深度解析:NVIDIA 祭出 Groq 3 LPX,AI 推理性能为何能暴涨 35 倍?
2025年底,NVIDIA完成对Groq的收购,将后者独创的LPU(语言处理单元)架构纳入自身生态,这一举措在行业内引发广泛关注。2026年GTC大会上,悬念终于揭晓——NVIDIA正式推出Groq 3 LPX,作为Vera Rubin平台的第七款核心芯片,以256颗LPU加速器组成机架式系统,与Vera Rubin NVL72形成协同,专为万亿参数模型的低延迟推理而生。这款产品不仅是CPX机架概念的进化迭代,更凭借独特的架构设计,重新定义了AI推理的硬件分工模式。
从CPX到LPX:NVIDIA的推理架构转向
去年AI Infra峰会上,NVIDIA曾发布CPX机架,主打长上下文推理加速,但当时该架构并未展现出超越Rubin GPU的实质性优势,仅在注意力操作加速方面略有潜力。随着Groq的收购完成,NVIDIA对这一概念进行了彻底重构,CPX最终进化为Groq 3 LPX机架——核心差异在于,LPX摒弃了原有的上下文处理导向,转而采用基于Groq芯片的全新解码加速架构。
作为全液冷设计的机架式系统,LPX基于MGX基础设施构建,计划于2026年下半年与Vera Rubin平台同步上市。NVIDIA官方数据显示,这款产品能使万亿参数模型的每兆瓦推理吞吐量提升35倍,同时为用户带来高达10倍的收入增长潜力。更重要的是,LPU可作为Vera和NVL72平台现有CUDA栈的加速器,以令牌为单位透明卸载计算任务,无需对现有软件生态进行修改。在GTC问答环节中,NVIDIA将其定位为“解码模型助推器”,并表示将与部署万亿参数模型的AI实验室及前沿模型开发者深度合作,推动下一代高端模型服务落地。
LPU核心解析:不同于GPU的确定性架构
1. 本质:超大规模向量处理器
LPU的核心定位是超大规模向量处理器,计算与通信的基本单位是320元素向量——INT8精度下为320字节,FP16精度下为640字节。芯片上的所有操作,无论是算术运算、内存访问、数据重构还是芯片间传输,均基于这一固定尺寸向量执行,这种设计确保了运算的高度并行性与可预测性。
2. 四大功能模块:分工明确的硬件架构
LPU以单一基础构建块为核心——SIMD功能单元搭配轻量级指令调度单元,并通过专业化衍生出四类功能模块,分别适配不同运算场景。
●矩阵执行模块(MXM):核心计算单元,提供密集型乘加运算能力,支持矩阵-向量、矩阵-矩阵运算。LPX机架中每块Groq 3 LP30芯片的FP8算力达1.2 PFLOPS,单个LPX托盘(含8块芯片)的总算力可达9.6 PFLOPS;
●向量执行模块(VXM):负责逐点算术运算、逻辑运算、类型转换及激活函数,其内部集成的ALU阵列可通过编译器自动串联,单次完成“归约-偏置加法-激活-类型转换”等复合操作;
●开关执行模块(SXM):处理结构化数据移动,包括向量的置换、旋转、分布与转置;
●存储单元(MEM):采用扁平化、SRAM优先的存储架构,无缓存层级设计,不存在缓存未命中问题。Groq 3 LP30芯片内置500MB片上SRAM,带宽达150 TB/s,编译器可直接寻址物理存储 bank 位置,全程掌握数据存储状态。
这些功能模块沿芯片水平方向排布,指令从上下两端流向中间,数据流则沿东西方向传输,二者在功能模块处交汇完成运算,形成高效的并行处理流水线。
