OpenClaw 为什么能“记住你是谁”?一次拆解 AI Agent 的记忆系统
最近 AI Agent 圈子里,一个项目被频繁提起:OpenClaw🦞。
很多开发者第一次打开它的代码时,都会产生一种很特别的感觉:这个项目不像是在做一个聊天机器人,更像是在设计一套 AI 的记忆体系。
在大多数 AI 应用里,“记忆”往往只是一个附加能力。有的产品会保存聊天记录,有的会接入一套简单的 RAG 检索系统,用来找回历史信息。
但 OpenClaw 的设计思路几乎是反过来的:它把“记忆”放在了 Agent 架构的中心。AI 的人格、用户是谁、最近发生了什么、哪些事情需要长期记住,这些信息都会被系统结构化地记录下来。
所以很多开发者第一次看到 OpenClaw 时都会有一种感觉:不像一个 AI 工具。更像是在搭建一个数字生命的记忆系统。
今天我们就从三个角度,一次讲清楚:
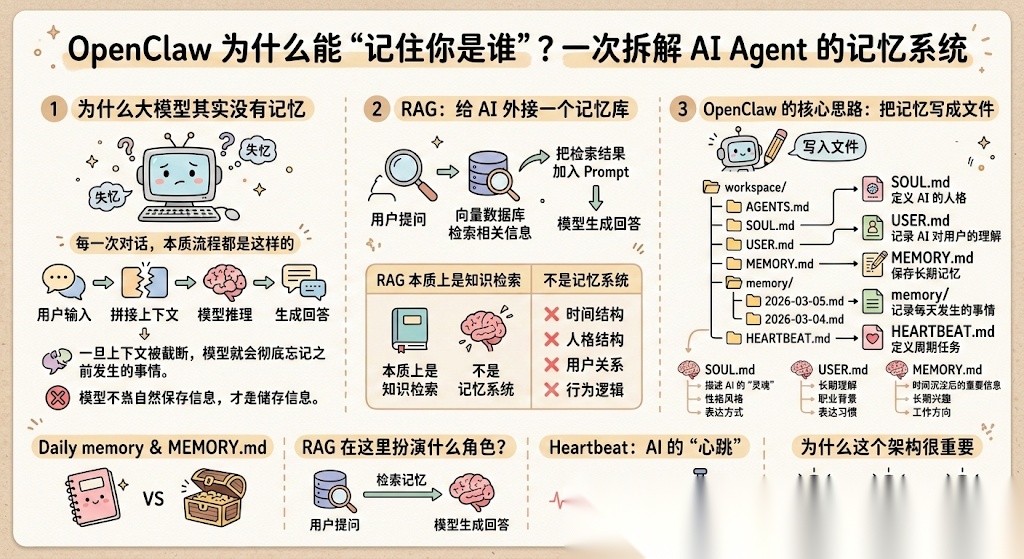
- 为什么大模型其实没有记忆
- RAG 为什么解决不了所有问题
- OpenClaw 是如何设计一套 Agent Memory 架构的
也就是一个问题:OpenClaw 为什么能“记得你是谁”?
一、为什么大模型其实没有记忆
很多人第一次接触大模型时,都会有一种直觉:LLM****是有记忆的。因为它能记住你刚刚说的话,也能根据前面的对话继续回答。
但从系统结构上看,大多数大模型其实是一个 “失忆体”。每一次对话,本质流程都是这样的:用户输入 -> 拼接上下文 -> 模型推理 -> 生成回答。
模型本身并不会真正存储你的信息。它只是根据当前输入的上下文,在概率空间里生成最合理的回答。
这就意味着,一旦上下文被截断,模型就会彻底忘记之前发生的事情。
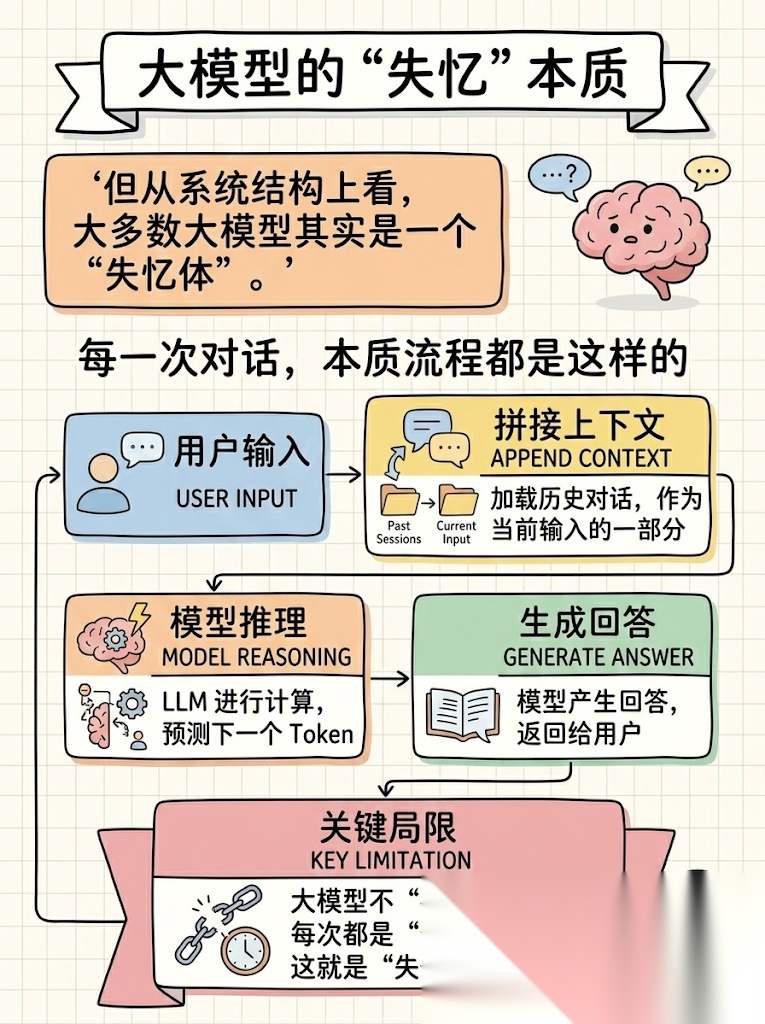
所以很多 AI 产品都会出现类似的问题:
- 记不住用户是谁
- 记不住长期项目
- 记不住用户习惯
- 每次聊天都像重新认识
这也是为什么,当我们开始构建 AI Agent 时,必须解决一个核心问题:AI 如何拥有长期记忆****?
目前主流的工程答案只有一个:RAG。
二、RAG:给 AI 外接一个记忆库
RAG是目前最常见的 AI 记忆方案。
它的核心逻辑其实非常简单:
用户提问
↓
向量数据库检索相关信息
↓
把检索结果加入Prompt
