训练大模型,你真的选对 GPU 了吗?A/H/B系列(100,800)的区别与选择
从 A100 到 B200,从 H800 到 H20——一篇写给工程师和研究者的多模态微调 & RFT 选卡指南。
1. 推理和训练,到底差在哪?
RTX 4090 跑推理飞快,但一到训练就哑火——这不是偶然,而是两种任务的物理需求完全不同。
做推理时,模型权重只需要加载一次到 GPU 显存里,然后反复使用。一张 GPU 就能独立工作,最大的瓶颈是"一次能放多少权重"(显存大小)和"一秒能算多少 token"(计算吞吐)。RTX 4090 有 24GB 显存,峰值算力高,做推理的性价比极高。
但训练完全是另一回事。
类比: 把训练想象成一个大型合唱团的排练——每个声部(GPU)唱完一段后,必须跟所有人对齐,哪里跑调了大家一起纠正,然后才能继续唱下一段。这个"对齐"的过程,就是梯度同步。合唱团人越多、同步越频繁,对"通讯线路"的要求就越高。
训练有三个推理没有的特殊挑战:
① 梯度同步
每训练一步,所有 GPU 都要把各自算出的"修正量"(梯度)汇总后广播给所有人。一个 70B 参数的模型,光是 BF16 格式的梯度就有 140GB——必须在每一步结束前传完,否则 GPU 就闲着等通信。
② 多卡并行
大模型根本塞不进一张卡。工程师会把模型切成几段(流水线并行)或把每层横向切开(张量并行),分布到多张卡上。卡和卡之间需要频繁交换中间计算结果(激活值)。
③ 长序列训练
多模态训练(图+文、视频+文)的输入序列动辄 8k 到 128k token,中间产生的激活值会把显存撑爆,必须再拆开分到多卡处理——这又是一轮卡间通信。
核心结论:训练的瓶颈不是"单卡算多快",而是"多卡之间传数据有多快"。这就是为什么 A/H 系列专业卡对训练更好的根本原因。
2. 三代架构:Ampere → Hopper → Blackwell
NVIDIA 的数据中心 GPU 分三代,每代都有质的跳跃。
说之前我吗先讨论一个问题算力到底是什么?
算力(Compute / FLOPS)本质上是 GPU 每秒能完成多少次浮点数乘加运算。单位是 FLOPS(Floating Point Operations Per Second),训练大模型常用 TFLOPS(万亿次/秒)或 PFLOPS(千万亿次/秒)。
A100 / A800(Ampere 架构,2020)
| 指标 | 数值 |
|---|---|
| 显存 | 80GB HBM2e |
| 显存带宽 | 2.0 TB/s |
| BF16 算力 | 312 TFLOPS |
| NVLink 带宽(A100) | 600 GB/s ✅ |
| NVLink 带宽(A800) | 400 GB/s ⚠️(砍了 33%) |
A100 是上一代训练主力,80GB 显存可以放下 34B 以下的模型(混合精度),微调 7B–34B 模型的性价比王者。
A800 是出口管制版,NVLink 砍了三分之一。单节点 8 卡训练差别不大,但大集群训练时通信会成为瓶颈。
H100 / H800(Hopper 架构,2022)
| 指标 | 数值 |
|---|---|
| 显存 | 80GB HBM3 |
| 显存带宽 | 3.35 TB/s |
| BF16 算力 | 989 TFLOPS |
| NVLink 带宽(H100) | 900 GB/s |
| NVLink 带宽(H800) | 400 GB/s |
相比 A100,H100 有三个关键升级:
- HBM 带宽从 2.0 → 3.35 TB/s
- BF16 算力接近翻倍(稀疏下约 3.9×)
- 引入 Transformer Engine,FP8 混合精度可再提升 1.5–2×
H100 是当前大规模分布式训练的首选,也是 70B 多模态全量微调和大规模 RFT 的主流选择。
H800 是出口管制版,计算和显存带宽完整。DeepSeek-R1 就用这个集群训练的,但代价是写出了极其精细的并行策略代码。
H20(Hopper 特供版)
| 指标 | 数值 |
|---|---|
| 显存 | 96GB HBM3(比 H100 还大) |
| 显存带宽 | 4.0 TB/s |
| BF16 算力 | 74 TFLOPS |
| NVLink 带宽 | 900 GB/s(完整) |
H20 是个奇特的产品——显存最大、NVLink 完整,但算力只有 H100 的 1/13。本质是一张大显存推理卡,适合跑 70B 以内模型的推理,不适合训练。
B200(Blackwell 架构,2024)
| 指标 | 数值 |
|---|---|
| 显存 | 192GB HBM3e(翻倍!) |
| 显存带宽 | 8.0 TB/s |
| BF16 算力 | 4.5 PFLOPS(约 4.5× H100) |
| NVLink 带宽 | 1800 GB/s |
B200 是质的跨越。单卡 192GB 显存可以放下更大的模型,减少了流水线并行的需求,从而降低通信开销。对于超大多模态模型训练和 RFT,B200 是下一代主力。
3. 那条被砍掉的"高速公路":NVLink 的秘密
你可能注意到,A800 和 H800 的计算能力、显存带宽和原版完全一样,只有 NVLink 被砍了。为什么这一项这么重要?
