中低端GPU也能跑出高端性能|焱融AI存储降低Token成本关键路径
北京时间 3 月 17 日凌晨,英伟达 CEO 黄仁勋在 GTC 2026 主题演讲中表示:推理拐点已至。他直言未来的数据中心将不再是存储文件的仓库,而是生产 Token 的工厂,Token 是新商品。而就在此演讲前一天傍晚,阿里巴巴宣布成立 Alibaba Token Hub(ATH)事业群,锚定 “创造、输送、应用 Token” 的核心目标,全面布局 AI Token 生态。
两大信号共同指向一个核心逻辑的切换:在 Agentic AI 时代,OpenClaw 等 Agent 带来的范式变迁,使得 Token 的消耗脱离了“一问一答”式的人类输入频率限制。Agent 可以全天候无休工作,在后台进行自主决策、工具调用、长链条思考和多轮复杂交互,Token 消耗千百倍量级增长,驱动整个 AI 工厂运转,成为新时代的“流量通货”。
这也意味着推理能力的核心指标转向 Token 生产效率——推理性能和推理效率。Token 的生成速度衡量性能高度,推理效率则直接影响每一个 Token 的“出厂成本”,两者进一步决定了企业的产出成果和收益。
在近期 ODCC 联合 NVIDIA、焱融等首发的 KVCache 测试结果中,焱融 YRCache 推理存储系统表现强劲。通过“以存代算”核心架构,YRCache 不仅实现了中端 GDDR GPU(如 RTX 6000D)和高端 HBM GPU(如 H20)推理性能和效率的全面数量级提升,更将 RTX 6000D 的推理能力全面拉近至 H20 水平, 重构推理成本和收益格局,让客户拥有更多硬件方案选择。
数据实证:焱融 YRCache让中低配显卡跑出“旗舰感”
基于 DeepSeek-R1 等主流大模型,以及 NVIDIA 的计算和网络平台环境,本次测试对比了在原生 vLLM 框架下与集成 YRCache 的系统性能表现。本次实测数据真实展现了焱融 YRCache 对推理性能边界的极限突破。


从上图中的数据可以看到,在未使用 YRCache 时,8 卡中端 GDDR GPU(如 RTX 6000D) 相较于 8 卡高端 HBM GPU(如 H20),在 TTFT、TPOT 和 Token 吞吐量等核心指标上均存在明显差距;而使用 YRCache 后,两者性能基本持平。
推理“存力”成为 Token “收益力”,YRCache 重构 AI 推理成本和收益格局
这一测试结果的价值,绝不仅仅是技术参数的领先,更是对 AI 基础设施核心逻辑的重构。“硬件决定性能上限”的认知正被打破,“以存代算”“存算协同”成为挖掘推理潜力的新关键。

黄仁勋在 GTC 演讲中强调,未来的 AI 工厂必须在固定功耗下追求最高的每瓦 Token 吞吐量。而吞吐量的提升本质上对应着单位 Token 成本的下降。焱融 YRCache 的实践印证了这一点——中低端 GPU 性能被拉平至高端 GPU,正是存力解放算力的最佳例证。这种“性能拉平”带来的冲击力是巨大的。下面以 400Gbps 网络环境下的测试数据为例,对原生 vLLM 方案与集成 YRCache 后的方案进行成本与收益的深度对比分析。
单位 Token 成本对比
在 400Gbps 网络环境下,RTX 6000D 在原生 vLLM 和集成 YRCache 后的 Token 吞吐量分别为 4341 和 78564 tokens/s;H20 在原生 vLLM 和集成 YRCache 后的 Token 吞吐量分别为 14269 和 103050 tokens/s;
硬件成本:为便于理解并简化计算,仅考虑 GPU 成本。中端 GDDR GPU 价格约为高端 HBM GPU 价格的一半。按照单卡 RTX 6000D 5万元、单卡 H20 10 万元计算。假设全年无休运行,且业务需求足以消化全部算力。

