多模态文档解析怎么学?Qianfan-OCR模型架构与训练方法全解(保姆级教程),收藏这一篇就够了!
文档解析范式分三个:(1)基于ocr-pipeline;(2)基于layout+vlm的两阶段;(3)基于vlm端到端;Qianfan-OCR是一个4B参数量的端到端的多模态文档解析模型,解决了传统OCR流水线的误差传播、视觉上下文丢失、部署复杂等问题,其方法体系围绕端到端架构设计、Layout-as-Thought机制、大规模数据合成、四阶段渐进式训练四大核心展开,下面来看看方案。
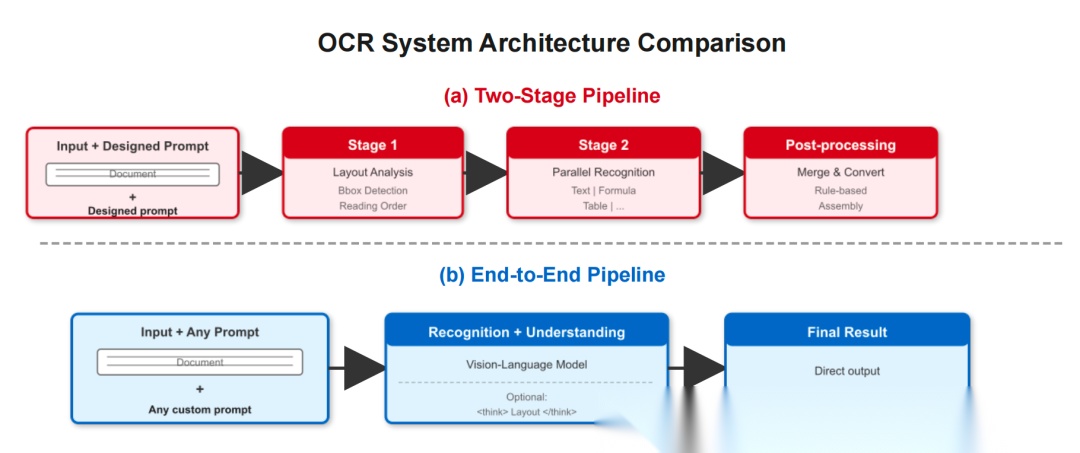
传统两阶段 OCR 流水线与Qianfan-OCR 的端到端方法之间的架构对比。(a) 传统流水线系统将版 面分析与内容识别分离为独立的阶段,存在错误传播和视觉上下文不可逆丢失的问题。(b) Qianfan-OCR 将 所有处理统一到一个单一的视觉-语言模型中,接受自定义提示以实现灵活的任务控制,并可选择通过布 局即思维(⟨ think ⟩ token)生成中间布局推理。
模型架构
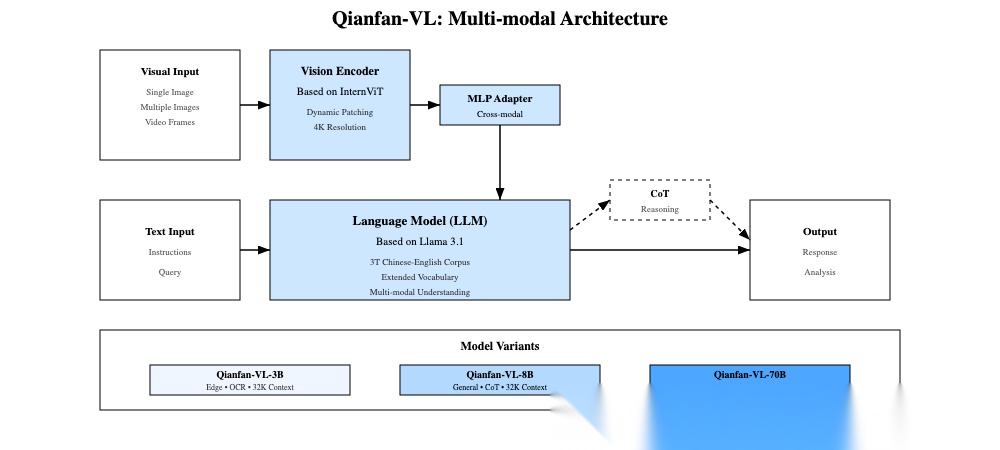
Qianfan-VL架构
