Vision Transformer(ViT)正余弦位置编码,解决空间顺序感知
一、简介
Transformer 作为自然语言处理和计算机视觉领域的里程碑模型,在视觉任务中以 Vision Transformer(ViT)为核心落地形态 ——ViT 突破了 CNN 对视觉任务的垄断,其核心思路是将 2D 图像切分为一维的图像块(Patch)序列,再通过 Transformer 自注意力机制捕捉块间的全局依赖。但自注意力机制的致命缺陷在 ViT 中同样存在:它仅计算图像块特征的相似度,完全不具备空间顺序感知能力,无论是文本序列的词序,还是 ViT 中图像块的空间位置(如左上角、中间、右下角),模型都无法天然区分 “谁在前、谁在后”。位置编码(Positional Encoding)正是为解决这一问题而生,它通过为 ViT 中每个图像块的特征向量注入空间位置信息,让 Transformer 能识别图像块的序列顺序与空间关系。
二、ViT 中的原始图像处理:图像→Patch 序列
ViT 对图像的核心预处理步骤是 “2D 图像→1D Patch 序列”,这是位置编码生效的前提,具体流程如下:
1. ViT 标准 Patch 分割逻辑
ViT 会将输入图像(通常为 H×W×C 的 RGB 图,或 H×W 的灰度图)切分为若干个固定大小的正方形 Patch(如标准 ViT 的 16×16 Patch),每个 Patch 对应图像的一个局部区域;所有 Patch 按 “从左到右、从上到下” 的空间顺序排列,形成一维序列 —— 这一步是将 2D 视觉信息转化为 Transformer 可处理的 1D 序列的核心。如下:
原始3×3灰度图像像素矩阵:
[
[10, 20, 30],
[40, 50, 60],
[70, 80, 90]
]
# ViT 风格的 Patch 分割(简化版)
第 0 个 Patch(位置编号 0):左上区域 → 像素 [10, 20; 40, 50](简化为序列第1位)
第 1 个 Patch(位置编号 1):中间区域 → 像素 [20, 30; 50, 60](简化为序列第2位)
第 2 个 Patch(位置编号 2):右下区域 → 像素 [50, 60; 80, 90](简化为序列第3位)
# 最终生成 ViT 的 Patch 序列
Patch 序列顺序:第 0 块 → 第 1 块 → 第 2 块
对应位置编号: 0 1 22.ViT 关键操作:Patch→特征向量(Patch Embedding)
分割后的 Patch 是像素矩阵(如 16×16×3),ViT 会通过线性投影(Patch Embedding) 将每个 Patch 转化为固定维度的特征向量—— 这一步让所有 Patch 统一为等长的特征向量,为后续添加位置编码、输入 Transformer 编码器做准备。
以本文 3 个 Patch 的简化示例为例:
- 每个 Patch 的像素矩阵经 Patch Embedding 后,比如转化为 4 维特征向量(适配位置编码维度);
- 3 个 Patch 最终生成 [3,4] 形状的特征矩阵(3 个 Patch × 4 维特征),此时特征向量仅包含图像内容信息,完全缺失空间位置信息 —— 这正是位置编码需要补充的核心。
3. 位置编号与序列的对应(【3,1】维度示例)
为后续计算位置编码,ViT 会为 3 个 Patch 生成位置索引矩阵,按序列顺序标记每个 Patch 的位置:
位置索引矩阵(形状 [3,1],ViT 中为一维索引扩展而来):
[
[0], # 第 0 个 Patch 的位置编号
[1], # 第 1 个 Patch 的位置编号
[2] # 第 2 个 Patch 的位置编号
]
三、ViT 中位置编码矩阵的生成(正弦 / 余弦 + 缩放因子)
在 ViT 中,得到 3 个 Patch 的特征矩阵([3,4])和位置索引矩阵([3,1])后,下一步核心是通过正弦 / 余弦函数 + 缩放因子生成同维度的位置编码矩阵([3,4])—— 这是为 Patch 特征注入空间位置信息的关键步骤,完全沿用 Transformer 原论文的位置编码设计。
