Nature 子刊 | 还在让PINN死记硬背方程?Ψ-NN引入知识蒸馏,自动解锁物理网络结构
在地球科学、材料科学、流体力学等诸多领域,偏微分方程(PDEs)是我们描述复杂物理系统演化的核心工具。近年来,物理启发神经网络(PINNs)作为一种将数据与物理先验相融合的深度学习方法,在科学建模中大放异彩。
然而,PINNs 真的完美吗?大部分现有的 PINN 模型只是通过在“损失函数”中加入物理惩罚项来迫使网络学习物理规律。这就好比用外部的规章制度去约束一个人,虽然有效,但这种“软约束”很难保证模型的预测能严格遵守底层的物理守恒定律。
有没有办法让神经网络从内部结构上就天然契合物理规律?
最近,发表在 Nature Communications 上的一篇最新研究提出了一种基于物理启发蒸馏的神经网络结构发现方法——Ψ-NN(Physics structure-informed neural network)。它不仅能自动提取具有物理意义的网络结构,还能大幅提升模型的精度和泛化能力。

- 论文标题:Automatic network structure discovery of physics informed neural networks via knowledge distillation
- 论文链接:https://www.nature.com/articles/s41467-025-64624-3
- 代码链接:github.com/ZitiLiu/Psi-NN
痛点:当正则化“打架”时,如何寻找网络结构?
要想让神经网络具备特定的结构(比如对称性),传统的方法往往依赖专家凭经验手动设计,费时费力且适用面窄。
在深度学习中,提取网络结构的一个有效方法是“正则化”(Regularization)。但在 PINN 中直接加入正则化项,效果往往很差。为什么?
论文指出,这是因为PINN 对正则化项不敏感,且参数正则化引入的梯度优化方向可能会与现有的物理约束正则化发生“冲突”。这种过度的约束反而会降低 PINN 的精度。
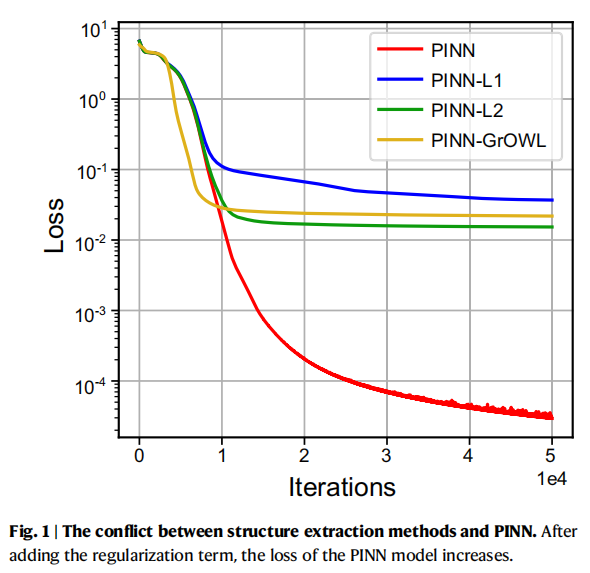
为了解决这个“神仙打架”的问题,研究团队巧妙地引入了**“知识蒸馏”(Knowledge Distillation)**的概念。
破局:Ψ-NN的“三步走”魔法
