【动态重建】LASER:基于层的尺度对齐无训练流式4D重建


标题:LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction来源:东北大学 ;三菱电机研究实验室链接:https://neu-vi.github.io/LASER
摘要
近期提出的前馈重建模型(如 VGGT 和 π 3)虽能实现卓越的重建质量,但由于存在二次内存复杂度问题,无法处理流式视频,这限制了其实际应用范围。现有流式方法通过学习记忆机制或因果注意力机制来解决该问题,但需要大量重新训练,且可能无法充分利用当前最先进的离线模型所具备的强几何先验特性。
Laser是无训练框架,通过跨连续时间窗口对齐预测结果,将离线重建模型转化为流式系统。研究发现,简单的相似性变换(Sim(3))对齐方法因 layer depth misalignment 导致失败:单目尺度模糊性使得不同场景层的相对深度尺度在窗口间呈现不一致性。为此,我们引入 layer-wise scale alignment(逐层尺度对齐技术),将深度预测分割为离散层级,计算各层级尺度因子,并将其传播至相邻窗口及时间戳之间。大量实验表明,Laser在 RTX A6000 GPU上以14帧/秒帧率和6GB峰值内存运行时,仍能实现相机姿态估计与点云重建的顶尖性能,为千米级流式视频的实际部署提供了可能。
一、Overview
核心目标:在不改变原有预训练模型参数的前提下,通过重叠时间窗口(Temporal Windows)和增量配准(Incremental Registration),实现视频流的实时4D重建。

阶段一:基于时间窗口的局部重建
将输入的单目RGB视频划分为多个相互重叠的片段:
- 1.窗口划分:视频被分为 L L L 帧长的窗口 W i \mathcal{W}_i Wi,相邻窗口之间有 O O O 帧的重叠。
- 2.模型预测:每个窗口通过一个冻结的重建器 f ( ⋅ ) f(\cdot) f(⋅),预测出该窗口内每一帧的:
密集点图 (Point Maps) P t ( i ) \mathbf{P}_t^{(i)} Pt(i):局部坐标系下的3D结构。
相机位姿 (Camera Poses) T t ( i ) \mathbf{T}_t^{(i)} Tt(i):包含旋转矩阵 R t ( i ) \mathbf{R}_t^{(i)} Rt(i) 和平移向量 t t ( i ) \mathbf{t}_t^{(i)} tt(i)。
置信度分数 (Confidence Scores) C t ( i ) \mathbf{C}_t^{(i)} Ct(i):用于后续的尺度估计。
- 3.局部子图构建:将窗口内所有帧的点图转换到该窗口的统一坐标系中,形成局部子图 S i \mathcal{S}_i Si。
阶段二: Sim ( 3 ) \text{Sim}(3) Sim(3) 空间的增量全局对齐
