实时生成领域的“速度与激情”: StreamDiffusion
最近对生图相关有些兴趣,看了看朋友推荐的 UC Berkeley、筑波大学等机构联合发布的论文——《StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation》,说句实话,习惯了在各种大模型时等几秒再出图的我,这篇文章给我的震撼,一点不亚于当初第一次看到 mid journey 给我生的图一样的感觉。

扩散模型在图像质量上其实已经做到相当顶尖了,各家大厂最新模型出图都效果刚刚的,但有个致命问题一直绕不开——推理延迟高、吞吐量低,只能等,搞不了一点实时交互场景(比如 AR/VR、直播、云游戏)。 StreamDiffusion从流水线层面,重新定义了实时生成的整个过程,就拿 RTX 4090 来说,它居然能跑到 91.07 FPS,这个数据是真的惊艳到我了。
基于论文里的核心设计,来跟大家好好拆解一下这个“实时生成神器”,尽量不堆砌术语,把关键逻辑讲明白。
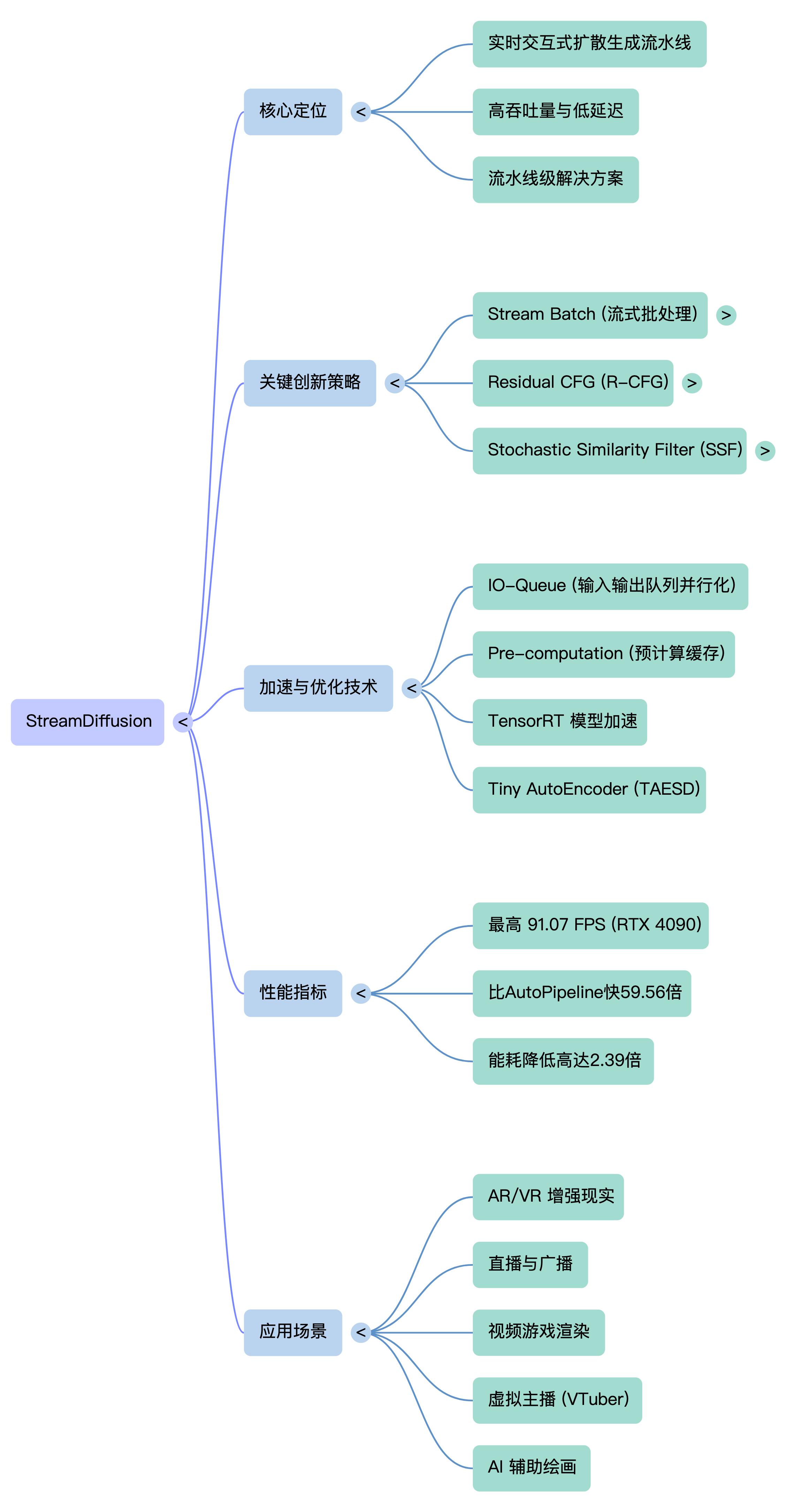
论文学习思维导图
一、核心痛点:为什么扩散模型跑不快?
