左程云-02 必备(1)
·
算法讲解019【必备】算法笔试中处理输入和输出

-
- C++ 的 Fast IO (对应图中 “不要用Scanner、System.out”)
// 关流同步,提速神器
std::ios::sync_with_stdio(false);
// 解绑 cin 和 cout,进一步提速
std::cin.tie(nullptr);
// std::cout.tie(nullptr); // 可加可不加
算法讲解020【必备】递归和master公式

class Solution {
public:
// 递归求最大值
int max(vector<int> arr, int l, int r) {
if (l == r) return arr.at(r);
int m = (l + r) / 2;
int lmax = max(arr, l, m);
int rmax = max(arr, m + 1, r);
return std::max(lmax, rmax);
}
};
算法讲解021【必备】归并排序

递归版本
int const max = 501;
static int arr[max];
static int help[max];
void merge(int left, int mid, int right)
{
int i = left;
int a = left;
int b = mid + 1;
while (a <= mid && b <= right)
{
// 谁小我移动谁
help[i++] = arr[a] <= arr[b] ? arr[a++] : arr[b++];
}
while (a <= mid)
{
help[i++] = arr[a++];
}
while (b <= right)
{
help[i++] = arr[b++];
}
for (i = left; i <= right; i++)
{
arr[i] = help[i];
}
}
void mergeSort(int left, int right)
{
if (left == right)
{
return;
}
int mid = (left + right) / 2;
mergeSort(left, mid);
mergeSort(mid + 1, right);
merge(left, mid, right);
}
非递归版本
#include <iostream>
#include <stack>
#include <vector>
#include <algorithm>
using std::stack;
using std::vector;
int const max = 501;
static int arr[max];
static int help[max];
void merge(int left, int mid, int right)
{
int i = left;
int a = left;
int b = mid + 1;
while (a <= mid && b <= right)
{
// 谁小我移动谁
help[i++] = arr[a] <= arr[b] ? arr[a++] : arr[b++];
}
while (a <= mid)
{
help[i++] = arr[a++];
}
while (b <= right)
{
help[i++] = arr[b++];
}
for (i = left; i <= right; i++)
{
arr[i] = help[i];
}
}
void mergeSort()
{
int n = max;
int left, mid, right;
for (int step = 1; step < n; n *= 2)
{
left = 0;
// 内部分组merge,时间复杂度为O(n)
while (left < n)
{
mid = left + step - 1;
if (mid + 1 >= n)
break;
right = std::max(left + (step * 2) - 1, n - 1);
merge(left, mid, right);
left = right + 1;
}
}
}
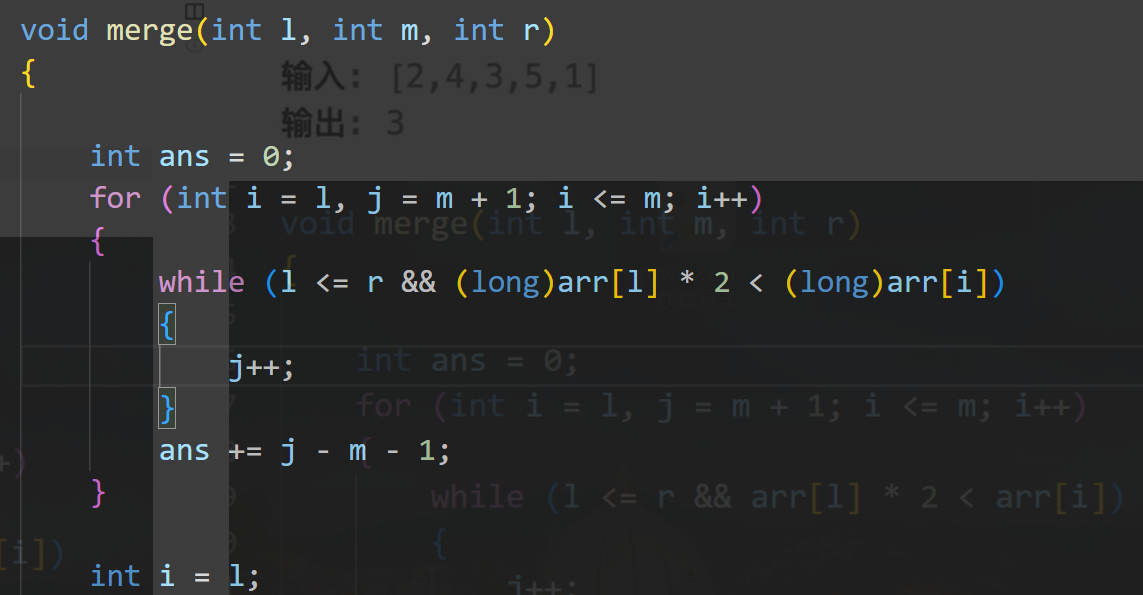
算法讲解022【必备】归并分治
首先考虑是不是可以将问题分解为三部分:左部分的结果+右部分的结果+跨左右的结果,然后考虑分别对左右两部分排序是否有利于结果

小和问题

https://www.nowcoder.com/practice/6dca0ebd48f94b4296fc11949e3a91b8?tpId=196&tqId=40415&ru=/exam/oj
#include <iostream>
#include <stack>
#include <vector>
#include <algorithm>
using std::stack;
using std::vector;
int const max = 501;
static int arr[max];
static int help[max];
static int n = 0; // 实际有多少个数
// 返回arr[l...r]范围上,小和的累加和,同时把arr[l...r]变有序
long smallSum(int left, int right)
{
if (left == right)
{
return 0;
}
int mid = (left + right) / 2;
return smallSum(left, mid) + smallSum(mid + 1, right) + merge(left, mid, right);
}
// 返回跨左右的小和累加和,左侧有序,右侧有序,让左右整体变有序
long merge(int left, int mid, int right)
{
// 统计部分:右侧部分相对于左侧部分的小和(注意此时已经变的有序了)
long ans = 0;
for (int j = mid + 1, i = left, sum = 0; j <= right; j++)
{
while (i <= mid && arr[i] <= arr[j])
{
sum += arr[i++]; // 注意这里不能将ans+=arr[i++],因为有重合的,左边的数可能小于右边的多个数而不是一个数
}
ans += sum;
}
// 正常merge
int i = left;
int a = left;
int b = mid + 1;
while (a <= mid && b <= right)
{
// 谁小我移动谁
help[i++] = arr[a] <= arr[b] ? arr[a++] : arr[b++];
}
while (a <= mid)
{
help[i++] = arr[a++];
}
while (b <= right)
{
help[i++] = arr[b++];
}
for (i = left; i <= right; i++)
{
arr[i] = help[i];
}
return ans;
}
翻转对

https://leetcode.cn/problems/reverse-pairs/description/
算法讲解023【必备】随机快速排序

经典的快速排序
#include <iostream>
#include <vector>
#include <cstdlib> // 需要引入 rand()
#include <ctime> // 需要引入 time()
using std::cout;
using std::endl;
using std::string;
using std::vector;
const int size = 500;
static vector<int> arr(size, 0);
void swap(int pos1, int pos2)
{
int tmp = arr[pos1];
arr[pos1] = arr[pos2];
arr[pos2] = tmp;
}
// 作用:将[l.....a-1] 全部都是<=x [a...r]全是>x,并返回a-1
// 这个函数保持你的逻辑不变
int partition1(int l, int r, int x)
{
int a = l, xi = 0;
// xi为<=x的区域中任何一个位置的x的位置,哪一个都可以
// 但是在代码中我们设置为满足区域中最右边那个数
for (int i = l; i <= r; i++)
{
// <=x时,i++,a++(扩充满足<=的范围)
if (arr[i] <= x)
{
swap(a, i); // 将<=x的数移动到满足的范围的右邻居的那个数
if (arr[a] == x)
{
xi = a;
}
a++;
}
// 当大于x的时:i++
}
// 最优将x移动到a为止
swap(xi, a - 1);
return a - 1;
}
void quickSort(int l, int r)
{
// l == r 只有一个数 不需要排序
// l > r 非法
if (l >= r)
return;
// 【核心修改点】在此处加入随机逻辑
// 1. 在 [l, r] 范围里随机选一个位置
// rand() % (r - l + 1) 会生成 0 到 (r-l) 的随机数
int randIdx = l + rand() % (r - l + 1);
int x = arr[randIdx]; // 现在这里的 x 是随机选择的
int mid = partition1(l, r, x);
quickSort(l, mid - 1);
quickSort(mid + 1, r);
}
荷兰国旗问题优化快排中的partition函数

将等于基准的都一次性的放到中间位置
#include <iostream>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <utility>
using namespace std;
class Solution {
public:
// 寻找第 K 大的元素 (LeetCode 215)
int findKthLargest(vector<int>& nums, int k) {
srand((unsigned)time(NULL));
// 第 K 大,就是在排序数组中下标为 N - K 的元素
return randomizedSelect(nums, nums.size() - k);
}
private:
void swap(vector<int>& arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
// 复用 Partition 逻辑
pair<int, int> partition(vector<int>& arr, int l, int r, int x) {
int first = l - 1;
int last = r + 1;
int i = l;
while (i < last) {
if (arr[i] < x) {
swap(arr, ++first, i++);
} else if (arr[i] > x) {
swap(arr, --last, i);
} else {
i++;
}
}
return {first + 1, last - 1};
}
// 【核心】迭代版选择 (非递归,省空间)
// 只需要找 targetIndex 这个下标的数
int randomizedSelect(vector<int>& arr, int targetIndex) {
int l = 0;
int r = arr.size() - 1;
while (l <= r) {
// 1. 真·随机选 pivot 并交换到头部
int randIdx = l + rand() % (r - l + 1);
int x = arr[randIdx ];
// 2. 划分
pair<int, int> range = partition(arr, l, r, x);
// 3. 判断 targetIndex 在哪个区域,只走一边!
if (targetIndex < range.first) {
// 目标在左边(小于区),下一轮只看左边
r = range.first - 1;
} else if (targetIndex > range.second) {
// 目标在右边(大于区),下一轮只看右边
l = range.second + 1;
} else {
// 目标就在中间(等于区),直接命中!
return x;
}
}
return -1;
}
};
复杂度

算法讲解024【必备】随机选择算法(选择第k大的数)

