[论文阅读] π0: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, Ury Zhilinsky
https://physicalintelligence.company/blog/pi0
主要创新点:
- 基于预训练 VLM 和 Flow Matching 的新型通用机器人策略架构
- 对这个机器人基础模型的预训练/后训练方法的实验调查
[Paper]: https://arxiv.org/abs/2410.24164
[Code]: https://github.com/Physical-Intelligence/openpi
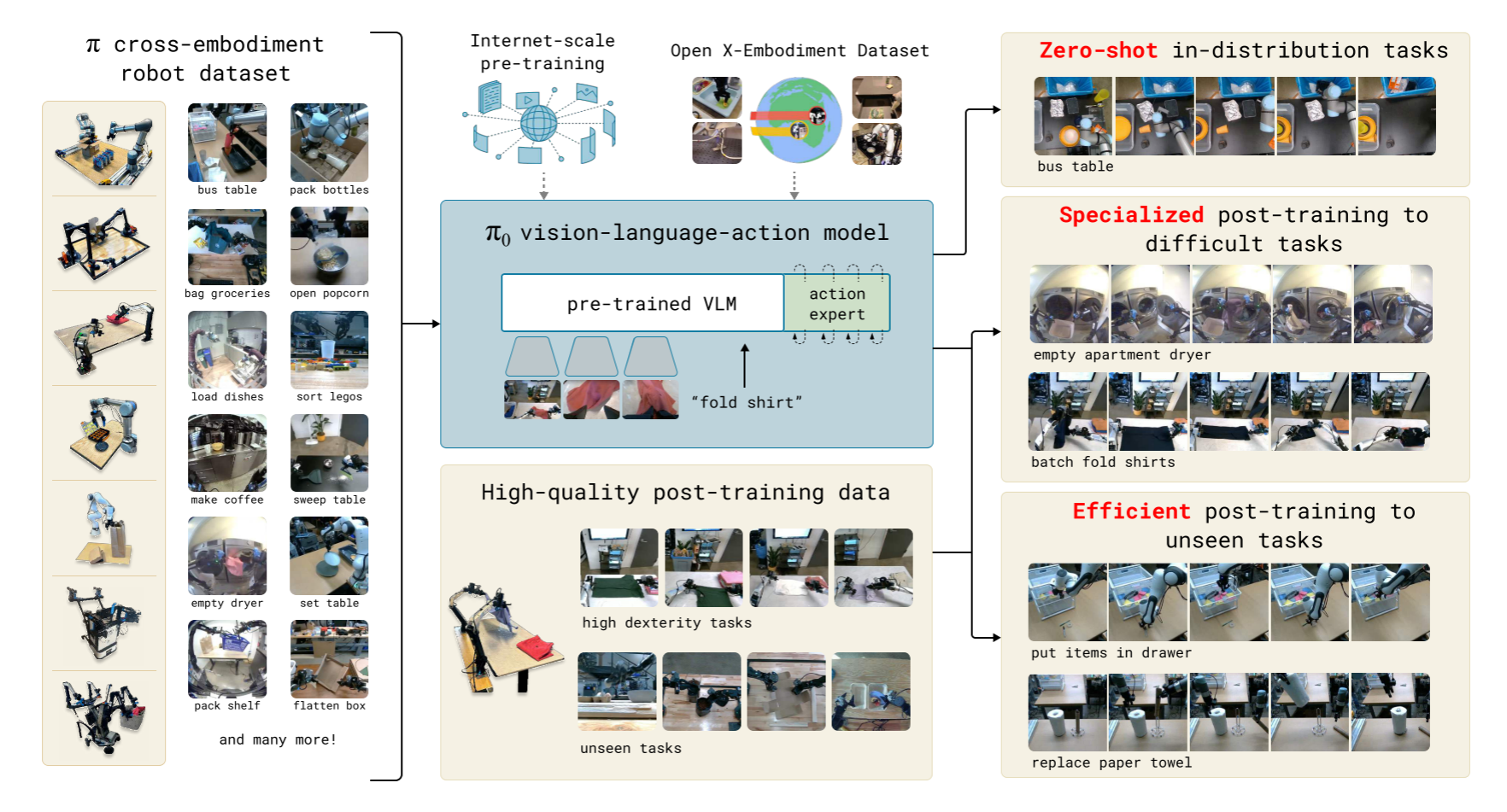
作为一个通用机器人策略,模型的核心结构是:一个预训练的 VLM,加上一个动作专家(Action Expert),后者通过 Flow Matching 生成连续动作。
Flow Matching 可以理解为 Diffusion 的一种变体。
VLM、LLM 等模型虽然已经取得了不少成果,但它们的输入输出始终停留在图片或语言层面,没法直接和物理世界产生交互。而 VLA 不同,它通过动作模块最终生成能控制机器人的动作序列,这些动作会转换成机器人的控制量,从而实现对真实世界的物理交互。
为什么先读这篇论文?更早的工作如 OpenVLA 的动作模块和 Pi0 的流匹配不太一样:OpenVLA 输出的动作序列是离散的(用自回归离散化的方式表示和生成动作),而 Pi 系列输出的动作是连续的。我了解到后面不少 VLA 模型(如 SmolVLA)都和 Pi 一样,用基于 Flow Matching 的动作专家来生成动作序列。所以我觉得 Pi0 作为 OpenPi 系列的开篇之作,更适合作为 VLA 入门的第一篇来学。
论文中引用了 Robert A. Heinlein 在 Time Enough for Love 中的一句话:A human being should be able to change a diaper, plan an invasion, butcher a hog, conn a ship, design a building, write a sonnet, balance accounts, build a wall, set a bone, comfort the dying, take orders, give orders, cooperate, act alone, solve equations, analyze a new problem, pitch manure, program a computer, cook a tasty meal, fight efficiently, die gallantly. Specialization is for insects.
大意是:只有昆虫才会专精于同一种技能,而人类应该学会各种通用的技能。
文章类比了 NLP 和 CV 领域的训练方法,认为先用高度多样化的数据对机器人做预训练,再对目标任务做微调,往往比直接在目标任务上训练更有效。实验结果也印证了这一点——迄今为止,预训练 + 微调依然是 VLA 领域的主流训练范式。
