智谱 GLM-OCR:0.9B 小模型登顶 OCR 榜单,3月起还能一行代码接入 Agent
导读:
———————————————————————————————————————————
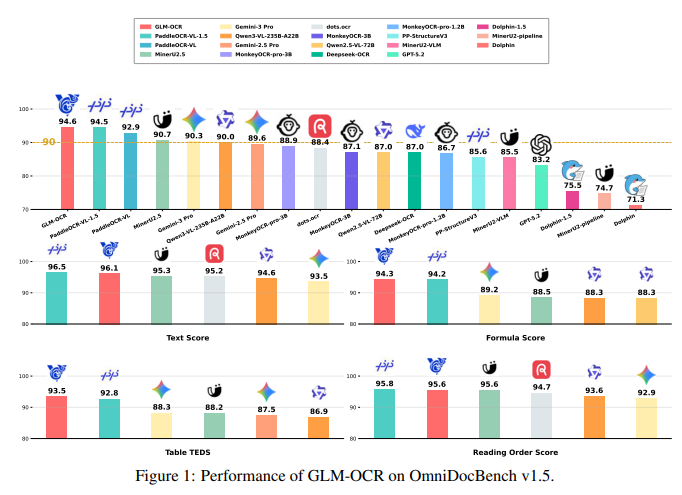
文档 OCR 领域正在经历一场参数量军备竞赛——Qwen3-VL 用 235B 参数拿到 89 分,Gemini-3 Pro 拿到 90 分。但 OmniDocBench V1.5 榜单的第一名 GLM-OCR,参数量只有 0.9B。
就在上周(3 月 11-12 日),智谱连续发布了两个更新:技术报告上线 arXiv,揭示了 Multi-Token Prediction 每步预测 10 个 token、吞吐量提升约 50% 的机制,以及全任务 GRPO 强化学习的完整设计;SDK 新增 Agent Skill 模式,一行代码即可将 GLM-OCR 接入 AI Agent 作为文档理解工具。
本文先介绍刚上线的 Agent Skill 集成方式,然后深入拆解技术报告中的关键设计。
一、Agent Skill:让 OCR 成为 Agent 的工具
———————————————————————————————————————————
AI Agent 在处理实际业务时,经常需要理解文档——读合同、解析票据、提取表格数据。但 Agent 本身不擅长 OCR,需要外接专门的工具来"看"文档。此前这意味着单独部署 OCR 服务、编写格式转换和调用胶水代码。Agent Skill 模式的价值在于把这个过程简化到一行代码:Agent 传入文档,GLM-OCR 返回结构化数据,中间不需要额外配置。
3 月 12 日的 SDK 更新(v0.1.2)新增了这一模式,核心目标是让 GLM-OCR 可以被 AI Agent 或 MCP Server 零配置调用。
最简集成方式
import json
import glmocr
def ocr_tool(image_path: str) -> str:
"""Parse a document and return structured JSON."""
result = glmocr.parse(image_path)
return result.to_json()
只需要在环境中设置 GLMOCR_API_KEY,不需要编写 YAML 配置文件。SDK 会自动走 MaaS 模式,将请求转发到智谱云端 API 并返回结构化结果。
两种运行模式
| 模式 | 是否需要 GPU | 适用场景 |
|---|---|---|
|
MaaS |
不需要 |
Agent 集成推荐,云端处理 |
|
Self-hosted |
需要 |
数据敏感场景,本地 vLLM/SGLang 部署 |
当提供 api_key 但未指定 mode 时,SDK 自动默认 MaaS 模式。
配置优先级
SDK 的配置解析遵循一个清晰的优先级链:
构造函数参数 > 环境变量 > .env 文件 > config.yaml > 内置默认值
Agent 可以通过构造函数参数覆盖各项设置,不需要接触配置文件。所有环境变量使用 GLMOCR_ 前缀(如 GLMOCR_API_KEY、GLMOCR_MODE)。
结果序列化
PipelineResult 提供三种输出方式,方便 Agent 处理:
to_dict()— JSON 可序列化的 Python 字典
to_json()— JSON 字符串
save(output_dir)— 写入文件(JSON + Markdown + 裁剪图片)
这个设计使 GLM-OCR 可以作为文档理解 Agent 的"眼睛"——Agent 负责决策和编排,GLM-OCR 负责将文档转为结构化数据。
二、模型架构:CogViT + GLM + MTP
———————————————————————————————————————————
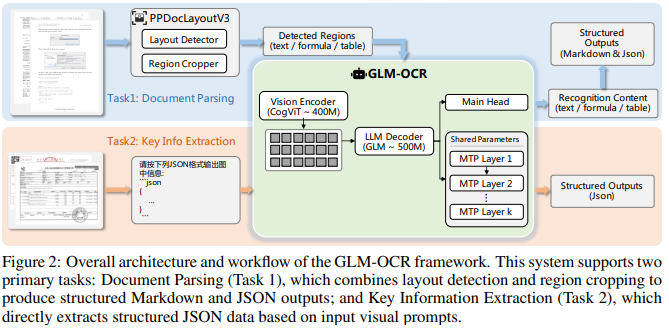
技术报告揭示了 GLM-OCR 的完整架构设计。模型总参数量 0.9B,由三个组件构成:
| 组件 | 参数量 | 职责 |
|---|---|---|
|
CogViT 视觉编码器 |
0.4B |
在数百亿级图文对上通过 MIM + CLIP 双任务预训练,并从更大的内部 ViT 蒸馏知识 |
|
轻量跨模态连接器 |
— |
token 下采样,连接视觉与语言空间 |
|
GLM-0.5B 语言解码器 |
0.5B |
基于 ChatGLM,生成 OCR 结果文本 |
两阶段处理流水线
系统分两个任务路径:
任务 1:文档解析
文档图像 → PP-DocLayout-V3(版面检测 + 区域裁剪)→ 各区域并行送入 GLM-OCR Core → 合并 & 后处理 → Markdown + JSON
PP-DocLayout-V3 将文档拆分为段落、表格、公式等区域,各区域独立识别后按阅读顺序合并。并行处理降低了单次输入的复杂度,也减少了幻觉风险。
任务 2:信息抽取(KIE)
完整文档图像 + JSON Schema 提示 → GLM-OCR Core → 结构化 JSON
信息抽取跳过版面分析,直接将完整图像和 JSON 格式要求一起送入模型。

三、Multi-Token Prediction:OCR 场景的加速策略
———————————————————————————————————————————
MTP 是技术报告中最值得关注的设计。
为什么 OCR 适合 MTP
标准自回归解码每步只生成一个 token,但 OCR 是确定性较强的任务——给定图像区域,输出文本的不确定性远低于开放式对话。特别是结构化标记(表格标签、Markdown 语法)具有很强的局部依赖性,适合一次预测多个 token。
具体实现
在主预测头之外,附加 k 个共享参数的辅助预测头,同时预测未来 k 个 token。关键设计:
训练时:每步预测 10 个 token
推理时:平均每步生成 5.2 个 token
吞吐量提升:约 50%
内存开销:辅助头共享参数,额外 GPU 内存开销很低
MTP 从预训练阶段引入,贯穿 SFT 阶段。
不只是加速
技术报告指出 MTP 还有一个训练效益:鼓励模型"看得更远",在生成结构化输出时产生更少的断裂标签和更稳定的格式。
四、全任务强化学习:GRPO + 任务感知奖励
———————————————————————————————————————————
GLM-OCR 在 SFT 之后加入了基于 GRPO(Group Relative Policy Optimization)的强化学习阶段,覆盖四类任务,每类有专门设计的奖励函数:
| 任务 | 准确性奖励 | 额外约束 |
|---|---|---|
|
文本识别 |
归一化编辑距离 |
重复惩罚 |
|
公式识别 |
CDM 分数 |
结构有效性检查 |
|
表格识别 |
TEDS 分数 |
标签闭合验证、结构解析 |
|
信息抽取 |
字段级 F1 分数 |
JSON 解析验证、缺失/重复字段惩罚 |
此外还有全局正则化:重复率惩罚和结构异常惩罚。
训练样本通过 SFT 模型 rollout 生成,自动评估后按难度分层构建优化集。这种分层策略使 RL 训练更稳定,避免在简单样本上浪费优化资源。
五、Benchmark 详解
———————————————————————————————————————————
OmniDocBench V1.5:各维度逐项对比
以下摘录 GLM-OCR 与几个关键对手在各维度上的数据:
| 模型 | 参数量 | 综合 | 文本 Edit↓ | 公式 CDM | 表格 TEDS | 阅读顺序 Edit↓ |
|---|---|---|---|---|---|---|
| GLM-OCR | 0.9B | 94.62 |
0.040 |
93.90 |
93.96 |
0.044 |
|
PaddleOCR-VL-1.5 |
0.9B |
94.50 |
0.035 | 94.21 |
92.76 |
0.042 |
|
Gemini-3 Pro |
— |
90.33 |
0.065 |
89.18 |
88.28 |
0.071 |
|
Qwen3-VL |
235B |
89.15 |
