通过自蒸馏的Reinforcement Learning
Abstract
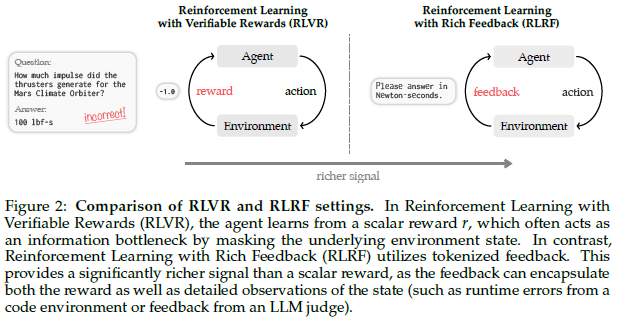
大型语言模型正越来越多地通过强化学习在可验证领域(如代码和数学)进行后训练。然而,当前基于可验证奖励的强化学习方法(RLVR)仅依赖每次尝试的标量结果奖励进行学习,这导致了严重的信用分配问题(credit assignment bottleneck)。
实际上,许多可验证环境能够提供丰富的文本反馈,例如运行时错误或评审打分,这些信息能够解释一次尝试为何失败。本文将这一情境形式化为一种带有丰富反馈的强化学习问题,并提出了**自蒸馏策略优化(Self-Distillation Policy Optimization, SDPO)**方法。该方法能够将标记化(tokenized)的反馈转化为密集的学习信号,而无需外部教师模型或显式奖励模型。
SDPO 将当前模型视为一个基于反馈进行条件化的“自教师”,并将其基于反馈的下一个 token 预测蒸馏回策略中。通过这种方式,SDPO 利用模型在上下文中回溯性识别自身错误的能力。
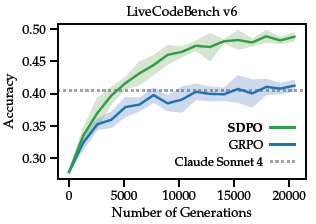
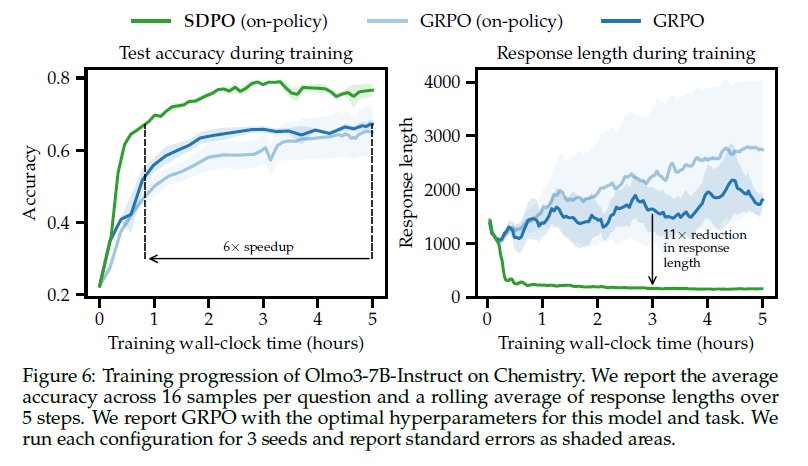
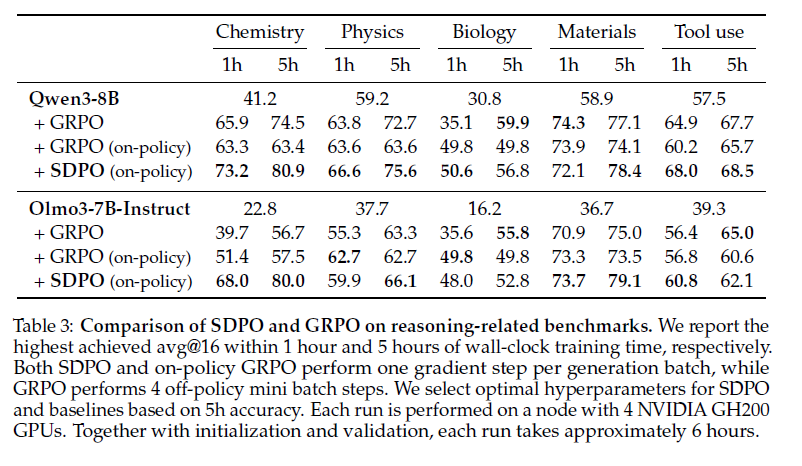
在 LiveCodeBench v6 上的科学推理、工具使用和竞赛编程任务中,SDPO 相比强基线 RLVR 方法,在样本效率和最终准确率上均有提升。值得注意的是,在仅返回标量反馈的标准 RLVR 环境中,SDPO 也通过将成功 rollout 作为失败尝试的隐式反馈,超越了基线方法。
最后,在测试阶段将 SDPO 应用于个体问题,可以加速在困难二元奖励任务中的探索过程,在达到与 best-of-k 采样或多轮对话相同发现概率的同时,将尝试次数减少至原来的三分之一。
Method


现在很多 reasoning / code / math 的 RL,都是 RLVR(Reinforcement Learning with Verifiable Rewards)范式。
也就是模型做一道题,环境最后只给一个标量 reward,比如:
对了:+1 / 错了:0 或 -1
问题在于,这种信号太粗了。还真是,粒度太粗了
模型只知道“这次错了”,却不知道:错在哪一步/应该怎么改/哪些 token / 哪段推理有问题
论文把这个问题叫做 credit assignment bottleneck,也就是信用分配困难。
因为一个完整回答里,真正错的可能只是一小段,但你最后只拿到一个总分。
环境给的不再只是一个数,而是一段tokenized feedback。
这篇论文最核心的想法:
让模型看到“自己之前的错误回答 + 环境反馈”,然后让模型重新评估那个错误回答中每个 token 的好坏,用自己当老师教自己。
这就是它叫 Self-Distillation Policy Optimization 的原因。
framework
论文里 student 和 self-teacher 其实是同一个模型,但扮演两个角色。
第一步:student 先做题
给问题 x,当前策略 πθ 生成回答 y。
比如图里例子:
Question
“写一个 python 函数,返回 1 到 n 的所有数字,简短回答。”
student 输出:
def numbers_up_to(n):
return list(range(1, n))
这个答案错了,因为没包含 n。
第二步:环境给反馈
环境返回反馈 f:
“Don’t include n.”
这里图里是一个简化例子,论文的意思是:环境会给出某种文本反馈,指出问题所在。
第三步:让同一个模型变成 self-teacher
现在重新把下面这些一起喂给模型:
1) 问题 x 2)原回答 y 3)环境反馈 f
构成一个 prompt,类似:
原题是什么?你之前回答了什么?环境反馈是什么?现在请重新评估原回答 / 正确解决原问题
这样模型就站在“事后诸葛亮”视角上看自己之前的回答。
这时模型会形成一个新的条件分布:
πθ(⋅∣x,f)
或者更细一点,是论文里写的:
πθ(⋅∣x,f,y<t)
意思是在看到了反馈之后,这个模型觉得第 t 个 token 本来应该多大概率出现?
student 学什么
student 原来的回答分布是:πθ(⋅∣x)
teacher 的回答分布是: πθ(⋅∣x,f)
SDPO的目标就是:让 student 去靠近 teacher。
也就是:原来没看反馈时的策略,去模仿“看过反馈后的自己”。
所以它本质上是一种 self-distillation。
Mathematical Explanation
loss
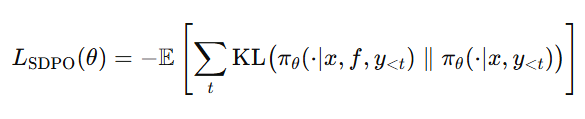
advantage
GRPO 的 advantage 大概是:
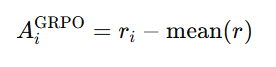
也就是按 sample-level reward 算。
而 SDPO 的 token-level advantage 是:
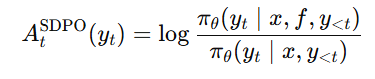
它表示:
-
如果某个 token 在 teacher 看来比 student 更合理,advantage 就是正的
-
如果某个 token 在 teacher 看来更不合理,advantage 就是负的
-
如果 teacher 和 student 觉得差不多,那这个 token 的 advantage 接近 0
所以 SDPO 相当于是把粗粒度 reward 拆成了逐 token 的 dense signal。
why works?
模型其实具备一种能力:事后看到反馈后,能意识到自己哪里错了。也就是说,模型虽然第一次直接答题可能错,但如果你告诉它:
-
你刚刚答了什么
-
环境怎么评价你
-
错误具体体现在哪
它往往能比第一次更清楚地知道“原来这一段不对”。
这就像:
-
第一次答题时是“现场作答”
-
第二次看反馈时是“带答案解析回看”
第二种状态下,模型对 token 的判断更准确。
于是作者把这种“带反馈的 hindsight 判断”提炼出来,反过来训练前面的策略。
工程改进
9.1 teacher 用 EMA 更新
不是直接拿当前 student 当 teacher,而是用 EMA teacher。
这样 teacher 更平滑,不会跟 student 一起乱跳。
9.2 用对称 Jensen-Shannon divergence
而不是直接用单边 distillation loss。
这样更稳。
Result

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)