ceph-基于rockylinux8.7构建企业级分布式存储
目录
1.安装前准备工作(所有节点)
1.1环境描述
|
主机名 |
IP地址 |
操作系统 |
磁盘 |
备注 |
|
ceph01 |
10.9.254.81 |
rockylinux8.7 |
sdb 100G sdc 100G |
|
|
ceph02 |
10.9.254.82 |
rockylinux8.7 |
sdb 100G sdc 100G |
|
|
ceph03 |
10.9.254.83 |
rockylinux8.7 |
sdb 100G sdc 100G |
|
|
ceph04 |
10.9.254.84 |
rockylinux8.7 |
sdb 100G sdc 100G |
|
|
ceph05 |
10.9.254.85 |
rockylinux8.7 |
sdb 100G sdc 100G |
1.2修改主机名和hosts(所有节点)
|
[root@poc /etc/sysconfig/network-scripts]# hostnamectl set-hostname ceph01 [root@poc /etc/sysconfig/network-scripts]# bash [root@ceph01 ~]# vim /etc/hosts |
|
#public network 10.9.254.81 ceph01 10.9.254.82 ceph02 10.9.254.83 ceph03 10.9.254.84 ceph04 10.9.254.85 ceph05 #cluster network 192.168.254.81 ceph01-cl 192.168.254.82 ceph02-cl 192.168.254.83 ceph03-cl 192.168.254.84 ceph04-cl 192.168.254.85 ceph05-cl |
|
[root@ceph01 ~]# ip a |
|
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 00:50:56:98:2b:ba brd ff:ff:ff:ff:ff:ff altname enp2s0 altname ens32 inet 10.9.254.81/24 brd 10.9.254.255 scope global noprefixroute eth0 valid_lft forever preferred_lft forever inet6 fe80::250:56ff:fe98:2bba/64 scope link noprefixroute valid_lft forever preferred_lft forever 3: eth1: mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 00:50:56:98:84:6b brd ff:ff:ff:ff:ff:ff altname enp2s2 altname ens34 inet 192.168.254.81/24 brd 192.168.254.255 scope global noprefixroute eth1 valid_lft forever preferred_lft forever inet6 fe80::250:56ff:fe98:846b/64 scope link noprefixroute valid_lft forever preferred_lft forever |
1.3关闭防火墙(所有节点)
|
[root@ceph01 ~]# systemctl disable --now firewalld [root@ceph01 ~]# setenforce 0 [root@ceph01 ~]# sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/sysconfig/selinux [root@ceph01 ~]# sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config [root@ceph01 ~]# cat /etc/selinux/config |
|
# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of these three values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy. Only selected processes are protected. # mls - Multi Level Security protection. SELINUXTYPE=targeted |
1.4修改内核参数及资源限制参数(所有节点)
|
[root@ceph01 ~]# vim /etc/modules-load.d/ceph.conf |
|
overlay br_netfilter |
|
[root@ceph01 ~]# modprobe overlay [root@ceph01 ~]# modprobe br_netfilter [root@ceph01 ~]# lsmod | grep br_netfilter |
|
br_netfilter 24576 0 bridge 290816 1 br_netfilter |
|
[root@ceph01 ~]# vim /etc/sysctl.d/ceph.conf |
|
net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 net.ipv4.ip_local_port_range = 1024 65335 net.netfilter.nf_conntrack_max = 2621440 net.nf_conntrack_max = 2621440 vm.max_map_count = 1048576 net.ipv4.tcp_wmem = 4096 16384 4194304 net.ipv4.tcp_rmem = 4096 87380 6291456 net.ipv4.tcp_mem = 381462 508616 762924 net.core.rmem_default = 8388608 net.core.rmem_max = 26214400 net.core.wmem_max = 26214400 fs.nr_open = 16777216 fs.file-max = 16777216 net.ipv4.neigh.default.gc_thresh1 = 40960 net.ipv4.neigh.default.gc_thresh2 = 81920 net.ipv4.neigh.default.gc_thresh3 = 102400 net.ipv4.tcp_max_syn_backlog = 65535 net.core.somaxconn = 65535 net.core.netdev_max_backlog = 250000 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_tw_reuse = 0 net.ipv4.tcp_fin_timeout = 30 net.ipv4.tcp_fastopen = 3 net.ipv4.tcp_orphan_retries = 3 net.ipv4.tcp_abort_on_overflow = 1 |
|
[root@ceph01 ~]# sysctl -p /etc/sysctl.d/ceph.conf |
|
net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 net.ipv4.ip_local_port_range = 1024 65335 sysctl: cannot stat /proc/sys/net/netfilter/nf_conntrack_max: No such file or directory sysctl: cannot stat /proc/sys/net/nf_conntrack_max: No such file or directory vm.max_map_count = 1048576 net.ipv4.tcp_wmem = 4096 16384 4194304 net.ipv4.tcp_rmem = 4096 87380 6291456 net.ipv4.tcp_mem = 381462 508616 762924 net.core.rmem_default = 8388608 net.core.rmem_max = 26214400 net.core.wmem_max = 26214400 fs.nr_open = 16777216 fs.file-max = 16777216 net.ipv4.neigh.default.gc_thresh1 = 40960 net.ipv4.neigh.default.gc_thresh2 = 81920 net.ipv4.neigh.default.gc_thresh3 = 102400 net.ipv4.tcp_max_syn_backlog = 65535 net.core.somaxconn = 65535 net.core.netdev_max_backlog = 250000 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_tw_reuse = 0 net.ipv4.tcp_fin_timeout = 30 net.ipv4.tcp_fastopen = 3 net.ipv4.tcp_orphan_retries = 3 net.ipv4.tcp_abort_on_overflow = 1 |
|
[root@ceph01 ~]# vim /etc/security/limits.d/ceph.conf |
|
* hard nofile 655360 * soft nofile 655360 * soft core 655360 * hard core 655360 * soft nproc unlimited root soft nproc unlimited |
1.5配置时钟同步(所有节点)
|
[root@ceph01 ~]# dnf -y install chrony |
|
Installed: chrony-4.1-1.el8.x86_64 timedatex-0.5-3.el8.x86_64 Complete! |
|
[root@ceph01 ~]# ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime [root@ceph01 ~]# echo 'Asia/Shanghai' >/etc/timezone [root@ceph01 ~]# systemctl start chronyd [root@ceph01 ~]# systemctl enable chronyd [root@ceph01 ~]# vi /etc/chrony.conf |
|
#pool 2.pool.ntp.org iburst server ntp.aliyun.com iburst server cn.ntp.org.cn iburst |
|
[root@ceph01 ~]# systemctl restart chronyd [root@ceph01 ~]# chronyc sources -v |
|
.-- Source mode '^' = server, '=' = peer, '#' = local clock. / .- Source state '*' = current best, '+' = combined, '-' = not combined, | / 'x' = may be in error, '~' = too variable, '?' = unusable. || .- xxxx [ yyyy ] +/- zzzz || Reachability register (octal) -. | xxxx = adjusted offset, || Log2(Polling interval) --. | | yyyy = measured offset, || \ | | zzzz = estimated error. || | | MS Name/IP address Stratum Poll Reach LastRx Last sample ^- 203.107.6.88 2 6 17 4 +3408us[+3408us] +/- 19ms ^* 106.75.107.80 2 6 17 5 -940us[-2018us] +/- 17ms |
1.6containerd安装(所有节点)
1.6.1containerd下载
https://github.com/containerd/containerd/releases
1.6.2containerd安装
|
[root@ceph01 ~]# ll |
|
-rw-r--r-- 1 root root 104215835 Sep 28 15:55 cri-containerd-1.7.6-linux-amd64.tar.gz |
|
[root@ceph01 ~]# tar xf cri-containerd-1.7.6-linux-amd64.tar.gz -C / [root@ceph01 ~]# ls -lt /usr/local/bin/ |
|
-rwxr-xr-x 1 root root 26243584 Sep 13 01:54 ctd-decoder -rwxr-xr-x 1 root root 54137463 Sep 13 01:54 crictl -rwxr-xr-x 1 root root 56286175 Sep 13 01:54 critest -rwxr-xr-x 1 root root 38972912 Sep 13 01:51 containerd -rwxr-xr-x 1 root root 6598656 Sep 13 01:51 containerd-shim -rwxr-xr-x 1 root root 8306688 Sep 13 01:51 containerd-shim-runc-v1 -rwxr-xr-x 1 root root 12062720 Sep 13 01:51 containerd-shim-runc-v2 -rwxr-xr-x 1 root root 17653760 Sep 13 01:51 containerd-stress -rwxr-xr-x 1 root root 18681856 Sep 13 01:51 ctr |
|
[root@ceph01 ~]# ls -lt /usr/local/sbin |
|
-rwxr-xr-x 1 root root 13511400 Sep 13 01:51 runc |
|
[root@ceph01 ~]# runc |
|
NAME: runc - Open Container Initiative runtime runc is a command line client for running applications packaged according to the Open Container Initiative (OCI) format and is a compliant implementation of the Open Container Initiative specification. runc integrates well with existing process supervisors to provide a production container runtime environment for applications. It can be used with your existing process monitoring tools and the container will be spawned as a direct child of the process supervisor. Containers are configured using bundles. A bundle for a container is a directory that includes a specification file named "config.json" and a root filesystem. The root filesystem contains the contents of the container. To start a new instance of a container: # runc run [ -b bundle ] Where "" is your name for the instance of the container that you are starting. The name you provide for the container instance must be unique on your host. Providing the bundle directory using "-b" is optional. The default value for "bundle" is the current directory. USAGE: runc [global options] command [command options] [arguments...] VERSION: 1.1.9 commit: v1.1.9-0-gccaecfcb spec: 1.0.2-dev go: go1.20.8 libseccomp: 2.5.2 COMMANDS: checkpoint checkpoint a running container create create a container delete delete any resources held by the container often used with detached container events display container events such as OOM notifications, cpu, memory, and IO usage statistics exec execute new process inside the container kill kill sends the specified signal (default: SIGTERM) to the container's init process list lists containers started by runc with the given root pause pause suspends all processes inside the container ps ps displays the processes running inside a container restore restore a container from a previous checkpoint resume resumes all processes that have been previously paused run create and run a container spec create a new specification file start executes the user defined process in a created container state output the state of a container update update container resource constraints features show the enabled features help, h Shows a list of commands or help for one command GLOBAL OPTIONS: --debug enable debug logging --log value set the log file to write runc logs to (default is '/dev/stderr') --log-format value set the log format ('text' (default), or 'json') (default: "text") --root value root directory for storage of container state (this should be located in tmpfs) (default: "/run/runc") --criu value path to the criu binary used for checkpoint and restore (default: "criu") --systemd-cgroup enable systemd cgroup support, expects cgroupsPath to be of form "slice:prefix:name" for e.g. "system.slice:runc:434234" --rootless value ignore cgroup permission errors ('true', 'false', or 'auto') (default: "auto") --help, -h show help --version, -v print the version |
|
[root@ceph01 ~]# ctr |
|
NAME: ctr - __ _____/ /______ / ___/ __/ ___/ / /__/ /_/ / \___/\__/_/ containerd CLI USAGE: ctr [global options] command [command options] [arguments...] VERSION: v1.7.6 DESCRIPTION: ctr is an unsupported debug and administrative client for interacting with the containerd daemon. Because it is unsupported, the commands, options, and operations are not guaranteed to be backward compatible or stable from release to release of the containerd project. COMMANDS: plugins, plugin Provides information about containerd plugins version Print the client and server versions containers, c, container Manage containers content Manage content events, event Display containerd events images, image, i Manage images leases Manage leases namespaces, namespace, ns Manage namespaces pprof Provide golang pprof outputs for containerd run Run a container snapshots, snapshot Manage snapshots tasks, t, task Manage tasks install Install a new package oci OCI tools sandboxes, sandbox, sb, s Manage sandboxes info Print the server info shim Interact with a shim directly help, h Shows a list of commands or help for one command GLOBAL OPTIONS: --debug Enable debug output in logs --address value, -a value Address for containerd's GRPC server (default: "/run/containerd/containerd.sock") [$CONTAINERD_ADDRESS] --timeout value Total timeout for ctr commands (default: 0s) --connect-timeout value Timeout for connecting to containerd (default: 0s) --namespace value, -n value Namespace to use with commands (default: "default") [$CONTAINERD_NAMESPACE] --help, -h show help --version, -v print the version |
|
[root@ceph01 ~]# crictl |
|
NAME: crictl - client for CRI USAGE: crictl [global options] command [command options] [arguments...] VERSION: 1.27.0 COMMANDS: attach Attach to a running container create Create a new container exec Run a command in a running container version Display runtime version information images, image, img List images inspect Display the status of one or more containers inspecti Return the status of one or more images imagefsinfo Return image filesystem info inspectp Display the status of one or more pods logs Fetch the logs of a container port-forward Forward local port to a pod ps List containers pull Pull an image from a registry run Run a new container inside a sandbox runp Run a new pod rm Remove one or more containers rmi Remove one or more images rmp Remove one or more pods pods List pods start Start one or more created containers info Display information of the container runtime stop Stop one or more running containers stopp Stop one or more running pods update Update one or more running containers config Get and set crictl client configuration options stats List container(s) resource usage statistics statsp List pod resource usage statistics completion Output shell completion code checkpoint Checkpoint one or more running containers help, h Shows a list of commands or help for one command GLOBAL OPTIONS: --config value, -c value Location of the client config file. If not specified and the default does not exist, the program's directory is searched as well (default: "/etc/crictl.yaml") [$CRI_CONFIG_FILE] --debug, -D Enable debug mode (default: false) --image-endpoint value, -i value Endpoint of CRI image manager service (default: uses 'runtime-endpoint' setting) [$IMAGE_SERVICE_ENDPOINT] --runtime-endpoint value, -r value Endpoint of CRI container runtime service (default: uses in order the first successful one of [unix:///var/run/dockershim.sock unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]). Default is now deprecated and the endpoint should be set instead. [$CONTAINER_RUNTIME_ENDPOINT] --timeout value, -t value Timeout of connecting to the server in seconds (e.g. 2s, 20s.). 0 or less is set to default (default: 2s) --help, -h show help --version, -v print the version |
|
[root@ceph01 ~]# vim /etc/crictl.yaml |
|
runtime-endpoint: unix:///run/containerd/containerd.sock image-endpoint: unix:///var/run/containerd/containerd.sock timeout: 10 debug: false |
|
[root@ceph01 ~]# mkdir /etc/containerd [root@ceph01 ~]# containerd config default > /etc/containerd/config.toml [root@ceph01 ~]# vim /etc/containerd/config.toml |
|
max_container_log_line_size = 163840 device_ownership_from_security_context = true SystemdCgroup = true 65 #sandbox_image = "registry.k8s.io/pause:3.8" 66 sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.8" 169 [plugins."io.containerd.grpc.v1.cri".registry.mirrors] 170 [plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"] 171 endpoint = ["https://7slsp6vu.mirror.aliyuncs.com"] |
|
[root@ceph01 ~]# vim /etc/systemd/system/containerd.service |
|
LimitNOFILE=655360 |
|
[root@ceph01 ~]# systemctl enable containerd && systemctl restart containerd [root@ceph01 /var/log]# ls -l /var/run/containerd |
|
srw-rw---- 1 root root 0 Sep 28 18:24 containerd.sock srw-rw---- 1 root root 0 Sep 28 18:24 containerd.sock.ttrpc drwx--x--x 2 root root 40 Sep 28 16:40 io.containerd.runtime.v1.linux drwx--x--x 2 root root 40 Sep 28 16:40 io.containerd.runtime.v2.task |
|
[root@ceph01 /var/log]# systemctl status containerd |
|
● containerd.service - containerd container runtime Loaded: loaded (/etc/systemd/system/containerd.service; enabled; vendor preset: disabled) Active: active (running) since Thu 2023-09-28 18:24:47 CST; 2min 20s ago Docs: https://containerd.io Process: 3698 ExecStartPre=/sbin/modprobe overlay (code=exited, status=0/SUCCESS) Main PID: 3700 (containerd) Tasks: 10 Memory: 19.8M CGroup: /system.slice/containerd.service └─3700 /usr/local/bin/containerd Sep 28 18:24:47 ceph01 containerd[3700]: time="2023-09-28T18:24:47.122049553+08:00" level=info msg="Start subscribing containerd ev> Sep 28 18:24:47 ceph01 containerd[3700]: time="2023-09-28T18:24:47.122290883+08:00" level=info msg="Start recovering state" Sep 28 18:24:47 ceph01 containerd[3700]: time="2023-09-28T18:24:47.122332027+08:00" level=info msg=serving... address=/run/containe> Sep 28 18:24:47 ceph01 containerd[3700]: time="2023-09-28T18:24:47.122381718+08:00" level=info msg=serving... address=/run/containe> Sep 28 18:24:47 ceph01 containerd[3700]: time="2023-09-28T18:24:47.122458973+08:00" level=info msg="Start event monitor" Sep 28 18:24:47 ceph01 containerd[3700]: time="2023-09-28T18:24:47.122516664+08:00" level=info msg="Start snapshots syncer" Sep 28 18:24:47 ceph01 containerd[3700]: time="2023-09-28T18:24:47.122541767+08:00" level=info msg="Start cni network conf syncer f> Sep 28 18:24:47 ceph01 containerd[3700]: time="2023-09-28T18:24:47.122556870+08:00" level=info msg="Start streaming server" Sep 28 18:24:47 ceph01 containerd[3700]: time="2023-09-28T18:24:47.122702480+08:00" level=info msg="containerd successfully booted > Sep 28 18:24:47 ceph01 systemd[1]: Started containerd container runtime. |
1.7安装docker
1.7.1下载docker
https://download.docker.com/linux/static/stable/x86_64/

https://download.docker.com/linux/static/stable/x86_64/docker-24.0.6.tgz
1.7.2docker安装(所有节点)
|
[root@ceph01 ~]# ll |
|
-rw-r--r-- 1 root root 69797795 Sep 28 18:32 docker-24.0.6.tgz |
|
[root@ceph01 ~]# tar xf docker-24.0.6.tgz [root@ceph01 ~]# ls -lt |
|
-rw-r--r-- 1 root root 69797795 Sep 28 18:32 docker-24.0.6.tgz -rw-r--r-- 1 root root 104215835 Sep 28 15:55 cri-containerd-1.7.6-linux-amd64.tar.gz drwxrwxr-x 2 1000 1000 146 Sep 4 20:34 docker |
|
[root@ceph01 ~]# ls -l docker |
|
-rwxr-xr-x 1 1000 1000 39129088 Sep 4 20:34 containerd -rwxr-xr-x 1 1000 1000 12374016 Sep 4 20:34 containerd-shim-runc-v2 -rwxr-xr-x 1 1000 1000 19140608 Sep 4 20:34 ctr -rwxr-xr-x 1 1000 1000 34752096 Sep 4 20:34 docker -rwxr-xr-x 1 1000 1000 63346888 Sep 4 20:34 dockerd -rwxr-xr-x 1 1000 1000 761712 Sep 4 20:34 docker-init -rwxr-xr-x 1 1000 1000 1965694 Sep 4 20:34 docker-proxy -rwxr-xr-x 1 1000 1000 15142440 Sep 4 20:34 runc |
|
[root@ceph01 ~]# mv docker/docker* /usr/bin/ [root@ceph01 ~]# useradd -s /sbin/nologin docker [root@ceph01 ~]# vim /usr/lib/systemd/system/docker.service |
|
[Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target docker.socket firewalld.service containerd.service Wants=network-online.target Requires=docker.socket [Service] Type=notify ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock ExecReload=/bin/kill -s HUP $MAINPID TimeoutSec=0 RestartSec=2 Restart=always StartLimitBurst=3 StartLimitInterval=60s LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity Delegate=yes KillMode=process [Install] WantedBy=sockets.target |
|
[root@ceph01 ~]# vim /usr/lib/systemd/system/docker.socket |
|
[Unit] Description=Docker Socket for the API PartOf=docker.service [Socket] ListenStream=/var/run/docker.sock SocketMode=0660 SocketUser=root SocketGroup=docker [Install] WantedBy=sockets.traget |
|
[root@ceph01 ~]# systemctl daemon-reload && systemctl enable docker --now |
|
Created symlink /etc/systemd/system/sockets.target.wants/docker.service → /usr/lib/systemd/system/docker.service. |
|
[root@ceph01 ~]# docker info |
|
Client: Version: 24.0.6 Context: default Debug Mode: false Server: Containers: 0 Running: 0 Paused: 0 Stopped: 0 Images: 0 Server Version: 24.0.6 Storage Driver: overlay2 Backing Filesystem: xfs Supports d_type: true Using metacopy: false Native Overlay Diff: true userxattr: false Logging Driver: json-file Cgroup Driver: cgroupfs Cgroup Version: 1 Plugins: Volume: local Network: bridge host ipvlan macvlan null overlay Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog Swarm: inactive Runtimes: io.containerd.runc.v2 runc Default Runtime: runc Init Binary: docker-init containerd version: 091922f03c2762540fd057fba91260237ff86acb runc version: v1.1.9-0-gccaecfcb init version: de40ad0 Security Options: seccomp Profile: builtin Kernel Version: 4.18.0-425.3.1.el8.x86_64 Operating System: Rocky Linux 8.7 (Green Obsidian) OSType: linux Architecture: x86_64 CPUs: 4 Total Memory: 7.769GiB Name: ceph01 ID: 434da3e4-5b29-448b-ad25-4268c357135b Docker Root Dir: /var/lib/docker Debug Mode: false Experimental: false Insecure Registries: 127.0.0.0/8 Live Restore Enabled: false Product License: Community Engine |
|
[root@ceph01 ~]# systemctl status docker |
|
● docker.service - Docker Application Container Engine Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled) Active: active (running) since Thu 2023-09-28 19:01:03 CST; 3min 44s ago Docs: https://docs.docker.com Main PID: 3880 (dockerd) Tasks: 10 (limit: 50662) Memory: 32.0M CGroup: /system.slice/docker.service └─3880 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock Sep 28 19:01:02 ceph01 systemd[1]: Starting Docker Application Container Engine... Sep 28 19:01:02 ceph01 dockerd[3880]: time="2023-09-28T19:01:02.382303308+08:00" level=info msg="Starting up" Sep 28 19:01:02 ceph01 dockerd[3880]: time="2023-09-28T19:01:02.552352691+08:00" level=info msg="Loading containers: start." Sep 28 19:01:03 ceph01 dockerd[3880]: time="2023-09-28T19:01:03.258877322+08:00" level=info msg="Loading containers: done." Sep 28 19:01:03 ceph01 dockerd[3880]: time="2023-09-28T19:01:03.302782480+08:00" level=info msg="Docker daemon" commit=1a79695 grap> Sep 28 19:01:03 ceph01 dockerd[3880]: time="2023-09-28T19:01:03.302943601+08:00" level=info msg="Daemon has completed initializatio> Sep 28 19:01:03 ceph01 dockerd[3880]: time="2023-09-28T19:01:03.423734187+08:00" level=info msg="API listen on /var/run/docker.sock" Sep 28 19:01:03 ceph01 systemd[1]: Started Docker Application Container Engine. |
|
[root@ceph01 ~]# mkdir /etc/docker [root@ceph01 ~]# vim /etc/docker/daemon.json |
|
{ "registry-mirrors":[ "https://docker.m.daocloud.io", ] } |
|
[root@ceph01 ~]# systemctl daemon-reload [root@ceph01 ~]# systemctl restart docker [root@ceph01 ~]# docker info |
|
Client: Version: 24.0.6 Context: default Debug Mode: false Server: Containers: 0 Running: 0 Paused: 0 Stopped: 0 Images: 0 Server Version: 24.0.6 Storage Driver: overlay2 Backing Filesystem: xfs Supports d_type: true Using metacopy: false Native Overlay Diff: true userxattr: false Logging Driver: json-file Cgroup Driver: cgroupfs Cgroup Version: 1 Plugins: Volume: local Network: bridge host ipvlan macvlan null overlay Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog Swarm: inactive Runtimes: io.containerd.runc.v2 runc Default Runtime: runc Init Binary: docker-init containerd version: 091922f03c2762540fd057fba91260237ff86acb runc version: v1.1.9-0-gccaecfcb init version: de40ad0 Security Options: seccomp Profile: builtin Kernel Version: 4.18.0-425.3.1.el8.x86_64 Operating System: Rocky Linux 8.7 (Green Obsidian) OSType: linux Architecture: x86_64 CPUs: 4 Total Memory: 7.769GiB Name: ceph01 ID: 434da3e4-5b29-448b-ad25-4268c357135b Docker Root Dir: /var/lib/docker Debug Mode: false Experimental: false Insecure Registries: 127.0.0.0/8 Registry Mirrors: "https://docker.m.daocloud.io" Live Restore Enabled: false Product License: Community Engine |
1.8配置ssh免密登录(ceph01)
|
[root@ceph01 ~]# ssh-keygen -t rsa |
|
Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:Rt8DfyPlaWVZw4cxa2D+e1++KoFMIlUNuSXedDQONi0 root@ceph01 The key's randomart image is: +---[RSA 3072]----+ | .o++=o++.| | . o.E++o+=| | . o B +.+.+| | . o = = = + | | . S o = B | | . o . = o | | . . o| | . oo| | ....+| +----[SHA256]-----+ |
|
[root@ceph01 ~]# for i in {1..5};do ssh-copy-id ceph0$i;done [root@ceph01 ~]# ssh ceph02 [root@ceph02 ~]# |
2.CEPH集群安装
O版本开始就不再支持ceph-deploy工具
2.1安装编排工具cephadm(所有节点)
cephadm安装前提
Python3
Systemd
Podman or Docker
Chrony or NTP
LVM2
|
[root@ceph01 ~]# vim /etc/yum.repos.d/ceph.repo |
|