#include <iostream>
#include <vector>
#include <cstdlib> // for rand()
#include <ctime> // for time()
#include <utility> // for std::pair
using namespace std;
class Solution
{
public:
// 交换函数 (建议直接用 std::swap)
void swap(vector<int> &arr, int i, int j)
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
// 核心:荷兰国旗问题 Partition
// 返回值:std::pair<int, int> 代表 {等于区的左边界, 等于区的右边界}
pair<int, int> partition(vector<int> &arr, int l, int r, int x)
{
int less = l - 1; // 小于区的右边界
int more = r + 1; // 大于区的左边界
int i = l; // 当前指针
while (i < more)
{
if (arr[i] == x)
{
i++;
}
else if (arr[i] < x)
{
// 当前数 < x,发货到小于区,i 前进
swap(arr, ++less, i++);
}
else
{
// 当前数 > x,发货到大于区,i 原地不动(因为换回来的数还没看过)
swap(arr, --more, i);
}
}
// 返回等于区的范围 [less+1, more-1]
return {less + 1, more - 1};
}
int randomizedSelect(vector<int> &arr, int k)
{
int l = 0;
int r = arr.size() - 1;
while (l <= r)
{
// 1. 随机选一个 pivot
// rand() % (r - l + 1) 生成 [0, len-1]
int pivotIndex = l + rand() % (r - l + 1);
int pivotValue = arr[pivotIndex];
// 2. 荷兰国旗划分
// range.first 是等于区左边界,range.second 是等于区右边界
pair<int, int> range = partition(arr, l, r, pivotValue);
// 3. 判断 k 在哪个区域
if (k < range.first)
{
// 命中左边(小于区)
r = range.first - 1;
}
else if (k > range.second)
{
// 命中右边(大于区)
l = range.second + 1;
}
else
{
// 命中中间(等于区),直接返回!
return pivotValue;
}
}
return -1; // Should not reach here
}
int findKthLargest(vector<int> &nums, int k)
{
// 初始化随机种子
srand((unsigned)time(NULL));
// 第 K 大,就是在排序数组中下标为 N - K 的元素
// 注意:这里必须传引用,否则 huge data 会超时
return randomizedSelect(nums, nums.size() - k);
}
};
C++中的堆结构

#include <iostream>
#include <queue>
int main() {
// 默认构造的priority_queue是大根堆
std::priority_queue<int> maxHeap;
maxHeap.push(3);
maxHeap.push(1);
while (!maxHeap.empty()) {
std::cout << maxHeap.top() << " ";
maxHeap.pop();
}
std::cout << std::endl;
return 0;
}
// 自定义比较函数,用于创建小根堆
struct Compare {
bool operator()(int a, int b) {
return a > b;
}
};
int main() {
// 使用std::less构建大根堆
std::priority_queue<int, std::vector<int>, std::less<int>> minHeap;
// 使用自定义比较函数创建小根堆
std::priority_queue<int, std::vector<int>, Compare> minHeap;
}
算法讲解025【必备】堆结构和堆排序

#include <iostream>
#include <vector>
#include <random>
using std::cout;
using std::endl;
using std::string;
using std::vector;
void swap(vector<int>& arr, int pos1, int pos2)
{
int tmp = arr[pos1];
arr[pos1] = arr[pos2];
arr[pos2] = tmp;
}
// i位置的数变大了,向上调整大根堆
void heapInsert(vector<int>& arr, int i)
{
while (i > 1 && arr[i] > arr[(i - 1) / 2]) // 插入节点大于父节点
{
swap(arr, i, (i - 1) / 2); // 子节点和父节点交换
i = (i - 1) / 2; // 下一步检查父节点是否满足要求
}
}
// i位置的数变小了,向下调整为大根堆
void heapify(vector<int>& arr, int i, int size)
{
int l = i * 2 + 1; // 左孩子
while (l < size)
{
int best = l + 1 < size && arr[l + 1] > arr[l] ? l + 1 : l; // 在孩子中挑出最大的
best = arr[best] > arr[i] ? best : i; // 比较父节点和最大的孩子节点谁大
if (best == i)
break;
swap(arr, best, i);
i = best;
l = i * 2 + 1;
}
}
// 1. 从顶到底建立大根堆: O(n *logn)
// 2. 依次弹出堆内最大值并排好序: O(n *logn)
// 总体复杂度:O(n *logn)
void heapSort1(vector<int>& arr)
{
// 1. 首先从顶到底建立大根堆
/*建立的过程:首先查看插入的元素是否大于父节点
如果小于则不干什么,
如果大于,则:交换父子节点,然后递归查看父节点是否大于它的父节点,知道满足位置
*/
for (int i = 0; i < arr.size(); i++)
{
heapInsert(arr, i);
}
// 2. 依次将最后一个元素和第一个元素交换,然后向下调整大根堆
/*
将0位置元素与最后一个元素交换,然后查看0位置元素是否满足要求,
大于父子节点,则满足
小于父子节点,则则交换,然后交换父子节点,逐渐向下已知满足条件
过程:首先是找出子节点中的最大节点和父节点比较
小
大,交换,则去查看子节点是否满足
*/
int size = arr.size();
while (size > 1)
{
swap(arr, 0, --size); // 将最后一个元素和第一个元素交换
heapify(arr, 0, size); // 然后向下调整大根堆
}
}
// 1. 从底到顶建立大根堆: O(n)
// 2. 依次弹出堆内最大值并排好序: O(n *logn)
// 总体复杂度:O(n *logn)
void heapSort2(vector<int>& arr)
{
for (int i = arr.size() - 1; i >= 0; i--)
{
heapify(arr, i, arr.size());
}
int size = arr.size();
while (size > 1)
{
swap(arr, 0, --size); // 将最后一个元素和第一个元素交换
heapify(arr, 0, size); // 然后向下调整大根堆
}
}



算法讲解026【必备】哈希表、有序表和比较器的用法

算法讲解027【必备】堆结构常见题
题目1:合并有序链表
两两合并
class Solution
{
public:
ListNode *mergeTwoLists(ListNode *list1, ListNode *list2)
{
if (list1 == nullptr && list2 == nullptr)
return nullptr;
if (list1 == nullptr)
return list2;
else if (list2 == nullptr)
return list1;
ListNode *p1 = list1;
ListNode *p2 = list2;
ListNode *head, *tail;
if (p1->val > p2->val)
{
head = p2;
p2 = p2->next;
}
else
{
head = p1;
p1 = p1->next;
}
tail = head;
while (p1 && p2)
{
if (p1->val > p2->val)
{
tail->next = p2;
tail = tail->next;
p2 = p2->next;
}
else
{
tail->next = p1;
tail = tail->next;
p1 = p1->next;
}
}
if (p1)
{
tail->next = p1;
}
else if (p2)
{
tail->next = p2;
}
return head;
}
ListNode *mergeKLists(vector<ListNode *> &lists)
{
if (lists.size() == 0)
return nullptr;
if (lists.size() == 1)
return lists[0];
ListNode *preList = mergeTwoLists(lists[0], lists[1]);
if (lists.size() <= 2)
return preList;
int i = 2;
while (i < lists.size())
{
ListNode *oldLise = preList;
preList = mergeTwoLists(oldLise, lists[i++]);
}
return preList;
}
};
使用大顶堆
全部压入节点
时间复杂度是:O(n*longn)
空间复杂度是:O(n)
#include <iostream>
#include <vector>
#include <queue>
class Solution {
public:
struct CompareListNode {
bool operator()(ListNode* elem1, ListNode* elem2) {
return elem1->val > elem2->val;
}
};
ListNode* mergeKLists(std::vector<ListNode*>& lists) {
if (lists.size() == 0)
return nullptr;
if (lists.size() == 1)
return lists[0];
std::priority_queue<ListNode*, std::vector<ListNode*>, CompareListNode> pre;
ListNode* head = nullptr;
ListNode* tail = nullptr;
for (int i = 0; i < lists.size(); ++i) {
ListNode* tmp = lists[i];
if (tmp) {
while (tmp) {
pre.push(tmp);
tmp = tmp->next;
}
}
}
if (pre.size() == 0)
return nullptr;
head = pre.top();
tail = head;
pre.pop();
while (!pre.empty()) {
tail->next = pre.top();
tail = tail->next;
pre.pop();
}
tail->next = nullptr; // 确保链表末尾为nullptr
return head;
}
};
保证堆中节点个数为k个
时间复杂度是:O(n*longk)
空间复杂度是:O(k)
class Solution
{
public:
struct CompareListNode
{
bool operator()(ListNode *elem1, ListNode *elem2)
{
return elem1->val > elem2->val;
}
};
ListNode *mergeKLists(vector<ListNode *> &lists)
{
if (lists.size() == 0)
return nullptr;
if (lists.size() == 1)
return lists[0];
std::priority_queue<ListNode *, vector<ListNode *>, CompareListNode> res;
ListNode *head = nullptr, *tail = nullptr;
// 保证堆中使用只有非空个链表的个数
for (int i = 0; i < lists.size(); i++)
{
if (lists[i]!=nullptr)
{
res.push(lists[i]);
}
}
if (res.size() == 0) // 所有的节点可能都为空
return nullptr;
head = res.top();
tail = head;
res.pop();
if (tail->next != nullptr)
{
res.push(tail->next);
}
while (!res.empty())
{
ListNode *cur = res.top();
tail->next = cur;
tail = tail->next;
res.pop();
if (cur->next != nullptr)
res.push(cur->next);
}
return head;
}
};
题目2:线段最多重合问题
- 任何一个重合区域的左边界,一定是某一个线段的左边界
#include <iostream>
#include <vector>
#include <algorithm>
#include <queue>
#include <functional>
using std::cout;
using std::endl;
using std::vector;
/*
1. 首先先根据每条线段的左边界的进行从小到大的排序
2. 依次比较,建立小根堆,以每条线段的右边界为存储到堆中的元素
3. 从小根堆堆中一次弹出下面的元素 :
堆中的值(右边界) < 要加入的元素的左边界 两条线段不相交
将自己的右边界加入到堆中
每次记录堆中元素的数量的最大值,即为相交线段的最大数量
本质上就是,堆中存储重合的线段。
*/
class Solution
{
public:
// 求重合线段数量的最大值
int maxLineCount(vector<vector<int>> lines)
{
// 1. 已经左边界排序
std::sort(lines.begin(), lines.end(), [](vector<int> elem1, vector<int> elem2)
{ return elem1[0] < elem2[0]; });
// 2. 建立小根堆:存储线段的右边界
std::priority_queue<int, std::vector<int>, std::greater<int>> minHeap;
int res = 0;
for (vector<int> elem : lines)
{
while (!minHeap.empty() && minHeap.top() < elem[0])
{
minHeap.pop();
}
minHeap.push(elem[1]);
res = std::max(res, static_cast<int>(minHeap.size()));
}
return res;
}
};
int main()
{
Solution solution;
vector<vector<int>> lines = {{1, 3}, {2, 4}, {2, 3}, {3, 5}};
int result = solution.maxLineCount(lines);
cout << "重叠线段数量的最大值: " << result << endl;
return 0;
}
题目3:让数组整体累加和减半的最少操作