其实传统扩散模型的采样过程,说穿了就是“串行操作”。举个简单的例子,一个需要 10 步完成的去噪过程,必须等第一步算完,才能开始第二步,一步都不能跳。这种“等做完再继续”的模式,导致 GPU 在处理连续输入流的时候,吞吐量低得让人着急。
之前的研究,大多盯着“减少去噪步数”做文章,比如 LCM、SD-Turbo 都是这个思路。但 StreamDiffusion 走了一条不一样的路——正交优化,说白了就是通过流水线并行,把 GPU 的性能榨干,这点真的很有启发。
二、绝招 1:Stream Batch —— 让去噪过程“流”起来
这应该是 StreamDiffusion 最有创新性的一个设计了,也是我个人觉得最亮眼的地方。
-
从串行到批处理,思路大转变:Stream Batch 把传统那种“一步等一步”的顺序去噪,重新改成了批处理模式。它会维护一个长度等于去噪步数(n)的批处理队列,每当有新的输入帧进来,流水线就会对队列里所有的元素,同时进行一步去噪。之后,把最末尾已经完成去噪的图像输出,再把新帧插进队列开头,形成一个循环,让去噪过程“流”起来。
-
显存换吞吐量,取舍很实在:这种方式,相当于把优化的平衡点,从“处理时间 vs 生成质量”,转移到了“显存容量 vs 生成质量”。只要你的显卡显存够大,就算是高步数的去噪,也能在一个 U-Net 处理周期内完成,这点对高端卡用户来说太友好了。
-
未来帧感知,解决视频一致性难题:更有意思的是,Stream Batch 还能在批处理里引入未来帧的信息,通过跨帧注意力机制(Cross-frame Attention),明显提升视频生成的时间一致性——大家都知道,视频生成最头疼的就是帧与帧之间脱节,这个设计正好戳中了痛点。
三、绝招 2:R-CFG —— 负面提示词推理的“免费午餐”
做过生成式 AI 的同学都知道,为了让生成结果贴合 Prompt,一般都会用 Classifier-Free Guidance (CFG)。但这个方法有个弊端:U-Net 每一步都要多算一次负面条件,计算量直接翻倍,速度一下就慢下来了。
作者们提出的 Residual Classifier-Free Guidance (R-CFG),相当于给这个问题开了个“特效药”:
-
