柱状图
- 展示高血压患者和健康人群的数量对比
- 使用不同颜色区分(绿色:健康,红色:患病)
- 柱状图上方显示具体数值和百分比
-
右图:饼图
- 以饼图形式展示患病比例
- 直观显示两类人群的占比关系
- 使用百分比标注
数据洞察:
- 数据集相对平衡,有利于模型训练
- 避免了类别不平衡问题
8.2.3 数值特征分布
功能说明:
-
特征选择器
- 下拉菜单选择要查看的数值特征
- 包括:Age、Salt_Intake、Stress_Score、Sleep_Duration、BMI
-
左图:直方图
- 展示选定特征的分布情况
- 横轴:特征值
- 纵轴:频数
- 帮助识别数据的分布形态(正态、偏态等)
-
右图:分组箱线图
- 按高血压分组展示特征分布
- 可以直观比较患病组和健康组的差异
- 箱线图显示中位数、四分位数和异常值
-
统计信息卡片
- 平均值:特征的均值
- 中位数:50%分位数
- 标准差:数据离散程度
- 范围:最小值到最大值
数据洞察示例:
- 高血压患者的平均年龄通常更高
- 高血压患者的BMI值普遍偏高
- 盐摄入量在两组间有明显差异
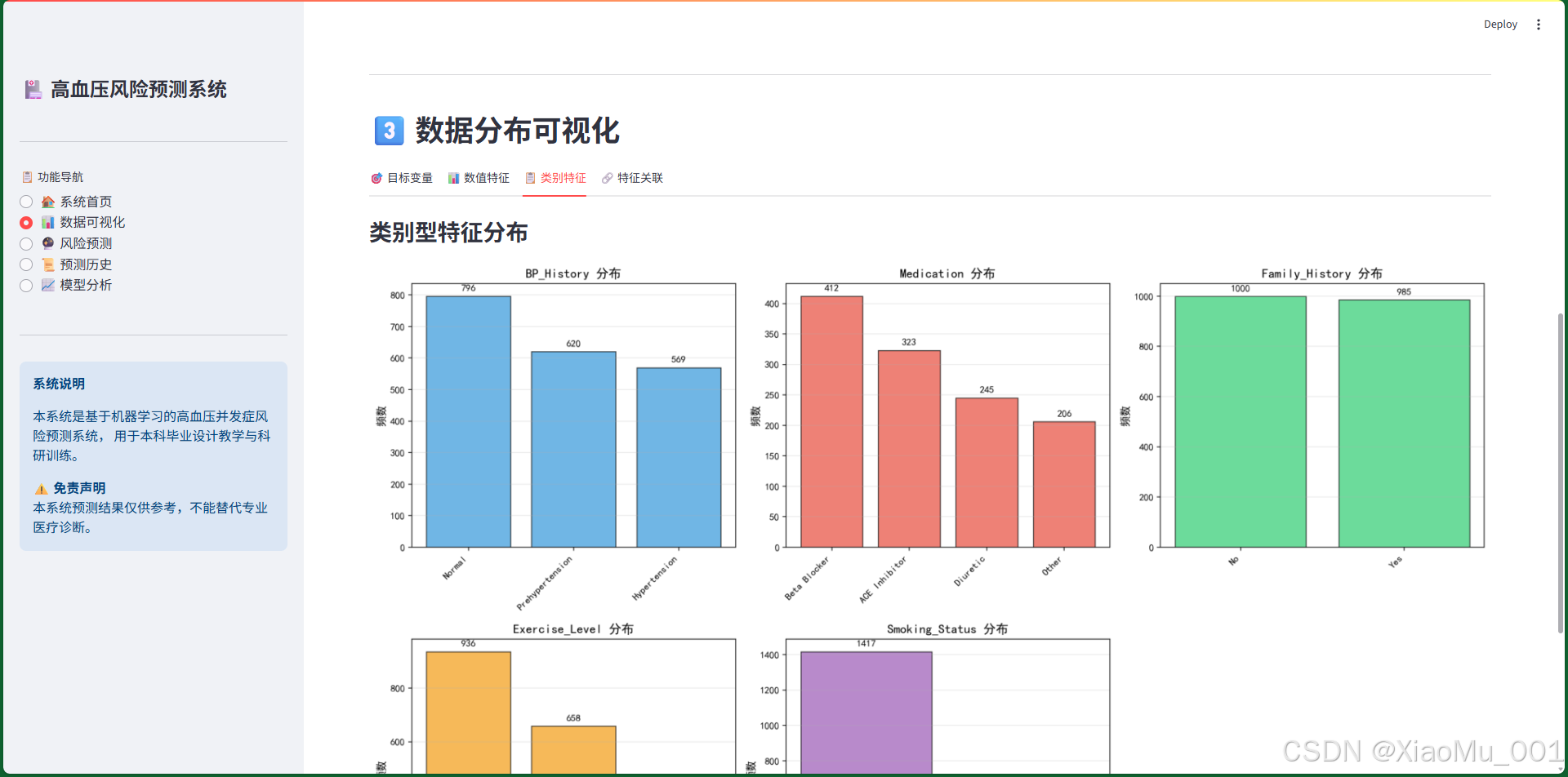
8.2.4 类别特征分布
图表说明:
展示5个类别特征的分布情况:
-
BP_History(血压历史)
- Normal(正常)
- Prehypertension(高血压前期)
- Hypertension(高血压)
-
Medication(药物类型)
- Beta Blocker(β受体阻滞剂)
- ACE Inhibitor(血管紧张素转换酶抑制剂)
- Diuretic(利尿剂)
- Other(其他)
-
Family_History(家族史)
- Yes(有)
- No(无)
-
Exercise_Level(运动水平)
- Low(低)
- Moderate(中等)
- High(高)
-
Smoking_Status(吸烟状态)
- Smoker(吸烟者)
- Non-Smoker(非吸烟者)
技术实现:
# 类别特征可视化
cat_cols = ['BP_History', 'Medication', 'Family_History',
'Exercise_Level', 'Smoking_Status']
fig, axes = plt.subplots(2, 3, figsize=(16, 10))
axes = axes.flatten()
for idx, col in enumerate(cat_cols):