超时
#include <iostream>
#include <vector>
#include <algorithm>
#include <queue>
#include <functional>
#include <numeric>
using std::cout;
using std::endl;
using std::vector;
class Solution
{
public:
// 贪心
int halveArray(vector<int> &nums)
{
vector<double> nums_d(nums.begin(), nums.end());
int res = 0;
double sum = std::accumulate(nums_d.begin(), nums_d.end(), 0);
double current_sum = sum;
sum /= 2;
do
{
std::sort(nums_d.begin(), nums_d.end());
current_sum -= static_cast<double>(nums_d[nums.size() - 1]) / 2;
nums_d[nums.size() - 1] /= 2;
res++;
} while (sum < current_sum);
return res;
}
};
大根堆
注意double类型
#include <iostream>
#include <vector>
#include <queue>
#include <numeric>
using std::cout;
using std::endl;
using std::vector;
class Solution
{
public:
// 贪心 + 最大堆(优先队列)
int halveArray(vector<int> &nums)
{
std::priority_queue<double> heap;
// 1. 插入堆时直接转double,避免int隐式转换的潜在问题
for (int elem : nums)
heap.push(static_cast<double>(elem));
// 2. 修复:accumulate第三个参数传0.0,强制返回double(避免int溢出/精度丢失)
double total_sum = std::accumulate(nums.begin(), nums.end(), 0.0);
double target = total_sum / 2; // 需要降到的目标和(原和的一半)
double current_sum = total_sum; // 当前数组和
int res = 0;
// 3. 修复:循环条件改为 current_sum > target(逻辑更直观,避免边界误差)
while (current_sum > target)
{
double cur = heap.top();
heap.pop();
// 核心:计算减半后减少的量(cur - cur/2 = cur/2),更新当前和
double reduce = cur / 2;
current_sum -= reduce;
cur /= 2;
heap.push(cur);
res++;
}
return res;
}
};
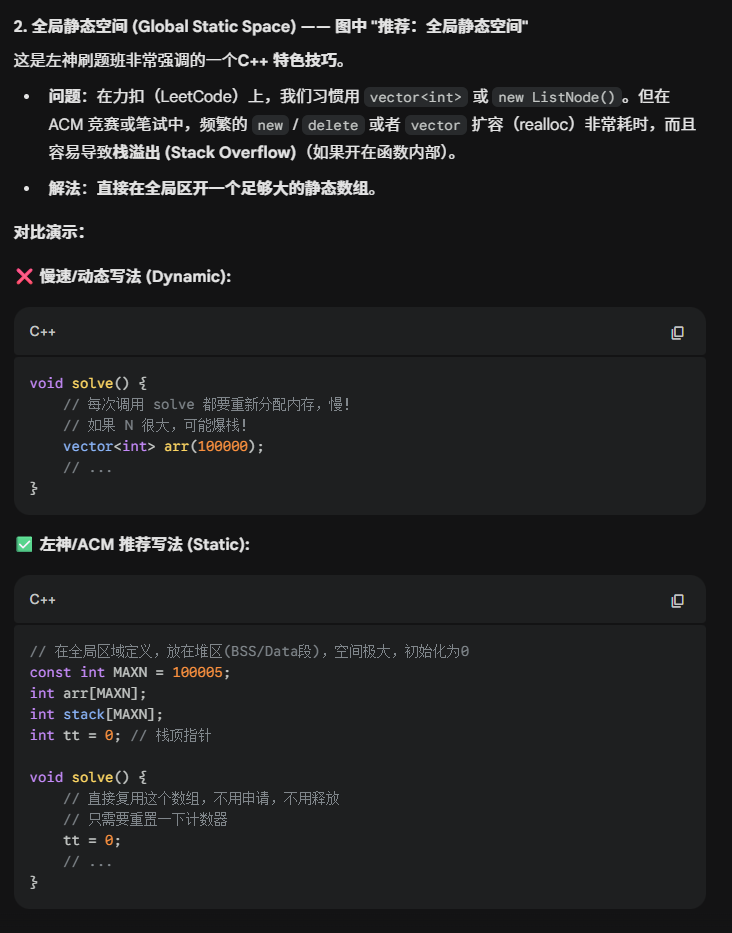
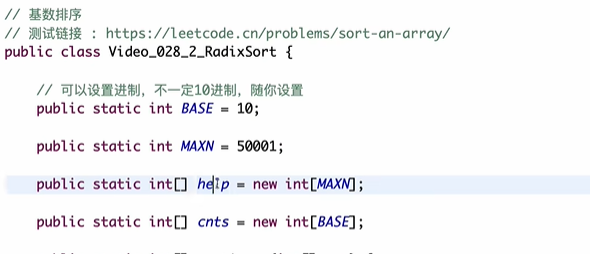
算法讲解028【必备】基数排序

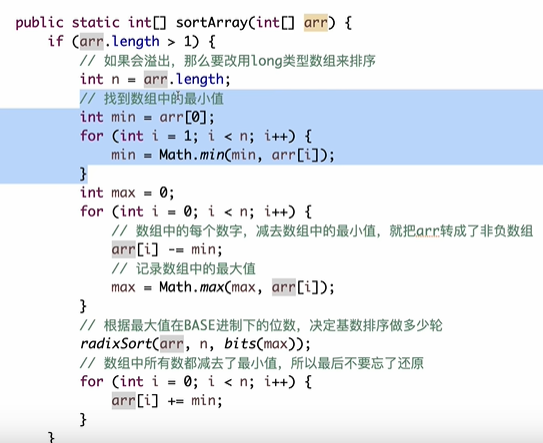

- 遇到负数,就将每个数都加数组中的负数的最大值的绝对值
#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath> // 用于计算位数的log10函数
using std::cout;
using std::endl;
using std::vector;
class Solution
{
public:
// 静态成员变量:BASE表示基数(10进制),MAXN作为help容器的最大初始容量
static int BASE;
static int MAXN;
static vector<int> help; // 基数排序的辅助数组
static vector<int> cnts; // 计数数组(长度等于BASE)
// 核心排序函数:支持负数数组排序
void sortArray(vector<int> &arr)
{
if (arr.empty() || arr.size() == 1) return; // 空数组/单元素直接返回
// 1. 处理负数:将所有数转为非负数(减去最小值)
int min_val = *std::min_element(arr.begin(), arr.end());
for (int &elem : arr) {
elem -= min_val; // 统一偏移,避免负数(这一步才是正确的偏移,而非lambda中修改)
}
// 2. 找到最大值,计算其位数(确定基数排序的轮次)
int max_val = *std::max_element(arr.begin(), arr.end());
int max_bits = getBits(max_val); // 计算最大位数
// 3. 基数排序(处理非负数数组)
radixSort(arr, max_bits);
// 4. 还原偏移,恢复原数值
for (int &elem : arr) {
elem += min_val;
}
}
private:
// 计算一个非负整数的位数(核心缺失函数)
int getBits(int num) {
if (num == 0) return 1; // 0的位数是1
int bits = 0;
while (num > 0) {
bits++;
num /= BASE;
}
return bits;
// 也可以用数学方式:return static_cast<int>(log10(num)) + 1;(需包含<cmath>)
}
// 基数排序核心逻辑(arr为非负数数组,bits为最大位数)
void radixSort(vector<int> &arr, int bits)
{
int n = arr.size();
// 动态调整辅助数组大小,避免越界/浪费内存
if (help.size() < n) {
help.resize(n, 0);
}
// 计数数组长度固定为BASE(10),提前清空
cnts.assign(BASE, 0);
// 按每一位进行排序(从低位到高位)
for (int offset = 1; bits > 0; offset *= BASE, bits--)
{
// 1. 统计当前位的数字出现次数
std::fill(cnts.begin(), cnts.end(), 0); // 重置计数数组
for (int i = 0; i < n; i++) {
int digit = (arr[i] / offset) % BASE; // 获取当前位的数字
cnts[digit]++;
}
// 2. 计算前缀和(确定每个数字的最后位置)
// 正确的前缀和计算:从1开始,避免越界
for (int i = 1; i < BASE; i++) {
cnts[i] += cnts[i - 1];
}
// 3. 逆序遍历,保证稳定性
for (int i = n - 1; i >= 0; i--) {
int digit = (arr[i] / offset) % BASE;
help[--cnts[digit]] = arr[i]; // 先减1再赋值,定位到正确位置
}
// 4. 复制回原数组
for (int i = 0; i < n; i++) {
arr[i] = help[i];
}
}
}
};
// 静态成员变量初始化
int Solution::BASE = 10; // 10进制基数
int Solution::MAXN = 100000; // 辅助数组最大初始容量
vector<int> Solution::help(Solution::MAXN, 0); // 初始化为10万长度,后续动态调整
vector<int> Solution::cnts(Solution::BASE, 0); // 计数数组长度固定为BASE(10)
// 测试代码
int main() {
Solution sol;
vector<int> arr = {5, -2, 9, 1, -7, 3, 0};
cout << "排序前:";
for (int num : arr) {
cout << num << " ";
}
cout << endl;
sol.sortArray(arr);
cout << "排序后:";
for (int num : arr) {
cout << num << " ";
}
cout << endl; // 输出:-7 -2 0 1 3 5 9
return 0;
}
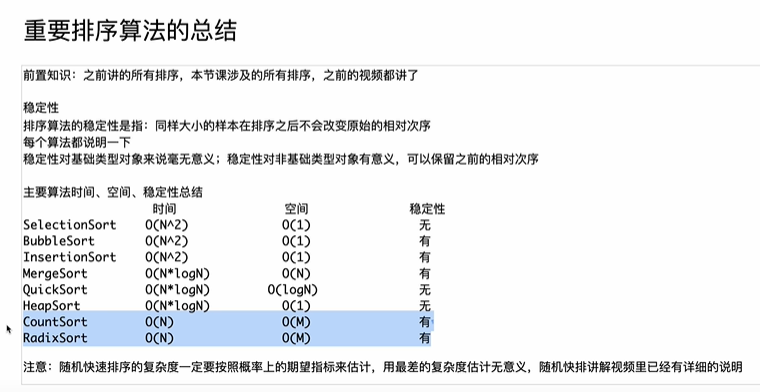
算法讲解029【必备】重要排序算法的总结

算法讲解030【必备】异或运算的骚操作

第四个运算的性质:
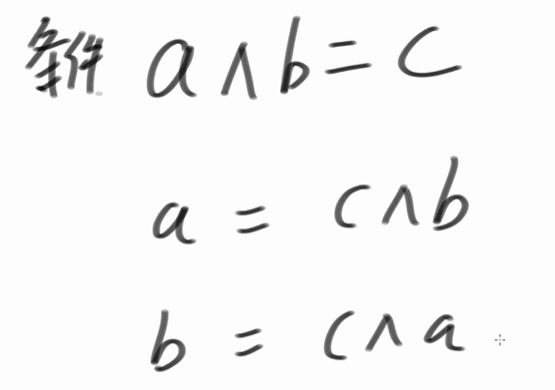

- 将白球看成0,黑球看成1

交换两个数

void swap(int &a, int &b)
{
a = a ^ b;
b = a ^ b;
a = a ^ b;
}
易错:

求最大值

#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath> // 用于计算位数的log10函数
using std::cout;
using std::endl;
using std::vector;
class Solution
{
public:
// 翻转:1变0,0变1
int flip(int n)
{
return n ^ 1;
}
// 提取符号:非负数(>=0)返回1,负数(<0)返回0
int sign(int n)
{
// C++ 中必须转 unsigned 来模拟 Java 的 >>>
// 注意C++中的右移都是有符号右移的
// 有符号右移:正数补0,负数补1
// 无符号右移:正数,负数都是补0
// n转无符号右移31位:非负数变0,负数变1。然后再flip翻转。
return flip((unsigned)n >> 31);
}
// 有溢出风险的实现
/*
假设 a 是非常大的正数(如 21亿),b 是非常小的负数(如 -21亿)。
*/
int getMax1(int a, int b)
{
int c = a - b;
// 如果 c 是非负数(a >= b),returnA 是 1
// 如果 c 是负数(a < b),returnA 是 0
int returnA = sign(c);
int returnB = flip(returnA);
return a * returnA + b * returnB;
}
// 没有任何问题的实现
int getMax2(int a, int b)
{
int c = a - b;
int sa = sign(a); // a的符号:a>=0为1,a<0为0
int sb = sign(b); // b的符号
int sc = sign(c); // c的符号
// 判断A与B符号是否不一样:diff = 1 表示 a 和 b 符号不一致;diff = 0 表示符号一致
int diff = sa ^ sb;
// 判断A与B符号是否一样:same = 1 表示 a 和 b 符号一致;same = 0 表示符号不一致
int same = flip(diff);
// 核心决断:什么时候我们应该返回 a ?(即让 returnA = 1)
// diff * sa: 条件 1:a 和 b 符号不同 (diff == 1),且 a 是非负数 (sa == 1) -> 此时 a 肯定比 b 大
// same * sc: 条件 2:a 和 b 符号相同 (same == 1),且 a - b >= 0 (sc == 1) -> 不会溢出,可以直接看 c 的符号
// 这两个条件是互斥的,所以可以用加法代替逻辑或 (||)
int returnA = diff * sa + same * sc;
int returnB = flip(returnA); // a 不选,自然就选 b
return a * returnA + b * returnB;
}
};
int main()
{
return 0;
}
找到缺失的数字