[ceph] name=Ceph packages for $basearch baseurl=https://mirrors.aliyun.com/ceph/rpm-18.2.0/el8//x86_64 enabled=1 priority=2 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc [ceph-noarch] name=Ceph noarch packages baseurl=https://mirrors.aliyun.com/ceph/rpm-18.2.0/el8//noarch enabled=1 priority=2 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc [ceph-source] name=Ceph source packages baseurl=https://mirrors.aliyun.com/ceph/rpm-18.2.0/el8//SRPMS enabled=0 priority=2 gpgcheck=1 |
|
[root@ceph01 ~]# yum clean all [root@ceph01 ~]# yum makecache |
|
Ceph packages for x86_64 129 kB/s | 81 kB 00:00 Ceph noarch packages 19 kB/s | 9.6 kB 00:00 Rocky Linux 8 - AppStream 2.0 MB/s | 11 MB 00:05 Rocky Linux 8 - BaseOS 2.2 MB/s | 7.1 MB 00:03 Rocky Linux 8 - Extras 28 kB/s | 14 kB 00:00 Extra Packages for Enterprise Linux 8 - x86_64 1.8 MB/s | 16 MB 00:08 Metadata cache created. |
|
[root@ceph01 ~]# yum -y install cephadm |
|
Upgraded: platform-python-setuptools-39.2.0-7.el8.noarch Installed: cephadm-2:18.2.0-0.el8.noarch python3-pip-9.0.3-22.el8.rocky.0.noarch python3-setuptools-39.2.0-7.el8.noarch python36-3.6.8-38.module+el8.5.0+671+195e4563.x86_64 Complete! |
|
[root@ceph01 ~]# rpm -ql cephadm |
|
/usr/sbin/cephadm /usr/share/man/man8/cephadm.8.gz /var/lib/cephadm /var/lib/cephadm/.ssh /var/lib/cephadm/.ssh/authorized_keys |
|
[root@ceph01 ~]# cephadm install |
|
Installing packages ['cephadm']... |
导入镜像
|
[root@ceph01 ~]# docker images |
|
REPOSITORY TAG IMAGE ID CREATED SIZE quay.io/ceph/ceph v18 2ddfbd2845f4 12 days ago 1.25GB quay.io/ceph/ceph-grafana 9.4.7 2c41d148cca3 6 months ago 633MB quay.io/prometheus/prometheus v2.43.0 a07b618ecd1d 6 months ago 234MB quay.io/prometheus/alertmanager v0.25.0 c8568f914cd2 9 months ago 65.1MB quay.io/prometheus/node-exporter v1.5.0 0da6a335fe13 10 months ago 22.5MB |
检查ceph各节点是否满足安装ceph集群,该命令需要在当前节点执行,比如要判断ceph02是否支持安装ceph集群,则在ceph02上执行
|
[root@ceph02 ~]# cephadm check-host --expect-hostname ceph01 |
|
docker (/usr/bin/docker) is present systemctl is present lvcreate is present Unit chronyd.service is enabled and running Hostname "ceph01" matches what is expected. Host looks OK |
|
[root@ceph02 ~]# cephadm check-host --expect-hostname ceph02 |
|
docker (/usr/bin/docker) is present systemctl is present lvcreate is present Unit chronyd.service is enabled and running Hostname "ceph02" matches what is expected. Host looks OK |
|
[root@ceph03 ~]# cephadm check-host --expect-hostname ceph03 |
|
docker (/usr/bin/docker) is present systemctl is present lvcreate is present Unit chronyd.service is enabled and running Hostname "ceph03" matches what is expected. Host looks OK |
|
[root@ceph04 ~]# cephadm check-host --expect-hostname ceph04 |
|
docker (/usr/bin/docker) is present systemctl is present lvcreate is present Unit chronyd.service is enabled and running Hostname "ceph04" matches what is expected. Host looks OK |
|
[root@ceph05 ~]# cephadm check-host --expect-hostname ceph05 |
|
docker (/usr/bin/docker) is present systemctl is present lvcreate is present Unit chronyd.service is enabled and running Hostname "ceph05" matches what is expected. Host looks OK |
2.2使用cephadm初始化ceph最小集群
|
[root@ceph01 ~]# cephadm bootstrap --help |
|
usage: cephadm bootstrap [-h] [--config CONFIG] [--mon-id MON_ID] [--mon-addrv MON_ADDRV | --mon-ip MON_IP] [--mgr-id MGR_ID] [--fsid FSID] [--output-dir OUTPUT_DIR] [--output-keyring OUTPUT_KEYRING] [--output-config OUTPUT_CONFIG] [--output-pub-ssh-key OUTPUT_PUB_SSH_KEY] [--skip-admin-label] [--skip-ssh] [--initial-dashboard-user INITIAL_DASHBOARD_USER] [--initial-dashboard-password INITIAL_DASHBOARD_PASSWORD] [--ssl-dashboard-port SSL_DASHBOARD_PORT] [--dashboard-key DASHBOARD_KEY] [--dashboard-crt DASHBOARD_CRT] [--ssh-config SSH_CONFIG] [--ssh-private-key SSH_PRIVATE_KEY] [--ssh-public-key SSH_PUBLIC_KEY] [--ssh-user SSH_USER] [--skip-mon-network] [--skip-dashboard] [--dashboard-password-noupdate] [--no-minimize-config] [--skip-ping-check] [--skip-pull] [--skip-firewalld] [--allow-overwrite] [--allow-fqdn-hostname] [--allow-mismatched-release] [--skip-prepare-host] [--orphan-initial-daemons] [--skip-monitoring-stack] [--with-centralized-logging] [--apply-spec APPLY_SPEC] [--shared_ceph_folder CEPH_SOURCE_FOLDER] [--registry-url REGISTRY_URL] [--registry-username REGISTRY_USERNAME] [--registry-password REGISTRY_PASSWORD] [--registry-json REGISTRY_JSON] [--cluster-network CLUSTER_NETWORK] [--single-host-defaults] [--log-to-file] optional arguments: -h, --help show this help message and exit --config CONFIG, -c CONFIG ceph conf file to incorporate --mon-id MON_ID mon id (default: local hostname) --mon-addrv MON_ADDRV mon IPs (e.g., [v2:localipaddr:3300,v1:localipaddr:6789]) --mon-ip MON_IP mon IP --mgr-id MGR_ID mgr id (default: randomly generated) --fsid FSID cluster FSID --output-dir OUTPUT_DIR directory to write config, keyring, and pub key files --output-keyring OUTPUT_KEYRING location to write keyring file with new cluster admin and mon keys --output-config OUTPUT_CONFIG location to write conf file to connect to new cluster --output-pub-ssh-key OUTPUT_PUB_SSH_KEY location to write the cluster's public SSH key --skip-admin-label do not create admin label for ceph.conf and client.admin keyring distribution --skip-ssh skip setup of ssh key on local host --initial-dashboard-user INITIAL_DASHBOARD_USER Initial user for the dashboard --initial-dashboard-password INITIAL_DASHBOARD_PASSWORD Initial password for the initial dashboard user --ssl-dashboard-port SSL_DASHBOARD_PORT Port number used to connect with dashboard using SSL --dashboard-key DASHBOARD_KEY Dashboard key --dashboard-crt DASHBOARD_CRT Dashboard certificate --ssh-config SSH_CONFIG SSH config --ssh-private-key SSH_PRIVATE_KEY SSH private key --ssh-public-key SSH_PUBLIC_KEY SSH public key --ssh-user SSH_USER set user for SSHing to cluster hosts, passwordless sudo will be needed for non-root users --skip-mon-network set mon public_network based on bootstrap mon ip --skip-dashboard do not enable the Ceph Dashboard --dashboard-password-noupdate stop forced dashboard password change --no-minimize-config do not assimilate and minimize the config file --skip-ping-check do not verify that mon IP is pingable --skip-pull do not pull the default image before bootstrapping --skip-firewalld Do not configure firewalld --allow-overwrite allow overwrite of existing --output-* config/keyring/ssh files --allow-fqdn-hostname allow hostname that is fully-qualified (contains ".") --allow-mismatched-release allow bootstrap of ceph that doesn't match this version of cephadm --skip-prepare-host Do not prepare host --orphan-initial-daemons Set mon and mgr service to `unmanaged`, Do not create the crash service --skip-monitoring-stack Do not automatically provision monitoring stack (prometheus, grafana, alertmanager, node-exporter) --with-centralized-logging Automatically provision centralized logging (promtail, loki) --apply-spec APPLY_SPEC Apply cluster spec after bootstrap (copy ssh key, add hosts and apply services) --shared_ceph_folder CEPH_SOURCE_FOLDER Development mode. Several folders in containers are volumes mapped to different sub-folders in the ceph source folder --registry-url REGISTRY_URL url for custom registry --registry-username REGISTRY_USERNAME username for custom registry --registry-password REGISTRY_PASSWORD password for custom registry --registry-json REGISTRY_JSON json file with custom registry login info (URL, Username, Password) --cluster-network CLUSTER_NETWORK subnet to use for cluster replication, recovery and heartbeats (in CIDR notation network/mask) --single-host-defaults adjust configuration defaults to suit a single-host cluster --log-to-file configure cluster to log to traditional log files in /var/log/ceph/$fsid |
2.2.1初始化单节点集群
cephadm bootstrap过程是在单一节点上创建一个小型的ceph集群,包括一个ceph monitor和一个ceph mgr,以及监控组件,包括prometheus、node-exporter等。
#初始化时,指定了mon-ip、集群网段、dashboard初始用户名和密码
|
[root@ceph01 ~]# cephadm bootstrap --mon-ip 10.9.254.81 --cluster-network 192.168.254.0/24 --initial-dashboard-user admin --initial-dashboard-password Cywetc.c0m |
|
Creating directory /etc/ceph for ceph.conf Verifying podman|docker is present... Verifying lvm2 is present... Verifying time synchronization is in place... Unit chronyd.service is enabled and running Repeating the final host check... docker (/usr/bin/docker) is present systemctl is present lvcreate is present Unit chronyd.service is enabled and running Host looks OK Cluster fsid: 4b4cc258-6679-11ee-ad4a-005056982bba Verifying IP 10.9.254.81 port 3300 ... Verifying IP 10.9.254.81 port 6789 ... Mon IP `10.9.254.81` is in CIDR network `10.9.254.0/24` Mon IP `10.9.254.81` is in CIDR network `10.9.254.0/24` Pulling container image quay.io/ceph/ceph:v18... Ceph version: ceph version 18.2.0 (5dd24139a1eada541a3bc16b6941c5dde975e26d) reef (stable) Extracting ceph user uid/gid from container image... Creating initial keys... Creating initial monmap... Creating mon... Waiting for mon to start... Waiting for mon... mon is available Assimilating anything we can from ceph.conf... Generating new minimal ceph.conf... Restarting the monitor... Setting mon public_network to 10.9.254.0/24 Setting cluster_network to 192.168.254.0/24 Wrote config to /etc/ceph/ceph.conf Wrote keyring to /etc/ceph/ceph.client.admin.keyring Creating mgr... Verifying port 9283 ... Verifying port 8765 ... Verifying port 8443 ... Waiting for mgr to start... Waiting for mgr... mgr not available, waiting (1/15)... mgr not available, waiting (2/15)... mgr not available, waiting (3/15)... mgr not available, waiting (4/15)... mgr not available, waiting (5/15)... mgr not available, waiting (6/15)... mgr is available Enabling cephadm module... Waiting for the mgr to restart... Waiting for mgr epoch 5... mgr epoch 5 is available Setting orchestrator backend to cephadm... Generating ssh key... Wrote public SSH key to /etc/ceph/ceph.pub Adding key to root@localhost authorized_keys... Adding host ceph01... Deploying mon service with default placement... Deploying mgr service with default placement... Deploying crash service with default placement... Deploying ceph-exporter service with default placement... Deploying prometheus service with default placement... Deploying grafana service with default placement... Deploying node-exporter service with default placement... Deploying alertmanager service with default placement... Enabling the dashboard module... Waiting for the mgr to restart... Waiting for mgr epoch 9... mgr epoch 9 is available Generating a dashboard self-signed certificate... Creating initial admin user... Fetching dashboard port number... Ceph Dashboard is now available at: URL: https://ceph01:8443/ User: admin Password: Cywetc.c0m Enabling client.admin keyring and conf on hosts with "admin" label Saving cluster configuration to /var/lib/ceph/4b4cc258-6679-11ee-ad4a-005056982bba/config directory Enabling autotune for osd_memory_target You can access the Ceph CLI as following in case of multi-cluster or non-default config: sudo /usr/sbin/cephadm shell --fsid 4b4cc258-6679-11ee-ad4a-005056982bba -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring Or, if you are only running a single cluster on this host: sudo /usr/sbin/cephadm shell Please consider enabling telemetry to help improve Ceph: ceph telemetry on For more information see: https://docs.ceph.com/en/latest/mgr/telemetry/ Bootstrap complete. |



将密码修改成Cywetc.c0m@
查看集群状态,进入容器查看
|
[root@ceph01 ~]# cephadm shell |
|
Inferring fsid 94c0209a-64e1-11ee-a238-005056982bba Inferring config /var/lib/ceph/94c0209a-64e1-11ee-a238-005056982bba/mon.ceph01/config Using ceph image with id '2ddfbd2845f4' and tag 'v18' created on 2023-09-27 00:11:26 +0800 CST quay.io/ceph/ceph@sha256:f239715e1c7756e32a202a572e2763a4ce15248e09fc6e8990985f8a09ffa784 [ceph: root@ceph01 /]# ceph -s cluster: id: 94c0209a-64e1-11ee-a238-005056982bba health: HEALTH_WARN OSD count 0 < osd_pool_default_size 3 services: mon: 1 daemons, quorum ceph01 (age 11m) mgr: ceph01.cvsxkx(active, since 7m) osd: 0 osds: 0 up, 0 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 0 B used, 0 B / 0 B avail pgs: [ceph: root@ceph01 /]# |
|
[ceph: root@ceph01 /]# ceph orch ps |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID alertmanager.ceph01 ceph01 *:9093,9094 running (8m) 6m ago 10m 15.2M - 0.25.0 c8568f914cd2 fb5005d76e7a ceph-exporter.ceph01 ceph01 running (11m) 6m ago 11m 6515k - 18.2.0 2ddfbd2845f4 d51ccac8cd1f crash.ceph01 ceph01 running (11m) 6m ago 11m 7088k - 18.2.0 2ddfbd2845f4 6b7423f6d37e grafana.ceph01 ceph01 *:3000 running (7m) 6m ago 9m 74.2M - 9.4.7 2c41d148cca3 091d300a7385 mgr.ceph01.cvsxkx ceph01 *:9283,8765,8443 running (12m) 6m ago 12m 449M - 18.2.0 2ddfbd2845f4 17c249dcd085 mon.ceph01 ceph01 running (12m) 6m ago 12m 34.2M 2048M 18.2.0 2ddfbd2845f4 3f636825cfea node-exporter.ceph01 ceph01 *:9100 running (10m) 6m ago 11m 16.0M - 1.5.0 0da6a335fe13 6b5265321413 prometheus.ceph01 ceph01 *:9095 running (8m) 6m ago 8m 31.0M - 2.43.0 a07b618ecd1d b12bc5375181 |
|
[ceph: root@ceph01 /]# ceph orch ls #列出服务 |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 7m ago 12m count:1 ceph-exporter 1/1 7m ago 12m * crash 1/1 7m ago 12m * grafana ?:3000 1/1 7m ago 12m count:1 mgr 1/2 7m ago 12m count:2 mon 1/5 7m ago 12m count:5 node-exporter ?:9100 1/1 7m ago 12m * prometheus ?:9095 1/1 7m ago 12m count:1 |
|
[ceph: root@ceph01 /]# ceph mgr services |
|
{ "dashboard": "https://10.9.254.81:8443/", "prometheus": "http://10.9.254.81:9283/" } |
|
[ceph: root@ceph01 /]# ls -l /etc/ceph |
|
-rw------- 1 ceph ceph 217 Oct 7 07:26 ceph.conf -rw------- 1 root root 151 Oct 7 07:26 ceph.keyring -rw-r--r-- 1 root root 92 Aug 3 19:43 rbdmap |
|
[root@ceph01 ~]# ls -l /etc/ceph |
|
-rw------- 1 root root 151 Oct 7 15:26 ceph.client.admin.keyring -rw-r--r-- 1 root root 173 Oct 7 15:26 ceph.conf -rw-r--r-- 1 root root 595 Oct 7 15:22 ceph.pub |
|
[root@ceph01 ~]# cat /etc/ceph/ceph.conf |
|
# minimal ceph.conf for 94c0209a-64e1-11ee-a238-005056982bba [global] fsid = 94c0209a-64e1-11ee-a238-005056982bba mon_host = [v2:10.9.254.81:3300/0,v1:10.9.254.81:6789/0] |
2.3添加节点到集群
将公钥复制到其它节点
|
[ceph: root@ceph01 /]# ls -l /etc/ceph |
|
-rw------- 1 ceph ceph 217 Oct 9 07:58 ceph.conf -rw------- 1 root root 151 Oct 9 07:58 ceph.keyring -rw-r--r-- 1 root root 92 Aug 3 19:43 rbdmap |
|
[root@ceph01 ~]# ll /etc/ceph |
|
-rw------- 1 root root 151 Oct 9 15:58 ceph.client.admin.keyring -rw-r--r-- 1 root root 173 Oct 9 15:58 ceph.conf -rw-r--r-- 1 root root 595 Oct 9 15:57 ceph.pub |
|
[root@ceph01 ~]# cat /etc/ceph/ceph.conf |
|
# minimal ceph.conf for 4b4cc258-6679-11ee-ad4a-005056982bba [global] fsid = 4b4cc258-6679-11ee-ad4a-005056982bba mon_host = [v2:10.9.254.81:3300/0,v1:10.9.254.81:6789/0] |
|
[root@ceph01 ~]# for i in {2..5};do ssh-copy-id -f -i /etc/ceph/ceph.pub ceph0$i; done |
|
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/etc/ceph/ceph.pub" Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'ceph02'" and check to make sure that only the key(s) you wanted were added. /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/etc/ceph/ceph.pub" Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'ceph03'" and check to make sure that only the key(s) you wanted were added. /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/etc/ceph/ceph.pub" Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'ceph04'" and check to make sure that only the key(s) you wanted were added. /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/etc/ceph/ceph.pub" Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'ceph05'" and check to make sure that only the key(s) you wanted were added. |
|
[root@ceph05 ~]# cat /root/.ssh/authorized_keys |
|
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDBqVrsHNP6BehExuL0QhsNk++CLufUHMUWKo7Y2XMYcB7+Kwdy/TzQI+ee2GKd0R8uqflLWing8ouRe0YXNZBEd1VBIMnI/rqzV5kPfpgrXFQSbGvb285dtulMvO9mT+uc1toFWL8LjKDr5a8qsKSzeCHvYFMZMgU4atvDMp/rhyUtRl322fc0hXXq7bDt6+QFHLLCWNjowCjV2NAVUNavJSPNZe1RvbT1+dD/GUguLddMRECmuYaB4nR0faORvNrgsJpnn2ufZ9Hx75LbbwYyfgt/ffVAcG3OAZL5I4wqhz9U3dXjGUfpcuQOIHXYJ6C8Ae0VsaYRB8zCYRf2Aw10ccLadPb18AzOQJ2jC3IaXlYBmEHccZDq+jzKgqxWURiPF7W+erqcNiNiEG19yLsRjhixwsI9LAgZWFPk83homM2Lmd/2uYAbOJJ02r7DEfO3r6sz9eFwNeLYISkSLwOyvw5I90ebap3N9+f7bIWPhNRYtsmeEqCNjWSUtetoNkE= root@ceph01 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDASd7BS/Xp6nGR6TT8QWkGsq0kpwaoZlMbPDNjlWRctflnAh1NIIi/rEOkaAeP34QXs619Fj5RtPREiix6IN56UI0oC/o3/qyRd8IrYlm9zc0BNDrLD1t/KmrSEIW7hniRA+W6wZjxw6tv5N1Eo8XtHOgoaaWGtAFEyvzfRVwfOTRKZ7z/SaV+jfXIMmIwL+dn6Ed+qxIBjBxbxhqgmxMrokb42+fRYQp3/gZELETSaKsvZSj7uHTCYVjA45apGQE99hlJiCLqdn09PrpX2WJSTpuELmMLzrAYS60StzEJb+jmIrq+YZA/dyLpwCTsLe6SMJri0IYMMfN0L220gkHlNblBTxrpq9XGlPPBD1zGQ6h0nCogHy6syhaAXYaCnS0D2VGOX7E9DMgqtFD2MvOiVbtOq31BmeGt2k8YgKw3qf2lAFWTnDqJpE1I8PT4mU4o/wbm2ZJ/iGa9xfjsPk4iCICEchRy0EHMNbV9B2con6KJuerKz+CES06ud74zoC0= ceph-4b4cc258-6679-11ee-ad4a-005056982bba |
使用cephadm将主机添加到存储集群中,执行添加节点命令后,会再目标节点拉到ceph /node-exporter镜像,需要一定时间,所以可提前在节点上将镜像导入。
|
[root@ceph01 ~]# cephadm shell [ceph: root@ceph01 /]# ceph orch host add ceph02 10.9.254.82 --labels=mon,mgr |
|
Added host 'ceph02' with addr '10.9.254.82' |
|
[ceph: root@ceph01 /]# ceph orch ls |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 2m ago 2h count:1 ceph-exporter 1/1 2m ago 2h * crash 1/1 2m ago 2h * grafana ?:3000 1/1 2m ago 2h count:1 mgr 1/2 2m ago 2h count:2 mon 1/5 2m ago 2h count:5 node-exporter ?:9100 1/1 2m ago 2h * prometheus ?:9095 1/1 2m ago 2h count:1 |
|
[ceph: root@ceph01 /]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin ceph02 10.9.254.82 mon,mgr 2 hosts in cluster |
|
[ceph: root@ceph01 /]# ceph orch host add ceph03 10.9.254.83 --labels=mon |
|
Added host 'ceph03' with addr '10.9.254.83' |
|
[ceph: root@ceph01 /]# ceph orch host add ceph04 10.9.254.84 |
|
Added host 'ceph04' with addr '10.9.254.84' |
|
[ceph: root@ceph01 /]# ceph orch host add ceph05 10.9.254.85 |
|
Added host 'ceph05' with addr '10.9.254.85' |
|
[ceph: root@ceph01 /]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin ceph02 10.9.254.82 mon,mgr ceph03 10.9.254.83 mon ceph04 10.9.254.84 ceph05 10.9.254.85 5 hosts in cluster |
|
[root@ceph01 ~]# yum -y install ceph |
|
Upgraded: libibverbs-44.0-2.el8.1.x86_64 Installed: ceph-2:18.2.0-0.el8.x86_64 ceph-base-2:18.2.0-0.el8.x86_64 ceph-common-2:18.2.0-0.el8.x86_64 ceph-grafana-dashboards-2:18.2.0-0.el8.noarch ceph-mds-2:18.2.0-0.el8.x86_64 ceph-mgr-2:18.2.0-0.el8.x86_64 ceph-mgr-cephadm-2:18.2.0-0.el8.noarch ceph-mgr-dashboard-2:18.2.0-0.el8.noarch ceph-mgr-k8sevents-2:18.2.0-0.el8.noarch ceph-mgr-modules-core-2:18.2.0-0.el8.noarch ceph-mgr-rook-2:18.2.0-0.el8.noarch ceph-mon-2:18.2.0-0.el8.x86_64 ceph-osd-2:18.2.0-0.el8.x86_64 ceph-prometheus-alerts-2:18.2.0-0.el8.noarch ceph-selinux-2:18.2.0-0.el8.x86_64 gperftools-libs-1:2.7-9.el8.x86_64 libbabeltrace-1.5.4-4.el8.x86_64 libcephfs2-2:18.2.0-0.el8.x86_64 libcephsqlite-2:18.2.0-0.el8.x86_64 libconfig-1.5-9.el8.x86_64 libicu-60.3-2.el8_1.x86_64 liboath-2.6.2-3.el8.x86_64 librabbitmq-0.9.0-3.el8.x86_64 librados2-2:18.2.0-0.el8.x86_64 libradosstriper1-2:18.2.0-0.el8.x86_64 librbd1-2:18.2.0-0.el8.x86_64 librdkafka-0.11.4-3.el8.x86_64 librdmacm-44.0-2.el8.1.x86_64 librgw2-2:18.2.0-0.el8.x86_64 libstoragemgmt-1.9.1-3.el8.x86_64 libunwind-1.3.1-3.el8.x86_64 lttng-ust-2.8.1-11.el8.x86_64 nvme-cli-1.16-7.el8.x86_64 python3-asyncssh-2.7.0-2.el8.noarch python3-babel-2.5.1-7.el8.noarch python3-bcrypt-3.1.6-2.el8.1.x86_64 python3-beautifulsoup4-4.6.3-2.el8.1.noarch python3-cachetools-3.1.1-4.el8.noarch python3-ceph-argparse-2:18.2.0-0.el8.x86_64 python3-ceph-common-2:18.2.0-0.el8.x86_64 python3-cephfs-2:18.2.0-0.el8.x86_64 python3-certifi-2018.10.15-7.el8.noarch python3-cffi-1.11.5-5.el8.x86_64 python3-chardet-3.0.4-7.el8.noarch python3-cheroot-8.5.2-1.el8.noarch python3-cherrypy-18.4.0-1.el8.noarch python3-cryptography-3.2.1-5.el8.x86_64 python3-cssselect-0.9.2-10.el8.noarch python3-defusedxml-0.6.0-1.el8.noarch python3-google-auth-1:1.1.1-10.el8.noarch python3-html5lib-1:0.999999999-6.el8.noarch python3-idna-2.5-5.el8.noarch python3-influxdb-5.3.1-1.el8.noarch python3-isodate-0.6.0-1.el8.noarch python3-jaraco-6.2-6.el8.noarch python3-jaraco-functools-2.0-4.el8.noarch python3-jinja2-2.10.1-3.el8.noarch python3-jsonpatch-1.21-2.el8.noarch python3-jsonpointer-1.10-11.el8.noarch python3-jwt-1.6.1-2.el8.noarch python3-kubernetes-1:11.0.0-6.el8.noarch python3-libstoragemgmt-1.9.1-3.el8.x86_64 python3-logutils-0.3.5-11.el8.noarch python3-lxml-4.2.3-4.el8.x86_64 python3-mako-1.0.6-14.el8.noarch python3-markupsafe-0.23-19.el8.x86_64 python3-more-itertools-7.2.0-3.el8.noarch python3-msgpack-0.6.2-1.el8.x86_64 python3-natsort-7.1.1-2.el8.noarch python3-oauthlib-2.1.0-1.el8.noarch python3-pecan-1.3.2-9.el8.noarch python3-pkgconfig-1.5.1-5.el8.noarch python3-ply-3.9-9.el8.noarch python3-portend-2.6-1.el8.noarch python3-prettytable-0.7.2-14.el8.noarch python3-pyOpenSSL-19.0.0-1.el8.noarch python3-pyasn1-0.3.7-6.el8.noarch python3-pyasn1-modules-0.3.7-6.el8.noarch python3-pycparser-2.14-14.el8.noarch python3-pysocks-1.6.8-3.el8.noarch python3-pytz-2017.2-9.el8.noarch python3-pyyaml-3.12-12.el8.x86_64 python3-rados-2:18.2.0-0.el8.x86_64 python3-rbd-2:18.2.0-0.el8.x86_64 python3-repoze-lru-0.7-6.el8.noarch python3-requests-2.20.0-3.el8_8.noarch python3-requests-oauthlib-1.0.0-1.el8.noarch python3-rgw-2:18.2.0-0.el8.x86_64 python3-routes-2.4.1-12.el8.noarch python3-rsa-4.9-2.el8.noarch python3-saml-1.9.0-3.el8.noarch python3-simplegeneric-0.8.1-17.el8.noarch python3-singledispatch-3.4.0.3-18.el8.noarch python3-tempora-1.14.1-5.el8.noarch python3-trustme-0.6.0-4.el8.noarch python3-urllib3-1.24.2-5.el8.noarch python3-waitress-1.4.3-1.el8.noarch python3-webencodings-0.5.1-6.el8.noarch python3-webob-1.8.5-1.el8.1.noarch python3-websocket-client-0.56.0-5.el8.noarch python3-webtest-2.0.33-1.el8.noarch python3-werkzeug-0.12.2-4.el8.noarch python3-xmlsec-1.3.3-7.el8.x86_64 python3-zc-lockfile-2.0-2.el8.noarch smartmontools-1:7.1-1.el8.x86_64 thrift-0.13.0-2.el8.x86_64 userspace-rcu-0.10.1-4.el8.x86_64 Complete! |
|
[root@ceph01 ~]# ceph -v |
|
ceph version 18.2.0 (5dd24139a1eada541a3bc16b6941c5dde975e26d) reef (stable) |
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin ceph02 10.9.254.82 mon,mgr ceph03 10.9.254.83 mon ceph04 10.9.254.84 ceph05 10.9.254.85 5 hosts in cluster |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_WARN OSD count 0 < osd_pool_default_size 3 services: mon: 5 daemons, quorum ceph01,ceph03,ceph04,ceph05,ceph02 (age 3m) mgr: ceph01.ywwete(active, since 65m), standbys: ceph04.ykcgel osd: 0 osds: 0 up, 0 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 0 B used, 0 B / 0 B avail pgs: |
查看其它节点应用
|
[root@ceph02 ~]# docker ps -a |
|
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES b511e94994b0 quay.io/ceph/ceph "/usr/bin/ceph-mon -…" 5 minutes ago Up 5 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-mon-ceph02 3b4fd4cadb3e quay.io/ceph/ceph "/usr/bin/ceph-crash…" 5 minutes ago Up 5 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-crash-ceph02 2546817aab89 quay.io/ceph/ceph "/usr/bin/ceph-expor…" 5 minutes ago Up 5 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-ceph-exporter-ceph02 8cd0b6e2eb9f quay.io/prometheus/node-exporter:v1.5.0 "/bin/node_exporter …" 6 minutes ago Up 6 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-node-exporter-ceph02 |
