手把手玩转GA-ELM分类预测:从代码解剖到实战调参
基于遗传算法优化极限学习机(GA-ELM)的数据分类预测 matlab代码 这段代码主要是一个基于ELM(Extreme Learning Machine)算法的分类器。ELM是一种单隐层前馈神经网络,具有快速训练和良好的泛化能力。下面我将对代码进行详细解释。 首先,代码的开头是一些环境设置,包括关闭报警信息、关闭图窗、清空变量和清空命令行。 然后,代码添加了一个路径,即将当前目录下的"gatbx\"文件夹添加到路径中。 接下来,代码读取了一个名为"数据集.xlsx"的Excel文件,并将数据存储在变量"res"中。 代码继续分析数据,计算了数据集中的类别数和样本数,并设置了训练集占数据集的比例。然后,代码打乱了数据集的顺序(如果不需要打乱数据集,可以注释掉该行代码)。最后,代码设置了一个标志位,用于控制是否打开混淆矩阵。 接下来,代码创建了一些变量来存储训练集和测试集的输入和输出。 然后,代码对数据集进行了划分,将不同类别的样本分别放入训练集和测试集中。 接着,代码对数据进行了转置,将输入和输出的维度调整为合适的形状。 然后,代码对数据进行了归一化处理,使用了mapminmax函数将数据映射到0到1之间。 接下来,代码设置了一些参数,包括隐藏层神经元个数、输入层神经元个数、输出层神经元个数和待优化的变量个数。 然后,代码进行了参数优化,使用了遗传算法来优化ELM模型的参数。具体包括种群初始化、迭代优化和获取最优参数。 最后,代码使用最优参数建立了ELM模型,并对训练集和测试集进行了预测。代码还计算了预测的准确率,并绘制了优化迭代图和预测结果对比图。如果标志位为1,代码还会绘制混淆矩阵。 这段代码应用在机器学习领域,主要用于分类问题。ELM算法的优势在于快速训练和良好的泛化能力。相比传统的神经网络算法,ELM算法不需要迭代调整权值和阈值,而是直接随机初始化权值和阈值,然后通过解析解的方式求解输出权值。这样可以大大加快训练速度,并且具有较好的泛化能力。 