从上表可以看出,在未使用YRCache时,H20 凭借更高的 HBM 带宽和容量,Token 产出是 RTX 6000D 的 3.3 倍,显著抵消了其价格较高带来的影响,单位 Token 成本比 RTX 6000D 低 40%。
然而,使用 YRCache 后,RTX 6000D 和 H20 的吞吐量均大幅提升,相应带来单位 Token 成本下降——H20 和 RTX 6000D 分别下降 86% 和 94%。但由于 YRCache 将 RTX 6000D 的性能拉升至接近 H20,叠加其本身硬件价格优势,其单位 token 成本优势反超 H20,仅为 H20 的 65%。
年 Token 收益能力对比
Token 定价参考:采用 deepseek-reasoner 级别模型定价标准,百万 tokens 输入(缓存命中)0.2 元,百万 tokens 输入(缓存未命中)2 元,百万 tokens 输出 3 元。
百万 tokens 平均收入:假设输入/输出比 3:1,缓存命中率 80%,则平均收入 = 4.68 元 / 百万 tokens
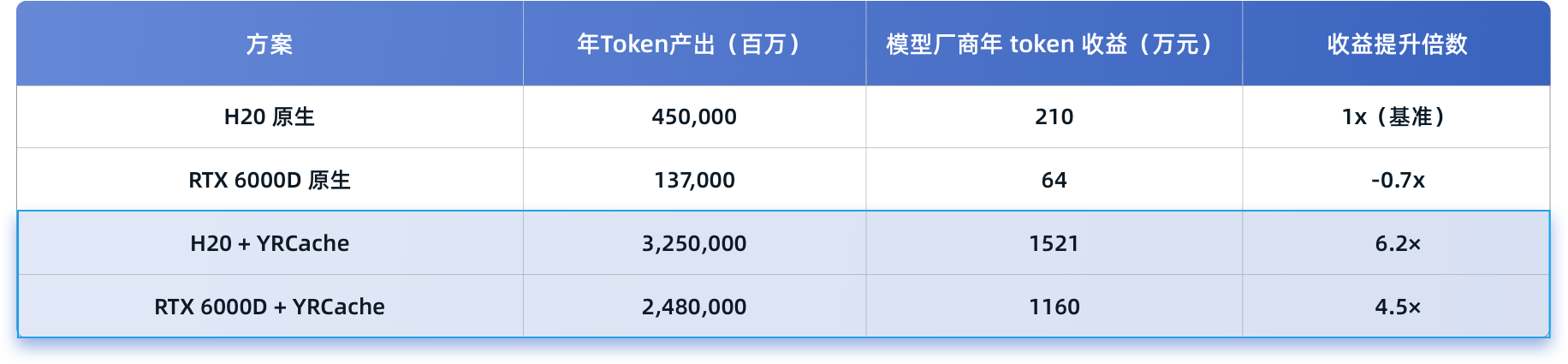
在 Token 即商品的时代,单位 Token 成本的降低与吞吐量的提升,更直接地影响了企业的收益水平。从上表中的测算数据可以看出,使用 YRCache 后,RTX 6000D 和 H20 创造的 Token 收益均实现千万级增长,相比其各自的原生方案分别增长了 17 倍和 6 倍。
与此同时,RTX 6000D 的收益能力也进入了高端卡区间,但其硬件成本只有高端卡的一半。这一对比充分证明,YRCache 是推理基础设施“以存代算”的优选解,助力企业实现“低成本、高产出”。
焱融 YRCache 推理存储系统在本次测试中的表现,不仅验证了其通过重构 KVCache 存储路径和极致管理优化,打破显存墙,显著提升推理性能和效率的能力,更揭示了一个重要事实:我们完全可以用更经济的中低端硬件,实现匹配高端硬件的推理能力。
Agentic AI 正在狂飙突进,Token 成为驱动整个 AI 工业体系运转的“燃料”。焱融 YRCache 不仅是一项推理存储技术的突破,更是一把加速 Token 生产、降低成本、提升收益的金钥匙,助力更多企业打造高效、低成本的 AI Token 工厂,在 Agentic AI 时代的 Token 竞争中抢占先机。
附:更多测试数据解析请查看ODCC联合NVIDIA、焱融等首发KVCache评测结果|焱融AI存储实现推理提速降本双突破

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)