Streamlit+Qwen3.5构造多模态对话助手
🌈
本文介绍了一种基于本地的qwen3.5-9b、Z-Image-Turbo模型以及搜索功能的多模态对话助手实现方法。
今天分享的是我基于Streamlit与本地的qwen3.5-9b、Z-Image-Turbo模型以及搜索功能构建的多模态对话助手。该助手具有对话交流,自动意图识别,自动生成图片,对图片内容进行理解,自动联网搜索,上下文记忆、多轮对话功能。为了解决本地显存不足的问题,采用了多卡模式,不足时自动清理显存。
实现效果
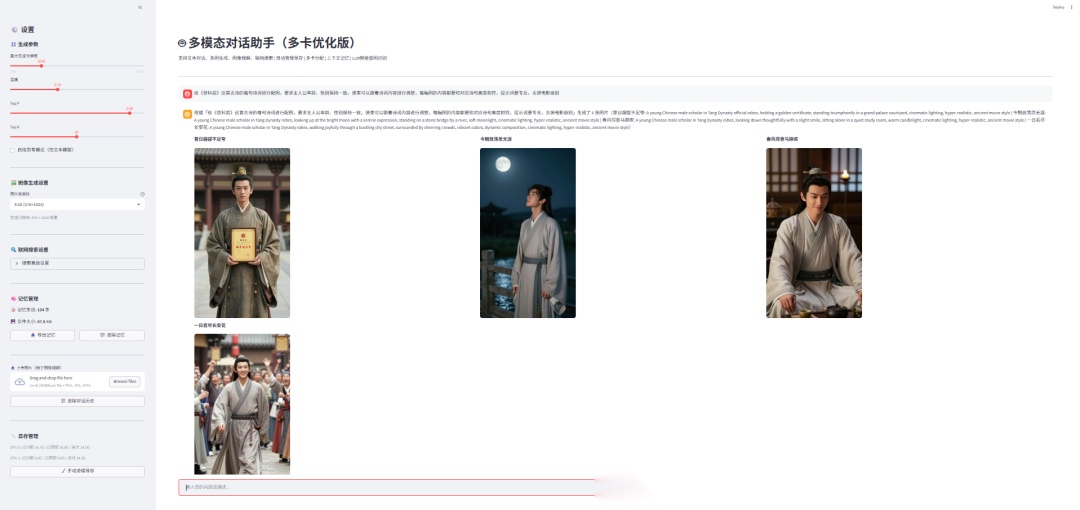
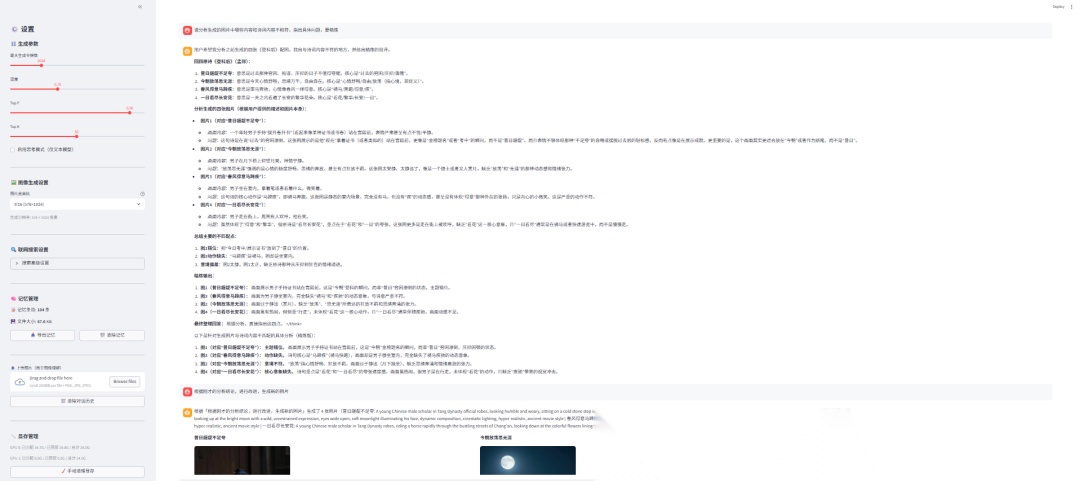
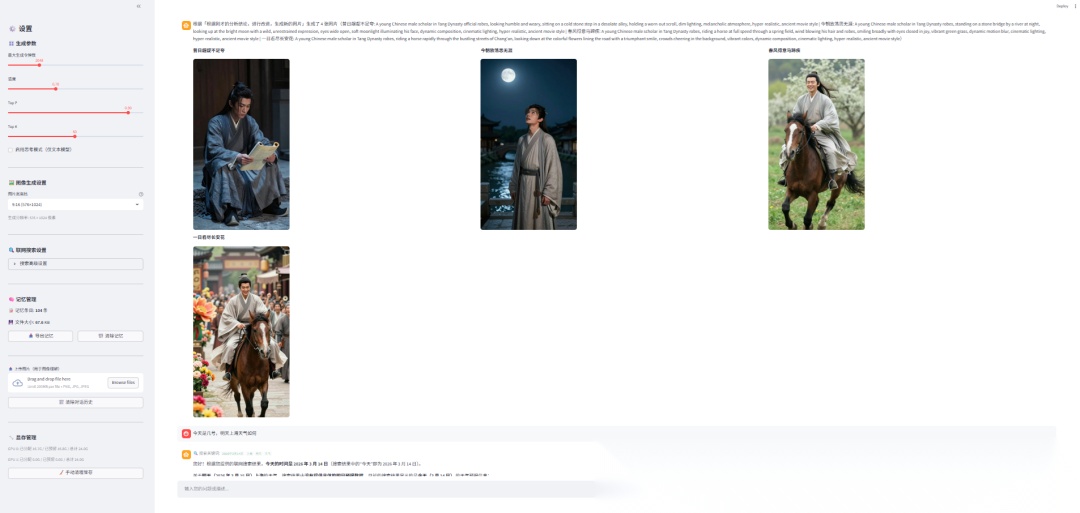
实现代码
import streamlit as stimport torchfrom transformers import ( AutoModelForCausalLM, AutoTokenizer, AutoModelForImageTextToText, AutoProcessor, TextIteratorStreamer)from diffusers import DiffusionPipelinefrom threading import Threadfrom PIL import Imagefrom datetime import datetimeimport ioimport gcimport reimport osimport jsonimport randomtry: from FreeKnowledge_AI import knowledge_center SEARCH_AVAILABLE = Trueexcept ImportError: SEARCH_AVAILABLE = False# -------------------- 页面配置 --------------------st.set_page_config( page_title="多模态对话助手(多卡优化版)", page_icon="🤖", layout="wide", initial_sidebar_state="expanded")# -------------------- 自定义样式 --------------------st.markdown("""<style> .stChatMessage { padding: 0.8rem 1rem; } .generated-image-container { max-width: 420px; margin: 0.5rem 0; border-radius: 12px; overflow: hidden; box-shadow: 0 2px 8px rgba(0,0,0,0.1); } .memory-status { font-size: 0.8rem; color: #888; text-align: center; padding: 4px 0; } div[data-testid="stImage"] img { border-radius: 8px; } .intent-badge { display: inline-block; padding: 2px 10px; border-radius: 12px; font-size: 0.75rem; margin-bottom: 6px; } .search-result-box { background: rgba(100, 149, 237, 0.08); border-left: 3px solid #6495ed; padding: 8px 12px; margin: 6px 0; border-radius: 0 8px 8px 0; font-size: 0.9rem; } .poem-title { font-style: italic; color: #5a4a3a; margin-bottom: 4px; font-size: 0.95rem; } .keyword-tag { display: inline-block; background: rgba(100, 149, 237, 0.15); color: #3366cc; padding: 2px 8px; border-radius: 10px; font-size: 0.8rem; margin: 2px 3px; }</style>""", unsafe_allow_html=True)# -------------------- 宽高比配置 --------------------ASPECT_RATIO_OPTIONS = { "9:16 (576×1024)": (576, 1024), "1:1 (1024×1024)": (1024, 1024), "3:4 (768×1024)": (768, 1024), "4:3 (1024×768)": (1024, 768), "16:9 (1024×576)": (1024, 576), "2:3 (682×1024)": (682, 1024), "3:2 (1024×682)": (1024, 682), "1:2 (512×1024)": (512, 1024), "2:1 (1024×512)": (1024, 512),}# -------------------- 对话历史限制常量 --------------------MAX_TEXT_HISTORY_TURNS = 20MAX_VL_HISTORY_TURNS = 6MAX_VL_IMAGES = 4MAX_SEARCH_HISTORY_TURNS = 10# -------------------- 初始化会话状态 --------------------if"messages"notin st.session_state: st.session_state.messages = []if"uploaded_image"notin st.session_state: st.session_state.uploaded_image = Noneif"loaded_model"notin st.session_state: st.session_state.loaded_model = { "name": None, "model": None, "tokenizer/processor": None, "device": None }if"memory_file"notin st.session_state: st.session_state.memory_file = "memory.md"# -------------------- 模型路径配置(默认值) --------------------DEFAULT_TEXT_PATH = r"E:\Qwen\Qwen3.5-9B\models"DEFAULT_VL_PATH = r"E:\Qwen\Qwen3.5-9B\models"DEFAULT_GEN_PATH = r"E:\Qwen\Z-Image-Turbo"if"text_model_path"notin st.session_state: st.session_state.text_model_path = DEFAULT_TEXT_PATHif"vl_model_path"notin st.session_state: st.session_state.vl_model_path = DEFAULT_VL_PATHif"gen_model_path"notin st.session_state: st.session_state.gen_model_path = DEFAULT_GEN_PATHif"device_text"notin st.session_state: st.session_state.device_text = "auto"if"device_vl"notin st.session_state: st.session_state.device_vl = "auto"if"device_gen"notin st.session_state: st.session_state.device_gen = "auto"if"aspect_ratio"notin st.session_state: st.session_state.aspect_ratio = "1:1 (1024×1024)"# -------------------- 联网搜索配置(默认值) --------------------if"search_mode"notin st.session_state: st.session_state.search_mode = "BAIDU"if"search_api_key"notin st.session_state: st.session_state.search_api_key = "sk-****这里替换成在硅基流动创建的key****"if"search_api_base"notin st.session_state: st.session_state.search_api_base = "https://api.siliconflow.cn/v1/chat/completions"if"search_api_model"notin st.session_state: st.session_state.search_api_model = "internlm/internlm2_5-7b-chat"if"search_max_results"notin st.session_state: st.session_state.search_max_results = 5if"search_enabled"notin st.session_state: st.session_state.search_enabled = True# -------------------- 记忆系统 --------------------MEMORY_FILE = "memory.md"definit_memory_file(): ifnot os.path.exists(MEMORY_FILE): withopen(MEMORY_FILE, "w", encoding="utf-8") as f: f.write("# 对话记忆\n\n") f.write(f"> 创建时间:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n\n") f.write("---\n\n")defsave_to_memory(role, content_text, intent=None, has_image=False): init_memory_file() timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S") withopen(MEMORY_FILE, "a", encoding="utf-8") as f: role_label = "👤 用户"if role == "user"else"🤖 助手" f.write(f"### {role_label} [{timestamp}]\n\n") if intent: intent_map = { "text": "💬 文本对话", "generate": "🎨 图像生成", "understand": "👁️ 图像理解", "search": "🔍 