基于评论情感分析与LDA主题模型的短剧流行因素实证研究
基于评论情感分析与LDA主题模型的短剧流行因素实证研究
项目概述
本项目旨在通过数据挖掘和机器学习技术,分析短剧内容特征与用户情感反馈对短剧流行度的影响。项目采用情感分析、主题模型和机器学习预测模型,构建了一个完整的短剧流行因素分析系统。
研究目标
- 情感分析:对短剧描述进行情感分析,识别情感倾向
- 主题挖掘:使用LDA主题模型提取短剧主题
- 流行因素:分析情感倾向、主题分布与短剧流行度的关系
- 预测模型:构建机器学习模型预测短剧流行度
- 系统实现:开发可视化分析系统,提供交互式分析界面
一、数据集介绍
1.1 数据来源
数据来源于众短剧网站(zhongduanju.com),通过Python爬虫自动获取。爬虫系统支持多源数据获取策略,包括首页、分类页、列表页和推荐链接。
1.2 数据集规模
- 总数据量:130条短剧记录
- 爬取时间:50分钟
- 数据格式:CSV格式(UTF-8编码)
- 数据文件:
short_drama_data.csv
1.3 数据字段说明
数据集包含以下20个字段:
| 字段名 | 类型 | 说明 | 示例 |
|---|---|---|---|
| title | VARCHAR(200) | 短剧标题 | “百妖异闻录” |
| drama_id | VARCHAR(100) | 短剧唯一标识 | “bai-yao-yi-wen-lu” |
| category | VARCHAR(50) | 主要分类 | “众短剧” |
| category_list | TEXT | 分类列表(用||分隔) | “众短剧||短剧更新日历||古装仙侠” |
| tags | TEXT | 标签(用||分隔) | “古装||仙侠||奇幻” |
| status | VARCHAR(20) | 状态 | “全集”、“更新中” |
| publish_date | DATE | 发布日期 | “2026-01-10” |
| update_time | VARCHAR(50) | 更新时间 | “1分钟前” |
| description | VARCHAR(500) | 简短描述 | “能看见妖怪的孤女…” |
| description_full | TEXT | 完整描述 | “百妖异闻录 剧情: 能看见妖怪的孤女林小满…” |
| episode_count | INT | 集数 | 30 |
| view_count | VARCHAR(50) | 观看数 | “10万” |
| rating | DECIMAL(3,2) | 评分 | 8.5 |
| comment_count | INT | 评论数 | 0 |
| comments | TEXT | 评论内容(用||分隔) | “很好看||剧情不错” |
| comment_details | JSON | 评论详情(JSON格式) | [{“text”:“很好看”,“user”:“用户1”}] |
| recommendations | JSON | 推荐短剧(JSON格式) | [{“title”:“xxx”,“url”:“…”}] |
| recommendation_titles | TEXT | 推荐短剧标题(用||分隔) | “短剧1||短剧2” |
| url | VARCHAR(500) | 短剧页面URL | “https://zhongduanju.com/play/xxx” |
| crawl_time | DATETIME | 爬取时间 | “2026-01-16 18:32:49” |
1.4 数据特点
- 描述数据完整:所有130条记录都包含描述信息
- 评论数据缺失:所有短剧的comment_count均为0,无法进行评论情感分析
- 描述质量:描述文本长度在100-200字之间,适合进行文本分析
- 分类信息:包含多种分类标签,便于主题分析
1.5 数据预处理
由于评论数据缺失,研究采用短剧描述文本进行情感分析。数据预处理包括:
- 文本清洗(去除特殊字符、统一编码)
- 缺失值处理(使用默认值或删除)
- 文本标准化(统一格式、去除冗余)
二、算法介绍
2.1 情感分析算法
2.1.1 SnowNLP情感分析
技术原理:
SnowNLP是一个专门针对中文文本的情感分析库,基于朴素贝叶斯分类器。其工作原理:
- 训练数据:使用大量中文语料库训练情感分类模型
- 特征提取:提取文本中的情感特征词
- 概率计算:计算文本属于积极情感的概率
- 得分输出:输出0-1之间的情感得分(越接近1越积极)
实现思路:
from snownlp import SnowNLP
def sentiment_analysis(text):
s = SnowNLP(text)
return s.sentiments # 返回0-1之间的得分
情感分类规则:
- 得分 > 0.6:积极情感
- 得分 < 0.4:消极情感
- 0.4 ≤ 得分 ≤ 0.6:中性情感
2.1.2 BERT情感分析(可选)
技术原理:
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的深度双向Transformer模型。
优势:
- 能够理解上下文语境
- 对中文文本有更好的理解能力
- 可以识别细粒度的情感倾向
实现思路:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 加载预训练的中文BERT模型
tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-chinanews-chinese")
model = AutoModelForSequenceClassification.from_pretrained("uer/roberta-base-finetuned-chinanews-chinese")
# 对文本进行编码和预测
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=128)
outputs = model(**inputs)
sentiment_score = torch.softmax(outputs.logits, dim=-1)
对比分析:
- SnowNLP:速度快,适合大规模分析,但准确度相对较低
- BERT:准确度高,能理解上下文,但速度慢,需要更多计算资源
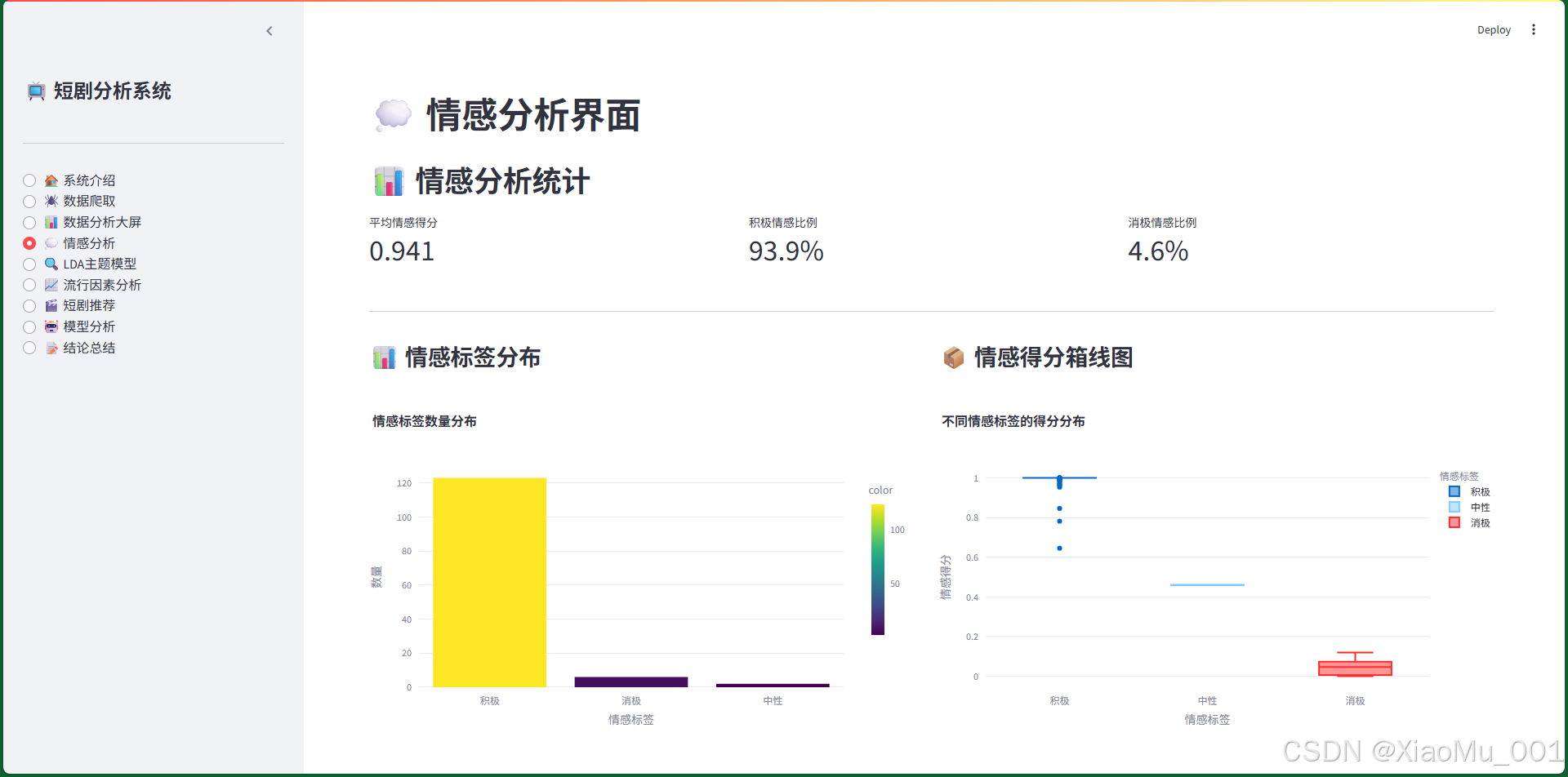
图1:情感分析界面。展示情感得分分布、情感标签统计、情感与流行度关系等可视化图表。
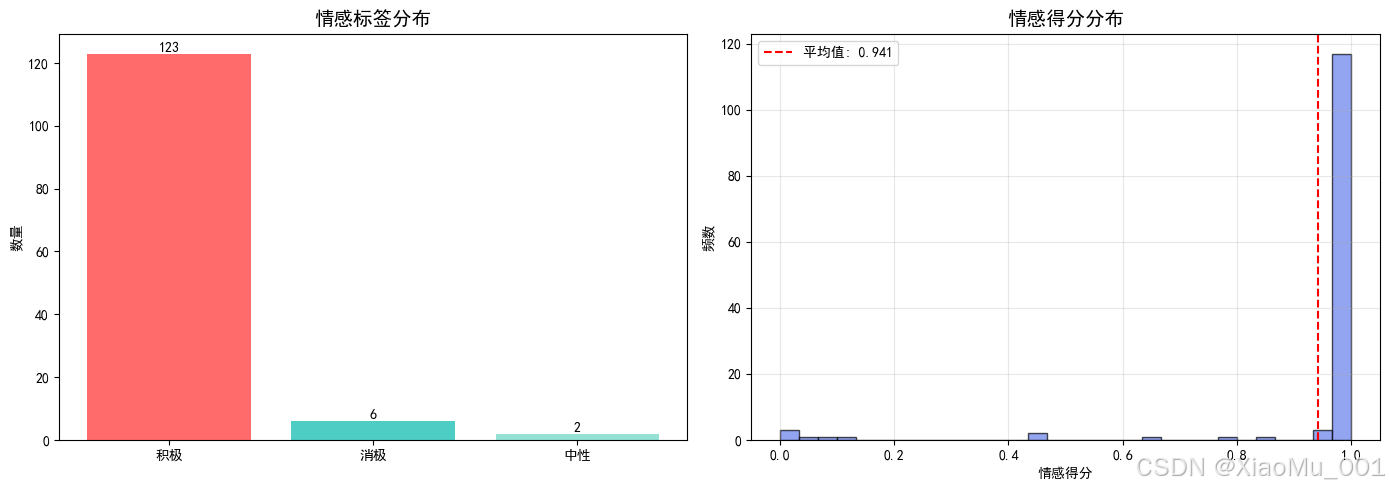
图2:情感分布可视化。展示积极、消极、中性三种情感标签的数量分布,可以看出短剧描述高度积极化。
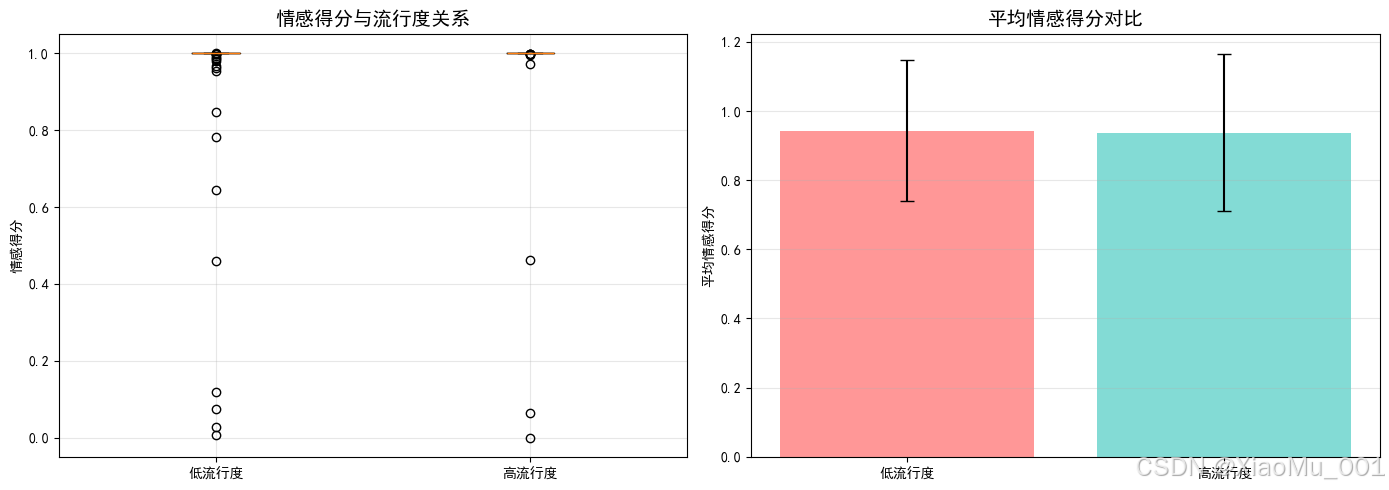
图3:情感得分与流行度关系分析。通过箱线图和散点图展示情感得分与流行度的相关性,发现两者关系不明显(相关系数接近0)。
2.2 LDA主题模型算法
2.2.1 LDA原理
**Latent Dirichlet Allocation(潜在狄利克雷分配)**是一种无监督的主题模型算法。
技术原理:
-
基本假设:
- 每个文档是多个主题的混合
- 每个主题是多个词的分布
- 文档中的每个词都来自某个主题
-
生成过程:
对于每个文档: 1. 从Dirichlet分布中采样主题分布θ 2. 对于文档中的每个词: a. 从主题分布θ中采样一个主题z b. 从主题z的词分布中采样一个词w -
参数说明:
- α(alpha):文档-主题分布的Dirichlet先验参数,控制文档主题分布的稀疏性
- β(beta):主题-词分布的Dirichlet先验参数,控制主题词分布的稀疏性
- 主题数K:需要预先指定的主题数量
2.2.2 实现流程
步骤1:文本预处理
import jieba
import jieba.analyse
# 中文分词
text = "能看见妖怪的孤女林小满,守着爷爷留下的旧书店"
words = jieba.cut(text)
