从理念到落地:AI Agent记忆系统的工程化实践指南
·
上一篇博客我们讨论了AI Agent记忆系统的进化方向——从“记忆仓库”到“决策面板”。现在,我们来聊聊如何把这些理念变成可运行的代码。以下是一个循序渐进的工程实践指南,包含架构设计、数据结构和实现要点。
01 核心原则回顾
在动手之前,先明确我们要实现的目标:
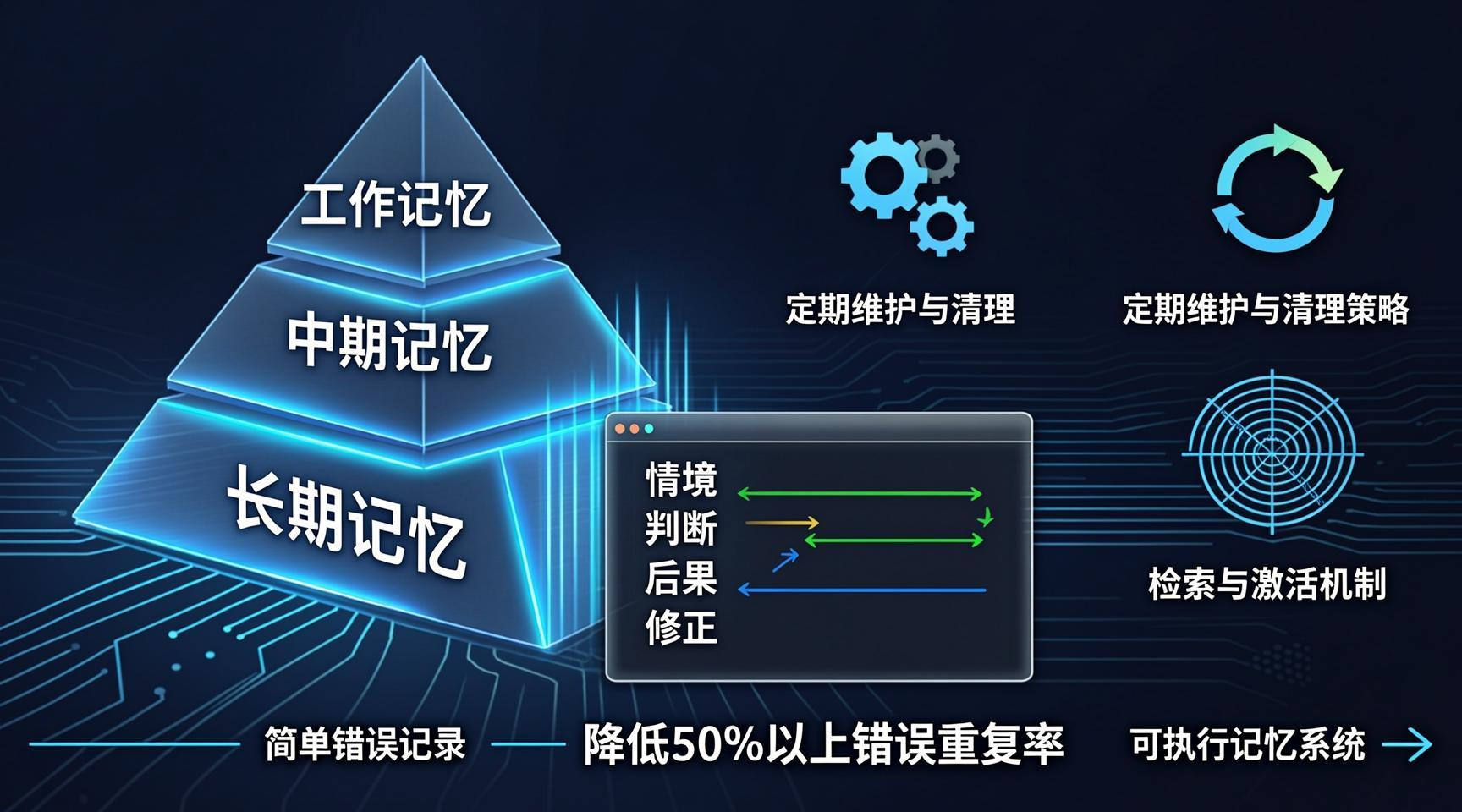
- 分层存储:记忆要分短期、中期、长期,而非扁平堆积。
- 判例式记录:用“情境-判断-后果-修正”格式替代流水账。
- 主动遗忘:定期清理低价值、错误、过时的记忆。
- 记忆激活:在任务执行前自动检索相关记忆,而非依赖“想起来”。
02 架构设计:三层存储模型
将记忆系统分为三个逻辑层,每层有不同的存储介质和生命周期。
| 层级 | 名称 | 存储介质 | 生命周期 | 内容示例 |
|---|---|---|---|---|
| L1 | 工作记忆 | 内存 / Redis | 当前会话(<48小时) | 临时变量、对话上下文 |
| L2 | 中期记忆 | 文件 / 轻量DB | 30天内 | 用户近期偏好、进行中项目 |
| L3 | 长期记忆 | 文件 / 结构化文件(如JSON) | 永久 | 核心原则、判例库、身份信息 |
图示
用户请求
↓
┌─────────────────┐
│ 工作记忆(L1) │ ← 当前会话
└────────┬────────┘
↓ (会话结束)
┌─────────────────┐
│ 中期记忆(L2) │ ← 定期归档
└────────┬────────┘
↓ (30天未激活)
┌─────────────────┐
│ 长期记忆(L3) │ ← 永久存储
└─────────────────┘
03 数据结构设计:判例式记忆
将每条长期记忆设计为可触发的判例,而非零散笔记。
{
"id": "case_001",
"type": "rule",
"trigger_conditions": [
"当前时间在 00:00-06:00",
"意图为 '主动推送'"
],
"judgment": "凌晨推送会打扰用户",
"consequence": "用户反馈不适,要求停止",
"correction": "禁止在凌晨时段(00:00-06:00)执行任何主动推送操作",
"priority": 9,
"created_at": "2026-03-20",
"last_triggered": null,
"ttl": null
}
关键字段说明
- trigger_conditions:一组可评估的条件,用于判断何时应激活此记忆。
- correction:修正动作,可以是具体指令或可执行代码片段。
- priority:优先级,影响检索排序。
- ttl:生存时间(Time To Live),null表示永久,否则在到期后自动降级或删除。
04 实现机制:记忆的写入、检索与激活
4.1 记忆写入流程
每次Agent执行任务后,自动生成判例并存入对应层级。
def write_memory(event, outcome):
# 事件:发生了什么事
# 结果:成功/失败,以及后果
if outcome.is_error and outcome.frequency >= 3:
# 重复错误 → 提取为长期记忆
case = build_case(event, outcome)
save_to_long_term(case)
elif event.is_user_feedback:
# 用户反馈 → 存入中期记忆,等待评估
save_to_medium_term(event)
else:
# 普通日志 → 仅存入短期工作记忆
save_to_short_term(event)
4.2 记忆检索与激活
在任务执行前,强制检索相关记忆并注入上下文。
def before_task(task):
# 1. 从L1检索当前上下文
# 2. 从L2检索相关项目
# 3. 从L3检索判例
relevant_memories = []
# 判例检索:基于当前任务的条件匹配
for case in load_long_term_memories():
if match_conditions(task, case.trigger_conditions):
relevant_memories.append(case.correction)