联网搜索" } f.write(f"**意图识别**: {intent_map.get(intent, intent)}\n\n") if has_image: f.write("📎 *附带图片*\n\n") if content_text: clean_text = content_text.replace("\n", "\n> ") f.write(f"> {clean_text}\n\n") f.write("---\n\n")defload_memory_context(max_entries=20): ifnot os.path.exists(MEMORY_FILE): return"" withopen(MEMORY_FILE, "r", encoding="utf-8") as f: content = f.read() sections = content.split("---") recent = sections[-max_entries - 1:-1] iflen(sections) > max_entries + 1else sections[1:-1] ifnot recent: return"" summary_parts = [] for section in recent: lines = [line.strip() for line in section.strip().split("\n") if line.strip()] for line in lines: if line.startswith(">"): summary_parts.append(line.lstrip("> ").strip()) if summary_parts: return"以下是之前对话的摘要记忆:\n" + "\n".join(summary_parts[-10:]) return""defget_memory_stats(): ifnot os.path.exists(MEMORY_FILE): return {"exists": False, "entries": 0, "size_kb": 0} withopen(MEMORY_FILE, "r", encoding="utf-8") as f: content = f.read() entries = content.count("### ") size_kb = os.path.getsize(MEMORY_FILE) / 1024 return {"exists": True, "entries": entries, "size_kb": round(size_kb, 1)}# -------------------- 辅助函数:显存清理 --------------------defclear_gpu_memory(): gc.collect() if torch.cuda.is_available(): torch.cuda.empty_cache() torch.cuda.synchronize()defunload_current_model(): if st.session_state.loaded_model["model"] isnotNone: del st.session_state.loaded_model["model"] del st.session_state.loaded_model["tokenizer/processor"] st.session_state.loaded_model["model"] = None st.session_state.loaded_model["tokenizer/processor"] = None st.session_state.loaded_model["name"] = None st.session_state.loaded_model["device"] = None clear_gpu_memory()defget_target_device(device_setting): if device_setting == "auto": return"cuda:0"if torch.cuda.is_available() else"cpu" else: return device_setting if torch.cuda.is_available() else"cpu"# -------------------- 对话历史截断工具函数 --------------------deftruncate_messages_for_text(messages, max_turns=MAX_TEXT_HISTORY_TURNS): iflen(messages) <= max_turns: return messages return messages[-max_turns:]deftruncate_messages_for_vl(messages, max_turns=MAX_VL_HISTORY_TURNS, max_images=MAX_VL_IMAGES): iflen(messages) <= max_turns: recent = messages else: recent = messages[-max_turns:] image_count = 0 filtered = [] for msg inreversed(recent): if msg["type"] in ("multimodal", "image"): content = msg["content"] imgs = content.get("images", []) if image_count + len(imgs) > max_images: text_only_content = {} if"text"in content and content["text"]: text_only_content["text"] = content["text"] if text_only_content: filtered.append({ "role": msg["role"], "type": "text", "content": text_only_content.get("text", "") }) else: image_count += len(imgs) filtered.append(msg) else: filtered.append(msg) filtered.reverse() return filtereddeftruncate_messages_for_search(messages, max_turns=MAX_SEARCH_HISTORY_TURNS): iflen(messages) <= max_turns: return messages return messages[-max_turns:]# -------------------- 模型加载函数 --------------------defload_text_model(model_path, device): tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained( model_path, torch_dtype=torch.float16, device_map=device, trust_remote_code=True ) model.eval() return tokenizer, modeldefload_vl_model(model_path, device): processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True) model = AutoModelForImageTextToText.from_pretrained( model_path, torch_dtype=torch.float16, device_map=device, trust_remote_code=True ) model.eval() return processor, modeldefload_gen_model(model_path, device): pipe = DiffusionPipeline.from_pretrained( model_path, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, ) pipe.to(device) return pipe# -------------------- 模型切换函数 --------------------defensure_model_loaded(model_type): if st.session_state.loaded_model["name"] == model_type: return unload_current_model() device_setting = None model_path = None if model_type == "text": device_setting = st.session_state.device_text model_path = st.session_state.text_model_path elif model_type == "vl": device_setting = st.session_state.device_vl model_path = st.session_state.vl_model_path elif model_type == "gen": device_setting = st.session_state.device_gen model_path = st.session_state.gen_model_path else: raise ValueError(f"Unknown model type: {model_type}") device = get_target_device(device_setting) with st.spinner(f"🔄 正在加载 {model_type} 模型到 {device}..."): if model_type == "text": tokenizer, model = load_text_model(model_path, device) st.session_state.loaded_model["tokenizer/processor"] = tokenizer st.session_state.loaded_model["model"] = model elif model_type == "vl": processor, model = load_vl_model(model_path, device) st.session_state.loaded_model["tokenizer/processor"] = processor st.session_state.loaded_model["model"] = model elif model_type == "gen": model = load_gen_model(model_path, device) st.session_state.loaded_model["model"] = model st.session_state.loaded_model["tokenizer/processor"] = None st.session_state.loaded_model["name"] = model_type