Transformer编码器结构
无监督学习
深度学习:
生成对抗网络:生成器,判别器(模型要有特征提取能力)
自监督学习:对比学习和生成式自监督。
对比学习:把自己和自己的增广当作同一类。比如我有分辨车标之间不同的能力,我只是不知道车标对应的品牌名。
生成式自监督学习:
图片经过model1(编码器encoder)形成特征,将特征经过model2(解码器decoder)还原出原始图片,过程记为自编码器
生成式自监督学习把自己的一部分当作学习的目标,用ViT把原始图片拆成块,并将部分遮住(mask)。没遮住的部分通过编码器和解码器还原原图,而没遮住的部分就相当于标签。loss来自原始图片和还原图片之间的差距。也可以输入黑白图片,还原出原图色彩;输入一段有遮挡的文字,还原出原文。
经过encoder处理得到的特征,如果是图片则包含内容、纹理等,如果是音频则包含内容、音色等,如果是文字则包含内容、写作风格等。
可将上一张图片提取出的风格加入到下一张图提取出的内容中,比如一张河畔照片加上梵高星空风格。如何结合?可以通过卷积,比如11层卷积,前面几层的特征图都代表风格,后面几层的特征图都代表内容,就将前面的特征图拿来生成风格,后面几层特征图生成内容
无监督本质还是要为有监督服务,无标签数据经过模型(encoder)后提取出很好的特征(无监督与训练pretrain,也就是GPT中的P),加上分类头后便可以进行分类(下游任务downstream),也可以拿去做分割/目标检测/生成文字以描述图片等
为什么是“预”训练?因为与下游的分类任务没有关系
对抗生成网络(GAN):生成器(输出假数据)、判别器(输入真与假数据,判断真假)
RNN循环神经网络
用向量/记忆单元存储数据,但其中可能存在“不孝子孙”,不利于长序列
LSTM长短期记忆(Long short-term memory)
输入门、遗忘门、记忆门
RNN和LSTM都太慢,只能一代接一代(一个字一个字)
self-attention自注意力机制