Ψ-NN 的核心思想是将物理正则化(来自控制方程)与参数正则化解耦,分别作用于“教师网络”和“学生网络”。整个算法流程(如图2所示)包含三大绝招: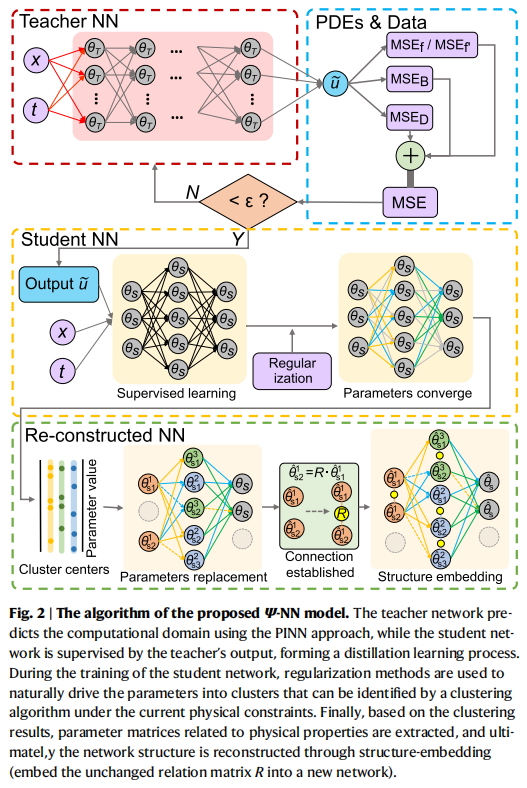
第一招:物理启发知识蒸馏 (Physics-informed Distillation)
研究人员首先用常规的 PINN 方法训练一个教师网络 (Teacher NN),让它去拟合带有物理约束的数据。接着,引入一个学生网络 (Student NN)。学生网络不需要直接面对复杂的偏微分方程,它的任务就是“抄老师的作业”——输出与教师网络一致的预测结果。
蒸馏的损失函数定义为:
MSET=1MT∑i=1MT∣uˉTi−uˉSi∣2MSE_{T}=\frac{1}{M_{T}}\sum_{i=1}^{M_{T}}|\bar{u}_{T}^{i}-\bar{u}_{S}^{i}|^{2}MSET=MT1i=1∑MT∣uˉTi−uˉSi∣2
其中 uˉT\bar{u}_{T}uˉT 和 uˉS\bar{u}_{S}uˉS 分别是教师和学生网络的输出[cite: 1]。
与此同时,只在学生网络上施加 L2 正则化:
Ω(θS)=∑l=1Lωl∣∣θl∣∣22\Omega(\theta_{S})=\sum_{l=1}^{L}\omega_{l}||\theta_{l}||_{2}^{2}Ω(θS)=l=1∑Lωl∣∣θl∣∣22
这样一来,高阶导数带来的物理学习负担交给了老师,而学生网络则可以专心在正则化的引导下,让参数逐渐靠拢,形成特定的结构。
第二招:网络结构提取 (Structure Extraction)
在正则化的作用下,学生网络中作用相似的参数会逐渐趋于一致(收敛)。团队采用层次凝聚聚类(HAC)算法,对各层权重的绝对值进行聚类。
在这个过程中,原本杂乱无章的参数被提取成了具有物理意义的“低秩参数矩阵”。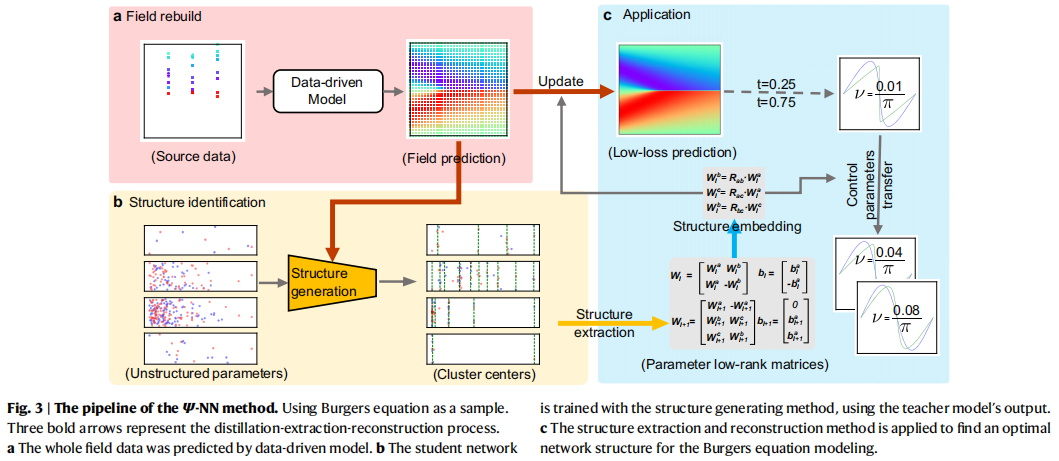
第三招:结构化网络重构 (Network Reconstruction)
提取出矩阵后,最神奇的一步来了。团队构建了一个关系矩阵 RRR,用来存储网络参数之间的关系(比如符号相反、参数共享或位置交换)。利用这个关系矩阵对网络进行重构,比如在 Laplace 方程案例中,某一层提取出的权重矩阵 W2W_{2}W2 变成了这样:
W2=[−W2a−W2bW2bW2a]W_{2}=\begin{bmatrix}-W_{2}^{a} & -W_{2}^{b} \\ W_{2}^{b} & W_{2}^{a}\end{bmatrix}W2=[−W2aW2b−W2bW2a]
这种结构在数学上直接将物理场中的空间对称性(如奇偶对称)“刻在了DNA里”,不仅减少了冗余参数,还让网络获得了强大的物理一致性。
实战表现:降维打击般的精度提升
为了验证 Ψ-NN 的威力,研究团队在多个经典的偏微分方程上进行了测试。
1. 精度更高,收敛更快 (Laplace 与 Burgers 方程)
在 Laplace 方程的稳态求解中,常规的 PINN 在训练中无法保持一致的对称性。而带有结构约束的 Ψ-NN 大大缩小了搜索空间,使得其在达到相同损失量级时,迭代次数减少了约 50%,全场 L2 误差相较于 PINN 降低了约 95%。
在描述非线性波动的 Burgers 方程中(参见论文图4:数值结果对比),面对激波形成后造成的强非对称性,传统模型误差极大,而 Ψ-NN 依然能够保持稳定的物理对称结构,获得了最低的误差。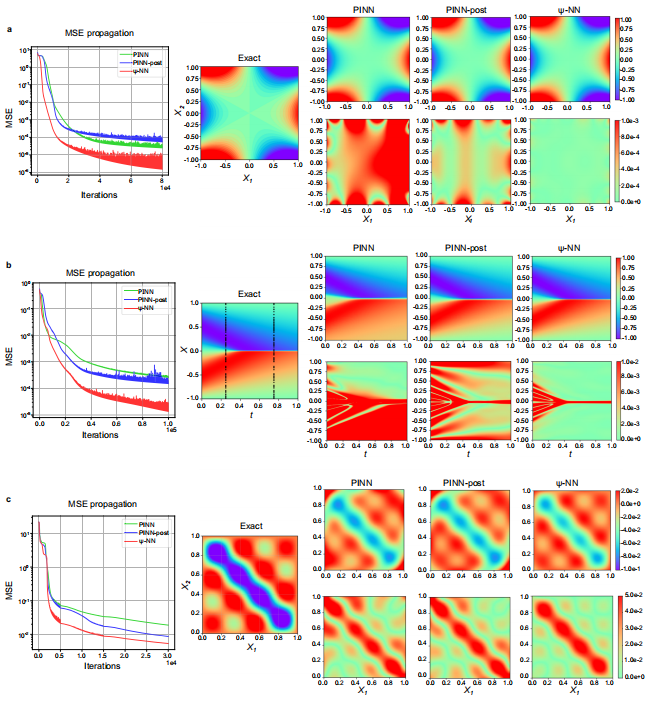
2. 强大的泛化与迁移能力 (流体力学测试)
在更复杂的圆柱绕流(二维不可压缩层流)测试中,流场同时包含了两种截然相反的对称性。使用之前在 Laplace 或 Burgers 方程中重构出的网络结构直接迁移到这里,Ψ-NN 在圆柱周围的拟合速度和精度上依然碾压了传统模型。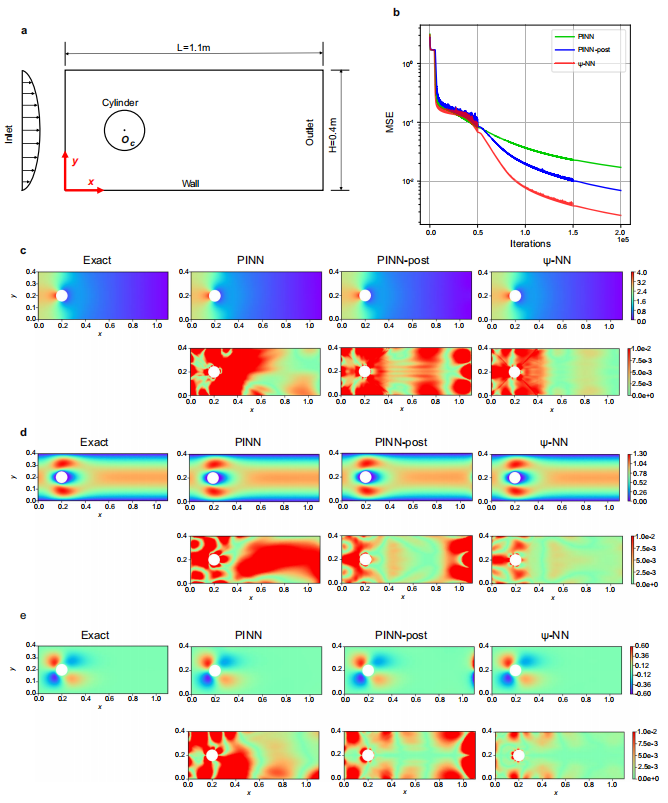
总结
如果说传统的 PINN 是一个努力死记硬背物理定律的学生,那么 Ψ-NN 则是通过“知识蒸馏与结构重构”,直接把物理定律变成了自己大脑皮层的回路。
Ψ-NN 框架通过解耦物理约束与参数正则化,实现了:
- 内在结构化:模型输出天然满足物理规律。
- 强可解释性:子矩阵组合揭示了底层特征关系。
- 高参数效率:参数共享机制降低了复杂度。
这为“AI for Science”提供了一个全新的视角——从过去的人工设计网络,走向基于数据的物理神经网络结构自动发现。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)