从自注意力到交叉注意力:2D扩散模型向4D世界的演进
一、基础篇:三篇奠基之作
论文 1:MVDream 多视角一致性的开创者 ICLR 2024
MVDream: Multi-view Diffusion for 3D Generation
problem:
2D扩散模型通过SDS做3D生成时,存在严重的多视角不一致问题:正面看是脸,背面也是脸(Janus问题),或者内容在不同视角下逐渐漂移。

见图1:左图是一匹马在走路,结果马有两个头;右图是一盘炸鸡和华夫饼,炸鸡逐渐变成华夫饼。这两个例子直观展示了2D lifting方法的典型失败案例。
核心思想:
直接训练一个能同时生成多个视角一致图像的扩散模型,让不同视角在生成过程中互相看见、互相讨论。同时用2D和3D数据联合训练,兼顾泛化能力和多视角一致性。
关键技术:
见图2:展示了MVDream的整体架构。模型输入是多个视角的噪声潜码和对应的相机参数,经过改造后的UNet,输出多视角一致的去噪图像。这个图的核心是告诉我们:MVDream不是单图生成,而是多图联合生成。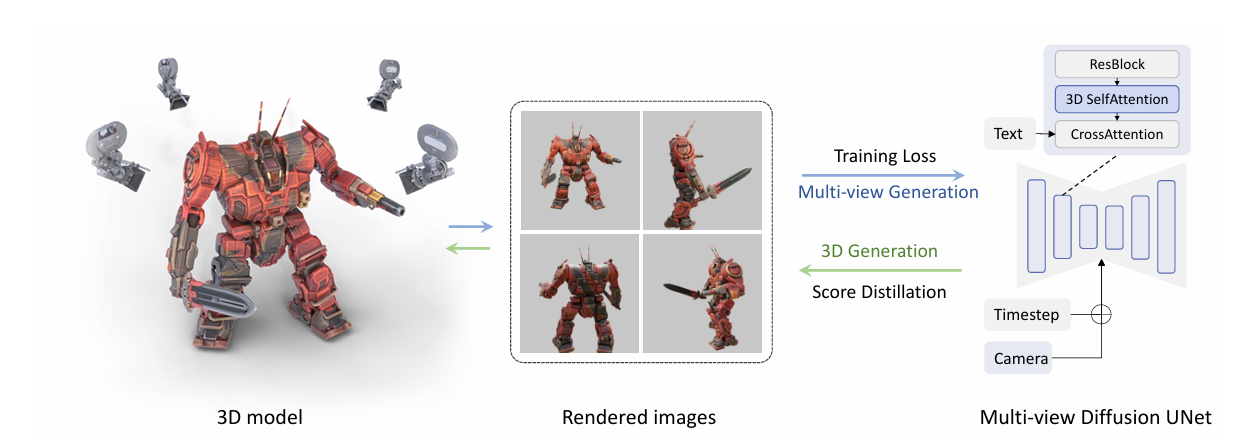
图 2:多视角扩散模型示意图。我们通过做两项小改动保持文本到图像 UNets 的结构:(1)将自注意从二维改为三维以实现交叉视角连接;(2)为每个视角添加摄像机嵌入。多视角渲染用于训练扩散模型。测试过程中,流水线的使用方式相反:多视角扩散模型作为三维,通过评分蒸馏采样(SDS)优化三维表示。
核心改造:将2D自注意力膨胀为3D跨视图注意力
-
输入形状:
[Batch, Views, Channels, Height, Width] -
在自注意力层中,将张量重塑为
[Batch, Views×H×W, Channels] -
让所有视角的所有像素块在同一个注意力空间中交互
-
权重从预训练的2D自注意力复制初始化,不是从头学