0.069 |
89.18 |
88.14 |
0.068 |
|
GPT-5.2 |
— |
85.50 |
0.123 |
86.11 |
82.66 |
0.099 |
|
dots.ocr |
3B |
88.41 |
0.048 |
83.22 |
86.78 |
0.053 |
|
MinerU2.5 |
1.2B |
90.67 |
0.047 |
88.46 |
88.22 |
0.044 |
几个值得注意的点:
GLM-OCR 与 PaddleOCR-VL-1.5 的竞争非常接近(94.62 vs 94.50),两者参数量相同(0.9B),但各有优劣——PaddleOCR-VL-1.5 在文本和公式上略优,GLM-OCR 在表格上领先
相比 Gemini-3 Pro,GLM-OCR 在文本、公式、表格三项均有明显优势,阅读顺序接近
同参数量级(0.9B-3B)的专用模型中,GLM-OCR 综合得分最高
实际场景测试
除了公开基准,技术报告还在内部测试集上做了评测,覆盖代码文档、实际表格、手写体、多语言、印章、票据等场景:
| 场景 | GLM-OCR | PaddleOCR-VL-1.5 | Gemini-3 Pro |
|---|---|---|---|
|
代码文档 |
84.7 |
75.8 |
86.9 |
|
实际表格 |
91.5 |
86.1 |
90.6 |
|
手写体 |
87.0 |
87.4 |
90.0 |
|
多语言 |
69.3 |
54.8 |
86.2 |
|
印章识别 |
90.5 |
42.2 |
91.3 |
|
票据 KIE |
94.5 |
— |
97.3 |
在印章识别上,GLM-OCR(90.5)大幅超越 PaddleOCR-VL-1.5(42.2),与 Gemini-3 Pro(91.3)接近。多语言场景(支持中英法西俄德日韩 8 种语言)也有较大优势。
处理速度
| 模型 | 图片(页/秒) | PDF(页/秒) |
|---|---|---|
| GLM-OCR | 0.67 | 1.86 |
|
PaddleOCR-VL-1.5 |
0.39 |
1.22 |
|
Deepseek-OCR2 |
0.32 |
— |
|
MinerU2.5 |
0.18 |
0.48 |
|
dots.ocr |
0.10 |
— |
GLM-OCR 的处理速度在同类模型中最快,PDF 处理速度约为 PaddleOCR-VL-1.5 的 1.5 倍,MinerU2.5 的 3.9 倍。
六、总结与思考
———————————————————————————————————————————
GLM-OCR 技术报告最有价值的两个贡献:
-
MTP 机制在 OCR 场景的验证——利用 OCR 任务的确定性特点,通过共享参数的多头预测实现约 50% 的吞吐提升,且不显著增加内存开销。这个思路对其他确定性较强的视觉理解任务也有参考价值。
-
全任务 RL 的奖励设计——针对文本/公式/表格/KIE 四类任务分别设计准确性奖励和结构约束,配合难度分层的训练样本构建,使 RL 训练更稳定。
当前局限:
两阶段流水线存在误差传播风险:版面检测不准会影响下游识别
跨页依赖和不规则多栏版面下,阅读顺序重建可能不完美
低分辨率、严重变形文档,以及训练数据中覆盖不足的语言,性能会下降
作为生成模型,换行和空格处理存在随机性,无法完全保证格式一致性
信息抽取依赖 prompt 质量,复杂表单中模糊字段可能导致抽取不完整
项目信息:
GitHub:https://github.com/zai-org/GLM-OCR
技术报告:arXiv 2603.10910
HuggingFace:https://huggingface.co/zai-org/GLM-OCR
协议:Apache 2.0(代码)+ MIT(模型)
最新版本:v0.1.3(2026-03-13)
API 定价:0.2 元/百万 token(约为传统 OCR 方案的 1/10)
点赞/关注/收藏!!!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)