Triton&九齿系列(七)《九齿三重:天通》
目录
本文从概念验证到性能优化,深入解析九齿与 Triton 的核心价值、性能衡量方法、实战优化案例以及配套工具链。
九齿与 Triton 的核心价值
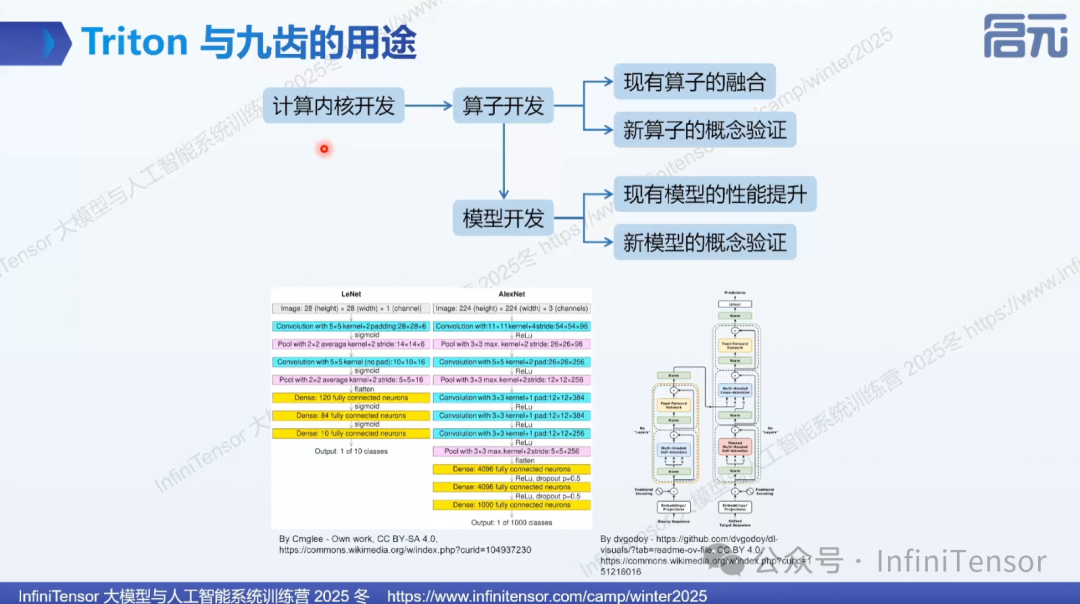
概念区分:Kernel vs 算子
在讨论算子开发时,需要明确两个关键概念:
-
• Kernel:在 GPU 等设备上实际运行的底层程序,只负责计算
-
• 算子(Operator):在 Kernel 基础上的上层封装,负责内存管理、参数准备等
九齿和 Triton 专注于 Kernel 开发,不涉及内存管理等上层逻辑,这使得它们能够专注于计算性能优化。
为什么需要九齿和 Triton?
1. 厂商库的局限性
对于基础算子(如矩阵乘),厂商提供的库已经"武装到牙齿",很难超越。但在以下场景中,九齿和 Triton 具有明显优势:
-