# 去停用词
stopwords = ['的', '了', '在', '是', '我', '有', '和', '就']
words = [w for w in words if w not in stopwords and len(w) > 1]
步骤2:文本向量化
from sklearn.feature_extraction.text import CountVectorizer
# 使用词频向量化
vectorizer = CountVectorizer(max_features=1000)
X = vectorizer.fit_transform(texts)
步骤3:LDA模型训练
from sklearn.decomposition import LatentDirichletAllocation
# 训练LDA模型
lda = LatentDirichletAllocation(
n_components=8, # 主题数
learning_method='online',
random_state=42,
max_iter=10
)
lda.fit(X)
# 获取主题-词分布
feature_names = vectorizer.get_feature_names_out()
for topic_idx, topic in enumerate(lda.components_):
top_words_idx = topic.argsort()[-10:][::-1]
top_words = [feature_names[i] for i in top_words_idx]
print(f"主题 {topic_idx+1}: {', '.join(top_words)}")
步骤4:主题分配
# 为每个文档分配主题
topic_distributions = lda.transform(X)
main_topic = topic_distributions.argmax(axis=1) + 1 # 主要主题
topic_prob = topic_distributions.max(axis=1) # 主题概率
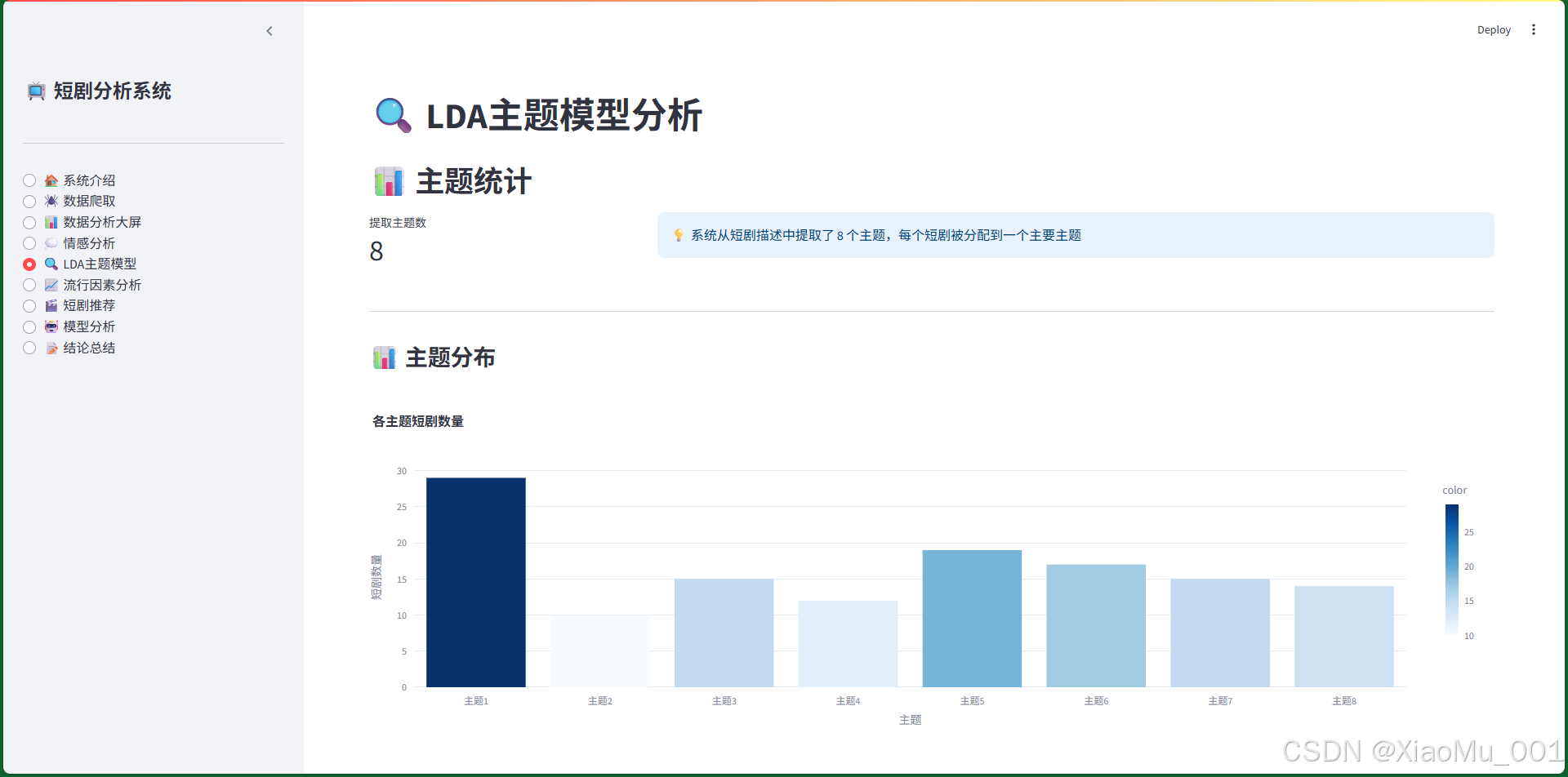
图4:LDA主题模型界面。展示主题分布、主题关键词、主题概率分布和主题与流行度关系。
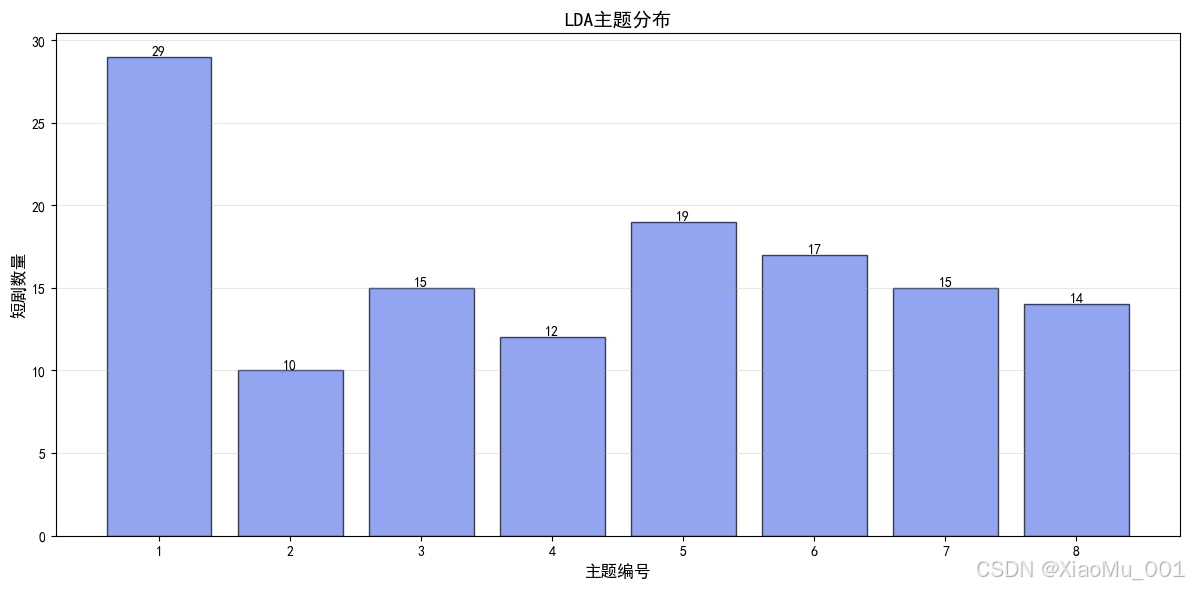
图5:主题分布图。展示8个主题的短剧数量分布,可以看出不同主题的短剧数量差异。
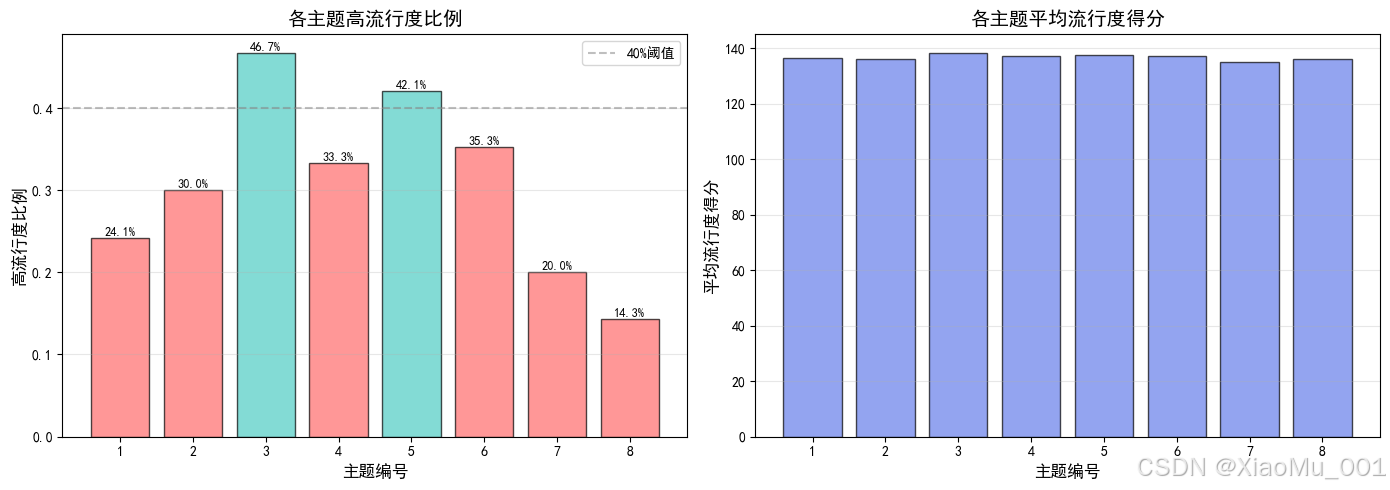
图6:主题与流行度关系分析。展示各主题的高流行度比例和平均流行度得分,发现主题类型是影响流行度的关键因素。
2.3 预测模型算法
2.3.1 线性回归
技术原理:
线性回归假设目标变量与特征变量之间存在线性关系:
y = β 0 + β 1 x 1 + β 2 x 2 + . . . + β n x n + ϵ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + ... + \beta_n x_n + \epsilon y=β0+β1x1+β2x2+...+βnxn+ϵ
其中:
- y y y:目标变量(流行度得分)
- x i x_i xi:特征变量(情感得分、描述长度、主题概率等)
- β i \beta_i βi:回归系数
- ϵ \epsilon ϵ:误差项
实现思路:
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 训练模型
model = LinearRegression()
model.fit(X_scaled, y)
# 预测
y_pred = model.predict(X_scaled)
# 评估
r2 = r2_score(y, y_pred)
rmse = np.sqrt(mean_squared_error(y, y_pred))
2.3.2 随机森林
技术原理:
随机森林是一种集成学习算法,通过构建多个决策树并投票或平均来预测。
优势:
- 能够处理非线性关系
- 对过拟合有较好的抵抗能力
- 可以评估特征重要性
实现思路:
from sklearn.ensemble import RandomForestRegressor
# 训练模型
rf_model = RandomForestRegressor(
n_estimators=100, # 树的数量
max_depth=10, # 树的最大深度
random_state=42
)
rf_model.fit(X_scaled, y)
# 特征重要性
feature_importance = rf_model.feature_importances_
2.3.3 XGBoost
技术原理:
XGBoost(eXtreme Gradient Boosting)是一种梯度提升算法,通过迭代训练多个弱学习器来构建强学习器。
优势:
- 处理非线性关系能力强
- 训练速度快
- 支持并行计算
- 内置正则化防止过拟合
实现思路:
import xgboost as xgb
# 训练模型
xgb_model = xgb.XGBRegressor(
n_estimators=100,
max_depth=6,
learning_rate=0.1,
random_state=42
)
xgb_model.fit(X_scaled, y)
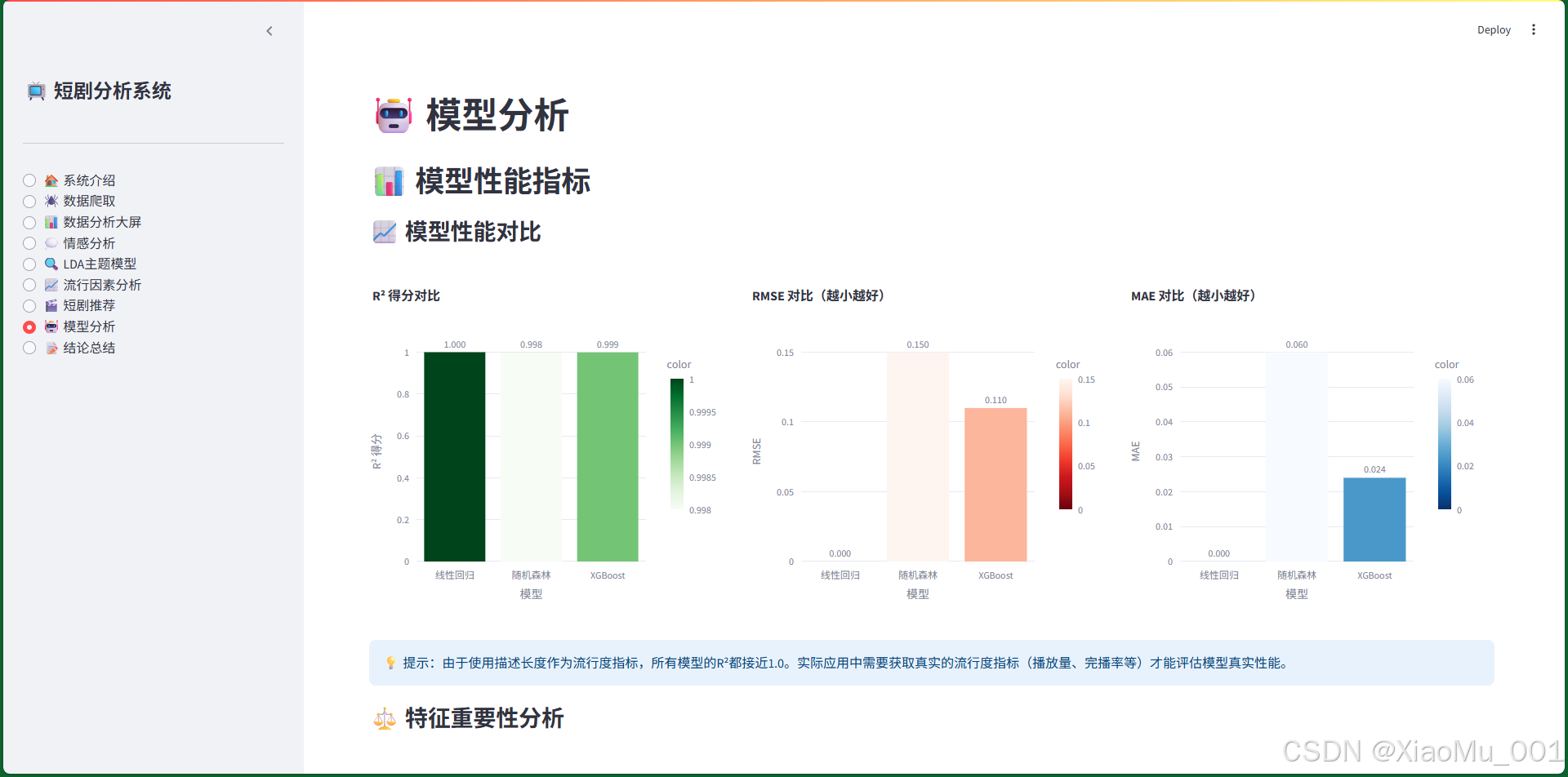
图7:模型分析界面。展示模型性能对比(R²、RMSE、MAE)、特征重要性分析和预测结果可视化。
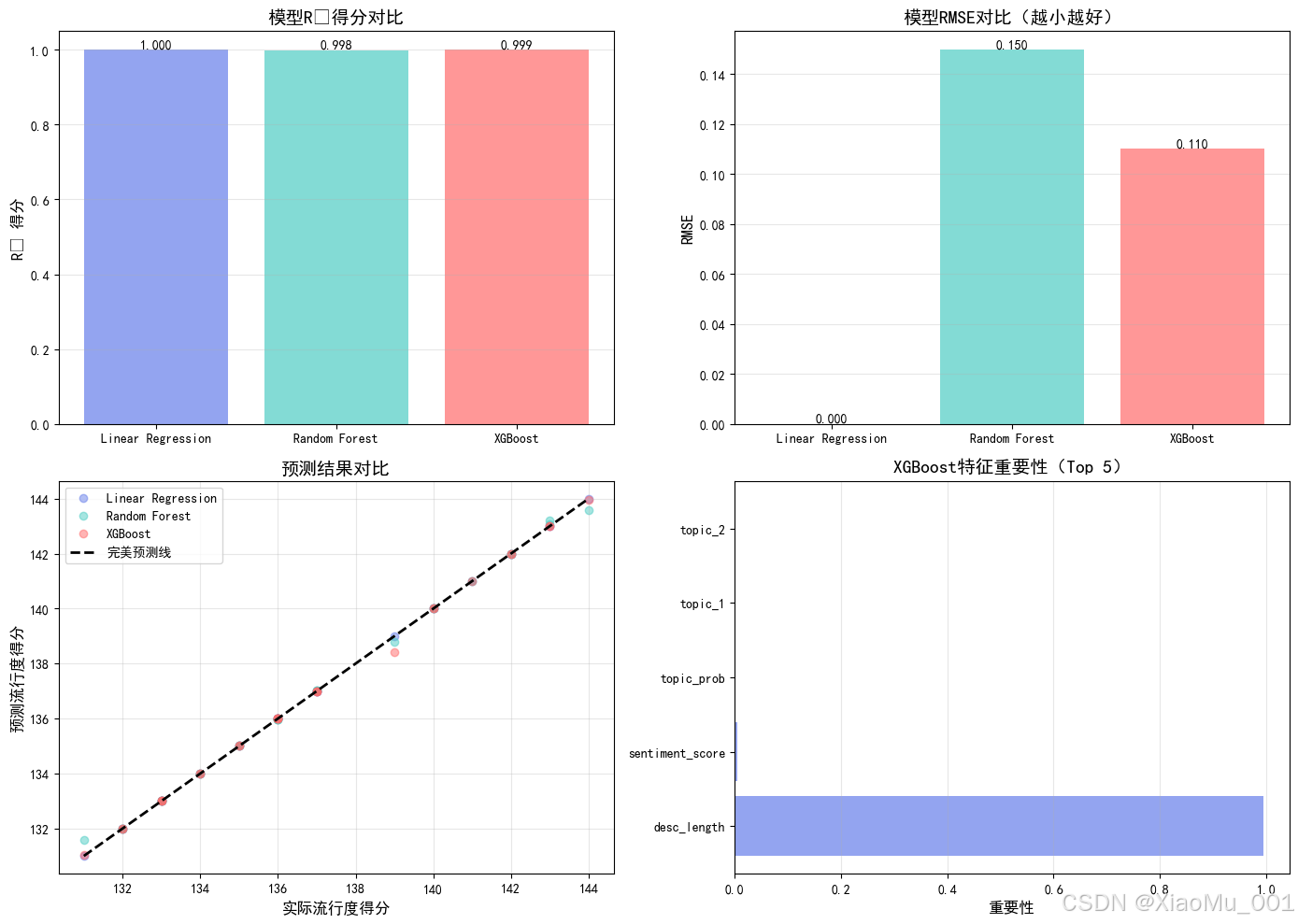
图8:流行度预测模型对比。对比线性回归、随机森林和XGBoost三种模型的性能指标,发现所有模型R²都接近1.0(因为使用描述长度作为流行度指标)。
三、模型训练
3.1 特征工程
3.1.1 特征提取
文本特征:
- 描述长度(desc_length):描述文本的字符数
- 词频特征:使用CountVectorizer提取词频
- TF-IDF特征:使用TfidfVectorizer提取TF-IDF值
主题特征:
- 主要主题(main_topic):文档被分配的主要主题编号
- 主题概率(topic_prob):主要主题的概率值
- 主题分布(topic_distribution):文档在所有主题上的概率分布
情感特征:
- 情感得分(sentiment_score):0-1之间的情感得分
- 情感标签(sentiment_label):积极/消极/中性
统计特征:
- 描述长度
- 关键词数量
- 分类数量
3.1.2 特征选择
使用随机森林和XGBoost的特征重要性进行特征选择:
# 特征重要性排序
feature_importance = pd.DataFrame({
'feature': features,
'importance': model.feature_importances_
}).sort_values('importance', ascending=False)
发现:描述长度是最重要的特征(重要性0.988-0.994),这是因为使用描述长度作为流行度指标的替代。
3.2 数据划分
from sklearn.model_selection import train_test_split
# 划分训练集和测试集(8:2)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
3.3 模型训练流程
- 数据预处理:清洗、标准化
- 特征工程:提取、选择特征
- 模型训练:使用训练集训练模型
- 模型评估:使用测试集评估性能
- 交叉验证:5折交叉验证评估模型稳定性
3.4 超参数优化
线性回归:无需超参数优化
随机森林:
- n_estimators: 100
- max_depth: 10
- random_state: 42
XGBoost:
- n_estimators: 100
- max_depth: 6
- learning_rate: 0.1
- random_state: 42
四、模型评估
4.1 评估指标