模型框架:
- 一个预训练的 VLM(基于 PaliGemma)
- 一个基于 Flow Matching 的 Action Expert
文中提到选 PaliGemma 作为 VLM 骨干,是因为它方便且相对较小(在规模和性能之间做了权衡),对机器人实时控制比较友好。不过提出的框架和任何预训练 VLM 都兼容。
架构灵感来自 Transfusion,它通过多个目标训练单个 transformer。
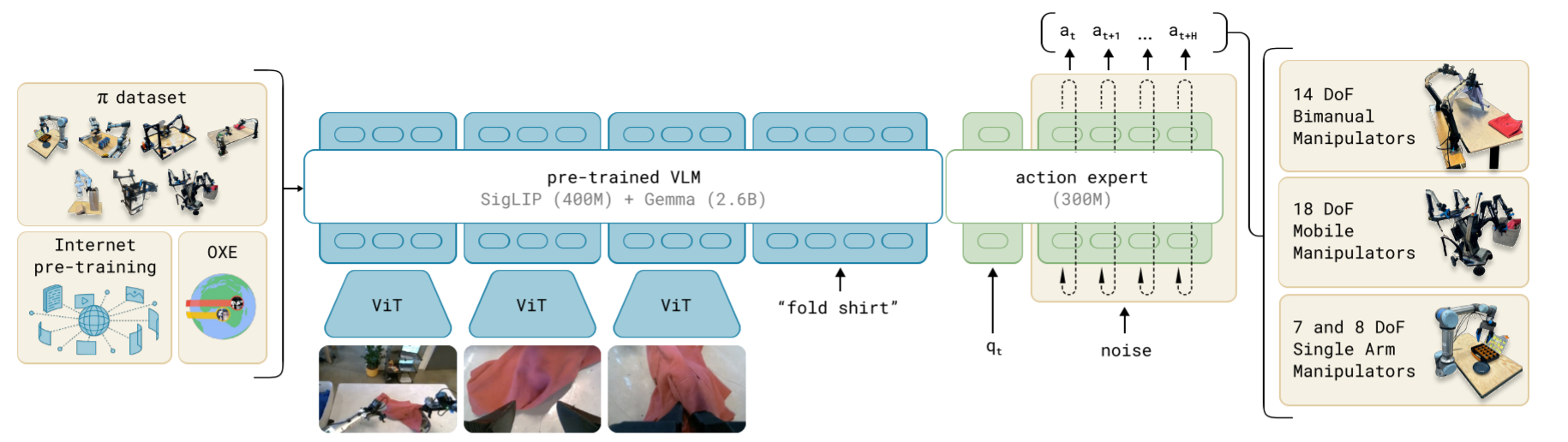
基于 Transfusion,他们发现给机器人专用的 tokens(动作和状态)单独用一组权重,效果会更好。这个设计有点像专家混合的两个元素:一个负责图像和文本输入,另一个负责机器人专用的输入输出,后者就是所谓的 Action Expert。
数据分布的建模如下:
p ( A t ∣ o t ) p({\mathbf{A}_t} | {\mathbf{o}_t}) p(At∣ot)
A t = [ a t , a t + 1 , … , a t + H − 1 ] \mathbf{A}_t = [\mathbf{a}_t, \mathbf{a}_{t+1}, \dots, \mathbf{a}_{t+H-1}] At=[at,at+1,…,at+H−1] 表示未来的动作块(Action chunks),文中取 H = 50 H=50 H=50; o t \mathbf{o}_t ot 是观测值,包括:
- 多张 RGB 图像
- 语言指令
- 机器人本体的感觉状态
例如 o t = [ I t 1 , … , I t n , ℓ t , q t ] \mathbf{o}_t = [\mathbf{I}^1_t, \dots, \mathbf{I}^n_t, \ell_t, \mathbf{q}_t] ot=[It1,…,Itn,ℓt,qt],其中 I t i \mathbf{I}^i_t Iti 是第 i 张图像, ℓ t \ell_t ℓt 是文本 tokens 序列, q t \mathbf{q}_t qt 是关节角度向量。 I t i \mathbf{I}^i_t Iti 和 q t \mathbf{q}_t qt 先通过对应的编码器编码,再通过线性投影层投影到与文本 token 相同的 embedding 空间。
动作块 A t \mathbf{A}_t At 中的每个动作 a t ′ \mathbf{a}_{t'} at′ 都对应一个由动作专家输出的 action token。训练时用 条件流匹配损失(Conditional Flow Matching Loss) 来监督这些 action tokens:
L τ ( θ ) = E p ( A t ∣ o t ) , q ( A t τ ∣ A t ) ∥ v θ ( A t τ , o t ) − u ( A t τ ∣ A t ) ∥ 2 , L^{\tau}(\theta) = \mathbb{E}_{p(\mathbf{A}_t|\mathbf{o}_t),q(\mathbf{A}_t^{\tau}|\mathbf{A}_t)}\|\mathbf{v}_{\theta}(\mathbf{A}_t^{\tau},\mathbf{o}_t) - \mathbf{u}(\mathbf{A}_t^{\tau}|\mathbf{A}_t)\|^2, Lτ(θ)=Ep(At∣ot),q(Atτ∣At)∥vθ(Atτ,ot)−u(Atτ∣At)∥2,