见图4:对比三种注意力方案的效果。从上到下分别是:时序注意力、新增3D注意力、膨胀2D注意力。可以看到,时序注意力仍有内容漂移(第一行),新增3D注意力质量下降(第二行),只有膨胀2D注意力既保持了质量又实现了一致性(第三行)。这个图是证明技术选择合理性的关键证据。

相机条件注入:将相机外参通过MLP编码后加到time embedding上,让模型知道每个图像对应的视角。
图 3:MVDream 的训练流水线。左:多视角扩散训练,采用两种模式:带 2D 注意力的图像模式(上方)和多视角模式(下处)带 3D 注意和相机嵌入。右侧:DreamBooth 的训练,预训练的多视角扩散模型在图像模式中进行微调,采用 2D 注意力和保存损失的图像模式。
同一场景从 F 的不同视角。训练完成后,该模型可作为多视角先验用于三维生成,采用分数蒸馏采样(SDS)等技术。
为了继承二维扩散模型的泛化性,我们希望尽可能保留其架构以便微调。然而,这类模型一次只能生成一张图像,且不接收相机条件作为输入。因此,这里的主要问题是:(1)如何从同一文本提示生成一组一致的图像(第 3.1.1 节),(2)如何添加相机姿态控制(第 3.1.2 节),以及(3)如何保持质量和泛化性(第 3.1.3 节)。
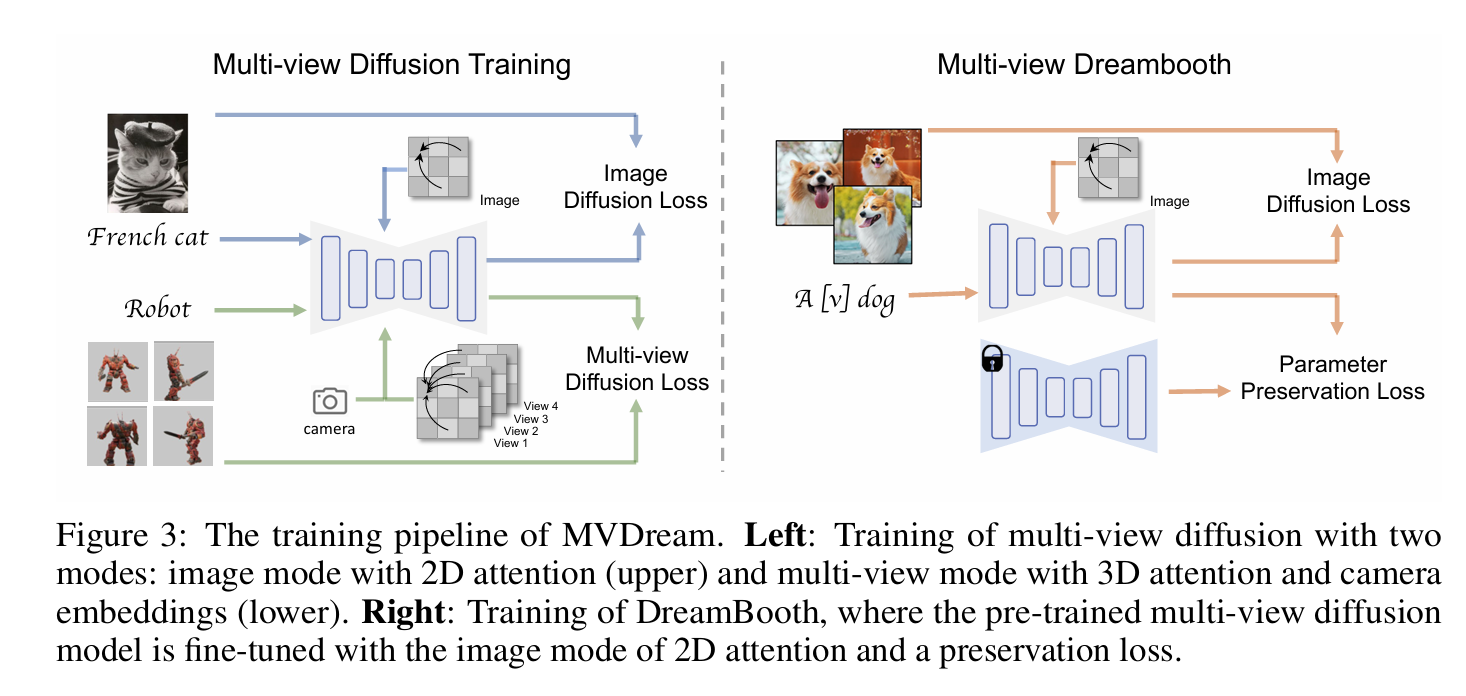
见图3:展示了训练流程。左侧是训练阶段:70%概率用3D数据(多视角+相机参数),30%概率用2D数据(单图+无相机)。右侧是DreamBooth微调流程。这个图说明了MVDream如何通过混合训练平衡一致性和泛化能力。
论文 2:Tune-A-Video时序一致性的奠基者 ICCV 2023
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
problem:
当时T2V(文本到视频)生成模型通常需要在大规模视频数据集上训练,比如WebVid-10M。这种范式虽然效果不错,但训练成本极高,需要大量GPU资源和时间。那么问题来了:能否利用现成的T2I(文本到图像)模型,只用一个文本-视频对,就让模型学会生成连贯的视频?