↓
模型生成回答
通过这种方式,AI 在回答问题时可以引用外部知识库,例如:公司文档、技术资料、用户历史信息、项目记录。
RAG 的优势非常明显:它可以存储大量信息,并且几乎不受上下文窗口限制。
但 RAG 其实有一个经常被忽略的问题:RAG 本质上是知识检索,而不是记忆系统。
因为它缺少几个关键结构:
- 它没有时间结构。
- 它没有人格结构。
- 它没有用户关系。
- 它也没有行为逻辑。
换句话说:RAG 更像是一个搜索引擎,而不是大脑。
这也是为什么很多 AI Agent 在接入 RAG 之后,虽然可以“查资料”,却依然不像一个真正拥有记忆的系统。
而 OpenClaw 的设计思路,正是从这里开始发生变化。
三、OpenClaw 的核心思路:把记忆写成文件
OpenClaw 采用了一个非常简单,但又非常优雅的思路:AI 的记忆必须是可读、可写、可编辑的。
于是它做了一件看起来非常“工程化”的事情:把所有记忆直接写进文件系统。
一个典型的 Agent workspace 大致是这样的结构:
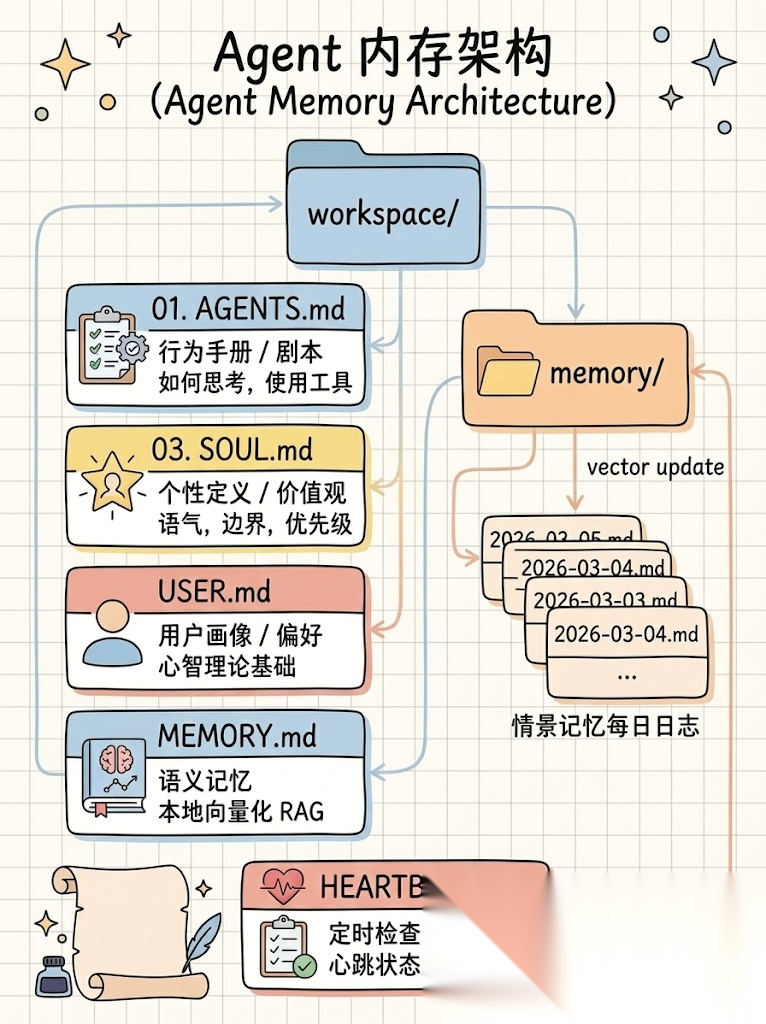
在这个结构里,每一个文件都有明确的职责。
- SOUL.md :定义 AI 的人格
- USER.md :记录 AI 对用户的理解
- MEMORY.md: 保存长期记忆
- memory/ :记录每天发生的事情
- HEARTBEAT.md: 定义周期任务
这些文件共同构成了一套非常清晰的 Agent Memory Architecture。
和传统的 AI 系统不同,这里有一个很重要的变化:记忆不再是数据库,而是系统结构的一部分。
四、SOUL.md:AI 的人格
在 OpenClaw 的记忆体系中,第一个关键文件是:SOUL.md。
顾名思义,它描述的是 AI 的 “灵魂”。
这个文件通常会定义 AI 的人格设定,例如:它的性格风格、行为原则、表达方式,以及在思考问题时倾向采用什么样的逻辑结构。
一个 SOUL.md 可能会写:
我是一个理性、冷静、喜欢解释原理的 AI。
回答问题时尽量结构化,优先解释背后的逻辑。
这些设定会在 Agent 启动时被加载,并成为 Prompt 的一部分。
从某种意义上说:SOUL.md 就是 AI 的人格配置文件。
这也是 Agent 系统和普通聊天机器人的一个重要区别——它不仅在回答问题,更是在 扮演一个稳定的角色。