st.session_state.loaded_model["device"] = device# -------------------- 联网搜索功能 --------------------defperform_web_search(query_string): ifnot SEARCH_AVAILABLE: returnNone try: center = knowledge_center.Center() results = center.get_response( query_string, True, st.session_state.search_mode, model=st.session_state.search_api_model, base_url=st.session_state.search_api_base, key=st.session_state.search_api_key, max_web_results=st.session_state.search_max_results ) if results andisinstance(results, str) and results.strip(): return results.strip() elif results andisinstance(results, dict): return json.dumps(results, ensure_ascii=False, indent=2) elif results andisinstance(results, list): return"\n\n".join([str(item) for item in results]) else: returnstr(results) if results elseNone except Exception as e: returnf"[搜索异常: {str(e)}]"defextract_search_info(raw_results): ifnot raw_results: return"" text = str(raw_results) text = re.sub(r'<[^>]+>', '', text) text = re.sub(r'\n{3,}', '\n\n', text) text = text.strip() max_chars = 4000 iflen(text) > max_chars: text = text[:max_chars] + "\n\n...(搜索结果已截断)" return text# -------------------- 搜索关键词提取(备用,不依赖LLM) --------------------deffallback_extract_keywords(user_text): stop_words = { "帮我", "帮忙", "请", "请问", "你好", "可以", "能不能", "能否", "我想", "我要", "我想要", "麻烦", "一下", "吗", "呢", "吧", "的", "了", "在", "是", "有", "和", "与", "或", "也", "都", "把", "被", "让", "给", "对", "从", "到", "以", "为", "什么", "怎么", "怎样", "如何", "哪里", "哪个", "谁", "这个", "那个", "这些", "那些", "它", "他", "她", "搜索", "搜一下", "查一下", "查询", "检索", "帮我查", "帮我搜", "上网", "联网", "查找", "找一下", "看看", "告诉我", "说说", "介绍", "整理", "总结", "列出", } text = user_text.strip() text = re.sub(r'[,。!?、;:""''()【】《》\s]+', ' ', text) words = text.split() keywords = [] for word in words: word = word.strip() ifnot word: continue if word in stop_words: continue iflen(word) == 1andnot word.isdigit(): continue keywords.append(word) ifnot keywords: keywords = [w.strip() for w in user_text.split() if w.strip()] ifnot keywords: keywords = [user_text.strip()] return keywords# -------------------- 智能意图识别(调用语言模型) --------------------INTENT_SYSTEM_PROMPT = """你是一个意图分类器。用户会给你一段话,你需要判断用户的意图属于以下四种之一:1. "generate" — 用户希望生成、绘制、创作图片/图像。包括但不限于: - 明确要求画画、生成图片(如"画一只猫"、"生成一张风景图") - 要求为某内容配图、插图(如"给这首诗配几幅图"、"帮这段话配一张图") - 要求创作视觉内容(如"设计一个海报"、"做一张壁纸") - 任何需要产出图像作为结果的请求2. "understand" — 用户上传了图片并希望理解、分析、描述图片内容。或者用户在对话中引用之前的图片要求进一步解读。3. "search" — 用户的问题需要联网搜索才能准确回答。包括但不限于: - 询问最新新闻、时事、实时信息 - 需要查询实时数据(天气、股价、赛事比分、汇率) - 询问你不确定或可能过时的事实性问题 - 用户明确要求搜索或查询 - 涉及具体日期、地点的近期事件4. "text" — 纯文本对话,包括问答、写作、翻译、代码、闲聊等。当问题可以用已有知识准确回答时选此项。请只回复一个JSON对象,格式如下,不要有任何其他内容:当需要生成图片时:{"intent": "generate", "prompts": ["英文提示词1", "英文提示词2", ...], "titles": ["图片标题1", "图片标题2", ...]}当需要联网搜索时:{"intent": "search", "keywords": ["关键词1", "关键词2", "关键词3", ...]}当为纯文本对话时:{"intent": "text"}当为图像理解时:{"intent": "understand"}关键规则(图片生成):- "prompts" 数组中每个元素是适合AI绘画模型的英文提示词,描述具体场景、物体、光线、色彩、风格。- "titles" 数组中每个元素是对应图片的中文标题,与 prompts 一一对应。【titles 标题规则——非常重要】:- 如果用户要求为古诗、诗词、歌词、名句等配图,titles 必须使用原文诗句/歌词/名句本身作为标题,每张图对应一句原文。例如用户说"给静夜思配图",titles 应为 ["床前明月光", "疑是地上霜", "举头望明月", "低头思故乡"],而不是"静夜思意境图一"之类的描述。- 如果用户要求为某段文字、故事、场景配图,titles 应摘取或概括该文字中最核心的短句作为标题。- 如果用户只是要求画某样东西(如"画一只猫"),titles 使用简洁描述即可(如"慵懒的猫咪")。- titles 应简短凝练,每个不超过15字。- 如果用户要求多张图,prompts 数组里应包含多个不同提示词,每个描述不同场景。最多6张,"几幅"理解为3-4幅。关键规则(联网搜索):- "keywords" 是一个数组,包含从用户问题中提取的核心搜索关键词。- 关键词提取原则: 1. 去除所有语气词、助词、连接词(如"帮我"、"请"、"一下"、"的"、"吗"等) 2. 去除动作指令词(如"搜索"、"查一下"、"告诉我"、"整理"、"总结"等) 3. 保留实义名词、时间词、地点词、人名、专有名词、数字等核心信息词 4. 如果涉及时间,自动补充具体年份(如"今年" → "2026年","最近" → "2026") 5. 每个关键词应是一个独立的信息单元,不要过长 6. 一般提取3-6个关键词- 示例: - "帮我查一下今年植树节在哪里举办的,整理一下对应新闻稿" → ["2026年", "植树节", "举办地点", "新闻"] - "最近英伟达的股票表现怎么样" → ["英伟达", "股票", "走势", "2026"] - "苹果公司最新发布了什么产品" → ["苹果公司", "最新", "发布", "产品", "2026"]- 只输出JSON,不要有任何解释文字。"""defdetect_intent_with_llm(user_text, has_image, conversation_history): if has_image: return"understand", [], [], [] ensure_model_loaded("text") tokenizer = st.session_state.loaded_model["tokenizer/processor"] model = st.session_state.loaded_model["model"] device = st.session_state.loaded_model["device"] recent_context = "" recent_msgs = conversation_history[-6:] iflen(conversation_history) > 6else conversation_history for msg in recent_msgs: role_label = "用户"if msg["role"] == "user"else"助手" if msg["type"] == "text": recent_context += f"{role_label}: {msg['content']}\n" elif msg["type"] == "multimodal": content = msg["content"] text_part = content.get("text", "") has_img = "images"in content andlen(content["images"]) > 0 if has_img: recent_context += f"{role_label}: [附带图片] {text_part}\n" else: recent_context += f"{role_label}: {text_part}\n" elif msg["type"] == "image": content = msg["content"] text_part = content.get("text", "") recent_context += f"{role_label}: [生成了图片] {text_part}\n" elif msg["type"] == "search": content = msg["content"] text_part = content.get("text", "") recent_context += f"{role_label}: [搜索回答] {text_part[:100]}\n" current_time = datetime.now().strftime("%Y年%m月%d日 %H:%M") classify_messages = [ {"role": "system", "content": INTENT_SYSTEM_PROMPT}, {"role": "user", "content": f"当前时间:{current_time}\n\n对话上下文:\n{recent_context}\n\n当前用户输入:{user_text}\n\n请判断意图并输出JSON:"} ] text = tokenizer.apply_chat_template( classify_messages, tokenize=False, add_generation_prompt=True, enable_thinking=False ) inputs = tokenizer(text, return_tensors="pt").to(device) with torch.no_grad(): outputs = model.generate( **inputs, max_new_tokens=600, temperature=0.1, top_p=0.9, do_sample=True, ) input_len = inputs["input_ids"].shape[1] generated_ids = outputs[0][input_len:] response_text = tokenizer.decode(generated_ids, skip_special_tokens=True).strip() del inputs, outputs, generated_ids clear_gpu_memory() intent, prompts_list, titles_list, search_keywords = parse_intent_response(response_text) if intent == "search"and (not st.session_state.search_enabled ornot SEARCH_AVAILABLE): intent = "text" search_keywords = [] return intent, prompts_list, titles_list, search_keywordsdefparse_intent_response(response_text): json_match = re.search(r'\{.*\}', response_text, re.DOTALL) if json_match: try: result = json.loads(json_match.group()) intent = result.get("intent", "text") if intent notin ("generate", "understand", "text", "search"): intent = "text" if intent == "generate": prompts = result.get("prompts", []) titles = result.get("titles", []) ifisinstance(prompts, str): prompts = [prompts] ifisinstance(titles, str): titles = [titles] old_prompt = result.get("prompt", None) ifnot prompts and old_prompt: prompts = [old_prompt] prompts = [p for p in prompts ifisinstance(p, str) and p.strip()] iflen(prompts) > 6: prompts = prompts[:6] titles = titles[:6] whilelen(titles) < len(prompts): titles.append(f"图片 {len(titles) + 1}") return intent, prompts, titles, [] if intent == "search": keywords = result.get("keywords", []) ifisinstance(keywords, str): keywords = [k.strip() for k in keywords.split() if k.strip()] old_query = result.get("query", None) ifnot keywords and old_query: keywords = [k.strip() for k in old_query.split() if k.strip()] keywords = [k for k in keywords ifisinstance(k, str) and k.strip()] return intent, [], [], keywords return intent, [], [], [] except json.JSONDecodeError: pass text_lower = response_text.lower() if"generate"in text_lower: return"generate", [], [], [] elif"understand"in text_lower: return"understand", [], [], [] elif"search"in text_lower: return"search", [], [], [] else: return"text", [], [], []deffallback_detect_intent(user_text): text_lower = user_text.lower().strip() generate_patterns = [ r"(帮我|请|给我|我想|我要|能不能|可以).{0,15}(画|绘制|生成|创建|制作|配).{0,15}(图|图片|图像|照片|壁纸|头像|海报|插画|漫画)", r"(画|绘制|生成|创建|制作)一?(张|幅|个|副|组)?.{0,20}(图|图片|图像|照片|壁纸|头像|海报|插画|漫画)", r"(draw|paint|generate|create|make)\s+(a|an|the|me)?\s*(image|picture|photo|illustration|poster|avatar|wallpaper)", r"(配|搭配|添加|加上).{0,10}(图|图片|插图|插画|配图)", r"(想要|需要|来).{0,10}(图|图片|图像)", ] for pattern in generate_patterns: if re.search(pattern, text_lower): return"generate", [], [], [] search_patterns = [ r"(搜索|搜一下|查一下|查询|检索|帮我查|帮我搜|上网|联网)", r"(最新|最近|今天|昨天|今年|本月|这周|刚刚|实时|当前).{0,10}(新闻|消息|动态|情况|进展|数据|信息|价格|天气|比分)", r"(现在|目前|当下).{0,10}(是谁|多少|怎样|如何|什么)", r"(news|latest|today|current|recent|search|look up|find out)", ] for pattern in search_patterns: if re.search(pattern, text_lower): if st.session_state.search_enabled and SEARCH_AVAILABLE: keywords = fallback_extract_keywords(user_text) return"search", [], [], keywords else: return"text", [], [], [] return"text", [], [], []# -------------------- 为图像生成构造英文提示词(备用/补充) --------------------defgenerate_image_prompts_with_llm(user_text, count=1): ensure_model_loaded("text") tokenizer = st.session_state.loaded_model["tokenizer/processor"] model = st.session_state.loaded_model["model"] device = st.session_state.loaded_model["device"] if count <= 1: system_content = """你是一个AI绘画提示词专家。用户会给你一段描述,你需要将其转换为高质量英文AI绘画提示词。请只输出一个JSON对象:{"prompts": ["英文prompt"], "titles": ["标题"]}【titles 标题规则】:- 如果用户要求为古诗、诗词、歌词、名句配图,titles 必须使用原文诗句本身,例如"床前明月光"而不是"月光图"- 如果是为故事/文字配图,titles 使用文中核心短句- 如果是自由创作,titles 使用简洁描述不要有任何其他文字。""" else: system_content = f"""你是一个AI绘画提示词专家。用户会给你一段描述,你需要根据描述生成{count}段不同角度/场景的高质量英文AI绘画提示词。请只输出一个JSON对象:{{"prompts": ["英文prompt1", ...], "titles": ["标题1", ...]}}【titles 标题规则——非常重要】:- 如果用户要求为古诗、诗词、歌词、名句配图,titles 必须使用原文诗句/歌词本身作为标题,每张图对应一句原文。例如用户说"给静夜思配图",titles 应为 ["床前明月光", "疑是地上霜", "举头望明月", "低头思故乡"]- 如果是为故事/文字配图,titles 使用文中核心短句- 如果是自由创作,titles 使用简洁描述- titles 每个不超过15字不要有任何其他文字。""" prompt_messages = [ {"role": "system", "content": system_content}, {"role": "user", "content": user_text} ] text = tokenizer.apply_chat_template( prompt_messages, tokenize=False, add_generation_prompt=True, enable_thinking=False ) inputs = tokenizer(text, return_tensors="pt").to(device) with torch.no_grad(): outputs = model.generate( **inputs, max_new_tokens=500, temperature=0.7, top_p=0.9, do_sample=True, ) input_len = inputs["input_ids"].shape[1] generated_ids = outputs[0][input_len:] response_text = tokenizer.decode(generated_ids, skip_special_tokens=True).strip() del inputs, outputs, generated_ids clear_gpu_memory() json_match = re.search(r'\{.