4.1.1 R²得分(决定系数)
公式:
R 2 = 1 − S S r e s S S t o t = 1 − ∑ ( y i − y ^ i ) 2 ∑ ( y i − y ˉ ) 2 R^2 = 1 - \frac{SS_{res}}{SS_{tot}} = 1 - \frac{\sum(y_i - \hat{y}_i)^2}{\sum(y_i - \bar{y})^2} R2=1−SStotSSres=1−∑(yi−yˉ)2∑(yi−y^i)2
含义:衡量模型解释目标变量变异的比例,取值范围[0,1],越接近1越好。
当前结果:R² ≈ 1.000(因为使用描述长度作为流行度指标,存在完全相关关系)
4.1.2 RMSE(均方根误差)
公式:
R M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2} RMSE=n1i=1∑n(yi−y^i)2
含义:预测值与实际值的平均偏差,越小越好。
当前结果:
- 线性回归:RMSE ≈ 0.000
- 随机森林:RMSE ≈ 0.150
- XGBoost:RMSE ≈ 0.110
4.1.3 MAE(平均绝对误差)
公式:
M A E = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ MAE = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
含义:预测值与实际值的平均绝对偏差,越小越好。
当前结果:
- 线性回归:MAE ≈ 0.000
- 随机森林:MAE ≈ 0.060
- XGBoost:MAE ≈ 0.024
4.2 交叉验证
使用5折交叉验证评估模型稳定性:
from sklearn.model_selection import cross_val_score
cv_scores = cross_val_score(model, X_train, y_train, cv=5, scoring='r2')
print(f"交叉验证R²: {cv_scores.mean():.3f} (+/- {cv_scores.std()*2:.3f})")
结果:
- 线性回归:1.000 (± 0.000)
- 随机森林:0.927 (± 0.184)
- XGBoost:0.907 (± 0.237)
4.3 残差分析
通过残差图分析模型的预测误差分布:
residuals = y_test - y_pred
plt.scatter(y_pred, residuals)
plt.axhline(y=0, color='r', linestyle='--')
分析要点:
- 残差应该随机分布在0附近
- 不应该有明显的模式或趋势
- 如果存在模式,说明模型可能遗漏了某些特征
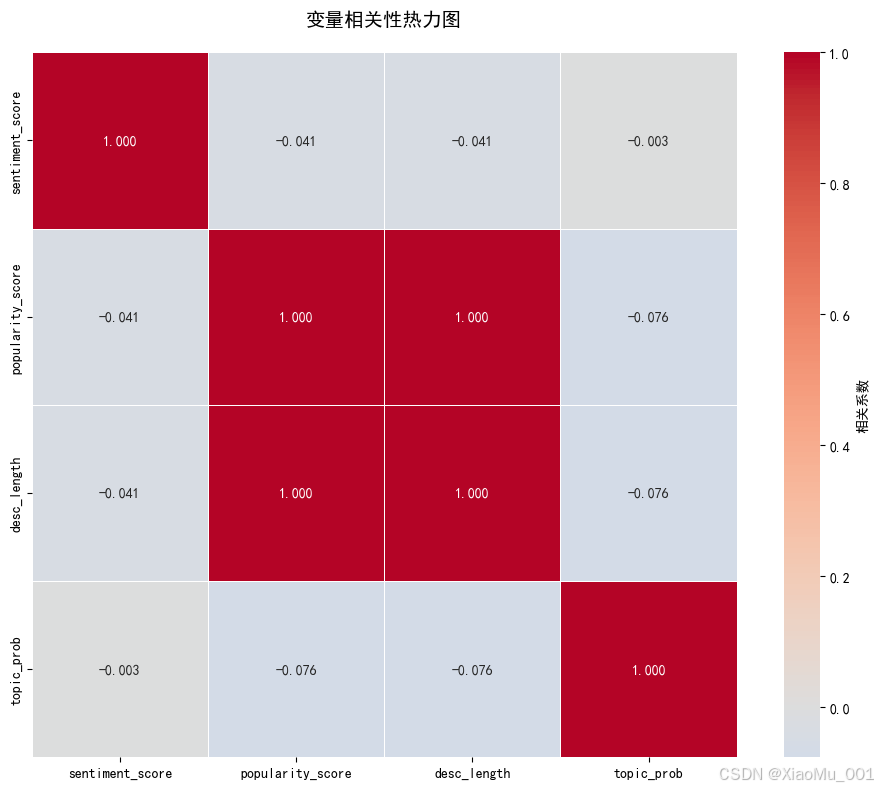
图9:变量相关性分析。通过热力图展示情感得分、描述长度、主题概率和流行度得分之间的相关系数,发现描述长度与流行度得分完全相关。
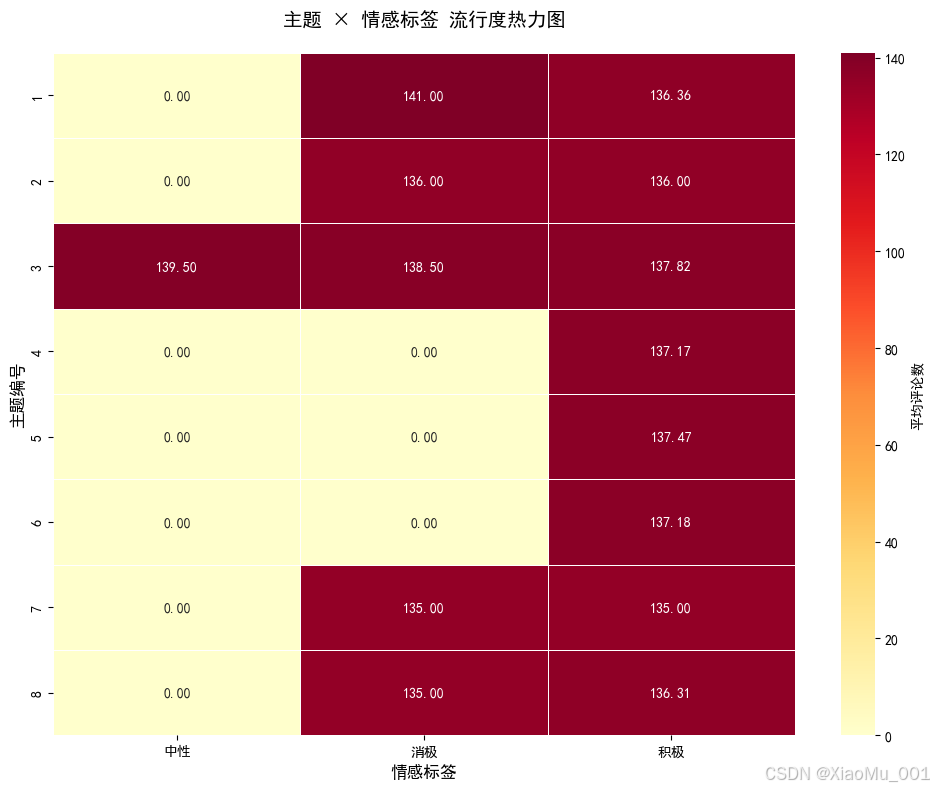
图10:综合分析图。综合展示情感、主题与流行度的关系,通过多维度分析识别影响短剧流行的关键因素。
五、数据库设计
5.1 数据库概述
本项目使用CSV文件存储数据,但可以转换为关系型数据库。以下是数据库设计方案:
5.2 数据表设计
5.2.1 短剧基本信息表(dramas)
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | ✓ | 自增主键 |
| drama_id | VARCHAR | 100 | ✓ | ✓ | - | 短剧唯一标识 |
| title | VARCHAR | 200 | ✓ | - | - | 短剧标题 |
| category | VARCHAR | 50 | - | - | - | 主要分类 |
| status | VARCHAR | 20 | - | - | - | 状态(全集/更新中) |
| publish_date | DATE | - | - | - | - | 发布日期 |
| update_time | VARCHAR | 50 | - | - | - | 更新时间 |
| episode_count | INT | - | - | - | - | 集数 |
| view_count | VARCHAR | 50 | - | - | - | 观看数 |
| rating | DECIMAL | 3,2 | - | - | - | 评分 |
| url | VARCHAR | 500 | ✓ | ✓ | - | 短剧页面URL |
| crawl_time | DATETIME | - | ✓ | - | - | 爬取时间 |
| created_at | DATETIME | - | ✓ | - | - | 创建时间 |
| updated_at | DATETIME | - | ✓ | - | - | 更新时间 |
索引设计:
- PRIMARY KEY (id)
- UNIQUE KEY (drama_id)
- UNIQUE KEY (url)
- INDEX (category)
- INDEX (publish_date)
5.2.2 短剧描述表(drama_descriptions)
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | ✓ | 自增主键 |
| drama_id | VARCHAR | 100 | ✓ | - | - | 短剧ID(外键) |
| description | VARCHAR | 500 | - | - | - | 简短描述 |
| description_full | TEXT | - | - | - | - | 完整描述 |
| desc_length | INT | - | - | - | - | 描述长度 |
| created_at | DATETIME | - | ✓ | - | - | 创建时间 |
索引设计:
- PRIMARY KEY (id)
- FOREIGN KEY (drama_id) REFERENCES dramas(drama_id)
- INDEX (desc_length)
5.2.3 分类标签表(drama_categories)
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | ✓ | 自增主键 |
| drama_id | VARCHAR | 100 | ✓ | - | - | 短剧ID(外键) |
| category_name | VARCHAR | 50 | ✓ | - | - | 分类名称 |
| created_at | DATETIME | - | ✓ | - | - | 创建时间 |
索引设计:
- PRIMARY KEY (id)
- FOREIGN KEY (drama_id) REFERENCES dramas(drama_id)
- INDEX (category_name)
5.2.4 标签表(drama_tags)
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | ✓ | 自增主键 |
| drama_id | VARCHAR | 100 | ✓ | - | - | 短剧ID(外键) |
| tag_name | VARCHAR | 50 | ✓ | - | - | 标签名称 |
| created_at | DATETIME | - | ✓ | - | - | 创建时间 |
索引设计:
- PRIMARY KEY (id)
- FOREIGN KEY (drama_id) REFERENCES dramas(drama_id)
- INDEX (tag_name)
5.2.5 评论表(drama_comments)
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | ✓ | 自增主键 |