论文中位置编码公式:
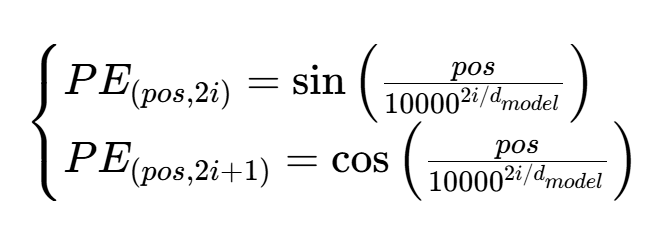
原公式的缩放分母计算较复杂,论文中通过指数 / 对数变换,将其转化为更易计算的缩放因子(div_term):
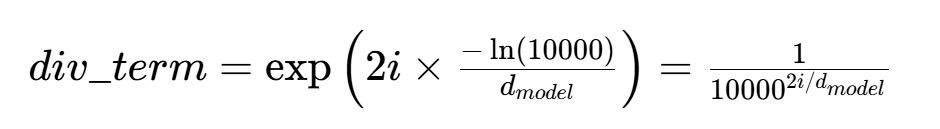
# 创建位置编码矩阵
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, embed_dim, 2) * (-math.log(10000.0) / embed_dim))
pe = torch.zeros(max_len, embed_dim)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
- `div_term`: 位置编码的分母项,用于缩放位置索引
- `pe`: 位置编码矩阵,形状为[max_len, embed_dim]
- `pe[:, 0::2] = torch.sin(position * div_term)`: 偶数位置使用正弦函数
- `pe[:, 1::2] = torch.cos(position * div_term)`: 奇数位置使用余弦函数缩放因子(div_term)
位置编码也要做成 [3,4] 的矩阵,才能和上面的块向量直接相加。怎么从 [3,1] 的位置,算出 [3,4] 的位置编码?这个就需要缩放因子参与
即embed_dim=4,就是每个位置要生成4 个数字。如果每个位置的数值不缩放,直接用 sin (0)、sin (1)、sin (2),那 4 个数字会重复、没区别。所以我们给每 2 个维度配一个缩放系数:embed_dim=4 → 分成 2 组,对应 2 个缩放值:
div_term = [1, 0.01]作用:给向量的前 2 维用快节奏,后 2 维用慢节奏,让 4 个数字各不相同
[3,1] × [2] → 算出 3 行 2 列的角度
位置0 × [1, 0.01] → [0, 0]
位置1 × [1, 0.01] → [1, 0.01]
位置2 × [1, 0.01] → [2, 0.02]
sin /cos 填满 4 列,得到 [3,4] 位置编码
位置0:[ sin(0), cos(0), sin(0), cos(0) ] → [ 0, 1, 0, 1 ]
位置1:[ sin(1), cos(1), sin(0.01), cos(0.01) ]->[0.84,0.54,0.01,1]
位置2:[ sin(2), cos(2), sin(0.02), cos(0.02) ]->[0.91,-0.42,0.02,1]
和图像块向量相加
图像块特征 [3,4] + 位置编码 [3,4]
[ a, b, c, d ] + [ 0, 1, 0, 1 ]
[ e, f, g, h ] + [sin1,cos1,sin0.01,cos0.01]
[ i, j, k, l ] + [sin2,cos2,sin0.02,cos0.02]关键变化:原本几乎一样的特征向量,加了位置编码后,每个维度的数值都拉开了差距:
如:
位置 原特征向量 + 位置编码 = 带位置的特征向量
块 0 [1,2,3,4] [0,1,0,1] [1, 3, 3, 5]
块 1 [1.1,2.1,3.1,4.1] [0.84,0.54,0.01,1] [1.94, 2.64, 3.11, 5.1]
块 2 [1.2,2.2,3.2,4.2] [0.91,-0.42,0.02,1] [2.11, 1.78, 3.22, 5.2]- 第 0 维:1 → 1.94 → 2.11(快维度,差距大)
- 第 1 维:3 → 2.64 → 1.78(快维度,差距更大)
- 第 2 维:3 → 3.11 → 3.22(慢维度,差距小但有)
- 第 3 维:5 → 5.1 → 5.2(慢维度,差距小但有)
- 快维度(第 0、1 维):相邻位置的标签值差很大(比如块 0→块 1,第 1 维从 3→2.64),模型能瞬间分清 “挨在一起的块”;