核心思想:
作者对预训练的T2I模型做了两个关键观察,如图2所示:

观察1(第一行):T2I模型能理解动词。给定提示“a man is running on the beach”,T2I模型能生成一个人在跑步(不是走路或跳跃)的快照。这说明模型通过跨模态注意力已经学会了静态动作的表征。
观察2(第二行):简单扩展自注意力能保持内容一致。如果把T2I模型的空间自注意力从一张图扩展到多张图,让多张图并行生成,会发现同一个物体在不同帧中保持一致,同一个男人、同一个海滩。这说明自注意力层是由空间相似性驱动的,而不是像素位置。
基于这两个观察,作者提出:只需要微调少量参数,让模型学会“连续运动”,就能把T2I模型变成T2V模型。
关键技术:
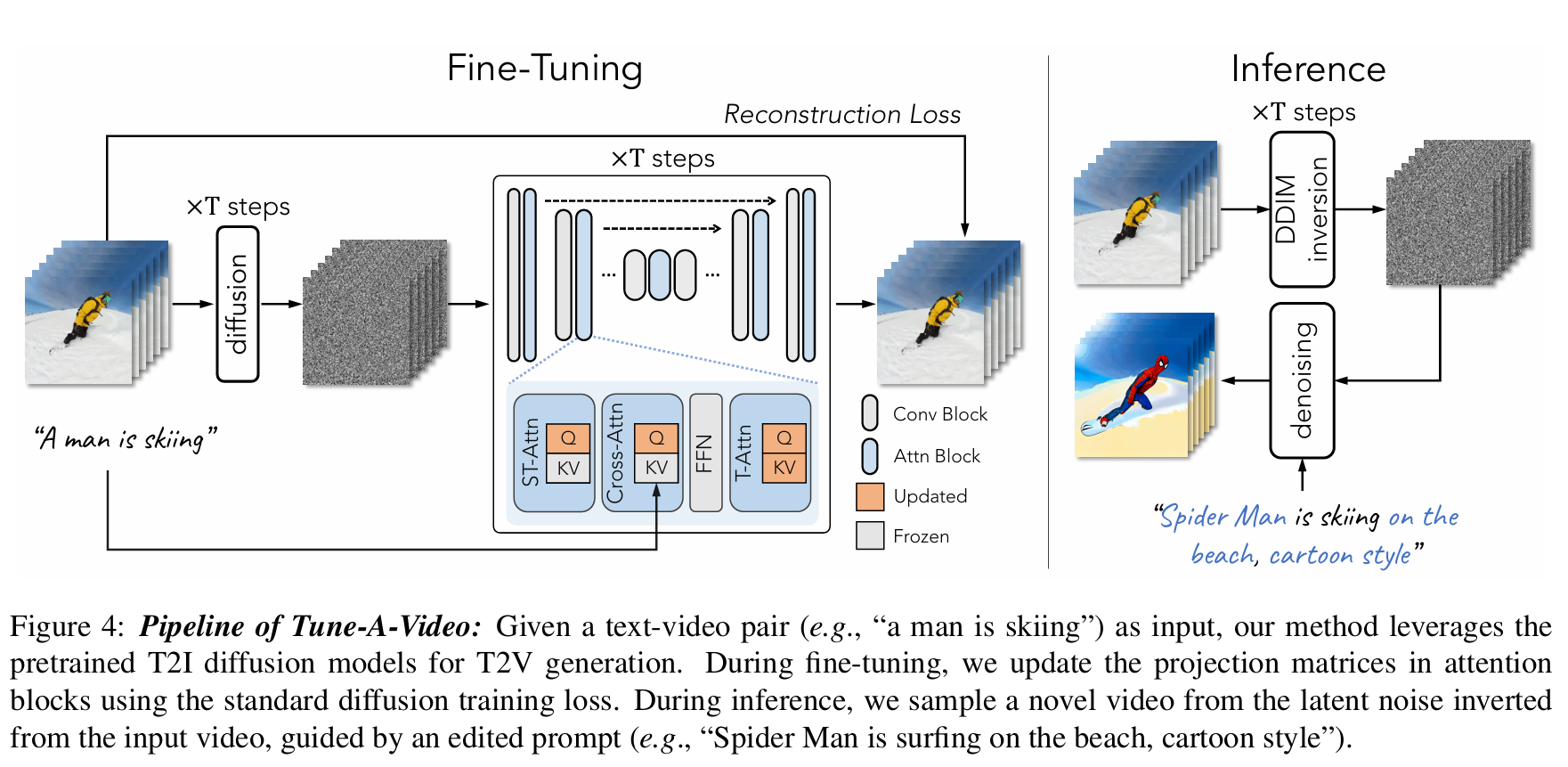
论文 3:Instruct-4DGS —— 两者的集大成者
主线一:多视角/3D生成(延续 MVDream 的思路)
论文 4:MEAT 用网格引导的高效多视角注意力 CVPR 2025
Problem:
高分辨率人体多视角生成的困境
在技术路线图中,MVDream 解决了多视角一致性问题,但它在处理高分辨率人体数据时效果不佳。原因有两个:
-
分辨率瓶颈:人体生成对细节要求极高,尤其是面部、手部、衣物等区域。如图2所示,在512×512分辨率下,VAE重建的人体细节已经失真,只有达到1024×1024才能满足要求。而现有扩散模型主要工作在256×256或512×512,无法生成高质量的人体多视角图像。
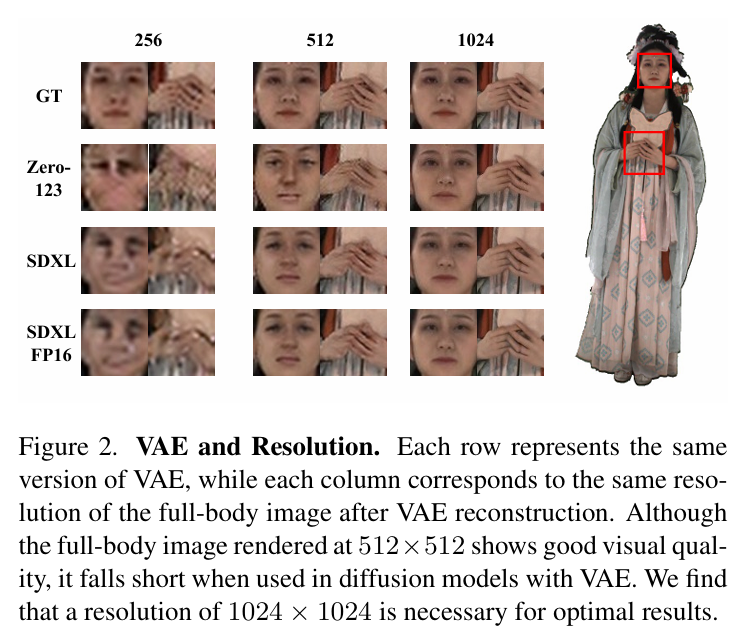
-
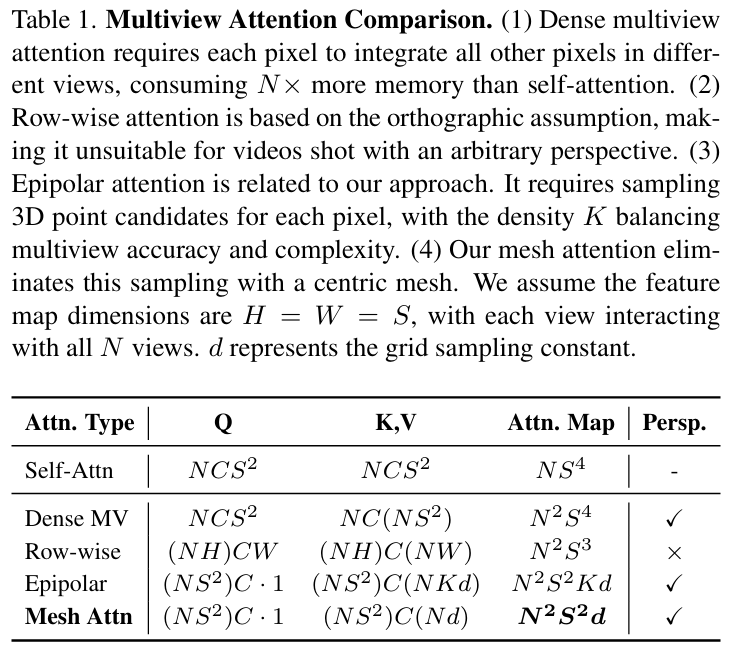
计算爆炸:如果简单将MVDream的密集多视角注意力扩展到1024分辨率,如表1所示,注意力图复杂度高达NS⁴,显存需求超过80GB,完全不可行。因此,需要一种高效的多视角注意力机制,既能保持跨视图一致性,又能处理高分辨率输入。
核心思想:
用网格建立跨视角对应
MEAT的核心思想是:利用一个粗略的穿衣人体网格作为中心几何表示,通过光栅化和投影建立像素之间的直接坐标对应,避免在全图范围内做暴力匹配。
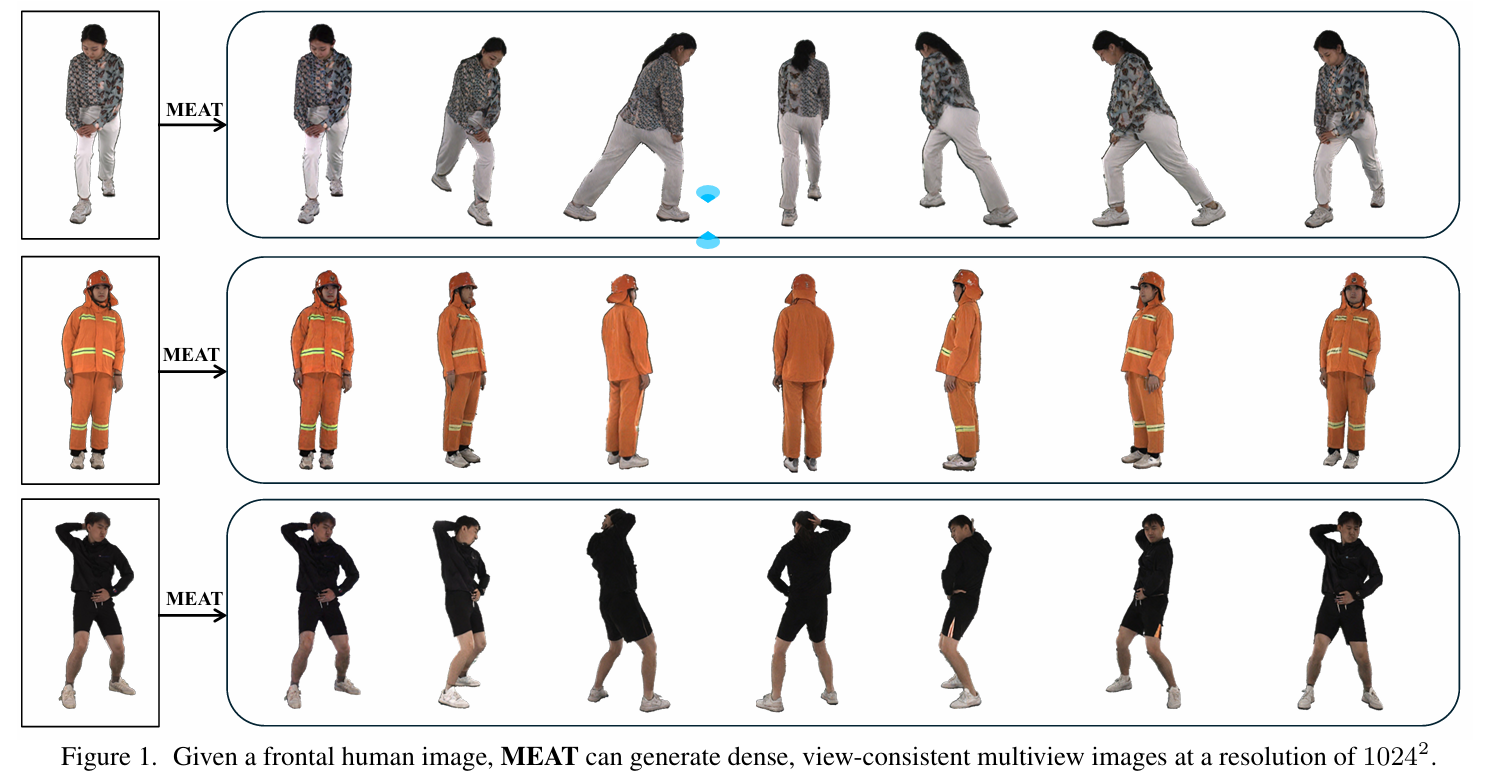
