第一章机器学习概述
什么是机器学习?
机器学习是计算机科学的子领域,也是人工智能的一个分支和实现方式,它使计算机系统能够利用数据和算法自动学习与改进其技能。
机器学习是让机器通过经验(数据)来做决策和预测。
机器学习已经广泛应用于许多领域,包括推荐系统、图像识别、语音识别、金融分析等。通过机器学习,汽车可以学习如何识别交通标志、行人和障碍物,以实现自动驾驶。
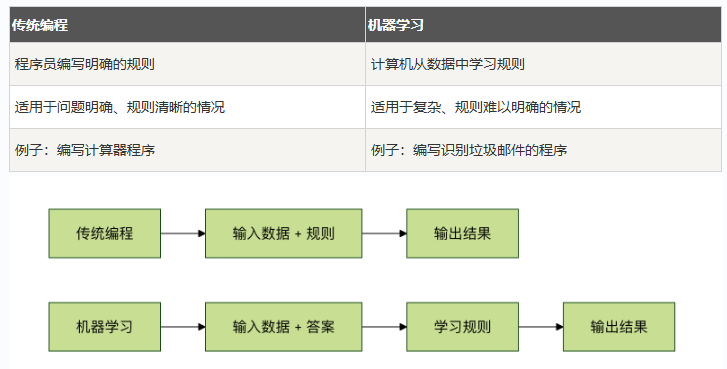
机器学习与传统编程的区别
机器学习、人工智能和数据挖掘
数据挖掘的目标是通过处理各种真实业务数据促进人们的决策;
机器学习的主要任务是使机器模仿人类学习,从而获得知识;
人工智能使借助机器学习和推理最终形成具体的智能行为。
什么是人工智能?
人工智能是让机器的行为看起来像人所表现出的智能行为一样。
人工智能的典型系统包括以下几个方面:
(1)博弈游戏(如深蓝、AlphaGo、AlphaZero等)
(2)机器人相关控制理论(运动规划、控制机器人行走等)
(3)机器翻译
(4)语音识别
(5)计算机视觉系统
(6)自然语言处理
什么是数据挖掘?
数据挖掘使用机器学习、统计学和数据库等方法再相对大量的数据集中发现模式及知识,它涉及数据预处理、建立模型与推断、可视化等。
数据挖掘包括以下几类常见任务:
(1)异常检测
异常检测是对不符合预期模式的样本、使劲按进行识别。异常也被成为离群值、偏差和例外等。异常检测常用于入侵检测、金融欺诈检测、疾病检测、故障检测等。
(2)关联规则学习
关联规则学习是在数据库中发现变量之间的关系(强关联)。比如牛奶和面包,常常被放在一起被购买。
(3)聚类
聚类是一种探索性分析,在未知数据结构的情况下,根据相似性把样本分为不同的簇或子集,不同簇的样本具有很大的差异性,从而发现数据的类别与结构。
(4)分类
分类是根据已知样本的某些特征,判断一个新样本数据哪种类型。通过特征选择和学习,建立判别函数以对样本进行分类。
(5)回归
回归是一种统计分析方法,用于了解两个或多个变量之间的相关关系。回归的目标是找出误差最小的拟合函数作为模型,用特定的自变量来预测因变量的值。
机器学习的三大要素
1、数据
数据是机器学习的燃料,质量越高、数量越多的数据,通常能让模型学得越好。
- 训练数据:用来教模型的数据
- 测试数据:用来检验模型学习效果的数据
- 真实数据:模型在实际应用中遇到的新数据
2、算法
算法是机器学习的学习方法,不同的算法适用于不同类型的问题。
- 监督学习:有标准答案的学习
- 无监督学习:没有标准答案,自己找规律
- 强化学习:通过试错和奖励来学习
3、模型
模型是学习的结果,就像学生学到的知识一样。
- 训练过程:算法从数据中学习规律
- 推理过程:使用学到的规律做预测
机器学习的流程
1. 明确目标任务
应用机器学习解决实际问题,首先要明确目标任务,这是机器学习算法选择的关键。明确要解决的问题和业务需求,才可能基于现有数据设计或选择算法。例如,在有监督学习中对定性问题可用分类算法,对定量问题可用回归算法;在无监督学习中,如果有样本细分则可应用聚类算法,如需要找出各个数据项之间的内容在联系,可应用关联分析。
2. 数据收集