#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath> // 用于计算位数的log10函数
using std::cout;
using std::endl;
using std::vector;
class Solution
{
public:
int missingNumber(vector<int> &nums)
{
int eorAll = 0, eorHas = 0;
for (int i = 0; i < nums.size(); i++)
{
eorAll ^= i;
eorHas ^= nums[i];
}
eorAll ^= nums.size();
return eorAll ^ eorHas;
}
};
只出现一次的数字

#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath> // 用于计算位数的log10函数
using std::cout;
using std::endl;
using std::vector;
class Solution
{
public:
int singleNumber(vector<int> &nums)
{
int eor = 0;
for (int elem : nums)
{
eor ^= elem;
}
return eor;
}
};
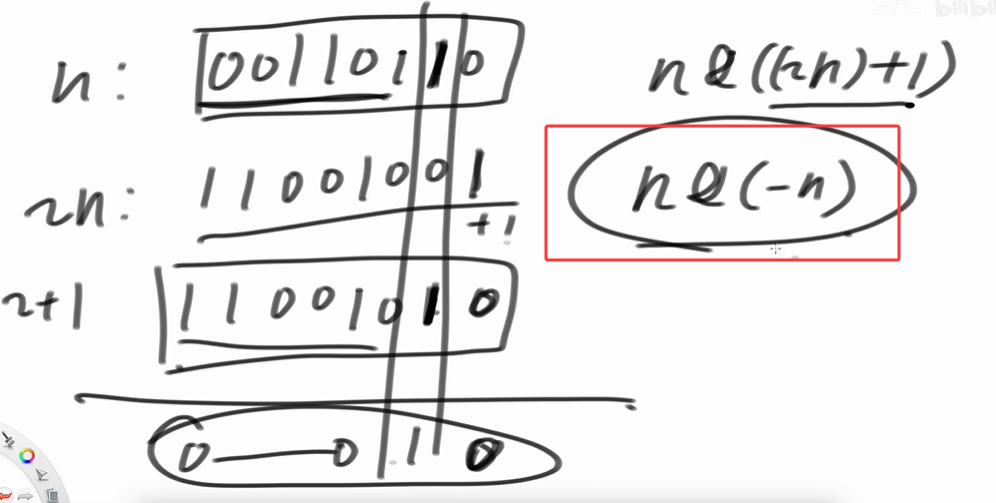
得到最右侧的1
只出现一次的数字III


#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath> // 用于计算位数的log10函数(注:此处实际未使用)
using std::cout;
using std::endl;
using std::vector;
class Solution
{
public:
vector<int> singleNumber(vector<int> &nums)
{
// 第一步:计算所有数的异或结果,最终得到 a ^ b
int eor1 = 0;
for (int num : nums)
{
eor1 ^= num;
} // eor1 = a^b
// 关键修复:转换为unsigned int避免溢出,再提取最右侧的1
unsigned int u_eor1 = static_cast<unsigned int>(eor1);
// 关键操作:提取eor1二进制中最右侧的1,a与b这一位一定是不同的
// 原理:负数在计算机中以补码形式存在(原码取反+1)
// 例如:6(0110) 的负数是 -6(1010),6 & -6 = 2(0010)
unsigned int rightOne = u_eor1 & (-u_eor1);
// 转回int不影响位判断,仅用于与num(int)做按位与
// 第二步:根据rightOne位将数组分组异或
int mask = static_cast<int>(rightOne);
int eor2 = 0;
for (int num : nums)
{
// 筛选出该位为0的数,异或后得到其中一个目标数
// 根据这一位分为包含a的集合(a的个数为奇数,其余数的个数为偶数),包含b的集合
if ((mask & num) == 0)
eor2 ^= num; // 其中的一个集合异或之后就是a或者b
}
// eor1 = a ^ b,所以另一个数 = eor1 ^ eor2
vector<int> res{eor2, eor1 ^ eor2};
return res;
}
};
//
只出现一次的数字II
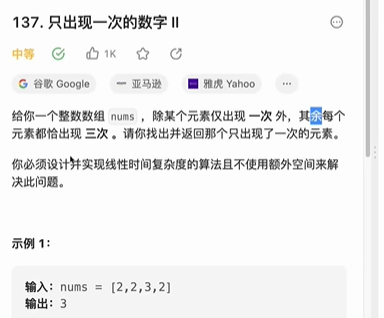


#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath> // 用于计算位数的log10函数(注:此处实际未使用)
using std::cout;
using std::endl;
using std::vector;
class Solution
{
public:
int singleNumber(vector<int> &nums)
{
return find(nums, 3);
}
int find(vector<int> &nums, int m)
{
// cnt[i]:第i位有多少个1
vector<int> cnts(32, 0);
for (int num : nums)
{
for (int i = 0; i < 32; i++)
{
cnts[i] += (num >> i) & 1;
}
}
int ans = 0;
for (int i = 0; i < 32; i++)
{
if (cnts[i] % m != 0) // 第i位上有1
{
ans |= (1 << i); // 将1左移i位,或上ans第i位上的0,将其赋为1
}
}
return ans;
}
};
算法讲解031【必备】位运算的骚操作


2的幂的判断
思想是,二进制位只有一个1
#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath> // 用于计算位数的log10函数(注:此处实际未使用)
using std::cout;
using std::endl;
using std::vector;
class Solution
{
public:
bool isPowerOfTwo(int num)
{
return num > 0 && (num & (-num)) == num;
}
};
3的幂的判断


def isPowerOfThree(n):
# 前置判断:排除0和负数
if n <= 0:
return False
# 循环除以3,直到无法整除
while n % 3 == 0:
n = n // 3 # 用整数除法,避免浮点数精度问题
# 最终只剩1则是3的幂
return n == 1
返回最小2次幂
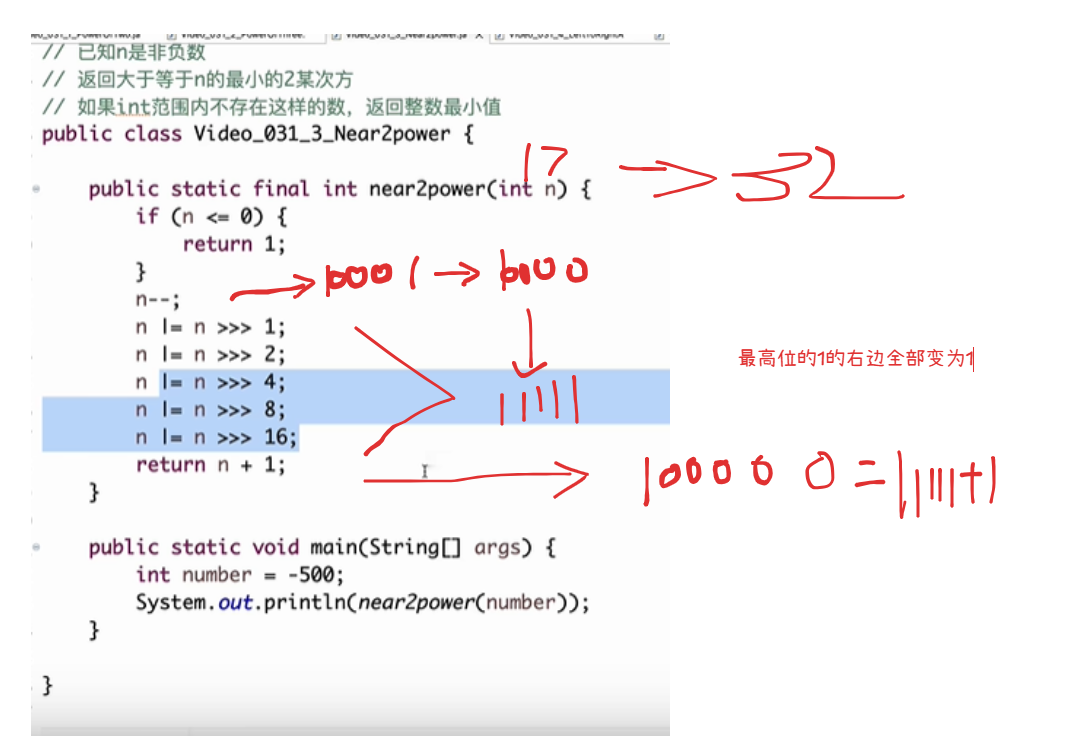
数字范围按位与

暴力
class Solution {
public:
int rangeBitwiseAnd(int left, int right) {
if (left == right)
return left;
int res = left;
// 循环条件改为 left < right,避免多算 right+1
while (left < right) {
left++; // 先自增到下一个数
res &= left; // 再按位与
}
return res;
}
};
按位与
// right &(right-1)实际上就是减去right二进制位中的1,所以下面的时间复杂度就是进行right的位数次
class Solution {
public:
int rangeBitwiseAnd(int left, int right) {
while (left < right) {
right -= (right & -right);
}
return right;
}
};
反转二进制的状态(逆序)
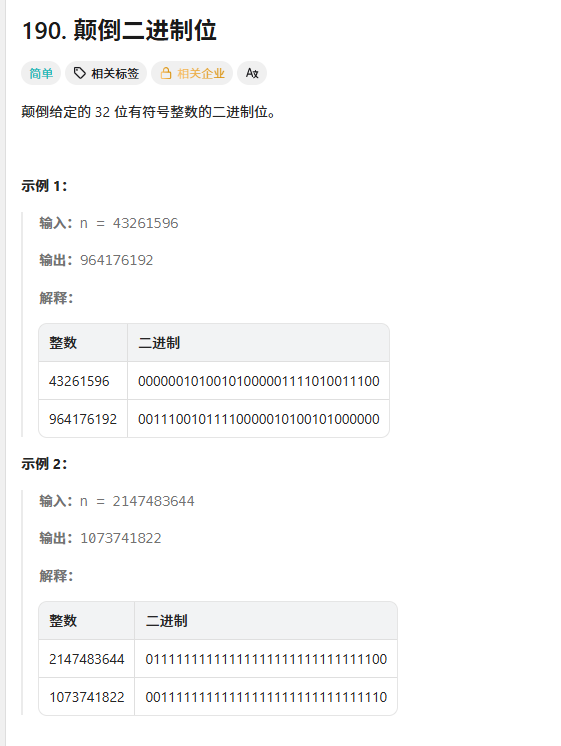
#include <cstdint> // 用于uint32_t类型
class Solution {
public:
uint32_t reverseBits(uint32_t n) { // 用uint32_t表示32位无符号整数
uint32_t res = 0;
// 必须循环32次,确保处理所有位(包括0)
for (int i = 0; i < 32; ++i) {
// 1. 取出n的最低位(原数的第i位)
uint32_t bit = n & 1;
// 2. 将该位放到res的对应反转位置(31-i位)
res |= (bit << (31 - i));
// 3. n右移1位,处理下一位
n >>= 1;
}
return res;
}
};
大牛思路