如图1所示,给定一张正面人体图像,MEAT可以生成16张1024×1024分辨率的多视角一致图像,细节清晰、视角连贯。这得益于网格注意力(Mesh Attention)带来的效率提升。
关键技术
1. 网格注意力(Mesh Attention)
这是MEAT的核心创新。如图3所示,网格注意力的工作流程分为三步:
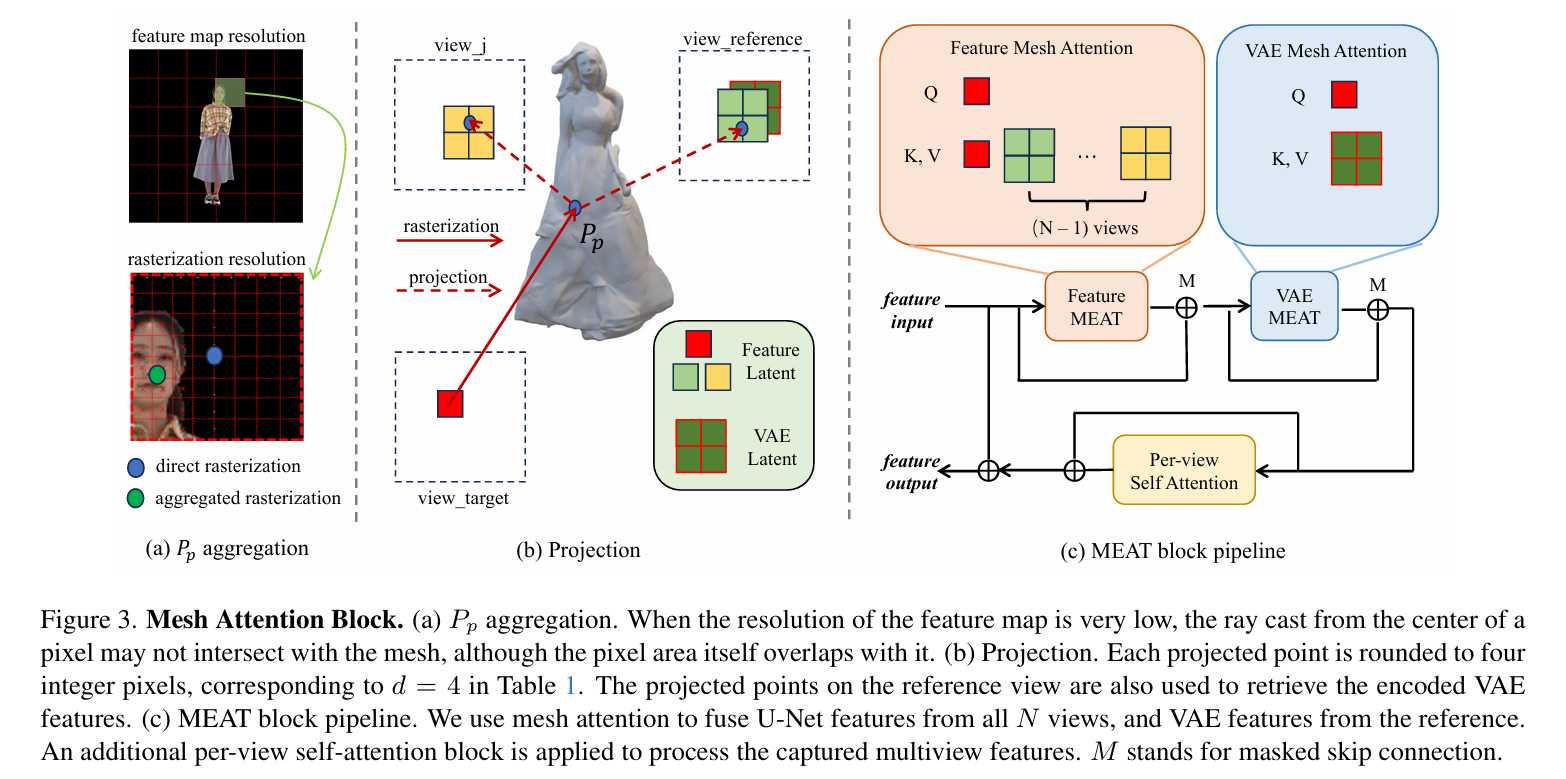
第一步:聚合光栅化(图3a)。由于特征图分辨率低(如16×16),直接光栅化会导致边缘像素被误判为无交点。MEAT先在更高分辨率做光栅化,然后聚合到特征图分辨率,得到每个像素对应的3D点P_p。
第二步:投影与网格采样(图3b)。利用相机参数将P_p投影到其他视角,得到对应像素位置。为了可微分,将投影坐标四舍五入到四个整数像素,提取对应的特征。
第三步:跨视图注意力(图3c)。对于目标视图的每个像素p,用交叉注意力融合其他视图的特征。同时,将参考视图的VAE特征也通过投影注入。
如表1所示,网格注意力的复杂度仅为NS²Sd,远低于密集注意力的NS⁴,是唯一能在1024分辨率训练的注意力方案。
2. 关键点条件注入
为了处理DNA-Rendering数据集中复杂的人体姿态,MEAT将检测到的骨架关键点作为条件注入U-Net。关键点图像经过一个小型卷积网络处理后,直接加到U-Net特征上。
3. 线性噪声调度
借鉴Zero123++的经验,使用线性噪声调度替代 scaled-linear 调度,以获得更好的多视角全局一致
论文 5:4D LangSplat 跨模态注意力的4D语义场 CVPR 2025
problem:
LangSplat成功地将CLIP特征嵌入3D高斯,实现了精确的3D开放词汇查询。但扩展到4D动态场景时面临两个根本性挑战:
-
CLIP无法捕捉时间动态:如图1所示,动态场景中的语义是随时间变化的——咖啡逐渐扩散、鸡嘴开合、饼干碎裂。CLIP是为静态图像-文本匹配设计的,无法理解状态变化、动作等时序语义。直接使用CLIP特征无法支持“running dog”、“pouring coffee”这类时间敏感查询。

-
缺乏像素对齐的物体级视频特征:现有视觉模型(如VideoCLIP)主要提取全局视频特征,无法提供逐物体、逐像素的时序语义监督。简单地对物体裁剪后提取特征会引入背景噪声,且无法区分物体运动和相机运动。