虚拟残差噪声,省掉重复计算:它利用 LCM 的自一致性原理,假设去噪过程是朝着输入图像 x₀ 方向移动的轨迹。通过计算一个虚拟的负面条件残差,就能大幅减少甚至直接消除负面提示词的重复计算,相当于“少干活还不影响效果”。
-
两种模式,按需选择:一种是 Self-Negative R-CFG,完全不需要额外的 U-Net 计算,延迟几乎没变化,相当于“零成本提速”;另一种是 Onetime-Negative R-CFG,只在第一步计算一次负面条件,后续步骤都用它的近似值,也能省不少算力。实测下来,在 5 步去噪的情况下,这种优化能带来 2.05 倍的提速,效果是真的明显。
四、绝招 3:Stochastic Similarity Filter (SSF) —— 聪明地“偷懒”
其实在直播、监控这类实时场景里,很多时候画面是静止的,或者变化很小。如果这时候还一直重复计算 VAE 和 U-Net,简直是天大的浪费,既费电又占资源。
StreamDiffusion 引入的随机相似性过滤(SSF),就是一种“聪明的偷懒”:
-
概率采样,比硬阈值更灵活:它没有用那种生硬的阈值判断(比如“变化小于多少就跳过”),而是根据当前帧和参考帧的余弦相似度,计算一个“跳过概率”,随机性更强,也更贴合实际场景。
-
兼顾节能与流畅度:比起硬阈值导致的画面卡顿,这种基于采样的过滤方式,既能节省算力、降低功耗,又能保证视频流的平滑度,不会出现突然卡顿的情况。在 RTX 4090 上测试,SSF 居然能把 GPU 功耗降低约 2 倍,这个优化真的很实用。
五、极致的工程优化,细节拉满
除了上面三个核心算法,StreamDiffusion 还集成了一堆工业级的工程优化方案,能看出作者们是真的想做落地,而不是单纯发论文:
-
IO-Queue(输入输出队列):把预处理(比如图像缩放、归一化)和后处理,从主循环里移出去,用多线程并行处理,这样就减少了主循环的性能瓶颈,整体速度又提了一截。
-
Pre-computation(预计算):把 Prompt Embedding、噪声调度系数(αᵣ、βᵣ)还有 LCM 的参数,提前缓存起来,避免每次推理都重复计算,省下来的时间都能用在核心去噪上。
-
加速工具链,强强联合:全面用 NVIDIA TensorRT 做算子融合和精度优化,再配合轻量级的 Tiny AutoEncoder (TAESD) 做图像解码,速度直接拉满,这一套组合拳下来,效率提升非常明显。