数据要有代表性并尽量覆盖领域,否则容易出现过拟合和欠拟合。对于分类问题,如果样本数据不平衡,不同类别的样本数量比例过大,会影响模型的准确性。还要对数据的量级进行评估,包括样本数和特征数,可以估算出数据以及分析对内存的消耗,判断训练过程中内存是否过大,否则需要改进算法或使用一些降维技术,或者使用分布式机器学习技术。
- 收集数据:这是机器学习项目的第一步,涉及收集相关数据。数据可以来自数据库、文件、网络或实时数据流。
- 数据类型:可以是结构化数据(如表格数据)或非结构化数据(如文本、图像、视频)。
3. 数据预处理
- 清洗数据:处理缺失值、异常值、错误和重复数据。
- 特征工程:选择有助于模型学习的最相关特征,可能包括创建新特征或转换现有特征。
- 数据标准化/归一化:调整数据的尺度,使其在同一范围内,有助于某些算法的性能。
4. 数据建模
- 确定问题类型:根据问题的性质(分类、回归、聚类等)选择合适的机器学习模型。
- 选择算法:基于问题类型和数据特性,选择一个或多个算法进行实验。
5. 训练模型
在模型训练过程中,需要对模型超参数进行调优,如果对算法原理理解不够透彻,往往无法快速定位能决定模型优劣的模型参数,因此在训练过程中,对机器学习算法原理的要求较高,理解越深入,就越容易发现问题的原因,从而确定合理的调优方案。
- 划分数据集:将数据分为训练集、验证集和测试集。
- 训练:使用训练集上的数据来训练模型,调整模型参数以最小化损失函数。
- 验证:使用验证集来调整模型参数,防止过拟合。
6. 评估模型
- 性能指标:使用测试集来评估模型的性能,常用的指标包括准确率、召回率、F1分数等。
- 交叉验证:一种评估模型泛化能力的技术,通过将数据分成多个子集进行训练和验证。
7. 模型优化
- 调整超参数:超参数是学习过程之前设置的参数,如学习率、树的深度等,可以通过网格搜索、随机搜索或贝叶斯优化等方法来调整。
- 特征选择:可能需要重新评估和选择特征,以提高模型性能。
8. 部署模型
- 集成到应用:将训练好的模型集成到实际应用中,如网站、移动应用或软件中。
- 监控和维护:持续监控模型的性能,并根据新数据更新模型。
9. 反馈循环
- 持续学习:机器学习模型可以设计为随着时间的推移自动从新数据中学习,以适应变化。
技术细节
- 损失函数:一个衡量模型预测与实际结果差异的函数,模型训练的目标是最小化这个函数。
- 优化算法:如梯度下降,用于找到最小化损失函数的参数值。
- 正则化:一种技术,通过添加惩罚项来防止模型过拟合。
机器学习的工作流程是迭代的,可能需要多次调整和优化以达到最佳性能。此外,随着数据的积累和算法的发展,机器学习模型可以变得更加精确和高效。
机器学习项目生命周期
机器学习项目就像建造一座房子,需要从设计图纸到施工再到验收的完整过程,每个环节都至关重要,缺一不可。
机器学习流程的六个核心阶段:
- 问题定义:明确要解决什么问题
- 数据收集:获取相关数据
- 数据准备:清洗和预处理数据
- 模型训练:选择算法并训练模型
- 模型评估:评估模型性能
- 模型部署:将模型投入使用
第一阶段:问题定义
明确业务问题:问题定义是机器学习项目最重要的起点,就像导航前需要明确目的地一样。
关键问题:我们要解决什么问题?
- 分类问题:判断邮件是否为垃圾邮件
- 回归问题:预测房价
- 聚类问题:客户分群
- 异常检测:发现信用卡欺诈
为什么这个问题重要?
- 业务价值:提高效率、降低成本、增加收入
- 用户价值:改善体验、提供个性化服务
成功的标准是什么?