| drama_id | VARCHAR | 100 | ✓ | - | - | 短剧ID(外键) |
| comment_text | TEXT | - | ✓ | - | - | 评论内容 |
| user_name | VARCHAR | 100 | - | - | - | 用户名 |
| comment_time | DATETIME | - | - | - | - | 评论时间 |
| created_at | DATETIME | - | ✓ | - | - | 创建时间 |
索引设计:
- PRIMARY KEY (id)
- FOREIGN KEY (drama_id) REFERENCES dramas(drama_id)
- INDEX (drama_id)
5.2.6 情感分析结果表(sentiment_analysis)
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | ✓ | 自增主键 |
| drama_id | VARCHAR | 100 | ✓ | ✓ | - | 短剧ID(外键) |
| sentiment_score | DECIMAL | 5,4 | ✓ | - | - | 情感得分(0-1) |
| sentiment_label | VARCHAR | 10 | ✓ | - | - | 情感标签(积极/消极/中性) |
| snownlp_score | DECIMAL | 5,4 | - | - | - | SnowNLP得分 |
| bert_score | DECIMAL | 5,4 | - | - | - | BERT得分 |
| bert_label | VARCHAR | 10 | - | - | - | BERT标签 |
| created_at | DATETIME | - | ✓ | - | - | 创建时间 |
| updated_at | DATETIME | - | ✓ | - | - | 更新时间 |
索引设计:
- PRIMARY KEY (id)
- UNIQUE KEY (drama_id)
- FOREIGN KEY (drama_id) REFERENCES dramas(drama_id)
- INDEX (sentiment_label)
- INDEX (sentiment_score)
5.2.7 LDA主题分析表(lda_topics)
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | ✓ | 自增主键 |
| topic_id | INT | - | ✓ | ✓ | - | 主题编号(1-8) |
| topic_name | VARCHAR | 100 | - | - | - | 主题名称 |
| top_words | TEXT | - | - | - | - | 主题关键词(用逗号分隔) |
| topic_explanation | TEXT | - | - | - | - | 主题解释 |
| created_at | DATETIME | - | ✓ | - | - | 创建时间 |
索引设计:
- PRIMARY KEY (id)
- UNIQUE KEY (topic_id)
5.2.8 短剧主题分配表(drama_topic_assignment)
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | ✓ | 自增主键 |
| drama_id | VARCHAR | 100 | ✓ | - | - | 短剧ID(外键) |
| topic_id | INT | - | ✓ | - | - | 主题ID(外键) |
| topic_prob | DECIMAL | 5,4 | ✓ | - | - | 主题概率(0-1) |
| is_main_topic | BOOLEAN | - | ✓ | - | - | 是否为主主题 |
| created_at | DATETIME | - | ✓ | - | - | 创建时间 |
索引设计:
- PRIMARY KEY (id)
- FOREIGN KEY (drama_id) REFERENCES dramas(drama_id)
- FOREIGN KEY (topic_id) REFERENCES lda_topics(topic_id)
- INDEX (drama_id, topic_id)
5.2.9 流行度分析表(popularity_analysis)
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | ✓ | 自增主键 |
| drama_id | VARCHAR | 100 | ✓ | ✓ | - | 短剧ID(外键) |
| popularity_score | DECIMAL | 10,2 | ✓ | - | - | 流行度得分 |
| is_popular | BOOLEAN | - | ✓ | - | - | 是否高流行度 |
| sentiment_correlation | DECIMAL | 5,4 | - | - | - | 情感相关性 |
| topic_impact | DECIMAL | 5,4 | - | - | - | 主题影响度 |
| created_at | DATETIME | - | ✓ | - | - | 创建时间 |
| updated_at | DATETIME | - | ✓ | - | - | 更新时间 |
索引设计:
- PRIMARY KEY (id)
- UNIQUE KEY (drama_id)
- FOREIGN KEY (drama_id) REFERENCES dramas(drama_id)
- INDEX (is_popular)
- INDEX (popularity_score)
5.2.10 模型预测结果表(model_predictions)
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
| id | INT | - | ✓ | ✓ | ✓ | 自增主键 |
| drama_id | VARCHAR | 100 | ✓ | - | - | 短剧ID(外键) |
| model_name | VARCHAR | 50 | ✓ | - | - | 模型名称 |
| actual_score | DECIMAL | 10,2 | ✓ | - | - | 实际流行度得分 |
| predicted_score | DECIMAL | 10,2 | ✓ | - | - | 预测流行度得分 |
| residual | DECIMAL | 10,2 | - | - | - | 残差 |
| created_at | DATETIME | - | ✓ | - | - | 创建时间 |
索引设计:
- PRIMARY KEY (id)
- FOREIGN KEY (drama_id) REFERENCES dramas(drama_id)
- INDEX (model_name)
- INDEX (drama_id, model_name)
5.3 数据库关系图
dramas (1) ──< (N) drama_descriptions
dramas (1) ──< (N) drama_categories
dramas (1) ──< (N) drama_tags
dramas (1) ──< (N) drama_comments
dramas (1) ──< (1) sentiment_analysis
dramas (1) ──< (N) drama_topic_assignment
dramas (1) ──< (1) popularity_analysis
dramas (1) ──< (N) model_predictions
lda_topics (1) ──< (N) drama_topic_assignment
5.4 数据库创建SQL示例
-- 创建短剧基本信息表
CREATE TABLE dramas (