*\}', response_text, re.DOTALL) if json_match: try: result = json.loads(json_match.group()) prompts = result.get("prompts", []) titles = result.get("titles", []) ifisinstance(prompts, str): prompts = [prompts] ifisinstance(titles, str): titles = [titles] prompts = [p for p in prompts ifisinstance(p, str) and p.strip()] whilelen(titles) < len(prompts): titles.append(f"图片 {len(titles) + 1}") if prompts: return prompts, titles except json.JSONDecodeError: pass cleaned = response_text.strip('"').strip("'").strip() return [cleaned] if cleaned else [user_text], ["图片 1"]defestimate_image_count(user_text): num_map = { "一": 1, "二": 2, "两": 2, "三": 3, "四": 4, "五": 5, "六": 6, "七": 7, "八": 8, "九": 9, "十": 10, } match = re.search(r'(\d+)\s*[张幅个副组]', user_text) ifmatch: returnmin(int(match.group(1)), 6) for cn_char, num in num_map.items(): pattern = cn_char + r'\s*[张幅个副组]' if re.search(pattern, user_text): returnmin(num, 6) multi_keywords = ["几幅", "几张", "几个", "几副", "多张", "多幅", "一些", "一组", "一批", "一套", "系列"] for kw in multi_keywords: if kw in user_text: return4 return1# -------------------- 搜索结果 + 语言模型整合回答 --------------------defgenerate_search_response_stream(user_text, search_results, messages, max_tokens, temperature, top_p, top_k, enable_thinking): ensure_model_loaded("text") tokenizer = st.session_state.loaded_model["tokenizer/processor"] model = st.session_state.loaded_model["model"] device = st.session_state.loaded_model["device"] text_messages = [] memory_context = load_memory_context(max_entries=10) system_content = "你是一个智能助手,擅长根据联网搜索结果来回答用户问题。" if memory_context: system_content += f"\n\n{memory_context}" system_content += f"\n\n以下是联网搜索获取的参考资料:\n\n{search_results}\n\n请根据以上参考资料,结合你自己的知识,准确、详细地回答用户的问题。要求:\n1. 优先使用搜索结果中的最新信息\n2. 如果搜索结果包含具体的时间、地点、人物等,请准确引用\n3. 对信息进行整理和总结,以清晰易读的方式呈现\n4. 如果搜索结果不足以完整回答问题,可以补充你已有的知识,但需注明\n5. 用中文回答(除非用户用其他语言提问)" text_messages.append({"role": "system", "content": system_content}) truncated = truncate_messages_for_search(messages[:-1]) for msg in truncated: if msg["type"] == "text": text_messages.append({"role": msg["role"], "content": msg["content"]}) elif msg["type"] == "multimodal": content = msg["content"] if"text"in content and content["text"]: text_messages.append({"role": msg["role"], "content": content["text"]}) elif msg["type"] == "image": content = msg["content"] if"text"in content and content["text"]: text_messages.append({"role": msg["role"], "content": content["text"]}) elif msg["type"] == "search": content = msg["content"] if"text"in content and content["text"]: text_messages.append({"role": msg["role"], "content": content["text"]}) text_messages.append({"role": "user", "content": user_text}) text = tokenizer.apply_chat_template( text_messages, tokenize=False, add_generation_prompt=True, enable_thinking=enable_thinking ) inputs = tokenizer(text, return_tensors="pt").to(device) streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True) generate_kwargs = { **inputs, "max_new_tokens": max_tokens, "temperature": temperature if temperature > 0else1.0, "top_p": top_p, "top_k": top_k, "do_sample": temperature > 0, "streamer": streamer, } def_generate(): with torch.no_grad(): model.generate(**generate_kwargs) thread = Thread(target=_generate) thread.start() for new_text in streamer: yield new_text thread.join() del inputs clear_gpu_memory()# -------------------- 图片显示尺寸计算 --------------------defget_display_width(num_images): if num_images == 1: return480 elif num_images == 2: return400 else: return340defdisplay_images_grid(images, titles, num_images): display_w = get_display_width(num_images) if num_images == 1: if titles: st.markdown(f"**{titles[0]}**") st.image(images[0], width=display_w) elif num_images == 2: cols = st.columns(2) for idx, img inenumerate(images): with cols[idx]: if idx < len(titles): st.markdown(f"**{titles[idx]}**") st.image(img, width=display_w) else: cols_per_row = 3if num_images >= 3else num_images for row_start inrange(0, num_images, cols_per_row): row_imgs = images[row_start:row_start + cols_per_row] row_titles = titles[row_start:row_start + cols_per_row] if titles else [] cols = st.columns(len(row_imgs)) for idx, img inenumerate(row_imgs): with cols[idx]: if idx < len(row_titles): st.markdown(f"**{row_titles[idx]}**") st.image(img, width=display_w)# -------------------- 侧边栏 --------------------with st.sidebar: st.title("⚙️ 设置") st.subheader("🎛️ 生成参数") max_tokens = st.slider("最大生成令牌数", 256, 8192, 2048) temperature = st.slider("温度", 0.0, 2.0, 0.7, step=0.1) top_p = st.slider("Top P", 0.0, 1.0, 0.9, step=0.05) top_k = st.slider("Top K", 1, 100, 50) enable_thinking = st.checkbox("启用思考模式(仅文本模型)", value=False) st.divider() st.subheader("🖼️ 图像生成设置") st.selectbox( "图片宽高比", list(ASPECT_RATIO_OPTIONS.keys()), key="aspect_ratio", help="选择生成图片的宽高比,图片始终以最高质量生成" ) selected_ratio = ASPECT_RATIO_OPTIONS[st.session_state.aspect_ratio] st.caption(f"生成分辨率: {selected_ratio[0]} × {selected_ratio[1]} 像素") st.divider() st.subheader("🔍 联网搜索设置") ifnot SEARCH_AVAILABLE: st.warning("⚠️ FreeKnowledge_AI 未安装,搜索功能不可用。