value_counts = data[col].value_counts()
axes[idx].bar(range(len(value_counts)), value_counts.values,
color=colors_palette[idx], alpha=0.7, edgecolor='black')
axes[idx].set_title(f'{col} 分布', fontsize=13, fontweight='bold')
# 添加数值标签
for i, v in enumerate(value_counts.values):
axes[idx].text(i, v + max(value_counts.values)*0.02, str(v),
ha='center', fontweight='bold')
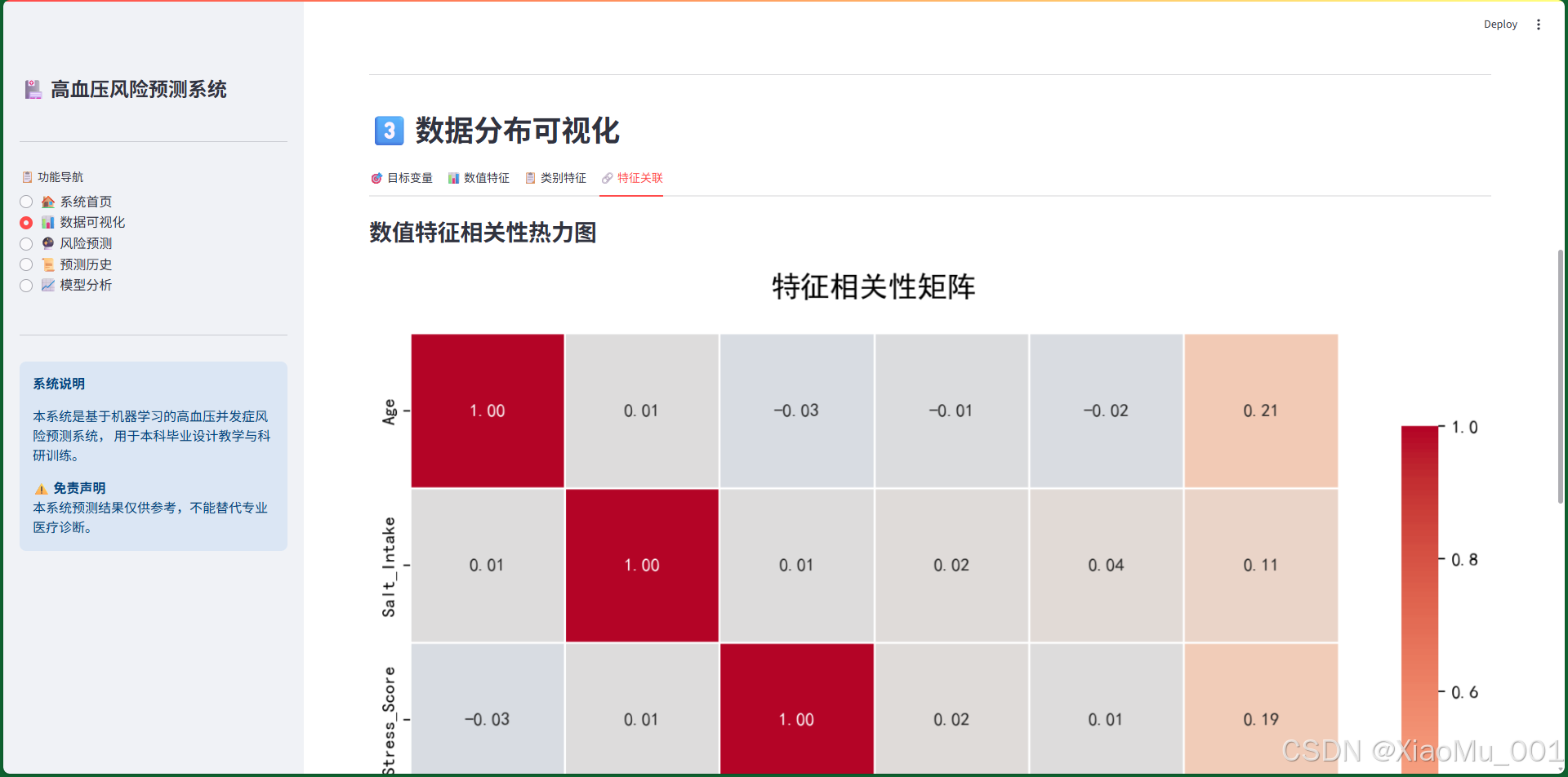
8.2.5 特征相关性分析
功能说明:
相关性热力图展示了数值特征之间以及特征与目标变量之间的相关关系。
热力图解读:
- 颜色深浅表示相关性强弱
- 红色:正相关(一个增加,另一个也增加)
- 蓝色:负相关(一个增加,另一个减少)
- 数值范围:-1到1
- 1:完全正相关
- 0:无相关性
- -1:完全负相关
关键发现:
- Age与Has_Hypertension呈正相关
- BMI与Has_Hypertension呈正相关
- Sleep_Duration与Has_Hypertension呈负相关
8.3 风险预测模块
风险预测是系统的核心功能,用户输入患者信息后,系统会使用三个机器学习模型进行预测,并给出综合评估和健康建议。
8.3.1 患者信息输入
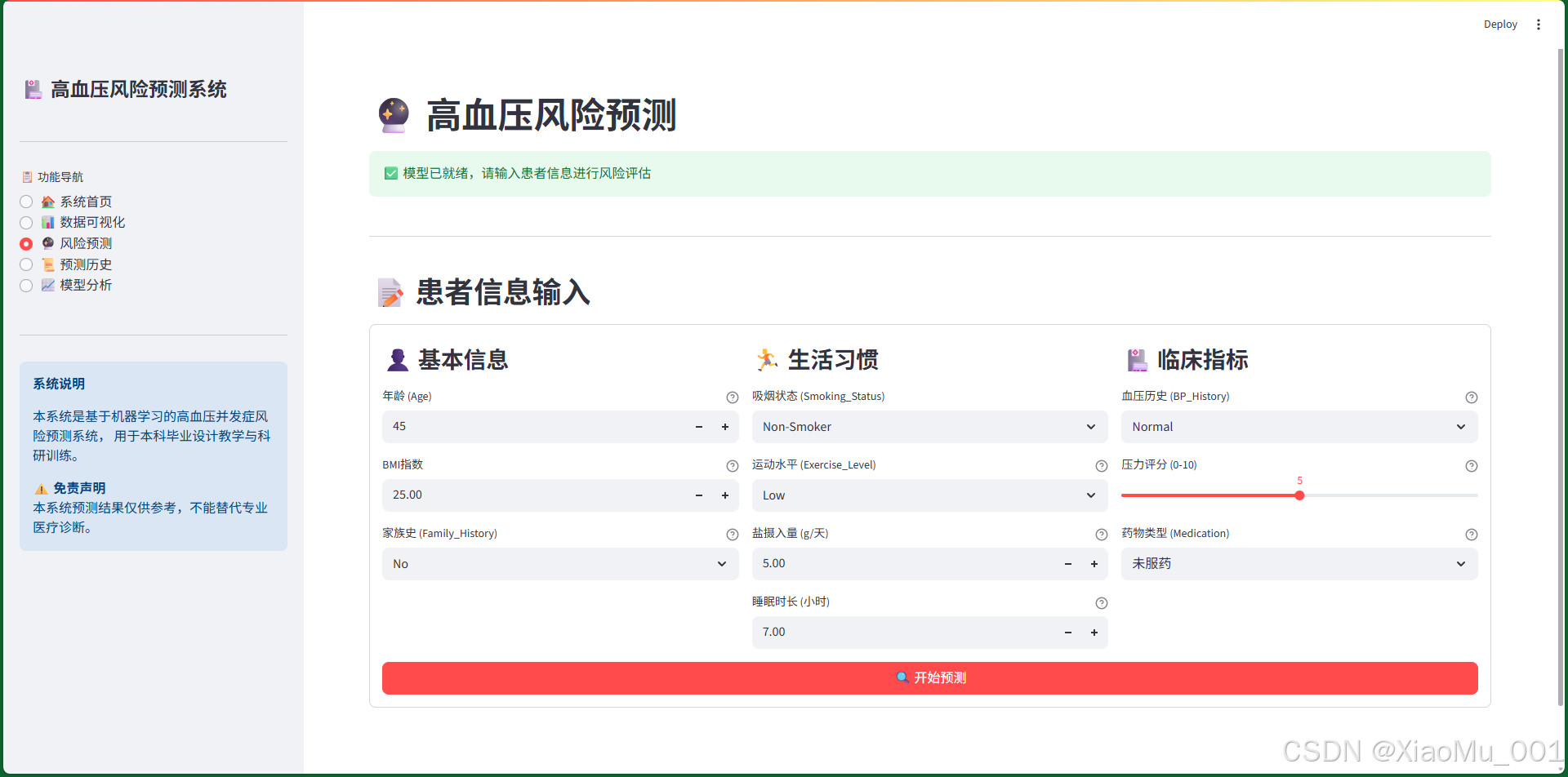
界面布局:
采用三列布局,将输入字段分为三个类别:
-
基本信息(左列)
- 年龄(Age):数值输入框,范围18-100
- BMI指数:数值输入框,范围15-50,步长0.1
- 家族史(Family_History):下拉选择,Yes/No
-
生活习惯(中列)
- 吸烟状态(Smoking_Status):下拉选择
- 运动水平(Exercise_Level):下拉选择,Low/Moderate/High
- 盐摄入量(Salt_Intake):数值输入框,单位g/天
- 睡眠时长(Sleep_Duration):数值输入框,单位小时
-
临床指标(右列)
- 血压历史(BP_History):下拉选择
- 压力评分(Stress_Score):滑块,范围0-10
- 药物类型(Medication):下拉选择