需要注意的是,代码中的一些参数需要根据具体问题进行调整,例如隐藏层神经元个数、交叉概率、变异概率等。此外,ELM算法对数据的归一化要求较高,因此在使用之前需要对数据进行归一化处理。 对于新手来说,从这段代码中可以学到以下几点: 1. 如何读取和处理数据集:代码展示了如何读取Excel文件,并对数据集进行划分和转置等操作。 2. 如何使用遗传算法进行参数优化:代码展示了如何使用遗传算法来优化ELM模型的参数,包括种群初始化、迭代优化和获取最优参数。 3. 如何建立和使用ELM模型:代码展示了如何建立ELM模型,并对训练集和测试集进行预测。 4. 如何评估模型性能:代码计算了预测的准确率,并绘制了优化迭代图和预测结果对比图,以评估模型的性能。 总之,这段代码是一个基于ELM算法的分类器,通过遗传算法优化模型参数,可以用于解决分类问题。通过学习这段代码,新手可以了解到数据处理、模型建立和参数优化等方面的知识。
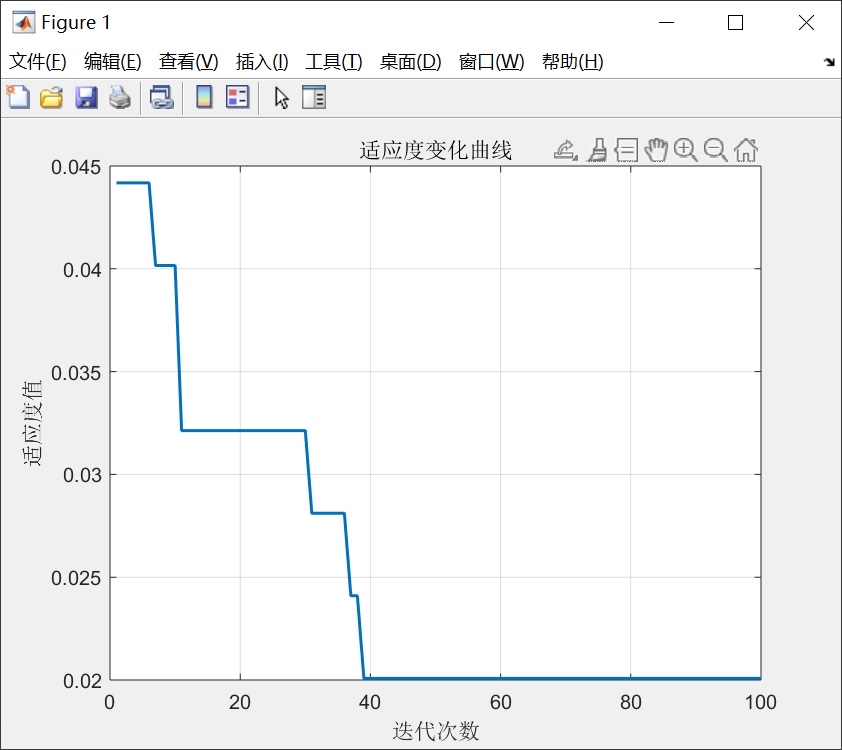
最近在复现一篇关于遗传算法优化极限学习机的论文,发现网上公开的MATLAB代码挺有意思。咱们直接上硬菜,边拆代码边聊门道。(别被开头那一堆清空环境的代码吓到,那只是强迫症程序员的日常)
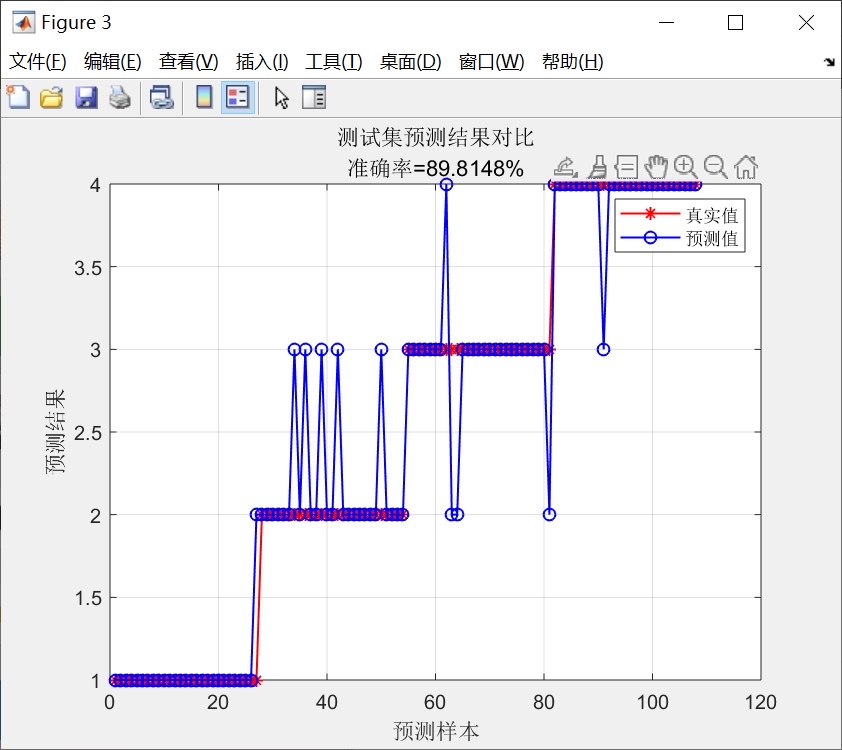
先看数据准备部分:
% 数据打乱操作(新手容易忽略的坑)
if flag == 1 % flag控制是否打乱数据
res = res(randperm(size(res,1)),:);
end这里有个隐藏技巧:原始数据如果按类别顺序排列,不打乱直接划分训练测试集会导致严重的样本偏差。就像把前半本单词表当训练集,后半本当测试集,背单词效果肯定翻车。