为了将局部子图 S i \mathcal{S}_i Si 合并到全局地图 G \mathcal{G} G 中,需要解决不同窗口间的尺度、旋转和平移差异:
- 1.相似变换估计:计算局部子图 S i \mathcal{S}_i Si 与已有的全局地图 G i − 1 \mathcal{G}_{i-1} Gi−1 之间的 Sim ( 3 ) \text{Sim}(3) Sim(3) 变换(包含尺度 s i w s_i^w siw、旋转 R i w \mathbf{R}_i^w Riw、平移 t i w \mathbf{t}_i^w tiw)。尺度估计:使用鲁棒的 IRLS(迭代重加权最小二乘法) 优化,确保相邻窗口间具有统一的度量。位姿对齐:在确定尺度后,利用 Kabsch 算法 优化旋转和平移。
- 2.坐标转换:将局部位姿转换为全局位姿 T t w \mathbf{T}_t^w Ttw。
- 3.地图更新:将当前窗口的点云增量式地并入全局地图: G i = G i − 1 ∪ { T t w P t ( i ) } \mathcal{G}_i = \mathcal{G}_{i-1} \cup \{\mathbf{T}_t^w \mathbf{P}_t^{(i)}\} Gi=Gi−1∪{TtwPt(i)}。
二、Layer-wise Scale Alignment (LSA)
尽管全局Sim(3)配准方法将每个视窗对齐至统一尺度,但其假设各向同性缩放特性——即相同缩放因子沿所有空间轴线均等应用。实际应用中该假设常失效,例如在低视差运动场景下,单目重建器无法可靠约束深度方向(Z轴)相对于横向轴线的坐标关系。因此即使完成全局对齐后,不同深度的表面仍可能出现分层尺度不一致性:如图3所示,前景区域相对于背景结构在视窗间呈现过度缩放或不足缩放现象。这种沿深度方向的各向异性缩放效应会随时间累积,导致融合重建结果出现可见畸变与度量漂移。

基于经典理论中场景可分解为深度有序层级的见解[1,50],我们提出基于几何结构的分层尺度对齐算法(LSA),该算法通过layer graph,对畸变进行校正。

1.深度层提取 (Depth Layer Extraction)
为了处理复杂的场景,算法首先将每一帧的 3D 信息分解为多个“层”:
- 伪深度图生成:利用 Sim ( 3 ) \text{Sim}(3) Sim(3) 注册后的点图 P ˉ t ( i ) \mathbf{\bar{P}}_t^{(i)} Pˉt(i) 的 Z Z Z 轴分量,推导出伪深度图 D ˉ t ( i ) \mathbf{\bar{D}}_t^{(i)} Dˉt(i)。
- 分层分割:使用高效分割算法将深度图划分为 M t ( i ) M_t^{(i)} Mt(i) 个不相交的深度层 { L t , m ( i ) } \{\mathcal{L}_{t,m}^{(i)}\} {Lt,m(i)}。
- 物理意义:每一层对应一个在空间深度上连续且连贯的几何表面斑块(Surface Patch)。
2.深度层图结构构建 (Depth Layer Graph Construction)