输入有图片、文字、音频,而神经网络如何知道输入的是具体的哪个文字?one-hot能表示,但是太长了,且没办法表示含义,比如猫与树、“我”的距离是一样的,没办法让猫和狗距离近一些。
仍使用one-hot编码,通过全连接linear(21128,768)降维并表示含义(模型学的)
每个词都有一个输出:词性分类(代词动词);每个句子一个输出:情感分类(褒义贬义);输入输出长度不对应:翻译
句子是序列输入而不是图片输入,需要考虑前后关系:用毒蛇的毒毒毒蛇,毒蛇会不会被毒死;
Transformer:特征提取器+生成模型
self-attention的每个字输入参考了整体句子后再输出,比如4个字,第一个字应该对句子中每个字分配多少注意力,最终得到第一个字的输出(一个字的编码维度为768,字的个数可以按照128或512计算)

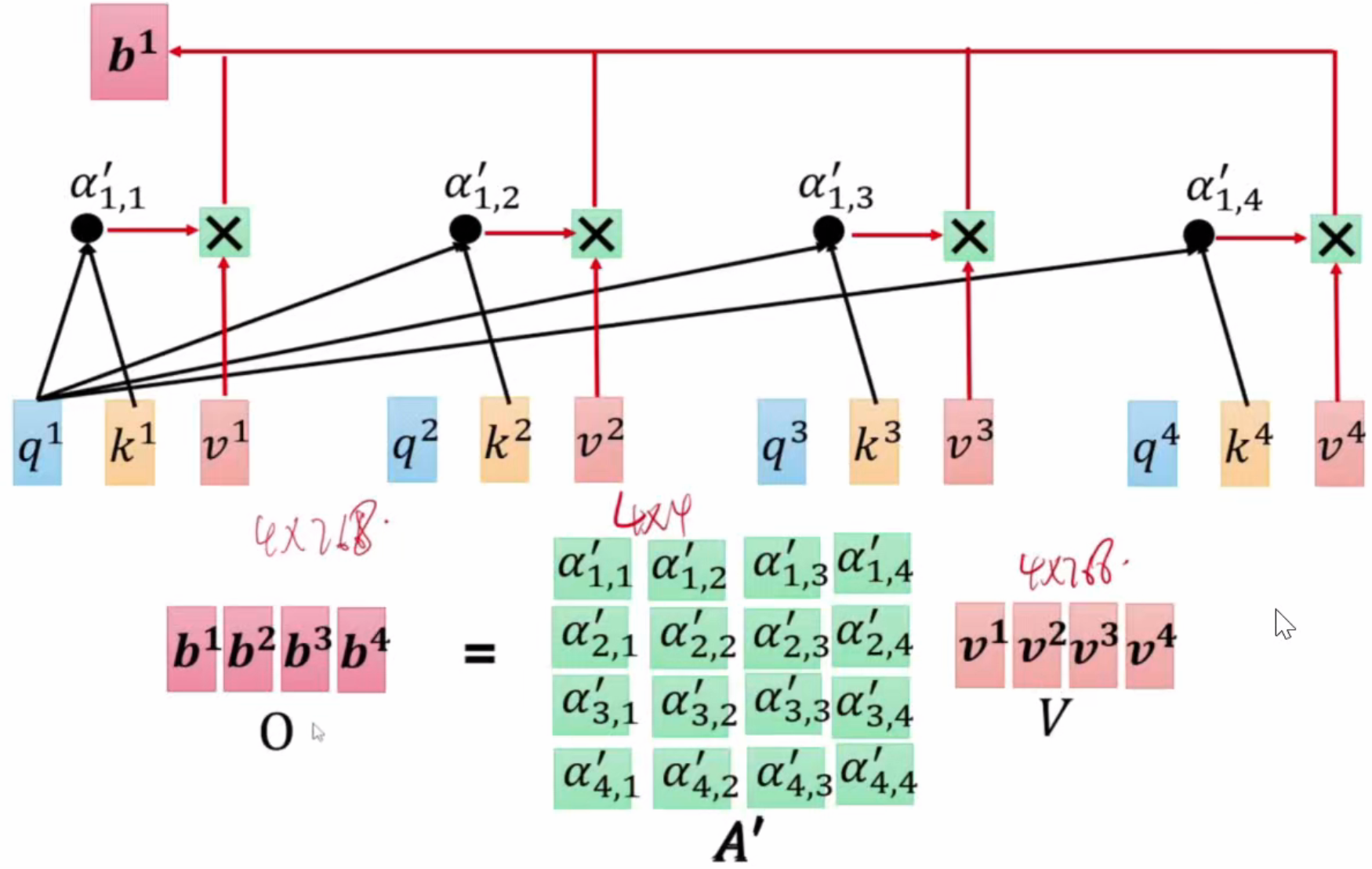
