Pipecat:构建实时语音 AI Agent 的开源编排框架,500ms 级端到端延迟

导读:
———————————————————————————————————————————
语音 AI 的模型越来越多——ASR 有 Deepgram、Whisper,LLM 有 GPT、Claude、Gemini,TTS 有 ElevenLabs、Azure。但要把这些模型串成一个能实时对话的 Agent,工程挑战远比模型选型更大:音频流怎么接入?各服务之间怎么低延迟传递?用户打断怎么处理?多模态(语音+视频)怎么同步?Pipecat 就是为解决这个问题设计的:一个开源 Python 框架,把 ASR、LLM、TTS 和传输层组装成可实时对话的管线,端到端延迟 500-800ms。
本文将介绍 Pipecat 的管线架构、服务生态、典型使用场景和上手方式。
项目信息
GitHub:https://github.com/pipecat-ai/pipecat
Stars:10.8k
协议:BSD 2-Clause
最新版本:v0.0.105(累计 8,300+ commits,2026 年 3 月仍在持续更新)
文档:https://docs.pipecat.ai
一、核心概念:管线(Pipeline)
———————————————————————————————————————————
Pipecat 的架构围绕一个核心概念——管线(Pipeline)。管线由一系列处理器(Processor)组成,数据以帧(Frame)的形式在处理器之间流动。
一次典型的语音对话流程:
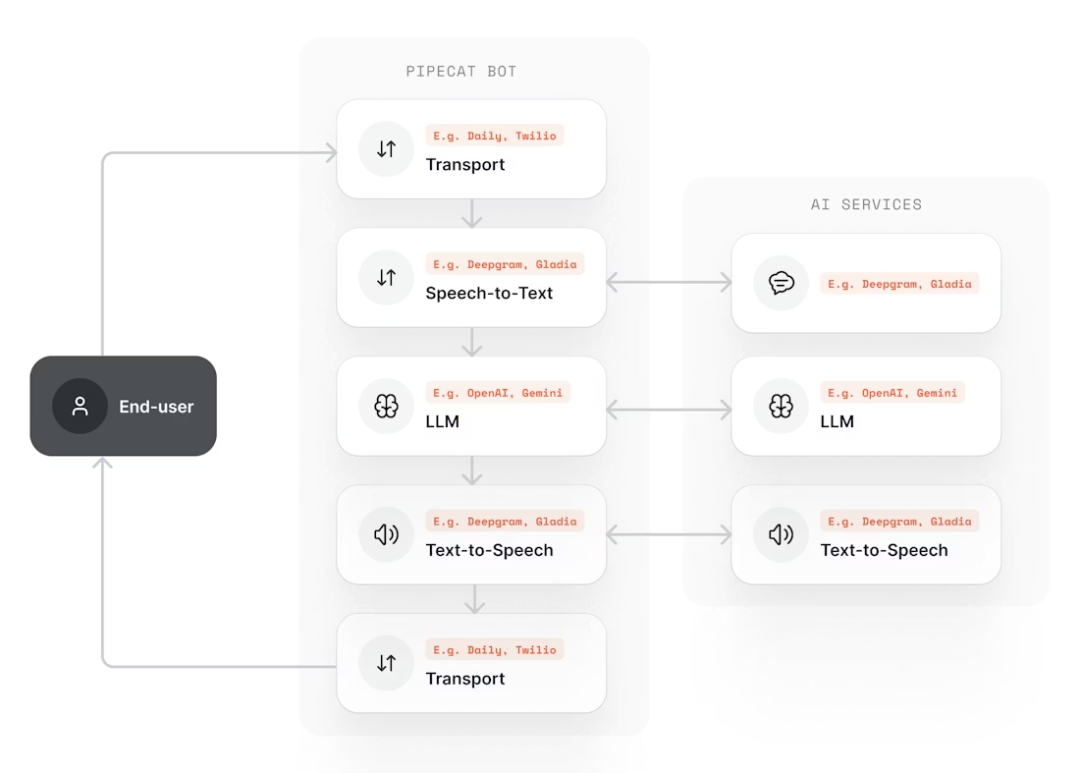
每个环节是一个独立的处理器,可以替换为不同的服务提供商。整个管线实时运行,端到端延迟控制在 500-800ms,接近自然对话体验。
二、服务生态:可插拔的 AI 服务
———————————————————————————————————————————
Pipecat 的价值在于不绑定特定服务商,而是提供统一接口对接各类 AI 服务:
| 类别 | 服务商数量 | 代表服务 |
|---|---|---|
|
语音识别(STT) |
18+ |
Deepgram、OpenAI Whisper、Google、Azure |
|
大语言模型(LLM) |
18+ |
Anthropic Claude、OpenAI GPT、Google Gemini、Groq |
|
语音合成(TTS) |
24+ |
ElevenLabs、Google、Azure、Piper(本地离线) |
|
语音到语音(S2S) |
新兴 |
OpenAI Realtime、Ultravox |
|
其他 |
— |
视频生成、音频处理、记忆系统、分析平台 |
切换服务商只需要替换管线中对应的处理器,不影响其他环节。例如从 Deepgram STT 切换到 Whisper,只需改一行配置。
三、不只是语音:多模态和结构化对话
———————————————————————————————————————————
多模态支持
Pipecat 的管线不限于音频。它可以同时处理:
语音输入/输出
视频流
图像
文本
传输层支持 WebRTC 和 WebSocket,可以连接浏览器、手机应用、电话系统等不同终端。
