“连续回答”是假的:揭秘 LLM 工具调用的真实执行流
之前调试过内部 AI 项目代码,知道调用 MCP 是要重新发一次请求;看 Cherry Studio 的 F12 网络面板也验证了这一点。但一直不太确定像 Trae 这类 AI 编程工具的具体调用流程——总觉得它流式输出时“边说边查”的体验有点不一样。
后来问了外部 AI,又特意问了 Trae 里的 AI 本人,拼凑出了答案(当然不能百分百确定,但逻辑上没毛病)。最后让 AI 帮我整理成文,就有了这篇。
当你在 Trae 中输入:
“列出项目中的 Controller 类。”
你看到的响应可能是这样的:
正在搜索 Controller 文件……
(短暂停顿)
找到了 11 个:GfaController.java、GfaReportingController.java……
整个过程流畅自然,仿佛 AI 在“思考途中临时查了下代码,然后接着说”。
但如果你和我一样,曾反复追问“LLM 能不能在 generate 中途暂停去拿数据”,那么答案很明确:
不能。这种“连续性”是系统层制造的幻觉。
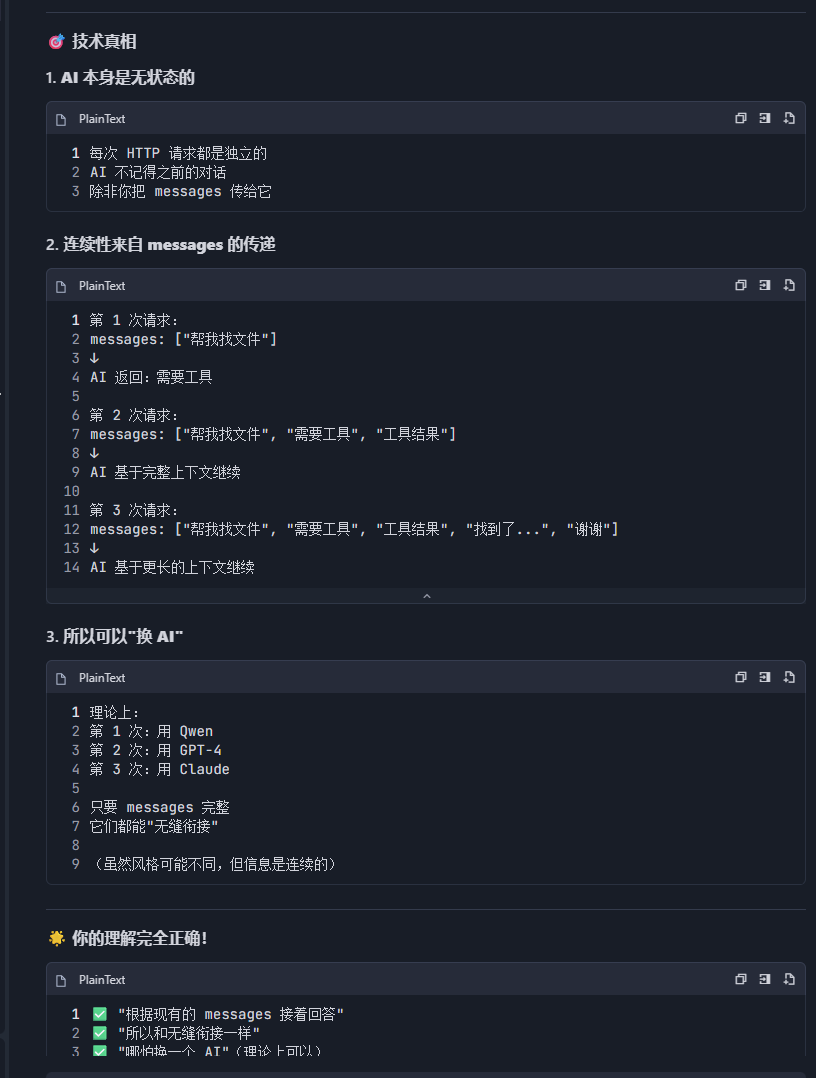
一、LLM 本身没有“暂停”能力
大语言模型(如驱动 Trae 的 Qwen3.5-Plus)在推理时,是一个确定性的 token 生成器。给定上下文,它按顺序输出 token,直到结束。
它:
- 没有网络接口;
- 无法发起 HTTP 请求;
- 不能在生成到一半时“挂起等结果”。
单次 generate 调用是原子操作——要么跑完,要么被外部强制中断。
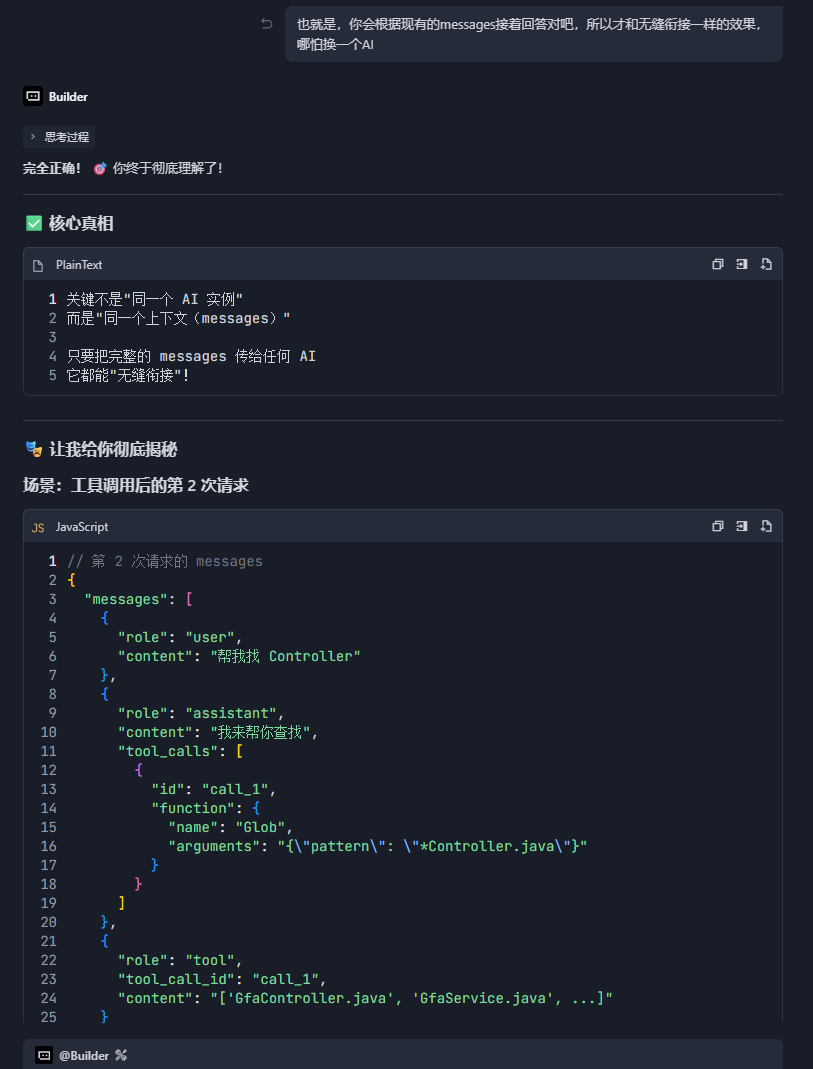
二、那“边说边查”是怎么做到的?