基于遗传算法优化极限学习机(GA-ELM)的数据分类预测 matlab代码 这段代码主要是一个基于ELM(Extreme Learning Machine)算法的分类器。ELM是一种单隐层前馈神经网络,具有快速训练和良好的泛化能力。下面我将对代码进行详细解释。 首先,代码的开头是一些环境设置,包括关闭报警信息、关闭图窗、清空变量和清空命令行。 然后,代码添加了一个路径,即将当前目录下的"gatbx\"文件夹添加到路径中。 接下来,代码读取了一个名为"数据集.xlsx"的Excel文件,并将数据存储在变量"res"中。 代码继续分析数据,计算了数据集中的类别数和样本数,并设置了训练集占数据集的比例。然后,代码打乱了数据集的顺序(如果不需要打乱数据集,可以注释掉该行代码)。最后,代码设置了一个标志位,用于控制是否打开混淆矩阵。 接下来,代码创建了一些变量来存储训练集和测试集的输入和输出。 然后,代码对数据集进行了划分,将不同类别的样本分别放入训练集和测试集中。 接着,代码对数据进行了转置,将输入和输出的维度调整为合适的形状。 然后,代码对数据进行了归一化处理,使用了mapminmax函数将数据映射到0到1之间。 接下来,代码设置了一些参数,包括隐藏层神经元个数、输入层神经元个数、输出层神经元个数和待优化的变量个数。 然后,代码进行了参数优化,使用了遗传算法来优化ELM模型的参数。具体包括种群初始化、迭代优化和获取最优参数。 最后,代码使用最优参数建立了ELM模型,并对训练集和测试集进行了预测。代码还计算了预测的准确率,并绘制了优化迭代图和预测结果对比图。如果标志位为1,代码还会绘制混淆矩阵。 这段代码应用在机器学习领域,主要用于分类问题。ELM算法的优势在于快速训练和良好的泛化能力。相比传统的神经网络算法,ELM算法不需要迭代调整权值和阈值,而是直接随机初始化权值和阈值,然后通过解析解的方式求解输出权值。这样可以大大加快训练速度,并且具有较好的泛化能力。 需要注意的是,代码中的一些参数需要根据具体问题进行调整,例如隐藏层神经元个数、交叉概率、变异概率等。此外,ELM算法对数据的归一化要求较高,因此在使用之前需要对数据进行归一化处理。 