结构化对话:Pipecat Flows
对于需要按固定流程推进的场景(如客服工单、信息采集、预约),Pipecat 提供了 Pipecat Flows 模块,用于定义结构化的对话流程,确保 Agent 按步骤完成任务而不跑偏。
四、客户端 SDK 和开发工具
Pipecat 不只是后端框架,还提供了前端接入方案:
| 组件 | 说明 |
|---|---|
|
JavaScript SDK |
浏览器端接入 |
|
React / React Native SDK |
Web 和移动端 |
|
Swift SDK |
iOS 原生 |
|
Kotlin SDK |
Android 原生 |
|
C++ SDK |
桌面/嵌入式 |
|
ESP32 SDK |
IoT 设备 |
开发工具:
| 工具 | 说明 |
|---|---|
|
Pipecat CLI |
项目脚手架,快速创建新项目 |
|
Whisker |
可视化调试器,查看管线中的帧流动 |
|
Tail |
终端仪表盘,监控运行状态 |
|
Voice UI Kit |
语音交互界面组件 |
五、上手方式
———————————————————————————————————————————
1.安装
# 使用 uv(推荐)
uv init my-voice-agent
cd my-voice-agent
uv add pipecat-ai
# 安装特定服务的依赖(如 Deepgram STT + OpenAI LLM + ElevenLabs TTS)
uv add "pipecat-ai[deepgram,openai,elevenlabs]"
也支持传统 pip 安装:
pip install pipecat-ai
pip install "pipecat-ai[deepgram,openai,elevenlabs]"
要求 Python 3.10+,推荐 3.12。
2.典型使用场景
| 场景 | 说明 |
|---|---|
|
语音助手 |
实时语音识别 + LLM 回复 + 语音播报 |
|
电话 Agent |
客服、信息采集、预约系统 |
|
AI 伴侣 |
教练、会议助手、角色扮演 |
|
多模态应用 |
语音 + 视频 + 图像组合交互 |
|
语音游戏 |
实时语音控制的 AI 游戏 |
|
业务 Agent |
工单处理、客户支持 |
六、总结
———————————————————————————————————————————
Pipecat 解决的是语音 AI 落地的工程编排问题:模型很多,但把它们串成一个低延迟、可靠、可维护的实时对话系统需要大量基础设施工作。Pipecat 把这层工作标准化了。
适合关注的场景:
需要构建实时语音对话 Agent(客服、助手、电话机器人)
想在多个 ASR/LLM/TTS 服务商之间灵活切换
需要多模态交互(语音 + 视频 + 文本)
需要将语音 Agent 接入手机、浏览器、IoT 设备等多种终端
当前局限:
依赖外部 AI 服务(STT/LLM/TTS),延迟和成本受服务商影响
本地离线运行的选项有限(Piper TTS 支持离线,但大部分服务需要网络)
版本号仍为 0.0.x,API 可能在迭代中变化

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)