Qianfan-OCR基于Qianfan-VL的多模态桥接架构改造,将所有文档处理任务融入单一模型,遵循经典的Vit【Qianfan-ViT(高分辨率自适应编码)专为文档OCR的高密度文本、小字体、复杂布局设计,核心特性是AnyResolution动态分块】+MLP(两层带GELU激活的MLP)+LLM【Qwen3-4B:平衡复杂文档推理能力和生产级部署效率】架构。
核心方法:Layout-as-Thought机制
该机制解决了纯端到端OCR缺乏显式布局分析的痛点:流水线OCR可输出元素边界框、类型和阅读顺序,而传统端到端OCR直接生成结果,丢失了空间定位能力。
机制定义:通过**⟨ think ⟩特殊token触发的可选思维阶段**,模型在生成最终输出前,先生成结构化的布局表示(边界框、元素类型、阅读顺序),将布局分析转化为模型的“中间推理步骤”,而非独立的前置任务。
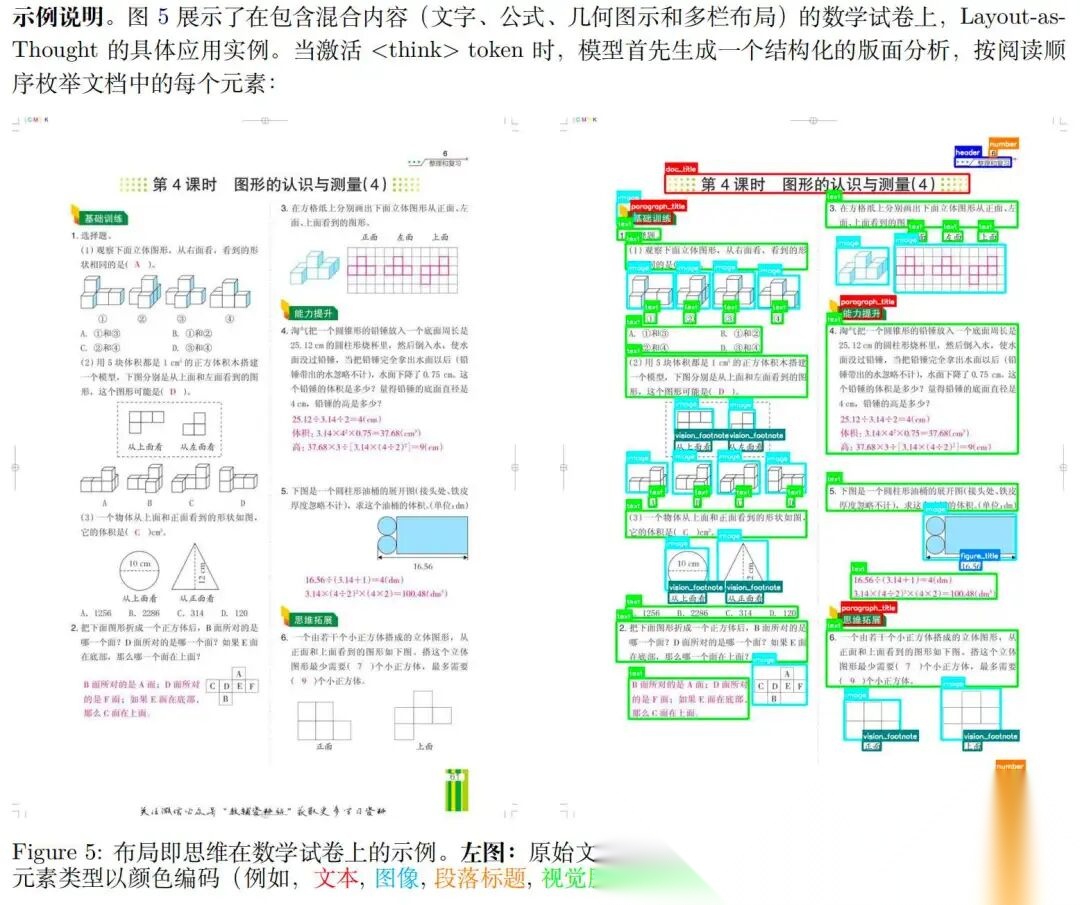
数据示例

数据示例
技术实现细节
(1)布局表示的结构化输出
触发⟨think⟩后,模型生成的布局信息包含三个核心字段,封装在<layout>...</layout>标签中:
<box>:归一化到[0,999]的边界框坐标,使用**<COORD_0>~<COORD_999>专用token**表示,相比纯数字编码减少50%的输出长度,降低推理延迟;<label>:元素类型标签,采用PaddleOCR-VL的25类精细标签体系,分为4组(文本元素12类、页眉页脚4类、图/表6类、公式3类);<brief>:文本类元素的内容摘要,非文本元素(如图、表)的视觉描述。
(2)坐标token的优化设计
所有坐标均映射为单一专用token,而非数字序列(如“779”需3个token,< COORD_779 >仅1个),解决了复杂文档(单页60+元素)的布局推理延迟问题。
(3)对最终输出的引导方式
布局推理结果通过两种方式提升最终输出质量:
- 元素类型感知生成:识别到公式则用"$$"包裹,识别到表格则转化为HTML,识别到图片则插入正确位置的占位符;
- 阅读顺序引导排序:按文档的自然阅读顺序枚举元素,解决多列、图文交错、脚注等场景的输出顺序混乱问题。
数据引擎
端到端模型的性能高度依赖数据,Qianfan-OCR针对OCR的专属任务设计了六大数据合成流水线,覆盖文档解析、KIE、复杂表格、图表理解、公式识别、多语言OCR,并通过多维度增强保证数据的多样性和真实性,最终生成支撑四阶段训练的大规模高质量数据集。
六大核心数据合成流水线
| 流水线类型 | 核心设计 | 特点 |