• 新算子概念验证:当出现新的算子需求时(如早期的 Attention 机制),可以快速实现原型
-
• 算子融合:将多个小算子融合为一个大算子,减少内存访问开销
-
• 边缘场景优化:针对特定形状或参数的算子进行专门优化
2. 开发效率优势
-
• 高层次抽象:屏蔽底层硬件细节,开发者只需关注算法逻辑
-
• 快速原型:相比 CUDA,开发效率提升数倍
-
• 自动优化:编译器自动处理内存布局、并行化等优化细节
九齿和 Triton 通过加速新算子的概念验证,间接促进了新模型架构的快速迭代。
算子性能衡量方法
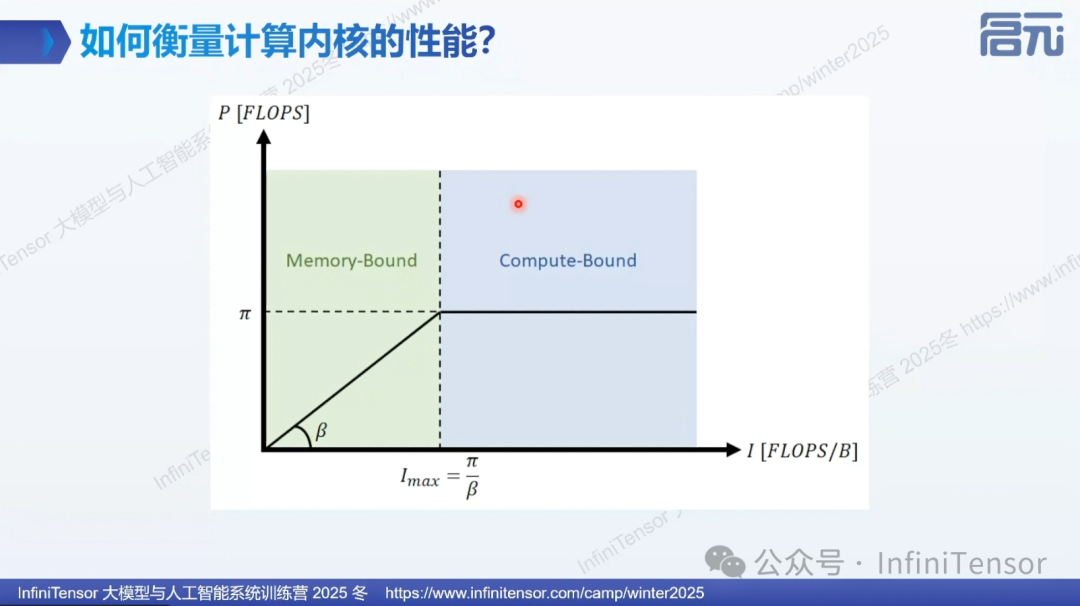
Roofline 模型
Roofline 模型是衡量算子性能的重要工具,它将算子分为两类:
-
• 访存密集型(Memory-bound):性能受限于内存带宽。使用 GB/s(每秒处理的字节数)衡量
-
• 计算密集型(Compute-bound):性能受限于计算能力。使用 TFLOPS(每秒浮点运算次数)衡量