类比: 把每张 GPU 想象成一个工厂。HBM 带宽是工厂内部的传送带速度,决定工厂自己的生产效率。NVLink 则是工厂之间的高速公路——当你有 8 个工厂要协同生产一件超大产品时,工厂间运货的速度就决定了整体进度。公路砍成一半宽度,工厂再高效也没用。
4. 出口版
| 型号 | 被砍的部分 | 没动的部分 | 实际影响 |
|---|---|---|---|
| A800 | NVLink 带宽(-33%) | 计算、HBM 带宽完整 | 单节点影响小,大集群明显 |
| H800 | NVLink 带宽(-56%) | 计算、HBM 带宽完整 | 节点内尚可,跨节点严重 |
| H20 | 算力 (-93%) | HBM 带宽、NVLink 完整 | 不适合训练,只能做推理 |
⚠️ 很多人看到 H20 有 96GB 显存、完整的 NVLink,以为它是训练好卡——但它的 BF16 算力只有 74 TFLOPS,仅为 H100 的 1/13。本质上是一张大显存推理卡,用来跑训练会非常慢。
H800 的情况更微妙。DeepSeek 团队用 H800 集群训练了 DeepSeek-R1,他们的解法是:用极其精细的流水线并行策略,把大部分通信压缩在节点内完成,减少对跨节点 NVLink 的依赖。这需要很深的系统级工程能力,不是每个团队都能轻易复现的。
5. 多模态微调 & RFT 怎么选卡?
场景 A:7B–13B 多模态 LoRA / SFT 微调
| 维度 | 情况 |
|---|---|
| 显存需求 | 40–80GB,LoRA 更低 |
| 序列长度 | 4k–32k token |
| 并行方式 | 数据并行为主,1–2 节点 |
| NVLink 重要性 | 中等,不是瓶颈 |
推荐:A100 / A800
这个规模 A100/A800 性价比最优,升级到 H100 提升有限但成本翻倍。
场景 B:34B–70B 多模态全参微调(图文 / 视频)
| 维度 | 情况 |
|---|---|
| 显存需求 | 需要 4–16 张 80GB 卡 |
| 序列长度 | 8k–64k(视频更长) |
| 并行方式 | TP + PP + 序列并行混合 |
| NVLink 重要性 | ⚠️ 高,直接影响实际效率 |
推荐:H100 SXM 首选,H800 SXM 次选(节点内)
此规模 NVLink 带宽成为关键瓶颈,H800 在多节点时劣势明显。
场景 C:RFT / GRPO / PPO 强化微调(长思维链)
| 维度 | 情况 |
|---|---|
| 显存需求 | 需同时放 actor + reference model |
| 序列长度 | 8k–32k(长推理链) |
| 特殊挑战 | rollout 推理 + 反向传播交替进行 |
| 显存压力 | 远大于普通 SFT |
推荐:H100 实用最优;B200 更优(显存够大可同卡放 actor + ref)
B200 的 192GB 显存可以把 actor 和 reference model 放同一批卡,大幅简化异步通信架构。
场景 D:100B+ 超大多模态模型 / 预训练
| 维度 | 情况 |
|---|---|
| 显存需求 | 需要大量 80GB 卡或 B200 |
| 序列长度 | 32k–256k(视频理解) |
| 并行方式 | 4D 并行(DP+TP+PP+SP) |
| B200 优势 | 192GB 显存减少 PP 层数,降低 bubble ratio |