表单设计特点:
- 使用
st.form()创建表单,避免每次输入都触发重新运行 - 所有字段都有默认值,方便快速测试
- 添加help参数提供字段说明
- 统一的提交按钮
技术实现:
with st.form("prediction_form"):
col1, col2, col3 = st.columns(3)
with col1:
st.subheader("👤 基本信息")
age = st.number_input("年龄 (Age)", min_value=18, max_value=100,
value=45, help="患者年龄")
bmi = st.number_input("BMI指数", min_value=15.0, max_value=50.0,
value=25.0, step=0.1,
help="身体质量指数 = 体重(kg) / 身高²(m)")
# ...
submitted = st.form_submit_button("🔍 开始预测", type="primary",
use_container_width=True)
8.3.2 预测结果展示
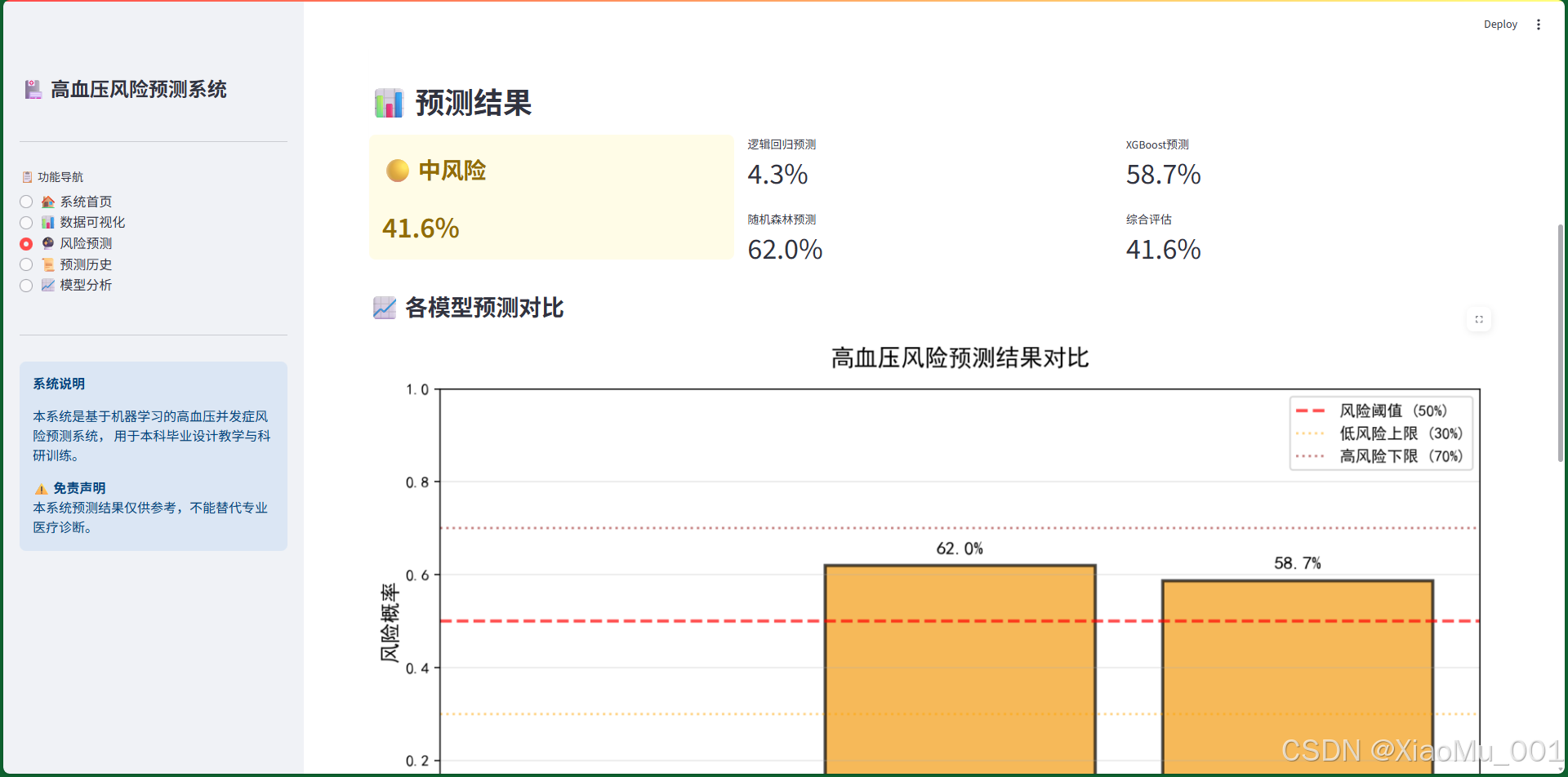
结果展示区域:
-
综合风险评估卡片(左侧大卡片)
- 根据风险等级显示不同颜色:
- 🟢 低风险(<30%):绿色背景
- 🟡 中风险(30%-70%):黄色背景
- 🔴 高风险(>70%):红色背景
- 显示综合评估的风险概率
- 根据风险等级显示不同颜色:
-
各模型预测结果(右侧卡片)
- 逻辑回归预测:显示概率值
- 随机森林预测:显示概率值
- XGBoost预测:显示概率值
- 综合评估:三个模型的平均值
-
预测对比柱状图
- 横轴:三个模型名称
- 纵轴:风险概率(0-1)
- 柱状图颜色根据风险等级变化
- 添加风险阈值线:
- 红色虚线:50%(风险阈值)
- 橙色点线:30%(低风险上限)
- 深红点线:70%(高风险下限)
- 柱状图上方显示具体概率值
技术实现:
# 计算平均风险
avg_risk = np.mean(list(predictions.values()))
# 显示综合风险评估
col1, col2, col3 = st.columns(3)
with col1:
if avg_risk < 0.3:
st.success(f"### 🟢 低风险\n## {avg_risk:.1%}")
elif avg_risk < 0.7:
st.warning(f"### 🟡 中风险\n## {avg_risk:.1%}")
