有没有好用的开源爬虫库?自媒体内容抓取实战指南(附推荐工具)
在做数据采集或者内容聚合的时候,很多人都会问:
有没有好用的开源爬虫库?尤其是能抓取抖音、B站、知乎、小红书这些自媒体平台的?
答案是:有,而且非常多,但要选对组合。
本文从实战角度,给你整理一套「开源爬虫技术栈 + 自媒体抓取方案」。
一、常见开源爬虫库推荐(Python为主)
1. Requests + BeautifulSoup(入门组合)

特点:
-
简单易上手
-
适合静态页面
-
学习成本低
适合场景:
-
爬文章列表
-
抓新闻内容
-
API接口数据
👉 Requests 用于发送请求,BeautifulSoup 用于解析HTML
2. Scrapy(工业级爬虫框架)
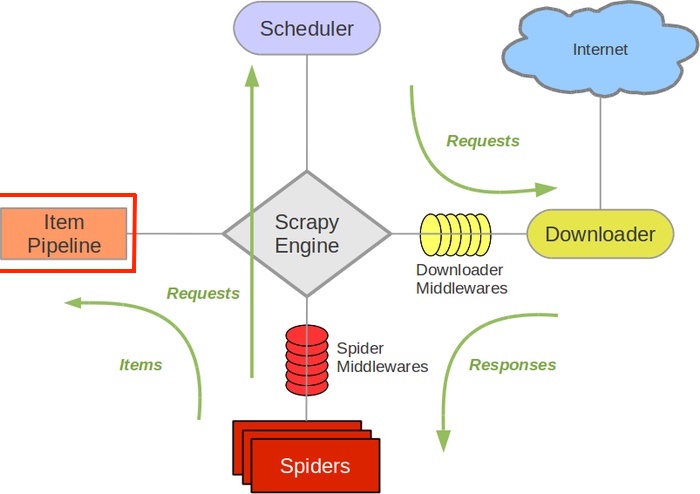
核心优势:
-
异步高性能
-
支持分布式
-
内置数据管道
Scrapy 是目前最主流的开源爬虫框架之一,适合大规模数据采集
适合场景:
-
批量采集自媒体内容
-
搭建内容聚合网站
-
SEO数据抓取
3. Playwright / Selenium(动态页面神器)
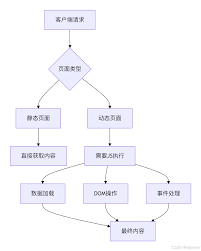
为什么必须用?
因为现在很多自媒体平台:
-
数据是 JS 渲染
-
接口加密
-
有反爬策略
👉 Playwright 比 Selenium 更快、更现代
适合场景:
-
抖音 / 快手 / 小红书
-
需要登录的页面
-
JS动态加载数据
4. aiohttp(高并发异步爬虫)
特点:
-
基于 asyncio
-
高并发请求
-
性能极高
适合:
-
接口型爬虫
-
批量抓取视频API
5. Scrapy + Redis(分布式爬虫)
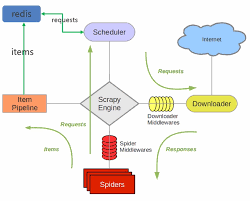
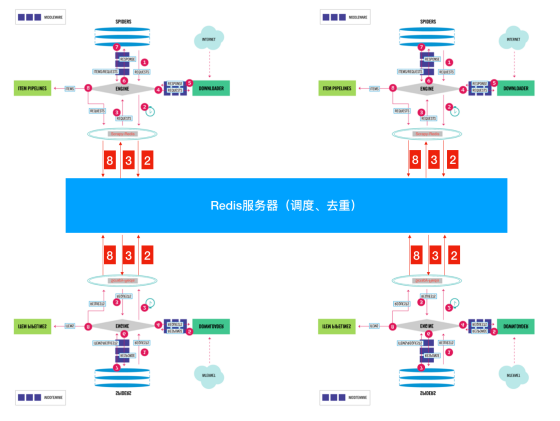
优势:
-
多机器协同
-
URL去重
-
队列管理
👉 可实现类似搜索引擎级别抓取
二、自媒体平台爬虫怎么做?