|
[root@ceph03 ~]# docker ps -a |
|
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 344830d1f960 quay.io/ceph/ceph "/usr/bin/ceph-mon -…" 19 minutes ago Up 19 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-mon-ceph03 5d0023a9d9ac quay.io/prometheus/node-exporter:v1.5.0 "/bin/node_exporter …" 19 minutes ago Up 19 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-node-exporter-ceph03 51342f1a2ecd quay.io/ceph/ceph "/usr/bin/ceph-crash…" 19 minutes ago Up 19 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-crash-ceph03 e70e11057e78 quay.io/ceph/ceph "/usr/bin/ceph-expor…" 19 minutes ago Up 19 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-ceph-exporter-ceph03 |
|
[root@ceph04 ~]# docker ps -a |
|
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ce7f89b9d81f quay.io/ceph/ceph "/usr/bin/ceph-mgr -…" 9 minutes ago Up 9 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-mgr-ceph04-ykcgel c940390bea81 quay.io/ceph/ceph "/usr/bin/ceph-mon -…" 19 minutes ago Up 19 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-mon-ceph04 ad2a61c7a224 quay.io/prometheus/node-exporter:v1.5.0 "/bin/node_exporter …" 19 minutes ago Up 19 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-node-exporter-ceph04 4824930bada2 quay.io/ceph/ceph "/usr/bin/ceph-crash…" 19 minutes ago Up 19 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-crash-ceph04 f294ff260174 quay.io/ceph/ceph "/usr/bin/ceph-expor…" 20 minutes ago Up 20 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-ceph-exporter-ceph04 |
|
[root@ceph05 ~]# docker ps -a |
|
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 9f9c36ed2c19 quay.io/ceph/ceph "/usr/bin/ceph-mon -…" 10 minutes ago Up 10 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-mon-ceph05 dd0f095c4c68 quay.io/prometheus/node-exporter:v1.5.0 "/bin/node_exporter …" 10 minutes ago Up 10 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-node-exporter-ceph05 cf92ac9f3a67 quay.io/ceph/ceph "/usr/bin/ceph-crash…" 10 minutes ago Up 10 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-crash-ceph05 e87140fa642c quay.io/ceph/ceph "/usr/bin/ceph-expor…" 10 minutes ago Up 10 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-ceph-exporter-ceph05 |
2.4为节点添加标签并调整mon个数
给节点打上指标标签后,后续可以按标签进行编排。
给节点打_admin标签,默认情况下,_admin标签应用于存储集群中的bootstrapped主机,client.admin密钥被分发到该主机(ceph orch client-keyring{ls|set|rm})。将这个标签添加到其他主机后,其他主机的/etc/ceph下也将有client.admin密钥。
#给ceph02、ceph03加上_admin标签
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin ceph02 10.9.254.82 mon,mgr ceph03 10.9.254.83 mon ceph04 10.9.254.84 ceph05 10.9.254.85 5 hosts in cluster |
|
[root@ceph01 ~]# ceph orch host label add ceph02 _admin |
|
Added label _admin to host ceph02 |
|
[root@ceph01 ~]# ceph orch host label add ceph03 _admin |
|
Added label _admin to host ceph03 |
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin ceph04 10.9.254.84 ceph05 10.9.254.85 5 hosts in cluster |
查看ceph02和ceph03上的密钥文件
|
[root@ceph02 ~]# ll /etc/ceph/ |
|
-rw------- 1 root root 151 Oct 9 17:24 ceph.client.admin.keyring -rw-r--r-- 1 root root 357 Oct 9 17:24 ceph.conf -rw-r--r-- 1 root root 92 Aug 4 03:43 rbdmap |
|
[root@ceph03 ~]# ll /etc/ceph |
|
-rw------- 1 root root 151 Oct 9 17:24 ceph.client.admin.keyring -rw-r--r-- 1 root root 357 Oct 9 17:24 ceph.conf -rw-r--r-- 1 root root 92 Aug 4 03:43 rbdmap |
|
[root@ceph04 ~]# ll /etc/ceph |
|
-rw-r--r-- 1 root root 92 Aug 4 03:43 rbdmap |
|
[root@ceph05 ~]# ll /etc/ceph |
|
-rw-r--r-- 1 root root 92 Aug 4 03:43 rbdmap |
给ceph01-ceph03加上mon标签,ceph03加上mgr标签。
|
[root@ceph01 ~]# ceph orch host label add ceph01 mon |
|
Added label mon to host ceph01 |
|
[root@ceph01 ~]# ceph orch host label add ceph03 mgr |
|
Added label mgr to host ceph03 |
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 ceph05 10.9.254.85 5 hosts in cluster |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_WARN OSD count 0 < osd_pool_default_size 3 services: mon: 5 daemons, quorum ceph01,ceph03,ceph04,ceph05,ceph02 (age 30m) mgr: ceph01.ywwete(active, since 93m), standbys: ceph04.ykcgel osd: 0 osds: 0 up, 0 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 0 B used, 0 B / 0 B avail pgs: |
共有mon节点5个,我们只让带标签的添加mon角色
|
[root@ceph01 ~]# ceph orch apply mon --placement="3 label:mon" |
|
Scheduled mon update... |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_WARN 1 stray daemon(s) not managed by cephadm OSD count 0 < osd_pool_default_size 3 services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 24s) #已经变成了3个mon节点 mgr: ceph01.ywwete(active, since 96m), standbys: ceph04.ykcgel osd: 0 osds: 0 up, 0 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 0 B used, 0 B / 0 B avail pgs: |
2.5集群添加OSD
osd_pool_default_size 3修改为2
|
[root@ceph01 ~]# ceph config set global osd_pool_default_size 2 [root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_WARN 1 stray daemon(s) not managed by cephadm OSD count 0 < osd_pool_default_size 2 #osd数量小于副本数量2,所以警告 services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 2m) mgr: ceph01.ywwete(active, since 98m), standbys: ceph04.ykcgel osd: 0 osds: 0 up, 0 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 0 B used, 0 B / 0 B avail pgs: |
|
[root@ceph01 ~]# ceph orch device ls |
|
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS ceph01 /dev/sdb hdd 100G Yes 20m ago ceph01 /dev/sdc hdd 100G Yes 20m ago ceph02 /dev/sdb hdd 100G Yes 7m ago ceph02 /dev/sdc hdd 100G Yes 7m ago ceph03 /dev/sdb hdd 100G Yes 20m ago ceph03 /dev/sdc hdd 100G Yes 20m ago ceph04 /dev/sdb hdd 100G Yes 20m ago ceph04 /dev/sdc hdd 100G Yes 20m ago ceph05 /dev/sdb hdd 100G Yes 10m ago ceph05 /dev/sdc hdd 100G Yes 10m ago |
|
[root@ceph01 ~]# ceph orch daemon add osd ceph01:/dev/sdb |
|
Created osd(s) 0 on host 'ceph01' |
|
[root@ceph01 ~]# ceph orch daemon add osd ceph01:/dev/sdc |
|
Created osd(s) 1 on host 'ceph01' |
|
[root@ceph01 ~]# ceph orch daemon add osd ceph02:/dev/sdb [root@ceph01 ~]# ceph orch daemon add osd ceph02:/dev/sdc [root@ceph01 ~]# ceph orch daemon add osd ceph03:/dev/sdb [root@ceph01 ~]# ceph orch daemon add osd ceph03:/dev/sdc [root@ceph01 ~]# ceph orch daemon add osd ceph04:/dev/sdb [root@ceph01 ~]# ceph orch daemon add osd ceph04:/dev/sdc [root@ceph01 ~]# ceph orch daemon add osd ceph05:/dev/sdb [root@ceph01 ~]# ceph orch daemon add osd ceph05:/dev/sdc |
|
Created osd(s) 9 on host 'ceph05' |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_WARN 1 stray daemon(s) not managed by cephadm services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 17m) mgr: ceph01.ywwete(active, since 113m), standbys: ceph04.ykcgel osd: 10 osds: 10 up (since 37s), 10 in (since 88s) #已经添加了10个osd data: pools: 1 pools, 1 pgs objects: 2 objects, 449 KiB usage: 669 MiB used, 999 GiB / 1000 GiB avail pgs: 1 active+clean |
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.97687 root default -3 0.19537 host ceph01 0 hdd 0.09769 osd.0 up 1.00000 1.00000 1 hdd 0.09769 osd.1 up 1.00000 1.00000 -5 0.19537 host ceph02 2 hdd 0.09769 osd.2 up 1.00000 1.00000 3 hdd 0.09769 osd.3 up 1.00000 1.00000 -7 0.19537 host ceph03 4 hdd 0.09769 osd.4 up 1.00000 1.00000 5 hdd 0.09769 osd.5 up 1.00000 1.00000 -9 0.19537 host ceph04 6 hdd 0.09769 osd.6 up 1.00000 1.00000 7 hdd 0.09769 osd.7 up 1.00000 1.00000 -11 0.19537 host ceph05 8 hdd 0.09769 osd.8 up 1.00000 1.00000 9 hdd 0.09769 osd.9 up 1.00000 1.00000 |
|
[root@ceph01 ~]# ceph osd perf |
|
osd commit_latency(ms) apply_latency(ms) 9 0 0 8 0 0 7 0 0 6 0 0 1 0 0 0 0 0 2 0 0 3 0 0 4 0 0 5 0 0 |
2.6OSD分类
- ceph不能自动识别磁盘类型的情况
- 设置osd分类前osd需要是未分类的,即:修改osd分类的做法是,先移除原有的分类,在添加新的分类:
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.97687 root default -3 0.19537 host ceph01 0 hdd 0.09769 osd.0 up 1.00000 1.00000 1 hdd 0.09769 osd.1 up 1.00000 1.00000 -5 0.19537 host ceph02 2 hdd 0.09769 osd.2 up 1.00000 1.00000 3 hdd 0.09769 osd.3 up 1.00000 1.00000 -7 0.19537 host ceph03 4 hdd 0.09769 osd.4 up 1.00000 1.00000 5 hdd 0.09769 osd.5 up 1.00000 1.00000 -9 0.19537 host ceph04 6 hdd 0.09769 osd.6 up 1.00000 1.00000 7 hdd 0.09769 osd.7 up 1.00000 1.00000 -11 0.19537 host ceph05 8 hdd 0.09769 osd.8 up 1.00000 1.00000 9 hdd 0.09769 osd.9 up 1.00000 1.00000 |
|
[root@ceph01 ~]# ceph osd crush rm-device-class osd.8 |
|
done removing class of osd(s): 8 |
|
[root@ceph01 ~]# ceph osd crush set-device-class ssd osd.8 |
|
set osd(s) 8 to class 'ssd' |
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.97687 root default -3 0.19537 host ceph01 0 hdd 0.09769 osd.0 up 1.00000 1.00000 1 hdd 0.09769 osd.1 up 1.00000 1.00000 -5 0.19537 host ceph02 2 hdd 0.09769 osd.2 up 1.00000 1.00000 3 hdd 0.09769 osd.3 up 1.00000 1.00000 -7 0.19537 host ceph03 4 hdd 0.09769 osd.4 up 1.00000 1.00000 5 hdd 0.09769 osd.5 up 1.00000 1.00000 -9 0.19537 host ceph04 6 hdd 0.09769 osd.6 up 1.00000 1.00000 7 hdd 0.09769 osd.7 up 1.00000 1.00000 -11 0.19537 host ceph05 9 hdd 0.09769 osd.9 up 1.00000 1.00000 8 ssd 0.09769 osd.8 up 1.00000 1.00000 #类型已修改为ssd |
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.97687 root default -3 0.19537 host ceph01 1 hdd 0.09769 osd.1 up 1.00000 1.00000 0 ssd 0.09769 osd.0 up 1.00000 1.00000 -5 0.19537 host ceph02 3 hdd 0.09769 osd.3 up 1.00000 1.00000 2 ssd 0.09769 osd.2 up 1.00000 1.00000 -7 0.19537 host ceph03 5 hdd 0.09769 osd.5 up 1.00000 1.00000 4 ssd 0.09769 osd.4 up 1.00000 1.00000 -9 0.19537 host ceph04 7 hdd 0.09769 osd.7 up 1.00000 1.00000 6 ssd 0.09769 osd.6 up 1.00000 1.00000 -11 0.19537 host ceph05 9 hdd 0.09769 osd.9 up 1.00000 1.00000 8 ssd 0.09769 osd.8 up 1.00000 1.00000 |
2.7创建池
创建两个存储池一个ssd,另一个hdd
|
[root@ceph01 ~]# ceph osd pool create ssdpool 128 128 |
|
pool 'ssdpool' created |
|
[root@ceph01 ~]# ceph osd pool create hddpool 128 128 |
|
pool 'hddpool' created |
|
[root@ceph01 ~]# ceph osd lspools |
|
1 .mgr 2 ssdpool 3 hddpool |
2.8创建规则以使用该设备
|
[root@ceph01 ~]# ceph osd crush rule create-replicated ssd default host ssd [root@ceph01 ~]# ceph osd crush rule create-replicated hdd default host hdd [root@ceph01 ~]# ceph osd crush rule ls |
|
replicated_rule ssd hdd |
将规则用在存储池上
|
[root@ceph01 ~]# ceph osd pool set ssdpool crush_rule ssd |
|
set pool 2 crush_rule to ssd |
|
[root@ceph01 ~]# ceph osd pool set hddpool crush_rule hdd |
|
set pool 3 crush_rule to hdd |
2.9配置监控组件
查看监控组件包括alertmanager、grafana、node-exporter、prometheus
|
[root@ceph01 ~]# ceph orch ls |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 8m ago 19h count:1 ceph-exporter 5/5 8m ago 19h * crash 5/5 8m ago 19h * grafana ?:3000 1/1 8m ago 19h count:1 mgr 2/2 8m ago 19h count:2 mon 3/3 8m ago 17h count:3;label:mon node-exporter ?:9100 5/5 8m ago 19h * osd 10 8m ago - prometheus ?:9095 1/1 8m ago 19h count:1 |
|
[root@ceph01 ~]# ceph mgr services |
|
{ "dashboard": "https://10.9.254.81:8443/", "prometheus": "http://10.9.254.81:9283/" } |
|
[root@ceph01 ~]# ceph mgr module ls |
|
MODULE balancer on (always on) crash on (always on) devicehealth on (always on) orchestrator on (always on) pg_autoscaler on (always on) progress on (always on) rbd_support on (always on) status on (always on) telemetry on (always on) volumes on (always on) cephadm on dashboard on iostat on nfs on prometheus on restful on alerts - diskprediction_local - influx - insights - k8sevents - localpool - mds_autoscaler - mirroring - osd_perf_query - osd_support - rgw - rook - selftest - snap_schedule - stats - telegraf - test_orchestrator - zabbix - |
调整grafana服务在主机的位置
|
[root@ceph01 ~]# ceph orch ps |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID alertmanager.ceph01 ceph01 *:9093,9094 running (18h) 15s ago 19h 24.8M - 0.25.0 c8568f914cd2 03024acf467e ceph-exporter.ceph01 ceph01 running (19h) 15s ago 19h 17.5M - 18.2.0 2ddfbd2845f4 45b49253fe32 ceph-exporter.ceph02 ceph02 running (18h) 9m ago 18h 31.4M - 18.2.0 2ddfbd2845f4 2546817aab89 ceph-exporter.ceph03 ceph03 running (18h) 9m ago 18h 31.2M - 18.2.0 2ddfbd2845f4 e70e11057e78 ceph-exporter.ceph04 ceph04 running (18h) 9m ago 18h 31.1M - 18.2.0 2ddfbd2845f4 f294ff260174 ceph-exporter.ceph05 ceph05 running (18h) 5m ago 18h 31.2M - 18.2.0 2ddfbd2845f4 e87140fa642c crash.ceph01 ceph01 running (19h) 15s ago 19h 7096k - 18.2.0 2ddfbd2845f4 42b819c1d277 crash.ceph02 ceph02 running (18h) 9m ago 18h 10.1M - 18.2.0 2ddfbd2845f4 3b4fd4cadb3e crash.ceph03 ceph03 running (18h) 9m ago 18h 10.0M - 18.2.0 2ddfbd2845f4 51342f1a2ecd crash.ceph04 ceph04 running (18h) 9m ago 18h 10.1M - 18.2.0 2ddfbd2845f4 4824930bada2 crash.ceph05 ceph05 running (18h) 5m ago 18h 10.1M - 18.2.0 2ddfbd2845f4 cf92ac9f3a67 grafana.ceph01 ceph01 *:3000 running (19h) 15s ago 19h 95.8M - 9.4.7 2c41d148cca3 93485908e28c mgr.ceph01.ywwete ceph01 *:9283,8765,8443 running (19h) 15s ago 19h 621M - 18.2.0 2ddfbd2845f4 2d2752586bdc mgr.ceph04.ykcgel ceph04 *:8443,9283,8765 running (18h) 9m ago 18h 459M - 18.2.0 2ddfbd2845f4 ce7f89b9d81f mon.ceph01 ceph01 running (19h) 15s ago 19h 400M 2048M 18.2.0 2ddfbd2845f4 c45b203f0495 mon.ceph02 ceph02 running (18h) 9m ago 18h 389M 2048M 18.2.0 2ddfbd2845f4 b511e94994b0 mon.ceph03 ceph03 running (18h) 9m ago 18h 389M 2048M 18.2.0 2ddfbd2845f4 344830d1f960 node-exporter.ceph01 ceph01 *:9100 running (19h) 15s ago 19h 29.3M - 1.5.0 0da6a335fe13 a954f05187f7 node-exporter.ceph02 ceph02 *:9100 running (18h) 9m ago 18h 28.2M - 1.5.0 0da6a335fe13 8cd0b6e2eb9f node-exporter.ceph03 ceph03 *:9100 running (18h) 9m ago 18h 30.0M - 1.5.0 0da6a335fe13 5d0023a9d9ac node-exporter.ceph04 ceph04 *:9100 running (18h) 9m ago 18h 29.6M - 1.5.0 0da6a335fe13 ad2a61c7a224 node-exporter.ceph05 ceph05 *:9100 running (18h) 5m ago 18h 30.3M - 1.5.0 0da6a335fe13 dd0f095c4c68 osd.0 ceph01 running (17h) 15s ago 17h 88.2M 4096M 18.2.0 2ddfbd2845f4 601ee7e09d85 osd.1 ceph01 running (17h) 15s ago 17h 90.4M 4096M 18.2.0 2ddfbd2845f4 18a2e23daeac osd.2 ceph02 running (17h) 9m ago 17h 85.4M 1184M 18.2.0 2ddfbd2845f4 2d1dca056476 osd.3 ceph02 running (17h) 9m ago 17h 87.6M 1184M 18.2.0 2ddfbd2845f4 2a8d7f72a03b osd.4 ceph03 running (17h) 9m ago 17h 86.9M 1184M 18.2.0 2ddfbd2845f4 363db89e7f48 osd.5 ceph03 running (17h) 9m ago 17h 89.2M 1184M 18.2.0 2ddfbd2845f4 1c5b076345a0 osd.6 ceph04 running (17h) 9m ago 17h 88.2M 4096M 18.2.0 2ddfbd2845f4 8c11b3ec9f78 osd.7 ceph04 running (17h) 9m ago 17h 85.9M 4096M 18.2.0 2ddfbd2845f4 01646673ed19 osd.8 ceph05 running (17h) 5m ago 17h 84.7M 1696M 18.2.0 2ddfbd2845f4 cfd33d90afc8 osd.9 ceph05 running (17h) 5m ago 17h 86.2M 1696M 18.2.0 2ddfbd2845f4 aad7c56bc534 prometheus.ceph01 ceph01 *:9095 running (18h) 15s ago 19h 148M - 2.43.0 a07b618ecd1d beb3796d1390 |
|
[root@ceph01 ~]# ceph orch apply grafana --placement="ceph02" |
|
Scheduled grafana update... |
|
[root@ceph01 ~]# ceph orch ps |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID alertmanager.ceph01 ceph01 *:9093,9094 running (18h) 30s ago 19h 24.6M - 0.25.0 c8568f914cd2 03024acf467e ceph-exporter.ceph01 ceph01 running (19h) 30s ago 19h 17.5M - 18.2.0 2ddfbd2845f4 45b49253fe32 ceph-exporter.ceph02 ceph02 running (18h) 30s ago 18h 31.4M - 18.2.0 2ddfbd2845f4 2546817aab89 ceph-exporter.ceph03 ceph03 running (18h) 74s ago 18h 31.2M - 18.2.0 2ddfbd2845f4 e70e11057e78 ceph-exporter.ceph04 ceph04 running (18h) 74s ago 18h 31.1M - 18.2.0 2ddfbd2845f4 f294ff260174 ceph-exporter.ceph05 ceph05 running (18h) 8m ago 18h 31.2M - 18.2.0 2ddfbd2845f4 e87140fa642c crash.ceph01 ceph01 running (19h) 30s ago 19h 7096k - 18.2.0 2ddfbd2845f4 42b819c1d277 crash.ceph02 ceph02 running (18h) 30s ago 18h 10.1M - 18.2.0 2ddfbd2845f4 3b4fd4cadb3e crash.ceph03 ceph03 running (18h) 74s ago 18h 10.0M - 18.2.0 2ddfbd2845f4 51342f1a2ecd crash.ceph04 ceph04 running (18h) 74s ago 18h 10.1M - 18.2.0 2ddfbd2845f4 4824930bada2 crash.ceph05 ceph05 running (18h) 8m ago 18h 10.1M - 18.2.0 2ddfbd2845f4 cf92ac9f3a67 grafana.ceph02 ceph02 *:3000 running (43s) 30s ago 43s 28.7M - 9.4.7 2c41d148cca3 8805bbcf7f67 mgr.ceph01.ywwete ceph01 *:9283,8765,8443 running (19h) 30s ago 19h 621M - 18.2.0 2ddfbd2845f4 2d2752586bdc mgr.ceph04.ykcgel ceph04 *:8443,9283,8765 running (18h) 74s ago 18h 459M - 18.2.0 2ddfbd2845f4 ce7f89b9d81f mon.ceph01 ceph01 running (19h) 30s ago 19h 400M 2048M 18.2.0 2ddfbd2845f4 c45b203f0495 mon.ceph02 ceph02 running (18h) 30s ago 18h 389M 2048M 18.2.0 2ddfbd2845f4 b511e94994b0 mon.ceph03 ceph03 running (18h) 74s ago 18h 391M 2048M 18.2.0 2ddfbd2845f4 344830d1f960 node-exporter.ceph01 ceph01 *:9100 running (19h) 30s ago 19h 29.4M - 1.5.0 0da6a335fe13 a954f05187f7 node-exporter.ceph02 ceph02 *:9100 running (18h) 30s ago 18h 27.7M - 1.5.0 0da6a335fe13 8cd0b6e2eb9f node-exporter.ceph03 ceph03 *:9100 running (18h) 74s ago 18h 30.1M - 1.5.0 0da6a335fe13 5d0023a9d9ac node-exporter.ceph04 ceph04 *:9100 running (18h) 74s ago 18h 30.0M - 1.5.0 0da6a335fe13 ad2a61c7a224 node-exporter.ceph05 ceph05 *:9100 running (18h) 8m ago 18h 30.3M - 1.5.0 0da6a335fe13 dd0f095c4c68 osd.0 ceph01 running (18h) 30s ago 18h 88.2M 4096M 18.2.0 2ddfbd2845f4 601ee7e09d85 osd.1 ceph01 running (18h) 30s ago 18h 90.5M 4096M 18.2.0 2ddfbd2845f4 18a2e23daeac osd.2 ceph02 running (17h) 30s ago 17h 85.4M 1184M 18.2.0 2ddfbd2845f4 2d1dca056476 osd.3 ceph02 running (17h) 30s ago 17h 87.6M 1184M 18.2.0 2ddfbd2845f4 2a8d7f72a03b osd.4 ceph03 running (17h) 74s ago 17h 86.9M 1184M 18.2.0 2ddfbd2845f4 363db89e7f48 osd.5 ceph03 running (17h) 74s ago 17h 89.2M 1184M 18.2.0 2ddfbd2845f4 1c5b076345a0 osd.6 ceph04 running (17h) 74s ago 17h 87.8M 4096M 18.2.0 2ddfbd2845f4 8c11b3ec9f78 osd.7 ceph04 running (17h) 74s ago 17h 85.5M 4096M 18.2.0 2ddfbd2845f4 01646673ed19 osd.8 ceph05 running (17h) 8m ago 17h 84.7M 1696M 18.2.0 2ddfbd2845f4 cfd33d90afc8 osd.9 ceph05 running (17h) 8m ago 17h 86.2M 1696M 18.2.0 2ddfbd2845f4 aad7c56bc534 prometheus.ceph01 ceph01 *:9095 running (18h) 30s ago 19h 144M - 2.43.0 a07b618ecd1d beb3796d1390 |
2.10配置MDS
MDS守护进程用于Cephfs(文件系统),MDS采用的是主备模式,即cephfs仅使用1个活跃的MDS守护进程,配置MDS服务有多种方法,此处介绍2种,大同小异。
先创建CephFS,然后使用placement部署MDS
先创建CephFS池
|
[root@ceph01 ~]# ceph osd pool create cephfs_data 64 64 |
|
pool 'cephfs_data' created |
|
[root@ceph01 ~]# ceph osd pool create cephfs_metadata 64 64 |
|
pool 'cephfs_metadata' created |
|
[root@ceph01 ~]# ceph osd lspools |
|
1 .mgr 2 ssdpool 3 hddpool 4 cephfs_data 5 cephfs_metadata |
为数据池和元数据池创建文件系统
|
[root@ceph01 ~]# ceph fs new cephfs cephfs_metadata cephfs_data |
|
new fs with metadata pool 5 and data pool 4 |
使用Ceph orch apply命令部署MDS服务
|
[root@ceph01 ~]# ceph orch apply mds cephfs --placement="3 ceph01 ceph02 ceph03" |
|
Scheduled mds.cephfs update... |
|
[root@ceph01 ~]# ceph orch ls |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 37s ago 20h count:1 ceph-exporter 5/5 6m ago 20h * crash 5/5 6m ago 20h * grafana ?:3000 1/1 37s ago 16m ceph02 mds.cephfs 3/3 38s ago 60s ceph01;ceph02;ceph03;count:3 mgr 2/2 6m ago 20h count:2 mon 3/3 38s ago 18h count:3;label:mon node-exporter ?:9100 5/5 6m ago 20h * osd 10 6m ago - prometheus ?:9095 1/1 37s ago 20h count:1 |
|
[root@ceph01 ~]# ceph orch ps |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID alertmanager.ceph01 ceph01 *:9093,9094 running (19h) 72s ago 20h 24.6M - 0.25.0 c8568f914cd2 03024acf467e ceph-exporter.ceph01 ceph01 running (20h) 72s ago 20h 17.5M - 18.2.0 2ddfbd2845f4 45b49253fe32 ceph-exporter.ceph02 ceph02 running (19h) 72s ago 19h 31.4M - 18.2.0 2ddfbd2845f4 2546817aab89 ceph-exporter.ceph03 ceph03 running (19h) 72s ago 19h 31.3M - 18.2.0 2ddfbd2845f4 e70e11057e78 ceph-exporter.ceph04 ceph04 running (19h) 7m ago 19h 31.1M - 18.2.0 2ddfbd2845f4 f294ff260174 ceph-exporter.ceph05 ceph05 running (19h) 4m ago 19h 31.2M - 18.2.0 2ddfbd2845f4 e87140fa642c crash.ceph01 ceph01 running (20h) 72s ago 20h 7096k - 18.2.0 2ddfbd2845f4 42b819c1d277 crash.ceph02 ceph02 running (19h) 72s ago 19h 10.1M - 18.2.0 2ddfbd2845f4 3b4fd4cadb3e crash.ceph03 ceph03 running (19h) 72s ago 19h 10.0M - 18.2.0 2ddfbd2845f4 51342f1a2ecd crash.ceph04 ceph04 running (19h) 7m ago 19h 10.1M - 18.2.0 2ddfbd2845f4 4824930bada2 crash.ceph05 ceph05 running (19h) 4m ago 19h 10.1M - 18.2.0 2ddfbd2845f4 cf92ac9f3a67 grafana.ceph02 ceph02 *:3000 running (17m) 72s ago 17m 160M - 9.4.7 2c41d148cca3 8805bbcf7f67 mds.cephfs.ceph01.aibnpt ceph01 running (82s) 72s ago 82s 15.5M - 18.2.0 2ddfbd2845f4 47174fba9bc0 mds.cephfs.ceph02.kzinfm ceph02 running (79s) 72s ago 79s 15.1M - 18.2.0 2ddfbd2845f4 e49ff6578da6 mds.cephfs.ceph03.pdkglx ceph03 running (83s) 72s ago 84s 15.7M - 18.2.0 2ddfbd2845f4 39761285bc18 mgr.ceph01.ywwete ceph01 *:9283,8765,8443 running (20h) 72s ago 20h 622M - 18.2.0 2ddfbd2845f4 2d2752586bdc mgr.ceph04.ykcgel ceph04 *:8443,9283,8765 running (19h) 7m ago 19h 459M - 18.2.0 2ddfbd2845f4 ce7f89b9d81f mon.ceph01 ceph01 running (20h) 72s ago 20h 401M 2048M 18.2.0 2ddfbd2845f4 c45b203f0495 mon.ceph02 ceph02 running (19h) 72s ago 19h 389M 2048M 18.2.0 2ddfbd2845f4 b511e94994b0 mon.ceph03 ceph03 running (19h) 72s ago 19h 391M 2048M 18.2.0 2ddfbd2845f4 344830d1f960 node-exporter.ceph01 ceph01 *:9100 running (20h) 72s ago 20h 29.0M - 1.5.0 0da6a335fe13 a954f05187f7 node-exporter.ceph02 ceph02 *:9100 running (19h) 72s ago 19h 28.2M - 1.5.0 0da6a335fe13 8cd0b6e2eb9f node-exporter.ceph03 ceph03 *:9100 running (19h) 72s ago 19h 30.5M - 1.5.0 0da6a335fe13 5d0023a9d9ac node-exporter.ceph04 ceph04 *:9100 running (19h) 7m ago 19h 29.8M - 1.5.0 0da6a335fe13 ad2a61c7a224 node-exporter.ceph05 ceph05 *:9100 running (19h) 4m ago 19h 30.7M - 1.5.0 0da6a335fe13 dd0f095c4c68 osd.0 ceph01 running (18h) 72s ago 18h 88.3M 4096M 18.2.0 2ddfbd2845f4 601ee7e09d85 osd.1 ceph01 running (18h) 72s ago 18h 91.0M 4096M 18.2.0 2ddfbd2845f4 18a2e23daeac osd.2 ceph02 running (18h) 72s ago 18h 86.2M 1184M 18.2.0 2ddfbd2845f4 2d1dca056476 osd.3 ceph02 running (18h) 72s ago 18h 87.4M 1184M 18.2.0 2ddfbd2845f4 2a8d7f72a03b osd.4 ceph03 running (18h) 72s ago 18h 86.8M 1184M 18.2.0 2ddfbd2845f4 363db89e7f48 osd.5 ceph03 running (18h) 72s ago 18h 90.1M 1184M 18.2.0 2ddfbd2845f4 1c5b076345a0 osd.6 ceph04 running (18h) 7m ago 18h 88.3M 4096M 18.2.0 2ddfbd2845f4 8c11b3ec9f78 osd.7 ceph04 running (18h) 7m ago 18h 86.3M 4096M 18.2.0 2ddfbd2845f4 01646673ed19 osd.8 ceph05 running (18h) 4m ago 18h 85.9M 1696M 18.2.0 2ddfbd2845f4 cfd33d90afc8 osd.9 ceph05 running (18h) 4m ago 18h 86.5M 1696M 18.2.0 2ddfbd2845f4 aad7c56bc534 prometheus.ceph01 ceph01 *:9095 running (19h) 72s ago 20h 140M - 2.43.0 a07b618ecd1d beb3796d1390 |
|
[root@ceph01 ~]# ceph fs ls |
|
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ] |
|
[root@ceph01 ~]# ceph fs status |
|
cephfs - 0 clients ====== RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS 0 active cephfs.ceph03.pdkglx Reqs: 0 /s 10 13 12 0 POOL TYPE USED AVAIL cephfs_metadata metadata 64.0k 474G cephfs_data data 0 474G STANDBY MDS cephfs.ceph01.aibnpt cephfs.ceph02.kzinfm MDS version: ceph version 18.2.0 (5dd24139a1eada541a3bc16b6941c5dde975e26d) reef (stable) |
|