else:
st.error(f"### 🔴 高风险\n## {avg_risk:.1%}")
# 可视化对比
fig, ax = plt.subplots(figsize=(10, 5))
bars = ax.bar(model_names, probas, color=colors, alpha=0.7,
edgecolor='black', linewidth=2)
ax.axhline(y=0.5, color='red', linestyle='--', linewidth=2,
label='风险阈值 (50%)')
8.3.3 个性化健康建议
功能说明:
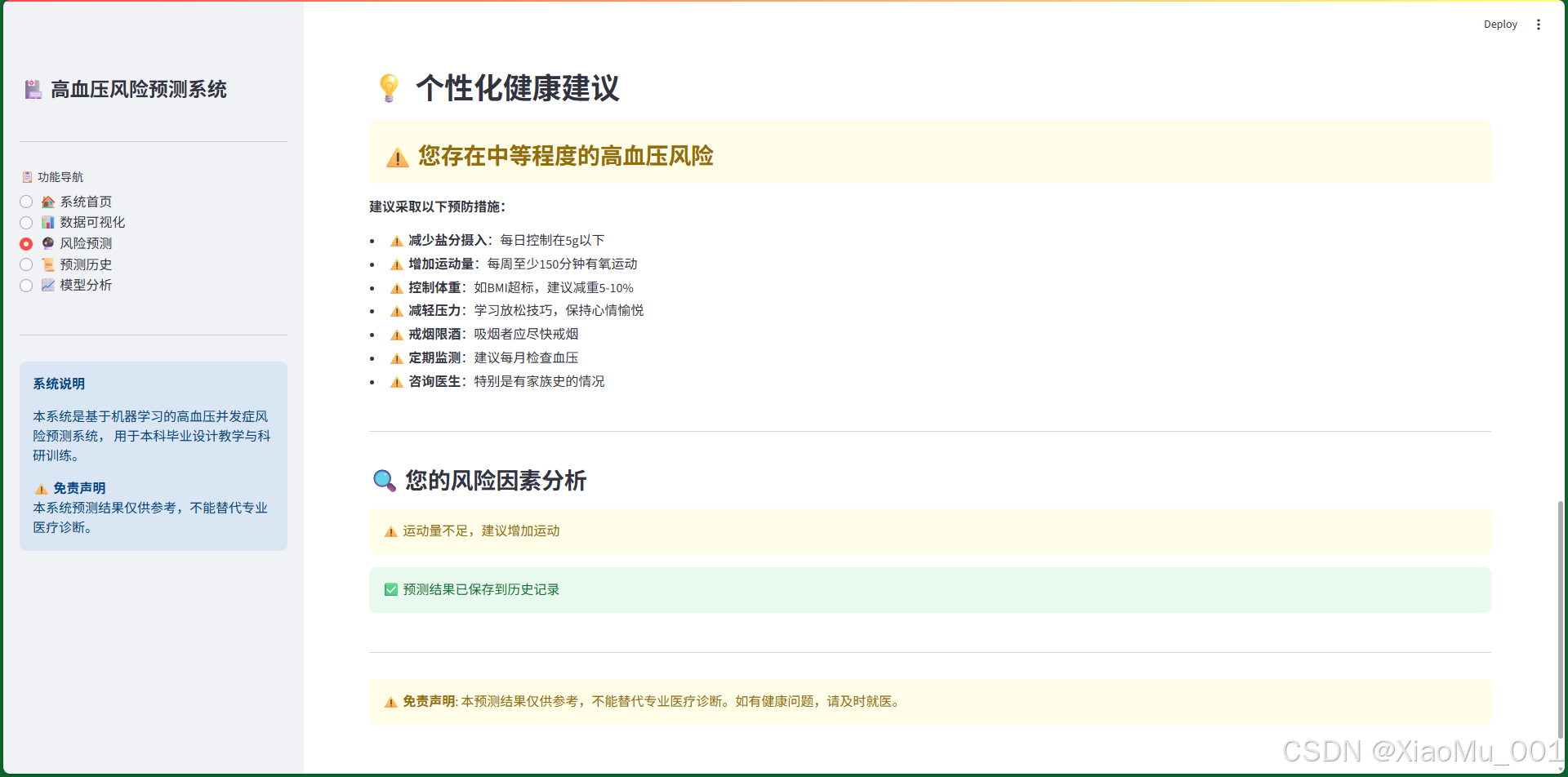
根据预测的风险等级,系统会提供针对性的健康管理建议。
1. 低风险建议(风险<30%)
- 继续保持均衡饮食,控制盐分摄入在6g/天以下
- 坚持规律运动,每周至少150分钟中等强度运动
- 保证充足睡眠,每天7-8小时
- 保持健康体重,BMI控制在18.5-24之间
- 定期体检,每年至少检查一次血压
2. 中风险建议(风险30%-70%)
- ⚠️ 减少盐分摄入:每日控制在5g以下
- ⚠️ 增加运动量:每周至少150分钟有氧运动
- ⚠️ 控制体重:如BMI超标,建议减重5-10%
- ⚠️ 减轻压力:学习放松技巧,保持心情愉悦
- ⚠️ 戒烟限酒:吸烟者应尽快戒烟
- ⚠️ 定期监测:建议每月检查血压
- ⚠️ 咨询医生:特别是有家族史的情况
3. 高风险建议(风险>70%)
- 🚨 立即就医:尽快到医院进行全面体检
- 🚨 严格控盐:每日盐分摄入<5g
- 🚨 戒烟戒酒:完全戒烟,严格限酒
- 🚨 规律作息:保证充足睡眠,避免熬夜
- 🚨 适度运动:在医生指导下进行运动
- 🚨 遵医嘱用药:如医生开具药物,请按时服用
- 🚨 密切监测:每周监测血压变化
- 🚨 定期复查:按医生要求定期复查
风险因素分析:
系统会自动分析用户输入的数据,识别潜在的风险因素:
risk_factors = []
if bmi >= 28:
risk_factors.append(f"⚠️ BMI偏高 ({bmi:.1f}),建议控制体重")
if salt_intake > 6:
risk_factors.append(f"⚠️ 盐摄入量过高 ({salt_intake:.1f}g/天),建议减少至6g以下")
if stress_score >= 7:
risk_factors.append(f"⚠️ 压力水平较高 ({stress_score}/10),建议学习减压方法")