a1*Wq矩阵得到q1矩阵(query)(就像一个扫码器),a2*Wk矩阵得到k2矩阵(key)(就像一个二维码),那么第一个字对第二个字应该分配的注意力a1,2=q1*k2点乘,自己对自己的注意力也是这样得来,以此类推。得到a1对所有4个字的注意力值为a1,1、a1,2、a1,3、a1,4,经过softmax得到4个合为1的新的注意力的值,每个新的值(比如a'1,1)再各自乘上Wv矩阵(value)得到的新的值之和为b1,b1就是a1看过整个句子后得到的值。
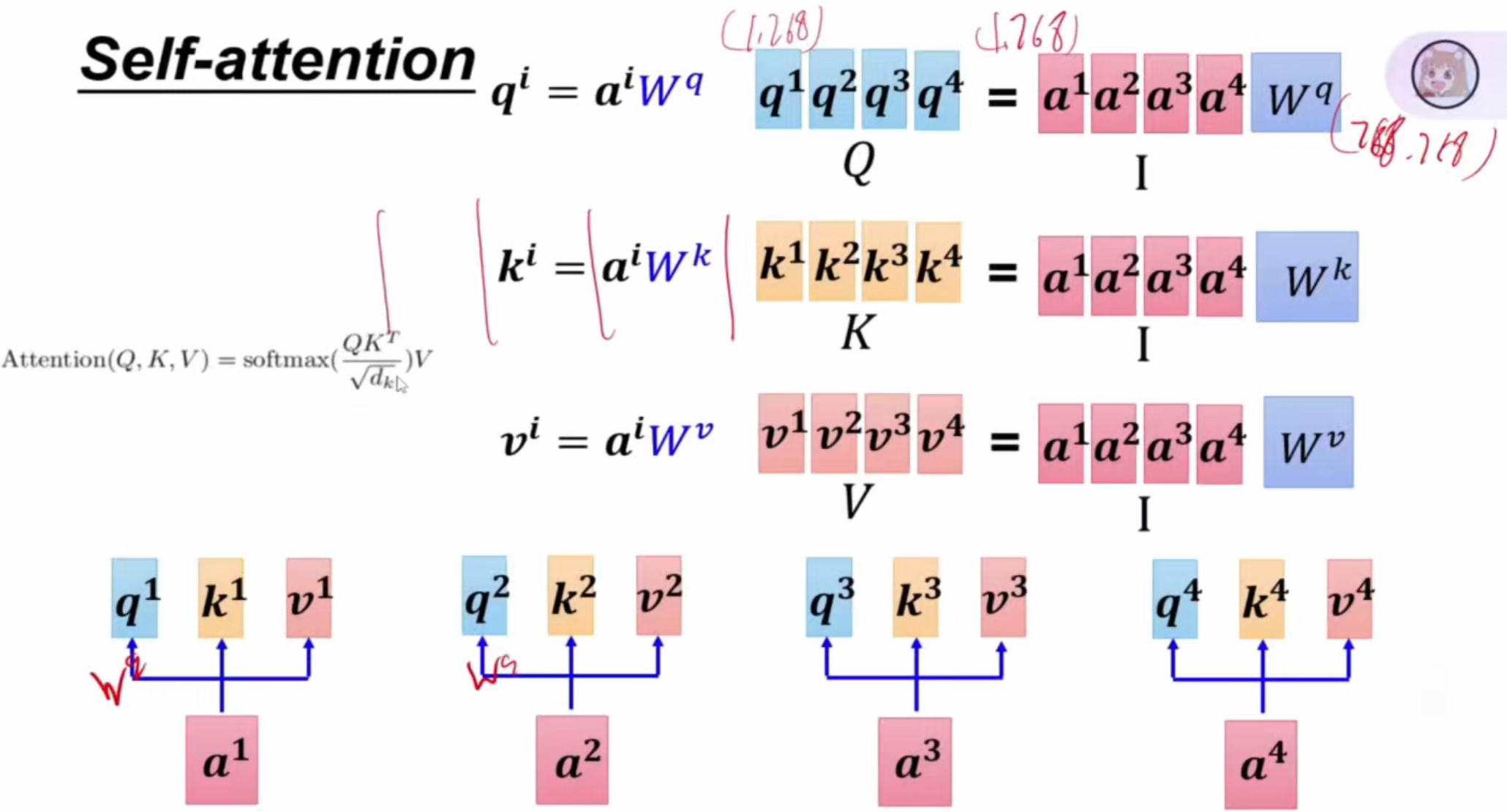
总结自注意力过程:a1通过Wq、Wk、Wv3个矩阵得到q、k、v三个值,每个q分别乘上所有k得到注意力经过softmax后再乘v得到a'1,i(i=1、2、3、4),a'1,i之和便是b1。并且每个字的特征提取都可以同步进行,因为它们不依赖前一个字产生的结果
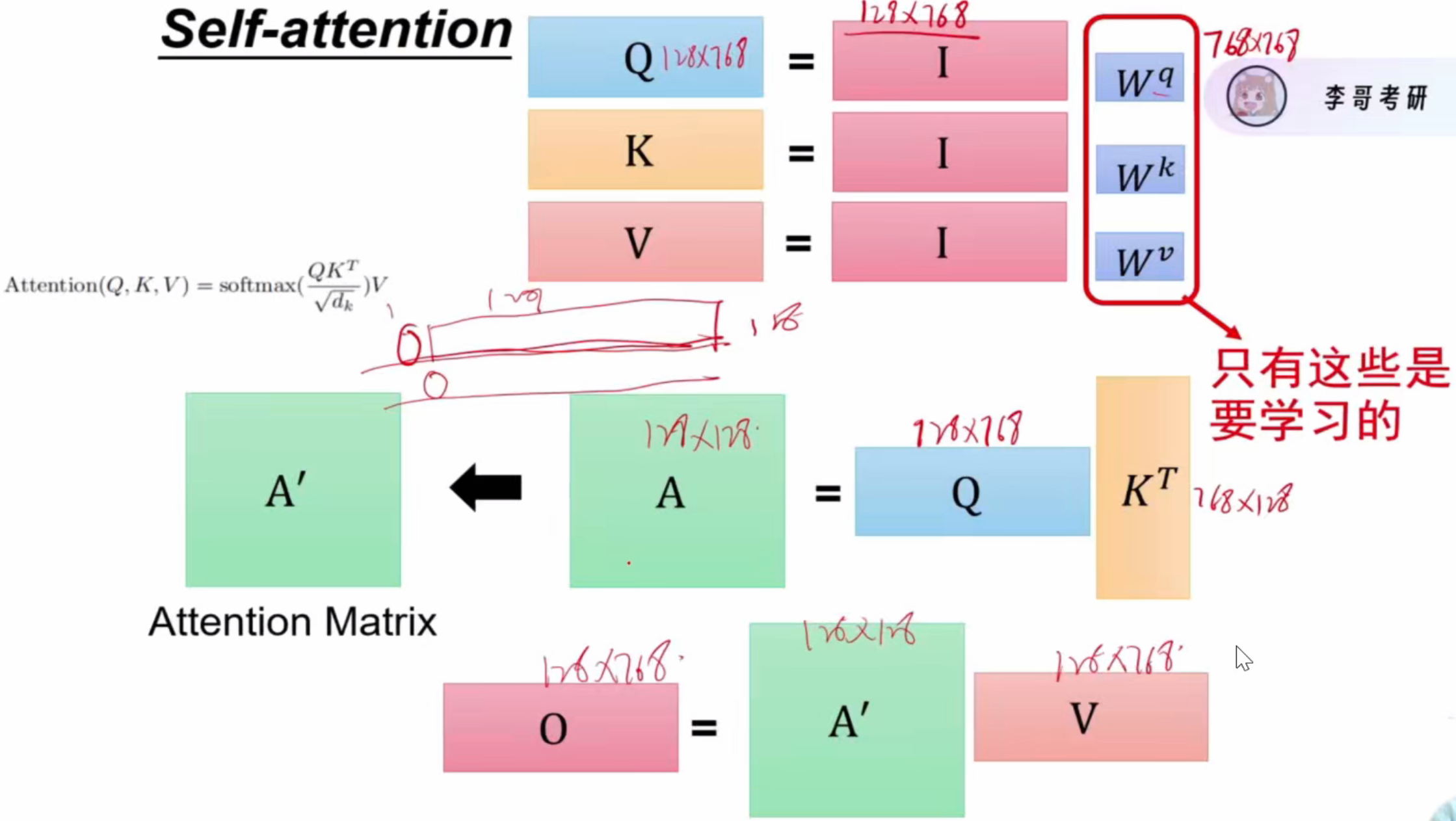
过程中Wq、Wk、Wv这3个矩阵需要学习
Transformer框架:
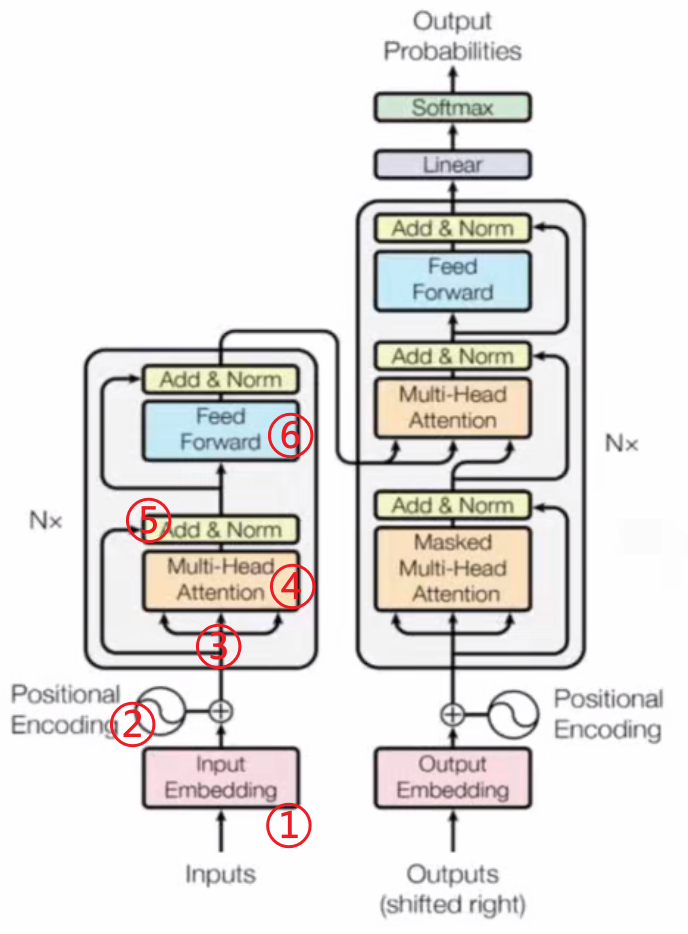