推荐:B200 SXM 或大量 H100
B200 单卡显存翻倍意味着流水线并行的气泡比例(bubble ratio)大幅降低,整体训练效率更高。
6. 工程师容易忽略的四个细节
① Transformer Engine 和 FP8 训练
H100 引入了 Transformer Engine,支持 FP8 混合精度训练。在 Megatron-LM 或 NeMo 框架里开启后,实际训练吞吐可以再提升 30–50%。A100 没有这个路径,只能用 BF16。B200 进一步支持 FP4,理论上还能翻倍,但框架成熟度还需要时间。
💡 实用建议: 如果你用 H100 做训练,一定要确认框架是否开启了 FP8。很多人买了 H100 却用 BF16 跑,相当于买了跑车开着限速 60。
② MFU 才是真实效率指标
看 GPU 规格时,我们总盯着峰值算力(TFLOPS)。但实际训练中,卡经常在等通信而不是在算数。MFU(Model FLOP Utilization,模型算力利用率) 才是真正的效率指标。
H100 集群的实际 MFU 通常只有 40–55%,剩余时间在等 all-reduce 通信完成。NVLink 带宽是影响 MFU 的核心变量之一,这正是 H800 在大集群里吃亏的地方。
③ RFT 是推理 + 训练的叠加
做 GRPO / PPO 类的 RFT 时,每个训练步需要:
- Rollout 阶段(推理):用当前策略生成多个答案,需要高 HBM 带宽和大 KV cache
- 反向传播阶段(训练):计算梯度并更新参数,需要高 NVLink 带宽
两个阶段对 GPU 的要求刚好相反,而且你需要在显存里同时保留当前策略(actor)和参考策略(reference model)。这意味着 RFT 的显存压力比普通 SFT 大得多。
④ 跨节点通信走 InfiniBand,不走 NVLink
NVLink 只连接同一台机器内的 GPU。多台服务器之间的通信走 InfiniBand(或 RoCE 以太网)。所以 H800 被砍的 NVLink 主要影响节点内的通信效率,跨节点通信取决于你的 IB 网络配置。
这也是为什么 DeepSeek 可以用 H800 集群训出好模型——他们重点优化了节点内通信,跨节点靠精细的并行切分来减少数据量。
7. 一句话总结
多模态微调选卡看 NVLink,不要只盯着显存大小和算力峰值。RFT 额外需要显存能同时放下 actor 和 ref model。
快速选卡参考表
| 你的情况 | 推荐选择 | 理由 |
|---|---|---|
| 7B–13B 微调,预算有限 | A100 / A800 | 性价比最优,NVLink 不是瓶颈 |
| 70B 全参微调,海外资源 | H100 SXM | NVLink 完整,FP8 可用 |
| 70B 全参微调,国内资源 | H800 SXM | 需精细并行策略绕开 NVLink 限制 |
| RFT / GRPO 强化微调 | H100 或 B200 | 显存要够放 actor + ref,带宽两阶段都需要 |
| 大显存推理部署 | H20 | 96GB 显存够推理用,但别拿来训练 |
| 100B+ 或下一代预训练 | B200 SXM | 192GB 显存大幅减少并行开销 |
GPU 规格随产品迭代可能变化,以 NVIDIA 官方数据为准。
附:“节点"不等于"卡”。一个节点 = 一台物理服务器,里面通常插了 8张 GPU。