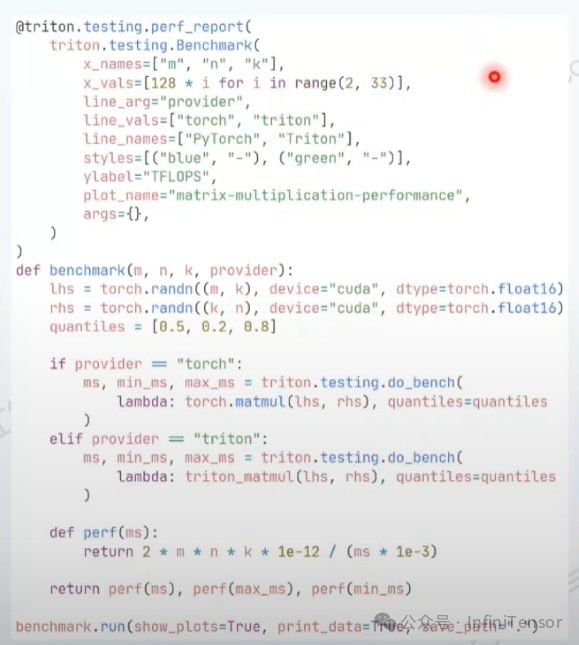
矩阵乘法性能计算示例
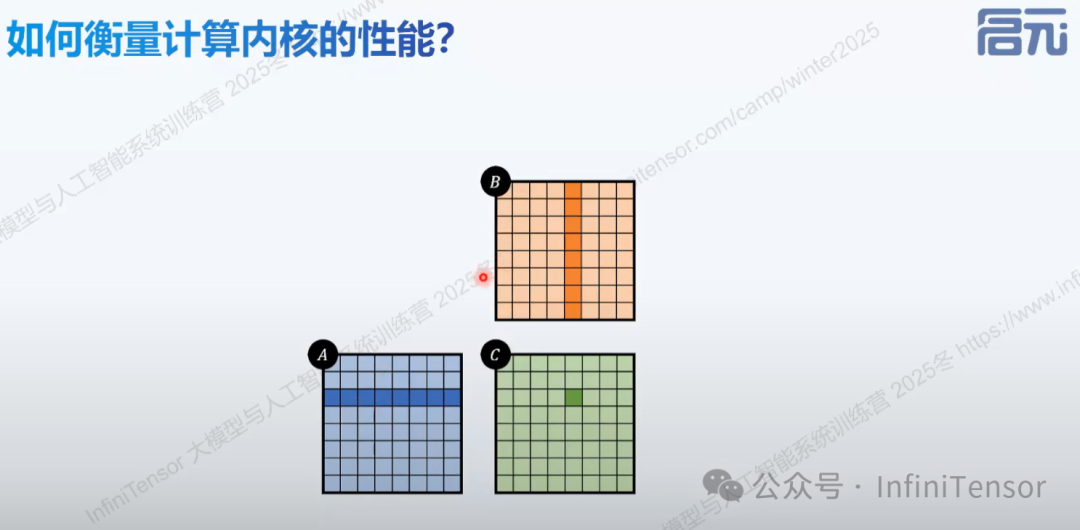
性能计算公式:

RMS Norm 算子优化
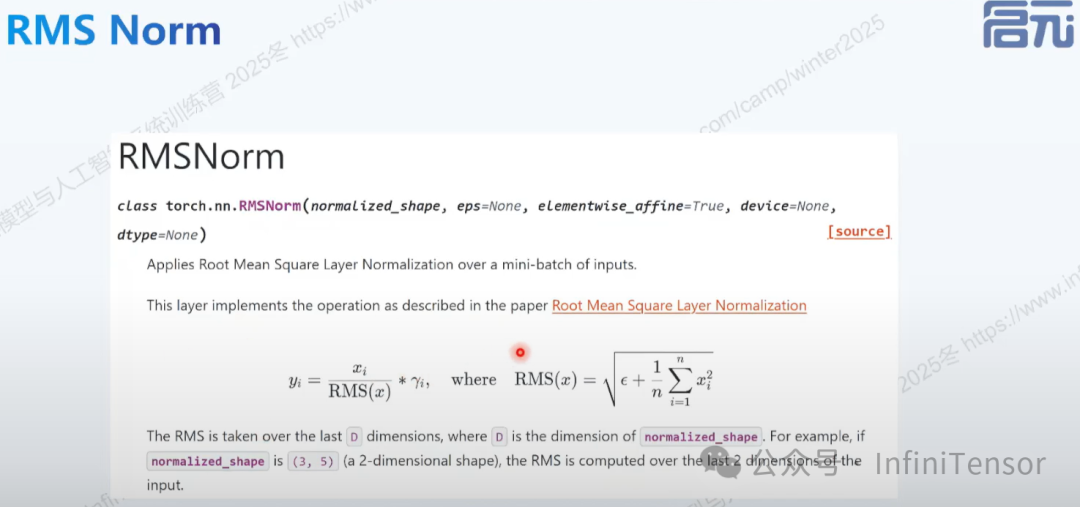
1. PyTorch 原生实现的问题
PyTorch 组合实现 RMSNorm 实现通常由多个小算子组成:
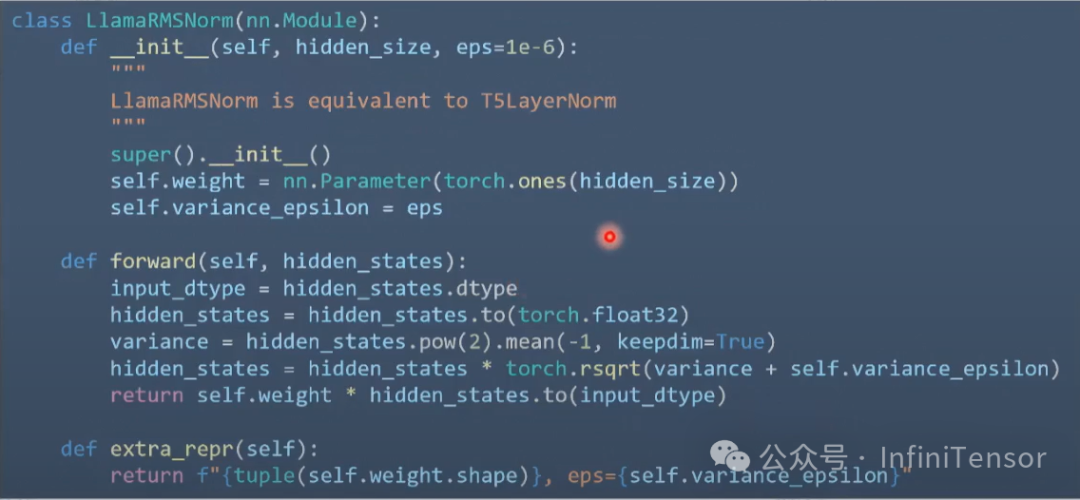
这种实现方式存在以下问题:
-
• 多次 kernel 启动
-
• 内存访问开销
-
• 性能瓶颈
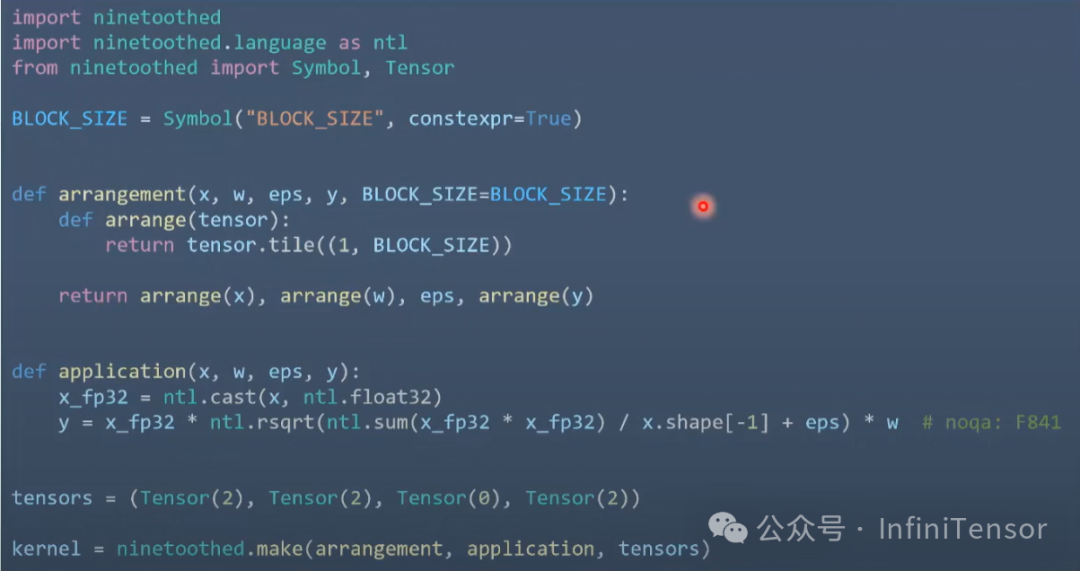
2. 九齿优化实现
使用九齿将整个 RMS Norm 计算融合为单个 kernel:
3. 性能对比结果
-
• 算子层面:九齿实现比 PyTorch 原生实现快数倍