root@ceph01 ~]# ceph orch ps --daemon_type=mds |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID mds.cephfs.ceph01.aibnpt ceph01 running (70m) 6m ago 70m 26.5M - 18.2.0 2ddfbd2845f4 47174fba9bc0 mds.cephfs.ceph02.kzinfm ceph02 running (70m) 6m ago 70m 26.6M - 18.2.0 2ddfbd2845f4 e49ff6578da6 mds.cephfs.ceph03.pdkglx ceph03 running (71m) 6m ago 71m 26.4M - 18.2.0 2ddfbd2845f4 39761285bc18 |
2.11Dashboard的使用
查看dashboard地址
|
[root@ceph01 ~]# ceph mgr services |
|
{ "dashboard": "https://10.9.254.81:8443/", "prometheus": "http://10.9.254.81:9283/" } |
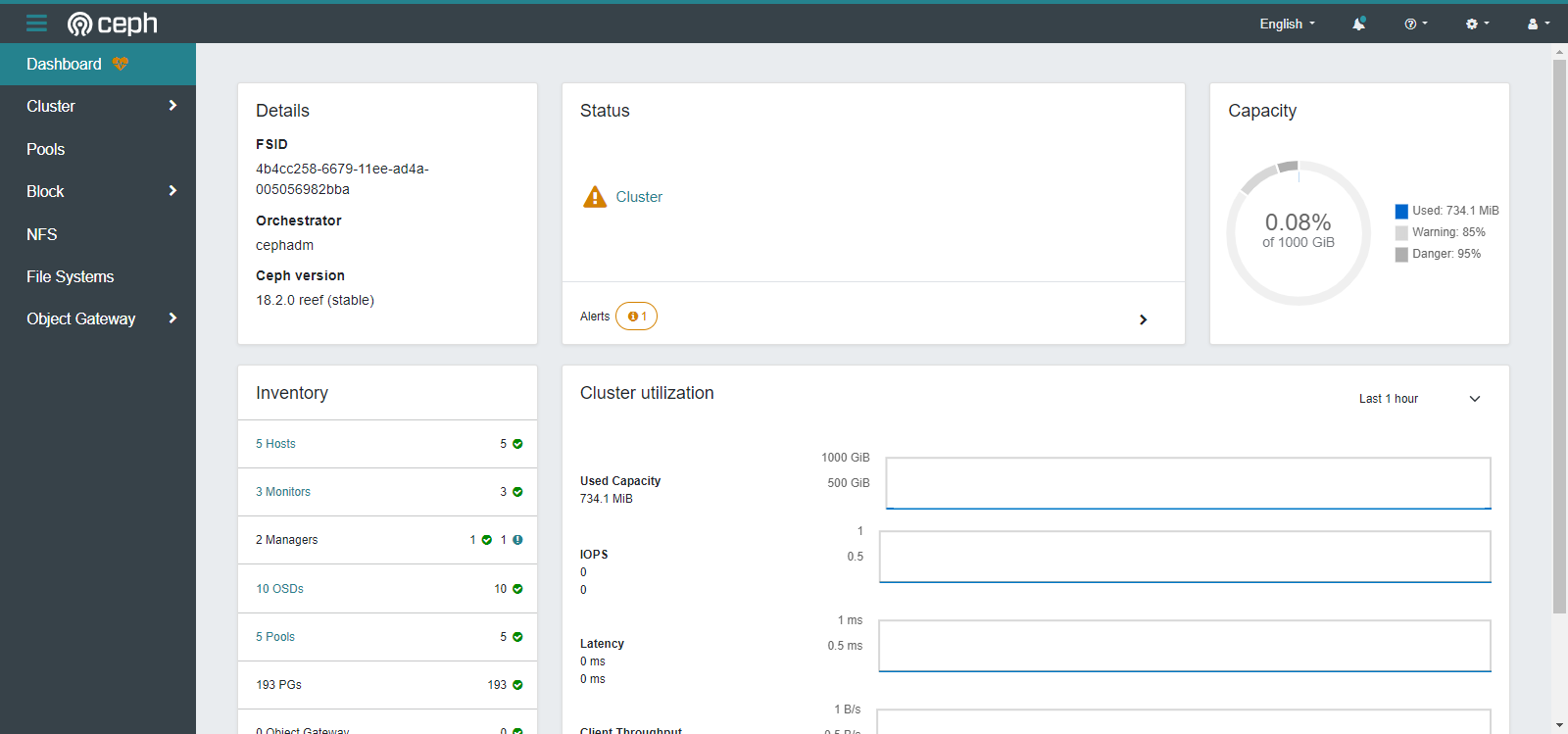
主机信息
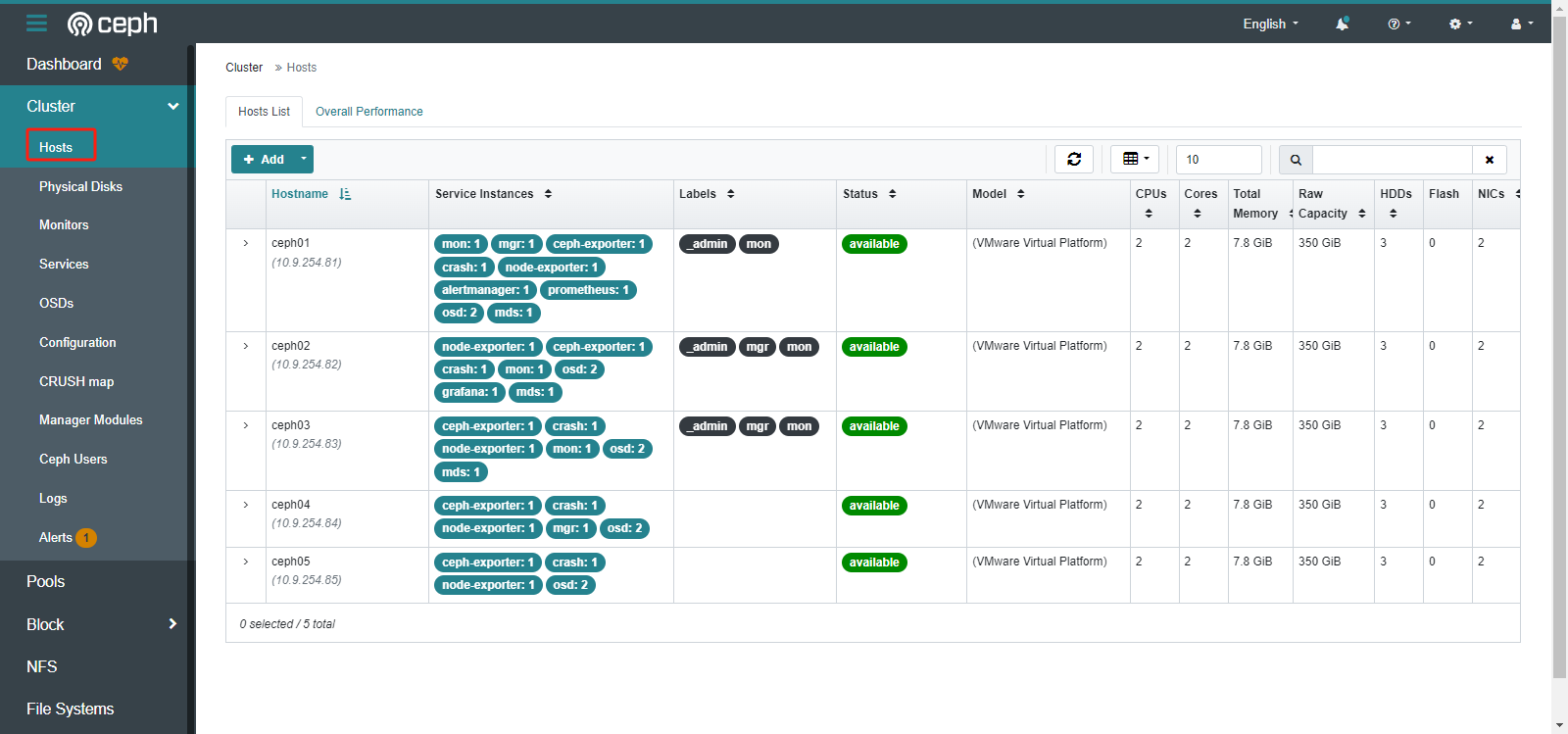
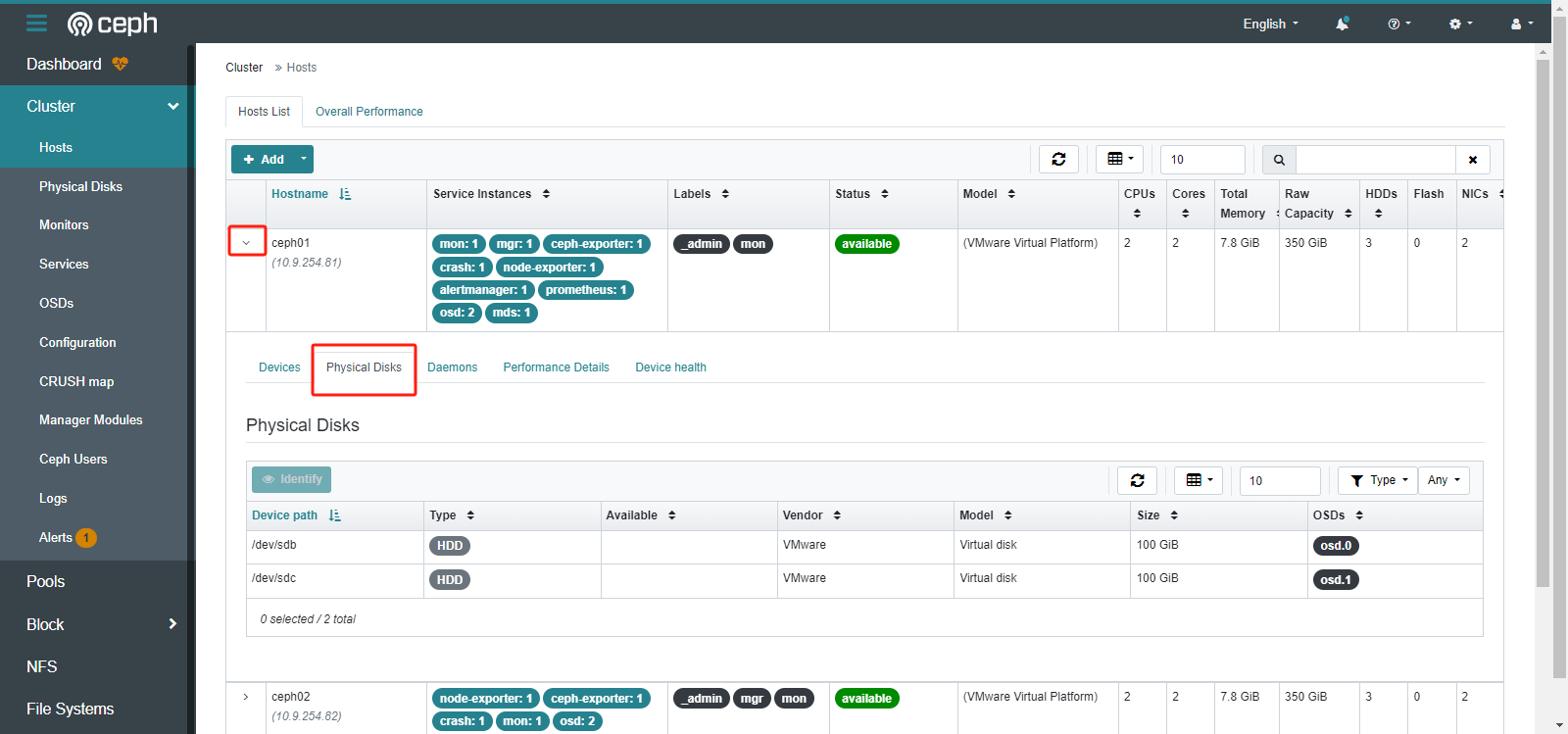
3.管理CEPH集群
3.1管理ceph节点
3.1.1添加节点
参照第一章节完成基础环境配置
|
[root@ceph01 ~]# ceph orch host add ceph06 10.9.254.86 |
删除节点后添加
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 4 hosts in cluster |
|
[root@ceph01 ~]# ceph orch host add ceph05 10.9.254.85 |
|
Added host 'ceph05' with addr '10.9.254.85' |
|
[root@ceph01 ~]# ceph orch daemon add osd ceph05:/dev/sdb |
|
Created osd(s) 8 on host 'ceph05' |
|
[root@ceph01 ~]# ceph orch daemon add osd ceph05:/dev/sdc |
|
Created osd(s) 9 on host 'ceph05' |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 23h) mgr: ceph01.ywwete(active, since 46h), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 92s), 10 in (since 44h) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 753 MiB used, 999 GiB / 1000 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph orch ps ceph05 |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID ceph-exporter.ceph05 ceph05 running (5m) 2m ago 5m 7543k - 18.2.0 2ddfbd2845f4 18f287bed785 crash.ceph05 ceph05 running (5m) 2m ago 5m 7088k - 18.2.0 2ddfbd2845f4 a99163decd6b node-exporter.ceph05 ceph05 *:9100 running (5m) 2m ago 5m 8680k - 1.5.0 0da6a335fe13 e04a809f0376 osd.8 ceph05 running (3m) 2m ago 3m 71.9M 1696M 18.2.0 2ddfbd2845f4 7a64e10bfcb0 osd.9 ceph05 running (2m) 2m ago 2m 13.1M 1696M 18.2.0 2ddfbd2845f4 c6a2dfa7cb73 |
|
[root@ceph05 ~]# docker ps -a |
|
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c6a2dfa7cb73 quay.io/ceph/ceph "/usr/bin/ceph-osd -…" 3 minutes ago Up 3 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-osd-9 7a64e10bfcb0 quay.io/ceph/ceph "/usr/bin/ceph-osd -…" 3 minutes ago Up 3 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-osd-8 e04a809f0376 quay.io/prometheus/node-exporter:v1.5.0 "/bin/node_exporter …" 6 minutes ago Up 6 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-node-exporter-ceph05 a99163decd6b quay.io/ceph/ceph "/usr/bin/ceph-crash…" 6 minutes ago Up 6 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-crash-ceph05 18f287bed785 quay.io/ceph/ceph "/usr/bin/ceph-expor…" 6 minutes ago Up 6 minutes ceph-4b4cc258-6679-11ee-ad4a-005056982bba-ceph-exporter-ceph05 |
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.97687 root default -3 0.19537 host ceph01 1 hdd 0.09769 osd.1 up 1.00000 1.00000 0 ssd 0.09769 osd.0 up 1.00000 1.00000 -5 0.19537 host ceph02 3 hdd 0.09769 osd.3 up 1.00000 1.00000 2 ssd 0.09769 osd.2 up 1.00000 1.00000 -7 0.19537 host ceph03 5 hdd 0.09769 osd.5 up 1.00000 1.00000 4 ssd 0.09769 osd.4 up 1.00000 1.00000 -9 0.19537 host ceph04 7 hdd 0.09769 osd.7 up 1.00000 1.00000 6 ssd 0.09769 osd.6 up 1.00000 1.00000 -11 0.19537 host ceph05 9 hdd 0.09769 osd.9 up 1.00000 1.00000 8 ssd 0.09769 osd.8 up 1.00000 1.00000 |
使用配置文件进行添加
|
[root@ceph01 ~]# vim hosts.yaml |
|
service_type: host addr: ceph05 hostname: ceph05 labels: - osd |
|
[root@ceph01 ~]# ceph orch apply -i hosts.yaml |
3.1.2节点进入维护模式
将主机置于维护模式,可加上--force,强制操作
|
[root@ceph01 ~]# ceph orch host maintenance enter ceph05 |
|
Daemons for Ceph cluster 4b4cc258-6679-11ee-ad4a-005056982bba stopped on host ceph05. Host ceph05 moved to maintenance mode |
查看主机上服务状态,均为stopped
|
[root@ceph01 ~]# ceph orch ps ceph05 |
|
查看NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID ceph-exporter.ceph05 ceph05 stopped 8m ago 20h 31.2M - 18.2.0 2ddfbd2845f4 e87140fa642c crash.ceph05 ceph05 stopped 8m ago 20h 10.1M - 18.2.0 2ddfbd2845f4 cf92ac9f3a67 node-exporter.ceph05 ceph05 *:9100 stopped 8m ago 20h 30.5M - 1.5.0 0da6a335fe13 dd0f095c4c68 osd.8 ceph05 stopped 8m ago 20h 85.2M 1696M 18.2.0 2ddfbd2845f4 cfd33d90afc8 osd.9 ceph05 stopped 8m ago 19h 86.9M 1696M 18.2.0 2ddfbd2845f4 aad7c56bc534 |
查看主机状态,发现主机上添加了maintenance标签
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 ceph05 10.9.254.85 Maintenance 5 hosts in cluster |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_WARN 1 stray daemon(s) not managed by cephadm 1 host is in maintenance mode 2 osds down 1 OSDs or CRUSH {nodes, device-classes} have {NOUP,NODOWN,NOIN,NOOUT} flags set 1 host (2 osds) down Degraded data redundancy: 8/48 objects degraded (16.667%), 7 pgs degraded, 75 pgs undersized services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 20h) mgr: ceph01.ywwete(active, since 22h), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 8 up (since 11m), 10 in (since 20h) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 734 MiB used, 999 GiB / 1000 GiB avail pgs: 8/48 objects degraded (16.667%) 118 active+clean 68 active+undersized 7 active+undersized+degraded |
|
[root@ceph01 ~]# ceph health detail |
|
HEALTH_WARN 1 stray daemon(s) not managed by cephadm; 1 host is in maintenance mode; 2 osds down; 1 OSDs or CRUSH {nodes, device-classes} have {NOUP,NODOWN,NOIN,NOOUT} flags set; 1 host (2 osds) down; Degraded data redundancy: 8/48 objects degraded (16.667%), 7 pgs degraded, 75 pgs undersized [WRN] CEPHADM_STRAY_DAEMON: 1 stray daemon(s) not managed by cephadm stray daemon mon.ceph05 on host ceph05 not managed by cephadm [WRN] HOST_IN_MAINTENANCE: 1 host is in maintenance mode ceph05 is in maintenance [WRN] OSD_DOWN: 2 osds down osd.8 (root=default,host=ceph05) is down osd.9 (root=default,host=ceph05) is down [WRN] OSD_FLAGS: 1 OSDs or CRUSH {nodes, device-classes} have {NOUP,NODOWN,NOIN,NOOUT} flags set host ceph05 has flags noout [WRN] OSD_HOST_DOWN: 1 host (2 osds) down host ceph05 (root=default) (2 osds) is down [WRN] PG_DEGRADED: Degraded data redundancy: 8/48 objects degraded (16.667%), 7 pgs degraded, 75 pgs undersized ..... |
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.97687 root default -3 0.19537 host ceph01 1 hdd 0.09769 osd.1 up 1.00000 1.00000 0 ssd 0.09769 osd.0 up 1.00000 1.00000 -5 0.19537 host ceph02 3 hdd 0.09769 osd.3 up 1.00000 1.00000 2 ssd 0.09769 osd.2 up 1.00000 1.00000 -7 0.19537 host ceph03 5 hdd 0.09769 osd.5 up 1.00000 1.00000 4 ssd 0.09769 osd.4 up 1.00000 1.00000 -9 0.19537 host ceph04 7 hdd 0.09769 osd.7 up 1.00000 1.00000 6 ssd 0.09769 osd.6 up 1.00000 1.00000 -11 0.19537 host ceph05 9 hdd 0.09769 osd.9 down 1.00000 1.00000 8 ssd 0.09769 osd.8 down 1.00000 1.00000 |
3.1.3节点退出维护模式
主机退出维护模式
|
[root@ceph01 ~]# ceph orch host maintenance exit ceph05 |
|
Ceph cluster 4b4cc258-6679-11ee-ad4a-005056982bba on ceph05 has exited maintenance mode |
查看主机上服务状态,均为running
|
[root@ceph01 ~]# ceph orch ps ceph05 |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID ceph-exporter.ceph05 ceph05 running (76s) 27s ago 21h 7451k - 18.2.0 2ddfbd2845f4 87ecd25691af crash.ceph05 ceph05 running (76s) 27s ago 21h 7096k - 18.2.0 2ddfbd2845f4 78d436ebe777 node-exporter.ceph05 ceph05 *:9100 running (76s) 27s ago 21h 8515k - 1.5.0 0da6a335fe13 0cac7213e159 osd.8 ceph05 running (74s) 27s ago 20h 84.4M 1696M 18.2.0 2ddfbd2845f4 47f71c844ad9 osd.9 ceph05 running (74s) 27s ago 20h 86.2M 1696M 18.2.0 2ddfbd2845f4 d5e4ddf027a4 |
查看主机状态,发现主机上maintenance标签已经删除掉
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 ceph05 10.9.254.85 5 hosts in cluster |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_WARN 1 stray daemon(s) not managed by cephadm services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 20h) mgr: ceph01.ywwete(active, since 22h), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 12m), 10 in (since 20h) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 1.4 GiB used, 999 GiB / 1000 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph health detail |
|
HEALTH_WARN 1 stray daemon(s) not managed by cephadm [WRN] CEPHADM_STRAY_DAEMON: 1 stray daemon(s) not managed by cephadm stray daemon mon.ceph05 on host ceph05 not managed by cephadm |
3.1.4节点标签管理
为节点添加标签
|
[root@ceph01 ~]# ceph orch host label add ceph05 mon |
|
Added label mon to host ceph05 |
|
[root@ceph01 ~]# ceph orch host label add ceph05 osd |
|
Added label osd to host ceph05 |
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 ceph05 10.9.254.85 mon,osd 5 hosts in cluster |
使用节点抱歉部署守护进程
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_WARN 1 stray daemon(s) not managed by cephadm services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 20h) #mon节点有3个,我们把ceph05添加 mgr: ceph01.ywwete(active, since 22h), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 22m), 10 in (since 20h) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 1.4 GiB used, 999 GiB / 1000 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph orch apply mon --placement="label:mon" |
|
Scheduled mon update... |
|
[root@ceph01 ~]# ceph orch ps --daemon_type=mon |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID mon.ceph01 ceph01 running (22h) 9m ago 22h 416M 2048M 18.2.0 2ddfbd2845f4 c45b203f0495 mon.ceph02 ceph02 running (21h) 9m ago 21h 401M 2048M 18.2.0 2ddfbd2845f4 b511e94994b0 mon.ceph03 ceph03 running (21h) 7m ago 21h 405M 2048M 18.2.0 2ddfbd2845f4 344830d1f960 mon.ceph05 ceph05 running (35s) 29s ago 35s 50.0M 2048M 18.2.0 2ddfbd2845f4 8bf873316591 |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 4 daemons, quorum ceph01,ceph03,ceph02,ceph05 (age 66s) #ceph05已添加 mgr: ceph01.ywwete(active, since 22h), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 25m), 10 in (since 20h) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 1.4 GiB used, 999 GiB / 1000 GiB avail pgs: 193 active+clean |
从节点上删除标签
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 ceph05 10.9.254.85 mon,osd 5 hosts in cluster |
|
[root@ceph01 ~]# ceph orch host label rm ceph05 mon |
|
Removed label mon from host ceph05 |
|
[root@ceph01 ~]# ceph orch host label rm ceph05 osd |
|
Removed label osd from host ceph05 |
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 ceph05 10.9.254.85 5 hosts in cluster |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 2m) mgr: ceph01.ywwete(active, since 22h), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 31m), 10 in (since 20h) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 1.4 GiB used, 999 GiB / 1000 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph orch ps --daemon_type=mon |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID mon.ceph01 ceph01 running (22h) 6m ago 22h 416M 2048M 18.2.0 2ddfbd2845f4 c45b203f0495 mon.ceph02 ceph02 running (21h) 6m ago 21h 406M 2048M 18.2.0 2ddfbd2845f4 b511e94994b0 mon.ceph03 ceph03 running (21h) 3m ago 21h 406M 2048M 18.2.0 2ddfbd2845f4 344830d1f960 |
3.1.5删除节点
获取被删除主机上有那些守护进程
|
[root@ceph01 ~]# ceph orch ps ceph05 |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID ceph-exporter.ceph05 ceph05 running (35m) 6m ago 21h 8580k - 18.2.0 2ddfbd2845f4 87ecd25691af crash.ceph05 ceph05 running (35m) 6m ago 21h 7096k - 18.2.0 2ddfbd2845f4 78d436ebe777 node-exporter.ceph05 ceph05 *:9100 running (35m) 6m ago 21h 17.6M - 1.5.0 0da6a335fe13 0cac7213e159 osd.8 ceph05 running (35m) 6m ago 20h 93.3M 1696M 18.2.0 2ddfbd2845f4 47f71c844ad9 osd.9 ceph05 running (35m) 6m ago 20h 94.7M 1696M 18.2.0 2ddfbd2845f4 d5e4ddf027a4 |
先排空被删除主机上的所有守护进程,使用drain参数,会再被删除主机上自动打上_no_schedule
|
[root@ceph01 ~]# ceph orch host drain ceph05 |
|
Scheduled to remove the following daemons from host 'ceph05' type id -------------------- --------------- ceph-exporter ceph05 crash ceph05 node-exporter ceph05 osd 8 osd 9 |
查看被移除的OSD状态
|
[root@ceph01 ~]# ceph orch osd rm status |
|
OSD HOST STATE PGS REPLACE FORCE ZAP DRAIN STARTED AT 8 ceph05 done, waiting for purge -1 False False False 2023-10-10 07:31:11.771642 9 ceph05 done, waiting for purge 0 False False False 2023-10-10 07:31:12.864134 |
|
[root@ceph01 ~]# ceph orch osd rm status |
|
No OSD remove/replace operations reported |
检查被删除主机上所有守护进程是否已经从集群中移除
|
[root@ceph01 ~]# ceph orch ps ceph05 |
|
No daemons reported |
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 ceph05 10.9.254.85 _no_schedule 5 hosts in cluster |
删除主机
注意:要删除对应节点,被删除节点上要部署了cephadm
|
[root@ceph01 ~]# ceph orch host rm ceph05 |
|
Removed host 'ceph05' |
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 4 hosts in cluster |
|
[root@ceph05 ~]# lsblk |
|
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 150G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 149G 0 part ├─rl-root 253:0 0 111G 0 lvm / ├─rl-swap 253:1 0 8G 0 lvm [SWAP] └─rl-home 253:2 0 30G 0 lvm /home sdb 8:16 0 100G 0 disk └─ceph--7744483c--8406--41a5--b417--505ab7705326-osd--block--98992d6a--cdad--4c1a--9f97--5a0f17b80a05 253:3 0 100G 0 lvm sdc 8:32 0 100G 0 disk └─ceph--36f5db24--3de4--4563--b0d6--77ea6118c63f-osd--block--fb4cf221--c4af--4497--8e52--d686e4ce6111 253:4 0 100G 0 lvm sr0 11:0 1 1024M 0 rom |
清理节点,切记要在被清理节点上运行
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_WARN 1 stray host(s) with 1 daemon(s) not managed by cephadm services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 76m) mgr: ceph01.ywwete(active, since 23h), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 8 osds: 8 up (since 25m), 8 in (since 22h) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 595 MiB used, 799 GiB / 800 GiB avail pgs: 193 active+clean |
|
[root@ceph05 ~]# cephadm rm-cluster --fsid 4b4cc258-6679-11ee-ad4a-005056982bba --force --zap-osds |
|
Using ceph image with id '2ddfbd2845f4' and tag 'v18' created on 2023-09-27 00:11:26 +0800 CST quay.io/ceph/ceph@sha256:f239715e1c7756e32a202a572e2763a4ce15248e09fc6e8990985f8a09ffa784 Zapping /dev/sdb... Zapping /dev/sdc... |
|
[root@ceph05 ~]# cephadm rm-cluster --help |
|
usage: cephadm rm-cluster [-h] --fsid FSID [--force] [--keep-logs] [--zap-osds] optional arguments: -h, --help show this help message and exit --fsid FSID cluster FSID --force proceed, even though this may destroy valuable data --keep-logs do not remove log files --zap-osds zap OSD devices for this cluster |
3.2管理ceph集群
3.2.1管理守护进程
3.2.1.1使用systemctl管理守护进程
在ceph集群中,所有守护进程都是通过systemd进行管理的
可以使用systemctl stop|start|restart service_id启动或停止服务;也可使用ceph orch daemon stop|start|restart daemon_name启动或停止服务;
#查看所有守护进程,需要在相应节点上操作
|
[root@ceph01 ~]# systemctl --type=service | grep ceph |
|
ceph-4b4cc258-6679-11ee-ad4a-005056982bba@alertmanager.ceph01.service loaded active running Ceph alertmanager.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@ceph-exporter.ceph01.service loaded active running Ceph ceph-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@crash.ceph01.service loaded active running Ceph crash.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@grafana.ceph01.service loaded active running Ceph grafana.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mds.cephfs.ceph01.aibnpt.service loaded active running Ceph mds.cephfs.ceph01.aibnpt for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mgr.ceph01.ywwete.service loaded active running Ceph mgr.ceph01.ywwete for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mon.ceph01.service loaded active running Ceph mon.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@node-exporter.ceph01.service loaded active running Ceph node-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.0.service loaded active running Ceph osd.0 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.1.service loaded active running Ceph osd.1 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@prometheus.ceph01.service loaded active running Ceph prometheus.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-crash.service loaded active running Ceph crash dump collector |
|
[root@ceph01 ~]# ceph orch ls |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 8m ago 47h count:1 ceph-exporter 5/5 8m ago 47h * crash 5/5 8m ago 47h * grafana ?:3000 1/1 8m ago 26h ceph01 mds.cephfs 3/3 8m ago 27h ceph01;ceph02;ceph03;count:3 mgr 2/2 8m ago 47h count:2 mon 3/3 8m ago 25h label:mon node-exporter ?:9100 5/5 8m ago 47h * osd 10 8m ago - prometheus ?:9095 1/1 8m ago 47h count:1 |
|
[root@ceph02 ~]# systemctl --type=service | grep ceph |
|
ceph-4b4cc258-6679-11ee-ad4a-005056982bba@ceph-exporter.ceph02.service loaded active running Ceph ceph-exporter.ceph02 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@crash.ceph02.service loaded active running Ceph crash.ceph02 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mds.cephfs.ceph02.kzinfm.service loaded active running Ceph mds.cephfs.ceph02.kzinfm for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mon.ceph02.service loaded active running Ceph mon.ceph02 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@node-exporter.ceph02.service loaded active running Ceph node-exporter.ceph02 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.2.service loaded active running Ceph osd.2 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.3.service loaded active running Ceph osd.3 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-crash.service loaded active running Ceph crash dump collector |
#重启守护进程,需要在相应节点上操作
|
[root@ceph01 ~]# systemctl restart ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mon.ceph01.service |
#停止守护进程,需要在相应节点上操作
|
[root@ceph01 ~]# ceph orch ps daemon_type=node-exporter |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID node-exporter.ceph01 ceph01 *:9100 running (47h) 4m ago 47h 29.8M - 1.5.0 0da6a335fe13 a954f05187f7 node-exporter.ceph02 ceph02 *:9100 running (46h) 19s ago 46h 28.4M - 1.5.0 0da6a335fe13 8cd0b6e2eb9f node-exporter.ceph03 ceph03 *:9100 running (47h) 7m ago 47h 30.7M - 1.5.0 0da6a335fe13 5d0023a9d9ac node-exporter.ceph04 ceph04 *:9100 running (47h) 4m ago 47h 30.7M - 1.5.0 0da6a335fe13 ad2a61c7a224 node-exporter.ceph05 ceph05 *:9100 running (90m) 87s ago 90m 16.8M - 1.5.0 0da6a335fe13 e04a809f0376 |
|
[root@ceph01 ~]# systemctl stop ceph-4b4cc258-6679-11ee-ad4a-005056982bba@node-exporter.ceph01.service [root@ceph01 ~]# systemctl --type=service | grep ceph |
|
ceph-4b4cc258-6679-11ee-ad4a-005056982bba@alertmanager.ceph01.service loaded active running Ceph alertmanager.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@ceph-exporter.ceph01.service loaded active running Ceph ceph-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@crash.ceph01.service loaded active running Ceph crash.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@grafana.ceph01.service loaded active running Ceph grafana.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mds.cephfs.ceph01.aibnpt.service loaded active running Ceph mds.cephfs.ceph01.aibnpt for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mgr.ceph01.ywwete.service loaded active running Ceph mgr.ceph01.ywwete for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mon.ceph01.service loaded active running Ceph mon.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ● ceph-4b4cc258-6679-11ee-ad4a-005056982bba@node-exporter.ceph01.service loaded failed failed Ceph node-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.0.service loaded active running Ceph osd.0 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.1.service loaded active running Ceph osd.1 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@prometheus.ceph01.service loaded active running Ceph prometheus.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-crash.service loaded active running Ceph crash dump collector |
|
[root@ceph01 ~]# netstat -ntlp | grep 9100 [root@ceph01 ~]# ceph orch ps --refresh |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID alertmanager.ceph01 ceph01 *:9093,9094 running (47h) 3m ago 2d 24.1M - 0.25.0 c8568f914cd2 03024acf467e ceph-exporter.ceph01 ceph01 running (2d) 3m ago 2d 17.6M - 18.2.0 2ddfbd2845f4 45b49253fe32 ceph-exporter.ceph02 ceph02 running (47h) 10m ago 47h 31.5M - 18.2.0 2ddfbd2845f4 2546817aab89 ceph-exporter.ceph03 ceph03 running (47h) 7m ago 47h 31.5M - 18.2.0 2ddfbd2845f4 e70e11057e78 ceph-exporter.ceph04 ceph04 running (47h) 3m ago 47h 31.1M - 18.2.0 2ddfbd2845f4 f294ff260174 ceph-exporter.ceph05 ceph05 running (100m) 39s ago 100m 9.91M - 18.2.0 2ddfbd2845f4 18f287bed785 crash.ceph01 ceph01 running (2d) 3m ago 2d 7096k - 18.2.0 2ddfbd2845f4 42b819c1d277 crash.ceph02 ceph02 running (47h) 10m ago 47h 10.1M - 18.2.0 2ddfbd2845f4 3b4fd4cadb3e crash.ceph03 ceph03 running (47h) 7m ago 47h 10.0M - 18.2.0 2ddfbd2845f4 51342f1a2ecd crash.ceph04 ceph04 running (47h) 3m ago 47h 10.1M - 18.2.0 2ddfbd2845f4 4824930bada2 crash.ceph05 ceph05 running (100m) 39s ago 100m 7088k - 18.2.0 2ddfbd2845f4 a99163decd6b grafana.ceph01 ceph01 *:3000 running (26h) 3m ago 26h 94.9M - 9.4.7 2c41d148cca3 9636b35d97ef mds.cephfs.ceph01.aibnpt ceph01 running (28h) 3m ago 28h 27.3M - 18.2.0 2ddfbd2845f4 47174fba9bc0 mds.cephfs.ceph02.kzinfm ceph02 running (28h) 10m ago 28h 27.4M - 18.2.0 2ddfbd2845f4 e49ff6578da6 mds.cephfs.ceph03.pdkglx ceph03 running (28h) 7m ago 28h 27.4M - 18.2.0 2ddfbd2845f4 39761285bc18 mgr.ceph01.ywwete ceph01 *:9283,8765,8443 running (2d) 3m ago 2d 680M - 18.2.0 2ddfbd2845f4 2d2752586bdc mgr.ceph04.ykcgel ceph04 *:8443,9283,8765 running (47h) 3m ago 47h 459M - 18.2.0 2ddfbd2845f4 ce7f89b9d81f mon.ceph01 ceph01 running (12m) 3m ago 2d 40.0M 2048M 18.2.0 2ddfbd2845f4 dec04d0c648d mon.ceph02 ceph02 running (47h) 10m ago 47h 424M 2048M 18.2.0 2ddfbd2845f4 b511e94994b0 mon.ceph03 ceph03 running (47h) 7m ago 47h 416M 2048M 18.2.0 2ddfbd2845f4 344830d1f960 node-exporter.ceph01 ceph01 *:9100 error 3m ago 2d - - node-exporter.ceph02 ceph02 *:9100 running (47h) 10m ago 47h 28.4M - 1.5.0 0da6a335fe13 8cd0b6e2eb9f node-exporter.ceph03 ceph03 *:9100 running (47h) 7m ago 47h 30.8M - 1.5.0 0da6a335fe13 5d0023a9d9ac node-exporter.ceph04 ceph04 *:9100 running (47h) 3m ago 47h 30.3M - 1.5.0 0da6a335fe13 ad2a61c7a224 node-exporter.ceph05 ceph05 *:9100 running (100m) 39s ago 100m 17.1M - 1.5.0 0da6a335fe13 e04a809f0376 osd.0 ceph01 running (46h) 3m ago 46h 92.9M 4096M 18.2.0 2ddfbd2845f4 601ee7e09d85 osd.1 ceph01 running (46h) 3m ago 46h 96.5M 4096M 18.2.0 2ddfbd2845f4 18a2e23daeac osd.2 ceph02 running (46h) 10m ago 46h 90.4M 4096M 18.2.0 2ddfbd2845f4 2d1dca056476 osd.3 ceph02 running (46h) 10m ago 46h 92.4M 4096M 18.2.0 2ddfbd2845f4 2a8d7f72a03b osd.4 ceph03 running (46h) 7m ago 46h 91.4M 4096M 18.2.0 2ddfbd2845f4 363db89e7f48 osd.5 ceph03 running (46h) 7m ago 46h 95.9M 4096M 18.2.0 2ddfbd2845f4 1c5b076345a0 osd.6 ceph04 running (46h) 3m ago 46h 93.3M 4096M 18.2.0 2ddfbd2845f4 8c11b3ec9f78 osd.7 ceph04 running (46h) 3m ago 46h 91.3M 4096M 18.2.0 2ddfbd2845f4 01646673ed19 osd.8 ceph05 running (98m) 39s ago 98m 82.5M 1696M 18.2.0 2ddfbd2845f4 7a64e10bfcb0 osd.9 ceph05 running (97m) 39s ago 97m 81.1M 1696M 18.2.0 2ddfbd2845f4 c6a2dfa7cb73 prometheus.ceph01 ceph01 *:9095 running (100m) 3m ago 2d 114M - 2.43.0 a07b618ecd1d ce9ea20927d7 |
#启动守护进程,需要在相应节点上操作
|
[root@ceph01 ~]# systemctl start ceph-4b4cc258-6679-11ee-ad4a-005056982bba@node-exporter.ceph01.service [root@ceph01 ~]# systemctl --type=service | grep ceph |