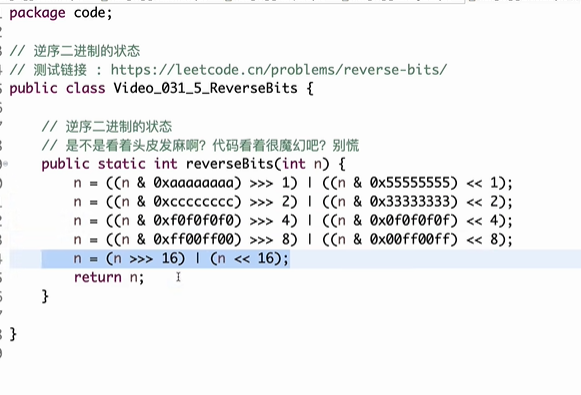
返回n的二进制中1的个数
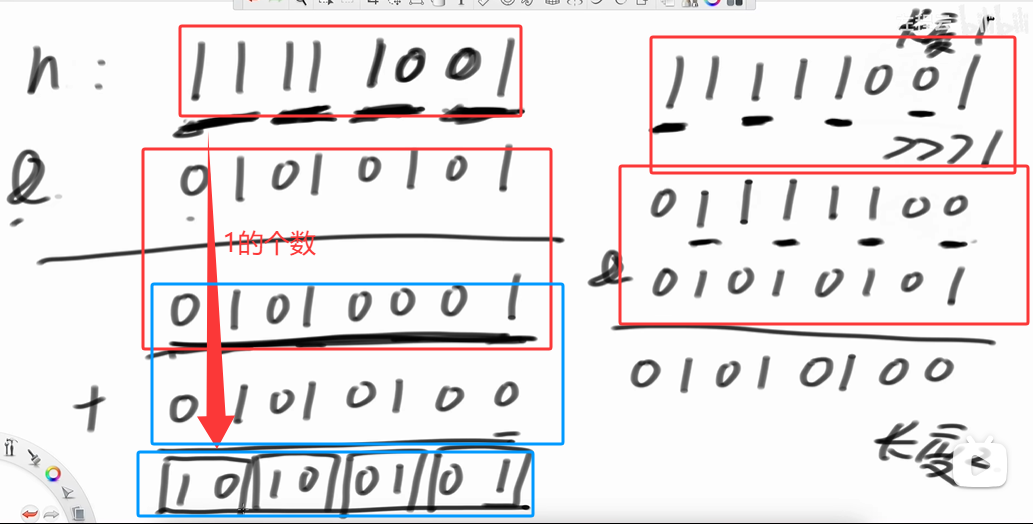
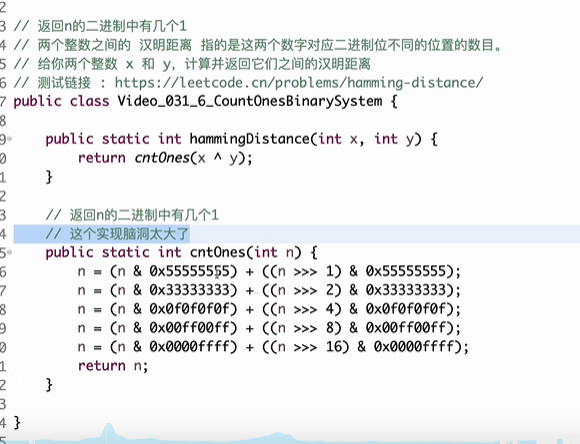
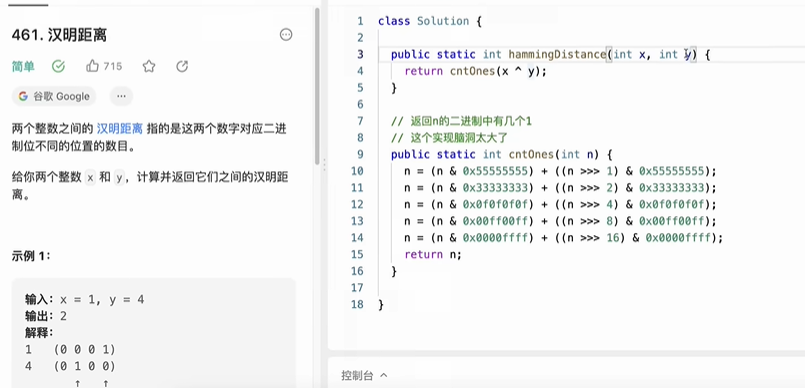
算法讲解032【必备】位图
#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath> // 用于计算位数的log10函数(注:此处实际未使用)
using std::cout;
using std::endl;
using std::vector;
class Bitset
{
public:
Bitset(int n)
{
// a/b 如果结果想向上取整,可以写成:(a+b-1)/b 前提:a和b都是非负数
set.resize((n + 31) / 32);
}
void add(int num)
{
set[num / 32] != 1 << (num % 32);
}
void remove(int num)
{
set[num / 32] &= ~(1 << (num % 32));
}
void reverse(int num)
{
set[num / 32] ^= 1 << (num % 32);
}
bool contains(int num)
{
return ((set[num / 32] >> (num % 32)) & 1) == 1;
}
private:
vector<int> set;
};
算法讲解033【必备】位运算实现加减乘除

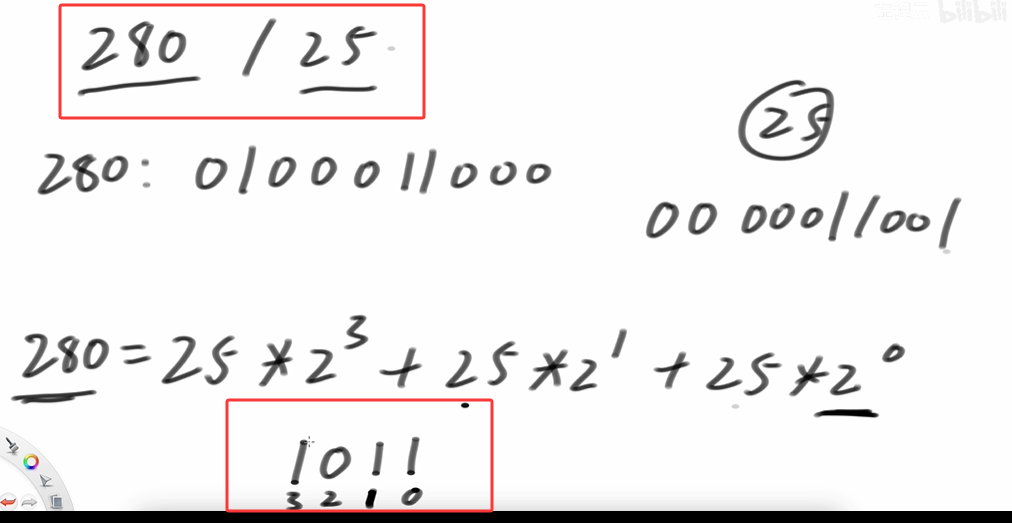

#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath> // 用于计算位数的log10函数(注:此处实际未使用)
using std::cout;
using std::endl;
using std::vector;
// 注意这里不能出现 +,-符号
class Bitset
{
public:
// 位运算的加法: 先无进位相加(异或),再相与并左移1位,不断重复以上步骤指导与的结果为0
int add(int a, int b)
{
int ans = 0;
while (b != 0)
{
ans = a ^ b; // 无进位的结果
b = (a & b) << 1; // 进位的结果
a = ans;
}
return ans;
}
// 求一个数的相反数: 这个数取反+1
int neg(int n)
{
return add(~n, 1);
}
int sub(int a, int b)
{
return add(a, neg(b));
}
int mul(int a, int b)
{
int ans = 0;
while (b != 0)
{
if ((b & 1) != 0) // 当前需要加a吗
{
ans = add(ans, a);
}
a <<= 1; // a左移
b = (unsigned int)b >> 1; // 无符号向右移动
}
return ans;
}
// 除法的完整运算
int Div(int a, int b)
{
int MIN = INT32_MAX;
if (a == MIN && b == MIN)
{
return 1;
}
if (a != MIN && b != MIN)
{
return div(a, b);
}
if (b == MIN)
return 0;
if (b == neg(1))
{
return INT32_MAX;
}
// a是整数最小,b不是整数最小,b也不是-1,a不能转化为其绝对值 a < 0 ? neg(a) : a;
a = add(a, b > 0 ? b : neg(b)); // 此时a就不是整数最小了
int ans = div(a, b);
int offset = b > 0 ? neg(1) : 1;
return add(ans, offset);
}
// 必须保证a和b都不是整数的最小值,因为整数最小值转化不了其绝对值的形式,neg
int div(int a, int b)
{
int x = a < 0 ? neg(a) : a;
int y = b < 0 ? neg(b) : a;
int ans = 0;
for (int i = 30; i >= 0; i = sub(i, 1))
{
if ((x >> i) >= y) // 注意这里是x右移i位,因为y左移30位可能会溢出
{
ans != (1 << i);
x = sub(x, y << i);
}
}
return a < 0 ^ b < 0 ? neg(ans) : ans;
}
};
整数最小值不能求其绝对值。
算法讲解034【必备】链表高频题目和必备技巧