所以有三个层级:
- 卡内(单张GPU内部):计算单元 ↔ 显存,走 HBM带宽
- 节点内(同一台服务器的8张卡之间):走 NVLink
- 节点间(服务器 A 的卡 ↔ 服务器 B 的卡):走 InfiniBand / 网线,NVLink 够不到
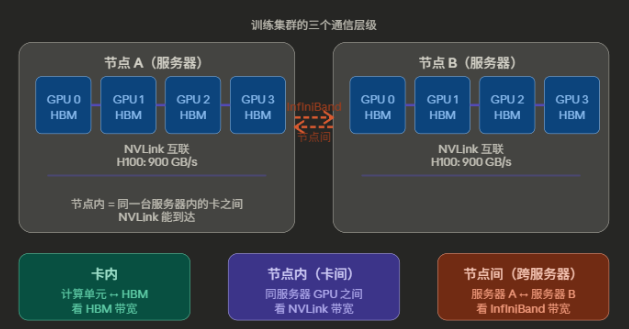
NVLink 被砍到 400 GB/s,影响的是同一台服务器内8张卡互相通信的速度。如果你只用1台服务器(8卡)训练,这个损失还能接受。但一旦跨服务器扩展到16卡、64卡,每台服务器内部的 NVLink 瓶颈会拖慢整个集群的梯度同步——因为数据先要在节点内汇聚,再走 InfiniBand 出去,节点内这段慢了,整体就卡住了。
附:什么是"含稀疏"(Sparse / Sparsity)
以看到厂商写"989 TFLOPS",心里要默认打个对折——训练场景下约 495 TFLOPS 才是更接近现实的参考基线,然后再乘以 MFU(约 40-55%)才是实际吞吐。
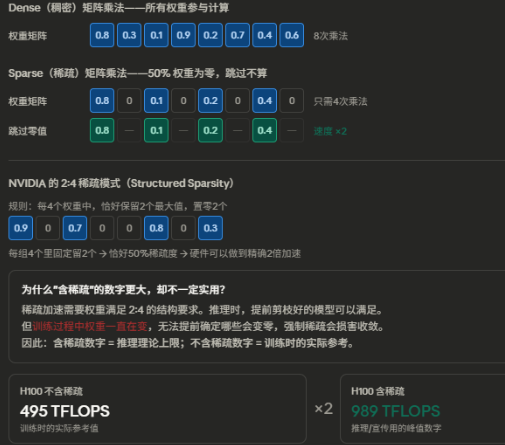
所以看到厂商写"989 TFLOPS",心里要默认打个对折——训练场景下约 495 TFLOPS 才是更接近现实的参考基线,然后再乘以 MFU(约 40-55%)才是实际吞吐。
附:NVLink 带宽 vs 显存带宽,根本区别在哪
这两个带宽解决的是完全不同的问题,用一个空间比喻来建立直觉:
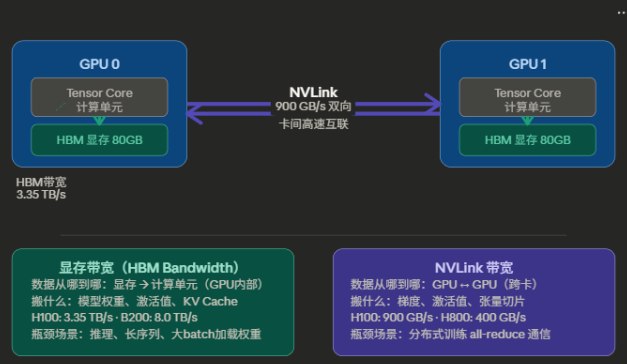
用一个更具体的类比来说:
显存带宽 是"厨师从冰箱取食材的速度"——冰箱就是 HBM 显存,厨师就是 Tensor Core。取得慢,厨师就闲着等。这个瓶颈在单卡上就会出现,推理时尤为明显(因为推理不需要算梯度,主要就是反复读权重)。
NVLink 带宽 是"两个厨房之间传递半成品的速度"——一个厨房(GPU 0)切好的食材,要通过传菜口(NVLink)传到另一个厨房(GPU 1)继续处理。传菜口窄了,两个厨房就得互相等。这个瓶颈只有在多卡协作时才出现。
附:精度理解
想象你要记录一个人的身高。
你有不同精度的量尺:
- 精度高的尺:记录 173.6482917 cm —— 非常精确,但写下来要占很多纸
- 精度低的尺:记录 174 cm —— 不那么精确,但只占一点纸
计算机存数字也是一样,精度越高,占的内存越多,计算越慢
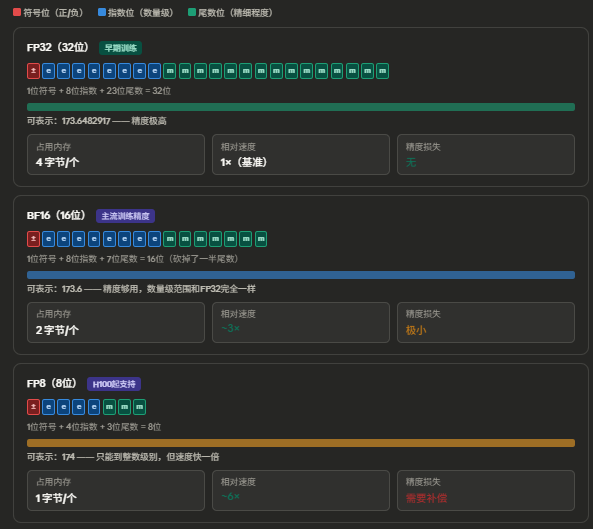
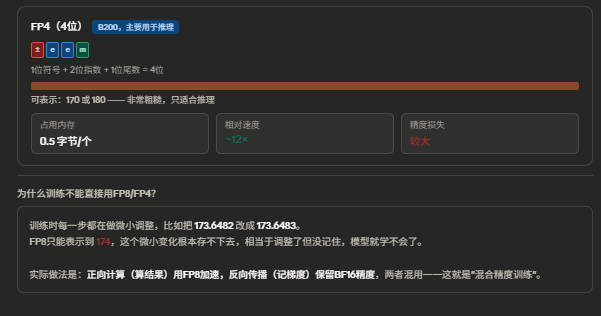
关键规律就三条:
位数越少 → 占内存越少 → 速度越快 → 但精度越粗糙。 每砍一半位数,速度大约翻倍,能塞进显存的模型大约也翻倍。
指数位决定"能表示多大的数",尾数位决定"能表示多精细"。 BF16 聪明的地方在于——它保留了和 FP32 一样多的指数位(8位),只砍了尾数。所以它能表示的数字范围和 FP32 完全一样大,只是没那么精细。这让训练过程中不容易出现数值溢出,这就是它成为训练主流精度的原因。
训练用 BF16 打底,FP8 做加速辅助;推理可以更激进,FP8 甚至 FP4 都行。 因为推理只是"用"模型,不需要记住微小变化,粗一点没关系。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)