|
ceph-4b4cc258-6679-11ee-ad4a-005056982bba@alertmanager.ceph01.service loaded active running Ceph alertmanager.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@ceph-exporter.ceph01.service loaded active running Ceph ceph-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@crash.ceph01.service loaded active running Ceph crash.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@grafana.ceph01.service loaded active running Ceph grafana.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mds.cephfs.ceph01.aibnpt.service loaded active running Ceph mds.cephfs.ceph01.aibnpt for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mgr.ceph01.ywwete.service loaded active running Ceph mgr.ceph01.ywwete for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mon.ceph01.service loaded active running Ceph mon.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@node-exporter.ceph01.service loaded active running Ceph node-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.0.service loaded active running Ceph osd.0 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.1.service loaded active running Ceph osd.1 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@prometheus.ceph01.service loaded active running Ceph prometheus.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-crash.service loaded active running Ceph crash dump collector |
|
[root@ceph01 ~]# netstat -ntlp | grep 9100 |
|
tcp6 0 0 :::9100 :::* LISTEN 692651/node_exporte |
使用ceph orch daemon来启动或停止服务
注意:使用ceph orch ps 查看守护进程状态会有延迟,可加上--refresh参数
3.2.1.2使用ceph orch daemon管理服务
#查看守护进程,在管理节点上操作即可
|
[root@ceph01 ~]# ceph orch ps |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID alertmanager.ceph01 ceph01 *:9093,9094 running (47h) 99s ago 2d 24.2M - 0.25.0 c8568f914cd2 03024acf467e ceph-exporter.ceph01 ceph01 running (2d) 99s ago 2d 17.6M - 18.2.0 2ddfbd2845f4 45b49253fe32 ceph-exporter.ceph02 ceph02 running (47h) 99s ago 47h 31.5M - 18.2.0 2ddfbd2845f4 2546817aab89 ceph-exporter.ceph03 ceph03 running (47h) 99s ago 47h 31.5M - 18.2.0 2ddfbd2845f4 e70e11057e78 ceph-exporter.ceph04 ceph04 running (47h) 99s ago 47h 31.2M - 18.2.0 2ddfbd2845f4 f294ff260174 ceph-exporter.ceph05 ceph05 running (2h) 99s ago 2h 10.4M - 18.2.0 2ddfbd2845f4 18f287bed785 crash.ceph01 ceph01 running (2d) 99s ago 2d 7096k - 18.2.0 2ddfbd2845f4 42b819c1d277 crash.ceph02 ceph02 running (47h) 99s ago 47h 10.1M - 18.2.0 2ddfbd2845f4 3b4fd4cadb3e crash.ceph03 ceph03 running (47h) 99s ago 47h 10.0M - 18.2.0 2ddfbd2845f4 51342f1a2ecd crash.ceph04 ceph04 running (47h) 99s ago 47h 10.1M - 18.2.0 2ddfbd2845f4 4824930bada2 crash.ceph05 ceph05 running (2h) 99s ago 2h 7088k - 18.2.0 2ddfbd2845f4 a99163decd6b grafana.ceph01 ceph01 *:3000 running (27h) 99s ago 27h 95.8M - 9.4.7 2c41d148cca3 9636b35d97ef mds.cephfs.ceph01.aibnpt ceph01 running (28h) 99s ago 28h 27.3M - 18.2.0 2ddfbd2845f4 47174fba9bc0 mds.cephfs.ceph02.kzinfm ceph02 running (28h) 99s ago 28h 27.4M - 18.2.0 2ddfbd2845f4 e49ff6578da6 mds.cephfs.ceph03.pdkglx ceph03 running (28h) 99s ago 28h 27.2M - 18.2.0 2ddfbd2845f4 39761285bc18 mgr.ceph01.ywwete ceph01 *:9283,8765,8443 running (2d) 99s ago 2d 678M - 18.2.0 2ddfbd2845f4 2d2752586bdc mgr.ceph04.ykcgel ceph04 *:8443,9283,8765 running (47h) 99s ago 47h 459M - 18.2.0 2ddfbd2845f4 ce7f89b9d81f mon.ceph01 ceph01 running (34m) 99s ago 2d 57.1M 2048M 18.2.0 2ddfbd2845f4 dec04d0c648d mon.ceph02 ceph02 running (47h) 99s ago 47h 423M 2048M 18.2.0 2ddfbd2845f4 b511e94994b0 mon.ceph03 ceph03 running (47h) 99s ago 47h 417M 2048M 18.2.0 2ddfbd2845f4 344830d1f960 node-exporter.ceph01 ceph01 *:9100 running (2m) 99s ago 2d 7923k - 1.5.0 0da6a335fe13 847649026ef8 node-exporter.ceph02 ceph02 *:9100 running (47h) 99s ago 47h 28.2M - 1.5.0 0da6a335fe13 8cd0b6e2eb9f node-exporter.ceph03 ceph03 *:9100 running (47h) 99s ago 47h 30.7M - 1.5.0 0da6a335fe13 5d0023a9d9ac node-exporter.ceph04 ceph04 *:9100 running (47h) 99s ago 47h 30.7M - 1.5.0 0da6a335fe13 ad2a61c7a224 node-exporter.ceph05 ceph05 *:9100 running (2h) 99s ago 2h 17.1M - 1.5.0 0da6a335fe13 e04a809f0376 osd.0 ceph01 running (46h) 99s ago 46h 92.9M 4096M 18.2.0 2ddfbd2845f4 601ee7e09d85 osd.1 ceph01 running (46h) 99s ago 46h 96.5M 4096M 18.2.0 2ddfbd2845f4 18a2e23daeac osd.2 ceph02 running (46h) 99s ago 46h 90.5M 4096M 18.2.0 2ddfbd2845f4 2d1dca056476 osd.3 ceph02 running (46h) 99s ago 46h 92.3M 4096M 18.2.0 2ddfbd2845f4 2a8d7f72a03b osd.4 ceph03 running (46h) 99s ago 46h 91.5M 4096M 18.2.0 2ddfbd2845f4 363db89e7f48 osd.5 ceph03 running (46h) 99s ago 46h 95.9M 4096M 18.2.0 2ddfbd2845f4 1c5b076345a0 osd.6 ceph04 running (46h) 99s ago 46h 93.3M 4096M 18.2.0 2ddfbd2845f4 8c11b3ec9f78 osd.7 ceph04 running (46h) 99s ago 46h 91.3M 4096M 18.2.0 2ddfbd2845f4 01646673ed19 osd.8 ceph05 running (119m) 99s ago 119m 82.0M 1696M 18.2.0 2ddfbd2845f4 7a64e10bfcb0 osd.9 ceph05 running (118m) 99s ago 119m 80.7M 1696M 18.2.0 2ddfbd2845f4 c6a2dfa7cb73 prometheus.ceph01 ceph01 *:9095 running (2h) 99s ago 2d 120M - 2.43.0 a07b618ecd1d ce9ea20927d7 |
#重启守护进程
|
[root@ceph01 ~]# ceph orch daemon restart mon.ceph01 |
|
Scheduled to restart mon.ceph01 on host 'ceph01' |
#停止守护进程
|
[root@ceph01 ~]# ceph orch daemon stop mon.ceph01 |
|
Scheduled to stop mon.ceph01 on host 'ceph01' |
#查看状态
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_WARN 1/3 mons down, quorum ceph03,ceph02 services: mon: 3 daemons, quorum ceph03,ceph02 (age 51s), out of quorum: ceph01 mgr: ceph01.ywwete(active, since 2d), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 2h), 10 in (since 46h) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 754 MiB used, 999 GiB / 1000 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph orch ps --refresh |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID alertmanager.ceph01 ceph01 *:9093,9094 running (47h) 86s ago 2d 24.1M - 0.25.0 c8568f914cd2 03024acf467e ceph-exporter.ceph01 ceph01 running (2d) 86s ago 2d 17.6M - 18.2.0 2ddfbd2845f4 45b49253fe32 ceph-exporter.ceph02 ceph02 running (47h) 9m ago 47h 31.5M - 18.2.0 2ddfbd2845f4 2546817aab89 ceph-exporter.ceph03 ceph03 running (47h) 9m ago 47h 31.5M - 18.2.0 2ddfbd2845f4 e70e11057e78 ceph-exporter.ceph04 ceph04 running (47h) 9m ago 47h 31.2M - 18.2.0 2ddfbd2845f4 f294ff260174 ceph-exporter.ceph05 ceph05 running (2h) 9m ago 2h 10.6M - 18.2.0 2ddfbd2845f4 18f287bed785 crash.ceph01 ceph01 running (2d) 86s ago 2d 7096k - 18.2.0 2ddfbd2845f4 42b819c1d277 crash.ceph02 ceph02 running (47h) 9m ago 47h 10.1M - 18.2.0 2ddfbd2845f4 3b4fd4cadb3e crash.ceph03 ceph03 running (47h) 9m ago 47h 10.0M - 18.2.0 2ddfbd2845f4 51342f1a2ecd crash.ceph04 ceph04 running (47h) 9m ago 47h 10.1M - 18.2.0 2ddfbd2845f4 4824930bada2 crash.ceph05 ceph05 running (2h) 9m ago 2h 7088k - 18.2.0 2ddfbd2845f4 a99163decd6b grafana.ceph01 ceph01 *:3000 running (27h) 86s ago 27h 93.1M - 9.4.7 2c41d148cca3 9636b35d97ef mds.cephfs.ceph01.aibnpt ceph01 running (28h) 86s ago 28h 27.3M - 18.2.0 2ddfbd2845f4 47174fba9bc0 mds.cephfs.ceph02.kzinfm ceph02 running (28h) 9m ago 28h 27.4M - 18.2.0 2ddfbd2845f4 e49ff6578da6 mds.cephfs.ceph03.pdkglx ceph03 running (28h) 9m ago 28h 27.2M - 18.2.0 2ddfbd2845f4 39761285bc18 mgr.ceph01.ywwete ceph01 *:9283,8765,8443 running (2d) 86s ago 2d 676M - 18.2.0 2ddfbd2845f4 2d2752586bdc mgr.ceph04.ykcgel ceph04 *:8443,9283,8765 running (47h) 9m ago 47h 459M - 18.2.0 2ddfbd2845f4 ce7f89b9d81f mon.ceph01 ceph01 stopped 86s ago 2d - 2048M mon.ceph02 ceph02 running (47h) 9m ago 47h 422M 2048M 18.2.0 2ddfbd2845f4 b511e94994b0 mon.ceph03 ceph03 running (47h) 9m ago 47h 417M 2048M 18.2.0 2ddfbd2845f4 344830d1f960 node-exporter.ceph01 ceph01 *:9100 running (19m) 86s ago 2d 16.7M - 1.5.0 0da6a335fe13 847649026ef8 node-exporter.ceph02 ceph02 *:9100 running (47h) 9m ago 47h 28.4M - 1.5.0 0da6a335fe13 8cd0b6e2eb9f node-exporter.ceph03 ceph03 *:9100 running (47h) 9m ago 47h 30.9M - 1.5.0 0da6a335fe13 5d0023a9d9ac node-exporter.ceph04 ceph04 *:9100 running (47h) 9m ago 47h 30.5M - 1.5.0 0da6a335fe13 ad2a61c7a224 node-exporter.ceph05 ceph05 *:9100 running (2h) 9m ago 2h 17.1M - 1.5.0 0da6a335fe13 e04a809f0376 osd.0 ceph01 running (47h) 86s ago 47h 93.0M 4096M 18.2.0 2ddfbd2845f4 601ee7e09d85 osd.1 ceph01 running (47h) 86s ago 47h 96.6M 4096M 18.2.0 2ddfbd2845f4 18a2e23daeac osd.2 ceph02 running (47h) 9m ago 47h 91.0M 4096M 18.2.0 2ddfbd2845f4 2d1dca056476 osd.3 ceph02 running (47h) 9m ago 47h 92.8M 4096M 18.2.0 2ddfbd2845f4 2a8d7f72a03b osd.4 ceph03 running (46h) 9m ago 46h 92.0M 4096M 18.2.0 2ddfbd2845f4 363db89e7f48 osd.5 ceph03 running (46h) 9m ago 46h 96.4M 4096M 18.2.0 2ddfbd2845f4 1c5b076345a0 osd.6 ceph04 running (46h) 9m ago 46h 93.4M 4096M 18.2.0 2ddfbd2845f4 8c11b3ec9f78 osd.7 ceph04 running (46h) 9m ago 46h 91.4M 4096M 18.2.0 2ddfbd2845f4 01646673ed19 osd.8 ceph05 running (2h) 9m ago 2h 82.0M 1696M 18.2.0 2ddfbd2845f4 7a64e10bfcb0 osd.9 ceph05 running (2h) 9m ago 2h 80.7M 1696M 18.2.0 2ddfbd2845f4 c6a2dfa7cb73 prometheus.ceph01 ceph01 *:9095 running (2h) 86s ago 2d 122M - 2.43.0 a07b618ecd1d ce9ea20927d7 |
#启动守护进程
|
[root@ceph01 ~]# ceph orch daemon start mon.ceph01 |
|
Scheduled to start mon.ceph01 on host 'ceph01' |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 2s) mgr: ceph01.ywwete(active, since 2d), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 2h), 10 in (since 46h) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 754 MiB used, 999 GiB / 1000 GiB avail pgs: 193 active+clean |
3.2.2重启服务
ceph服务是把具有相同类型的ceph守护进程进行逻辑分组。ceph中的编排层允许用户以集中的方式管理这些服务,从而可以轻松地执行影响到同一逻辑服务的所有ceph守护进程的操作。每个节点上运行的ceph守护进程通过systemd服务进行管理。可以从要管理ceph服务的主机启动、停止和重新启动所有ceph服务。
#查看服务
|
[root@ceph01 ~]# ceph orch ls |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 7m ago 2d count:1 ceph-exporter 5/5 9m ago 2d * crash 5/5 9m ago 2d * grafana ?:3000 1/1 7m ago 27h ceph01 mds.cephfs 3/3 9m ago 28h ceph01;ceph02;ceph03;count:3 mgr 2/2 9m ago 2d count:2 mon 3/3 9m ago 26h label:mon node-exporter ?:9100 5/5 9m ago 2d * osd 10 9m ago - prometheus ?:9095 1/1 7m ago 2d count:1 |
#停止服务
|
[root@ceph01 ~]# ceph orch stop grafana |
|
Scheduled to stop grafana.ceph01 on host 'ceph01' |
|
[root@ceph01 ~]# ceph orch ls --refresh |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 55s ago 2d count:1 ceph-exporter 5/5 2m ago 2d * crash 5/5 2m ago 2d * grafana ?:3000 0/1 55s ago 27h ceph01 mds.cephfs 3/3 2m ago 29h ceph01;ceph02;ceph03;count:3 mgr 2/2 2m ago 2d count:2 mon 3/3 2m ago 26h label:mon node-exporter ?:9100 5/5 2m ago 2d * osd 10 2m ago - prometheus ?:9095 1/1 55s ago 2d count:1 |
#启动服务
|
[root@ceph01 ~]# ceph orch start grafana |
|
Scheduled to start grafana.ceph01 on host 'ceph01' |
|
[root@ceph01 ~]# ceph orch ls --refresh |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 7s ago 2d count:1 ceph-exporter 5/5 2m ago 2d * crash 5/5 2m ago 2d * grafana ?:3000 1/1 7s ago 27h ceph01 mds.cephfs 3/3 2m ago 29h ceph01;ceph02;ceph03;count:3 mgr 2/2 2m ago 2d count:2 mon 3/3 2m ago 26h label:mon node-exporter ?:9100 5/5 2m ago 2d * osd 10 2m ago - prometheus ?:9095 1/1 7s ago 2d count:1 |
#重启服务
|
[root@ceph01 ~]# ceph orch restart mon |
|
Scheduled to restart mon.ceph01 on host 'ceph01' Scheduled to restart mon.ceph02 on host 'ceph02' Scheduled to restart mon.ceph03 on host 'ceph03' |
说明:ceph orch rm 命令可以用来删除服务
3.2.3查看守护进程日志
#查看守护进程日志,需要在相应节点操作
|
[root@ceph01 ~]# systemctl --type=service | grep ceph |
|
ceph-4b4cc258-6679-11ee-ad4a-005056982bba@alertmanager.ceph01.service loaded active running Ceph alertmanager.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@ceph-exporter.ceph01.service loaded active running Ceph ceph-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@crash.ceph01.service loaded active running Ceph crash.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@grafana.ceph01.service loaded active running Ceph grafana.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mds.cephfs.ceph01.aibnpt.service loaded active running Ceph mds.cephfs.ceph01.aibnpt for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mgr.ceph01.ywwete.service loaded active running Ceph mgr.ceph01.ywwete for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mon.ceph01.service loaded active running Ceph mon.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@node-exporter.ceph01.service loaded active running Ceph node-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.0.service loaded active running Ceph osd.0 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.1.service loaded active running Ceph osd.1 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@prometheus.ceph01.service loaded active running Ceph prometheus.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-crash.service loaded active running Ceph crash dump collector |
|
[root@ceph01 ~]# journalctl -u ceph-4b4cc258-6679-11ee-ad4a-005056982bba@grafana.ceph01.service -f |
|
-- Logs begin at Mon 2023-10-09 13:38:31 CST. -- Oct 11 17:01:50 ceph01 bash[709962]: logger=provisioning.datasources t=2023-10-11T09:01:50.33768545Z level=info msg="deleted datasource based on configuration" name=Dashboard1 Oct 11 17:01:50 ceph01 bash[709962]: logger=provisioning.datasources t=2023-10-11T09:01:50.349039257Z level=info msg="inserting datasource from configuration " name=Dashboard1 uid=P43CA22E17D0F9596 Oct 11 17:01:50 ceph01 bash[709962]: logger=provisioning.alerting t=2023-10-11T09:01:50.575431283Z level=info msg="starting to provision alerting" Oct 11 17:01:50 ceph01 bash[709962]: logger=provisioning.alerting t=2023-10-11T09:01:50.575502093Z level=info msg="finished to provision alerting" Oct 11 17:01:50 ceph01 bash[709962]: logger=grafanaStorageLogger t=2023-10-11T09:01:50.576345452Z level=info msg="storage starting" Oct 11 17:01:50 ceph01 bash[709962]: logger=ngalert.state.manager t=2023-10-11T09:01:50.576968554Z level=info msg="Warming state cache for startup" Oct 11 17:01:50 ceph01 bash[709962]: logger=http.server t=2023-10-11T09:01:50.578867373Z level=info msg="HTTP Server Listen" address=[::]:3000 protocol=https subUrl= socket= Oct 11 17:01:50 ceph01 bash[709962]: logger=ngalert.state.manager t=2023-10-11T09:01:50.628247332Z level=info msg="State cache has been initialized" states=0 duration=51.27762ms Oct 11 17:01:50 ceph01 bash[709962]: logger=ticker t=2023-10-11T09:01:50.628327176Z level=info msg=starting first_tick=2023-10-11T09:02:00Z Oct 11 17:01:50 ceph01 bash[709962]: logger=ngalert.multiorg.alertmanager t=2023-10-11T09:01:50.628341586Z level=info msg="starting MultiOrg Alertmanager" |
3.2.4关闭集群
3.2.4.1使用systemctl关闭集群
使用systemctl命令关闭集群,涉及到以下步骤
1#停止cephfs
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 28m) mgr: ceph01.ywwete(active, since 2d), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 3h), 10 in (since 47h) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 754 MiB used, 999 GiB / 1000 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph fs ls |
|
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ] |
|
[root@ceph01 ~]# ceph fs set cephfs max_mds 1 [root@ceph01 ~]# ceph fs fail cephfs |
|
cephfs marked not joinable; MDS cannot join the cluster. All MDS ranks marked failed. |
|
[root@ceph01 ~]# ceph status |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_ERR 1 filesystem is degraded 1 filesystem is offline services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 32m) mgr: ceph01.ywwete(active, since 2d), standbys: ceph04.ykcgel mds: 0/1 daemons up (1 failed), 3 standby osd: 10 osds: 10 up (since 3h), 10 in (since 47h) data: volumes: 0/1 healthy, 1 failed pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 754 MiB used, 999 GiB / 1000 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph fs set cephfs joinable false |
|
cephfs marked not joinable; MDS cannot join as newly active. |
2#为OSD设置noout、norecover、 noreblance、nobackfill、nodown、pause标志
|
[root@ceph01 ~]# ceph osd set noout |
|
noout is set |
|
[root@ceph01 ~]# ceph osd set norecover |
|
norecover is set |
|
[root@ceph01 ~]# ceph osd set norebalance |
|
norebalance is set |
|
[root@ceph01 ~]# ceph osd set nobackfill |
|
nobackfill is set |
|
[root@ceph01 ~]# ceph osd set nodown |
|
nodown is set |
|
[root@ceph01 ~]# ceph osd set pause |
|
pauserd,pausewr is set |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_ERR 1 filesystem is degraded 1 filesystem is offline pauserd,pausewr,nodown,noout,nobackfill,norebalance,norecover flag(s) set services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 41m) mgr: ceph01.ywwete(active, since 2d), standbys: ceph04.ykcgel mds: 0/1 daemons up (1 failed), 3 standby osd: 10 osds: 10 up (since 3h), 10 in (since 47h) flags pauserd,pausewr,nodown,noout,nobackfill,norebalance,norecover data: volumes: 0/1 healthy, 1 failed pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 755 MiB used, 999 GiB / 1000 GiB avail pgs: 193 active+clean |
3#关闭MDS和对象网关服务
|
[root@ceph01 ~]# ceph orch ls |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 2m ago 2d count:1 ceph-exporter 5/5 2m ago 2d * crash 5/5 2m ago 2d * grafana ?:3000 1/1 2m ago 28h ceph01 mds.cephfs 3/3 2m ago 30h ceph01;ceph02;ceph03;count:3 mgr 2/2 2m ago 2d count:2 mon 3/3 2m ago 27h label:mon node-exporter ?:9100 5/5 2m ago 2d * osd 10 2m ago - prometheus ?:9095 1/1 2m ago 2d count:1 |
|
[root@ceph01 ~]# ceph orch stop mds.cephfs |
|
Scheduled to stop mds.cephfs.ceph01.aibnpt on host 'ceph01' Scheduled to stop mds.cephfs.ceph02.kzinfm on host 'ceph02' Scheduled to stop mds.cephfs.ceph03.pdkglx on host 'ceph03' |
|
[root@ceph01 ~]# ceph orch ls --refresh |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 0s ago 2d count:1 ceph-exporter 5/5 1s ago 2d * crash 5/5 1s ago 2d * grafana ?:3000 1/1 0s ago 28h ceph01 mds.cephfs 0/3 1s ago 30h ceph01;ceph02;ceph03;count:3 mgr 2/2 1s ago 2d count:2 mon 3/3 1s ago 27h label:mon node-exporter ?:9100 5/5 1s ago 2d * osd 10 1s ago - prometheus ?:9095 1/1 0s ago 2d count:1 |
4#逐个关闭所有OSD
|
[root@ceph01 ~]# systemctl | grep ceph |
|
ceph-4b4cc258-6679-11ee-ad4a-005056982bba@alertmanager.ceph01.service loaded active running Ceph alertmanager.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@ceph-exporter.ceph01.service loaded active running Ceph ceph-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@crash.ceph01.service loaded active running Ceph crash.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@grafana.ceph01.service loaded active running Ceph grafana.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mgr.ceph01.ywwete.service loaded active running Ceph mgr.ceph01.ywwete for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mon.ceph01.service loaded active running Ceph mon.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@node-exporter.ceph01.service loaded active running Ceph node-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.0.service loaded active running Ceph osd.0 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.1.service loaded active running Ceph osd.1 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@prometheus.ceph01.service loaded active running Ceph prometheus.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-crash.service loaded active running Ceph crash dump collector system-ceph\x2d4b4cc258\x2d6679\x2d11ee\x2dad4a\x2d005056982bba.slice loaded active active system-ceph\x2d4b4cc258\x2d6679\x2d11ee\x2dad4a\x2d005056982bba.slice ceph-4b4cc258-6679-11ee-ad4a-005056982bba.target loaded active active Ceph cluster 4b4cc258-6679-11ee-ad4a-005056982bba ceph-mgr.target loaded active active ceph target allowing to start/stop all ceph-mgr@.service instances at once ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once ceph.target |
|
[root@ceph01 ~]# systemctl stop ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.0.service |
#或者使用下面命令停止osd
|
[root@ceph01 ~]# ceph orch ps | grep osd | awk '{print "ceph orch daemon stop " $1}' | bash |
|
Scheduled to stop osd.0 on host 'ceph01' Scheduled to stop osd.1 on host 'ceph01' Scheduled to stop osd.2 on host 'ceph02' Scheduled to stop osd.3 on host 'ceph02' Scheduled to stop osd.4 on host 'ceph03' Scheduled to stop osd.5 on host 'ceph03' Scheduled to stop osd.6 on host 'ceph04' Scheduled to stop osd.7 on host 'ceph04' Scheduled to stop osd.8 on host 'ceph05' Scheduled to stop osd.9 on host 'ceph05' |
|
[root@ceph01 ~]# ceph orch ps --refresh |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID alertmanager.ceph01 ceph01 *:9093,9094 running (2d) 22s ago 2d 24.6M - 0.25.0 c8568f914cd2 03024acf467e ceph-exporter.ceph01 ceph01 running (2d) 22s ago 2d 17.6M - 18.2.0 2ddfbd2845f4 45b49253fe32 ceph-exporter.ceph02 ceph02 running (2d) 22s ago 2d 31.8M - 18.2.0 2ddfbd2845f4 2546817aab89 ceph-exporter.ceph03 ceph03 running (2d) 22s ago 2d 31.9M - 18.2.0 2ddfbd2845f4 e70e11057e78 ceph-exporter.ceph04 ceph04 running (2d) 22s ago 2d 31.2M - 18.2.0 2ddfbd2845f4 f294ff260174 ceph-exporter.ceph05 ceph05 running (3h) 22s ago 3h 13.1M - 18.2.0 2ddfbd2845f4 18f287bed785 crash.ceph01 ceph01 running (2d) 22s ago 2d 7096k - 18.2.0 2ddfbd2845f4 42b819c1d277 crash.ceph02 ceph02 running (2d) 22s ago 2d 10.1M - 18.2.0 2ddfbd2845f4 3b4fd4cadb3e crash.ceph03 ceph03 running (2d) 22s ago 2d 10.0M - 18.2.0 2ddfbd2845f4 51342f1a2ecd crash.ceph04 ceph04 running (2d) 22s ago 2d 10.1M - 18.2.0 2ddfbd2845f4 4824930bada2 crash.ceph05 ceph05 running (3h) 22s ago 3h 7088k - 18.2.0 2ddfbd2845f4 a99163decd6b grafana.ceph01 ceph01 *:3000 running (75m) 22s ago 28h 89.7M - 9.4.7 2c41d148cca3 d7d63acb15c5 mds.cephfs.ceph01.aibnpt ceph01 stopped 22s ago 30h - - mds.cephfs.ceph02.kzinfm ceph02 stopped 22s ago 30h - - mds.cephfs.ceph03.pdkglx ceph03 stopped 22s ago 30h - - mgr.ceph01.ywwete ceph01 *:9283,8765,8443 running (2d) 22s ago 2d 684M - 18.2.0 2ddfbd2845f4 2d2752586bdc mgr.ceph04.ykcgel ceph04 *:8443,9283,8765 running (2d) 22s ago 2d 459M - 18.2.0 2ddfbd2845f4 ce7f89b9d81f mon.ceph01 ceph01 running (74m) 22s ago 2d 82.5M 2048M 18.2.0 2ddfbd2845f4 50c74c9dd65a mon.ceph02 ceph02 running (73m) 22s ago 2d 80.8M 2048M 18.2.0 2ddfbd2845f4 54d10384fa18 mon.ceph03 ceph03 running (73m) 22s ago 2d 76.2M 2048M 18.2.0 2ddfbd2845f4 b30f706022d7 node-exporter.ceph01 ceph01 *:9100 running (110m) 22s ago 2d 17.1M - 1.5.0 0da6a335fe13 847649026ef8 node-exporter.ceph02 ceph02 *:9100 running (2d) 22s ago 2d 28.4M - 1.5.0 0da6a335fe13 8cd0b6e2eb9f node-exporter.ceph03 ceph03 *:9100 running (2d) 22s ago 2d 30.5M - 1.5.0 0da6a335fe13 5d0023a9d9ac node-exporter.ceph04 ceph04 *:9100 running (2d) 22s ago 2d 30.8M - 1.5.0 0da6a335fe13 ad2a61c7a224 node-exporter.ceph05 ceph05 *:9100 running (3h) 22s ago 3h 17.4M - 1.5.0 0da6a335fe13 e04a809f0376 osd.0 ceph01 stopped 22s ago 2d - 4096M osd.1 ceph01 stopped 22s ago 2d - 4096M osd.2 ceph02 stopped 22s ago 2d - 4096M osd.3 ceph02 stopped 22s ago 2d - 4096M osd.4 ceph03 stopped 22s ago 2d - 4096M osd.5 ceph03 stopped 22s ago 2d - 4096M osd.6 ceph04 stopped 22s ago 2d - 4096M osd.7 ceph04 stopped 22s ago 2d - 4096M osd.8 ceph05 stopped 22s ago 3h - 1696M osd.9 ceph05 stopped 22s ago 3h - 1696M prometheus.ceph01 ceph01 *:9095 running (3h) 22s ago 2d 111M - 2.43.0 a07b618ecd1d ce9ea20927d7 |
5#逐个关闭所有mon
|
[root@ceph01 ~]# systemctl | grep ceph |