算法构建了一个有向图 H = ( V , E ) \mathcal{H}=(\mathcal{V}, \mathcal{E}) H=(V,E),通过图结构来建模层与层之间的联系:
- 节点 ( V \mathcal{V} V):每个节点代表一个具体的深度层。
- 边 ( E \mathcal{E} E):通过交并比(IoU)判断层的重叠度,若 I o U > 0.3 IoU > 0.3 IoU>0.3,则建立连接(用来传递尺度信息,而非合并):
跨窗口边 ( E inter \mathcal{E}_{\text{inter}} Einter):连接不同窗口( W i − 1 \mathcal{W}_{i-1} Wi−1 与 W i \mathcal{W}_i Wi)但在同一时间戳下的相同几何表面:重叠度高,说明它们描述的是物理世界中同一个表面。
窗口内边 ( E intra \mathcal{E}_{\text{intra}} Eintra):连接同一窗口内相邻帧之间的相同几何表面,用于编码时间的几何连续性。
3.基于 IRLS(迭代重加权最小二乘法) 的层级尺度估计
这是算法的核心优化步骤,用于修正因独立窗口重建导致的尺度漂移:
- 构建对应关系:在两个层的交集区域内,根据像素坐标 x x x 提取点对 ( d p , d q ) (d_p, d_q) (dp,dq),其中 d p d_p dp 来自前一窗口, d q d_q dq 来自当前窗口。
- 优化目标:使用 IRLS(迭代重加权最小二乘法) 求解最优缩放因子 s ^ t , n ( i ) \hat{s}_{t,n}^{(i)} s^t,n(i): s ^ t , n ( i ) = arg min s > 0 ∑ ( d p , d q ) ∈ C t , n ( i ) ρ ( ∥ s d p − d q ∥ ) \hat{s}_{t,n}^{(i)} = \arg \min_{s>0} \sum_{(d_p, d_q) \in \mathcal{C}_{t,n}^{(i)}} \rho(\| s d_p - d_q \|) s^t,n(i)=args>0min(dp,dq)∈Ct,n(i)∑ρ(∥sdp−dq∥)这里使用了 Huber loss ( ρ \rho ρ) 来增强对离群点的鲁棒性。
4.尺度传播与聚合 (Propagation & Aggregation)
得到初步的尺度估计后,算法在全局图结构上进行平滑处理:
- 多路径聚合:一个深度层可能会从 E inter \mathcal{E}_{\text{inter}} Einter(跨窗口)和 E intra \mathcal{E}_{\text{intra}} Eintra(跨时间)接收到多个不同的尺度建议。
- 加权平均:根据 IoU 分数 作为权重,对接收到的尺度进行加权聚合,确保最终尺度在时空维度上一致。 即:如果一个新 Layer 同时和好几个旧 Layer 都有高 IoU(比如一个大平面被切成了小块),它会接收到多个尺度建议,然后根据 IoU 的大小作为权重进行加权平均