3. 核心特性:1D互连与确定性执行
(1)1D互连与流寄存器
LPU的功能模块间通信依赖流寄存器与一维互连架构,包含东西两个方向的传输路径,每个流寄存器对应一次数据跳转。数据传输严格遵循“每时钟周期一跳”的规则,编译器可根据功能模块的物理位置,通过简单的加减运算即可预判数据传输时间。这种设计摒弃了队列与竞争机制,将复杂的二维调度问题简化为易处理的一维问题,正如Groq首席架构师Igor Arsovski所言:“编译器能精确知晓10个周期后数据的位置,因为它恰好会完成10次跳转”,不存在任何歧义与硬件自主路由决策。
(2)确定性执行
确定性是LPU的标志性特征。与传统处理器不同,LPU移除了硬件互锁等动态组件,将所有决策逻辑移交编译器,硬件仅负责执行预设调度方案,确保所有功能模块同步运行,无任何执行差异。这一特性带来三大优势:操作延迟完全一致、功耗可精准预测、数值计算具备确定性。通过Groq的TruePoint技术,LPU可基于320元素融合点积与单次舍入步骤,从FP16输入中获得FP32级别的计算精度,这对LLM推理的结果一致性至关重要。
三、LPU互联架构:RealScale与机架拓扑
1. 数据传输模式:流水线式协同
LPU间的数据传输采用流水线模式:模型编译时被划分为多个阶段,每个阶段被映射到一组LPU芯片,该组芯片将所需权重参数存储在本地片上SRAM中;推理过程中,芯片组间仅传输前一阶段的中间激活输出,数据如同流水线工件般逐站传递,每个芯片组完成指定运算后即刻转发结果。这种模式与GPU形成本质区别——GPU的每个计算阶段都需从片外HBM中读取完整权重并写回结果,而LPU的权重始终驻留本地SRAM,仅激活张量在芯片间流动,大幅降低数据传输开销。
2. 关键澄清:Groq RealScale vs NVIDIA C2C
需特别注意的是,LPX系统采用的芯片间(C2C)互连是Groq的RealScale技术,与NVIDIA生态中的C2C技术存在本质差异:
**●NVIDIA C2C:**缓存一致性互连,适用于紧耦合模块内的异构芯片通信(如CPU-GPU),采用高速SerDes与一致性协议;
●Groq RealScale:软件调度的确定性点对点互连,网络链路由编译器显式流控,与MXM、VXM等计算单元同等对待,无硬件仲裁与自适应路由,数据包不含地址头信息,链路相位对齐且延迟固定,通过准同步协议解决芯片间时钟漂移,为编译器提供全局统一时间域。
LPX机架内的所有C2C连接(托盘内、托盘间背板、机架间前端端口)均采用RealScale技术,该技术自第一代GroqNode起未变,仅将链路速率从30 Gbps提升至112 Gbps。
3. 三级互联拓扑
(1)托盘内互联(Intra-Tray)
每个1U计算托盘包含8颗LP30芯片,采用全连接(all-to-all)拓扑,每颗芯片可直接与其他7颗芯片通信。单颗LP30芯片配备96个C2C链路(112 Gbps/链路),双向带宽达2.5 TB/s,托盘内芯片间形成28条独立连接链路。扣除32条前端机架间链路后,剩余736条链路用于托盘内与背板通信,双向总带宽达20.6 TB/s,与NVIDIA官方公布的20 TB/s规格基本一致,这8颗芯片组成蜻蜓网络拓扑的“本地组”。
(2)机架内互联(Intra-Rack)