|
ceph-4b4cc258-6679-11ee-ad4a-005056982bba@alertmanager.ceph01.service loaded active running Ceph alertmanager.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@ceph-exporter.ceph01.service loaded active running Ceph ceph-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@crash.ceph01.service loaded active running Ceph crash.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@grafana.ceph01.service loaded active running Ceph grafana.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mgr.ceph01.ywwete.service loaded active running Ceph mgr.ceph01.ywwete for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mon.ceph01.service loaded active running Ceph mon.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@node-exporter.ceph01.service loaded active running Ceph node-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@prometheus.ceph01.service loaded active running Ceph prometheus.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-crash.service loaded active running Ceph crash dump collector system-ceph\x2d4b4cc258\x2d6679\x2d11ee\x2dad4a\x2d005056982bba.slice loaded active active system-ceph\x2d4b4cc258\x2d6679\x2d11ee\x2dad4a\x2d005056982bba.slice ceph-4b4cc258-6679-11ee-ad4a-005056982bba.target loaded active active Ceph cluster 4b4cc258-6679-11ee-ad4a-005056982bba ceph-mgr.target loaded active active ceph target allowing to start/stop all ceph-mgr@.service instances at once ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once ceph.target loaded active active All Ceph clusters and services |
|
[root@ceph01 ~]# systemctl stop ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mon.ceph01.service |
#或者使用下面命令停止mon
|
[root@ceph01 ~]# ceph orch ps | grep mon | awk '{print "ceph orch daemon stop " $1}' | bash |
|
Scheduled to stop mon.ceph01 on host 'ceph01' Scheduled to stop mon.ceph02 on host 'ceph02' Scheduled to stop mon.ceph03 on host 'ceph03' |
|
[root@ceph01 ~]# systemctl | grep ceph |
|
6#ceph-4b4cc258-6679-11ee-ad4a-005056982bba@alertmanager.ceph01.service loaded active running Ceph alertmanager.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@ceph-exporter.ceph01.service loaded active running Ceph ceph-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@crash.ceph01.service loaded active running Ceph crash.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@grafana.ceph01.service loaded active running Ceph grafana.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mgr.ceph01.ywwete.service loaded active running Ceph mgr.ceph01.ywwete for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@node-exporter.ceph01.service loaded active running Ceph node-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@prometheus.ceph01.service loaded active running Ceph prometheus.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-crash.service loaded active running Ceph crash dump collector system-ceph\x2d4b4cc258\x2d6679\x2d11ee\x2dad4a\x2d005056982bba.slice loaded active active system-ceph\x2d4b4cc258\x2d6679\x2d11ee\x2dad4a\x2d005056982bba.slice ceph-4b4cc258-6679-11ee-ad4a-005056982bba.target loaded active active Ceph cluster 4b4cc258-6679-11ee-ad4a-005056982bba ceph-mgr.target loaded active active ceph target allowing to start/stop all ceph-mgr@.service instances at once ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once ceph.target loaded active active All Ceph clusters and services |
6#逐个关闭所有mgr
|
[root@ceph01 ~]# systemctl stop ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mgr.ceph01.ywwete.service |
|
[root@ceph01 ~]# ceph orch ps | grep mgr | awk '{print "ceph orch daemon stop " $1}' | bash |
7#重启节点(或关闭节点)
关闭所有节点
|
[root@ceph01 ~]# init 0 |
说明:ceph osd set noout:防止标记osd为“out”状态,并暂停数据迁移和其他操作
ceph osd set norecover:禁用osd的数据恢复功能。
ceph osd set norebalance:禁用数据再平衡操作。
ceph osd set nobackfill:禁用数据回填操作。
ceph osd set nodown:禁用osd的下线。
ceph osd set pause:暂停osd的数据处理功能。
ceph mds fail cephfs:1:关闭指定的ceph文件系统。
3.2.4.2使用orch关闭集群
1#停止cephfs
|
[root@ceph01 ~]# ceph fs set cephfs max_mds 1 [root@ceph01 ~]# ceph fs fail cephfs |
|
cephfs marked not joinable; MDS cannot join the cluster. All MDS ranks marked failed. |
|
[root@ceph01 ~]# ceph status |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_ERR 1 filesystem is degraded 1 filesystem is offline services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 15h) mgr: ceph01.ywwete(active, since 16h), standbys: ceph04.ykcgel mds: 0/1 daemons up (1 failed), 3 standby osd: 10 osds: 10 up (since 15h), 10 in (since 2d) data: volumes: 0/1 healthy, 1 failed pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 422 MiB used, 1000 GiB / 1000 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph fs set cephfs joinable false |
|
cephfs marked not joinable; MDS cannot join as newly active. |
2#为OSD设置noout、norecover、noreblance、nodown、pause标志
|
[root@ceph01 ~]# ceph osd set noout |
|
noout is set |
|
[root@ceph01 ~]# ceph osd set norecover |
|
norecover is set |
|
[root@ceph01 ~]# ceph osd set norebalance |
|
norebalance is set |
|
[root@ceph01 ~]# ceph osd set nobackfill |
|
nobackfill is set |
|
[root@ceph01 ~]# ceph osd set nodown |
|
nodown is set |
|
[root@ceph01 ~]# ceph osd set pause |
|
pauserd,pausewr is set |
3#停止MDS
|
[root@ceph01 ~]# ceph orch ls --service-type mds |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT mds.cephfs 3/3 5m ago 47h ceph01;ceph02;ceph03;count:3 |
|
[root@ceph01 ~]# ceph orch stop mds.cephfs |
|
Scheduled to stop mds.cephfs.ceph01.aibnpt on host 'ceph01' Scheduled to stop mds.cephfs.ceph02.kzinfm on host 'ceph02' Scheduled to stop mds.cephfs.ceph03.pdkglx on host 'ceph03' |
4#停止对象网关服务rgw
|
[root@ceph01 ~]# ceph orch ls --service-type rgw |
|
No services reported |
|
[root@ceph01 ~]# ceph orch stop prd.rgw |
5#逐个停止osd,在所有节点上操作停止相应osd
|
[root@ceph01 ~]# ceph orch ps --daemon-type=osd |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID osd.0 ceph01 running (16h) 3m ago 2d 53.2M 4096M 18.2.0 2ddfbd2845f4 5249eb942307 osd.1 ceph01 running (16h) 3m ago 2d 51.1M 4096M 18.2.0 2ddfbd2845f4 5f38d5e05ba5 osd.2 ceph02 running (16h) 3m ago 2d 53.3M 4096M 18.2.0 2ddfbd2845f4 e6b436b20fed osd.3 ceph02 running (16h) 3m ago 2d 53.5M 4096M 18.2.0 2ddfbd2845f4 2a5cfe31d7b4 osd.4 ceph03 running (16h) 3m ago 2d 68.7M 4096M 18.2.0 2ddfbd2845f4 b695551f9dc6 osd.5 ceph03 running (16h) 3m ago 2d 68.9M 4096M 18.2.0 2ddfbd2845f4 af31c7281a69 osd.6 ceph04 running (16h) 14s ago 2d 48.4M 4096M 18.2.0 2ddfbd2845f4 3f8e9f355f4c osd.7 ceph04 running (16h) 14s ago 2d 53.1M 4096M 18.2.0 2ddfbd2845f4 56d91efc4daf osd.8 ceph05 running (16h) 14s ago 21h 58.1M 1696M 18.2.0 2ddfbd2845f4 b7a864c1de41 osd.9 ceph05 running (16h) 14s ago 21h 61.0M 1696M 18.2.0 2ddfbd2845f4 885e0dbdb1ad |
|
[root@ceph01 ~]# ceph orch ps | grep osd | awk '{print "ceph orch daemon stop " $1}' | bash |
|
Scheduled to stop osd.0 on host 'ceph01' Scheduled to stop osd.1 on host 'ceph01' Scheduled to stop osd.2 on host 'ceph02' Scheduled to stop osd.3 on host 'ceph02' Scheduled to stop osd.4 on host 'ceph03' Scheduled to stop osd.5 on host 'ceph03' Scheduled to stop osd.6 on host 'ceph04' Scheduled to stop osd.7 on host 'ceph04' Scheduled to stop osd.8 on host 'ceph05' Scheduled to stop osd.9 on host 'ceph05' |
6#逐个停止监视器,在所有节点上操作停止mon
|
[root@ceph01 ~]# ceph orch ps | grep mon | awk '{print "ceph orch daemon stop " $1}' | bash |
|
Scheduled to stop mon.ceph01 on host 'ceph01' Scheduled to stop mon.ceph02 on host 'ceph02' Scheduled to stop mon.ceph03 on host 'ceph03' |
7#停止崩溃服务crash
|
[root@ceph01 ~]# ceph orch stop crash |
8#停止alertmanager
|
[root@ceph01 ~]# ceph orch stop alertmanager |
9#停止node-exporter
|
[root@ceph01 ~]# ceph orch stop node-exporter |
10#停止prometheus
|
[root@ceph01 ~]# ceph orch stop prometheus |
11#停止grafana
|
[root@ceph01 ~]# ceph orch stop grafana |
12#关闭主机
|
[root@ceph01 ~]# init 0 |
3.2.5重启集群
3.2.5.1重启systemctl关闭的集群
1#正常,节点重启后,会自启动相关服务,只需要用命令检查服务是否正常启动即可。
|
[root@ceph01 ~]# systemctl | grep ceph |
|
ceph-4b4cc258-6679-11ee-ad4a-005056982bba@alertmanager.ceph01.service loaded active running Ceph alertmanager.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@ceph-exporter.ceph01.service loaded active running Ceph ceph-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@crash.ceph01.service loaded active running Ceph crash.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@grafana.ceph01.service loaded active running Ceph grafana.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mds.cephfs.ceph01.aibnpt.service loaded active running Ceph mds.cephfs.ceph01.aibnpt for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mgr.ceph01.ywwete.service loaded active running Ceph mgr.ceph01.ywwete for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@mon.ceph01.service loaded active running Ceph mon.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@node-exporter.ceph01.service loaded active running Ceph node-exporter.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.0.service loaded active running Ceph osd.0 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@osd.1.service loaded active running Ceph osd.1 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-4b4cc258-6679-11ee-ad4a-005056982bba@prometheus.ceph01.service loaded active running Ceph prometheus.ceph01 for 4b4cc258-6679-11ee-ad4a-005056982bba ceph-crash.service loaded active running Ceph crash dump collector system-ceph\x2d4b4cc258\x2d6679\x2d11ee\x2dad4a\x2d005056982bba.slice loaded active active system-ceph\x2d4b4cc258\x2d6679\x2d11ee\x2dad4a\x2d005056982bba.slice ceph-4b4cc258-6679-11ee-ad4a-005056982bba.target loaded active active Ceph cluster 4b4cc258-6679-11ee-ad4a-005056982bba ceph-mds.target loaded active active ceph target allowing to start/stop all ceph-mds@.service instances at once ceph-mgr.target loaded active active ceph target allowing to start/stop all ceph-mgr@.service instances at once ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once ceph.target loaded active active All Ceph clusters and services |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_ERR 1 filesystem is degraded 1 filesystem is offline pauserd,pausewr,nodown,noout,nobackfill,norebalance,norecover flag(s) set services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 39s) mgr: ceph01.ywwete(active, since 6m), standbys: ceph04.ykcgel mds: 0/1 daemons up (1 failed), 3 standby osd: 10 osds: 10 up (since 3m), 10 in (since 2d) flags pauserd,pausewr,nodown,noout,nobackfill,norebalance,norecover data: volumes: 0/1 healthy, 1 failed pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 416 MiB used, 1000 GiB / 1000 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph orch ps --refresh |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID alertmanager.ceph01 ceph01 *:9093,9094 running (7m) 4s ago 2d 35.7M - 0.25.0 c8568f914cd2 c1b902158786 ceph-exporter.ceph01 ceph01 running (7m) 4s ago 2d 24.0M - 18.2.0 2ddfbd2845f4 ca320e116c00 ceph-exporter.ceph02 ceph02 running (7m) 5s ago 2d 14.2M - 18.2.0 2ddfbd2845f4 d9a496211062 ceph-exporter.ceph03 ceph03 running (7m) 73s ago 2d 19.0M - 18.2.0 2ddfbd2845f4 4e63e53eeadd ceph-exporter.ceph04 ceph04 running (5m) 5s ago 2d 7659k - 18.2.0 2ddfbd2845f4 30eb1332cf49 ceph-exporter.ceph05 ceph05 running (7m) 108s ago 4h 23.3M - 18.2.0 2ddfbd2845f4 262faebe21d4 crash.ceph01 ceph01 running (7m) 4s ago 2d 8624k - 18.2.0 2ddfbd2845f4 8d15dd453431 crash.ceph02 ceph02 running (7m) 5s ago 2d 12.2M - 18.2.0 2ddfbd2845f4 03b5237e1802 crash.ceph03 ceph03 running (7m) 73s ago 2d 12.0M - 18.2.0 2ddfbd2845f4 1650f36e86e9 crash.ceph04 ceph04 running (5m) 5s ago 2d 7075k - 18.2.0 2ddfbd2845f4 0c9bee814e56 crash.ceph05 ceph05 running (7m) 108s ago 4h 14.3M - 18.2.0 2ddfbd2845f4 65b690dbbac7 grafana.ceph01 ceph01 *:3000 running (7m) 4s ago 30h 154M - 9.4.7 2c41d148cca3 25e2e1a29348 mds.cephfs.ceph01.aibnpt ceph01 running (7m) 4s ago 31h 19.7M - 18.2.0 2ddfbd2845f4 5ab64d9611ee mds.cephfs.ceph02.kzinfm ceph02 running (5m) 5s ago 31h 18.5M - 18.2.0 2ddfbd2845f4 32317a374b0b mds.cephfs.ceph03.pdkglx ceph03 running (7m) 73s ago 31h 25.4M - 18.2.0 2ddfbd2845f4 df4dfa6e6046 mgr.ceph01.ywwete ceph01 *:9283,8765,8443 running (7m) 4s ago 2d 518M - 18.2.0 2ddfbd2845f4 cc62273c7b46 mgr.ceph04.ykcgel ceph04 *:8443,9283,8765 running (5m) 5s ago 2d 423M - 18.2.0 2ddfbd2845f4 4725bf209487 mon.ceph01 ceph01 running (2m) 4s ago 2d 37.3M 2048M 18.2.0 2ddfbd2845f4 0c702754da5c mon.ceph02 ceph02 running (80s) 5s ago 2d 24.5M 2048M 18.2.0 2ddfbd2845f4 b675c2ca79d5 mon.ceph03 ceph03 running (115s) 73s ago 2d 22.7M 2048M 18.2.0 2ddfbd2845f4 570de2f6a4e5 node-exporter.ceph01 ceph01 *:9100 running (7m) 4s ago 2d 19.0M - 1.5.0 0da6a335fe13 ce9432d47f8b node-exporter.ceph02 ceph02 *:9100 running (7m) 5s ago 2d 24.5M - 1.5.0 0da6a335fe13 408c56db453e node-exporter.ceph03 ceph03 *:9100 running (7m) 73s ago 2d 18.9M - 1.5.0 0da6a335fe13 5d568b35dcad node-exporter.ceph04 ceph04 *:9100 running (5m) 5s ago 2d 27.2M - 1.5.0 0da6a335fe13 4389b63e03f5 node-exporter.ceph05 ceph05 *:9100 running (7m) 108s ago 4h 27.6M - 1.5.0 0da6a335fe13 c73ce7b5471f osd.0 ceph01 running (7m) 4s ago 2d 48.5M 4096M 18.2.0 2ddfbd2845f4 5249eb942307 osd.1 ceph01 running (7m) 4s ago 2d 45.9M 4096M 18.2.0 2ddfbd2845f4 5f38d5e05ba5 osd.2 ceph02 running (7m) 5s ago 2d 48.5M 4096M 18.2.0 2ddfbd2845f4 e6b436b20fed osd.3 ceph02 running (7m) 5s ago 2d 49.0M 4096M 18.2.0 2ddfbd2845f4 2a5cfe31d7b4 osd.4 ceph03 running (7m) 73s ago 2d 63.6M 4096M 18.2.0 2ddfbd2845f4 b695551f9dc6 osd.5 ceph03 running (7m) 73s ago 2d 61.9M 4096M 18.2.0 2ddfbd2845f4 af31c7281a69 osd.6 ceph04 running (4m) 5s ago 2d 40.0M 4096M 18.2.0 2ddfbd2845f4 3f8e9f355f4c osd.7 ceph04 running (4m) 5s ago 2d 44.7M 4096M 18.2.0 2ddfbd2845f4 56d91efc4daf osd.8 ceph05 running (7m) 108s ago 4h 50.5M 1696M 18.2.0 2ddfbd2845f4 b7a864c1de41 osd.9 ceph05 running (7m) 108s ago 4h 55.4M 1696M 18.2.0 2ddfbd2845f4 885e0dbdb1ad prometheus.ceph01 ceph01 *:9095 running (6m) 4s ago 2d 99.2M - 2.43.0 a07b618ecd1d 8ec647e40c1f |
2#若节点均已上线,且服务都已经启动,此时就可以取消noout、norecover、 noreblance、nobackfill、nodown、pause标志
|
[root@ceph01 ~]# ceph osd unset noout |
|
noout is unset |
|
[root@ceph01 ~]# ceph osd unset norecover |
|
norecover is unset |
|
[root@ceph01 ~]# ceph osd unset norebalance |
|
norebalance is unset |
|
[root@ceph01 ~]# ceph osd unset nobackfill |
|
nobackfill is unset |
|
[root@ceph01 ~]# ceph osd unset nodown |
|
nodown is unset |
|
[root@ceph01 ~]# ceph osd unset pause |
|
pauserd,pausewr is unset |
3#如果使用了cephfs,需通过joinable标启为true来使cephfs集群重新启动
|
[root@ceph01 ~]# ceph fs set cephfs joinable true |
|
cephfs marked joinable; MDS may join as newly active. |
4#检查集群健康状态
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 16m) mgr: ceph01.ywwete(active, since 22m), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 19m), 10 in (since 2d) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 451 KiB usage: 417 MiB used, 1000 GiB / 1000 GiB avail pgs: 193 active+clean |
3.3管理Mon监视器
1#建议部署奇数个mon,生产环境要求至少3个mon,奇数个监控器对故障有更高的抗压性。例如,若要在2个mon上维护仲裁,ceph无法容忍任何故障;对于4个mon,可以容忍一个失败,对于五个mon,可以容忍2个失败。这就是建议为奇数的原因。ceph需要大多数mon正在运行,并能够相互通信。
2#配置mon选择策略,有3种mon策略
claasic默认策略,最低等级的监控,根据两个站点之间的选举模块进行投票,建议使用该模式,除非有不满足的特殊要求。
disallow此模式可让您将monitor标记为禁止,在这种情况下,他们会参与仲裁并服务客户端,但不能是选择的领导者。
connectivity这个模式主要用于解决网络差异。它会根据ping检查其对等点提供的ping评估连接分数,并选出最连接的、可靠mon成为leader。这个模式旨在处理网络分割,如果您的集群在多个数据中心间扩展或存在影响,则可能会出现这种情况。
3#部署mon
bootstrap节点是mon的初始节点,添加mon时,确保bootstrap节点包含在部署mon主机列表中。
在节点上部署mon监视器的前提是节点已经加入集群!!
部署mon有多种方法:
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 23m) mgr: ceph01.ywwete(active, since 24m), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 22m), 10 in (since 2d) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 453 KiB usage: 452 MiB used, 1000 GiB / 1000 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph orch ps |
|
mon.ceph01 ceph01 running (28m) 84s ago 2d 67.8M 2048M 18.2.0 2ddfbd2845f4 3dd41e1b45cd mon.ceph02 ceph02 running (24m) 7m ago 2d 47.7M 2048M 18.2.0 2ddfbd2845f4 fdfa8a81a35e mon.ceph03 ceph03 running (26m) 84s ago 2d 55.8M 2048M 18.2.0 2ddfbd2845f4 c4794d6002c8 |
节点未加入集群时,就部署mon会报如下错误(一点要先将节点加入集群)
|
[root@ceph01 ~]# ceph orch apply mon --placement="ceph06" |
|
Error EINVAL: Cannot place on ceph06: Unknown hosts |
3.3.1部署Mon监视器
3.3.1.1使用--placement部署mon
ceph orch apply mon --placement=“ceph01 ceph02 ceph03”
注意:务必将bootstrap节点包含为命令中的第一个节点。另外在缩减节点时,要逐个缩减,不能一次减多个,可能会导致集群出现“1 stray daemon(s) not managed by cephadm” 警告
|
[root@ceph01 ~]# ceph orch apply mon --placement="ceph01 ceph02 ceph03 ceph04" |
|
Scheduled mon update... |
|
[root@ceph01 ~]# ceph orch ps |
|
mon.ceph01 ceph01 running (49m) 65s ago 2d 78.8M 2048M 18.2.0 2ddfbd2845f4 3dd41e1b45cd mon.ceph02 ceph02 running (45m) 7m ago 2d 59.8M 2048M 18.2.0 2ddfbd2845f4 fdfa8a81a35e mon.ceph03 ceph03 running (47m) 66s ago 2d 67.5M 2048M 18.2.0 2ddfbd2845f4 c4794d6002c8 mon.ceph04 ceph04 running (42s) 35s ago 42s 56.9M 2048M 18.2.0 2ddfbd2845f4 f0867dac41d8 |
3.3.1.2使用标签部署mon
使用放置规格,通过标签在特定主机上部署特定数量的mon监视器
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 ceph05 10.9.254.85 5 hosts in cluster |
|
[root@ceph01 ~]# ceph orch host label add ceph05 mon |
|
Added label mon to host ceph05 |
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 ceph05 10.9.254.85 mon 5 hosts in cluster |
|
[root@ceph01 ~]# ceph orch apply mon --placement="label:mon" |
|
Scheduled mon update... |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 4 daemons, quorum ceph01,ceph03,ceph02,ceph05 (age 7s) mgr: ceph01.ywwete(active, since 106m), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 104m), 10 in (since 2d) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 453 KiB usage: 452 MiB used, 1000 GiB / 1000 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph orch ps |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID alertmanager.ceph01 ceph01 *:9093,9094 running (109m) 8m ago 2d 22.9M - 0.25.0 c8568f914cd2 d6def5466e35 ceph-exporter.ceph01 ceph01 running (109m) 8m ago 2d 12.5M - 18.2.0 2ddfbd2845f4 42297be35c30 ceph-exporter.ceph02 ceph02 running (106m) 3m ago 2d 12.7M - 18.2.0 2ddfbd2845f4 996d86fbe05f ceph-exporter.ceph03 ceph03 running (108m) 8m ago 2d 12.7M - 18.2.0 2ddfbd2845f4 1161869cabf1 ceph-exporter.ceph04 ceph04 running (107m) 63s ago 2d 10.9M - 18.2.0 2ddfbd2845f4 85ed10340364 ceph-exporter.ceph05 ceph05 running (105m) 63s ago 25h 10.0M - 18.2.0 2ddfbd2845f4 af63cbe7b2a8 crash.ceph01 ceph01 running (109m) 8m ago 2d 7088k - 18.2.0 2ddfbd2845f4 6ac8c32340c3 crash.ceph02 ceph02 running (106m) 3m ago 2d 7079k - 18.2.0 2ddfbd2845f4 13eb6680e859 crash.ceph03 ceph03 running (108m) 8m ago 2d 7079k - 18.2.0 2ddfbd2845f4 5f92dd5a67e3 crash.ceph04 ceph04 running (107m) 63s ago 2d 7079k - 18.2.0 2ddfbd2845f4 6d2cc984be97 crash.ceph05 ceph05 running (105m) 63s ago 25h 7067k - 18.2.0 2ddfbd2845f4 532357b5cb1a grafana.ceph01 ceph01 *:3000 running (108m) 8m ago 2d 90.2M - 9.4.7 2c41d148cca3 be44c31a7eea mds.cephfs.ceph01.aibnpt ceph01 running (109m) 8m ago 2d 26.0M - 18.2.0 2ddfbd2845f4 cc709ea4e7fb mds.cephfs.ceph02.kzinfm ceph02 running (105m) 3m ago 2d 23.8M - 18.2.0 2ddfbd2845f4 9d25df212020 mds.cephfs.ceph03.pdkglx ceph03 running (107m) 8m ago 2d 27.3M - 18.2.0 2ddfbd2845f4 28aea4a2cc90 mgr.ceph01.ywwete ceph01 *:9283,8765,8443 running (110m) 8m ago 2d 494M - 18.2.0 2ddfbd2845f4 3bdecf9d09b4 mgr.ceph04.ykcgel ceph04 *:8443,9283,8765 running (105m) 63s ago 2d 433M - 18.2.0 2ddfbd2845f4 1d41e39b15cd mon.ceph01 ceph01 running (110m) 8m ago 2d 108M 2048M 18.2.0 2ddfbd2845f4 3dd41e1b45cd mon.ceph02 ceph02 running (106m) 3m ago 2d 95.2M 2048M 18.2.0 2ddfbd2845f4 fdfa8a81a35e mon.ceph03 ceph03 running (108m) 8m ago 2d 116M 2048M 18.2.0 2ddfbd2845f4 c4794d6002c8 mon.ceph05 ceph05 running (75s) 63s ago 75s 59.8M 2048M 18.2.0 2ddfbd2845f4 6761915801cf node-exporter.ceph01 ceph01 *:9100 running (109m) 8m ago 2d 17.6M - 1.5.0 0da6a335fe13 3044ee507f0c node-exporter.ceph02 ceph02 *:9100 running (105m) 3m ago 2d 17.2M - 1.5.0 0da6a335fe13 ccc08e011a2e node-exporter.ceph03 ceph03 *:9100 running (108m) 8m ago 2d 16.9M - 1.5.0 0da6a335fe13 3a1b9ded2c42 node-exporter.ceph04 ceph04 *:9100 running (107m) 63s ago 2d 18.2M - 1.5.0 0da6a335fe13 8f882872cb4d node-exporter.ceph05 ceph05 *:9100 running (105m) 63s ago 25h 15.6M - 1.5.0 0da6a335fe13 975e4cbae7ee osd.0 ceph01 running (116m) 8m ago 2d 48.1M 4096M 18.2.0 2ddfbd2845f4 c9966c2574a2 osd.1 ceph01 running (116m) 8m ago 2d 47.4M 4096M 18.2.0 2ddfbd2845f4 33d436945427 osd.2 ceph02 running (105m) 3m ago 2d 46.7M 4096M 18.2.0 2ddfbd2845f4 3d8a043a78f7 osd.3 ceph02 running (105m) 3m ago 2d 49.1M 4096M 18.2.0 2ddfbd2845f4 b5a1f0b592c5 osd.4 ceph03 running (2h) 8m ago 2d 87.0M 4096M 18.2.0 2ddfbd2845f4 86e18a71d474 osd.5 ceph03 running (2h) 8m ago 2d 51.9M 4096M 18.2.0 2ddfbd2845f4 1067433a4d95 osd.6 ceph04 running (2h) 63s ago 2d 53.8M 4096M 18.2.0 2ddfbd2845f4 4b9a742c18a4 osd.7 ceph04 running (2h) 63s ago 2d 54.8M 4096M 18.2.0 2ddfbd2845f4 648f51494b6b osd.8 ceph05 running (2h) 63s ago 25h 60.9M 1184M 18.2.0 2ddfbd2845f4 62ebd91aa00c osd.9 ceph05 running (2h) 63s ago 25h 60.6M 1184M 18.2.0 2ddfbd2845f4 fb6fe02a9e68 prometheus.ceph01 ceph01 *:9095 running (106m) 8m ago 2d 133M - 2.43.0 a07b618ecd1d 67586c6cd93e |
3.3.1.3部署特定数量的监视器
|
[root@ceph01 ~]# ceph orch apply mon --placement="3 ceph01 ceph02 ceph03" |
|
Scheduled mon update... |
|
[root@ceph01 ~]# ceph orch ps |
|
mon.ceph01 ceph01 running (114m) 79s ago 3d 139M 2048M 18.2.0 2ddfbd2845f4 3dd41e1b45cd mon.ceph02 ceph02 running (109m) 7m ago 2d 95.2M 2048M 18.2.0 2ddfbd2845f4 fdfa8a81a35e mon.ceph03 ceph03 running (111m) 80s ago 2d 123M 2048M 18.2.0 2ddfbd2845f4 c4794d6002c8 |
3.3.1.4随机部署监控器
|
[root@ceph01 ~]# ceph orch apply mon 3 |
3.3.1.5使用配置文件部署mon监控器
|
[root@ceph01 ~]# vim mon.yaml |
|
service_type: mon placement: host: - ceph01 - ceph02 - ceph03 |
|
[root@ceph01 ~]# ceph orch apply -i mon.yaml |
3.3.2列出节点上的mon
|
[root@ceph01 ~]# ceph orch ps --daemon_type=mon |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID mon.ceph01 ceph01 running (2h) 10m ago 3d 144M 2048M 18.2.0 2ddfbd2845f4 3dd41e1b45cd mon.ceph02 ceph02 running (2h) 4m ago 2d 109M 2048M 18.2.0 2ddfbd2845f4 fdfa8a81a35e mon.ceph03 ceph03 running (2h) 10m ago 2d 130M 2048M 18.2.0 2ddfbd2845f4 c4794d6002c8 |
注意镜像ID,如果镜像ID不同,则表明存在多个ceph版本
3.3.3移除mon
#移除ceph02上的mon
|
[root@ceph01 ~]# ceph orch apply mon --placement="2 ceph01 ceph03" |
|
Scheduled mon update... |
|
[root@ceph01 ~]# ceph orch ls |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 3m ago 3d count:1 ceph-exporter 5/5 6m ago 3d * crash 5/5 6m ago 3d * grafana ?:3000 1/1 3m ago 2d ceph01 mds.cephfs 3/3 3m ago 2d ceph01;ceph02;ceph03;count:3 mgr 2/2 6m ago 3d count:2 mon 2/2 3m ago 21s ceph01;ceph03;count:2 node-exporter ?:9100 5/5 6m ago 3d * osd 10 6m ago - prometheus ?:9095 1/1 3m ago 3d count:1 |
|
[root@ceph01 ~]# ceph orch ps --daemon_type=mon |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID mon.ceph01 ceph01 running (2h) 4m ago 3d 149M 2048M 18.2.0 2ddfbd2845f4 3dd41e1b45cd mon.ceph03 ceph03 running (2h) 4m ago 2d 136M 2048M 18.2.0 2ddfbd2845f4 c4794d6002c8 |
如果mon节点一直无法删除,则可尝试强制删除,生产环境谨慎操作!!!