\n请运行: `pip install FreeKnowledge_AI`") with st.expander("搜索高级设置", expanded=False): st.selectbox("搜索引擎", ["BAIDU", "DUCKDUCKGO"], key="search_mode") st.number_input("最大搜索结果数", min_value=1, max_value=20, value=5, key="search_max_results") st.text_input("搜索API模型", key="search_api_model") st.text_input("搜索API地址", key="search_api_base") st.text_input("搜索API密钥", key="search_api_key", type="password") st.divider() st.subheader("🧠 记忆管理") memory_stats = get_memory_stats() if memory_stats["exists"]: st.markdown(f"📝 记忆条目: **{memory_stats['entries']}** 条") st.markdown(f"💾 文件大小: **{memory_stats['size_kb']}** KB") else: st.markdown("📝 暂无记忆记录") col_mem1, col_mem2 = st.columns(2) with col_mem1: if st.button("📥 导出记忆", use_container_width=True): if os.path.exists(MEMORY_FILE): withopen(MEMORY_FILE, "r", encoding="utf-8") as f: memory_content = f.read() st.download_button( label="下载 memory.md", data=memory_content, file_name="memory.md", mime="text/markdown", use_container_width=True ) with col_mem2: if st.button("🗑️ 清除记忆", use_container_width=True): if os.path.exists(MEMORY_FILE): os.remove(MEMORY_FILE) st.success("记忆已清除") st.rerun() st.divider() uploaded_file = st.file_uploader("📤 上传图片(用于图像理解)", type=["png", "jpg", "jpeg"]) if uploaded_file isnotNone: st.session_state.uploaded_image = Image.open(io.BytesIO(uploaded_file.getvalue())).convert("RGB") st.success("图片已暂存") if st.button("🗑️ 清除对话历史", type="secondary", use_container_width=True): st.session_state.messages = [] st.session_state.uploaded_image = None st.rerun() st.divider() st.subheader("🔧 显存管理") if torch.cuda.is_available(): for i inrange(torch.cuda.device_count()): total = torch.cuda.get_device_properties(i).total_memory / (1024 ** 3) allocated = torch.cuda.memory_allocated(i) / (1024 ** 3) reserved = torch.cuda.memory_reserved(i) / (1024 ** 3) st.caption(f"GPU {i}: 已分配 {allocated:.1f}G / 已预留 {reserved:.1f}G / 总计 {total:.1f}G") else: st.caption("未检测到 CUDA GPU") if st.button("🧹 手动清理显存", use_container_width=True): clear_gpu_memory() st.success("显存缓存已清理")# -------------------- 主界面 --------------------st.title("🤖 多模态对话助手(多卡优化版)")st.markdown("支持文本对话、多图生成、图像理解、联网搜索 | 自动管理显存 | 多卡分配 | 上下文记忆 | LLM智能意图识别")st.markdown("---")for msg in st.session_state.messages: with st.chat_message(msg["role"]): if msg["type"] == "text": st.markdown(msg["content"]) elif msg["type"] == "multimodal": content = msg["content"] if"text"in content and content["text"]: st.markdown(content["text"]) if"images"in content: for img in content["images"]: st.image(img, width=400) elif msg["type"] == "image": content = msg["content"] if"text"in content: st.markdown(content["text"]) if"images"in content: img_list = content["images"] titles = content.get("titles", []) display_images_grid(img_list, titles, len(img_list)) elif msg["type"] == "search": content = msg["content"] if"search_keywords"in content and content["search_keywords"]: kw_tags = " ".join([f"`{k}`"for k in content["search_keywords"]]) st.caption(f"🔍 搜索关键词: {kw_tags}") if"text"in content and content["text"]: st.markdown(content["text"])# -------------------- 文本对话流式生成 --------------------defgenerate_text_stream(messages, max_tokens, temperature, top_p, top_k, enable_thinking): ensure_model_loaded("text") tokenizer = st.session_state.loaded_model["tokenizer/processor"] model = st.session_state.loaded_model["model"] device = st.session_state.loaded_model["device"] text_messages = [] memory_context = load_memory_context(max_entries=15) if memory_context: text_messages.append({"role": "system", "content": memory_context}) truncated = truncate_messages_for_text(messages) for msg in truncated: if msg["type"] == "text": text_messages.append({"role": msg["role"], "content": msg["content"]}) elif msg["type"] == "multimodal": content = msg["content"] if"text"in content and content["text"]: text_messages.append({"role": msg["role"], "content": content["text"]}) elif msg["type"] == "image": content = msg["content"] if"text"in content and content["text"]: text_messages.append({"role": msg["role"], "content": content["text"]}) elif msg["type"] == "search": content = msg["content"] if"text"in content and content["text"]: text_messages.append({"role": msg["role"], "content": content["text"]}) text = tokenizer.apply_chat_template( text_messages, tokenize=False, add_generation_prompt=True, enable_thinking=enable_thinking ) inputs = tokenizer(text, return_tensors="pt").to(device) streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True) generate_kwargs = { **inputs, "max_new_tokens": max_tokens, "temperature": temperature if temperature > 0else1.0, "top_p": top_p, "top_k": top_k, "do_sample": temperature > 0, "streamer": streamer, } def_generate(): with torch.no_grad(): model.generate(**generate_kwargs) thread = Thread(target=_generate) thread.start() for new_text in streamer: yield new_text thread.join() del inputs clear_gpu_memory()# -------------------- 图像理解流式生成 --------------------defgenerate_vl_stream(messages, max_tokens, temperature, top_p, top_k): ensure_model_loaded("vl") processor = st.session_state.loaded_model["tokenizer/processor"] model = st.session_state.loaded_model["model"] device = st.session_state.loaded_model["device"] vl_messages = [] images = [] memory_context = load_memory_context(max_entries=10) if memory_context: vl_messages.append({"role": "system", "content": memory_context}) truncated = truncate_messages_for_vl(messages) for msg in truncated: if msg["type"] == "text": vl_messages.append({"role": msg["role"], "content": msg["content"]}) elif msg["type"] == "multimodal": content = msg["content"] content_list = [] if"images"in content: for img in content["images"]: content_list.append({"type": "image", "image": img}) images.append(img) if"text"in content and content["text"]: content_list.append({"type": "text", "text": content["text"]}) vl_messages.append({"role": msg["role"], "content": content_list}) elif msg["type"] == "image": content = msg["content"] content_list = [] if"images"in content: for img in content["images"]: content_list.append({"type": "image", "image": img}) images.append(img) if"text"in content and content["text"]: content_list.append({"type": "text", "text": content["text"]}) vl_messages.append({"role": msg["role"], "content": content_list}) prompt = processor.apply_chat_template(vl_messages, add_generation_prompt=True, tokenize=False) inputs = processor(text=prompt, images=images if images elseNone, return_tensors="pt", padding=True) inputs = {k: v.to(device) for k, v in inputs.items()} streamer = TextIteratorStreamer(processor, skip_prompt=True, skip_special_tokens=True) generate_kwargs = { **inputs, "max_new_tokens": max_tokens, "temperature": temperature if temperature > 0else1.0, "top_p": top_p, "top_k": top_k, "do_sample": temperature > 0, "streamer": streamer, } def_generate(): with torch.no_grad(): model.generate(**generate_kwargs) thread = Thread(target=_generate) thread.start() for new_text in streamer: yield new_text thread.join() del inputs, images clear_gpu_memory()# -------------------- 图像生成(单张,支持自定义宽高) --------------------defgenerate_image(prompt, seed=None, num_inference_steps=9, guidance_scale=0.0, img_width=1024, img_height=1024): ensure_model_loaded("gen") pipe = st.session_state.loaded_model["model"] device = st.session_state.loaded_model["device"] if seed isNone: seed = random.randint(0, 2147483647) generator = torch.Generator(device=device).manual_seed(seed) with torch.no_grad(): image = pipe( prompt=prompt, height=img_height, width=img_width, num_inference_steps=num_inference_steps, guidance_scale=guidance_scale, generator=generator, ).images[0] return image# -------------------- 处理用户输入 --------------------if prompt := st.chat_input("输入您的问题或描述..."): has_image = st.session_state.uploaded_image isnotNone user_image = st.session_state.uploaded_image st.session_state.uploaded_image = None if has_image: user_msg = { "role": "user", "type": "multimodal", "content": {"text": prompt, "images": [user_image]} } with st.chat_message("user"): if prompt: st.markdown(prompt) st.image(user_image, width=400) else: user_msg = {"role": "user", "type": "text", "content": prompt} with st.chat_message("user"): st.markdown(prompt) st.session_state.messages.append(user_msg) with st.chat_message("assistant"): with st.spinner("🧠 正在分析意图..."): try: intent, prompts_list, titles_list, search_keywords = detect_intent_with_llm( prompt, has_image, st.session_state.messages ) except Exception as e: st.warning(f"LLM意图识别异常,启用备用规则: {str(e)}") intent, prompts_list, titles_list, search_keywords = fallback_detect_intent(prompt) intent_labels = { "text": "💬 文本对话", "generate": "🎨 图像生成", "understand": "👁️ 图像理解", "search": "🔍 联网搜索" } st.caption(f"识别意图: {intent_labels.get(intent, intent)}") save_to_memory("user", prompt, intent=intent, has_image=has_image) try: if intent == "search": ifnot search_keywords: search_keywords = fallback_extract_keywords(prompt) search_query_string = " ".join(search_keywords) kw_display = " ".join([f"`{k}`"for k in search_keywords]) st.info(f"🔍 提取关键词: {kw_display}\n\n📡 搜索语句: **{search_query_string}**") with st.spinner("🌐 正在联网搜索,请稍候..."): raw_results = perform_web_search(search_query_string) if raw_results: clean_results = extract_search_info(raw_results) with st.expander("📄 查看搜索原始结果", expanded=False): st.text(clean_results[:2000] + ("..."iflen(clean_results) > 2000else"")) st.markdown("---") st.markdown("**📝 基于搜索结果生成回答:**") response = st.write_stream( generate_search_response_stream( prompt, clean_results, st.session_state.messages, max_tokens, temperature, top_p, top_k, enable_thinking ) ) assistant_msg = { "role": "assistant", "type": "search", "content": { "text": response, "search_keywords": search_keywords, "search_query": search_query_string, } } st.session_state.messages.append(assistant_msg) save_to_memory("assistant", f"[搜索: {search_query_string}]\n{response}") else: st.warning("搜索未返回有效结果,将使用本地模型直接回答。") response = st.write_stream( generate_text_stream( st.session_state.messages, max_tokens, temperature, top_p, top_k, enable_thinking ) ) assistant_msg = {"role": "assistant", "type": "text", "content": response} st.session_state.messages.append(assistant_msg) save_to_memory("assistant", response) elif intent == "generate": ifnot prompts_list: estimated_count = estimate_image_count(prompt) with st.spinner(f"🎨 正在生成 {estimated_count} 条绘画提示词..."): prompts_list, titles_list = generate_image_prompts_with_llm(prompt, count=estimated_count) num_images = len(prompts_list) gen_width, gen_height = ASPECT_RATIO_OPTIONS[st.session_state.aspect_ratio] st.markdown(f"📋 将生成 **{num_images}** 张图片({st.session_state.aspect_ratio},{gen_width}×{gen_height}):") for i, (title, p) inenumerate(zip(titles_list, prompts_list)): st.caption(f" {i + 1}. **{title}** — {p}") generated_images = [] progress_bar = st.progress(0, text="正在生成图片...") for i, img_prompt inenumerate(prompts_list): progress_bar.progress( (i) / num_images, text=f"🖼️ 正在生成第 {i + 1}/{num_images} 张: {titles_list[i] if i < len(titles_list) else ''}" ) seed = random.randint(0, 2147483647) img = generate_image( img_prompt, seed=seed, img_width=gen_width, img_height=gen_height ) generated_images.append(img) clear_gpu_memory() progress_bar.progress(1.0, text=f"✅ 全部 {num_images} 张图片生成完成!") display_images_grid(generated_images, titles_list, num_images) prompts_summary = " | ".join([f"{t}: {p}"for t, p inzip(titles_list, prompts_list)]) response_text = f"根据「{prompt}」生成了 {num_images} 张图片({prompts_summary})" assistant_msg = { "role": "assistant", "type": "image", "content": { "text": response_text, "images": generated_images, "titles": titles_list } } st.session_state.messages.append(assistant_msg) save_to_memory("assistant", response_text) elif intent == "understand": response = st.write_stream( generate_vl_stream( st.session_state.messages, max_tokens, temperature, top_p, top_k ) ) assistant_msg = {"role": "assistant", "type": "text", "content": response} st.session_state.messages.append(assistant_msg) save_to_memory("assistant", response) else: response = st.write_stream( generate_text_stream( st.session_state.messages, max_tokens, temperature, top_p, top_k, enable_thinking ) ) assistant_msg = {"role": "assistant", "type": "text", "content": response} st.session_state.messages.append(assistant_msg) save_to_memory("assistant", response) except Exception as e: st.error(f"发生错误: {str(e)}") unload_current_model()# -------------------- 底部信息 --------------------st.markdown("---")memory_stats = get_memory_stats()memory_info = f"记忆: {memory_stats['entries']} 条"if memory_stats["exists"] else"记忆: 无"search_status = "搜索: ✅"if (st.session_state.search_enabled and SEARCH_AVAILABLE) else"搜索: ❌"st.markdown( f""" <div style='text-align: center; color: gray; font-size: 0.85rem;'> <p>多模态对话助手 | 多卡优化 | 显存自动管理 | LLM智能意图识别 | 多图生成 | 关键词搜索 | 📝 {memory_info} | {search_status}</p> </div> """, unsafe_allow_html=True)
准备模型
我们的模型从modelscope上下载。 1、Qwen3.5-9B模型下载地址
https://modelscope.cn/models/Qwen/Qwen3.5-9B
下载方法
git clone https://www.modelscope.cn/Qwen/Qwen3.5-9B.git
2、Z-IMAGE-Turbo模型下载地址
https://modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo
下载方法
git clone https://www.modelscope.cn/Tongyi-MAI/Z-Image-Turbo.git
运行环境
nvcc: NVIDIA (R) Cuda compiler driverCopyright (c) 2005-2024 NVIDIA CorporationBuilt on Fri_Jun_14_16:44:19_Pacific_Daylight_Time_2024Cuda compilation tools, release 12.6, V12.6.20Build cuda_12.6.r12.6/compiler.34431801_0
``````plaintext
Package Version------------------------- ------------accelerate 1.13.0addict 2.4.0altair 6.0.0annotated-doc 0.0.4annotated-types 0.7.0anyio 4.12.1attrs 25.4.0beautifulsoup4 4.14.3blinker 1.9.0cachetools 7.0.5certifi 2026.2.25charset-normalizer 3.4.5click 8.3.1colorama 0.4.6contourpy 1.3.3cycler 0.12.1diffusers 0.37.0distro 1.9.0einops 0.8.2filelock 3.25.2fonttools 4.62.1FreeKnowledge_AI 0.3.1fsspec 2026.2.0gitdb 4.0.12GitPython 3.1.46h11 0.16.0hf-xet 1.4.2httpcore 1.0.9httpx 0.28.1huggingface_hub 1.7.1idna 3.11importlib_metadata 8.7.1jieba 0.42.1Jinja2 3.1.6jiter 0.13.0jsonschema 4.26.0jsonschema-specifications 2025.9.1kiwisolver 1.5.0markdown-it-py 4.0.0MarkupSafe 3.0.3matplotlib 3.10.8mdurl 0.1.2modelscope 1.35.0mpmath 1.3.0narwhals 2.18.0networkx 3.6.1numpy 1.26.4openai 2.28.0packaging 26.0pandas 2.3.3pillow 12.1.1pip 26.0.1protobuf 6.33.5psutil 7.2.2pyarrow 23.0.1pydantic 2.12.5pydantic_core 2.41.5pydeck 0.9.1Pygments 2.19.2pyparsing 3.3.2python-dateutil 2.9.0.post0pytz 2026.1.post1PyYAML 6.0.3referencing 0.37.0regex 2026.2.28requests 2.32.5rich 14.3.3rpds-py 0.30.0safetensors 0.7.0setuptools 65.5.0shellingham 1.5.4six 1.17.0smmap 5.0.3sniffio 1.3.1soupsieve 2.8.3streamlit 1.55.0sympy 1.13.1tenacity 9.1.4tokenizers 0.22.2toml 0.10.2torch 2.6.0+cu126torchvision 0.21.0+cu126tornado 6.5.5tqdm 4.67.3transformers 5.3.0typer 0.24.1typing_extensions 4.15.0typing-inspection 0.4.2tzdata 2025.3urllib3 2.6.3watchdog 6.0.0zipp 3.23.0
搜索配置
需要在硅基流动网站实名认证一下,并在下方控制台生成免费的Key,搜索后端将默认使用上海书生浦语大模型进行处理
https://cloud.siliconflow.cn/me/account/ak
同时安装搜索包
pip install FreeKnowledge-AI
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献185条内容
已为社区贡献185条内容

所有评论(0)