单个LPX机架包含32个计算托盘(共256颗芯片),通过背板中的4个ETL spine实现托盘间互联,形成机架级扩展域。全机架聚合扩展带宽达640 TB/s(32托盘×20 TB/s),每个spine承担约160 TB/s的双向带宽。
(3)机架间互联(Inter-Rack)
每个计算托盘前端配备4个QSFP C2C端口(共32条链路),采用对称连接模式:16条链路连接左侧相邻机架,16条连接右侧相邻机架,且同U位机架相互对应。单托盘机架间双向带宽达448 GB/s,全机架则提供14.3 TB/s的单向带宽(两侧各约7.2 TB/s)。这种设计使机架间形成稀疏的全局连接,延续了GroqRack的低网络直径特性(264芯片部署中最大跳转仅3次)。
值得一提的是,单台LPX机架的芯片密度达初代四机架GroqRack的4倍,通过液冷与无电缆背板设计,在MGX ETL机架形态中实现了超高密度部署。对于超出单机架SRAM容量(256芯片共128 GB)的大型模型,可通过前端C2C端口级联多个LPX机架,扩展流水线长度。
核心目标:FFN层卸载与解码拆分
1. 解码瓶颈:为何FFN层成为关键
AI推理的预填充阶段(摄入提示词并构建KV缓存)与解码阶段(逐令牌生成)对硬件需求差异显著。随着模型推理输出的推理链延长、前缀缓存技术降低预填充成本、上下文窗口扩展至数十万令牌,解码阶段的延迟逐渐成为用户感知的核心瓶颈。尤其在智能体工作流中,延迟会在多次模型调用与工具交互中累积,而低延迟高吞吐量的推理服务往往能带来更高商业价值——Anthropic的Fast Mode服务价格即为普通服务的6倍。
NVIDIA的调研显示,解码阶段的核心瓶颈是前馈网络(FFN)层。在Transformer架构中,FFN层负责令牌的独立特征转换(投影至高维空间→非线性激活→投影回原空间),堪称模型的“知识库”;而在DeepSeek R1、Kimi K2等主流MoE架构模型中,FFN层被复制为数百个独立“专家”,注意力机制则保持共享,导致FFN层占比高达90%-99%的模型权重,成为解码阶段的主要计算负载。
以DeepSeek R1为例,该模型包含61个Transformer层(隐藏维度7168),其中59个为MoE层,每个MoE层包含256个路由专家与1个共享专家,单个专家的SwiGLU FFN模块含4400万参数,全模型FFN层总参数达6691亿,占模型总大小的97.7%(FP8格式下约623.1 GB),其计算压力可见一斑。
2. 解码拆分架构(AFD):GPU与LPU的分工协作
NVIDIA提出注意力-FFN拆分(AFD)架构,将解码阶段拆分为两个独立步骤,由不同硬件分别处理:
●Rubin GPU:负责解码注意力运算,从HBM中读取KV缓存,计算注意力分数并生成中间激活张量;
●Groq 3 LPX:接收中间激活张量,执行FFN/MoE专家计算,以极高带宽与确定性延迟完成运算后,将结果返回GPU继续令牌生成。
这种分工完美契合硬件特性:GPU擅长处理变长注意力运算与大规模KV缓存存储,LPU则在带宽密集型、静态调度的FFN权重运算中具备优势。更重要的是,FFN层权重是模型架构的固定常量,与上下文长度无关(1000令牌与100万令牌场景的FFN运算量一致),而注意力运算量随上下文长度线性增长。因此,随着上下文窗口扩大,GPU仅需承担额外的KV缓存存储与注意力计算成本,LPX的负载保持稳定,彻底解决了纯SRAM加速器难以适配超长上下文的痛点。
3. Dynamo:异构解码的调度核心