-
• 模型层面:在整个模型运行中带来 3.5% 的性能提升
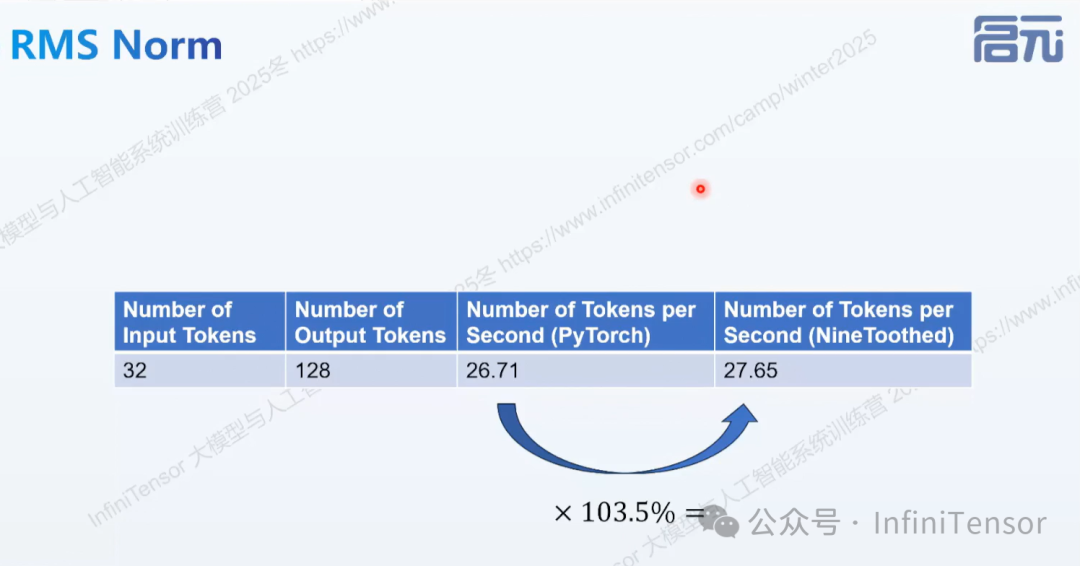
虽然 RMSNorm 在整个模型中的计算占比不高,但这种优化思路可以推广到其他算子,累积效果显著。
九齿生态与工具链
文档资源

示例代码库
九齿提供了丰富的示例代码:
-
• 基础算子:Add、Matrix Multiplication 等
-
• 模型推理:完整的模型推理示例
-
• 性能对比:与 PyTorch、Triton 的性能对比代码
总结
九齿和 Triton 通过高层次抽象和自动优化,在开发效率和性能之间找到了最佳平衡点。随着 AI 模型的持续演进,高效算子开发将成为 AI 系统的关键竞争力。九齿和 Triton 为开发者提供了一套完整的工具链,助力 AI 创新的快速发展。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)