- 慢维度(第 2、3 维):相邻位置的标签值差很小,但如果是远距离块(比如块 0 和块 100),慢维度的标签值会慢慢拉开,模型能分清 “隔很远的块”。
如sin (x) 作为周期震荡函数,慢维度依赖极小的缩放因子(如 0.01),让位置编号转化为角度 x 的增速极慢,只有序列长度足够长时,x 的累积变化才能使 sin (x) 产生可区分的数值差;若缩放因子过大(如接近 1),x 会随位置快速增长,sin (x) 因频繁震荡导致远距离位置的编码值重复,丧失对长序列位置的区分度。
但模型不会单独依赖快维度或慢维度判断位置,而是综合快慢维度 + sin/cos 奇偶维度的互补信息实现精准定位:快维度(大缩放因子)能快速区分相邻位置,但长序列下易因 sin (x) 震荡重复丢失区分度;慢维度(小缩放因子)相邻位置差异小,却能通过角度累积体现远距离位置差异;同时 sin/cos 奇偶维度互补(
数学上,对任意位置 pos,(sin(pos×k), cos(pos×k)) 是唯一的坐标(极坐标):
- 位置 0:(sin0, cos0) = (0,1) → 唯一
- 位置 1:(sin1, cos1) ≈ (0.84,0.54) → 唯一
- 位置 2:(sin2, cos2) ≈ (0.91,-0.42) → 唯一
),避免单函数值重复。最终模型通过自注意力点积运算,整合所有维度的数值特征,判断每个 Patch 的相对位置。
Transformer 的自注意力要处理两种位置关系:
- 短距离依赖(比如相邻块的纹理关联)→ 需要「快变化分组(缩放 1)」:
- 相邻块的编码值差大→点积相似度差大→模型能快速捕捉 “这两个块挨得近”;
- 长距离依赖(比如图片左上角和右下角的全局关联)→ 需要「慢变化分组(缩放 0.01)」:
- 远距离块的编码值不会因为 sin 周期震荡而重复→点积能体现 “这两个块离得远,但仍有全局关联”。
如果不分组(全用一个缩放因子):
- 全用快因子→长距离块的编码重复→自注意力分不清;
- 全用慢因子→短距离块的编码几乎一样→自注意力也分不清。
对接下来Transformer 注意力机制计算的影响
自注意力的核心是计算「查询向量 (Q) 和键向量 (K) 的点积」,点积越大→相似度越高→注意力权重越大。
以下为例
块0:[1,2,3,4] 块1:[1.1,2.1,3.1,4.1] 块2:[1.2,2.2,3.2,4.2]
第一步:不加位置编码→点积相似度(完全体现不出顺序)
计算块 0 的 Q 和所有块的 K 的点积(Q=K = 原始特征):
- 块 0・块 0 = 1×1 + 2×2 + 3×3 + 4×4 = 30
- 块 0・块 1 = 1×1.1 + 2×2.1 + 3×3.1 + 4×4.1 = 31
- 块 0・块 2 = 1×1.2 + 2×2.2 + 3×3.2 + 4×4.2 = 32
点积几乎一样,模型会认为 “块 0 和块 2 的相似度更高”,位置搞错
第二步:加位置编码→点积相似度(能体现位置远近)
加位置编码后的向量:
块0:[1,3,3,5] 块1:[1.94,2.64,3.11,5.1] 块2:[2.11,1.78,3.22,5.2]再计算块 0 的 Q 和所有块的 K 的点积:
- 块 0・块 0 = 1×1 + 3×3 + 3×3 + 5×5 = 1+9+9+25 = 44
- 块 0・块 1 = 1×1.94 + 3×2.64 + 3×3.11 + 5×5.1 = 1.94+7.92+9.33+25.5 = 44.69
- 块 0・块 2 = 1×2.11 + 3×1.78 + 3×3.22 + 5×5.2 = 2.11+5.34+9.66+26 = 43.11
关键变化:块 0 和相邻的块 1点积(44.69)> 块 0 和自己的点积(44)> 块 0 和远距离的块 2点积(43.11)→ 模型能通过点积判断:“块 0 和块 1 挨得近,和块 2 离得远”,这就是顺序感知的核心。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)