- 像素级应用:优化后的层级尺度最终应用到该层包含的所有像素上,从而调整原始点图 P ˉ t ( i ) \mathbf{\bar{P}}_t^{(i)} Pˉt(i),消除重建中的形变(Distortions)。
实验
1.实验设置
任务、数据集与指标:
- 视频深度估计协议。在Sintel[2]、Bonn[42]和 KITTI [16]数据集上进行评估。预测深度通过仅比例尺对齐方式与真实值进行校准。
- 相机位姿估计协议。在小规模数据集Sintel[2]、ScanNet[8]及TUM RGB-D[52] 上进行对比测试。预测轨迹通过Sim(3)变换与真实值对齐。大规模评估采用文献[9]中 KITTI 里程计算法[16]。
- 多视图点云估计协议。除文献[24,73]因存储限制在 NRGBD 数据集上使用15帧间隔外,其余实验均采用7-Scenes[51]和 NRGBD [67]数据集,关键帧采样间隔为10帧。预测点云通过Umeyama算法(粗略Sim(3)对齐)与真实值配准后,再采用迭代最近点(ICP)算法进行精修。
Baselines:
- 离线前馈模型。纳入了DUSt3R[63]、Fast3R[68]、 VGGT [59]和 π 3[64]等模型,这些模型无需时间约束即可处理静态图像批次。
- 流式或在线前馈方法。采用Spann3R[58]、CUT3R[62]、MASt3R-SLAM[39]、Point3R[66]、 VGGT -SLAM[35]、StreamVGGT[73]、 STream3Rβ [24]、WinT3R[27]和TTT3R[6]等方案,这些方法可实现因果推断或保持持久记忆。
- 经典SLAM系统。针对 KITTI 里程计上的相机位姿评估,我们与ORB-SLAM2[38]、 LDSO [15]、droid-VO、droidslam[55]、 DPV -SLAM及 DPV -SLAM++[31]等SLAM方法进行对比。
- 无需训练工作。为充分验证无训练设计的优势并确保性能不受强骨干网络影响,我们还基于 VGGT [59]框架评估了 VGGT -Long[9]这一无训练并行流式框架。为确保公平性,我们在 π 3[64]骨干网络上重新实现了其流程(命名为 π 3-Long),从而在相同基础模型下实现一对一性能对比。
细节:采用 VGGT 或 π 3 π^3 π3 作为离线4D重建的底层框架来实现激光雷达建模。在千米级 KITTI 里程计测量中,为确保可比性,我们采用了 VGGT -Long[9]配置的闭环回路技术。
2.视频深度估计
表1展示了视频深度估计结果。相较于离线方法,流式方法(CUT3R、StreamVGGT和 STream3Rβ)的性能略有下降是合理的,因为流式方法仅利用有限的时间上下文信息,导致深度预测结果存在不一致性。

3.相机位姿估计