异构架构的高效运行依赖NVIDIA Dynamo编排层:预填充阶段,Dynamo将任务路由至GPU节点构建KV缓存;解码阶段,Dynamo协调AFD循环,实现GPU与LPU间的张量传输、任务调度与结果整合,形成统一的推理服务链路。
此外,Dynamo还提供KV感知路由(将请求分发至已有相关KV缓存的节点)、延迟目标驱动调度(保障交互式会话响应速度)、低开销传输管理等功能,确保在复杂生产环境中(变长上下文、混合请求类型、突发并发)的尾延迟稳定性。
主流模型FFN规模与LPX配置测算
通过分析Hugging Face上主流开源模型的config.json与model.safetensors.index.json文件,我们整理了FFN层的关键参数的规模: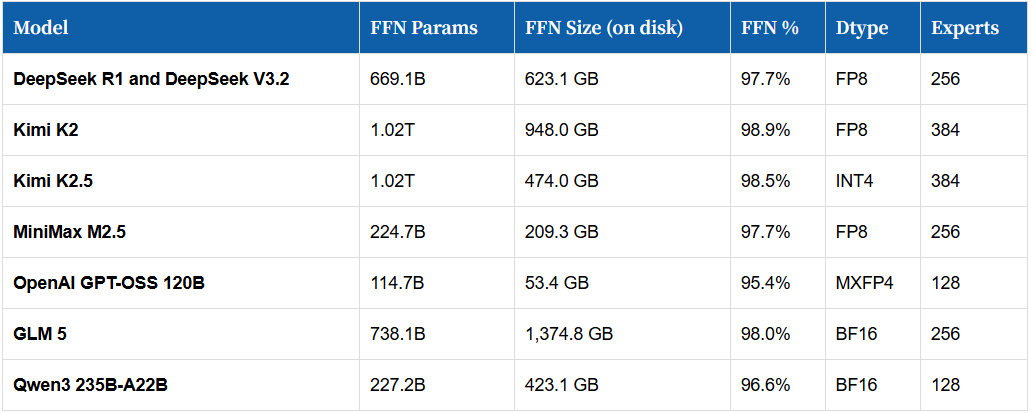
结合单台LPX机架128 GB的总SRAM容量,可得出初步配置建议:
●OpenAI GPT-OSS 120B(53 GB FFN):单台LPX机架即可满足需求;
●DeepSeek R1(623.1 GB FFN):需5台LPX机架级联;
●GLM 5(1.37 TB FFN,BF16):需11台LPX机架,若量化为FP8则可减半至5-6台。
这也印证了机架间互联端口的设计必要性——通过级联多台LPX机架,可满足不同规模模型的FFN层运算需求。
LPX的第二场景:推测解码加速
除AFD解码循环外,LPX的另一核心应用是作为推测解码的草稿模型生成引擎。推测解码的核心逻辑是:小型快速草稿模型提前生成多个候选令牌,大型目标模型并行验证并确认有效令牌,若草稿模型预测准确,可单次提交多个令牌,显著提升有效令牌生成速率并降低延迟。
这一技术的关键瓶颈是草稿模型的生成速度,而LPX的确定性执行与超高SRAM带宽恰好完美适配:小型草稿模型可完整驻留于单LPX托盘或少量托盘的SRAM中,确定性调度确保草稿生成速度稳定可预测,避免因硬件波动导致的验证等待。在这种配置下,LPX负责快速生成候选令牌,Rubin GPU专注于令牌验证与最终生成,二者协同工作,相比GPU单硬件方案,大幅提升推测解码的效率与吞吐量。
软硬件协同的极致探索
NVIDIA推出Groq 3 LPX的核心逻辑,是对万亿参数MoE模型推理瓶颈的精准洞察与硬件优化。注意力-FFN拆分并非营销概念,而是基于实际负载特征的架构创新——将带宽密集、静态调度的FFN层卸载至LPU,将容量密集、动态变化的注意力运算保留给GPU,这种分工使两类硬件的优势得到最大化发挥。从CUDA生态的无缝兼容、Dynamo的异构编排,到MGX机架的无电缆设计,不难看出NVIDIA对全部署生命周期的深度考量。
当然,LPX仍存在诸多待验证的未知点:“Fabric Expansion Logic and DRAM”的具体功能与芯片选型、x86插槽对应的Intel处理器型号、生产环境下的实际性能与能效比等,均需独立测试验证。初期LPX将聚焦模型开发者与服务提供商,而非广泛商用,但这并不妨碍其成为万亿参数模型低延迟推理的里程碑产品。
面对即将来临的万亿参数模型应用浪潮,我们致力于为企业提供从算力架构规划到液冷数据中心部署的全栈解决方案。如果您对 Vera Rubin 或 Groq 3 LPX 的落地应用有任何疑问,欢迎关注并与我们深入探讨。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)