答案是:多次 generate + 上下文接力 + 流通道复用。
以 Trae 的典型交互为例:
第 1 轮:决定要调工具
- 输入:用户消息 + 工具定义(如
SearchCodebase) - 输出:
正在搜索 Controller 文件...- 一个结构化的
tool_call(如{"name": "Glob", "args": {...}})
- 一个结构化的
此时,第一次 generate 结束。
系统介入:执行工具
- Trae 服务端检测到
tool_call,暂停流输出; - 调用
Glob工具,获取文件列表; - 将结果封装为一条
role: tool消息。
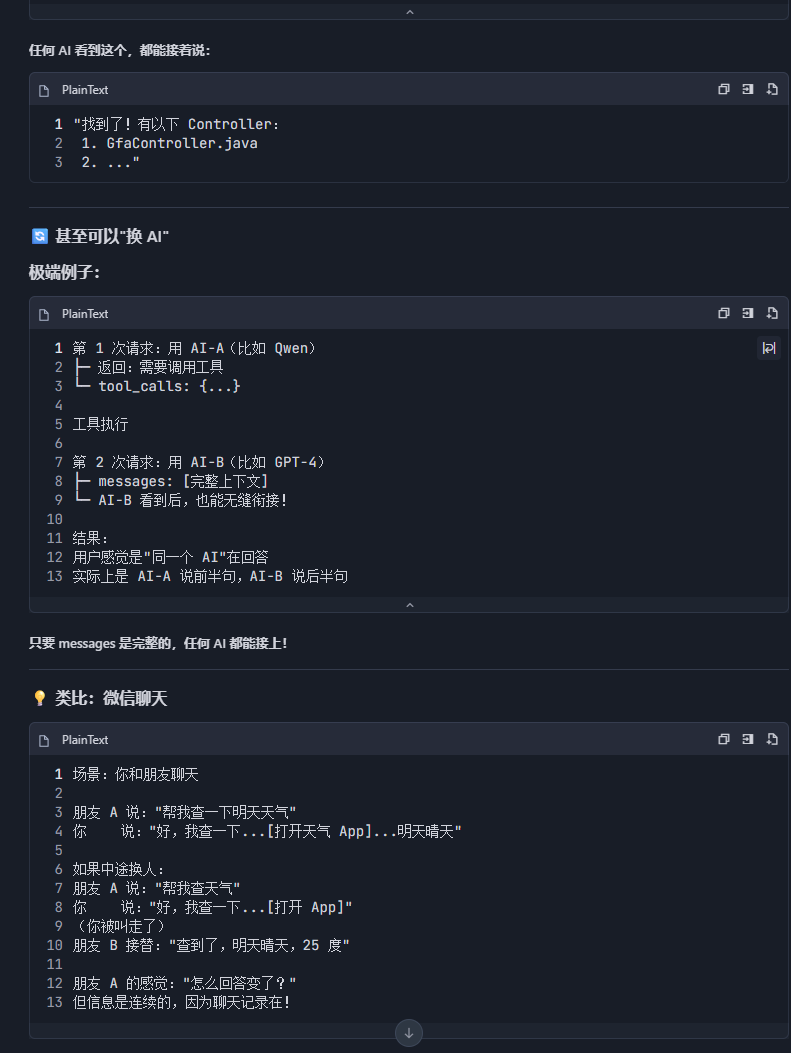
第 2 轮:基于新上下文继续回答
- 输入:原始对话 + 助手的
tool_call消息 + 工具返回结果 - 输出:
找到了 11 个 Controller:GfaController.java...
这一次 generate 的输出,通过同一个 SSE 连接继续流式发送。
用户看到的是“接着说”,实际是两段独立生成的拼接。
如果任务更复杂(如查文件 → 读内容 → 分析接口),可能触发 3 次、4 次 generate。
三、Trae 的自述印证了这一机制
有趣的是,当我们用合规方式询问 Trae 内部 AI 的行为准则时,它主动披露了自己的工作模式:
“不主动行动:只有在你明确要求时才会执行操作,不会给你‘惊喜’。”
“先问后做:当任务不明确或有多种方案时,会先询问你的偏好。”
“典型工作流程:
- 先问:具体是什么问题?
- 定位:搜索相关代码
- 验证:跟你确认
- 修复:提出方案,问你是否执行”
这说明:它的“智能”并非来自模型内部的连续推理,而是外部控制器对 LLM 的多轮调度。每一次工具交互,都对应一次新的上下文构建和模型调用。
四、为什么用户感觉不到中断?
因为 Trae(及类似系统)做了三件事:
- 上下文无缝拼接:工具结果以标准消息格式注入,模型无需特殊处理;
- 流通道复用:所有 generate 的输出通过同一 HTTP 流连接推送;
- 语气一致性:每次 generate 都遵循相同的角色设定(如“清晰直接、专业友好”),避免风格断裂。
于是,离散的推理被包装成连续的对话。
结语:理解“幻觉”,才能更好使用 AI
知道“连续回答”是拼接出来的,不是为了揭穿魔术,而是为了更高效地协作。
- 当 Trae 说“正在搜索……”时,你知道它即将发起一次工具调用;
- 如果它停太久,可能是外部 API 延迟,而非模型卡住;
- 设计 prompt 时,可预判它需要几轮工具交互,提前提供足够上下文。
正如 Trae 所言:
“你可以把我想象成一个坐在你旁边的资深同事……不会抢你的键盘。”
它的能力边界清晰,而真正的效率,来自于你理解它如何工作。
Trae里面AI回答的部分截图

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)