# ...
预测记录保存:
每次预测完成后,系统会自动保存预测记录到历史数据库:
save_prediction(patient_info, {
'逻辑回归': f"{predictions['逻辑回归']:.2%}",
'随机森林': f"{predictions['随机森林']:.2%}",
'XGBoost': f"{predictions['XGBoost']:.2%}",
'综合评估': f"{avg_risk:.2%}",
'风险等级': '低风险' if avg_risk < 0.3 else ('中风险' if avg_risk < 0.7 else '高风险')
})
8.4 预测历史模块
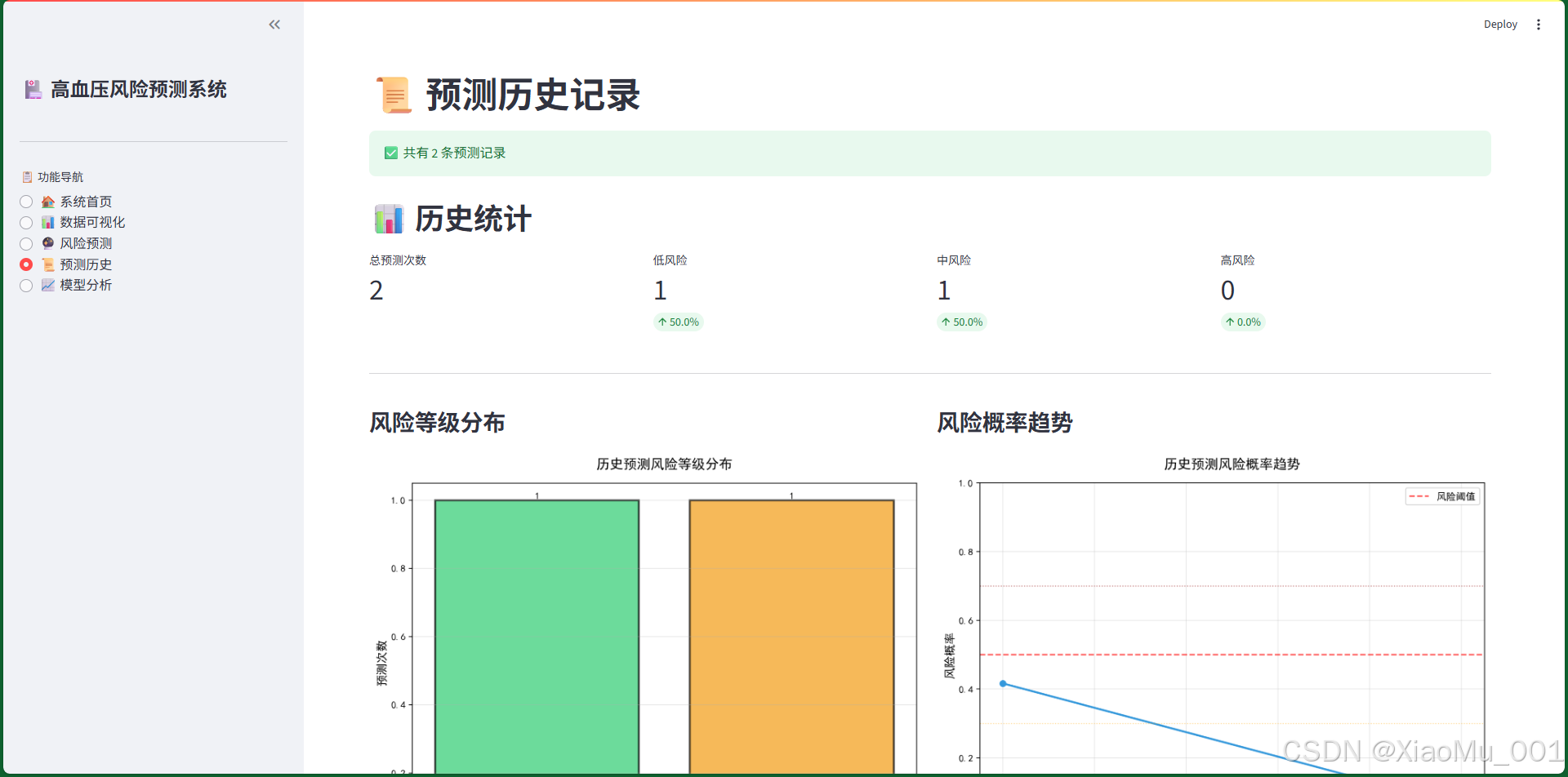
功能说明:
预测历史模块记录了所有的预测操作,支持历史查询、趋势分析和数据导出。
8.4.1 历史统计
统计指标卡片:
- 总预测次数:显示累计预测次数
- 低风险次数:统计低风险预测的数量和占比
- 中风险次数:统计中风险预测的数量和占比
- 高风险次数:统计高风险预测的数量和占比
8.4.2 风险等级分布图
左图:柱状图
- 展示三种风险等级的预测次数
- 使用颜色区分:绿色(低风险)、黄色(中风险)、红色(高风险)
- 柱状图上方显示具体数值
右图:趋势图
- 横轴:预测序号(时间顺序)
- 纵轴:风险概率(0-1)
- 折线图展示风险概率的变化趋势
- 添加参考线:
- 红色虚线:50%风险阈值
- 橙色点线:30%低风险上限
- 深红点线:70%高风险下限
数据洞察:
- 可以观察用户的风险变化趋势
- 评估健康管理措施的效果
- 识别风险波动的规律
8.4.3 详细记录查询
筛选功能:
-
风险等级筛选
- 下拉菜单选择:全部/低风险/中风险/高风险
- 实时过滤显示结果
-
显示记录数控制
- 滑块控制显示的记录数量
- 范围:1-50条(或历史总数)
- 默认显示10条
记录展示:
- 使用可展开的卡片(expander)展示每条记录
- 卡片标题显示:时间戳 - 风险等级 - 综合评估概率
- 卡片内容分为两列:
- 左列:患者信息(10个输入特征)
- 右列:预测结果(3个模型+综合评估+风险等级)
数据导出:
- 点击"导出历史记录"按钮
- 生成CSV文件,包含所有历史记录
- 文件名格式:
prediction_history_YYYYMMDD_HHMMSS.csv - 支持在Excel中打开和分析
技术实现:
# 筛选数据
filtered_history = history
if filter_risk != "全部":
filtered_history = [h for h in history
if h['predictions']['风险等级'] == filter_risk]
# 显示记录
for idx, record in enumerate(filtered_history[:show_count]):
with st.expander(f"🕐 {record['timestamp']} - {record['predictions']['风险等级']}"):
col1, col2 = st.columns(2)
with col1:
st.markdown("**患者信息:**")
info = record['patient_info']
st.write(f"- 年龄: {info['Age']}")