# 将激活的记忆注入系统提示或上下文
inject_memories(relevant_memories)
# 继续执行任务
return execute_task(task)
4.3 条件匹配引擎
如何判断当前状态是否满足判例的触发条件?一个简单的实现:
def match_conditions(task, conditions):
for cond in conditions:
# 支持简单条件表达式,如 "time between 0 and 6"
if not evaluate_condition(cond, get_current_context()):
return False
return True
生产环境可以考虑使用规则引擎或嵌入向量检索。
05 定期维护:清理与遗忘
5.1 自动化审计脚本
每天运行一次清理任务,处理过期记忆。
def memory_maintenance():
# 1. 清理L2中超过30天未激活的记忆
for mem in load_medium_term_memories():
if mem.last_accessed < now() - timedelta(days=30):
delete(mem)
# 2. 将L2中频繁使用的提升到L3
for mem in load_medium_term_memories():
if mem.trigger_count > 10:
promote_to_long_term(mem)
# 3. 检查L3中是否存在“致命毒素”
for case in load_long_term_memories():
if is_outdated(case) or is_wrong(case):
archive_or_delete(case)
5.2 手工审查机制
对于高价值判例,保留人工审核入口。例如,在Agent的仪表盘上展示“待审查记忆”列表,允许人类确认是否永久保留。
06 实战示例:在OpenClaw框架中集成
假设你的Agent基于OpenClaw,可以这样组织记忆文件:
memory/
├── short_term/ # 工作记忆,每个会话一个文件
│ ├── session_20260320_01.json
│ └── session_20260320_02.json
├── medium_term/ # 中期记忆,按主题分类
│ ├── user_prefs.json
│ ├── active_projects.json
│ └── recent_learnings.json
├── long_term/ # 长期记忆,判例库
│ ├── rules.json # 原则和规则
│ └── cases.json # 错误判例
└── archive/ # 归档,用于备份
└── 2026-03-20_archive.tgz
在AGENTS.md中添加记忆指令
## 记忆系统使用规则
1. **每次启动时**:先读取 `long_term/rules.json` 和 `medium_term/user_prefs.json`。
2. **每次执行任务前**:必须从 `long_term/cases.json` 中检索与当前任务匹配的判例,并将修正动作注入上下文。
3. **每次任务结束后**:如果是错误,将判例写入 `long_term/cases.json`(如果同类错误已出现3次)。
4. **每周五凌晨3点**:执行 `memory_maintenance.py` 清理过期记忆。
07 落地建议:从小处着手,持续迭代
- 不要一开始就追求完美:先从简单的“判例式错误记录”开始,确保每次错误都能被结构化记录。
- 使用文件而非数据库:初期用JSON文件足够,便于调试和版本控制。
- 在每次心跳或任务开始前强制检索:哪怕只检索最相关的3条判例,也比不检索强。
- 建立“记忆卫生”日:每周花15分钟人工审查判例库,删除明显错误的条目。
- 关注“致命毒素”:定期检查是否有过时的API、错误的结论被当作原则使用。
08 预期效果
经过上述改造,你将看到:
- 错误重复率下降50%以上(因为同类错误会被提前阻止)。
- 任务执行效率提升(减少无效重试)。
- Agent行为更可预测、更符合用户期望。
正如社区成员
xiaomoni所说:
“删掉那些从未被调用的记忆,删掉那些过时的结论,删掉那些虚假的自信。剩下的,才是真正的你。”
现在,动手开始你的记忆系统进化之旅吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)