重点来了👇
1. 不同平台的抓取方式
| 平台 | 抓取方式 |
|---|---|
| 抖音 / 快手 | 接口 + 签名逆向 |
| B站 | API + m3u8 |
| 小红书 | Web接口 + cookie |
| 知乎 | JSON接口 |
| 头条 | 接口签名 |
2. 三种主流方案
方案一:接口抓取(推荐)
抓包 → 找API → 还原参数 → 请求数据
优点:
-
稳定
-
速度快
方案二:浏览器自动化
Playwright 模拟打开页面 → 获取数据
优点:
-
简单粗暴
-
不怕JS
缺点:
-
慢
方案三:m3u8视频解析(视频类)
适用于:
-
抖音/B站/头条视频
流程:
页面 → 播放 → m3u8 → ts → 合成mp4
三、自媒体爬虫的核心难点
主要问题:
1️⃣ 参数加密(sign / token)
2️⃣ IP限制(封IP)
3️⃣ 登录校验
4️⃣ 动态渲染
👉 解决思路:
-
逆向JS
-
使用代理池
-
模拟浏览器
-
Cookie复用
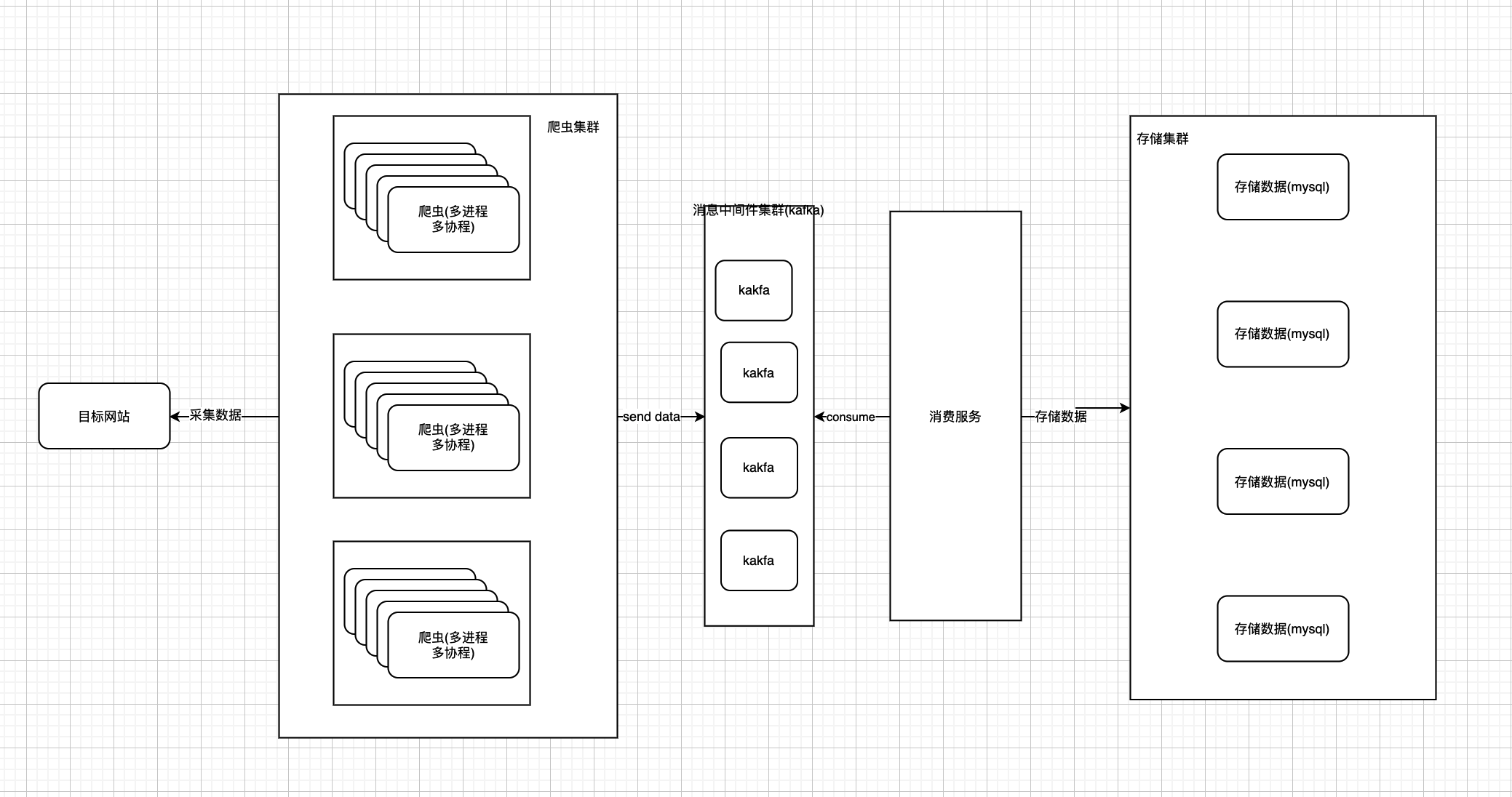
四、推荐技术组合(实战)
如果你是做自媒体内容抓取,推荐:
⭐ 最佳组合:
Scrapy + Playwright + 代理池 + Redis
👉 原因:
-
Scrapy负责调度
-
Playwright解决动态页面
-
Redis实现分布式
-
代理池绕过封IP
五、总结
如果你问:
有没有好用的开源爬虫库?
✔️ 有,而且推荐这样选:
| 需求 | 推荐 |
|---|---|
| 入门 | Requests |
| 中级 | Scrapy |
| 动态页面 | Playwright |
| 高并发 | aiohttp |
| 大规模 | Scrapy + Redis |
🔚 最后一句(实话)
👉 自媒体爬虫不是“写代码”这么简单,本质是:
逆向 + 抓包 + 协议分析 + 反反爬
如果你已经在做抖音/快手这类抓取,其实已经进入“爬虫进阶区”了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)