这两个问题导致无法构建精确的4D语言场,限制了开放词汇查询在动态场景中的应用。
核心技术:
4D LangSplat的核心思想是:绕过从视觉特征学习语义场的困难,而是用多模态大语言模型(MLLMs)生成物体级的视频描述,再用大语言模型(LLM)编码成句子嵌入,作为4D语义场的监督信号。
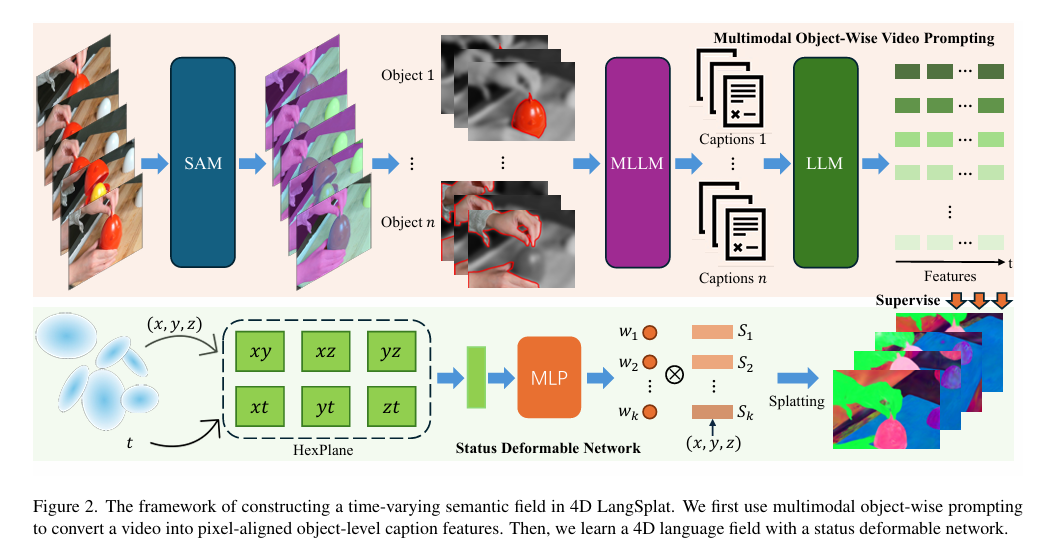
如图2所示,整个流程分为三步:
-
多模态物体级视频提示:用SAM+DEVA跟踪得到物体掩码,结合视觉提示(轮廓、灰度、模糊)引导MLLM生成高质量、时序一致的物体描述。
-
编码为像素对齐特征:用LLM(e5-mistral-7b)将描述编码成句子嵌入,作为逐像素的物体级特征监督。
-
用状态变形网络学习4D语言场:将语义特征嵌入4D高斯,并引入状态变形网络建模状态的连续变化。
这种方法将视觉理解问题转化为文本生成问题,避开了视觉特征难以对齐的困境。
关键技术:
1. 多模态物体级视频提示
为了生成高质量、时序一致的物体描述,作者设计了多模态提示方法(公式4-6,图2上半部分):
-
视觉提示(公式4):对每个物体,用红色轮廓高亮、背景灰度化、背景高斯模糊三种方式组合,让MLLM聚焦目标物体同时保留场景上下文。
-
两阶段时序提示:
-
先对视频序列生成视频级运动描述 DiDi(公式5),概括物体在整个视频中的运动动态。
-
再以此为上下文,结合当前帧的视觉提示,生成逐帧状态描述 Ci,tCi,t(公式6),确保描述在时间上的连贯性。
-
-
特征生成(公式7):用e5-mistral-7b将标题编码成句子嵌入 ei,tei,t,作为像素对齐的物体级特征监督。
2. 状态变形网络(Status Deformable Network)
这是建模动态语义的核心创新(图2下半部分,公式8)。不同于直接学习语义特征的变形场 ΔfΔf,状态变形网络将每个高斯点的语义特征表示为 K个状态原型的线性组合:
fi,t=∑k=1Kwi,t,kSi,kfi,t=k=1∑Kwi,t,kSi,k
其中 Si,kSi,k 是第k个状态原型(代表一个典型的语义状态,如“完整”、“正在碎裂”、“已碎裂”),wi,t,kwi,t,k 是权重系数。这样,语义特征只能在有限的状态集合之间平滑过渡,符合真实世界动态场景中物体状态连续变化的特性。