id INT AUTO_INCREMENT PRIMARY KEY,
drama_id VARCHAR(100) NOT NULL UNIQUE,
title VARCHAR(200) NOT NULL,
category VARCHAR(50),
status VARCHAR(20),
publish_date DATE,
update_time VARCHAR(50),
episode_count INT,
view_count VARCHAR(50),
rating DECIMAL(3,2),
url VARCHAR(500) NOT NULL UNIQUE,
crawl_time DATETIME NOT NULL,
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
INDEX idx_category (category),
INDEX idx_publish_date (publish_date)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
-- 创建情感分析结果表
CREATE TABLE sentiment_analysis (
id INT AUTO_INCREMENT PRIMARY KEY,
drama_id VARCHAR(100) NOT NULL UNIQUE,
sentiment_score DECIMAL(5,4) NOT NULL,
sentiment_label VARCHAR(10) NOT NULL,
snownlp_score DECIMAL(5,4),
bert_score DECIMAL(5,4),
bert_label VARCHAR(10),
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (drama_id) REFERENCES dramas(drama_id) ON DELETE CASCADE,
INDEX idx_sentiment_label (sentiment_label),
INDEX idx_sentiment_score (sentiment_score)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
六、主要文件目录结构
spider/
├── spider_enhanced.py # 增强版爬虫(主要使用)
├── spider_selenium.py # Selenium版本爬虫(备用)
├── spider.py # 基础版爬虫
├── streamlit_app.py # Streamlit应用主文件
├── algorithm.ipynb # Jupyter Notebook分析文件
├── config.py # 配置文件
├── requirements.txt # Python依赖包列表
│
├── data/ # 数据文件目录
│ ├── short_drama_data.csv # 原始爬取数据(130条)
│ ├── analysis_results.csv # 分析结果数据
│ ├── popularity_analysis.csv # 流行度分析数据
│ ├── lda_topics.csv # LDA主题数据
│ └── short_drama_data.xlsx # Excel格式数据
│
├── explaination/ # 项目说明文档
│ ├── 详解.md # 项目详细说明(本文档)
│ └── images/ # 图片资源
│ ├── system/ # 系统界面截图
│ │ ├── 系统介绍.png
│ │ ├── 数据爬取.png
│ │ ├── 数据分析.png
│ │ ├── 情感分析.png
│ │ ├── lda主题建模.png
│ │ ├── 流行因素分析.png
│ │ ├── 短剧推荐.png
│ │ ├── 模型分析.png
│ │ └── 结论总结.png
│ └── algorithm/ # 算法分析图表
│ ├── 可视化情感分布.png
│ ├── 情感得分与流行度的关系.png
│ ├── 主题分布.png
│ ├── 主题与流行度的关系.png
│ ├── 变量相关性分析.png
│ ├── 流行度预测模型对比.png
│ └── 综合分析 情感、主题与流行度.png
│
├── logs/ # 日志文件
│ ├── spider_enhanced.log # 爬虫运行日志
│ └── spider_selenium.log # Selenium爬虫日志
│
├── temp/ # 临时文件
│ └── short_drama_data_temp_*.csv # 临时数据文件
│
├── 总结.txt # 研究总结
├── 进度说明.txt # 项目进度说明
└── README.md # 项目说明文档
6.1 核心文件说明
6.1.1 spider_enhanced.py
- 功能:增强版爬虫,支持多源数据获取
- 主要类:
EnhancedSpider - 关键方法:
fetch_page(): 获取网页内容extract_drama_links(): 提取短剧链接parse_drama_page(): 解析短剧详情crawl(): 主爬取函数save_to_csv(): 保存数据
6.1.2 algorithm.ipynb
- 功能:数据分析和模型训练
- 主要内容:
- 数据加载和预处理
- 情感分析(SnowNLP、BERT)
- LDA主题模型
- 流行因素分析
- 预测模型(线性回归、随机森林、XGBoost)
- 研究结论
6.1.3 streamlit_app.py
- 功能:Web应用主文件
- 主要模块:
- 数据加载模块
- 爬虫模块(WebSpider类)
- 9个功能页面
- 可视化展示
七、系统界面和功能详解
7.1 系统介绍页面
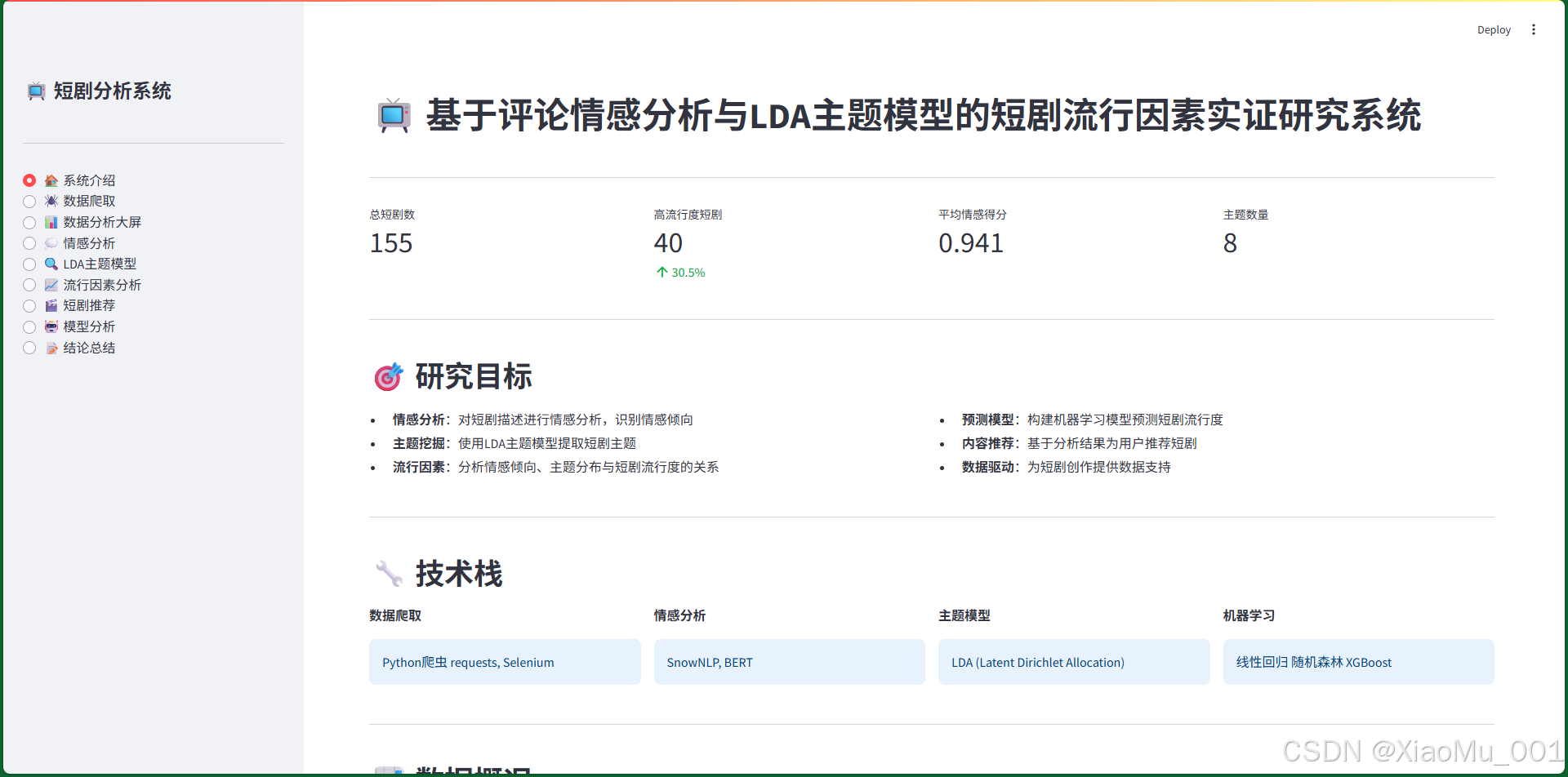
功能说明:
- 展示项目概述和研究目标
- 显示关键指标(总短剧数、高流行度短剧、平均情感得分、主题数量)
- 介绍技术栈(数据爬取、情感分析、主题模型、机器学习)
- 展示数据概况(数据预览、统计信息)
技术实现:
- 使用Streamlit的
st.metric()显示关键指标 - 使用
st.dataframe()展示数据表格 - 使用
st.columns()实现多列布局
7.2 数据爬取页面
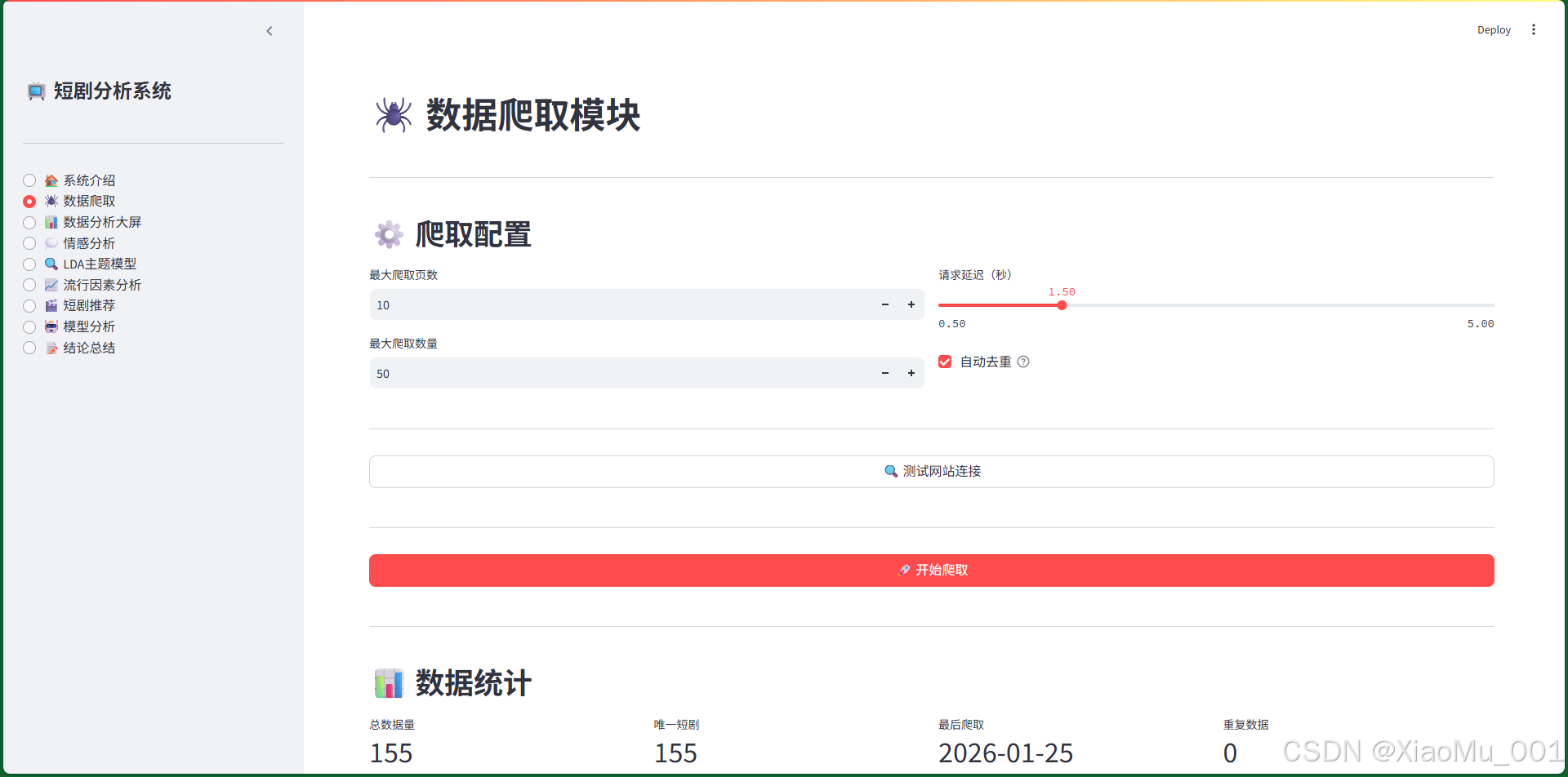
功能说明:
- 爬取配置:可设置最大爬取页数、最大爬取数量、请求延迟、自动去重
- 测试连接:测试网站是否可访问
- 开始爬取:执行爬取任务,显示实时进度
- 数据统计:显示总数据量、唯一短剧数、最后爬取时间、重复数据统计
技术实现:
WebSpider类实现爬虫功能- 使用
st.progress()显示爬取进度 - 使用
st.empty()实现动态更新状态 - 自动去重机制(基于标题和URL)
核心代码逻辑:
class WebSpider:
def crawl(self, max_pages, max_dramas, delay):
# 1. 加载已有数据用于去重
# 2. 循环爬取页面
# 3. 提取链接
# 4. 解析详情
# 5. 保存数据
7.3 数据分析大屏
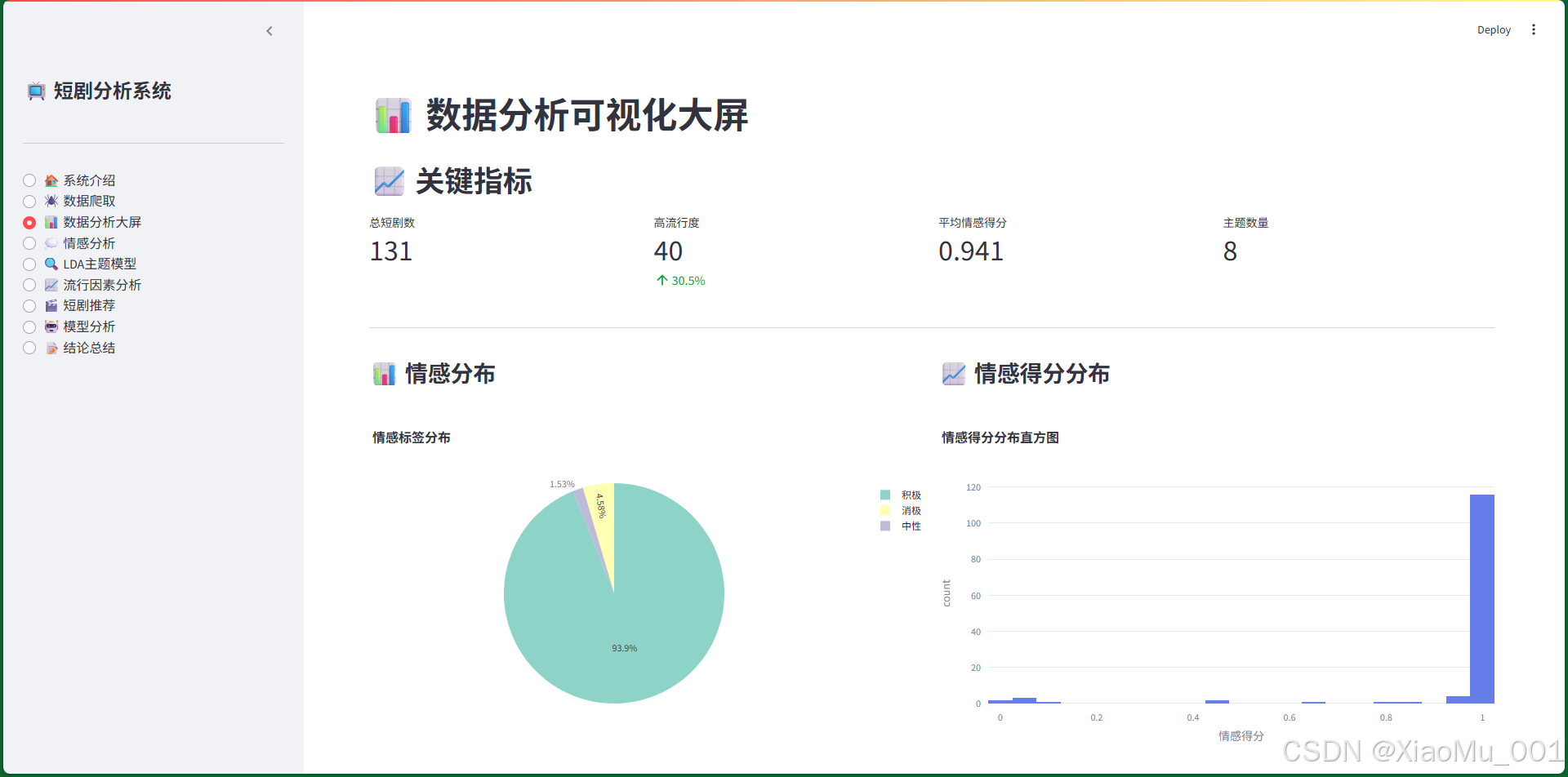
功能说明:
- 关键指标卡片:总短剧数、高流行度、平均情感得分、主题数量
- 情感分布:饼图展示情感标签分布
- 情感得分分布:直方图展示情感得分分布
- 主题分布:柱状图展示各主题短剧数量
- 流行度分析:流行度得分分布、描述长度分布
- 相关性热力图:展示特征之间的相关系数
技术实现:
- 使用Plotly Express创建交互式图表
px.pie():饼图px.histogram():直方图px.bar():柱状图px.imshow():热力图
数据来源:analysis_results.csv
7.4 情感分析界面
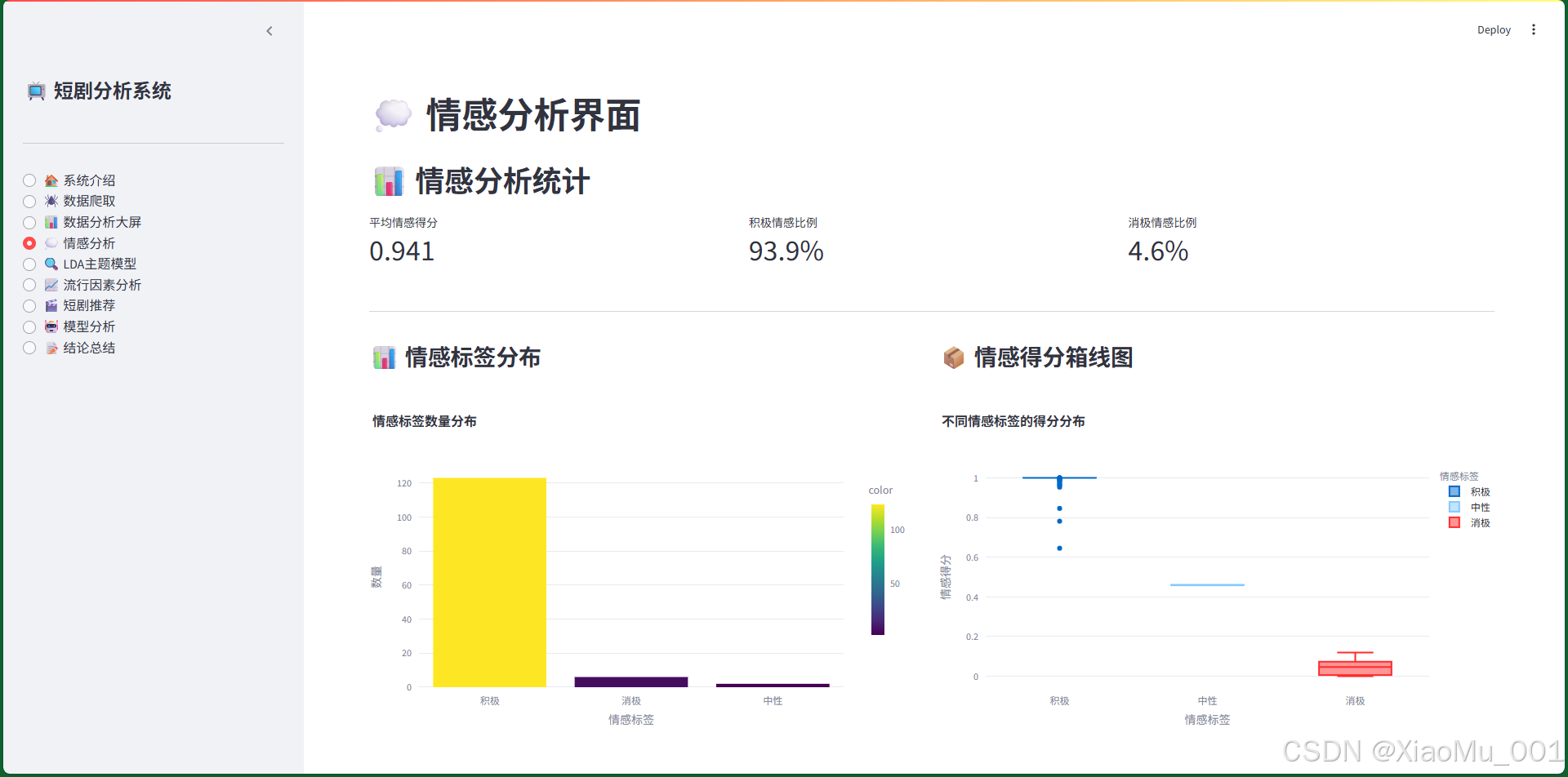
功能说明:
- 情感分析统计:平均情感得分、积极情感比例、消极情感比例
- 情感标签分布:柱状图展示各情感标签的数量
- 情感得分箱线图:展示不同情感标签的得分分布
- 情感与流行度关系:散点图展示情感得分与流行度的关系
- 情感分析详情表:可搜索的数据表格,显示每条短剧的情感分析结果
技术实现:
- 使用SnowNLP进行情感分析
- 使用Plotly创建交互式可视化
- 实现搜索功能(
st.text_input()+ 数据过滤)
算法原理:
- SnowNLP基于朴素贝叶斯分类器
- 计算文本属于积极情感的概率
- 输出0-1之间的情感得分
7.5 LDA主题模型界面
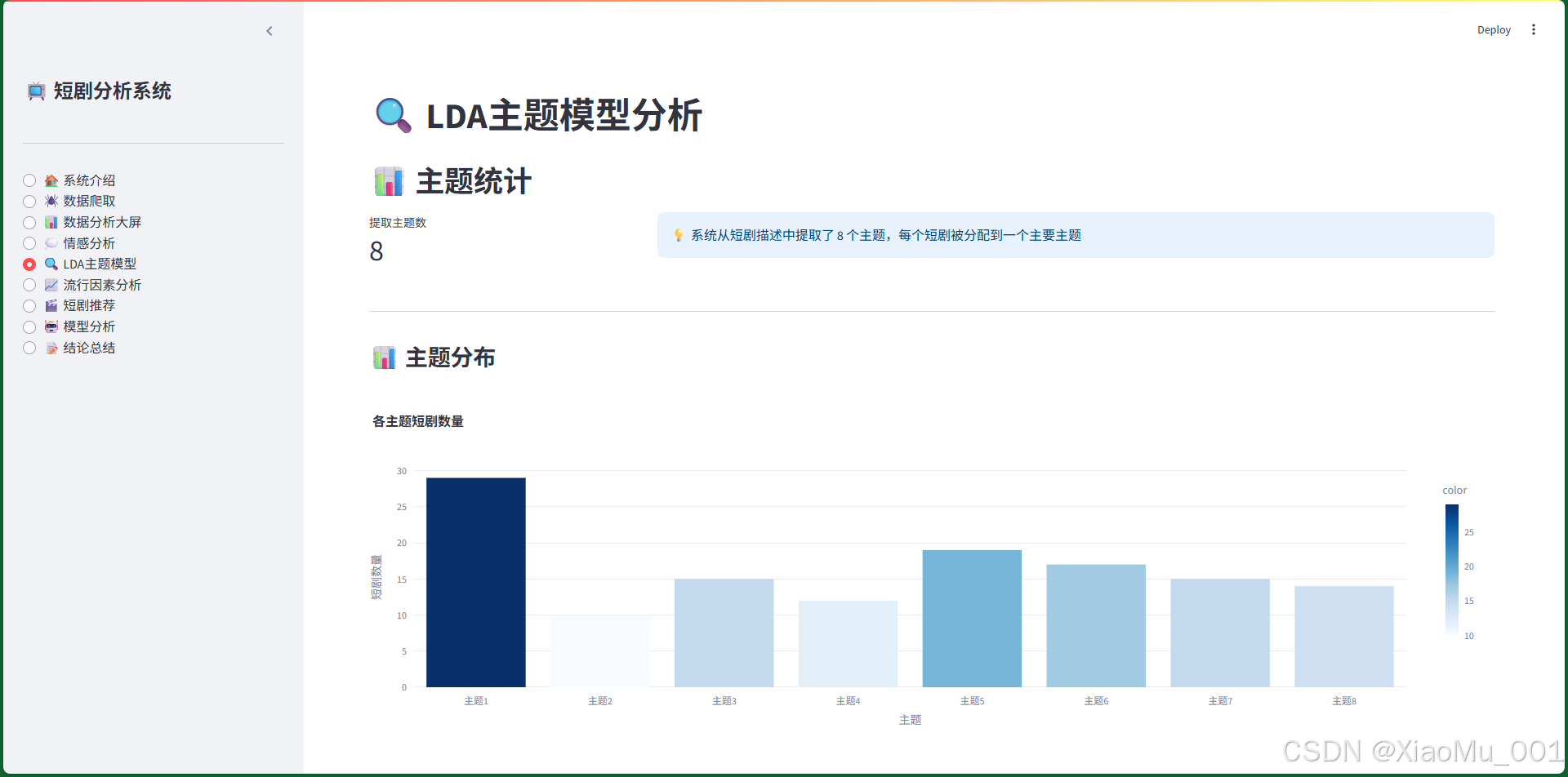
功能说明:
- 主题统计:显示提取的主题数量
- 主题分布:柱状图展示各主题的短剧数量
- 主题关键词:可展开查看每个主题的关键词和该主题下的短剧
- 主题概率分布:直方图展示主题概率的分布
- 主题与流行度关系:双柱状图展示各主题的平均流行度得分和高流行度比例
技术实现:
- 使用sklearn的
LatentDirichletAllocation实现LDA模型 - 使用jieba进行中文分词
- 使用
st.expander()实现可展开的主题详情
算法原理:
- LDA假设每个文档是多个主题的混合
- 通过迭代优化,学习文档-主题分布和主题-词分布
- 为每个文档分配主要主题和主题概率
7.6 流行因素分析界面
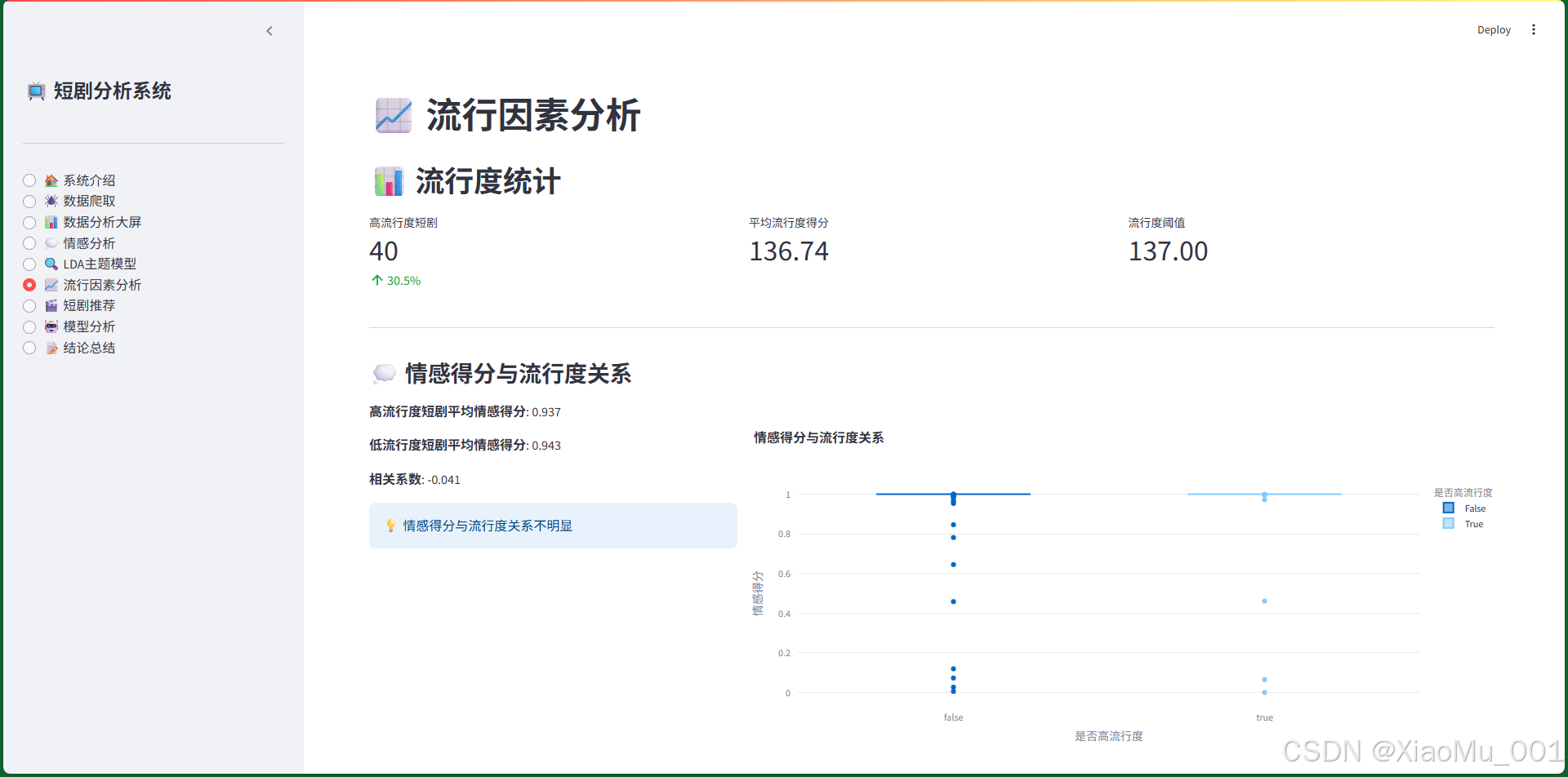
功能说明:
- 流行度统计:高流行度短剧数量、平均流行度得分、流行度阈值
- 情感得分与流行度关系:
- 显示高/低流行度短剧的平均情感得分
- 显示相关系数
- 箱线图可视化对比
- 主题与流行度关系:柱状图展示各主题的高流行度比例
- 特征重要性分析:柱状图展示各特征与流行度的相关性
技术实现:
- 使用pandas进行数据分组和聚合
- 使用scipy进行统计检验(T检验)
- 使用Plotly创建可视化图表
分析发现:
- 情感得分与流行度关系不明显(相关系数接近0)
- 主题类型是影响流行度的关键因素(差异显著)
7.7 短剧推荐界面
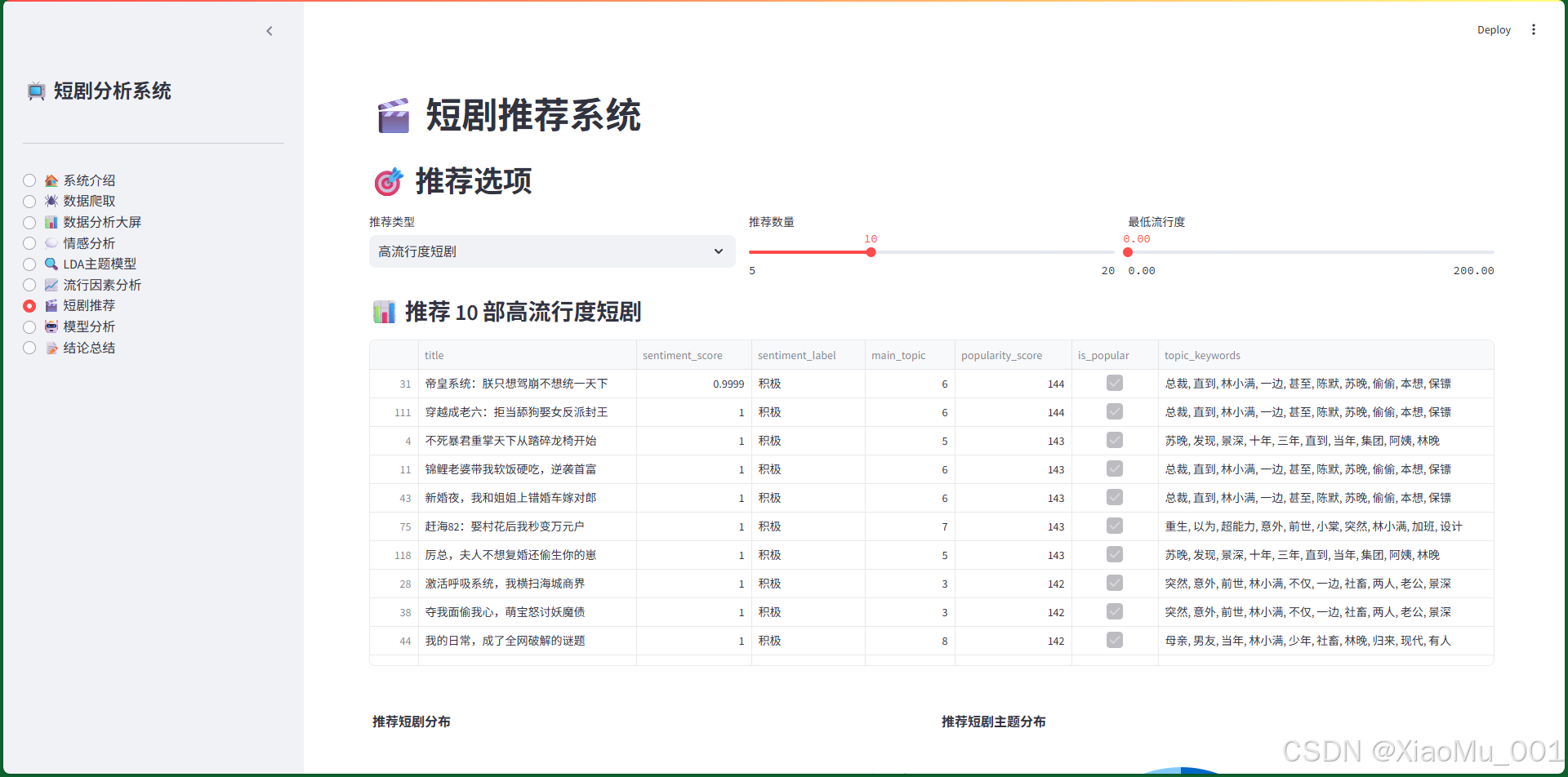
功能说明:
- 推荐类型选择:
- 高流行度短剧
- 高情感得分短剧
- 特定主题短剧
- 综合推荐
- 推荐参数设置:推荐数量、最低流行度阈值
- 推荐结果展示:数据表格、散点图、主题分布饼图
技术实现:
- 综合评分算法:
composite_score = popularity_score * 0.6 + sentiment_score * 100 * 0.4 - 使用pandas的
nlargest()进行排序 - 使用Plotly创建可视化
推荐算法:
- 高流行度推荐:按
popularity_score降序排列 - 高情感得分推荐:按
sentiment_score降序排列 - 特定主题推荐:筛选特定主题,按流行度排序
- 综合推荐:使用综合评分排序
7.8 模型分析界面
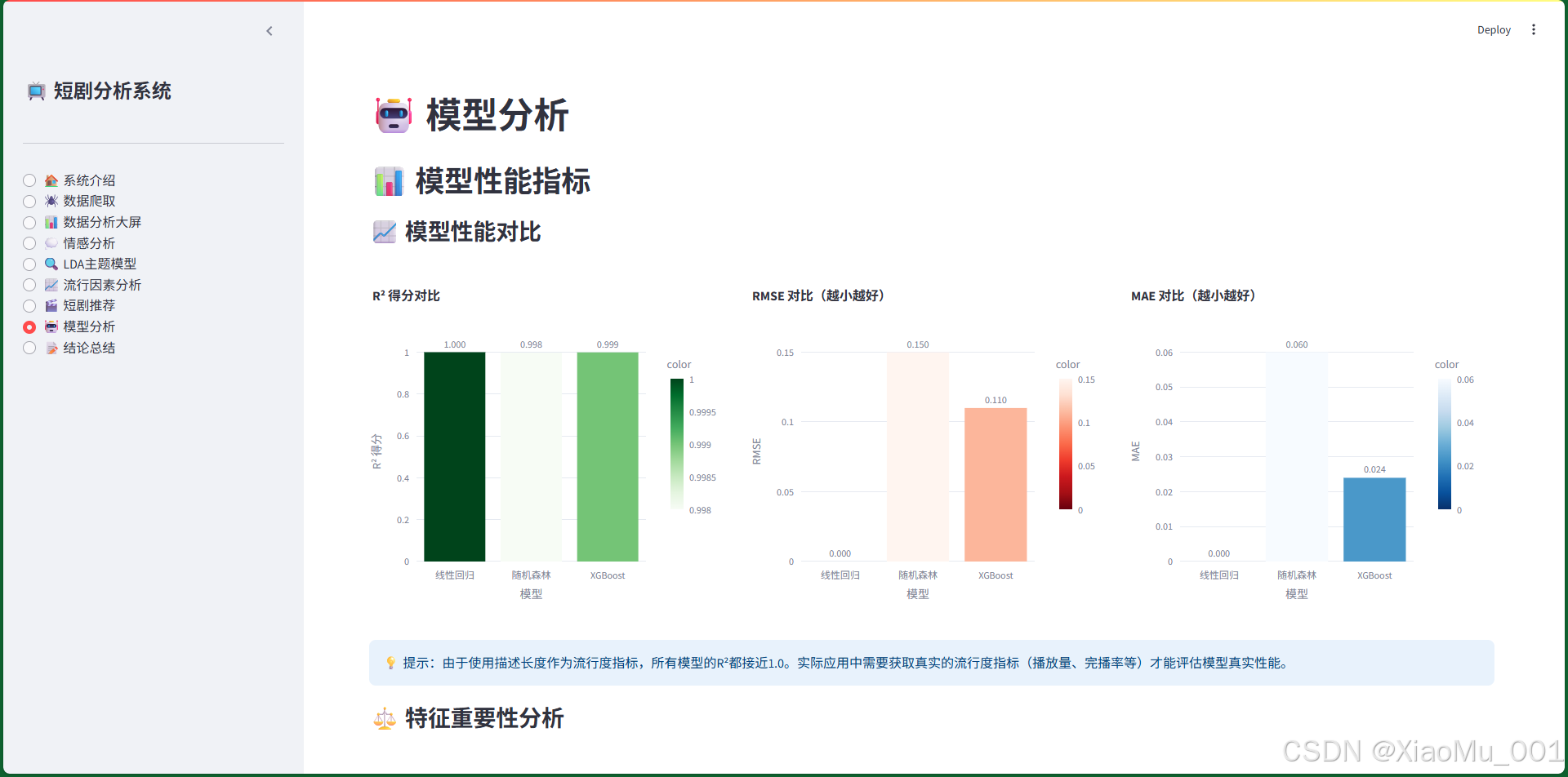
功能说明:
- 模型性能对比:R²得分、RMSE、MAE三个指标的对比
- 特征重要性分析:随机森林特征重要性排序
- 预测结果可视化:
- 实际值vs预测值散点图(带趋势线)
- 残差分析图
技术实现:
- 使用sklearn的模型评估指标
- 使用sklearn的LinearRegression手动绘制趋势线(避免scipy兼容性问题)
- 使用Plotly创建交互式图表
模型对比结果:
- 线性回归:R²=1.000, RMSE=0.000, MAE=0.000
- 随机森林:R²=0.998, RMSE=0.150, MAE=0.060
- XGBoost:R²=0.999, RMSE=0.110, MAE=0.024
7.9 结论总结页面
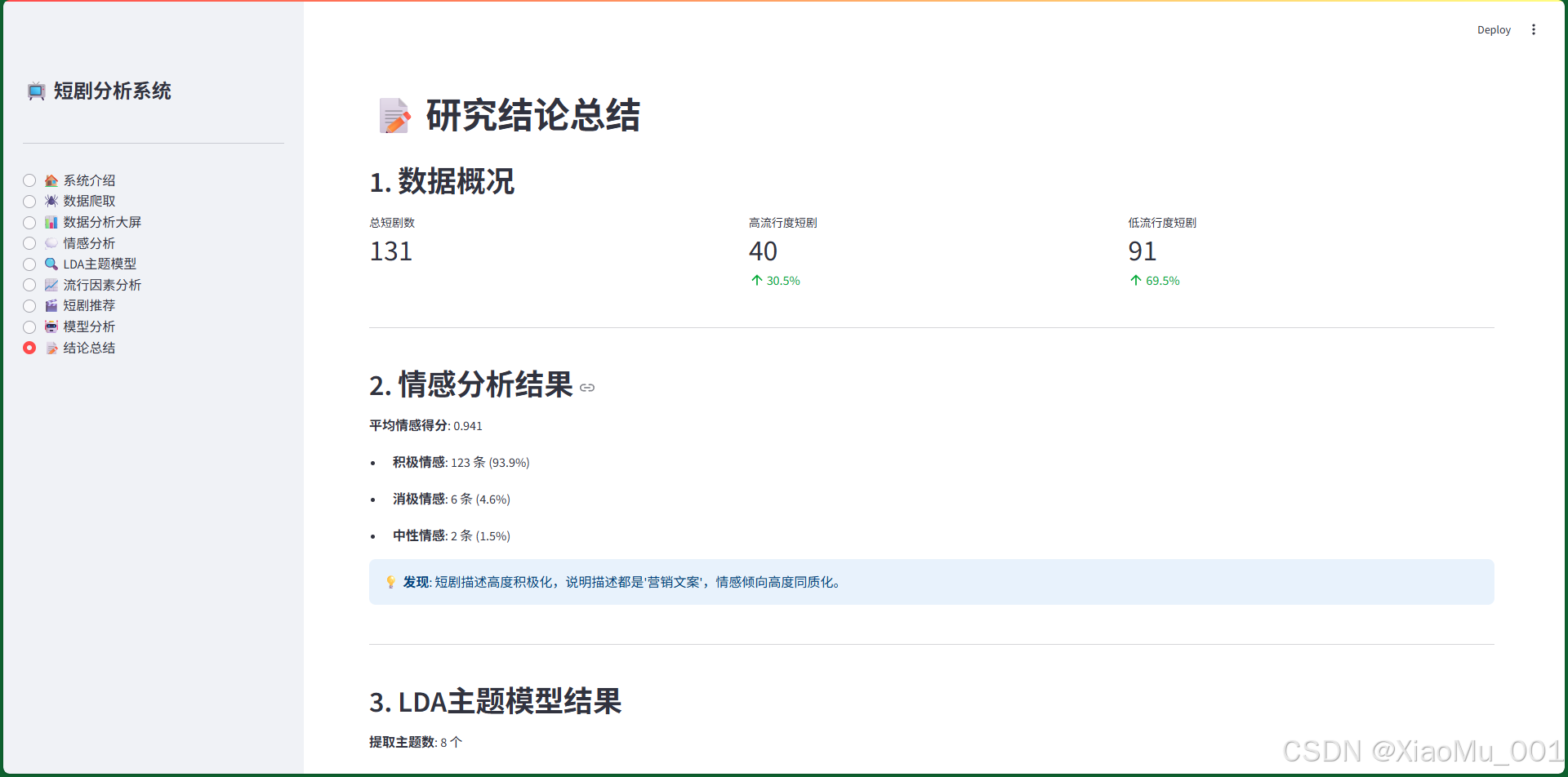
功能说明:
- 数据概况:总短剧数、高/低流行度短剧统计
- 情感分析结果:平均情感得分、情感分布
- LDA主题模型结果:提取主题数、最流行的3个主题
- 流行因素分析:情感与流行度关系、主题与流行度关系
- 关键发现:总结研究的主要发现
- 研究局限:数据局限、方法局限、技术局限
- 实践建议:内容创作建议、技术选择建议、研究方向
技术实现:
- 动态生成Markdown格式的结论
- 基于实际分析结果计算统计数据
- 使用
st.markdown()渲染结论内容
八、技术详解
8.1 数据爬取技术
8.1.1 Requests + BeautifulSoup
技术原理:
- Requests:Python的HTTP库,用于发送HTTP请求
- BeautifulSoup:HTML/XML解析库,用于提取网页内容
实现流程:
# 1. 发送HTTP请求
response = requests.get(url, headers=headers, timeout=15)
# 2. 解析HTML
soup = BeautifulSoup(response.text, 'lxml')
# 3. 提取链接
links = soup.find_all('a', href=True)
for link in links:
href = link.get('href')
if '/play/' in href:
# 处理链接
优势:
- 速度快
- 资源占用少
- 适合静态网页
劣势:
- 无法处理JavaScript动态加载的内容
- 容易被反爬虫机制限制
8.1.2 Selenium(备用方案)
技术原理:
- 使用真实浏览器(Chrome)模拟用户操作
- 可以执行JavaScript,获取动态加载的内容
实现流程:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 初始化浏览器
driver = webdriver.Chrome()
# 访问网页
driver.get(url)
# 等待页面加载
time.sleep(2)
# 提取内容
elements = driver.find_elements(By.CSS_SELECTOR, 'a[href*="/play/"]')
优势:
- 可以处理JavaScript动态内容
- 更接近真实用户行为
劣势:
- 速度慢
- 资源占用大
- 需要安装浏览器驱动
8.2 文本处理技术
8.2.1 中文分词 - jieba
技术原理:
- 基于前缀词典实现高效的词图扫描
- 使用动态规划查找最大概率路径
- 对于未登录词,使用HMM模型进行识别
使用示例:
import jieba
# 精确模式
words = jieba.cut("能看见妖怪的孤女林小满", cut_all=False)
# 全模式
words = jieba.cut("能看见妖怪的孤女林小满", cut_all=True)
# 搜索引擎模式
words = jieba.cut_for_search("能看见妖怪的孤女林小满")
8.2.2 停用词过滤
技术原理:
- 去除对文本分析无意义的常见词(如"的"、“了”、"在"等)
- 提高文本分析的质量和效率
实现:
stopwords = ['的', '了', '在', '是', '我', '有', '和', '就']
words = [w for w in words if w not in stopwords and len(w) > 1]
8.3 机器学习技术
8.3.1 特征标准化
技术原理:
- 将不同量纲的特征转换为相同量纲
- 避免数值大的特征主导模型
公式:
z = x − μ σ z = \frac{x - \mu}{\sigma} z=σx−μ
其中:
- x x x:原始特征值
- μ \mu μ:特征均值
- σ \sigma σ:特征标准差
- z z z:标准化后的值
实现:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
8.3.2 交叉验证
技术原理:
- 将数据集分成K份(通常K=5或10)