- 量化指标:准确率达到 90% 以上
- 业务指标:转化率提升 20%
第二阶段:数据收集
数据来源:数据是机器学习的燃料,没有合适的数据再好的算法也无法发挥作用。
- 内部数据:公司业务数据、用户行为数据
- 外部数据:公开数据集、第三方数据服务
- 网络爬虫:网页数据、社交媒体数据
- 传感器数据:IoT 设备、监控系统
第三阶段:数据准备
数据准备的重要性:数据准备占机器学习项目 60-80% 的时间,就像做菜前的准备工作一样重要。
- 数据清洗:处理缺失值、异常值、重复值
- 特征工程:创建新特征、选择重要特征
- 数据转换:标准化、归一化、编码
- 数据划分:训练集、验证集、测试集
第四阶段:模型训练
模型选择策略:选择合适的模型是成功的关键,就像选择合适的工具来完成工作一样。
模型选择考虑因素:
- 问题类型:分类、回归、聚类等
- 数据特征:数据量、特征数量、数据类型
- 性能要求:准确率、速度、可解释性
- 资源约束:计算资源、时间限制
第五阶段:模型评估
评估指标选择:选择合适的评估指标就像选择合适的尺子,不同的指标适用于不同的场景。
常见评估指标:
分类问题:
- 准确率(Accuracy):正确预测的比例
- 精确率(Precision):预测为正的样本中真正为正的比例
- 召回率(Recall):实际为正的样本中被正确预测为正的比例
- F1 分数:精确率和召回率的调和平均
回归问题:
- 均方误差(MSE):预测值与真实值差的平方的平均
- 均方根误差(RMSE):MSE 的平方根
- 平均绝对误差(MAE):预测值与真实值差的绝对值的平均
- R² 分数:模型解释的方差比
第六阶段:模型部署
部署策略:模型部署是将模型投入实际使用的过程,就像将研发的产品推向市场一样。
部署方式:
- 批量预测:定期处理大量数据
- 实时预测:在线服务,即时响应
- 嵌入式部署:将模型集成到现有系统
- 边缘部署:在设备端运行模型
机器学习的类型
1. 监督学习(Supervised Learning)
- 定义: 监督学习是指使用带标签的数据进行训练,模型通过学习输入数据与标签之间的关系,来做出预测或分类。
- 应用: 分类(如垃圾邮件识别)、回归(如房价预测)。
- 例子: 线性回归、决策树、支持向量机(SVM)。
2. 无监督学习(Unsupervised Learning)
- 定义: 无监督学习使用没有标签的数据,模型试图在数据中发现潜在的结构或模式。
- 应用: 聚类(如客户分群)、降维(如数据可视化)。
- 例子: K-means 聚类、主成分分析(PCA)。
3. 强化学习(Reinforcement Learning)
- 定义: 强化学习通过与环境互动,智能体在试错中学习最佳策略,以最大化长期回报。每次行动后,系统会收到奖励或惩罚,来指导行为的改进。
- 应用: 游戏AI(如AlphaGo)、自动驾驶、机器人控制。
- 例子: Q-learning、深度Q网络(DQN)。
机器学习的应用领域
-
推荐系统: 例如,抖音推荐你可能感兴趣的视频,淘宝推荐你可能会购买的商品,网易云音乐推荐你喜欢的音乐。
-
自然语言处理(NLP): 机器学习在语音识别、机器翻译、情感分析、聊天机器人等方面的应用。例如,Google 翻译、Siri 和智能客服等。
-
计算机视觉: 机器学习在图像识别、物体检测、面部识别、自动驾驶等领域有广泛应用。例如,自动驾驶汽车通过摄像头和传感器识别周围的障碍物,识别行人和其他车辆。
-
金融分析: 机器学习在股市预测、信用评分、欺诈检测等金融领域具有重要应用。例如,银行利用机器学习检测信用卡交易中的欺诈行为。
-
医疗健康: 机器学习帮助医生诊断疾病、发现药物副作用、预测病情发展等。例如,IBM 的 Watson 系统帮助医生分析患者的病历数据,提供诊断和治疗建议。
-
游戏和娱乐: 机器学习不仅用于游戏中的智能对手,还应用于游戏设计、动态难度调整等方面。例如,AlphaGo 使用深度学习技术战胜了围棋世界冠军。
机器学习的未来
随着数据量的爆炸式增长和计算能力的提升,机器学习的应用将继续扩展,带来更加智能和高效的系统。例如:
-
强化学习: 使计算机能够在没有明确指导的情况下通过试错来解决复杂问题。例如,AlphaGo 和 Dota 2 游戏 AI 都使用了强化学习。
-
自监督学习: 目前的机器学习模型通常需要大量带标签的数据来进行训练,而自监督学习则能够在没有标签的数据下学习更有效的表示。
-
深度学习: 深度学习是机器学习中的一个分支,主要关注神经网络的应用,它已经在图像识别、自然语言处理等方面取得了突破性进展。未来,深度学习将继续推动人工智能的发展。
通过机器学习,我们能够创建更智能的系统,自动化繁琐的任务,并改善我们日常生活的各个方面。随着技术的发展,机器学习将成为未来各行业的核心驱动力之一。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)