编码器Encoder:(左半边,代表:文字分类模型Bert)
①词embedding:21128个文字编码长度由one-hot得来,再Linear(21128,768)
②位置embedding:512为句子长度,再Linear(512,768),词与位置二者维度相同,直接相加得到一个token
③三个箭头分别为将输入乘Wq、Wk、Wv矩阵(均为768*768)得到的qi、ki、vi,仍是768维
④self-attention模块:多头自注意力机制。输出f(x),768维
⑤ResNet残差连接:Out=f(x)+x,让网络走得更深,输出768维
⑥MLP:两次全连接,nn.linear(768,3072)和nn.linear(3072,768),输出经残差连接后仍为768维
以上为一层,一次self-attention输出后维度不变,所以可以叠加很多层。
解码器Encoder:(右半边,代表:生成模型GPT)
Bert
预训练任务:
①Masked Language Model:MLM,一般在句子中遮住15%,在这15%中的80%是真的遮住,用[MASK]代替,10%随替换成其他词,10%不变;
②Next Sentence Prediction:给句子之间打上是否是连贯句子的标签。
结构: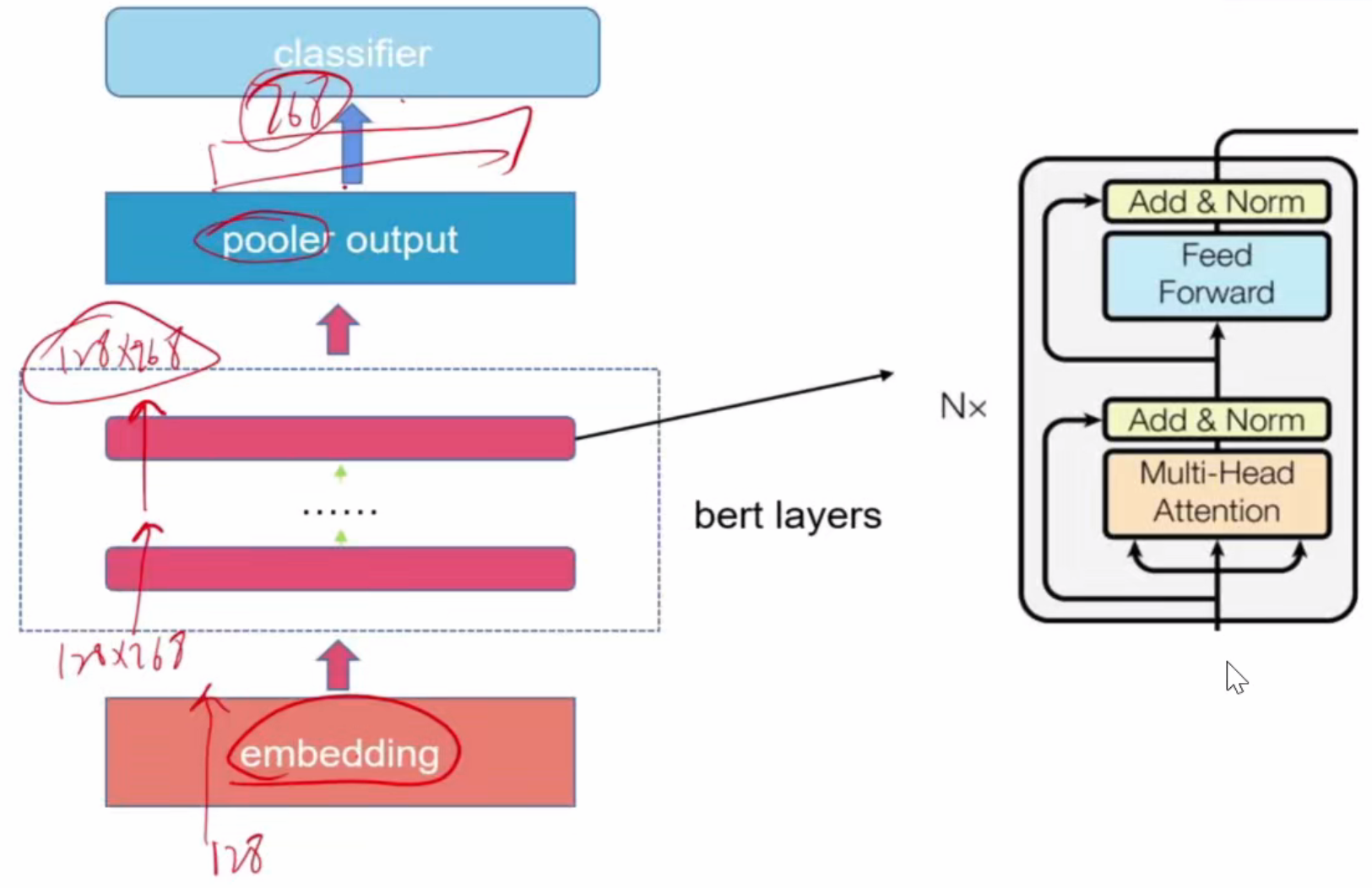
①输入:embedding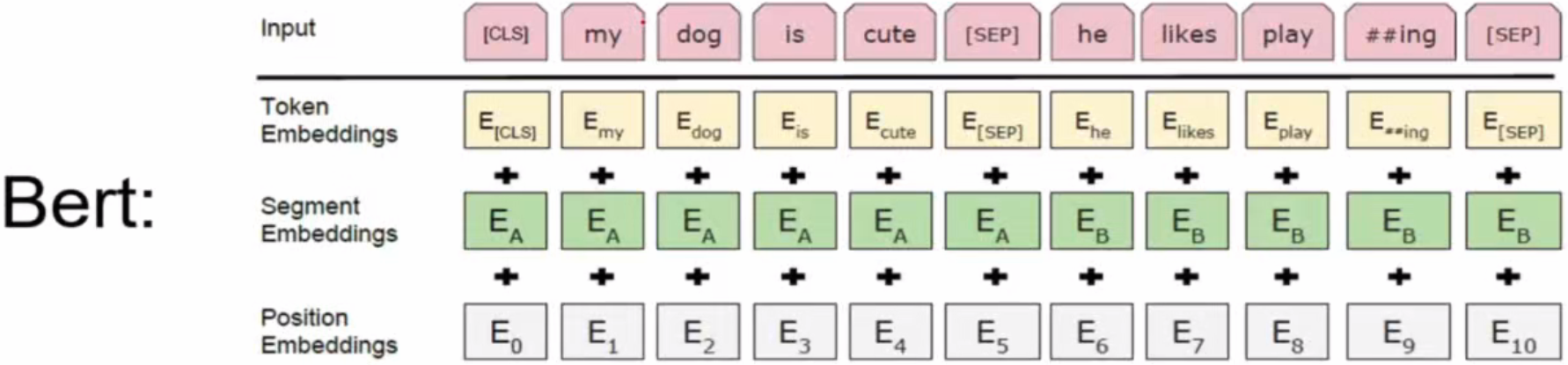
多了一个SegmentEmbedding,用于表示当前词在哪个句子中;[CLS]:可统揽全局的token,输出也是768维,可用于作句子分类,类似于链表中加了个头节点;[SEP]:表示句子间断的token。
②池化输出:pooler output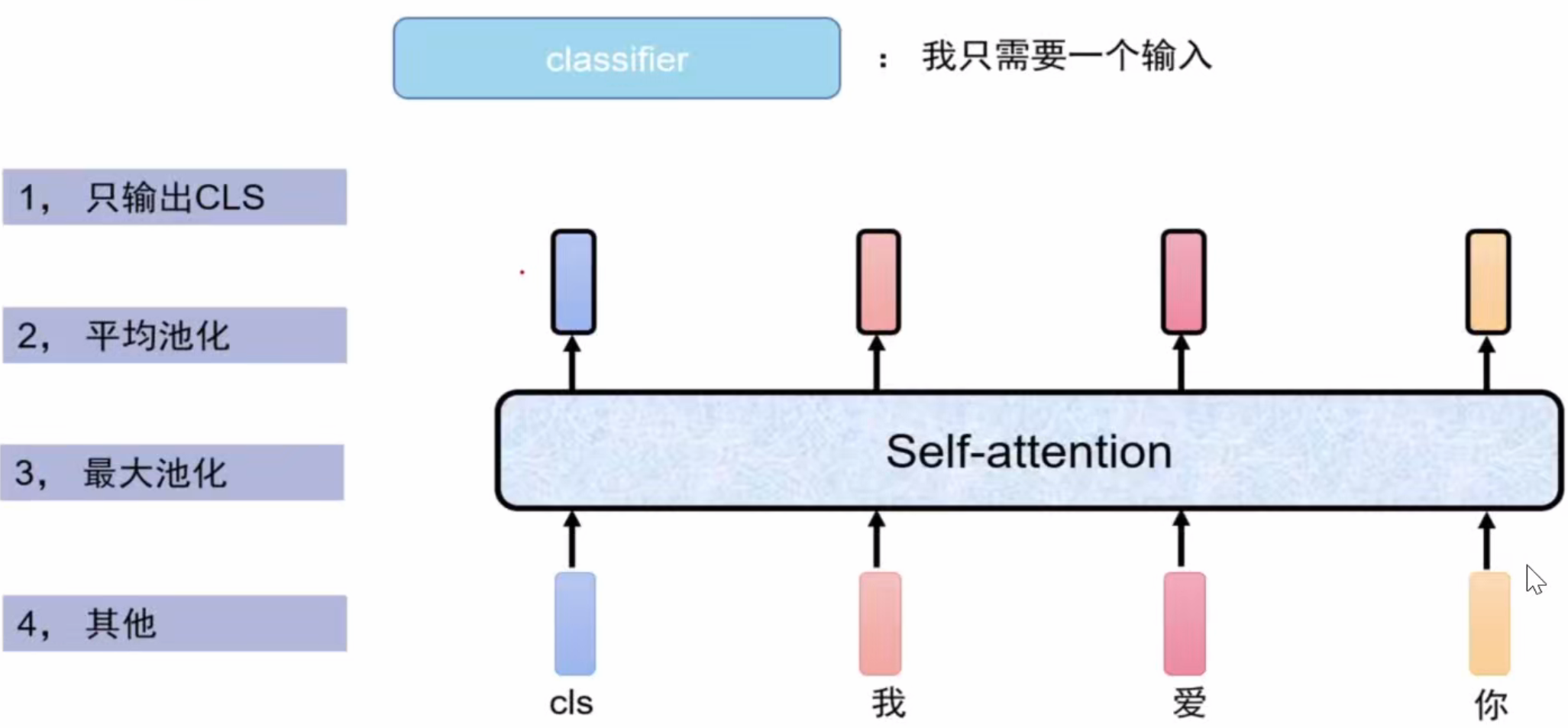
self-attention机制给了4*768的输出,但是分类器classifier只要1*768方便进行n类的分类linear(768,n),于是有上图4种降维方式,最常见的是只输出CLS。
一点总结:
①字的表示:one-hot编码后转为768维
②为了知道上下文,引入了RNN和LSTM
③RNN和LSTM不能并行,速度慢,后一个输入需要前面的输出(单向),所以引入self-attention
④self-attention,每个字加上位置的embedding构成token。与Q、K、V三个矩阵交互,Q是query,K是key,V是value。先通过Q和K算出注意力,经softmax后与V计算得到的多个值相加即为输出。
⑤bert:一个编码器,目的是把一句话编码为特征。通过自监督预训练获得特征提取能力。之后在下游任务可以提取特征后,让特征去做分类任务。
⑥bert结构:一,embedding层;二,self-attention层让特征交互;三,pooler输出。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)