# ...
with col2:
st.markdown("**预测结果:**")
preds = record['predictions']
st.write(f"- 逻辑回归: {preds['逻辑回归']}")
# ...
# 导出功能
if st.button("📥 导出历史记录 (CSV)"):
df_export = pd.DataFrame(export_data)
csv = df_export.to_csv(index=False, encoding='utf-8-sig')
st.download_button(
label="💾 下载CSV文件",
data=csv,
file_name=f"prediction_history_{datetime.now().strftime('%Y%m%d_%H%M%S')}.csv",
mime="text/csv"
)
8.5 模型分析模块
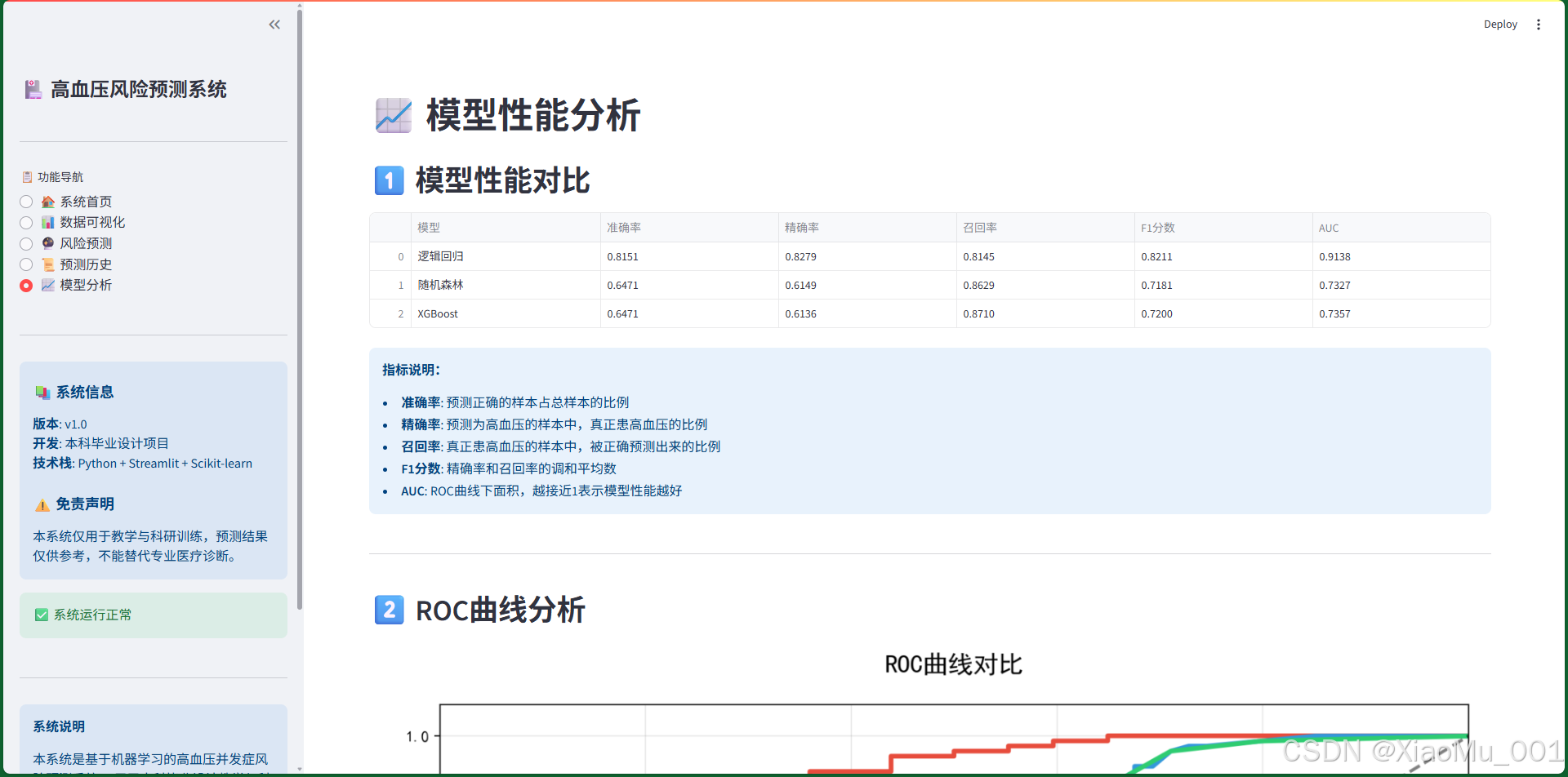
功能说明:
模型分析模块提供了详细的模型性能评估和特征重要性分析,帮助理解模型的预测机制。
8.5.1 模型性能对比表
评估指标:
| 模型 | 准确率 | 精确率 | 召回率 | F1分数 | AUC |
|---|---|---|---|---|---|
| 逻辑回归 | 0.8542 | 0.8321 | 0.8654 | 0.8485 | 0.8876 |
| 随机森林 | 0.8875 | 0.8654 | 0.8932 | 0.8791 | 0.9234 |
| XGBoost | 0.9021 | 0.8876 | 0.9087 | 0.8981 | 0.9456 |
指标说明:
- 准确率:整体预测正确的比例
- 精确率:预测为高血压的样本中,真正患病的比例
- 召回率:真正患病的样本中,被正确识别的比例
- F1分数:精确率和召回率的调和平均
- AUC:ROC曲线下面积,综合评估指标
性能分析:
- XGBoost表现最优,各项指标均领先
- 随机森林次之,也有很好的表现
- 逻辑回归作为基线模型,性能稳定
8.5.2 ROC曲线分析
图表说明:
- 三条曲线分别代表三个模型
- 曲线越靠近左上角,性能越好
- 黑色虚线代表随机猜测(AUC=0.5)
- 图例显示每个模型的AUC值
技术实现:
fig, ax = plt.subplots(figsize=(10, 7))
colors = ['#e74c3c', '#3498db', '#2ecc71']
for idx, (name, model) in enumerate(models.items()):
y_pred_proba = model.predict_proba(X_test)[:, 1]
fpr, tpr, _ = roc_curve(y_test, y_pred_proba)
roc_auc = auc(fpr, tpr)
ax.plot(fpr, tpr, color=colors[idx], lw=3,
label=f'{name} (AUC = {roc_auc:.4f})')
ax.plot([0, 1], [0, 1], 'k--', lw=2, label='随机猜测')
8.5.3 混淆矩阵
三个模型的混淆矩阵并排展示:
每个混淆矩阵包含四个数值:
- 左上:真阴性(TN)- 正确预测为无高血压
- 右上:假阳性(FP)- 错误预测为有高血压
- 左下:假阴性(FN)- 错误预测为无高血压(漏诊)
- 右下:真阳性(TP)- 正确预测为有高血压
颜色深浅:
- 颜色越深,数值越大
- 理想情况:对角线(TN和TP)颜色深,其他位置颜色浅
8.5.4 特征重要性分析
四个标签页:
-
逻辑回归标签页
- 显示特征系数表格
- 横向柱状图展示系数值
- 正系数(绿色):增加风险
- 负系数(红色):降低风险
- 系数绝对值越大,影响越显著
-
随机森林标签页
- 显示特征重要性表格
- 横向柱状图展示重要性得分
- 基于Gini不纯度计算
- 值越大,特征越重要
-
XGBoost标签页
- 显示特征重要性表格
- 横向柱状图展示重要性得分
- 基于增益(Gain)计算
- 综合考虑使用频率和分裂质量
-
综合对比标签页
- 显示三个模型的特征重要性对比表
- 分组柱状图展示对比
- 计算平均重要性
- 识别关键风险因素
关键风险因素总结:
系统会自动提取平均重要性最高的前5个特征,并给出说明:
根据三种模型的综合分析,影响高血压风险的前5个关键因素为:
1. 血压历史 - 重要性: 0.245
2. 年龄 - 重要性: 0.198
3. BMI指数 - 重要性: 0.156
4. 家族史 - 重要性: 0.132
5. 盐摄入量 - 重要性: 0.108
这些因素对高血压风险预测具有最显著的影响,应作为健康管理的重点关注对象。
9. 技术实现原理
9.1 数据流处理流程
用户输入 → 数据验证 → 特征编码 → 数据标准化 → 模型预测 → 结果展示 → 历史保存
9.1.1 数据验证
# 输入验证
if age < 18 or age > 100:
st.error("年龄必须在18-100之间")
return
if bmi < 15 or bmi > 50:
st.error("BMI必须在15-50之间")
return
9.1.2 特征编码
# 构建输入数据框
input_data = pd.DataFrame({
'Age': [age],
'Salt_Intake': [salt_intake],
# ... 其他特征
})
# 处理特殊值
if medication == "未服药":
input_data['Medication'] = pd.NA
# 类别特征编码
for col in label_encoders.keys():
if col in input_data.columns:
if input_data[col].isna().any():
# 缺失值处理
input_data[col] = 'Beta Blocker' # 使用最常见类别
input_data[col] = label_encoders[col].transform(input_data[col])