|---|---|---|
| 文档解析数据 | 基于PaddleOCR-VL将文档图像转为结构化Markdown,表格转HTML、公式包$$块 | 归一化边界框[0,999],过滤重复/超长样本,图像增强(压缩、翻转、模糊) |
| Layout-as-Thought数据 | 构造⟨think⟩触发的布局推理样本,包含边界框、标签、摘要 | 聚焦复杂布局(多列、图文交错),强化空间推理能力 |
| 关键信息提取(KIE)数据 | 支持“全提取”和“目标提取”,多模型协同标注解决幻觉问题 | 语义泛化(同一字段多同义描述)、业务规则过滤(如单价×数量=总价)、难样本挖掘 |
| 复杂表格数据 | 程序合成+真实文档提取结合,支持单元格合并、50+CSS主题渲染 | 几何变换、颜色扰动、模糊增强,双模型(PaddleOCR-VL+内部表格模型)一致性验证 |
| 图表理解数据 | 基于arXiv LaTeX源码提取图表,TexLive渲染矢量图,VLM生成视觉描述 | 覆盖11类主流图表,为不同图表设计定制推理任务(折线图趋势分析、箱线图异常检测),合成30万+样本 |
| 多语言OCR数据 | 基于HPLT多语言语料的反向合成,支持192种语言 | 差异化处理不同书写体系(RTL阿拉伯语、梵文等),自动检测文字方向、阿拉伯语字符重塑 |