相交链表

暴力法
class Solution
{
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB)
{
for (ListNode *p1 = headA; p1 != nullptr; p1 = p1->next)
{
for (ListNode *p2 = headB; p2 != nullptr; p2 = p2->next)
{
if (p1 == p2)
return p1;
}
}
return nullptr;
}
};
快慢指针
class Solution
{
public:
// 让指针最长的链表上先走节点数量差异个步数
// 然后两个指针同时走,相交的节点一定会相遇,不相交的a会走到null
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB)
{
if (headA == nullptr || headB == nullptr)
return nullptr;
ListNode *a = headA;
ListNode *b = headB;
int diff = 0;
while (a)
{
a = a->next;
diff++;
}
while (b)
{
b = b->next;
diff--;
}
// 下面统一:a是最长的节点
if (diff > 0)
{
a = headA;
b = headB;
}
else
{
diff = -diff;
a = headB;
b = headA;
}
// 长链表a先走diff步
while (diff-- > 0)
{
a = a->next;
}
while (a != b)
{
a = a->next;
b = b->next;
}
return a;
}
};
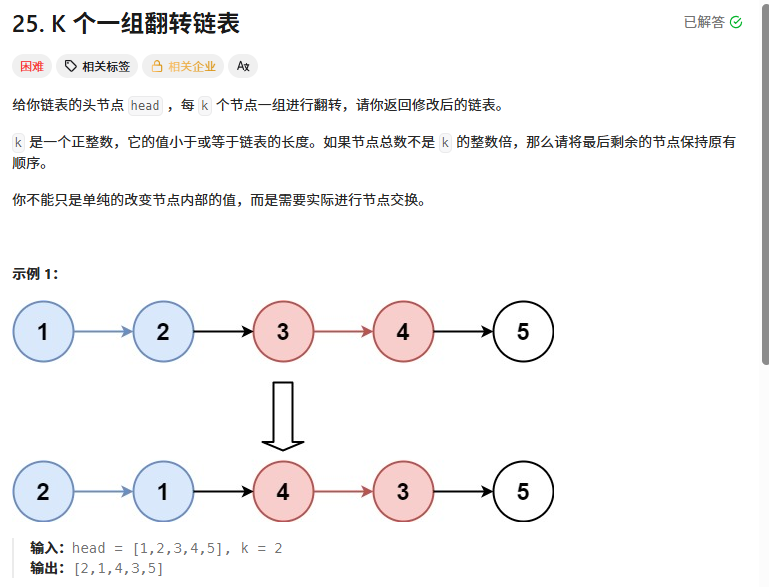
k个一组翻转链表
#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath>
using std::cout;
using std::endl;
using std::vector;
struct ListNode
{
int val;
ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};
class Solution
{
public:
ListNode *reverseKGroup(ListNode *head, int k)
{
ListNode *start = head;
ListNode *end = teamEnd(start, k);
if (end == nullptr)
return head;
// 第一组很特殊,因为牵扯到换头的问题
head = end;
reverse(start, end);
// 翻转之后start变成上一组的结尾节点
ListNode *lastTeamEnd = start;
while (lastTeamEnd->next != nullptr)
{
start = lastTeamEnd->next;
end = teamEnd(start, k);
if (end == nullptr)
return head;
reverse(start, end);
lastTeamEnd->next = end;
lastTeamEnd = start;
}
return head;
}
// 当前组的开始节点是s,往下数k个找到当前组的结束节点返回
ListNode *teamEnd(ListNode *s, int k)
{
while (--k != 0 && s != nullptr)
s = s->next;
return s;
}
// 1-》2-》3-》4-》5-》6 其中s=1 e=3
// 3-》2-》1-》4-》5-》6
void reverse(ListNode *s, ListNode *e)
{
e = e->next;
ListNode *pre = nullptr, *cur = s, *next = nullptr;
while (cur != e)
{
next = cur->next;
cur->next = pre;
pre = cur;
cur = next;
}
s->next = e;
}
};
随机链表的复制

容器的方法
class Solution
{
public:
Node *copyRandomList(Node *head)
{
if (head == nullptr)
return nullptr;
// 建立原节点 -> 新节点的映射
std::map<Node *, Node *> old_new;
Node *cur = head;
// 第一步:先复制所有节点的值,建立映射关系(只创建节点,不处理指针)
while (cur != nullptr)
{
old_new[cur] = new Node(cur->val);
cur = cur->next;
}
// 第二步:处理 next 和 random 指针
cur = head;
while (cur != nullptr)
{
// 新节点的 next 指向 原节点next 对应的新节点
// old_new[cur]是目前cur在新链表中所对应的节点
old_new[cur]->next = old_new[cur->next];
// 新节点的 random 指向 原节点random 对应的新节点
old_new[cur]->random = old_new[cur->random];
cur = cur->next;
}
// 返回新链表的头节点
return old_new[head];
}
};
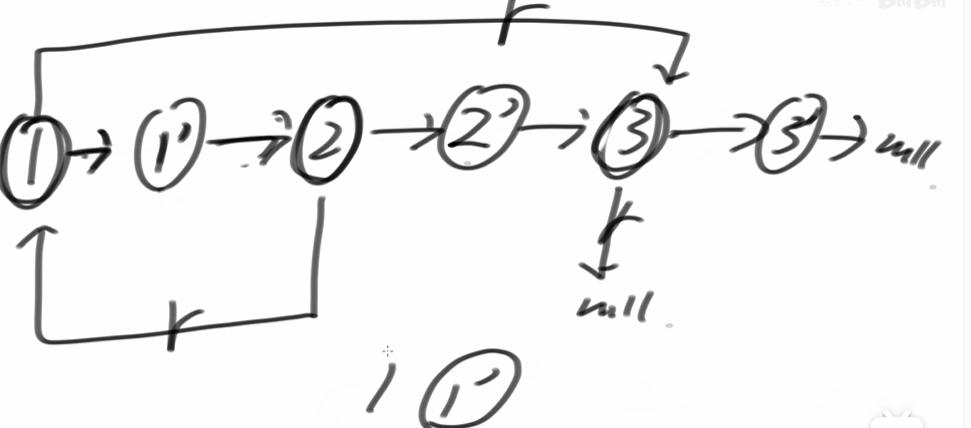
非容器方法
class Solution
{
public:
Node *copyRandomList(Node *head)
{
if (head == nullptr)
return nullptr;
Node *cur = head;
Node *next = nullptr;
// 第一步:复制节点并插入到原节点后面(原1->复1->原2->复2)
while (cur != nullptr)
{
next = cur->next; // 保存原节点的下一个节点
Node *newNode = new Node(cur->val); // 创建复制节点
cur->next = newNode; // 原节点指向复制节点
newNode->next = next; // 复制节点指向原节点的下一个节点
cur = next; // 移动到下一个原节点
}
// 第二步:设置复制节点的random指针
cur = head;
while (cur != nullptr)
{
next = cur->next; // next 是当前原节点对应的复制节点
// 关键:先判断原节点的random是否为空,避免空指针访问
if (cur->random != nullptr)
{
// 复制节点的random = 原节点random的下一个节点(即原random的复制节点)
next->random = cur->random->next;
}
else
{
next->random = nullptr; // 原节点random为空,复制节点也为空
}
cur = next->next; // 移动到下一个原节点
}
// 第三步:拆分链表,提取复制节点形成新链表
cur = head;
Node *newHead = head->next; // 新链表的头节点是第一个复制节点
Node *newCur = newHead; // 遍历新链表的指针
while (cur != nullptr)
{
next = cur->next; // next 是当前原节点的复制节点
cur->next = next->next; // 恢复原链表的next指针(原节点指向原节点)
cur = cur->next; // 移动到下一个原节点
// 处理复制节点的next:如果不是最后一个复制节点,指向后续复制节点
if (cur != nullptr)
{
newCur->next = cur->next;
}
else
{
newCur->next = nullptr; // 最后一个复制节点的next置空
}
newCur = newCur->next; // 移动到下一个复制节点
}
return newHead;
}
};
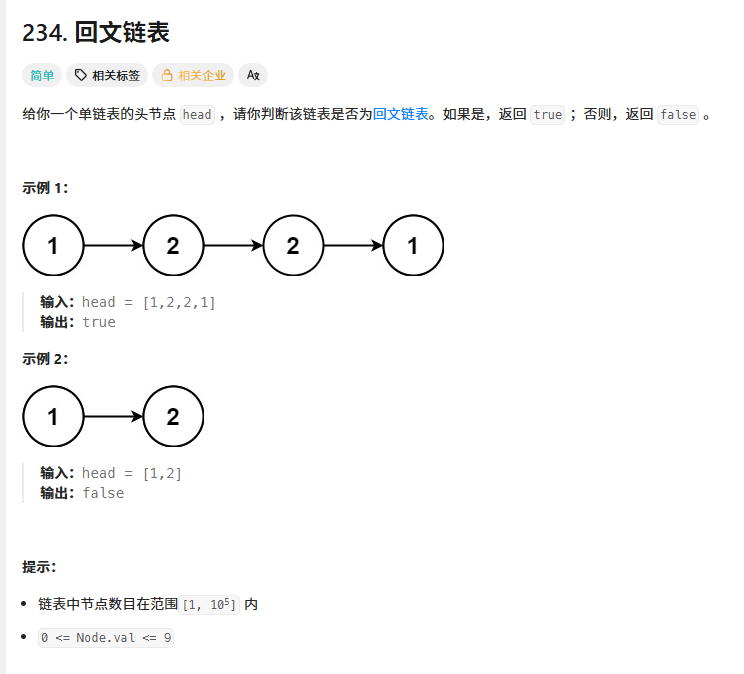
判断链表是否是回文结构
容器的方法
- 两次遍历,栈和第二次遍历比较
class Solution
{
public:
bool isPalindrome(ListNode *head)
{
if (head == nullptr)
return true;
std::stack<ListNode *> sta;
ListNode *ptr = head;
while (ptr)
{
sta.push(ptr);
ptr = ptr->next;
}
ptr = head;
while (!sta.empty())
{
ListNode *elem = sta.top();
sta.pop();
if (elem->val != ptr->val)
return false;
ptr = ptr->next;
}
return true;
}
};
快慢指针
- 技巧:两个指针同时从头节点出发,快指针每次走两步,慢指针每次走一步,当快指针到达终点的时候,慢指针到达中间节点
#include <iostream>
#include <stack>
using std::cout;
using std::endl;
// 首先定义ListNode结构体(链表节点)
struct ListNode
{
int val;
ListNode *next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode *next) : val(x), next(next) {}
};
class Solution
{
public:
/*
1. 快慢指针,慢指针到达中点(前半段最后一个节点)
2. 反转后半段链表
3. 两端指针向中间节点开始比较
4. 恢复原链表
*/
bool isPalindrome(ListNode *head)
{
if (head == nullptr || head->next == nullptr)
return true; // 空链表或单个节点都是回文
ListNode *slow = head, *fast = head;
// 1. 快慢指针找中点(慢指针停在左半段最后一个节点)
// 循环条件:fast->next != nullptr && fast->next->next != nullptr
// 这样能保证:
// - 偶数长度:slow停在第n/2个节点(左半段最后一个)
// - 奇数长度:slow停在中间节点的前一个
while (fast->next != nullptr && fast->next->next != nullptr)
{
slow = slow->next;
fast = fast->next->next;
}
// 2. 反转后半段链表(从slow->next开始)
ListNode *second_half_head = reverseList(slow->next);
ListNode *second_half_copy = second_half_head; // 保存反转后的头,用于恢复
// 3. 两端指针向中间比较
ListNode *left = head;
ListNode *right = second_half_head;
bool is_pal = true;
while (right != nullptr) // 后半段更短(奇数长度时),用right作为终止条件
{
if (left->val != right->val)
{
is_pal = false;
break; // 发现不相等,提前退出,但仍要恢复链表
}
left = left->next;
right = right->next;
}
// 4. 恢复原链表(关键:避免修改原链表结构)
slow->next = reverseList(second_half_copy);
return is_pal;
}
private:
// 辅助函数:反转链表(经典迭代法)并且返回新链表的头节点
ListNode *reverseList(ListNode *head)
{
ListNode *prev = nullptr;
ListNode *curr = head;
while (curr != nullptr)
{
ListNode *next_temp = curr->next; // 保存下一个节点
curr->next = prev; // 反转当前节点指针
prev = curr; // prev后移
curr = next_temp; // curr后移
}
return prev; // 反转后的头节点
}
};
考研题
- 类似思路
入环节点的确定
容器方法
快慢指针
- 一个走一步,一个走两步。根据快指针是否为null确定是否有环
- 节点位置,此时慢指针从头节点开始,快指针从相遇处开始,都各走一步,再次相遇时就为环节点
链表上排序
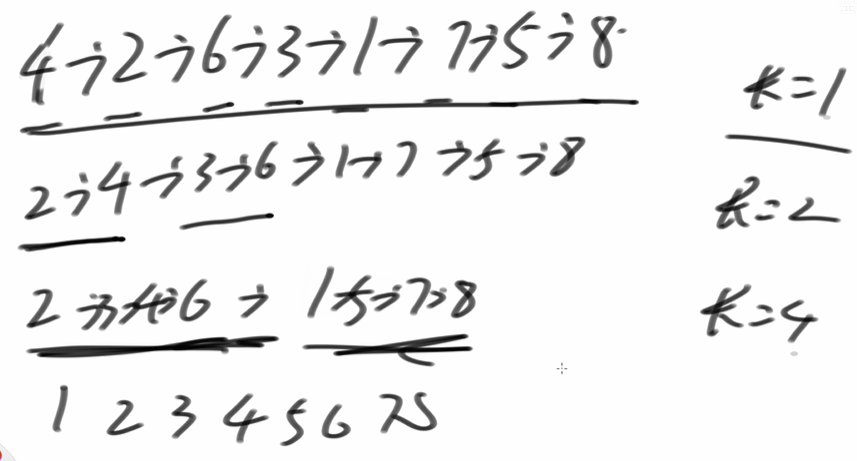
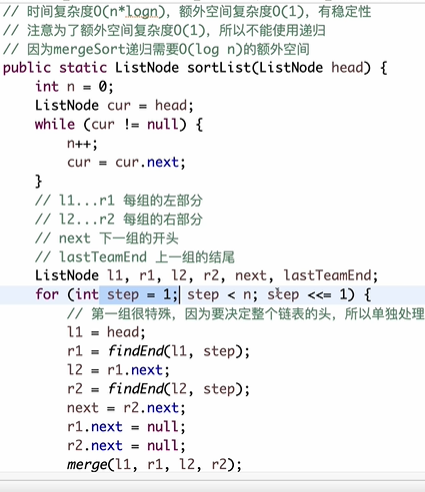
#include <iostream>
using namespace std;
struct ListNode {
int val;
ListNode *next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode *next) : val(x), next(next) {}
};
class Solution {
public:
ListNode* sortList(ListNode* head) {
if (head == nullptr || head->next == nullptr) return head;
// 1. 统计链表总长度 n (对应左神截图里的代码)
int n = 0;
ListNode* cur = head;
while (cur != nullptr) {
n++;
cur = cur->next;
}
// 使用哨兵节点,方便处理头节点改变的情况
ListNode dummy(0);
dummy.next = head;
// 2. 步长 step 依次为 1, 2, 4, 8...
for (int step = 1; step < n; step <<= 1) {
ListNode* prev = &dummy; // prev 用于连接合并后的各个子链表
cur = dummy.next; // cur 用于遍历整个链表
while (cur != nullptr) {
// 第一部分:切出长度为 step 的左链表
ListNode* left = cur;
ListNode* right = split(left, step);
// 第二部分:切出长度为 step 的右链表,cur 指向下一组的开头
cur = split(right, step);
// 第三部分:合并 left 和 right,并把合并后的整段挂在 prev 后面
// merge 函数返回的是合并后链表的【尾节点】,方便下一组继续挂接
prev = merge(left, right, prev);
}
}
return dummy.next;
}
private:
// 辅助函数 1:从 head 开始,切出长度为 step 的一段。
// 断开连接,并返回剩下链表的头节点。
ListNode* split(ListNode* head, int step) {
if (head == nullptr) return nullptr;
// 往前走 step - 1 步,找到这部分的尾巴
for (int i = 1; i < step && head->next != nullptr; i++) {
head = head->next;
}
// 切断,并保留右边剩下的部分
ListNode* right = head->next;
head->next = nullptr; // 【关键】断开连接
return right;
}
// 辅助函数 2:合并两个有序链表 l1 和 l2,接在 prev 的后面。
// 返回合并后链表的最后一个节点(尾节点)。
ListNode* merge(ListNode* l1, ListNode* l2, ListNode* prev) {
ListNode* cur = prev;
// 经典的合并逻辑
while (l1 != nullptr && l2 != nullptr) {
if (l1->val <= l2->val) {
cur->next = l1;
l1 = l1->next;
} else {
cur->next = l2;
l2 = l2->next;
}
cur = cur->next;
}
// 谁没挂完,直接全挂上去
if (l1 != nullptr) cur->next = l1;
else if (l2 != nullptr) cur->next = l2;
// 【关键】让 cur 一直走到新合并链表的最后面,作为尾巴返回
while (cur->next != nullptr) {
cur = cur->next;
}
return cur;
}
};
算法讲解035【必备】数据结构设计高频题