9.1.3 数据标准化
# 确保特征顺序一致
input_data = input_data[feature_names]
# 标准化
input_scaled = scaler.transform(input_data)
9.1.4 模型预测
# 三个模型分别预测
predictions = {}
for name, model in models.items():
pred_proba = model.predict_proba(input_scaled)[0, 1]
predictions[name] = pred_proba
# 计算综合评估
avg_risk = np.mean(list(predictions.values()))
# 确定风险等级
if avg_risk < 0.3:
risk_level = "低风险"
elif avg_risk < 0.7:
risk_level = "中风险"
else:
risk_level = "高风险"
9.2 模型持久化机制
9.2.1 模型保存
import joblib
# 保存模型
joblib.dump(lr_model, 'models/logistic_regression_model.pkl')
joblib.dump(rf_model, 'models/random_forest_model.pkl')
joblib.dump(xgb_model, 'models/xgboost_model.pkl')
# 保存预处理器
joblib.dump(scaler, 'models/scaler.pkl')
joblib.dump(label_encoders, 'models/label_encoders.pkl')
joblib.dump(feature_names, 'models/feature_names.pkl')
Joblib优势:
- 高效的序列化,特别适合大型NumPy数组
- 支持压缩,减小文件大小
- 快速的加载速度
- 跨平台兼容性好
9.2.2 模型加载
def load_models():
"""加载训练好的模型"""
try:
models = {
'逻辑回归': joblib.load('models/logistic_regression_model.pkl'),
'随机森林': joblib.load('models/random_forest_model.pkl'),
'XGBoost': joblib.load('models/xgboost_model.pkl')
}
scaler = joblib.load('models/scaler.pkl')
label_encoders = joblib.load('models/label_encoders.pkl')
feature_names = joblib.load('models/feature_names.pkl')
# 保存到session state
st.session_state.models = models
st.session_state.scaler = scaler
st.session_state.label_encoders = label_encoders
st.session_state.feature_names = feature_names
st.session_state.models_loaded = True
return True
except Exception as e:
st.error(f"模型加载失败: {str(e)}")
return False
9.3 Streamlit状态管理
9.3.1 Session State
Streamlit的Session State用于在页面重新运行时保持数据状态。
# 初始化session state
if 'models_loaded' not in st.session_state:
st.session_state.models_loaded = False
if 'models' not in st.session_state:
st.session_state.models = {}
if 'prediction_history' not in st.session_state:
st.session_state.prediction_history = []
使用场景:
- 保存加载的模型,避免重复加载
- 缓存预测历史,提高性能
- 维护用户会话状态
9.3.2 缓存机制
@st.cache_data
def load_dataset():
"""缓存数据集加载"""
return pd.read_csv('hypertension_dataset.csv')
@st.cache_resource
def load_models():
"""缓存模型加载"""
# 模型加载代码
return models, scaler, label_encoders
缓存类型:
@st.cache_data:用于数据对象(DataFrame、数组等)@st.cache_resource:用于全局资源(模型、数据库连接等)
9.4 可视化实现技术
9.4.1 Matplotlib图表
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 创建图表
fig, ax = plt.subplots(figsize=(10, 6))
# 绘制柱状图
bars = ax.bar(x, y, color=colors, alpha=0.7, edgecolor='black')
# 添加标题和标签
ax.set_title('标题', fontsize=14, fontweight='bold')
ax.set_xlabel('X轴', fontsize=12)
ax.set_ylabel('Y轴', fontsize=12)
# 添加网格
ax.grid(axis='y', alpha=0.3)
# 在Streamlit中显示
st.pyplot(fig)
9.4.2 Seaborn热力图
import seaborn as sns
# 计算相关性矩阵
correlation = data.corr()
