基于OpenClaw环境的Agent强化学习(RFT+GRPO)训练机制与自动化实践报告
·
摘要
本报告围绕OpenClaw体系下Agent的强化学习(RL)训练方法论,重点解析**RFT(Reward Fine-Tuning,奖励微调)+ GRPO(Group Relative Policy Optimization)**训练链路,并结合自动化工具ark-trainer-inner,梳理从需求输入到模型部署的全流程实践方案。报告旨在降低大模型RL训练门槛,实现自然语言驱动的训练自动化,为OpenClaw环境下Agent的偏好对齐与任务性能优化提供可落地的技术路径。
一、背景与目标
1.1 OpenClaw Agent训练体系背景
OpenClaw体系构建了完整的Agent模型训练方法论,覆盖:
- 轨迹收集、数据处理、奖励设计、奖励模型训练
- Policy Model RL训练方法论
- 模型参数自动化更新机制
- 端到端测评体系
传统RL训练流程繁琐,需手动完成数据构造、标注、策略选择、训练调度等环节,门槛高、迭代效率低。
1.2 核心目标
通过自动化工具ark-trainer-inner,实现:
- 以自然语言驱动RFT+GRPO训练全流程
- 自动完成环境检查、框架安装、策略选择、数据处理、训练调度与测评验证
- 联动OpenClaw环境,实现训练-部署-测评的闭环
二、核心技术原理:RFT与GRPO
2.1 RFT(奖励微调)
- 定位:RLHF(人类反馈强化学习)的核心前置环节,是模型偏好对齐的关键步骤。
- 作用:基于奖励模型(RM)生成的偏好数据,对基座模型进行微调,让模型输出更贴合人类偏好/业务规则(如客服合规性、用户满意度)。
- 流程:偏好数据构造 → 优劣样本标注 → 奖励微调训练 → 偏好对齐模型输出。
2.2 GRPO(分组相对策略优化)
- 定位:RFT之后的强化学习优化步骤,进一步提升模型任务表现。
- 作用:在RFT校准后的模型基础上,通过策略梯度优化,让模型在特定任务(如客服质检、对话生成)中获得更高奖励,强化任务能力。
- 优势:相比纯RLHF,RFT+GRPO组合能实现更稳定的偏好对齐与性能提升。
2.3 训练策略对比
| 策略 | 适用场景 | 核心优势 | 流程特点 |
|---|---|---|---|
| RFT+GRPO | 高精度偏好对齐、复杂业务场景(如客服质检) | 先校准偏好,再强化学习,效果更稳定、对齐更精准 | 两步走:RFT微调 → GRPO强化学习 |
| Only GRPO | 快速迭代、偏好基础较好的模型 | 跳过RFT步骤,训练周期更短 | 单步强化学习 |
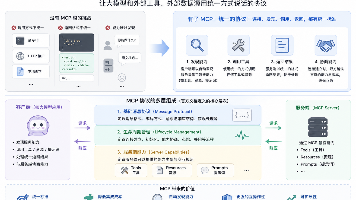
三、自动化工具:ark-trainer-inner 解析
3.1 工具定位
ark-trainer-inner是基于ark-sdk的大模型训练任务自动化工具,核心价值是用自然语言替代手动操作,实现RFT+GRPO训练全流程自动化。
3.2 核心自动化能力
- 策略自动选择:
- 支持用户通过自然语言指定训练需求(如“对客服质检Agent做RFT+GRPO训练”)
- 自动根据模型效果或业务需求,选择
RFT+GRPO或Only GRPO策略
- RFT数据自动化处理:
- 自动生成模型输出对(如“合规回答 vs 不合规回答”)
- 调用奖励模型完成优劣样本标注,无需人工干预
- 训练流程自动化:
- 自动执行RFT微调训练
- RFT完成后自动触发GRPO强化学习,实现链路无缝衔接
- 任务与测评管理:
- 训练任务心跳监控,避免超时中断
- 自动选择评测集、运行评测指标,生成训练效果报告
- 训练完成后自动同步模型参数到OpenClaw Agent体系
- OpenClaw环境联动:
- 自动检查OpenClaw环境配置、登录状态
- 一键安装训练依赖框架
- 自动更新模型参数至OpenClaw,支持线上直接部署
四、RFT+GRPO训练命令行操作模板
4.1 前置条件
# 1. 激活OpenClaw环境(以conda为例)
conda activate openclaw
# 2. 安装核心依赖
pip install ark-trainer-inner>=1.0.0 openclaw-sdk>=2.0.0 torch>=2.1.0 transformers>=4.35.0
4.2 基础快速版模板(通用场景)
# RFT+GRPO训练核心命令
ark-trainer-inner train \
--strategy "RFT+GRPO" \
--task_name "客服质检_agent_training" \
--model_path "/path/to/base_model" \