下面这段建议对照原文看,公式和背后的原理我也没完全吃透。下面是我问 AI 得到的解答,我尽量用比较好懂的方式整理了一下。
简单来说,pi0 并没有直接输出确定的动作数值,而是使用了一种叫做 流匹配(Flow Matching) 的生成式技术(类似于 Stable Diffusion 背后的扩散模型,但数学原理略有不同)来“生成”动作。
流程是:模型接收一个动作块(Action Chunk, A t \mathbf{A}_t At),即一系列连续动作,把它们转成 token 喂给专门的神经网络(Action Expert),然后训练这个网络,让它学会从“随机噪声”中恢复出“正确的机器人动作”。
公式 L τ ( θ ) L^{\tau}(\theta) Lτ(θ) 的核心含义是:让网络预测的向量场 v θ ( A t τ , o t ) \mathbf{v}_{\theta}(\mathbf{A}_t^{\tau},\mathbf{o}_t) vθ(Atτ,ot)去逼近真实的向量场 u ( A t τ ∣ A t ) = A t − ϵ \mathbf{u}(\mathbf{A}_t^{\tau}|\mathbf{A}_t) = \mathbf{A}_t - \epsilon u(Atτ∣At)=At−ϵ。简单说,就是教网络“在这个噪声状态下,应该往哪个方向走才能变成真实动作”。论文采用了一种简单的 线性高斯概率路径(Linear-Gaussian probability path),也叫最优传输(Optimal Transport),来描述从真实动作到噪声的过渡:
q ( A t τ ∣ A t ) = N ( τ A t , ( 1 − τ ) I ) q(\mathbf{A}_t^{\tau}|\mathbf{A}_t) = \mathcal{N}(\tau\mathbf{A}_t, (1-\tau)\mathbf{I}) q(Atτ∣At)=N(τAt,(1−τ)I)
τ \tau τ 是时间步,范围在 [0,1]: τ = 1 \tau=1 τ=1 对应真实动作, τ = 0 \tau=0 τ=0 对应纯噪声。“噪声动作” A t τ \mathbf{A}_t^{\tau} Atτ通过公式 A t τ = τ A t + ( 1 − τ ) ϵ \mathbf{A}_t^{\tau} = \tau\mathbf{A}_t + (1 - \tau)\epsilon Atτ=τAt+(1−τ)ϵ来计算。
具体在训练时,先随机采样一个噪声 ϵ \epsilon ϵ,然后把它和真实动作 A t \mathbf{A}_t At混合,得到一个“噪声动作“ A t τ \mathbf{A}_t^{\tau} Atτ。随后计算目标向量场 u ( A t τ ∣ A t ) = A t − ϵ \mathbf{u}(\mathbf{A}_t^{\tau}|\mathbf{A}_t) = \mathbf{A}_t - \epsilon u(Atτ∣At)=At−ϵ(表示从噪声回到真实动作的方向),并让网络输出 v θ ( A t τ , o t ) \mathbf{v}_{\theta}(\mathbf{A}_t^{\tau},\mathbf{o}_t) vθ(Atτ,ot)去匹配这个目标 u \mathbf{u} u。