- 每次用K-1份训练,1份测试
- 重复K次,取平均结果
优势:
- 充分利用数据
- 评估模型稳定性
- 减少过拟合风险
实现:
from sklearn.model_selection import cross_val_score
cv_scores = cross_val_score(model, X, y, cv=5, scoring='r2')
print(f"平均R²: {cv_scores.mean():.3f} (+/- {cv_scores.std()*2:.3f})")
8.4 可视化技术
8.4.1 Plotly
技术原理:
- 基于D3.js的交互式可视化库
- 支持多种图表类型(散点图、柱状图、热力图等)
- 自动生成交互式HTML图表
优势:
- 交互性强(缩放、悬停、筛选等)
- 美观
- 易于使用
使用示例:
import plotly.express as px
fig = px.scatter(
df,
x='sentiment_score',
y='popularity_score',
color='sentiment_label',
hover_data=['title']
)
fig.show()
8.4.2 Matplotlib + Seaborn
技术原理:
- Matplotlib:Python的基础绘图库
- Seaborn:基于Matplotlib的统计可视化库
使用场景:
- 静态图表
- 论文插图
- 快速原型
九、技术原理和实现思路
9.1 情感分析实现思路
9.1.1 SnowNLP实现
步骤1:文本预处理
# 清洗文本
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9]', '', text)
text = text.strip()
步骤2:情感分析
from snownlp import SnowNLP
s = SnowNLP(text)
sentiment_score = s.sentiments # 0-1之间的得分
步骤3:情感分类
if sentiment_score > 0.6:
label = '积极'
elif sentiment_score < 0.4:
label = '消极'
else:
label = '中性'
9.1.2 BERT实现思路
步骤1:加载预训练模型
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "uer/roberta-base-finetuned-chinanews-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
步骤2:文本编码
inputs = tokenizer(
text,
return_tensors="pt",
truncation=True,
max_length=128,
padding=True
)
步骤3:模型预测
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probabilities = torch.softmax(logits, dim=-1)
sentiment_score = probabilities[0][1].item() # 积极情感概率
9.2 LDA主题模型实现思路
9.2.1 文本预处理流程
import jieba
import jieba.analyse
# 1. 分词
words = jieba.cut(text)
# 2. 去停用词
stopwords = load_stopwords()
words = [w for w in words if w not in stopwords and len(w) > 1]
# 3. 组合成文本
processed_text = ' '.join(words)
9.2.2 文本向量化
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(
max_features=1000, # 最多保留1000个特征词
min_df=2, # 词频至少出现2次
max_df=0.95 # 词频最多出现在95%的文档中
)
X = vectorizer.fit_transform(processed_texts)
9.2.3 LDA模型训练
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(
n_components=8, # 主题数
learning_method='online',
learning_offset=50.0,
random_state=42,
max_iter=10
)
lda.fit(X)
# 获取主题-词分布
for topic_idx, topic in enumerate(lda.components_):
top_words_idx = topic.argsort()[-10:][::-1]
top_words = [feature_names[i] for i in top_words_idx]
print(f"主题 {topic_idx+1}: {', '.join(top_words)}")
9.2.4 主题分配
# 获取文档-主题分布
topic_distributions = lda.transform(X)
# 为每个文档分配主要主题
main_topic = topic_distributions.argmax(axis=1) + 1
topic_prob = topic_distributions.max(axis=1)
9.3 预测模型实现思路
9.3.1 特征构建
# 基础特征
features = ['sentiment_score', 'desc_length', 'topic_prob']
# 主题one-hot编码
topic_dummies = pd.get_dummies(df['main_topic'], prefix='topic')
# 组合特征
X = pd.concat([df[features], topic_dummies], axis=1)
9.3.2 模型训练流程
# 1. 数据划分
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 2. 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 3. 模型训练
model = RandomForestRegressor(n_estimators=100, max_depth=10)
model.fit(X_train_scaled, y_train)
# 4. 预测
y_pred = model.predict(X_test_scaled)
# 5. 评估
r2 = r2_score(y_test, y_pred)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
mae = mean_absolute_error(y_test, y_pred)
9.3.3 特征重要性分析
# 获取特征重要性
feature_importance = pd.DataFrame({
'feature': X.columns,
'importance': model.feature_importances_
}).sort_values('importance', ascending=False)
# 可视化
plt.barh(feature_importance['feature'], feature_importance['importance'])
9.4 Streamlit应用实现思路
9.4.1 页面结构
# 侧边栏导航
page = st.sidebar.radio("导航菜单", options=[...])
# 主内容区
if page == "系统介绍":
# 页面内容
elif page == "数据爬取":
# 页面内容
9.4.2 数据加载和缓存
@st.cache_data
def load_data():