五、USER.md:AI 对用户的理解
如果说 SOUL.md 定义的是 AI 是谁。
那么 USER.md 记录的就是:用户是谁。
这个文件通常会保存 AI 对用户的长期理解,例如:用户的职业背景、兴趣领域、表达习惯,以及一些长期偏好。
当 Agent 启动时,它会同时读取两个重要信息:
- 我是谁
- 你是谁。
这一步其实非常像人类的认知过程。
当我们和某个人对话时,大脑会自然地先建立两个上下文:
- 我现在处在什么角色
- 我正在和谁交流。
有了 USER.md,AI 才真正开始拥有一种 稳定的用户关系记忆。
六、daily memory:AI 的日记系统
除了人格和用户信息之外,OpenClaw 还设计了一层非常有意思的结构:daily memory。
在 workspace 中,通常会有一个 memory/ 文件夹,里面的文件按日期保存:
memory/
2026-03-05.md
2026-03-04.md
2026-03-03.md
这些文件记录的,其实就是:AI 的日记。
每天发生的重要事情都会被写入这里,例如:今天用户在研究 OpenClaw memory,用户准备写公众号文章,讨论了 RAG 与 Agent memory。
这些信息构成了 Agent 的 短期记忆层。
为了避免上下文过大,Agent 在启动时通常只会加载最近的记录,例如:今天、昨天,或者最近几天。这样既可以恢复最近的对话背景,也不会占用太多上下文空间。
从结构上看,这其实非常接近人类的记忆方式:最近发生的事情更容易被回忆起来。
七、MEMORY.md:长期记忆
如果说 daily memory 更像是日记。
那么:MEMORY.md就是 AI 的 长期记忆****库。
这里记录的是那些经过时间沉淀之后,依然重要的信息,例如:用户的长期兴趣、用户的工作方向、用户的一些稳定习惯。
比如:用户喜欢技术深度文章、用户经常写 AI 公众号、用户对 Agent memory 很感兴趣。
OpenClaw 通常会通过后台机制,把 daily memory 中的重要信息 总结并写入 MEMORY.md。
这个过程其实非常像人类记忆形成的方式:
日常经历
→ 经过整理
→ 变成长期经验
也正因为有了这一步,Agent 才不只是记录历史,而是在不断形成经验。
八、RAG 在这里扮演什么角色?