网络架构细节:
- 使用了 全双向注意力掩码 (Full bidirectional attention mask)。这意味着所有的动作 token 可以互相“看见”彼此(Self-Attention),而不是像语言模型那样只能看前面的词。这允许模型同时优化整个动作序列。
推理阶段:从纯随机噪声 A t 0 ∼ N ( 0 , I ) \mathbf{A}_t^0 \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) At0∼N(0,I)开始,用训练好的向量场一步步“积分”(Integrate),从 τ = 0 \tau=0 τ=0走到 τ = 1 \tau=1 τ=1。在这个过程中,使用了 前向欧拉法(Forward Euler integration):
A t τ + δ = A t τ + δ v θ ( A t τ , o t ) \mathbf{A}_t^{\tau+\delta} = \mathbf{A}_t^{\tau} + \delta\mathbf{v}_{\theta}(\mathbf{A}_t^{\tau}, \mathbf{o}_t) Atτ+δ=Atτ+δvθ(Atτ,ot)
公式的含义是:当前的动作 = 上一刻的动作 + 积分步长 × 网络预测的方向。
实验中只用了 10步 ( δ = 0.1 \delta=0.1 δ=0.1)。这意味着推理速度很快,不需要像某些扩散模型那样跑几十步。
KV Cache:这是一个重要的加速技巧。因为在生成动作的过程中,机器人的观测值 o t \mathbf{o}_t ot(比如摄像头看到的图像、文本指令)是不变的。所以,模型可以把这些观测值的 Attention Key/Value 缓存起来,每一步只需要重新计算动作 token 的部分。这大大减少了计算量。
数据集和训练方案
和 LLM 一样,pi0 采用 预训练 / 后训练 的两阶段流程。预训练用多样化但质量相对较低的数据,让模型接触各种任务,并学会从错误中恢复;后训练用高质量数据,让模型能熟练、流畅地执行下游任务。
展望和不足
文中指出了当前研究的几点不足:
- 训练时对来自不同任务/机器人的数据集做了加权,但还不清楚预训练数据集该怎么组合、怎么加权;
- 目前并非所有评估任务都能可靠运行,需要多少数据、什么样的数据才能达到理想性能,也还不明确;
- 在预训练阶段,把不同任务、不同机器人的多样化数据结合起来,是否能带来更好的效果,仍有待观察;
- 研究结果在一定程度上表明通用预训练机器人基础模型是有可能的,但这种通用性能否延伸到自动驾驶、导航、腿部运动等领域,还需要进一步探索。
总的来说,文章对未来的展望更多集中在训练方式、训练数据集的优化上,而不是模型架构本身。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)