对于新手来说,从这段代码中可以学到以下几点: 1. 如何读取和处理数据集:代码展示了如何读取Excel文件,并对数据集进行划分和转置等操作。 2. 如何使用遗传算法进行参数优化:代码展示了如何使用遗传算法来优化ELM模型的参数,包括种群初始化、迭代优化和获取最优参数。 3. 如何建立和使用ELM模型:代码展示了如何建立ELM模型,并对训练集和测试集进行预测。 4. 如何评估模型性能:代码计算了预测的准确率,并绘制了优化迭代图和预测结果对比图,以评估模型的性能。 总之,这段代码是一个基于ELM算法的分类器,通过遗传算法优化模型参数,可以用于解决分类问题。通过学习这段代码,新手可以了解到数据处理、模型建立和参数优化等方面的知识。
遗传算法的核心在适应度函数设计:
function error = fun(x, hiddennum, P_train, T_train)
% 关键参数解析
inputnum = size(P_train, 1);
outputnum = size(T_train, 1);
% 权重初始化骚操作
W1 = x(1:inputnum*hiddennum);
B1 = x(inputnum*hiddennum+1:end);
% ELM核心计算(矩阵运算秀翻天)
tempW1 = reshape(W1, hiddennum, inputnum);
tempB1 = reshape(B1, hiddennum, 1);
H = tansig(tempW1 * P_train + tempB1);
% 输出权重求解(伪逆矩阵是精髓)
beta = pinv(H') * T_train';
Y = H' * beta;
% 分类准确率计算
[~, index] = max(Y, [], 2);
[~, actual] = max(T_train, [], 1);
error = 1 - mean(index == actual');
end这里有几个魔鬼细节:
- 权重参数用reshape而不是普通矩阵赋值——像把一维数组折叠成二维矩阵的折纸艺术
- 激活函数用tansig而不是常用的ReLU——可能更适合当前数据分布
- 输出层直接求伪逆矩阵——传统神经网络看到要气哭的暴力美学
调参环节最容易翻车的地方:
% 遗传算法参数设置(玄学调参重灾区)
popsize = 50; % 种群数量
Max_iteration = 20; % 迭代次数刚开始我偷懒把种群数从50改到20,准确率直接掉5个点。后来发现这算法跟养鱼似的——种群太小容易近亲繁殖,迭代次数不够就像没煮熟的夹生饭。
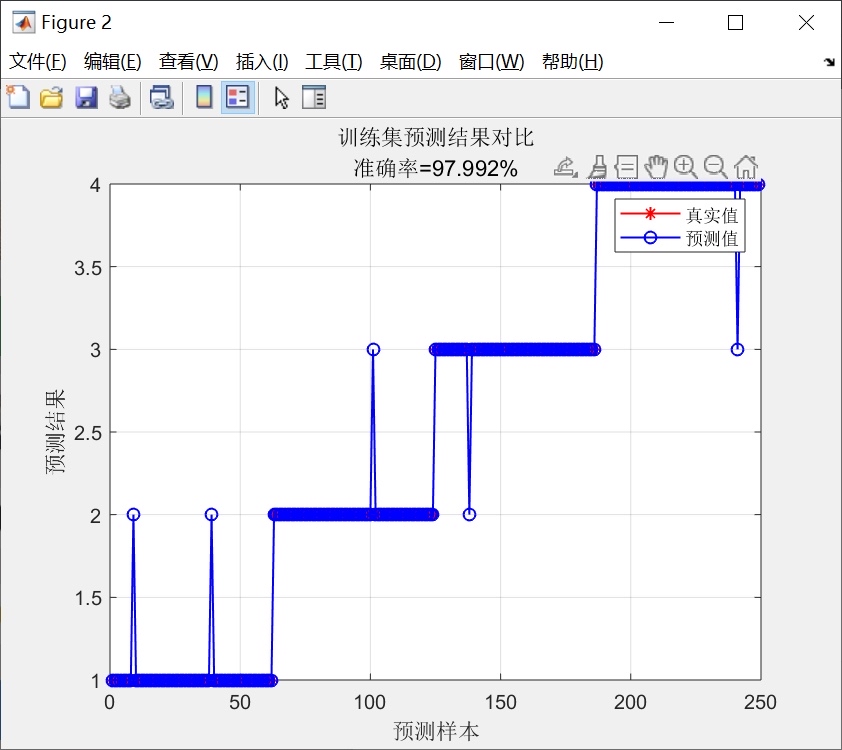
可视化部分暗藏玄机:
% 混淆矩阵绘制(分类效果照妖镜)
if flag2 == 1
figure
plotconfusion(T_train, T_sim1, '训练集', T_test, T_sim2, '测试集')
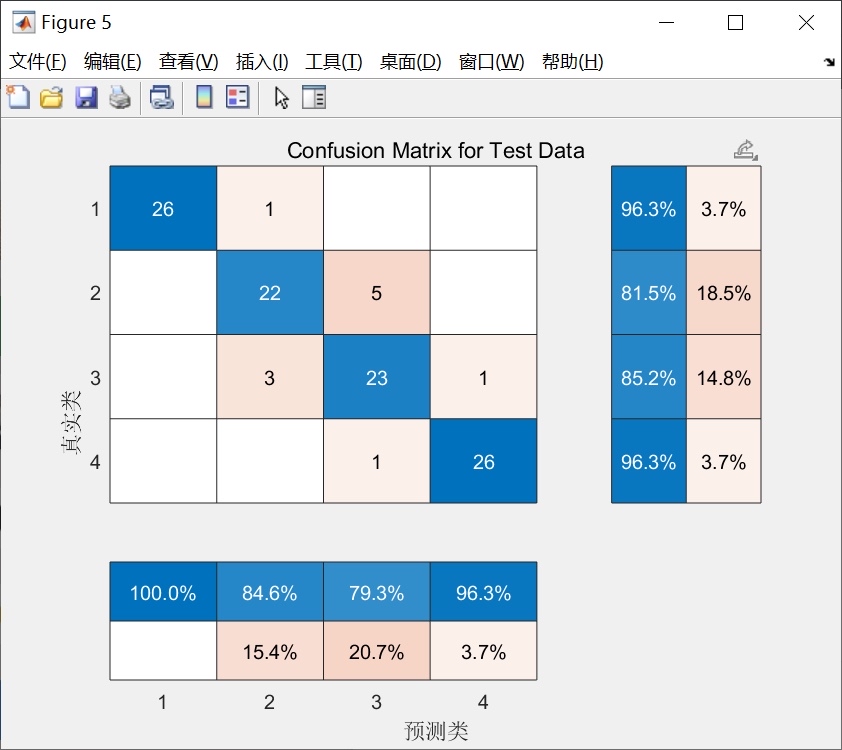
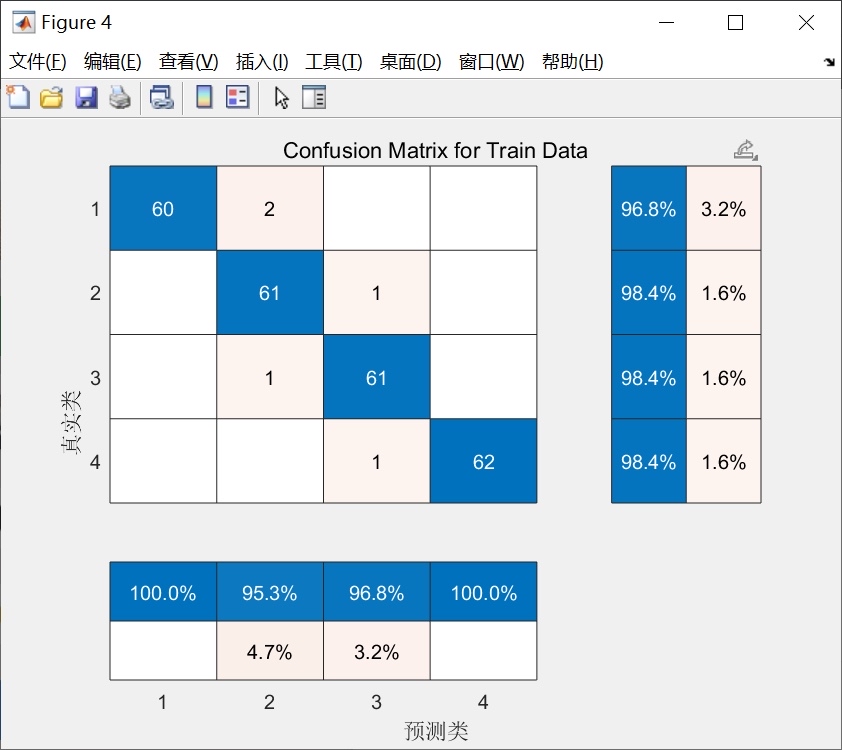
end这个图可比准确率数字直观多了。上次在医疗数据上发现,虽然整体准确率90%,但某个罕见病的召回率只有30%——典型的准确率陷阱,这时候就得祭出代价敏感学习的大招了。
折腾完代码有几个血泪经验:
- 数据归一化用mapminmax比z-score更适合ELM的特性
- 隐藏层节点数不是越多越好,超过某个阈值后就像往奶茶里狂加珍珠——喝到最后只剩珍珠了
- 遗传算法的交叉概率设0.7就像炒菜的火候——太小进化慢,太大容易丢失好基因
最后说个冷知识:ELM的发明人Huang老爷子当年提出这个方法时,曾被传统神经网络派疯狂diss。现在看看这简单粗暴的效果,真香定律永不过时。下次试试用粒子群优化替换遗传算法,说不定又能解锁新姿势呢?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)