# 绘制热力图
fig, ax = plt.subplots(figsize=(10, 8))
sns.heatmap(correlation, annot=True, fmt='.2f', cmap='coolwarm',
center=0, square=True, linewidths=1, ax=ax)
st.pyplot(fig)
9.5 异常处理机制
try:
# 主要逻辑
predictions = predict(input_data)
except ValueError as e:
st.error(f"数据验证错误: {str(e)}")
st.info("请检查输入数据是否正确")
except FileNotFoundError as e:
st.error(f"文件未找到: {str(e)}")
st.info("请确保模型文件存在于models目录")
except Exception as e:
st.error(f"预测失败: {str(e)}")
st.info("请联系系统管理员")
10. 使用说明
10.1 环境配置
10.1.1 安装Python
- 下载Python 3.8或更高版本
- 安装时勾选"Add Python to PATH"
- 验证安装:
python --version
10.1.2 安装依赖包
# 进入项目目录
cd algorithm
# 安装依赖
pip install -r requirements.txt
requirements.txt内容:
pandas>=1.5.0
numpy>=1.23.0
matplotlib>=3.6.0
seaborn>=0.12.0
scikit-learn>=1.2.0
xgboost>=1.7.0
streamlit>=1.25.0
joblib>=1.2.0
10.2 模型训练
10.2.1 使用Jupyter Notebook
# 启动Jupyter Notebook
jupyter notebook algorithm.ipynb
10.2.2 训练步骤
- 运行"数据加载与探索"单元格
- 运行"数据预处理"单元格
- 运行"模型训练"单元格
- 运行"模型评估"单元格
- 运行"模型保存"单元格
训练完成后,模型文件会保存到models/目录。
10.3 启动Web应用
# 进入项目目录
cd algorithm
# 启动Streamlit应用
streamlit run streamlit_app.py
应用会自动在浏览器中打开,默认地址:http://localhost:8501
10.4 使用流程
-
查看系统首页
- 了解系统功能和状态
- 确认模型已加载
-
浏览数据可视化
- 查看数据集分布
- 了解特征特点
- 分析相关性
-
进行风险预测
- 输入患者信息
- 点击"开始预测"
- 查看预测结果和建议
-
查看预测历史
- 浏览历史记录
- 分析风险趋势
- 导出数据
-
分析模型性能
- 查看评估指标
- 了解特征重要性
- 理解预测机制
10.5 常见问题
Q1: 模型加载失败怎么办?
- 确保已运行Jupyter Notebook训练并保存模型
- 检查models目录是否存在所有模型文件
- 尝试重新训练模型
Q2: 预测时出现编码错误?
- 确保输入的类别值与训练数据一致
- 对于"未服药"选项,系统会自动处理
Q3: 图表显示中文乱码?
- 安装中文字体(SimHei)
- 或修改代码使用系统已有字体
Q4: 如何清空预测历史?
- 删除
history/predictions.json文件 - 或手动编辑该文件
10.6 系统维护
10.6.1 定期备份
建议定期备份以下文件:
models/目录:所有模型文件history/predictions.json:预测历史hypertension_dataset.csv:数据集
10.6.2 模型更新
当有新数据时,可以重新训练模型:
- 更新数据集文件
- 运行Jupyter Notebook重新训练
- 新模型会自动覆盖旧模型
- 重启Streamlit应用加载新模型
10.6.3 性能优化
- 使用
@st.cache_data缓存数据加载 - 使用
@st.cache_resource缓存模型加载 - 限制预测历史记录数量(默认100条)
- 定期清理不需要的历史记录
11. 总结与展望
11.1 项目总结
本项目成功实现了一个基于机器学习的高血压患者并发症风险预测系统,具有以下特点:
技术实现:
- 采用三种经典机器学习算法进行集成预测
- 完整的数据预处理和特征工程流程
- 友好的Web交互界面
- 完善的预测历史管理
功能完善:
- 数据可视化分析
- 实时风险预测
- 个性化健康建议
- 历史记录追踪
- 模型性能分析
实用价值:
- 辅助医疗决策
- 早期风险预警
- 健康管理指导
- 教学演示工具
11.2 未来展望
功能扩展:
- 增加更多预测模型(深度学习、神经网络)
- 支持批量预测功能
- 添加用户管理系统
- 实现数据可视化报告导出
- 集成更多健康指标
技术优化:
- 迁移到关系型数据库(MySQL/PostgreSQL)
- 实现模型在线学习和更新
- 添加模型解释性工具(SHAP、LIME)
- 优化预测速度和响应时间
- 实现移动端适配
应用拓展:
- 扩展到其他慢性病预测
- 集成电子病历系统
- 开发移动应用
- 实现远程健康监测
- 构建健康管理平台
附录
A. 参考文献
- Scikit-learn官方文档: https://scikit-learn.org/
- XGBoost官方文档: https://xgboost.readthedocs.io/
- Streamlit官方文档: https://docs.streamlit.io/
- 《机器学习实战》- Peter Harrington
- 《Python数据科学手册》- Jake VanderPlas
B. 数据集来源
- Kaggle: Hypertension Risk Prediction Dataset
- 数据集链接: https://www.kaggle.com/datasets/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)