|
[root@ceph01 ~]# ceph orch daemon rm mon.ceph02 |
3.3.4添加mon
#在ceph02上添加mon
|
[root@ceph01 ~]# ceph orch apply mon --placement="3 ceph01 ceph02 ceph03" |
|
Scheduled mon update... |
|
[root@ceph01 ~]# ceph orch ls |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 8m ago 3d count:1 ceph-exporter 5/5 8m ago 3d * crash 5/5 8m ago 3d * grafana ?:3000 1/1 8m ago 2d ceph01 mds.cephfs 3/3 8m ago 2d ceph01;ceph02;ceph03;count:3 mgr 2/2 8m ago 3d count:2 mon 3/3 8m ago 21s ceph01;ceph02;ceph03;count:3 node-exporter ?:9100 5/5 8m ago 3d * osd 10 8m ago - prometheus ?:9095 1/1 8m ago 3d count:1 |
|
[root@ceph01 ~]# ceph orch ps --daemon_type=mon |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID mon.ceph01 ceph01 running (2h) 27s ago 3d 179M 2048M 18.2.0 2ddfbd2845f4 3dd41e1b45cd mon.ceph02 ceph02 running (2m) 2m ago 2m 42.4M 2048M 18.2.0 2ddfbd2845f4 658be10add60 mon.ceph03 ceph03 running (2h) 28s ago 2d 143M 2048M 18.2.0 2ddfbd2845f4 c4794d6002c8 |
注意事项:不要单独添加mon,例如:执行第命令1在ceph01上创建mon
##命令1
ceph orch apply mon ceph01
然后,执行添加命令2,在ceph02上创建mon
##命令2
ceph orch apply mon ceph02
此时ceph02上的mon监视器会取代ceph01上的mon监视器,并只在ceph02上创mon建监控器。然后,执行命令3,在ceph03上创建mon监视器。
##命令3
ceph orch apply mon ceph03
此时ceph03会取代ceph02上的mon监控器,并在ceph03上创建监控器。最后,只有ceph03上有一个mon监控器。
3.3.5关闭自动管理
如果整个ceph集群位于同一子网中,则cephadm会在向集群添加新主机时,自动添加最多5个mon监视器守护进程,即cephadm会自动配置新主机上的mon守护进程,直到有5个mon监视器。可以通过禁用自动监视器部署,来禁止cephadm自动部署mon监视器。
|
[root@ceph01 ~]# ceph orch apply mon --unmanaged |
|
Scheduled mon update... |
3.4管理Mgr管理器
ceph manager,mgr维护放置组(pg)的详细信息;维护pg元数据包括:PG的状态、容量、健康状态和复制因子;维护主机元数据包括:主机状态、监控状态、负载等。同时还提供RESTfu API和命令行工具;插件扩展等能力
3.4.1查看模块
|
[root@ceph01 ~]# ceph mgr module ls |
|
MODULE balancer on (always on) crash on (always on) devicehealth on (always on) orchestrator on (always on) pg_autoscaler on (always on) progress on (always on) rbd_support on (always on) status on (always on) telemetry on (always on) volumes on (always on) cephadm on dashboard on iostat on nfs on prometheus on restful on alerts - diskprediction_local - influx - insights - k8sevents - localpool - mds_autoscaler - mirroring - osd_perf_query - osd_support - rgw - rook - selftest - snap_schedule - stats - telegraf - test_orchestrator - zabbix - |
3.4.2启用模块
|
[root@ceph01 ~]# ceph mgr module enable alerts |
#启用osd_perf_query后,ceph osd perf命令可以更加高效的获取osd的性能指标,并且可以在osd性能下降时更快地识别问题,提高调试和故障排除效率。
|
[root@ceph01 ~]# ceph mgr module enable alerts [root@ceph01 ~]# ceph mgr module enable osd_perf_query [root@ceph01 ~]# ceph mgr module enable selftest [root@ceph01 ~]# ceph mgr module ls |
|
MODULE balancer on (always on) crash on (always on) devicehealth on (always on) orchestrator on (always on) pg_autoscaler on (always on) progress on (always on) rbd_support on (always on) status on (always on) telemetry on (always on) volumes on (always on) alerts on cephadm on dashboard on iostat on nfs on osd_perf_query on prometheus on restful on selftest on diskprediction_local - influx - insights - k8sevents - localpool - mds_autoscaler - mirroring - osd_support - rgw - rook - snap_schedule - stats - telegraf - test_orchestrator - zabbix - |
关闭模块
|
[root@ceph01 ~]# ceph mgr module disable alerts [root@ceph01 ~]# ceph mgr module disable alerts [root@ceph01 ~]# ceph mgr module disable osd_perf_query [root@ceph01 ~]# ceph mgr module disable selftest |
3.4.3重启mgr进程
|
[root@ceph01 ~]# ceph orch restart mgr |
|
Scheduled to restart mgr.ceph01.ywwete on host 'ceph01' Scheduled to restart mgr.ceph04.ykcgel on host 'ceph04' |
3.4.4查看mgr状态
|
[root@ceph01 ~]# ceph mgr stat |
|
{ "epoch": 87, "available": true, "active_name": "ceph01.ywwete", "num_standby": 1 } |
3.4.5查看mgr版本
|
[root@ceph01 ~]# ceph mgr versions |
|
{ "ceph version 18.2.0 (5dd24139a1eada541a3bc16b6941c5dde975e26d) reef (stable)": 2 } |
3.4.6增加或减少一个mgr节点
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 75m) mgr: ceph01.ywwete(active, since 37m), standbys: ceph04.ykcgel mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 3h), 10 in (since 2d) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 458 KiB usage: 454 MiB used, 1000 GiB / 1000 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph orch apply mgr --placement="3 ceph01 ceph02 ceph03" |
|
Scheduled mgr update... |
|
[root@ceph01 ~]# ceph orch ls |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 20s ago 3d count:1 ceph-exporter 5/5 8m ago 3d * crash 5/5 8m ago 3d * grafana ?:3000 1/1 20s ago 2d ceph01 mds.cephfs 3/3 30s ago 2d ceph01;ceph02;ceph03;count:3 mgr 3/3 30s ago 47s ceph01;ceph02;ceph03;count:3 mon 3/3 30s ago 78m ceph01;ceph02;ceph03;count:3 node-exporter ?:9100 5/5 8m ago 3d * osd 10 8m ago - prometheus ?:9095 1/1 20s ago 3d count:1 |
|
[root@ceph01 ~]# ceph orch ps --daemon_type=mgr |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID mgr.ceph01.ywwete ceph01 *:9283,8765,8443 running (41m) 72s ago 3d 489M - 18.2.0 2ddfbd2845f4 967d527c56fb mgr.ceph02.sqifom ceph02 *:8443,9283,8765 running (95s) 82s ago 95s 221M - 18.2.0 2ddfbd2845f4 6c80c7a555f7 mgr.ceph03.ldkltw ceph03 *:8443,9283,8765 running (97s) 82s ago 97s 232M - 18.2.0 2ddfbd2845f4 a62cb3956fbf |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 79m) mgr: ceph01.ywwete(active, since 42m), standbys: ceph03.ldkltw, ceph02.sqifom mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 3h), 10 in (since 2d) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 458 KiB usage: 454 MiB used, 1000 GiB / 1000 GiB avail pgs: 193 active+clean |
#减少ceph02一个mgr节点
|
[root@ceph01 ~]# ceph orch apply mgr --placement="2 ceph01 ceph03" |
|
Scheduled mgr update... |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 84m) mgr: ceph01.ywwete(active, since 46m), standbys: ceph03.ldkltw mds: 1/1 daemons up, 2 standby osd: 10 osds: 10 up (since 3h), 10 in (since 3d) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 458 KiB usage: 454 MiB used, 1000 GiB / 1000 GiB avail pgs: 193 active+clean |
3.4.7删除一个mgr进程(会自动新建)
|
[root@ceph01 ~]# ceph orch ps --daemon_type=mgr |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID mgr.ceph01.ywwete ceph01 *:9283,8765,8443 running (55m) 10m ago 3d 491M - 18.2.0 2ddfbd2845f4 967d527c56fb mgr.ceph03.ldkltw ceph03 *:8443,9283,8765 running (15m) 5m ago 15m 449M - 18.2.0 2ddfbd2845f4 a62cb3956fbf |
|
[root@ceph01 ~]# ceph orch daemon rm mgr.ceph03.ldkltw |
|
Removed mgr.ceph03.ldkltw from host 'ceph03' |
|
[root@ceph01 ~]# ceph orch ps --daemon_type=mgr |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID mgr.ceph01.ywwete ceph01 *:9283,8765,8443 running (56m) 65s ago 3d 491M - 18.2.0 2ddfbd2845f4 967d527c56fb mgr.ceph03.alzljc ceph03 *:8443,9283,8765 running (9s) 3s ago 9s 97.0M - 18.2.0 2ddfbd2845f4 65ba285e8d6c |
3.5管理OSD
OSD通常由一个磁盘驱动器和一个ceph-osd守护进程外加节点中的相关日志组成。如果节点有多个存储驱动器,则为每个驱动器映射一个ceph-osd守护进程。OSD用于存储客户端数据,此外,OSD利用节点的CPU、内存和网络资源来执行心跳、数据复制、纠删码、数据恢复、监控和报告功能。
在配置ceph节点硬件时,有限考虑统一节点硬件,以实现一致的性能配置。
在有少量SSD及大量HDD驱动器环境,block.db和block.wal都要放在SSD上。对于块、对象、文件混合的存储环境,block.db分区大小是bluestore的4%(4T盘,block.db为4T4%=160GB),如果仅是块存储或单一的存储,block.db的分区大小是bluestore的1%(4T盘,block.db为4T1%=40GB);对于block.wal大小要求,只要大于10GB即可。
调优OSD内存,OSD守护进程根据osd_memory_target参数调整内存消耗。如果ceph部署在专用节点上,即不与其他服务共享内存的专用节点上,cephadm会自动根据内存总量和部署的OSD数量自动调整每个OSD的内存消耗。osd_memory_target_autotune参数设置为true。如果ceph与其他服务共享节点部署(如HCI超融合部署架构),则建议将osd_memory_target_autotune设置为false,并手动指定osd_memory_target,确保内存不会争用。
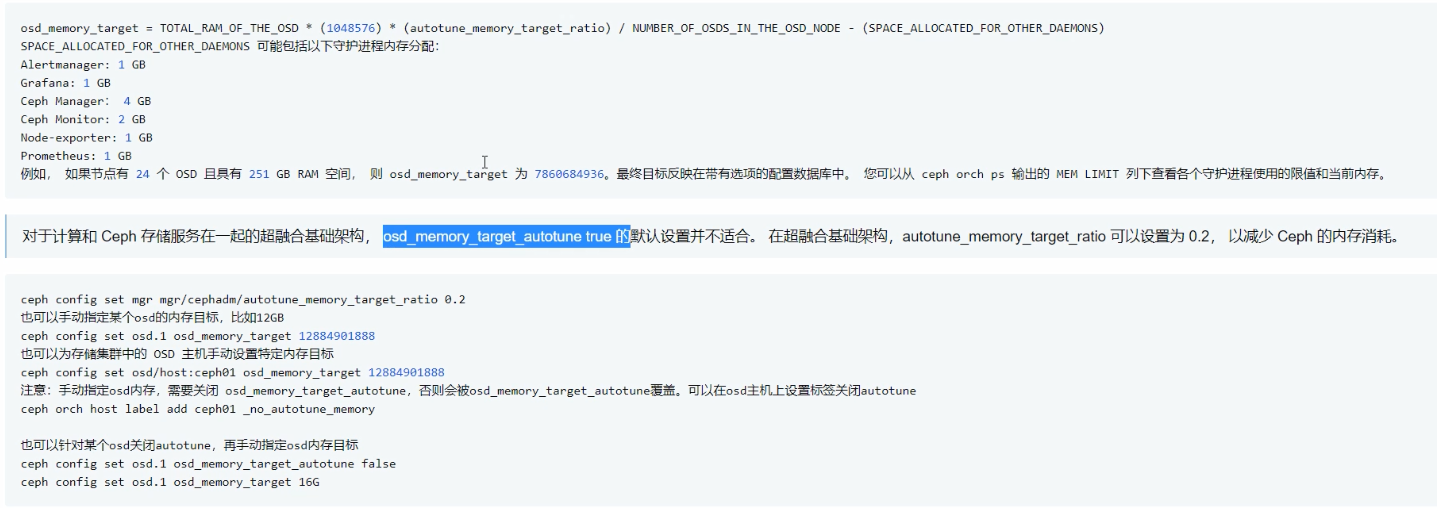
3.5.1列出osd设备
在使用ceph orch部署osd之前,先检查可用设备列表,要达到可用设备的前置条件:
设备不能有分区
设备不能有任何LVM状态
设备没有被挂载
设备没有任何文件系统
该设备不得包含ceph bluestore osd
该设备必须大于5GB
ceph不会将不可用的设备编排为osd
|
[root@ceph01 ~]# ceph orch device ls --wide --refresh |
|
HOST PATH TYPE TRANSPORT RPM DEVICE ID SIZE HEALTH IDENT FAULT AVAILABLE REFRESHED REJECT REASONS ceph01 /dev/sdb hdd 100G N/A N/A No 2m ago Insufficient space ( ceph01 /dev/sdc hdd 100G N/A N/A No 2m ago Insufficient space ( ceph02 /dev/sdb hdd 100G N/A N/A No 26m ago Insufficient space ( ceph02 /dev/sdc hdd 100G N/A N/A No 26m ago Insufficient space ( ceph03 /dev/sdb hdd 100G N/A N/A No 2m ago Insufficient space ( ceph03 /dev/sdc hdd 100G N/A N/A No 2m ago Insufficient space ( ceph04 /dev/sdb hdd 100G N/A N/A No 4m ago Insufficient space ( ceph04 /dev/sdc hdd 100G N/A N/A No 4m ago Insufficient space ( ceph05 /dev/sdb hdd 100G N/A N/A No 4m ago Insufficient space ( ceph05 /dev/sdc hdd 100G N/A N/A No 4m ago Insufficient space ( #AVAILABLE 全部为No,表示不可用 |
使用--wide选项提供与该设备相关的所有详细信息,包括设备可能有资格用作osd的原因。
无可用磁盘,我们把ceph05节点删除。
|
[root@ceph01 ~]# ceph orch host drain ceph05 |
|
Scheduled to remove the following daemons from host 'ceph05' type id -------------------- --------------- ceph-exporter ceph05 crash ceph05 node-exporter ceph05 osd 8 osd 9 |
|
[root@ceph01 ~]# ceph orch osd rm status |
|
OSD HOST STATE PGS REPLACE FORCE ZAP DRAIN STARTED AT 8 ceph05 draining 0 False False False 2023-10-13 09:28:31.242790 9 ceph05 draining 0 False False False 2023-10-13 09:28:32.373399 |
|
[root@ceph01 ~]# ceph orch osd rm status |
|
No OSD remove/replace operations reported |
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 ceph05 10.9.254.85 mon,_no_schedule 5 hosts in cluster |
|
[root@ceph01 ~]# ceph orch host rm ceph05 |
|
Removed host 'ceph05' |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 29h) mgr: ceph01.ywwete(active, since 28h), standbys: ceph03.alzljc mds: 1/1 daemons up, 2 standby osd: 8 osds: 8 up (since 4h), 8 in (since 4d) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 458 KiB usage: 395 MiB used, 800 GiB / 800 GiB avail pgs: 193 active+clean |
|
[root@ceph05 ~]# lsblk |
|
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 150G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 149G 0 part ├─rl-root 253:0 0 111G 0 lvm / ├─rl-swap 253:1 0 8G 0 lvm [SWAP] └─rl-home 253:4 0 30G 0 lvm /home sdb 8:16 0 100G 0 disk └─ceph--106764df--7a92--4de7--9e83--2ac8c70d010c-osd--block--0975afef--4817--4faa--9970--c75e5e7acb5b 253:3 0 100G 0 lvm sdc 8:32 0 100G 0 disk └─ceph--fc196c36--e4aa--4506--a9ae--aecb06d17d7b-osd--block--cce33e0e--a546--4f95--8061--299ede60aaf8 253:2 0 100G 0 lvm sr0 11:0 1 1024M 0 rom |
|
[root@ceph05 ~]# cephadm rm-cluster --fsid 4b4cc258-6679-11ee-ad4a-005056982bba --force --zap-osds |
|
Using ceph image with id '2ddfbd2845f4' and tag 'v18' created on 2023-09-27 00:11:26 +0800 CST quay.io/ceph/ceph@sha256:f239715e1c7756e32a202a572e2763a4ce15248e09fc6e8990985f8a09ffa784 Zapping /dev/sdb... Zapping /dev/sdc... |
|
[root@ceph05 ~]# lsblk |
|
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 150G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 149G 0 part ├─rl-root 253:0 0 111G 0 lvm / ├─rl-swap 253:1 0 8G 0 lvm [SWAP] └─rl-home 253:4 0 30G 0 lvm /home sdb 8:16 0 100G 0 disk sdc 8:32 0 100G 0 disk sr0 11:0 1 1024M 0 rom |
|
[root@ceph01 ~]# ceph orch apply osd --all-available-devices --unmanaged #osd设备不自动添加 |
|
Scheduled osd.all-available-devices update... |
将ceph05节点添加集群,查看osd是否自动添加
|
[root@ceph01 ~]# ceph orch host add ceph05 |
|
Added host 'ceph05' with addr '10.9.254.85' |
|
[root@ceph01 ~]# ceph orch host ls |
|
HOST ADDR LABELS STATUS ceph01 10.9.254.81 _admin,mon ceph02 10.9.254.82 mon,mgr,_admin ceph03 10.9.254.83 mon,_admin,mgr ceph04 10.9.254.84 ceph05 10.9.254.85 5 hosts in cluster |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 29h) mgr: ceph01.ywwete(active, since 29h), standbys: ceph03.alzljc mds: 1/1 daemons up, 2 standby osd: 8 osds: 8 up (since 4h), 8 in (since 4d) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 458 KiB usage: 395 MiB used, 800 GiB / 800 GiB avail pgs: 193 active+clean |
|
[root@ceph01 ~]# ceph orch device ls |
|
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS ceph01 /dev/sdb hdd 100G No 66s ago Insufficient space ( ceph01 /dev/sdc hdd 100G No 66s ago Insufficient space ( ceph02 /dev/sdb hdd 100G No 73s ago Insufficient space ( ceph02 /dev/sdc hdd 100G No 73s ago Insufficient space ( ceph03 /dev/sdb hdd 100G No 74s ago Insufficient space ( ceph03 /dev/sdc hdd 100G No 74s ago Insufficient space ( ceph04 /dev/sdb hdd 100G No 72s ago Insufficient space ( ceph04 /dev/sdc hdd 100G No 72s ago Insufficient space ( ceph05 /dev/sdb hdd 100G Yes 98s ago ceph05 /dev/sdc hdd 100G Yes 98s ago #osd为可用状态 |
3.5.2添加osd
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.78149 root default -3 0.19537 host ceph01 1 hdd 0.09769 osd.1 up 1.00000 1.00000 0 ssd 0.09769 osd.0 up 1.00000 1.00000 -5 0.19537 host ceph02 3 hdd 0.09769 osd.3 up 1.00000 1.00000 2 ssd 0.09769 osd.2 up 1.00000 1.00000 -7 0.19537 host ceph03 5 hdd 0.09769 osd.5 up 1.00000 1.00000 4 ssd 0.09769 osd.4 up 1.00000 1.00000 -9 0.19537 host ceph04 7 hdd 0.09769 osd.7 up 1.00000 1.00000 6 ssd 0.09769 osd.6 up 1.00000 1.00000 -11 0 host ceph05 |
1#将主机上所有可用设备编排成osd
|
[root@ceph01 ~]# ceph orch apply osd --all-available-devices |
|
Scheduled osd.all-available-devices update... |
#或者禁止cephadm自动部署osd
|
[root@ceph01 ~]# ceph orch apply osd --all-available-devices --unmanaged |
|
Scheduled osd.all-available-devices update... |
2#指定主机的驱动器创建osd,即逐个添加osd
|
[root@ceph01 ~]# ceph orch daemon add osd ceph05:/dev/sdb |
|
Created osd(s) 8 on host 'ceph05' |
说明:添加osd时,建议将磁盘格式化为无分区的原始磁盘
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.87918 root default -3 0.19537 host ceph01 1 hdd 0.09769 osd.1 up 1.00000 1.00000 0 ssd 0.09769 osd.0 up 1.00000 1.00000 -5 0.19537 host ceph02 3 hdd 0.09769 osd.3 up 1.00000 1.00000 2 ssd 0.09769 osd.2 up 1.00000 1.00000 -7 0.19537 host ceph03 5 hdd 0.09769 osd.5 up 1.00000 1.00000 4 ssd 0.09769 osd.4 up 1.00000 1.00000 -9 0.19537 host ceph04 7 hdd 0.09769 osd.7 up 1.00000 1.00000 6 ssd 0.09769 osd.6 up 1.00000 1.00000 -11 0.09769 host ceph05 8 hdd 0.09769 osd.8 up 1.00000 1.00000 |
添加另一块磁盘
|
[root@ceph01 ~]# ceph orch daemon add osd ceph05:/dev/sdc |
|
Created osd(s) 9 on host 'ceph05' |
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.97687 root default -3 0.19537 host ceph01 1 hdd 0.09769 osd.1 up 1.00000 1.00000 0 ssd 0.09769 osd.0 up 1.00000 1.00000 -5 0.19537 host ceph02 3 hdd 0.09769 osd.3 up 1.00000 1.00000 2 ssd 0.09769 osd.2 up 1.00000 1.00000 -7 0.19537 host ceph03 5 hdd 0.09769 osd.5 up 1.00000 1.00000 4 ssd 0.09769 osd.4 up 1.00000 1.00000 -9 0.19537 host ceph04 7 hdd 0.09769 osd.7 up 1.00000 1.00000 6 ssd 0.09769 osd.6 up 1.00000 1.00000 -11 0.19537 host ceph05 8 hdd 0.09769 osd.8 up 1.00000 1.00000 9 hdd 0.09769 osd.9 up 1.00000 1.00000 |
3.5.3停止某个osd
|
[root@ceph01 ~]# ceph orch ps --daemon_type=osd |
|
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID osd.0 ceph01 running (32h) 10m ago 4d 56.7M 4096M 18.2.0 2ddfbd2845f4 c9966c2574a2 osd.1 ceph01 running (32h) 10m ago 4d 56.6M 4096M 18.2.0 2ddfbd2845f4 33d436945427 osd.2 ceph02 running (32h) 2m ago 4d 54.5M 4096M 18.2.0 2ddfbd2845f4 3d8a043a78f7 osd.3 ceph02 running (32h) 2m ago 4d 59.7M 4096M 18.2.0 2ddfbd2845f4 b5a1f0b592c5 osd.4 ceph03 running (33h) 2m ago 4d 93.9M 4096M 18.2.0 2ddfbd2845f4 86e18a71d474 osd.5 ceph03 running (33h) 2m ago 4d 61.6M 4096M 18.2.0 2ddfbd2845f4 1067433a4d95 osd.6 ceph04 running (33h) 6m ago 4d 61.7M 1696M 18.2.0 2ddfbd2845f4 4b9a742c18a4 osd.7 ceph04 running (33h) 6m ago 4d 63.7M 1696M 18.2.0 2ddfbd2845f4 648f51494b6b osd.8 ceph05 running (7m) 3m ago 7m 57.8M 1696M 18.2.0 2ddfbd2845f4 58531a40cde7 osd.9 ceph05 running (3m) 3m ago 3m 13.2M 1696M 18.2.0 2ddfbd2845f4 714bedcf18a0 |
|
[root@ceph01 ~]# ceph orch daemon stop osd.9 |
|
Scheduled to stop osd.9 on host 'ceph05' |
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.97687 root default -3 0.19537 host ceph01 1 hdd 0.09769 osd.1 up 1.00000 1.00000 0 ssd 0.09769 osd.0 up 1.00000 1.00000 -5 0.19537 host ceph02 3 hdd 0.09769 osd.3 up 1.00000 1.00000 2 ssd 0.09769 osd.2 up 1.00000 1.00000 -7 0.19537 host ceph03 5 hdd 0.09769 osd.5 up 1.00000 1.00000 4 ssd 0.09769 osd.4 up 1.00000 1.00000 -9 0.19537 host ceph04 7 hdd 0.09769 osd.7 up 1.00000 1.00000 6 ssd 0.09769 osd.6 up 1.00000 1.00000 -11 0.19537 host ceph05 9 hdd 0.09769 osd.9 down 1.00000 1.00000 8 ssd 0.09769 osd.8 up 1.00000 1.00000 |
3.5.4启动某个osd
|
[root@ceph01 ~]# ceph orch daemon start osd.9 |
|
Scheduled to start osd.9 on host 'ceph05' |
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.97687 root default -3 0.19537 host ceph01 1 hdd 0.09769 osd.1 up 1.00000 1.00000 0 ssd 0.09769 osd.0 up 1.00000 1.00000 -5 0.19537 host ceph02 3 hdd 0.09769 osd.3 up 1.00000 1.00000 2 ssd 0.09769 osd.2 up 1.00000 1.00000 -7 0.19537 host ceph03 5 hdd 0.09769 osd.5 up 1.00000 1.00000 4 ssd 0.09769 osd.4 up 1.00000 1.00000 -9 0.19537 host ceph04 7 hdd 0.09769 osd.7 up 1.00000 1.00000 6 ssd 0.09769 osd.6 up 1.00000 1.00000 -11 0.19537 host ceph05 9 hdd 0.09769 osd.9 up 1.00000 1.00000 8 ssd 0.09769 osd.8 up 1.00000 1.00000 |
3.5.5批量重启osd
|
[root@ceph01 ~]# ceph orch ps | grep osd | awk '{print "ceph orch daemon restart " $1}' | bash |
|
Scheduled to restart osd.0 on host 'ceph01' Scheduled to restart osd.1 on host 'ceph01' Scheduled to restart osd.2 on host 'ceph02' Scheduled to restart osd.3 on host 'ceph02' Scheduled to restart osd.4 on host 'ceph03' Scheduled to restart osd.5 on host 'ceph03' Scheduled to restart osd.6 on host 'ceph04' Scheduled to restart osd.7 on host 'ceph04' Scheduled to restart osd.8 on host 'ceph05' Scheduled to restart osd.9 on host 'ceph05' |
3.5.6移除osd(测试环境操作,直接rm)
1#按osd id 移除osd
当osd上没有剩余的PG时,它会被停用并从集群中移除。
移除OSD节点(生产环境操作)生产环境,移除OSD节点之前,请确保集群可以回填所有OSD的内容,而不会达到全满比率。达到全满比率会导致集群拒绝写操作。移除OSD节点步骤如下:
|
[root@ceph01 ~]# ceph orch osd rm 9 |
|
Scheduled OSD(s) for removal. VG/LV for the OSDs won't be zapped (--zap wasn't passed). Run the `ceph-volume lvm zap` command with `--destroy` against the VG/LV if you want them to be destroyed. |
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.87918 root default -3 0.19537 host ceph01 1 hdd 0.09769 osd.1 up 1.00000 1.00000 0 ssd 0.09769 osd.0 up 1.00000 1.00000 -5 0.19537 host ceph02 3 hdd 0.09769 osd.3 up 1.00000 1.00000 2 ssd 0.09769 osd.2 up 1.00000 1.00000 -7 0.19537 host ceph03 5 hdd 0.09769 osd.5 up 1.00000 1.00000 4 ssd 0.09769 osd.4 up 1.00000 1.00000 -9 0.19537 host ceph04 7 hdd 0.09769 osd.7 up 1.00000 1.00000 6 ssd 0.09769 osd.6 up 1.00000 1.00000 -11 0.09769 host ceph05 8 ssd 0.09769 osd.8 up 1.00000 1.00000 |
|
[root@ceph01 ~]# ceph orch device ls |
|
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS ceph01 /dev/sdb hdd 100G No 14m ago Insufficient space ( ceph01 /dev/sdc hdd 100G No 14m ago Insufficient space ( ceph02 /dev/sdb hdd 100G No 14m ago Insufficient space ( ceph02 /dev/sdc hdd 100G No 14m ago Insufficient space ( ceph03 /dev/sdb hdd 100G No 14m ago Insufficient space ( ceph03 /dev/sdc hdd 100G No 14m ago Insufficient space ( ceph04 /dev/sdb hdd 100G No 14m ago Insufficient space ( ceph04 /dev/sdc hdd 100G No 14m ago Insufficient space ( ceph05 /dev/sdb hdd 100G No 27m ago Insufficient space ( ceph05 /dev/sdc hdd 100G No 27m ago Insufficient space ( |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 30h) mgr: ceph01.ywwete(active, since 30h), standbys: ceph03.alzljc mds: 1/1 daemons up, 2 standby osd: 9 osds: 9 up (since 2m), 9 in (since 4d) data: volumes: 1/1 healthy pools: 5 pools, 193 pgs objects: 24 objects, 458 KiB usage: 419 MiB used, 900 GiB / 900 GiB avail pgs: 193 active+clean |
模拟在生产环境中删除osd
#临时禁用清理
清理是确保集群数据的持久性,但这是自愿密集型。在删除OSD节点之前,可以临时禁用清理和深度清理。
#禁用清理和深度清理
|
[root@ceph01 ~]# ceph osd set noscru |
|
noscrub is set |
|
[root@ceph01 ~]# ceph osd set nodeep-scrub |
|
nodeep-scrub is set |
#限制回填和恢复速度
如果不限制集群回填速度,集群将以最快的时间恢复,这样做会对ceph客户端I/O性能造成重大影响。要保持较高的ceph客户端I/O性能,就需要限制回填和恢复操作,并允许集群花费更长的时间来恢复,避免对客户端造成影响;
调整以下参数
osd_max_backfills = 1
osd_recovery_max_active = 1
osd_recovery_op_priority = 1
|
[root@ceph01 ~]# ceph config set osd osd_max_backfills 1 [root@ceph01 ~]# ceph config set osd osd_recovery_max_active 1 [root@ceph01 ~]# ceph config set osd osd_recovery_op_priority 1 |
还可以适当调大osd_recovery_sleep参数,让集群花费更长的时间来恢复
ceph config set osd osd_recovery_sleep_hdd 1.5
ceph config set osd osd_recovery_sleep_ssd 1.5
ceph config set osd osd_recovery_sleep_hybrid 1.5
|
[root@ceph01 ~]# ceph osd df |
|
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS 1 hdd 0.09769 1.00000 100 GiB 48 MiB 7.6 MiB 17 KiB 40 MiB 100 GiB 0.05 1.03 49 up 0 ssd 0.09769 1.00000 100 GiB 48 MiB 7.5 MiB 4 KiB 40 MiB 100 GiB 0.05 1.03 45 up 3 hdd 0.09769 1.00000 100 GiB 48 MiB 7.6 MiB 4 KiB 40 MiB 100 GiB 0.05 1.03 45 up 2 ssd 0.09769 1.00000 100 GiB 48 MiB 7.5 MiB 2 KiB 40 MiB 100 GiB 0.05 1.03 43 up 5 hdd 0.09769 1.00000 100 GiB 48 MiB 8.0 MiB 2 KiB 40 MiB 100 GiB 0.05 1.04 39 up 4 ssd 0.09769 1.00000 100 GiB 48 MiB 7.6 MiB 5 KiB 41 MiB 100 GiB 0.05 1.04 40 up 7 hdd 0.09769 1.00000 100 GiB 49 MiB 8.0 MiB 8 KiB 41 MiB 100 GiB 0.05 1.04 44 up 6 ssd 0.09769 1.00000 100 GiB 48 MiB 7.6 MiB 5 KiB 40 MiB 100 GiB 0.05 1.03 40 up 8 ssd 0.09769 1.00000 100 GiB 34 MiB 7.6 MiB 9 KiB 27 MiB 100 GiB 0.03 0.74 41 up TOTAL 900 GiB 419 MiB 69 MiB 61 KiB 350 MiB 900 GiB 0.05 |
删除节点OSD
从存储集群中移除OSD节点时,建议在节点中一次删除一个OSD,并允许集群恢复到active+clean状态,然后继续移除下一个OSD。
|
[root@ceph01 ~]# ceph orch osd rm 8 |
|
Scheduled OSD(s) for removal. VG/LV for the OSDs won't be zapped (--zap wasn't passed). Run the `ceph-volume lvm zap` command with `--destroy` against the VG/LV if you want them to be destroyed. |
|
[root@ceph01 ~]# ceph orch osd rm status |
|
No OSD remove/replace operations reported |
|
[root@ceph01 ~]# ceph osd tree |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.78149 root default -3 0.19537 host ceph01 1 hdd 0.09769 osd.1 up 1.00000 1.00000 0 ssd 0.09769 osd.0 up 1.00000 1.00000 -5 0.19537 host ceph02 3 hdd 0.09769 osd.3 up 1.00000 1.00000 2 ssd 0.09769 osd.2 up 1.00000 1.00000 -7 0.19537 host ceph03 5 hdd 0.09769 osd.5 up 1.00000 1.00000 4 ssd 0.09769 osd.4 up 1.00000 1.00000 -9 0.19537 host ceph04 7 hdd 0.09769 osd.7 up 1.00000 1.00000 6 ssd 0.09769 osd.6 up 1.00000 1.00000 -11 0 host ceph05 |
每移除一个osd后,要检查集群容量是否达到near-full比率
重复删除节点OSD步骤,直到该节点所有OSD被完全移除
排空节点上所有daemon守护进程(包括osd、mgr等)
|
[root@ceph01 ~]# ceph orch host drain ceph05 |
|
Scheduled to remove the following daemons from host 'ceph05' type id -------------------- --------------- ceph-exporter ceph05 crash ceph05 node-exporter ceph05 |
|
[root@ceph01 ~]# ceph orch osd rm status |
|
No OSD remove/replace operations reported |
#删除节点
|
[root@ceph01 ~]# ceph orch host rm ceph05 |
|
Removed host 'ceph05' |
#取消禁用清理
在删除完OSD节点且集群返回active+clean状态后,就可以取消设置noscrub、nodeep-scrub
|
[root@ceph01 ~]# ceph osd unset noscrub |
|
noscrub is unset |
|
[root@ceph01 ~]# ceph osd unset nodeep-scrub |
|
nodeep-scrub is unset |
如果osd节点一直处在调度删除,可以尝试强制删除(生产环境谨慎操作!!!)