--data_path "/path/to/train_data.jsonl" \
--output_dir "/path/to/output_model" \
--openclaw_env True \
--eval_auto True \
--max_train_steps 10000 \
--batch_size 8 \
--log_dir "/path/to/train_log"
4.3 进阶自定义版模板(精细化调参)
# 进阶版RFT+GRPO训练命令
ark-trainer-inner train \
--strategy "RFT+GRPO" \
--task_name "智能客服_RFT_GRPO_v2" \
--model_path "/path/to/llama3-8b-base" \
--data_path "/path/to/chat_quality_data.jsonl" \
--output_dir "/path/to/trained_model/20260320" \
--openclaw_env True \
--eval_auto True \
--eval_dataset "/path/to/custom_eval_data" \
--max_train_steps 15000 \
--rft_steps 5000 \
--grpo_learning_rate 5e-6 \
--batch_size 8 \
--gradient_accumulation_steps 2 \
--warmup_ratio 0.1 \
--save_steps 2000 \
--log_dir "/path/to/train_log" \
--device "cuda:0" \
--fp16 True \
--rm_model_path "/path/to/reward_model" \
--auto_heartbeat True
4.4 核心参数说明
| 参数名 | 核心作用 | 推荐值(新手) |
|---|---|---|
--strategy |
指定训练策略 | 固定为"RFT+GRPO" |
--model_path |
基座模型路径 | OpenClaw内置模型/本地微调模型路径 |
--data_path |
训练数据路径 | JSONL格式,包含「问题+候选回答」 |
--rft_steps |
RFT阶段训练步数 | 总步数的1/3~1/2(如总步数15000则设5000) |
--batch_size |
训练批次大小 | 16G显存:4-8;32G显存:16-32 |
--openclaw_env |
联动OpenClaw环境 | 固定为True |
4.5 实践流程
- 参数修改:将模板中
/path/to/xxx替换为实际路径 - 启动训练:在终端执行命令,工具自动完成全流程
- 进度监控:查看
--log_dir日志或OpenClaw控制台 - 效果验证:训练完成后,工具自动生成评测报告,验证偏好对齐率与任务准确率
五、应用场景:客服质检Agent训练实践
5.1 场景需求
优化OpenClaw环境下的客服质检Agent,提升回答合规性与用户满意度。
5.2 实践步骤
- 需求输入:自然语言指令
"对当前客服质检Agent执行RFT+GRPO训练,优化合规性与用户满意度" - 环境准备:工具自动检查OpenClaw环境,安装训练框架
- RFT数据处理:自动构造「合规回答/不合规回答」样本,用奖励模型标注优劣
- RFT微调:对基座模型进行奖励微调,校准偏好
- GRPO强化学习:基于RFT模型,执行GRPO训练,强化质检决策能力
- 测评与部署:自动运行评测集,验证合规率与满意度,同步模型到OpenClaw
5.3 预期效果
- RFT阶段:偏好对齐率提升≥20%
- GRPO阶段:客服质检准确率提升≥15%
- 全流程耗时:相比手动操作减少≥60%
六、总结与价值
6.1 核心价值
- 降低门槛:自然语言驱动自动化,无需深入RL细节即可完成训练
- 提升效率:全流程自动化,大幅减少手动操作与迭代时间
- 保障效果:RFT+GRPO组合实现稳定的偏好对齐与性能优化
- 闭环部署:联动OpenClaw环境,实现训练-测评-部署的端到端闭环
6.2 展望
未来可进一步扩展:
- 支持更多训练策略(如DPO、PPO)
- 优化多卡训练与低显存适配
- 增强日志可视化与故障自动排查能力
七、附录
- 工具文档:
ark-trainer-innerSKILL.md - 参考资料:OpenClaw RL训练机制文档、RLHF技术白皮书

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)