文档图像增强策略
针对OCR和布局解析的不同需求,设计两套增强流水线,均包含三级噪声+旋转增强:
- 三级噪声增强
- 文本噪声:笔画断裂、墨水渗透、字符错位;
- 背景噪声:纹理、颜色漂移、水印;
- 成像噪声:模糊、摩尔纹、阴影、曝光变化;
- 旋转增强:90°/180°/270°旋转+±15°倾斜,解决票据、证件等非标准朝向的识别问题。
训练方法
Qianfan-OCR采用Qianfan-VL的多阶段渐进式训练方法论,核心是从通用能力到OCR专属能力的逐步强化,同时通过数据混合策略防止灾难性遗忘。
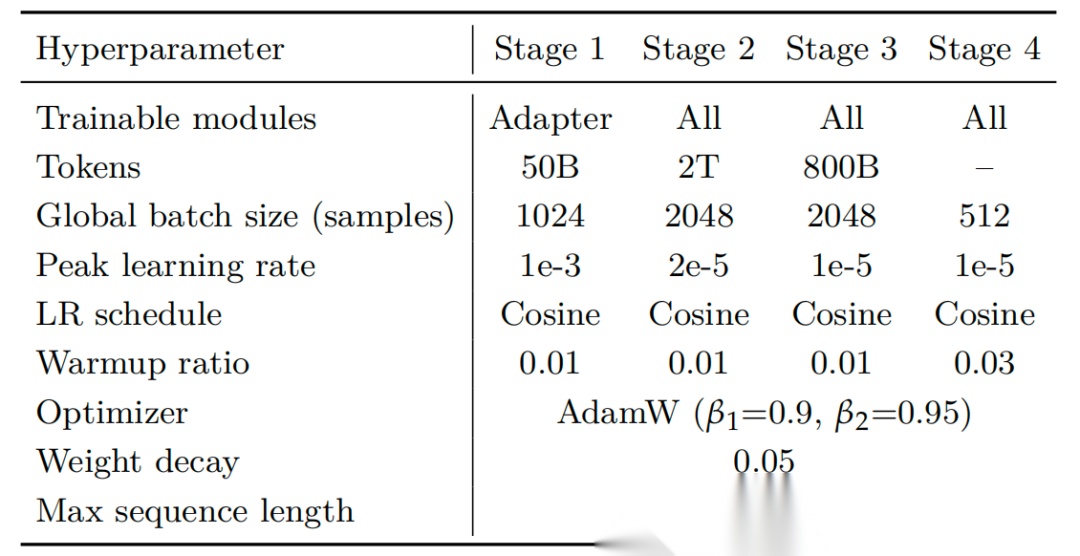
训练参数
| 训练阶段 | 核心目标 | 数据规模 | 训练模块 | 关键数据混合 | 学习率 | 全局批次 |
|---|---|---|---|---|---|---|
| 阶段1:跨模态对齐 | 建立视觉-语言基础对齐,稳定初始化 | 50Btoken | 仅适配器 | 基础图像-标题对+简单OCR任务 | 1e-3 | 1024 |