SetAll

#include <iostream>
using namespace std;
struct ListNode
{
int val;
ListNode *next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode *next) : val(x), next(next) {}
};
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
// 泛型设计:K 是 Key 的类型,V 是 Value 的类型
template <typename K, typename V>
class SetAllHashMap
{
private:
// 内部节点:把 value 和时间戳绑定在一起
struct Node
{
V value;
long long time;
// 默认构造
Node() : time(-1) {}
// 带参构造
Node(V v, long long t) : value(v), time(t) {}
};
unordered_map<K, Node> map; // 底层哈希表
long long timeCounter; // 全局时钟(发号器)
V setAllValue; // 记录 setAll 的值
long long setAllTime; // 记录发生 setAll 的时间点
public:
// 构造函数初始化
SetAllHashMap()
{
timeCounter = 0;
setAllTime = -1; // 初始状态,还没发生过 setAll
}
// O(1)
void put(K key, V value)
{
// 存入当前值,并打上当前的时间戳,然后时间戳自增
map[key] = Node(value, timeCounter++);
}
// O(1)
void setAll(V value)
{
// 核心:不遍历 map!只更新全局变量和全局时间戳
setAllValue = value;
setAllTime = timeCounter++;
}
// O(1)
// C++ 中为了处理 key 不存在的情况,通常通过引用/指针带出结果,返回 bool 表达是否成功
bool get(K key, V &outValue)
{
// 1. 如果 map 里根本没这个 key,直接返回 false
if (map.find(key) == map.end())
{
return false;
}
// 2. 拿出这个 key 对应的节点
Node node = map[key];
// 3. PK 时间戳!
if (node.time > setAllTime)
{
// key 的时间戳更新,说明它是 setAll 之后单独 put 进来的
outValue = node.value;
}
else
{
// key 的时间戳太老了,已经被 setAll 覆盖了
outValue = setAllValue;
}
return true;
}
};
实现LRU结构
#include <iostream>
#include <list>
#include <unordered_map> // 用unordered_map效率更高,map也可以
using namespace std;
// LRU缓存:核心是「哈希表 + 双向链表」
// 双向链表:存储(key, value),头部是最近使用的,尾部是最久未使用的
// 哈希表:key -> 链表迭代器,用于快速查找节点
// 以后不要在使用指针,使用迭代器替代指针
class LRUCache
{
private:
int _capacity; // 缓存容量
list<pair<int, int>> _cacheList; // 双向链表:存储(key, value)
unordered_map<int, list<pair<int, int>>::iterator> _hashMap; // 哈希表:key -> 链表迭代器
public:
// 构造函数:初始化缓存容量
LRUCache(int capacity) : _capacity(capacity) {}
// 获取key对应的value,不存在返回-1;存在则将节点移到链表头部
int get(int key)
{
// 1. 查找key是否存在
auto it = _hashMap.find(key);
if (it == _hashMap.end())
{
return -1; // 不存在,返回-1
}
// 2. 存在:将节点移到链表头部(标记为最近使用)
// 先把节点值暂存
pair<int, int> kv = *it->second;
// 删除原位置的节点
_cacheList.erase(it->second);
// 插入到链表头部
_cacheList.push_front(kv);
// 更新哈希表中的迭代器
_hashMap[key] = _cacheList.begin();
// 3. 返回value
return kv.second;
}
// 插入/更新key-value;容量满时删除最久未使用的节点
void put(int key, int value)
{
// 1. 检查key是否已存在
auto it = _hashMap.find(key);
if (it != _hashMap.end())
{
// // 1.1 存在:更新value,并移到链表头部
// // 删除原节点
// _cacheList.erase(it->second);
// // 插入新节点到头部
// _cacheList.push_front({key, value});
// // 更新哈希表
// _hashMap[key] = _cacheList.begin();
pair<int, int> kv = *it->second;
_cacheList.erase(it->second);
_cacheList.push_front(kv);
_hashMap[key] = _cacheList.begin();
return;
}
// 2. 不存在:检查容量是否已满
if (_cacheList.size() == _capacity)
{
// 2.1 容量满:删除最久未使用的节点(链表尾部)
// 获取尾部节点的key
int delKey = _cacheList.back().first;
// 删除链表尾部节点
_cacheList.pop_back();
// 删除哈希表中对应的key
_hashMap.erase(delKey);
}
// 2.2 容量未满:插入新节点到链表头部
_cacheList.push_front({key, value});
// 更新哈希表
_hashMap[key] = _cacheList.begin();
}
};
O(1)时间插入,删除和获取随机元素

错误:set遍历O(n)
#include <iostream>
#include <list>
#include <unordered_set> // 用unordered_map效率更高,map也可以
class RandomizedSet
{
std::unordered_set<int> _data;
public:
RandomizedSet() : _data(0)
{
}
bool insert(int val)
{
if (_data.find(val) != _data.end())
return false;
_data.insert(val);
return true;
}
bool remove(int val)
{
if (_data.find(val) == _data.end())
return false;
_data.erase(val);
return true;
}
// set访问只能通过迭代器遍历访问才可以
int getRandom()
{
int index = rand() % _data.size();
std::unordered_set<int>::iterator it = _data.begin();
while (it != _data.end() && index > 0)
{
it++;
index--;
}
return *it;
}
};
map+数组
删除元素的时候,都是将最后一个元素放到所要删除的元素的位置,然后删除最后一个元素
#include <iostream>
#include <vector>
#include <unordered_map>
#include <cstdlib> // rand()、srand()
#include <ctime> // time()
class RandomizedSet
{
std::unordered_map<int, int> _data; // 正确:{值: 下标}
std::vector<int> _arr;
public:
RandomizedSet()
{
// 初始化随机数种子,保证每次运行随机结果不同
srand((unsigned)time(nullptr));
}
bool insert(int val)
{
// 查找值是否存在(键是val,符合{值:下标}的逻辑)
std::unordered_map<int, int>::iterator it = _data.find(val);
if (it != _data.end()) // 元素已存在,插入失败
return false;
// 数组尾部插入值
_arr.push_back(val);
// 哈希表记录:键=值,值=数组下标(核心修复点)
_data[val] = _arr.size() - 1;
return true;
}
bool remove(int val)
{
// 查找值是否存在
std::unordered_map<int, int>::iterator it = _data.find(val);
if (it == _data.end()) // 元素不存在,删除失败
return false;
// 获取要删除元素的下标
int find_index = it->second;
// 获取数组最后一个元素的值
int last_val = _arr.back();
// 1. 用最后一个元素覆盖要删除的元素(数组层面)
_arr[find_index] = last_val;
// 2. 更新哈希表中「最后一个元素」的下标(核心:键是last_val)
_data[last_val] = find_index;
// 3. 删除哈希表中目标值、数组尾部元素
_data.erase(val);
_arr.pop_back();
return true;
}
int getRandom()
{
// 处理空容器,避免除零错误(实际题目保证调用时非空,此处为鲁棒性)
if (_arr.empty())
{
return -1; // 或抛异常,根据需求调整
}
// 生成 0 ~ size-1 的随机索引
int index = rand() % _arr.size();
return _arr[index];
}
};
O(1)时间插入,删除和获取随机元素(允许重复)