有意思的是,OpenClaw 并没有抛弃 RAG。
相反,它把 RAG 用在了一个非常合理的位置:检索记忆。
随着时间推移,memory 文件会越来越多。当用户提出某些问题时,比如:“我之前写过什么 AI 文章?”
系统就可以先做两件事:
- 第一步,把 memory 文件向量化。
- 第二步,通过 RAG 检索相关记录。
找到最相关的几条 memory 之后,再把这些内容加入 Prompt,让模型生成回答。
所以 OpenClaw 的整体结构其实是:文件记忆 + RAG 检索。
这种设计,比单纯的 RAG 系统更接近人类记忆的运作方式。
九、Heartbeat:AI 的“心跳”
OpenClaw 还有一个非常有意思的机制:Heartbeat。
在 workspace 中通常会有一个文件:HEARTBEAT.md。
它定义的是 Agent 的周期任务系统。
系统会定期触发 heartbeat,例如:每 30 分钟。
在这个周期里,AI 会执行一些后台任务,例如:检查最近的 memory、总结新的长期信息、提醒用户未完成的任务。
从结构上看,这有点像 AI 在进行 后台思考。这也是 Agent 系统和普通聊天机器人的另一个重要区别。
普通 AI 的行为模式是:**被动回答。 而 Agent 的行为模式是:**持续运行。
它不仅在对话,还在不断整理自己的记忆。
十、为什么这个架构很重要
OpenClaw 的 memory 设计,看起来其实并不复杂。很多核心信息,只是写进了一些 markdown 文件,例如:
SOUL.md
USER.md
MEMORY.md
memory/YYYY-MM-DD.md
但正是这种简单结构,让整个系统变得非常清晰。
首先,它让 AI 的记忆变得可解释。
在很多 AI 系统里,记忆通常藏在数据库或者向量空间里,对开发者来说是一个黑盒。
而在 OpenClaw 中,大部分重要信息都是可读文件。你可以直接打开这些文件,看到 AI 的人格设定、用户信息,以及每天发生的事情。
如果某个 Agent 的行为出现问题,也很容易通过这些记录找到原因。
其次,这种结构让 AI 的行为可以逐渐成长。
每天产生的 interaction 会被写入 daily memory,而 heartbeat 机制会定期对这些记录进行总结,把重要的信息整理进长期记忆。
随着时间推移,一个 Agent 的 memory 会越来越丰富,它的行为模式也会逐渐稳定下来。
这种感觉其实非常像人类的经验积累过程。
最后,这种设计还带来了一个非常重要的特点:可控性。
如果 AI 的某些记忆出现错误,并不需要重新训练模型。只需要修改对应的 memory 文件,系统在下一次读取时就会使用新的信息。
从工程角度看,这种方式其实非常优雅:复杂的问题被拆成了很多简单结构。
而从更宏观的角度来看,OpenClaw 其实在回答一个非常有意思的问题:未来的 AI,到底只是一个强大的模型,还是一个拥有长期记忆的系统?
当 AI 拥有稳定的人格设定、持续更新的记忆,以及对用户关系的长期理解时,它的角色就会发生变化。
它不再只是一个回答问题的工具,而更像是一个持续成长的数字助手。
也许未来的 AI 不只会记住你刚刚的问题。它还会记得:你是谁、你习惯如何工作、你过去做过哪些事情。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献227条内容
已为社区贡献227条内容

所有评论(0)