| 阶段2:基础OCR训练 | 构建全面OCR能力,覆盖通用场景 | 2Ttoken | 全参数 | 文档OCR(45%)+场景OCR(25%)+标题(15%)+专用OCR(15%) | 2e-5 | 2048 |
| 阶段3:领域专属增强 | 强化企业级关键OCR领域能力 | 800Btoken | 全参数 | 复杂表格(22%)+公式(20%)+图表(18%)+KIE(18%)+多语言(12%)+文档理解(10%),7:3专属/通用数据 | 1e-5 | 2048 |
| 阶段4:指令调优与推理增强 | 适配多样化用户Prompt,提升复杂推理能力 | 数百万指令样本 | 全参数 | 公共数据改写+反向合成QA+图表数据挖掘 | 1e-5 | 512 |
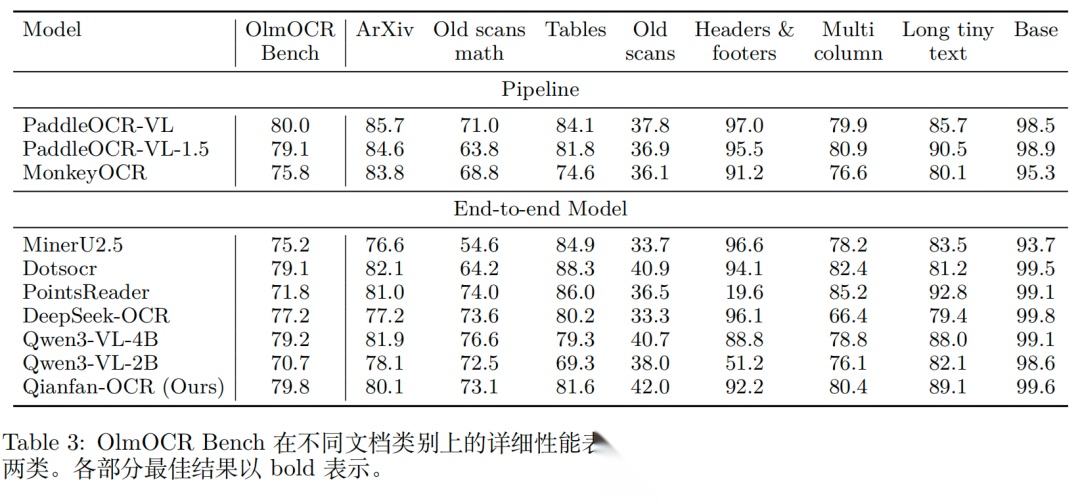
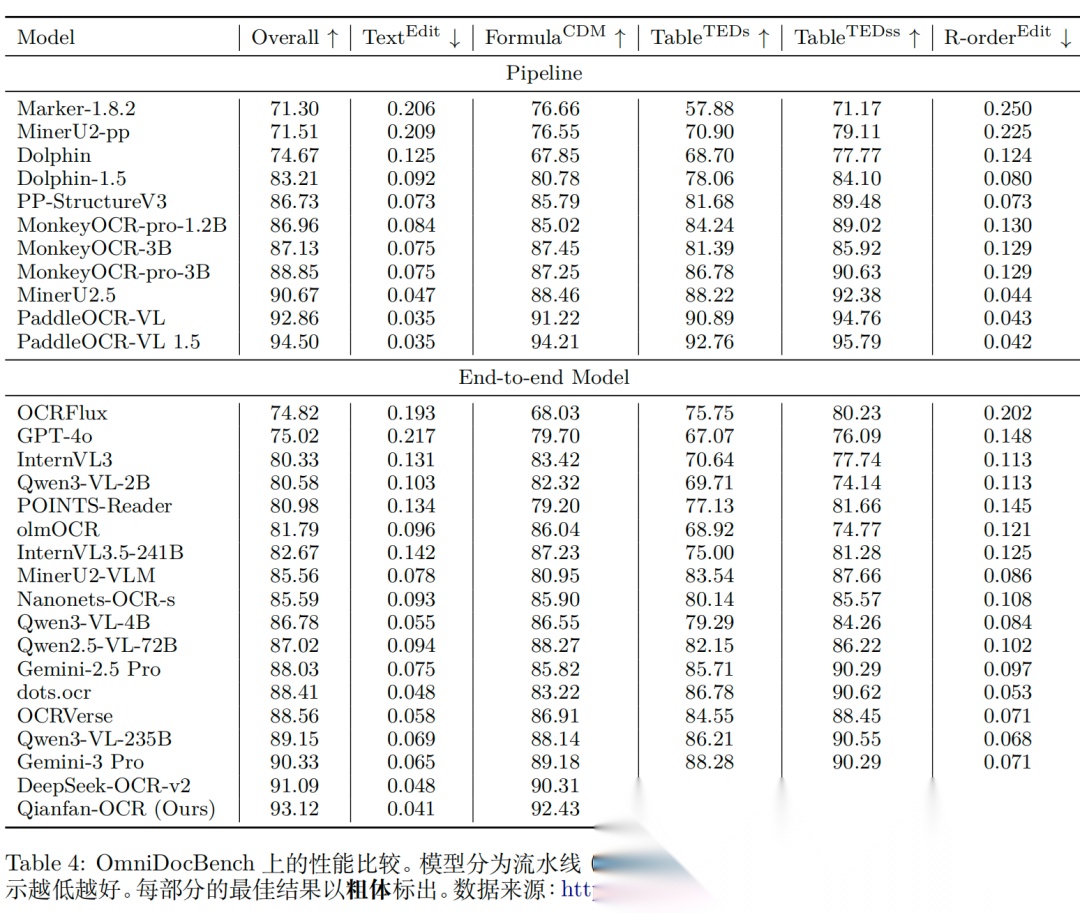
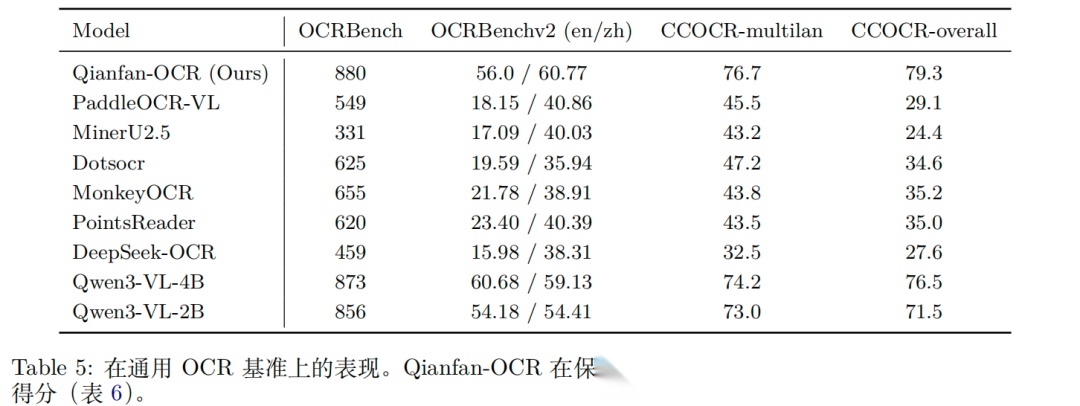
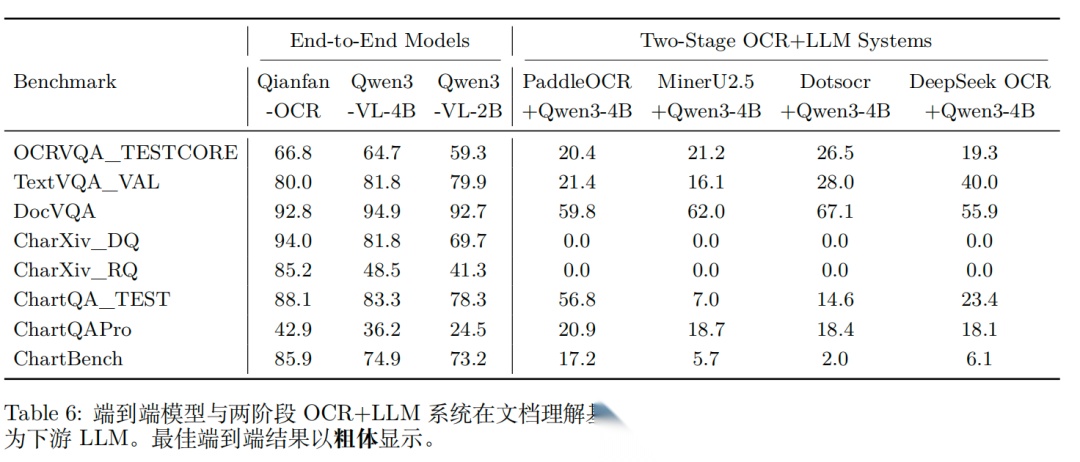
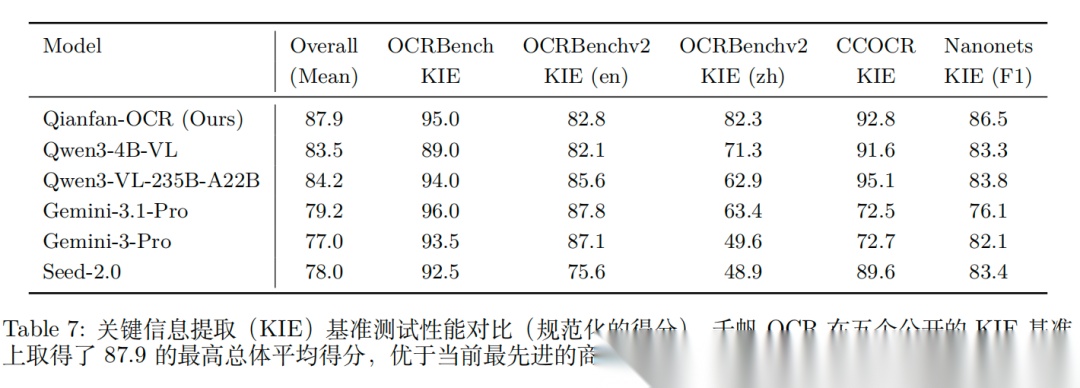
实验性能

学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)