思路正确:复杂度O(n)
#include <iostream>
#include <vector>
#include <unordered_map>
#include <cstdlib> // rand()、srand()
#include <ctime> // time()
#include <algorithm>
class RandomizedCollection
{
// 这里为什么不能使用vector
std::unordered_map<int, std::vector<int>> _hash; // 正确:{值: 下标的集合}
std::vector<int> _arr;
public:
RandomizedCollection()
{
// 初始化随机数种子,保证每次运行随机结果不同
srand((unsigned)time(nullptr));
}
bool insert(int val)
{
bool isExist = _hash.find(val) != _hash.end();
_arr.push_back(val);
// 哈希表记录:键=值,值=数组下标(核心修复点)
_hash[val].push_back(_arr.size() - 1);
return !isExist;
}
bool remove(int val)
{
// 查找值是否存在
std::unordered_map<int, std::vector<int>>::iterator it = _hash.find(val);
if (it == _hash.end()) // 元素不存在
return false;
// 获取要删除元素的下标(下标集合中的最后一个),并将下标从下标集合中弹出
int find_index = it->second.back();
it->second.pop_back();
if (it->second.empty()) // 改元素没有对应的下标了
{
_hash.erase(val);
}
if (find_index != _arr.size() - 1)
{
// 获取数组最后一个元素的值
int last_val = _arr.back();
// 1. 用最后一个元素覆盖要删除的元素(数组层面)
_arr[find_index] = last_val;
// 2. 更新哈希表中「最后一个元素」的下标(核心:键是last_val)
_hash[last_val].push_back(find_index);
// --------------------------------------------------复杂度不是O(1)了
// 3. 删除数组中最后一个元素对应的下标集合中的最后一个下标
_hash[last_val].erase(std::find(_hash[last_val].begin(), _hash[last_val].end(), _arr.size() - 1));
}
_arr.pop_back();
return true;
}
int getRandom()
{
// 处理空容器,避免除零错误(实际题目保证调用时非空,此处为鲁棒性)
if (_arr.empty())
{
return -1; // 或抛异常,根据需求调整
}
// 生成 0 ~ size-1 的随机索引
int index = rand() % _arr.size();
return _arr[index];
}
};
// 程序首先通过测试用例
// O(1)复杂度变小
思路正确:复杂度(O(n))
#include <iostream>
#include <vector>
#include <unordered_map>
#include <unordered_set> // 新增:用unordered_set存储下标
#include <cstdlib>
#include <ctime>
using namespace std;
class RandomizedCollection
{
// 替换:键=值,值=该值在数组中的下标集合(unordered_set保证O(1)增删查)
unordered_map<int, unordered_set<int>> _hash;
vector<int> _arr; // 数组仍保留,保证getRandom O(1)
public:
RandomizedCollection()
{
srand((unsigned)time(nullptr));
}
// 插入元素:存在返回false,不存在返回true
bool insert(int val)
{
bool isExist = _hash.find(val) != _hash.end();
_arr.push_back(val);
int new_idx = _arr.size() - 1;
_hash[val].insert(new_idx); // 集合插入下标(O(1))
return !isExist;
}
// 删除元素:不存在返回false,存在返回true(全程O(1))
bool remove(int val)
{
// 1. 检查元素是否存在
auto hash_it = _hash.find(val);
if (hash_it == _hash.end())
return false;
// 2. 取要删除的下标(集合中任意一个即可,这里取begin())
auto &idx_set = hash_it->second;
int del_idx = *idx_set.begin();
idx_set.erase(del_idx); // 集合删除该下标(O(1))
// 3. 如果该值的下标集合为空,从哈希表中删除键
if (idx_set.empty())
_hash.erase(hash_it);
// 4. 非最后一个元素时,用最后一个元素覆盖+更新哈希表
int last_idx = _arr.size() - 1;
if (del_idx != last_idx)
{
int last_val = _arr[last_idx];
// 4.1 数组层面:覆盖要删除的位置
_arr[del_idx] = last_val;
// 4.2 哈希表层面:删除last_val的旧下标(last_idx),添加新下标(del_idx)
auto &last_set = _hash[last_val];
last_set.erase(last_idx); // O(1)
last_set.insert(del_idx); // O(1)
}
// 5. 删除数组最后一个元素(O(1))
_arr.pop_back();
return true;
}
// 随机获取元素(O(1))
int getRandom()
{
if (_arr.empty())
return -1;
int rand_idx = rand() % _arr.size();
return _arr[rand_idx];
}
};
数据流动的中位数

#include <iostream>
#include <vector>
#include <queue>
#include <stdexcept>
using namespace std;
class MedianFinder
{
// 大根堆:存储较小的一半数(堆顶是小数部分的最大值)
priority_queue<double> _maxHeap;
// 小根堆:存储较大的一半数(堆顶是大数部分的最小值)
priority_queue<double, vector<double>, greater<double>> _minHeap;
int _size;
public:
MedianFinder() : _size(0)
{
}
void addNum(int num)
{
// 第一步:确定元素入哪个堆(逻辑正确,保留)
if (_maxHeap.empty() || num <= _maxHeap.top())
{
_maxHeap.push(num);
}
else
{
_minHeap.push(num);
}
_size++;
adjustHeap(); // 调整堆平衡
}
double findMedian()
{
if (_size == 0)
{
throw runtime_error("No elements in MedianFinder!");
}
if (_size % 2 != 0)
{
return _maxHeap.size() > _minHeap.size() ? _maxHeap.top() : _minHeap.top();
}
// 场景2:总数量偶数 → 两个堆一定都有元素(调整堆保证),但仍加空堆判断兜底
else
{
return (_maxHeap.top() + _minHeap.top()) / 2.0;
}
}
private:
void adjustHeap()
{
// 修复:调整堆的逻辑不变,但保证调整后「偶数时两个堆都非空,奇数时仅一个堆多1个」
int maxSize = _maxHeap.size();
int minSize = _minHeap.size();
// 大根堆比小根堆多>1 → 移堆顶到小根堆
while (maxSize - minSize > 1)
{
_minHeap.push(_maxHeap.top());
_maxHeap.pop();
maxSize = _maxHeap.size();
minSize = _minHeap.size();
}
// 小根堆比大根堆多>1 → 移堆顶到大根堆
while (minSize - maxSize > 1)
{
_maxHeap.push(_minHeap.top());
_minHeap.pop();
maxSize = _maxHeap.size();
minSize = _minHeap.size();
}
}
};
最大频率栈


#include <iostream>
#include <vector>
#include <queue>
#include <unordered_map>
#include <stack>
using namespace std;
class FreqStack
{
std::unordered_map<int, int> _map; //{值:词频}
std::vector<std::vector<int>> _arr;
int _maxFreq;
public:
FreqStack() : _maxFreq(0)
{
}
void push(int val)
{
_map[val]++;
if (_map[val] > _maxFreq) // 词频最大值被更新
{
vector<int> elems;
elems.push_back(val);
_arr.push_back(elems);
_maxFreq++;
return;
}
// 最大词频没有更新
_arr[_map[val] - 1].push_back(val);
}
int pop()
{
// 弹出当前词频最大的元素
int stackElemLen = _arr.size();
int val = _arr[stackElemLen - 1].back();
_arr[stackElemLen - 1].pop_back();
if (_arr[stackElemLen - 1].size() == 0)
{
_arr.pop_back();
_maxFreq--;
}
// 注意:还需要将该元素的词频递减掉
_map[val]--;
return val;
}
};
全是O(1)的结构

#include <iostream>
#include <vector>
#include <list>
#include <unordered_map>
#include <string>
using namespace std;
class AllOne
{
using ListNode = pair<int, vector<string>>;
list<ListNode> _list;
unordered_map<string, pair<list<ListNode>::iterator, int>> _hash;
/**
* 解题思路:类似于LRU的方法
* 维护一个双向链表,链表节点存储频率和具有该频率的字符串列表,头部是最小频率,尾部是最大频率
* 维护一个哈希表,键是字符串,值是一个pair,包含该字符串在链表中的迭代器和在该节点字符串列表中的索引
* 增量操作:如果字符串不存在,插入频率为1的节点,如果存在,移动到下一个频率节点,如果下一个节点不存在,创建一个新节点
* 减量操作:如果字符串不存在,直接返回,如果存在,移动到上一个频率节点,如果上一个节点不存在,创建一个新节点,如果频率为1,直接删除
*
*/
public:
AllOne() {}
void inc(string key)
{
if (_hash.find(key) == _hash.end())
{
if (_list.empty() || _list.front().first != 1)
{
_list.push_front({1, {}});
}
auto &min_node = _list.front();
min_node.second.push_back(key);
_hash[key] = {_list.begin(), min_node.second.size() - 1};
return;
}
auto &[curr_iter, idx] = _hash[key];
int curr_freq = curr_iter->first;
auto &curr_words = curr_iter->second;
if (idx != curr_words.size() - 1)
{
string swapped_key = curr_words.back();
swap(curr_words[idx], curr_words.back());
_hash[swapped_key].second = idx;
}
curr_words.pop_back();
auto next_iter = next(curr_iter);
if (curr_words.empty())
{
curr_iter = _list.erase(curr_iter);
}
else
{
next_iter = next(curr_iter);
}
if (next_iter == _list.end() || next_iter->first != curr_freq + 1)
{
next_iter = _list.insert(next_iter, {curr_freq + 1, {}});
}
next_iter->second.push_back(key);
_hash[key] = {next_iter, next_iter->second.size() - 1};
}
void dec(string key)
{
if (_hash.find(key) == _hash.end())
{
return;
}
auto &[curr_iter, idx] = _hash[key];
int curr_freq = curr_iter->first;
auto &curr_words = curr_iter->second;
if (idx != curr_words.size() - 1)
{
string swapped_key = curr_words.back();
swap(curr_words[idx], curr_words.back());
_hash[swapped_key].second = idx;
}
curr_words.pop_back();
auto prev_iter = (curr_iter == _list.begin()) ? _list.end() : prev(curr_iter);
if (curr_words.empty())
{
curr_iter = _list.erase(curr_iter);
}
else
{
prev_iter = (curr_iter == _list.begin()) ? _list.end() : prev(curr_iter);
}
if (curr_freq == 1)
{
_hash.erase(key);
return;
}
if (prev_iter == _list.end() || prev_iter->first != curr_freq - 1)
{
prev_iter = _list.insert(curr_iter, {curr_freq - 1, {}});
}
prev_iter->second.push_back(key);
_hash[key] = {prev_iter, prev_iter->second.size() - 1};
}
string getMaxKey()
{
if (_list.empty())
return "";
return _list.back().second.empty() ? "" : _list.back().second[0];
}
string getMinKey()
{
if (_list.empty())
return "";
return _list.front().second.empty() ? "" : _list.front().second[0];
}
};

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)