六、性能实测:不只是快,而且强
论文里的实验部分,真的把 StreamDiffusion 的性能展现得淋漓尽致,说是“统治级”也不为过:
-
吞吐量碾压:在相同去噪步数下,它的性能比 Diffusers 官方的 AutoPipeline 快了 59.56 倍,这个差距真的太大了,完全不在一个量级。
-
画质不打折,甚至更优:最让人意外的是,在不做任何微调的情况下,StreamDiffusion 的 FID 分数居然比 LCM 等基准模型还好。这说明它的流水线设计不只是高效,甚至还能对生成质量有正面帮助,这一点真的超出预期。
-
商用潜力拉满:论文里还展示了实时游戏渲染、生成式滤镜、AI 辅助绘图等好几个应用场景,不是那种“纸上谈兵”的理论,而是真的能落地商用,这对我们做 AIGC 应用的开发者来说,参考价值太大了。
总结
说实话,看完这篇论文,我最大的感受是:StreamDiffusion 不只是一个“更快的扩散模型”,它更像是一套面向工业化落地的实时生成框架。其实挺想自己跑起来试试看的,可是看论文都是挤时间的情况下,真的有心无力。
不过好像搜狐AILab的绘光织影的“边画边变”功能就是把这个论文给复现落地了,我是从他们的描述里感觉的哈,真的很像是用的这个论文。看着他们确实有在真实线下活动中使用,看来AI界的论文和以前的论文还真不一样,要么是马上能落地,要么有的比论文可能还先行。

写在最后
如果大家对这个项目感兴趣,可以去它的 GitHub 开源地址看看(论文首页就有标注):https://github.com/cumulo-autumn/StreamDiffusion,建议大家结合代码再读论文,理解会更透彻。有了这个技术,我们就可以:
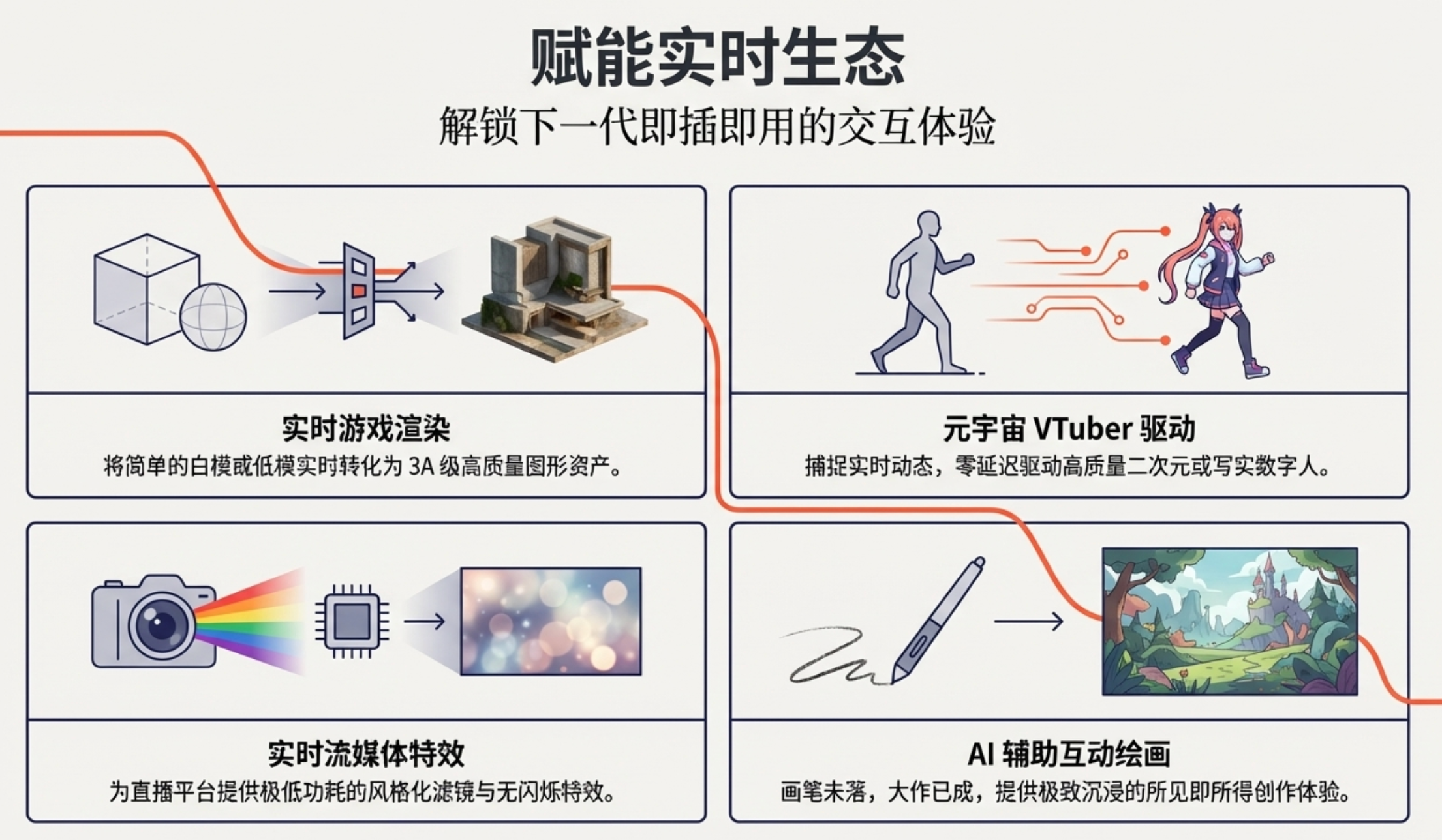
实时游戏,实时变化的剧情,和你互动的场景,想想好极了;
无宇宙,咋感觉和实时游戏一样了,哈哈;
实时流,那就是生成的内容可以直播了,以前太慢肯定是只能有视频,不能变直播流的;
辅助绘画,而且是实时的,感觉很适合亲子活动呀,小朋友的想像力变现,不用学画画专业知识了,也不用担心不够快玩不下去了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)