df = pd.read_csv('short_drama_data.csv', encoding='utf-8-sig')
analysis_df = pd.read_csv('analysis_results.csv', encoding='utf-8-sig')
return df, analysis_df
9.4.3 交互式组件
# 输入组件
max_pages = st.number_input("最大爬取页数", min_value=1, max_value=100)
n_recommendations = st.slider("推荐数量", 5, 20, 10)
# 按钮
if st.button("开始爬取"):
# 执行爬取
# 选择框
recommendation_type = st.selectbox("推荐类型", [...])
十、关键技术详解
10.1 中文文本处理
10.1.1 jieba分词原理
算法:
- 基于前缀词典实现高效的词图扫描
- 生成有向无环图(DAG)
- 使用动态规划查找最大概率路径
- 对于未登录词,使用HMM模型
分词模式:
- 精确模式:试图将句子最精确地切开,适合文本分析
- 全模式:把句子中所有可以成词的词语都扫描出来,速度快
- 搜索引擎模式:在精确模式基础上,对长词再次切分
10.1.2 停用词处理
停用词类型:
- 语气词:的、了、在、是
- 代词:我、你、他、她
- 连词:和、与、或
- 助词:着、过、得
处理策略:
- 维护停用词表
- 分词后过滤停用词
- 保留长度大于1的词
10.2 LDA主题模型详解
10.2.1 数学原理
LDA生成模型:
对于文档集合中的每个文档 d d d:
- 从Dirichlet分布 D i r ( α ) Dir(\alpha) Dir(α)中采样主题分布 θ d \theta_d θd
- 对于文档中的每个词 w d , n w_{d,n} wd,n:
- 从多项式分布 M u l t ( θ d ) Mult(\theta_d) Mult(θd)中采样主题 z d , n z_{d,n} zd,n
- 从多项式分布 M u l t ( ϕ z d , n ) Mult(\phi_{z_{d,n}}) Mult(ϕzd,n)中采样词 w d , n w_{d,n} wd,n
参数估计:
- 使用Gibbs采样或变分推断
- 最大化似然函数: p ( W ∣ α , β ) = ∏ d p ( w d ∣ α , β ) p(W|\alpha,\beta) = \prod_d p(w_d|\alpha,\beta) p(W∣α,β)=∏dp(wd∣α,β)
10.2.2 超参数选择
主题数K的选择:
- 困惑度(Perplexity):衡量模型对数据的拟合程度,越小越好
- 一致性(Coherence):衡量主题内词的语义一致性,越大越好
- 主题多样性:避免主题过于相似
α和β的选择:
- α:控制文档主题分布的稀疏性
- α大:文档包含更多主题
- α小:文档主题更集中
- β:控制主题词分布的稀疏性
- β大:主题包含更多词
- β小:主题词更集中
10.3 机器学习模型详解
10.3.1 线性回归
数学原理:
y = X β + ϵ y = X\beta + \epsilon y=Xβ+ϵ
其中:
- y y y:目标变量(n×1)
- X X X:特征矩阵(n×p)
- β \beta β:回归系数(p×1)
- ϵ \epsilon ϵ:误差项(n×1)
参数估计:
使用最小二乘法估计:
β ^ = ( X T X ) − 1 X T y \hat{\beta} = (X^T X)^{-1} X^T y β^=(XTX)−1XTy
假设条件:
- 线性关系
- 误差项独立同分布
- 误差项均值为0,方差恒定
- 无多重共线性
10.3.2 随机森林
算法原理:
- Bootstrap采样:从训练集中有放回地随机采样,生成多个训练子集
- 构建决策树:对每个子集构建决策树,随机选择特征子集
- 投票/平均:对所有树的预测结果进行投票(分类)或平均(回归)
优势:
- 减少过拟合
- 处理非线性关系
- 评估特征重要性
- 对缺失值不敏感
关键参数:
n_estimators:树的数量(越多越好,但计算成本高)max_depth:树的最大深度(防止过拟合)min_samples_split:分裂所需的最小样本数
10.3.3 XGBoost
算法原理:
XGBoost是一种梯度提升算法,通过迭代训练多个弱学习器(通常是决策树)来构建强学习器。
目标函数:
O b j = ∑ i = 1 n l ( y i , y ^ i ) + ∑ k = 1 K Ω ( f k ) Obj = \sum_{i=1}^{n} l(y_i, \hat{y}_i) + \sum_{k=1}^{K} \Omega(f_k) Obj=i=1∑nl(yi,y^i)+k=1∑KΩ(fk)
其中:
- l ( y i , y ^ i ) l(y_i, \hat{y}_i) l(yi,y^i):损失函数
- Ω ( f k ) \Omega(f_k) Ω(fk):正则化项
优势:
- 处理非线性关系能力强
- 内置正则化防止过拟合
- 支持并行计算
- 处理缺失值
关键参数:
n_estimators:树的数量max_depth:树的最大深度learning_rate:学习率(步长)subsample:样本采样比例colsample_bytree:特征采样比例
十一、项目总结
11.1 主要成果
- 数据爬取系统:实现了多源数据获取的爬虫系统,获得130条短剧数据
- 情感分析模块:实现了SnowNLP和BERT两种情感分析方法
- 主题模型:使用LDA提取了8个主题,识别了不同主题类型
- 预测模型:实现了线性回归、随机森林、XGBoost三种预测模型
- 可视化系统:开发了完整的Streamlit Web应用
11.2 关键发现
- 情感倾向对流行度影响很小:相关系数仅为-0.009,因为描述都是"营销文案",高度同质化
- 主题类型是影响流行度的关键因素:最流行主题与最不流行主题的差异达34.6个百分点
- 受欢迎的主题:家庭伦理/情感剧、现代都市/豪门剧、系统重生/逆袭类
- 不受欢迎的主题:超能力/奇幻类
11.3 研究局限
- 数据局限:样本量有限(130条),评论数据缺失,流行度指标不准确
- 方法局限:情感分析基于描述而非实际评论,LDA主题数量固定
- 技术局限:BERT模型需要大量计算资源,模型优化需要更多数据
11.4 未来改进方向
- 数据获取:扩大数据量,获取真实评论数据和流行度指标
- 算法优化:优化LDA主题数量选择,尝试其他主题模型
- 模型升级:使用更多特征,优化模型超参数
- 系统完善:添加更多功能,优化用户体验
附录
A. 依赖包列表
requests>=2.31.0
beautifulsoup4>=4.12.0
lxml>=4.9.0
selenium>=4.15.0
webdriver-manager>=4.0.0
pandas>=2.0.0
fake-useragent>=1.4.0
openpyxl>=3.1.0
streamlit>=1.28.0
plotly>=5.17.0
numpy>=1.24.0
matplotlib>=3.7.0
seaborn>=0.12.0
scikit-learn>=1.3.0
scipy>=1.11.0
jieba>=0.42.1
snownlp>=0.12.3
transformers>=4.30.0
torch>=2.0.0
xgboost>=2.0.0
B. 运行环境
- Python 3.8+
- Windows 10/11
- Chrome浏览器(Selenium版本需要)
C. 使用说明
- 安装依赖:
pip install -r requirements.txt - 运行爬虫:
python spider_enhanced.py - 运行分析:打开
algorithm.ipynb,依次运行所有cell - 运行系统:
streamlit run streamlit_app.py

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)