权重系数由MLP解码器 ϕϕ 根据Hexplane的时空特征预测,与状态原型联合训练。这比直接学习任意变形更稳定,时序一致性更强。
3. 开放词汇4D查询(Sec. 3.5)
如图3和公式所示,4D LangSplat支持两种查询模式:
-
时间无关查询:只用时间无关语义场(CLIP特征),渲染特征图后计算与查询文本的相关性得分,得到空间掩码。
-
时间敏感查询:先用时间无关场得到初始掩码,再在掩码区域内计算时间敏感场与查询文本的余弦相似度,超过阈值的帧即为相关时间段,空间掩码保留。
这种组合方式同时捕捉了物体的持久属性和动态特征。
主线二:视频生成/编辑(延续 Tune-A-Video 的思路)
论文 6:AdaSpa 自适应稀疏注意力 CVPR 2025
problem:
生成高保真长视频时,注意力机制的计算成本成为主要瓶颈。例如,用HunyuanVideo生成8秒720p视频(110K个token)需要约600 PFLOPs,其中近500 PFLOPs被注意力计算消耗。随着视频时长和分辨率增加,这一比例急剧上升,严重制约了长视频生成的实用性。
现有稀疏注意力方法在应用于扩散变换器(DiTs)时存在明显局限:
-
静态模式不足:如滑动窗口、BigBird等固定模式无法适应DiTs的动态、不规则稀疏特征。
-
动态模式不精确:现有动态方法(如MInference)依赖离线搜索或在线近似,无法准确识别DiT的稀疏索引,导致生成质量下降。
需要一种既能适应DiTs动态特性、又能精确高效识别稀疏模式的新方法。
核心技术:
AdaSpa的核心思想基于对DiTs注意力模式的两个关键观察:
观察1:稀疏模式具有层次化和分块化结构。如图3-4所示,不同模态(视频-视频、视频-文本、文本-视频、文本-文本)之间的注意力形成清晰的区域划分,视频帧之间也存在自然的块状边界。
观察2:稀疏模式随输入、层和注意力头变化,但在去噪步骤之间保持不变。这意味着可以在早期步骤中精确搜索稀疏模式,后续步骤复用,既保证了精确性又避免了重复计算。
基于此,AdaSpa提出动态模式+在线精确搜索的稀疏注意力方法——用分块模式高效表示层次化稀疏性,同时利用去噪步骤间的不变性实现低开销的精确在线搜索。
关键技术:
1. 块状模式表示(Blockified Pattern)
如图3-4所示,DiT的注意力矩阵具有自然的块状结构。AdaSpa不是选择单个token交互,而是在块级别操作,识别可以跳过的注意力矩阵块。这将复杂度从O(L²d)降至O((1-sparsity)L²d),同时与DiT的层次化结构天然对齐。
分块化方法通过最大化“召回率”(Recall)来选择块——即选择具有最高注意力权重和(W_sum_attn)的块,以最好地保留原始密集注意力行为。
2. 融合LSE缓存搜索(Fused LSE-Cached Search)
这是实现低开销在线精确搜索的核心创新,分为两阶段:
-
预热步(Warmup Steps):在前几个去噪步中执行完整的FlashAttention计算,同时缓存每行的Log-Sum-Exp(LSE)值。用这些LSE值以块方式计算W_sum_attn,从中导出最优稀疏掩码。
-
缓存搜索(LSE-Cached Search):后续去噪步骤中,利用LSE分布的不变性直接复用缓存的LSE值,无需重新计算,将在线搜索时间减少到全注意力生成时间的5%以下。
3. 头自适应层次化稀疏(Head-adaptive Hierarchical Block Sparse Attention)
不同注意力头对稀疏性的敏感度不同。AdaSpa实现动态稀疏分配策略:
text
Sparsity_head = f(Recall_head, Sparsity_global)
召回率高的头(对稀疏容忍度高)获得更高稀疏度,敏感的头保留更多注意力信息。这种自适应方法在保持整体质量的同时最大化效率提升。
4. 即插即用实现
AdaSpa作为自适应、即插即用解决方案,可无缝集成到现有DiT模型中,无需额外微调或数据剖析。提供简单的adaspa_attention_handler接口,只需一行代码即可替换标准注意力。
额外优化包括:Text Sink保留文本token的注意力交互以维持文本-视频对齐;Row-wise Selection确保均匀注意力分布防止区域伪影。
论文 7:Long Context Tuning 场景级注意力扩展 ICCV 2025
problem:
核心技术:
关键技术:
论文 8:ΔConvFusion 用卷积替代注意力 ICCV 2025
problem:
核心技术:
关键技术:
论文 9:ViT-Linearizer 跨架构注意力蒸馏 ICCV 2025
problem:
核心技术:
关键技术:
三、总结篇:演进脉络与核心启示
3.1 两条主线的演进规律
| 主线 | 基础论文 | 演进方向 | 代表论文 |
|---|---|---|---|
| 多视角生成 | MVDream | 通用→垂直领域 | MEAT(人体生成) |
| 视觉编辑→语义理解 | 4D LangSplat(4D语言场) | ||
| 视频生成 | Tune-A-Video | 静态稀疏→动态稀疏 | AdaSpa(自适应注意力) |
| 镜头内→镜头间 | Long Context Tuning(场景级) | ||
| 注意力→替代方案 | ΔConvFusion(卷积替代)、ViT-Linearizer(线性模型) |
3.2 对 Instruct-4DGS 的深度启发
-
更高效的注意力设计:借鉴MEAT的Mesh Attention或AdaSpa的动态稀疏注意力,优化4DGS中Deformation Field的时序建模,处理更长的动态场景。
-
注意力机制的替代方案:参考ΔConvFusion和ViT-Linearizer,探索用卷积或线性RNN(如Mamba)替换部分注意力,在保证编辑质量的同时大幅提升4D编辑效率。
-
扩展到更复杂的4D场景:借鉴Long Context Tuning,将Instruct-4DGS从编辑“单段动态”扩展到编辑“多镜头、场景级”的4D内容,实现更复杂的叙事性编辑。
-
跨模态语义的深度融合:参考4D LangSplat,将文本指令理解从简单属性编辑升级为对动态场景的复杂语义查询和编辑(如“把2023年穿红色衣服的人变成蓝色”)。
3.3 核心洞察
这条技术演进路线告诉我们:注意力机制的改造正朝着更高效、更智能、更多元的方向发展——从MVDream/Tune-A-Video的结构改造,到Instruct-4DGS的集成应用,再到2025-2026年新作的精细化设计、动态化调控、甚至替代性方案。无论走哪条路,核心目标始终是:在保证生成质量的前提下,让模型更好地理解空间和时间,更高效地响应用户指令。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)