3.5.7检查集群容量
|
[root@ceph01 ~]# ceph df |
|
--- RAW STORAGE --- CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 400 GiB 400 GiB 193 MiB 193 MiB 0.05 ssd 500 GiB 500 GiB 226 MiB 226 MiB 0.04 TOTAL 900 GiB 900 GiB 419 MiB 419 MiB 0.05 --- POOLS --- POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL .mgr 1 1 449 KiB 2 904 KiB 0 427 GiB ssdpool 2 32 0 B 0 0 B 0 237 GiB hddpool 3 32 0 B 0 0 B 0 190 GiB cephfs_data 4 64 0 B 0 0 B 0 427 GiB cephfs_metadata 5 64 40 KiB 22 140 KiB 0 427 GiB |
|
[root@ceph01 ~]# rados df |
|
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR .mgr 904 KiB 2 0 4 0 0 0 928 1.7 MiB 329 2.4 MiB 0 B 0 B cephfs_data 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B cephfs_metadata 140 KiB 22 0 44 0 0 0 142 142 KiB 90 55 KiB 0 B 0 B hddpool 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B ssdpool 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B total_objects 24 total_used 419 MiB total_avail 900 GiB total_space 900 GiB |
|
[root@ceph01 ~]# ceph osd df |
|
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS 1 hdd 0.09769 1.00000 100 GiB 48 MiB 7.6 MiB 17 KiB 40 MiB 100 GiB 0.05 1.03 49 up 0 ssd 0.09769 1.00000 100 GiB 48 MiB 7.5 MiB 4 KiB 40 MiB 100 GiB 0.05 1.03 45 up 3 hdd 0.09769 1.00000 100 GiB 48 MiB 7.6 MiB 4 KiB 40 MiB 100 GiB 0.05 1.03 45 up 2 ssd 0.09769 1.00000 100 GiB 48 MiB 7.5 MiB 2 KiB 40 MiB 100 GiB 0.05 1.03 43 up 5 hdd 0.09769 1.00000 100 GiB 48 MiB 8.0 MiB 2 KiB 40 MiB 100 GiB 0.05 1.04 39 up 4 ssd 0.09769 1.00000 100 GiB 48 MiB 7.6 MiB 5 KiB 41 MiB 100 GiB 0.05 1.04 40 up 7 hdd 0.09769 1.00000 100 GiB 49 MiB 8.0 MiB 8 KiB 41 MiB 100 GiB 0.05 1.04 44 up 6 ssd 0.09769 1.00000 100 GiB 48 MiB 7.6 MiB 5 KiB 40 MiB 100 GiB 0.05 1.03 40 up 8 ssd 0.09769 1.00000 100 GiB 34 MiB 7.6 MiB 9 KiB 27 MiB 100 GiB 0.03 0.74 41 up TOTAL 900 GiB 419 MiB 69 MiB 61 KiB 350 MiB 900 GiB 0.05 MIN/MAX VAR: 0.74/1.04 STDDEV: 0.00 |
3.6管理Pool
ceph池是ceph客户端与ceph集群通信的接口。ceph存在两种类型的池,一种是replicated即复制池,另一种是erasure-coded即纠删代码池,有点类似于软RAID5.都是用于保护数据的完整性和持久性。默认使用复制池,纠删代码池持久性所需的磁盘空间使用量,但其计算量(需要对数据进行复杂的计算以生成校验块)比复制池要高很多,即性能开销要高于复制池,因此后续都是使用复制池。
3.6.1创建池
#创建池之前,先修改下池默认副本数,调整为2,默认为3
|
[root@ceph01 ~]# ceph config set global osd_pool_default_size 2 [root@ceph01 ~]# ceph osd pool create ssdpool 128 128 [root@ceph01 ~]# ceph osd pool create hddpool 128 128 |
#列出池
|
[root@ceph01 ~]# ceph osd lspools |
|
1 .mgr 2 ssdpool 3 hddpool 4 cephfs_data 5 cephfs_metadata |
#为每个设备添加一个类,默认已按磁盘类型(ssh/hdd)分类
|
[root@ceph01 ~]# ceph osd crush set-device-class hdd osd.1 osd.3 osd.5 osd.7 osd.9 |
|
osd.1 already set to class hdd. set-device-class item id 1 name 'osd.1' device_class 'hdd': no change. osd.3 already set to class hdd. set-device-class item id 3 name 'osd.3' device_class 'hdd': no change. osd.5 already set to class hdd. set-device-class item id 5 name 'osd.5' device_class 'hdd': no change. osd.7 already set to class hdd. set-device-class item id 7 name 'osd.7' device_class 'hdd': no change. osd.9 already set to class hdd. set-device-class item id 9 name 'osd.9' device_class 'hdd': no change. set osd(s) to class 'hdd' |
|
[root@ceph01 ~]# ceph osd crush set-device-class ssd osd.0 osd.2 osd.4 osd.6 osd.8 |
|
osd.0 already set to class ssd. set-device-class item id 0 name 'osd.0' device_class 'ssd': no change. osd.2 already set to class ssd. set-device-class item id 2 name 'osd.2' device_class 'ssd': no change. osd.4 already set to class ssd. set-device-class item id 4 name 'osd.4' device_class 'ssd': no change. osd.6 already set to class ssd. set-device-class item id 6 name 'osd.6' device_class 'ssd': no change. osd.8 already set to class ssd. set-device-class item id 8 name 'osd.8' device_class 'ssd': no change. set osd(s) to class 'ssd' |
3.6.2创建crush rule
|
[root@ceph01 ~]# ceph osd crush rule create-replicated ssd default host ssd [root@ceph01 ~]# ceph osd crush rule create-replicated hdd default host hdd |
#查看池规则
|
[root@ceph01 ~]# ceph osd crush rule ls |
|
replicated_rule ssd hdd |
#转储特定crush规格的内容
|
[root@ceph01 ~]# ceph osd crush rule dump ssd |
#删除crush rule
|
[root@ceph01 ~]# ceph osd crush rule rm ssd [root@ceph01 ~]# ceph osd crush rule rm hdd |
3.6.3将crush rule应用到池上
|
[root@ceph01 ~]# ceph osd pool set ssdpool crush_rule ssd |
|
set pool 2 crush_rule to ssd |
|
[root@ceph01 ~]# ceph osd pool set hddpool crush_rule hdd |
|
set pool 3 crush_rule to hdd |
3.6.4调整池副本数
#查看当前池的副本数
|
[root@ceph01 ~]# ceph osd dump | grep ssd |
|
pool 2 'ssdpool' replicated size 2 min_size 1 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 1072 lfor 0/604/602 flags hashpspool stripe_width 0 read_balance_score 1.41 |
|
[root@ceph01 ~]# ceph osd dump | grep hdd |
|
pool 3 'hddpool' replicated size 2 min_size 1 crush_rule 2 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 1071 lfor 0/630/628 flags hashpspool stripe_width 0 read_balance_score 1.41 |
#调整池对象副本数为3,这里的3副本包括对象本身,即除对象本身外,还有2个副本
|
[root@ceph01 ~]# ceph osd pool set ssdpool size 3 |
|
set pool 2 size to 3 |
|
[root@ceph01 ~]# ceph osd pool set hddpool size 3 |
|
set pool 3 size to 3 |
|
[root@ceph01 ~]# ceph osd dump | egrep 'ssd|hdd' |
|
pool 2 'ssdpool' replicated size 3 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 1073 lfor 0/604/602 flags hashpspool stripe_width 0 read_balance_score 1.41 pool 3 'hddpool' replicated size 3 min_size 2 crush_rule 2 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 1075 lfor 0/630/628 flags hashpspool stripe_width 0 read_balance_score 1.41 |
#查看池副本数
|
[root@ceph01 ~]# ceph osd pool get ssdpool size |
|
size: 3 |
|
[root@ceph01 ~]# ceph osd pool get hddpool size |
|
size: 3 |
|
[root@ceph01 ~]# ceph osd dump | grep ssdpool | grep "size" |
|
pool 2 'ssdpool' replicated size 3 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 1073 lfor 0/604/602 flags hashpspool stripe_width 0 read_balance_score 1.41 |
##对象可能会接受降级模式下的IO操作,即副本数可以小于pool size时,还可以进行读写操作;min_size表示IO所需的最小副本数
|
[root@ceph01 ~]# ceph osd pool set ssdpool min_size 1 |
注意:对象不能接受小于min_size副本的IO操作
3.6.5重命名池
|
[root@ceph01 ~]# ceph osd pool rename hddpool zbypool |
|
pool 'hddpool' renamed to 'zbypool' |
|
[root@ceph01 ~]# ceph osd lspools |
|
1 .mgr 2 ssdpool 3 zbypool 4 cephfs_data 5 cephfs_metadata |
注意:重命名池名称后,如果具有经过身份验证的用户访问该池,还必须用新的池名称区更新用户的功能(cap即capability,表明用户有操作ceph的特定权限)
3.6.6统计池使用情况
##统计池使用情况,可以使用如下命令
|
[root@ceph01 ~]# rados df |
|
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR .mgr 904 KiB 2 0 4 0 0 0 928 1.7 MiB 329 2.4 MiB 0 B 0 B cephfs_data 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B cephfs_metadata 130 KiB 22 0 44 0 0 0 142 142 KiB 90 55 KiB 0 B 0 B ssdpool 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B zbypool 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B total_objects 24 total_used 459 MiB total_avail 1000 GiB total_space 1000 GiB |
##若要统计某个指定的池,则可以加上-p参数
|
[root@ceph01 ~]# ceph df -p zbypool [root@ceph01 ~]# ceph df |
|
--- RAW STORAGE --- CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 500 GiB 500 GiB 230 MiB 230 MiB 0.04 ssd 500 GiB 500 GiB 229 MiB 229 MiB 0.04 TOTAL 1000 GiB 1000 GiB 459 MiB 459 MiB 0.04 --- POOLS --- POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL .mgr 1 1 449 KiB 2 904 KiB 0 475 GiB ssdpool 2 32 0 B 0 0 B 0 158 GiB zbypool 3 32 0 B 0 0 B 0 158 GiB cephfs_data 4 64 0 B 0 0 B 0 475 GiB cephfs_metadata 5 64 35 KiB 22 130 KiB 0 475 GiB |
3.6.7对池进行快照
1#创建快照
|
[root@ceph01 ~]# ceph osd pool mksnap zbypool snap-zbypool-20231014 |
|
created pool zbypool snap snap-zbypool-20231014 |
|
[root@ceph01 ~]# rados -p zbypool mksnap snap-zbypool-20231015 |
|
created pool zbypool snap snap-zbypool-20231015 |
2#列出快照
|
[root@ceph01 ~]# rados -p zbypool lssnap |
|
1 snap-zbypool-20231014 2023.10.14 03:04:09 2 snap-zbypool-20231015 2023.10.14 03:14:37 2 snaps |
3#回滚至存储池快照
|
[root@ceph01 ~]# rados -p zbypool rollback zbypool snap-zbypool-20231014 |
|
rolled back pool zbypool to snapshot snap-zbypool-20231014 |
4#删除池快照
|
[root@ceph01 ~]# ceph osd pool rmsnap zbypool snap-zbypool-20231014 |
|
removed pool zbypool snap snap-zbypool-20231014 |
|
[root@ceph01 ~]# rados -p zbypool rmsnap snap-zbypool-20231015 |
|
removed pool zbypool snap snap-zbypool-20231015 |
如果创建了池快照,将无法在池中执行RBD的镜像快照,并且不可逆
3.6.8为池设置/禁用应用(Application)类型
ceph为池提供了额外的保护,以防止未经授权类型的客户端将数据写入池中。在创建池时管理员必须明确启用池的应用程序来接收IO操作,如ceph block device(rbd块设备)、ceph object gateway(rgw对象网关)等应用程序。否则,未启用的池将会出现一个HEALTH_WARN状态,且客户端无法对该池执行IO操作,例如,将池zbypool启用应用程序为rgw
#查看池应用程序
|
[root@ceph01 ~]# ceph osd dump | grep cephfs |
|
pool 4 'cephfs_data' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 652 flags hashpspool stripe_width 0 application cephfs read_balance_score 2.19 pool 5 'cephfs_metadata' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 652 flags hashpspool stripe_width 0 pg_autoscale_bias 4 pg_num_min 16 recovery_priority 5 application cephfs read_balance_score 1.41 |
#启用应用程序
|
[root@ceph01 ~]# ceph osd pool application enable zbypool rgw |
|
enabled application 'rgw' on pool 'zbypool' |
#禁用应用程序
|
[root@ceph01 ~]# ceph osd pool application disable zbypool rgw --yes-i-really-mean-it |
|
disable application 'rgw' on pool 'zbypool' |
3.6.9设置/删除应用程序元数据
设置池类型(应用程序)元数据,主要用来描述客户端应用属性,元数据是键值对
|
[root@ceph01 ~]# ceph osd pool application enable zbypool rbd |
|
enabled application 'rbd' on pool 'zbypool' |
|
[root@ceph01 ~]# ceph osd pool application set zbypool rbd testkey testvalue |
|
set application 'rbd' key 'testkey' to 'testvalue' on pool 'zbypool' |
#查看应用元数据
|
[root@ceph01 ~]# ceph osd pool application get zbypool |
|
{ "rbd": { "testkey": "testvalue" } } |
#删除应用元数据
|
[root@ceph01 ~]# ceph osd pool application rm zbypool rbd testkey |
|
removed application 'rbd' key 'testkey' on pool 'zbypool' |
3.6.10删除池
##为了保护数据,默认无法删除池,在删除池钱,需要修改参数:mon_allow_pool_delete为true
|
[root@ceph01 ~]# ceph config set mon mon_allow_pool_delete true |
#删除池是,池的名字要输入2次
|
[root@ceph01 ~]# ceph osd pool rm zbypool zbypool --yes-i-really-really-mean-it |
|
pool 'zbypool' removed |
3.7管理MDS
MDS守护进程用于Cephfs(文件系统),MDS采用的是主备模式,即cephfs仅使用1个活跃的MDS守护进程。
Cephfs文件系统要使用2个池:
- 元数据池:用于存储Ceph元数据服务器(MDS)数据的池,通常由索引节点(inode)组成,包括文件所有权、权限、创建时间、上次修改或访问时间、父目录等信息。
- Data池:专门用于存储文件数据的池。Ceph可以将一个文件存储为一个或多个对象,在存储时通常将数据划分成较小的块。例如,在存储文件时,Ceph将文件数据划分成较小的对象并分别存储。
当客户端请求访问文件时,Ceph会将这些对象组合成一个完整的文件返回给客户端。
对于具有元数据密集型的工作负载,请不要将MDS服务部署在与其他内存密集型的节点上,因为MDS需要更多的内存。
`mds_cache_memory_limit`参数表示MDS元数据内存使用限制,默认为4GB,设置成64G或更大,表示MDS缓存的最大内存使用目标。
MDS将尝试保持在此限制的保留范围内(默认为95%;1 - mds_cache_reservation)通过在其缓存中修剪未使用的元数据并回收客户端缓存中的缓存项。
`mds_cache_reservation` 参数值默认为0.05,表示MDS缓存预留百分比。
由于从客户端召回缓存较慢,MDS有可能超过此限制。
`mds_health_cache_threshold`(默认为1.5)参数为MDS发出集群健康警告时设置缓存满阈值。
当缓存大小超出限制时,MDS 将无法为元数据对象提供快速响应,从而导致文件系统性能下降。
配置MDS服务有多种方法,此处介绍2种,大同小异。
3.7.1创建cephfs
3.7.1.1先创建cephfs再部署MDS
1#先创建cephfs池
|
[root@ceph01 ~]# ceph osd pool create cephfs_data 128 128 [root@ceph01 ~]# ceph osd pool create cephfs_metadata 64 64 [root@ceph01 ~]# ceph osd lspools |
|
1 .mgr 2 ssdpool 4 cephfs_data 5 cephfs_metadata |
2#为数据池和元数据池创建文件系统
|
[root@ceph01 ~]# ceph fs new cephfs cephfs_metadata cephfs_data |
|
filesystem 'cephfs' already exists |
3#使用ceph orch apply命令部署MDS服务
|
[root@ceph01 ~]# ceph orch apply mds cephfs --placement="2 ceph01 ceph02" |
|
Scheduled mds.cephfs update... |
4#查看状态
|
[root@ceph01 ~]# ceph fs ls |
|
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ] |
|
[root@ceph01 ~]# ceph fs status |
|
cephfs - 0 clients ====== RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS 0 active cephfs.ceph01.aibnpt Reqs: 0 /s 10 13 12 0 POOL TYPE USED AVAIL cephfs_metadata metadata 130k 474G cephfs_data data 0 474G STANDBY MDS cephfs.ceph02.kzinfm MDS version: ceph version 18.2.0 (5dd24139a1eada541a3bc16b6941c5dde975e26d) reef (stable) |
|
[root@ceph01 ~]# ceph -s |
|
cluster: id: 4b4cc258-6679-11ee-ad4a-005056982bba health: HEALTH_OK services: mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 3d) mgr: ceph01.ywwete(active, since 3d), standbys: ceph03.alzljc mds: 1/1 daemons up, 1 standby osd: 10 osds: 10 up (since 2d), 10 in (since 6d) data: volumes: 1/1 healthy pools: 4 pools, 161 pgs objects: 24 objects, 458 KiB usage: 488 MiB used, 999 GiB / 1000 GiB avail pgs: 161 active+clean |
3.7.1.2先部署MDS再创建cephfs
1#配置mds.yaml
|
[root@ceph01 ~]# vim mds.yaml |
|
service_type: mds service_id: cephfs placement: host: - ceph01 - ceph02 |
2#应用mds.yaml
|
[root@ceph01 ~]# ceph orch apply -i mds.yaml |
3#等待mds.cephfs服务就绪
|
[root@ceph01 ~]# ceph orch ls |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 4m ago 6d count:1 ceph-exporter 5/5 5m ago 6d * crash 5/5 5m ago 6d * grafana ?:3000 1/1 4m ago 5d ceph01 mds.cephfs 2/2 5m ago 13m ceph01;ceph02;count:2 mgr 2/2 4m ago 3d ceph01;ceph03;count:2 mon 3/3 5m ago 3d ceph01;ceph02;ceph03;count:3 node-exporter ?:9100 5/5 5m ago 6d * osd 10 5m ago - osd.all-available-devices 0 - 2d prometheus ?:9095 1/1 4m ago 6d count:1 |
4#创建cephfs池
|
[root@ceph01 ~]# ceph osd pool create cephfs_data 128 128 [root@ceph01 ~]# ceph osd pool create cephfs_metadata 64 64 |
5#为数据池和元数据池创建文件系统
|
[root@ceph01 ~]# ceph fs new cephfs cephfs_metadata cephfs_data |
3.7.2使用cephfs
1#创建cephfs客户端,允许访问cephFS两个池(cephfs_metadata和cephfs_data)
|
[root@ceph01 ~]# ceph auth get-or-create client.cephfs mon 'allow r' mds 'allow rw' osd 'allow rwx pool=cephfs_metadata,allow rwx pool=cephfs_data' -o /etc/ceph/ceph.client.cephfs.keyring [root@ceph01 ~]# ll /etc/ceph |
|
-rw------- 1 root root 151 Oct 12 17:04 ceph.client.admin.keyring -rw-r--r-- 1 root root 64 Oct 16 13:34 ceph.client.cephfs.keyring -rw-r--r-- 1 root root 265 Oct 12 17:04 ceph.conf -rw-r--r-- 1 root root 595 Oct 9 15:57 ceph.pub -rw-r--r-- 1 root root 92 Aug 4 03:43 rbdmap |
2#将cephfs客户端的秘钥存储到/etc/ceph/cephfs.key,这样在挂载指定时,可以直接指定该文件,而不用显示输入秘钥
|
[root@ceph01 ~]# ceph auth print-key client.cephfs > /etc/ceph/cephfs.key [root@ceph01 ~]# cat /etc/ceph/cephfs.key |
|
AQBnyyxlei+mNRAAfq1KYSdhz7v1ImSjlAWxKw== |
3#在需要挂载cephfs的目标主机上创建挂载点,并安装ceph软件包
|
[root@client ~]# vim /etc/yum.repos.d/ceph.repo |
|
[ceph] name=Ceph packages for $basearch baseurl=https://mirrors.aliyun.com/ceph/rpm-18.2.0/el8//x86_64 enabled=1 priority=2 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc [ceph-noarch] name=Ceph noarch packages baseurl=https://mirrors.aliyun.com/ceph/rpm-18.2.0/el8//noarch enabled=1 priority=2 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc [ceph-source] name=Ceph source packages baseurl=https://mirrors.aliyun.com/ceph/rpm-18.2.0/el8//SRPMS enabled=0 priority=2 gpgcheck=1 |
|
[root@client ~]# yum clean all [root@client ~]# yum makecache [root@client ~]# yum -y install ceph ceph-common |
|
Upgraded: libibverbs-44.0-2.el8.1.x86_64 platform-python-setuptools-39.2.0-7.el8.noarch Installed: ceph-2:18.2.0-0.el8.x86_64 ceph-base-2:18.2.0-0.el8.x86_64 ceph-common-2:18.2.0-0.el8.x86_64 ceph-grafana-dashboards-2:18.2.0-0.el8.noarch ceph-mds-2:18.2.0-0.el8.x86_64 ceph-mgr-2:18.2.0-0.el8.x86_64 ceph-mgr-cephadm-2:18.2.0-0.el8.noarch ceph-mgr-dashboard-2:18.2.0-0.el8.noarch ceph-mgr-k8sevents-2:18.2.0-0.el8.noarch ceph-mgr-modules-core-2:18.2.0-0.el8.noarch ceph-mgr-rook-2:18.2.0-0.el8.noarch ceph-mon-2:18.2.0-0.el8.x86_64 ceph-osd-2:18.2.0-0.el8.x86_64 ceph-prometheus-alerts-2:18.2.0-0.el8.noarch ceph-selinux-2:18.2.0-0.el8.x86_64 cephadm-2:18.2.0-0.el8.noarch gperftools-libs-1:2.7-9.el8.x86_64 libbabeltrace-1.5.4-4.el8.x86_64 libcephfs2-2:18.2.0-0.el8.x86_64 libcephsqlite-2:18.2.0-0.el8.x86_64 libconfig-1.5-9.el8.x86_64 libicu-60.3-2.el8_1.x86_64 liboath-2.6.2-3.el8.x86_64 librabbitmq-0.9.0-3.el8.x86_64 librados2-2:18.2.0-0.el8.x86_64 libradosstriper1-2:18.2.0-0.el8.x86_64 librbd1-2:18.2.0-0.el8.x86_64 librdkafka-0.11.4-3.el8.x86_64 librdmacm-44.0-2.el8.1.x86_64 librgw2-2:18.2.0-0.el8.x86_64 libstoragemgmt-1.9.1-3.el8.x86_64 libunwind-1.3.1-3.el8.x86_64 lttng-ust-2.8.1-11.el8.x86_64 nvme-cli-1.16-7.el8.x86_64 python3-asyncssh-2.7.0-2.el8.noarch python3-babel-2.5.1-7.el8.noarch python3-bcrypt-3.1.6-2.el8.1.x86_64 python3-beautifulsoup4-4.6.3-2.el8.1.noarch python3-cachetools-3.1.1-4.el8.noarch python3-ceph-argparse-2:18.2.0-0.el8.x86_64 python3-ceph-common-2:18.2.0-0.el8.x86_64 python3-cephfs-2:18.2.0-0.el8.x86_64 python3-certifi-2018.10.15-7.el8.noarch python3-cffi-1.11.5-5.el8.x86_64 python3-chardet-3.0.4-7.el8.noarch python3-cheroot-8.5.2-1.el8.noarch python3-cherrypy-18.4.0-1.el8.noarch python3-cryptography-3.2.1-5.el8.x86_64 python3-cssselect-0.9.2-10.el8.noarch python3-defusedxml-0.6.0-1.el8.noarch python3-google-auth-1:1.1.1-10.el8.noarch python3-html5lib-1:0.999999999-6.el8.noarch python3-idna-2.5-5.el8.noarch python3-influxdb-5.3.1-1.el8.noarch python3-isodate-0.6.0-1.el8.noarch python3-jaraco-6.2-6.el8.noarch python3-jaraco-functools-2.0-4.el8.noarch python3-jinja2-2.10.1-3.el8.noarch python3-jsonpatch-1.21-2.el8.noarch python3-jsonpointer-1.10-11.el8.noarch python3-jwt-1.6.1-2.el8.noarch python3-kubernetes-1:11.0.0-6.el8.noarch python3-libstoragemgmt-1.9.1-3.el8.x86_64 python3-logutils-0.3.5-11.el8.noarch python3-lxml-4.2.3-4.el8.x86_64 python3-mako-1.0.6-14.el8.noarch python3-markupsafe-0.23-19.el8.x86_64 python3-more-itertools-7.2.0-3.el8.noarch python3-msgpack-0.6.2-1.el8.x86_64 python3-natsort-7.1.1-2.el8.noarch python3-oauthlib-2.1.0-1.el8.noarch python3-pecan-1.3.2-9.el8.noarch python3-pip-9.0.3-22.el8.rocky.0.noarch python3-pkgconfig-1.5.1-5.el8.noarch python3-ply-3.9-9.el8.noarch python3-portend-2.6-1.el8.noarch python3-prettytable-0.7.2-14.el8.noarch python3-pyOpenSSL-19.0.0-1.el8.noarch python3-pyasn1-0.3.7-6.el8.noarch python3-pyasn1-modules-0.3.7-6.el8.noarch python3-pycparser-2.14-14.el8.noarch python3-pysocks-1.6.8-3.el8.noarch python3-pytz-2017.2-9.el8.noarch python3-pyyaml-3.12-12.el8.x86_64 python3-rados-2:18.2.0-0.el8.x86_64 python3-rbd-2:18.2.0-0.el8.x86_64 python3-repoze-lru-0.7-6.el8.noarch python3-requests-2.20.0-3.el8_8.noarch python3-requests-oauthlib-1.0.0-1.el8.noarch python3-rgw-2:18.2.0-0.el8.x86_64 python3-routes-2.4.1-12.el8.noarch python3-rsa-4.9-2.el8.noarch python3-saml-1.9.0-3.el8.noarch python3-setuptools-39.2.0-7.el8.noarch python3-simplegeneric-0.8.1-17.el8.noarch python3-singledispatch-3.4.0.3-18.el8.noarch python3-tempora-1.14.1-5.el8.noarch python3-trustme-0.6.0-4.el8.noarch python3-urllib3-1.24.2-5.el8.noarch python3-waitress-1.4.3-1.el8.noarch python3-webencodings-0.5.1-6.el8.noarch python3-webob-1.8.5-1.el8.1.noarch python3-websocket-client-0.56.0-5.el8.noarch python3-webtest-2.0.33-1.el8.noarch python3-werkzeug-0.12.2-4.el8.noarch python3-xmlsec-1.3.3-7.el8.x86_64 python3-zc-lockfile-2.0-2.el8.noarch python36-3.6.8-38.module+el8.5.0+671+195e4563.x86_64 smartmontools-1:7.1-1.el8.x86_64 thrift-0.13.0-2.el8.x86_64 userspace-rcu-0.10.1-4.el8.x86_64 Complete! |
|
[root@client ~]# vim /etc/hosts |
|
#public network 10.9.254.81 ceph01 10.9.254.82 ceph02 10.9.254.83 ceph03 10.9.254.84 ceph04 10.9.254.85 ceph05 |
4#将秘钥文件同步到目标主机上
|
[root@ceph01 ~]# scp /etc/ceph/ceph.client.cephfs.keyring /etc/ceph/cephfs.key /etc/ceph/ceph.conf 10.9.254.86:/etc/ceph [root@client ~]# ll /etc/ceph/ |
|
-rw-r--r-- 1 root root 64 Oct 16 13:51 ceph.client.cephfs.keyring -rw-r--r-- 1 root root 265 Oct 16 13:51 ceph.conf -rw-r--r-- 1 root root 40 Oct 16 13:51 cephfs.key -rw-r--r-- 1 root root 92 Aug 4 03:43 rbdmap |
5#在目标机器上进行挂载(前提已经安装了ceph软件包,并同步了ceph.conf文件和密钥文件)
6789为mon服务端口
|
[root@client /]# mkdir /cephfs [root@client /]# mount -t ceph ceph01:6789,ceph02:6789,ceph03:6789:/ /cephfs -o name=cephfs,secretfile=/etc/ceph/cephfs.key [root@client /]# df -hT |
|
Filesystem Type Size Used Avail Use% Mounted on devtmpfs devtmpfs 3.9G 0 3.9G 0% /dev tmpfs tmpfs 3.9G 0 3.9G 0% /dev/shm tmpfs tmpfs 3.9G 17M 3.9G 1% /run tmpfs tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup /dev/mapper/rl-root xfs 111G 3.3G 108G 3% / /dev/sda1 xfs 1014M 188M 827M 19% /boot /dev/mapper/rl-home xfs 30G 247M 30G 1% /home tmpfs tmpfs 796M 0 796M 0% /run/user/0 10.9.254.81:6789,10.9.254.82:6789,10.9.254.83:6789:/ ceph 475G 0 475G 0% /cephfs |
|
[root@client /]# vim /etc/fstab |
|
/dev/mapper/rl-root / xfs defaults 0 0 UUID=98bf19dc-f5d4-459d-88f8-b8123a08e089 /boot xfs defaults 0 0 /dev/mapper/rl-home /home xfs defaults 0 0 /dev/mapper/rl-swap none swap defaults 0 0 ceph01:6789,ceph02:6789,ceph03:6789:/ /cephfs ceph defaults,name=cephfs,secretfile=/etc/ceph/cephfs.key,_netdev 0 0 |
3.7.3删除cephfs
需要删除MDS服务,包括CephFS卷、关联的池和服务
1#挂载了cephfs的客户端要先取消挂载cephfs
|
[root@client /]# umount /cephfs |
2#修改参数,允许删除池,需要将参数 mon_allow_pool_delete 置为 true
|
[root@ceph01 ~]# ceph config show-with-defaults mon.ceph01 |grep mon_allow_pool_delete |
|
mon_allow_pool_delete false mon |
|
[root@ceph01 ~]# ceph config set mon mon_allow_pool_delete true |
3#删除文件系统,同时会删除对应的池和mds服务,包括上面创建的cephfs_data和cephfs_metadata
|
[root@ceph01 ~]# ceph fs volume rm cephfs --yes-i-really-mean-it |
|
metadata pool: cephfs_metadata data pool: ['cephfs_data'] removed |
|
[root@ceph01 ~]# ceph osd lspools |
|
1 .mgr 2 ssdpool |
4#删除mds.cephfs 服务 (如果未被删除,则手工执行如下命令)
|
[root@ceph01 ~]# ceph orch ls |
|
NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 105s ago 6d count:1 ceph-exporter 5/5 10m ago 6d * crash 5/5 10m ago 6d * grafana ?:3000 1/1 105s ago 6d ceph01 mgr 2/2 7m ago 3d ceph01;ceph03;count:2 mon 3/3 7m ago 3d ceph01;ceph02;ceph03;count:3 node-exporter ?:9100 5/5 10m ago 6d * osd 10 10m ago - osd.all-available-devices 0 - 2d prometheus ?:9095 1/1 105s ago 6d count:1 |
|
[root@ceph01 ~]# ceph orch rm mds.cephfs |
|
Removed service mds.cephfs |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 22
22 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)