表2展示了小规模数据集的实验结果。在所有三个数据集上,LASER( π 3 π^3 π3)在几乎所有指标中均表现最优,甚至在某些情况下超越了其离线骨干网络
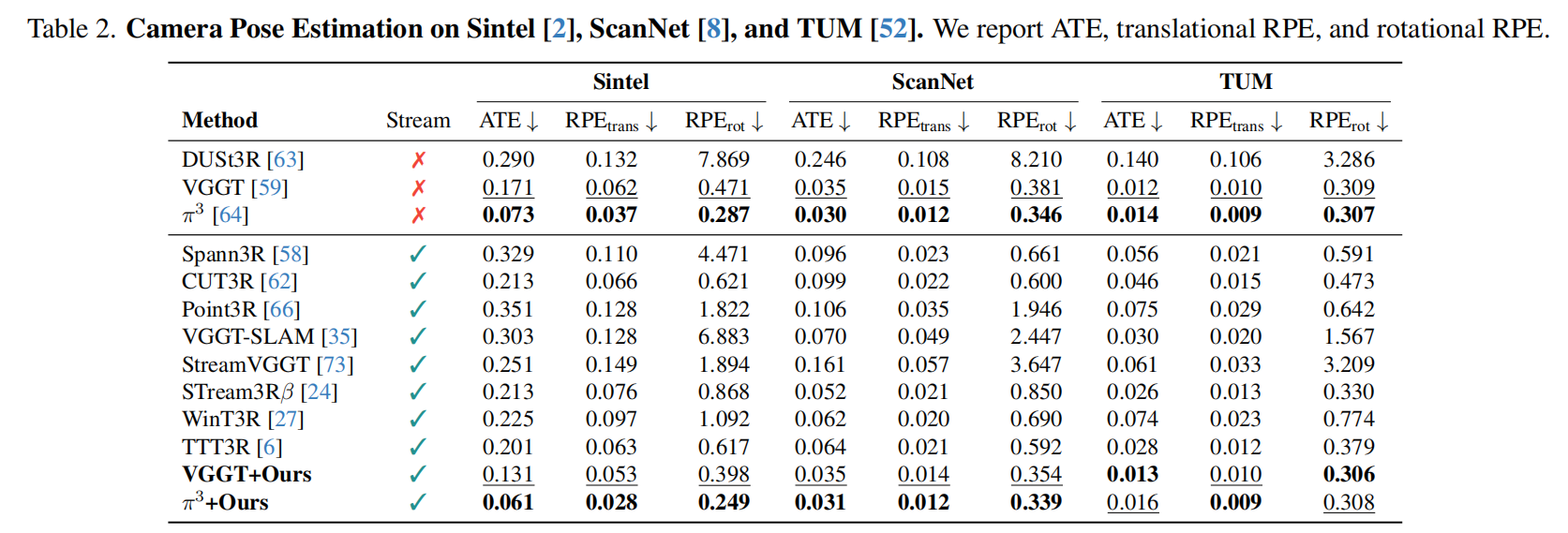
表3展示了大规模户外场景,采用 π 3 π^3 π3as 主干网络的LASER在平均精度和平均*值指标上均表现优异,其平均平均绝对误差(ATE)在所有方法中位列第二低。该方法的精度可与ORB-SLAM2[38]、droidslam[55]等设计精良的SLAM系统相媲美甚至更优。VGGT [59]、 π3 [64]等密集离线模型因内存限制难以处理长序列数据,而CUT3R[62]、MASt3R-SLAM[39]等流式处理变体则常出现内存不足或跟踪失效问题。
4.多视角点云图估计
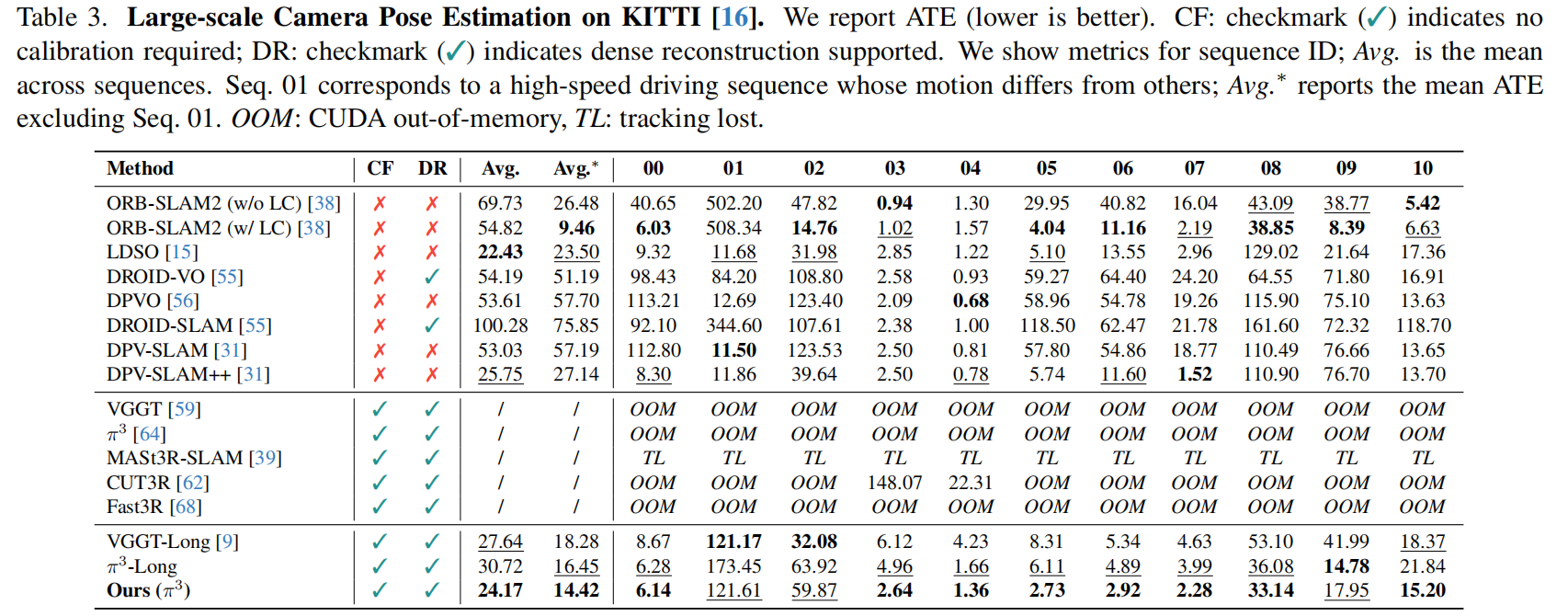
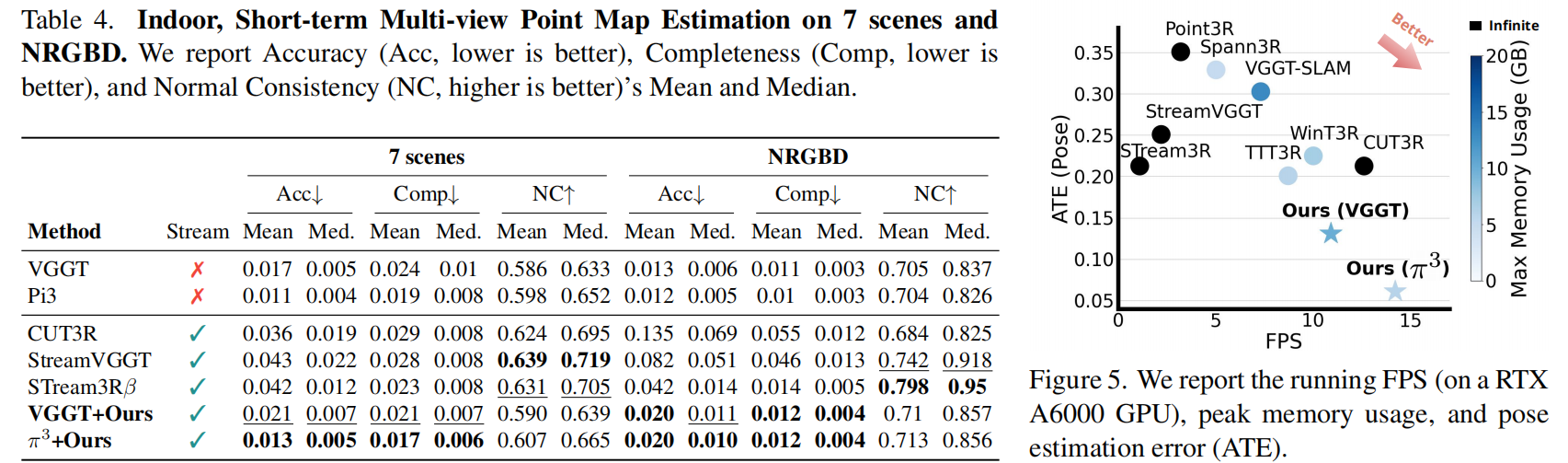
表4展示了短期多视角 point map 估计结果。LASER在准确率(Acc)和一致性(Comp)方面持续优于现有流式基线方法。虽然 π 3+Ours的归一化系数(NC)略低于StreamVGGT或 STream3Rβ ,但该差异源于 π 3 π^3 π3 主干网络对表面法线的保真度有限。值得注意的是,我们的无训练公式在NC指标上仍优于 π 3。 VGGT +Ours与 VGGT 之间也呈现相似趋势。实验结果表明,我们的在线整合方法相较于主干网络能生成更平滑、更连贯的表面方向特征。
一*、 Sim ( 3 ) \text{Sim}(3) Sim(3) 空间:相似变换群
在 3D 空间中,如果我们要将一个局部物体对齐到全局场景,通常会涉及到 Sim ( 3 ) \text{Sim}(3) Sim(3)(Similarity Group)。
- 定义: Sim ( 3 ) \text{Sim}(3) Sim(3) 是三维空间中的相似变换群。它比我们常听到的 S E ( 3 ) SE(3) SE(3)(欧式变换,仅包含旋转和平移)多了一个维度:尺度(Scale)。
- 构成要素:一个 Sim ( 3 ) \text{Sim}(3) Sim(3) 变换包含 7 个自由度(DoF):旋转 (Rotation, R \mathbf{R} R):3 个自由度。平移 (Translation, t \mathbf{t} t):3 个自由度。缩放 (Scale, s s s):1 个自由度。
- 数学表达:对于一个 3D 点 P \mathbf{P} P,变换后的点 P ′ \mathbf{P}' P′ 为: P ′ = s R P + t \mathbf{P}' = s\mathbf{R}\mathbf{P} + \mathbf{t} P′=sRP+t
二*、最小二乘法 (LS) vs. 迭代重加权最小二乘法 (IRLS)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)