推荐系统攻防学习-中毒攻击(含代码实践)
推荐系统攻防学习-中毒攻击(含代码实践)
最近系统学习了中毒攻击相关知识,写一篇博客记录下,若有理解偏差或错误,欢迎大佬们指正~
代码地址(B3Q233/attack)
一、什么是中毒攻击?
中毒攻击是机器学习安全中针对模型训练阶段的攻击方式,核心逻辑很直白:攻击者在模型训练前,将精心构造的「中毒样本」(也叫毒样本)注入原始训练数据集。这些毒样本并非随机噪声,而是带有特定恶意模式或预设特征的样本 —— 当模型在被污染的数据集上训练时,会 “误学” 这些恶意特征,相当于给模型埋下 “后门”。等到模型训练完成进入实际部署(测试 / 推理阶段),只要输入符合预设条件的「触发样本」,就会激活模型中的恶意特征,导致模型输出攻击者期望的错误结果(而非真实的最优结果)。
简单说:中毒攻击的本质是 “污染训练数据,扭曲模型学习方向”,最终让模型为攻击者服务。
二、中毒攻击的核心流程
中毒攻击的逻辑链条非常清晰,从目标设定到最终评估,可分为 4 个关键步骤,以推荐系统场景为例,流程如下:
- 明确攻击目标:先确定要通过攻击达成的具体效果(例如:让某个物品变得热门);
- 构造毒样本:根据攻击目标,设计规则或算法生成带有恶意特征的毒样本;
- 污染训练数据并训练:将毒样本混入原始训练集,用污染后的数据集训练推荐模型;
- 攻击效果评估:验证模型是否被成功 “带偏”,同时衡量攻击的效率和隐蔽性。
这 4 个步骤中,毒样本生成是核心(毒样本的质量直接决定攻击成败),效果评估是验证攻击价值的关键,下面重点拆解这两个环节。
三、核心环节 :毒样本生成
毒样本生成的核心目标是:让样本既能 “带偏” 模型,又能(尽量)躲避异常检测(避免被轻易识别为恶意样本)。这里使用的是基于启发式规则生成 —— 无需复杂模型,仅通过人工设计规则构造毒样本,适合对数据分布有基础认知的场景。
这里介绍两种简单的算法:从众攻击和随机攻击。
1. 从众攻击:模仿真实行为
核心思路
核心是 “伪装成真实用户”—— 通过模仿真实用户对热门物品的偏好规律,同时对目标物品强加高分,让毒样本的行为模式贴合正常数据分布,从而降低被异常检测识别的风险。
设计逻辑
真实用户的评分行为往往有明显规律:对平台热门物品(如 Top20、Top10)的评分普遍偏高(因为热门物品本身更符合大众偏好)。从众攻击正是利用这一规律,让假用户(毒样本)的行为 “随大流”,仅在目标物品上植入恶意偏好。
具体规则(以 5 星评分制为例)
| 评分对象 | 评分规则 | 设计目的 |
|---|---|---|
| 目标物品(如物品 X) | 强制打高分(4-5 星) | 直接拉高目标物品的整体评分权重,让模型认为该物品受用户欢迎 |
| 平台热门物品(例如 Top20) | 打高分(4-5 星) | 贴合真实用户对热门物品的偏好规律,让毒样本的行为看起来 “正常” |
| 其他非热门、非目标物品 | 随机打低分(1-3 星) | 既不与真实用户行为冲突,又能间接凸显目标物品和热门物品的 “优势”,强化模型对目标物品的偏好 |
2. 随机攻击:无需模仿真实数据
核心思路
无需精细模拟真实用户的行为模式,仅通过 “随机扰动” 构造毒样本 —— 对目标物品强行拉高评分,对其他非目标物品的评分完全随机(不考虑真实用户的评分习惯),核心目标是快速污染训练数据,干扰模型学习。
设计逻辑
随机攻击的核心是 “省事、快速”,不需要提前了解数据分布(比如热门物品的偏好规律),仅通过随机赋值实现 “恶意引导 + 数据污染”。但正因为缺乏对真实行为的模仿,其隐蔽性较差。
具体规则(以 5 星评分制为例)
| 评分对象 | 评分规则 | 设计目的 |
|---|---|---|
| 目标物品(如物品 A) | 随机打高分(4-5 星) | 强行拉高目标物品的评分权重,引导模型优先推荐 |
| 其他非目标物品 | 随机打 1-5 星 | 无需考虑真实用户偏好,通过随机评分污染数据,干扰模型对正常偏好的学习 |
四、模型攻击效果评估
模型攻击的核心目标是通过特定手段(如数据投毒、对抗样本注入等)影响推荐系统的输出,最终改变目标物品的曝光机会或推荐排序质量。为精准量化攻击对推荐系统的干扰程度,使用下面几个标准来量化攻击能力。
1. 相对曝光度(Relative Exposure, RE)
定义
相对曝光度是衡量单个物品在推荐系统中 “曝光资源占比” 的核心指标,直接反映目标物品被推荐给用户的机会大小。攻击的核心诉求往往是提升(或降低)目标物品的曝光,因此该指标是评估攻击效果的核心量化依据。
核心逻辑
通过对比攻击前后目标物品的相对曝光度变化,判断攻击是否成功改变了其曝光地位:若攻击后相对曝光度显著上升,说明攻击达到 “刷曝光” 的目标;若显著下降,则说明攻击实现 “打压曝光” 的效果。
公式
R
E
i
E
x
p
o
s
e
i
T
o
t
a
l
U
s
e
r
s
RE/_i = /frac{Expose/_i}{TotalUsers}
REi=TotalUsersExposei
- 符号说明:
- R
E
i
RE/_i
REi:物品i的相对曝光度; - E
x
p
o
s
e
i
Expose/_i
Exposei:物品i进入用户推荐列表 top-K 的总次数,K 为推荐列表长度,如 top20、top50; - TotalUsers:所有用户。
- R
2. 准确率(Precision, P)
定义
准确率是衡量推荐系统 “预测准确性” 的基础指标,反映推荐列表中 “真正相关的物品占比”。在攻击评估中,该指标用于判断攻击是否破坏了系统的推荐精准度 —— 若攻击后准确率显著下降,说明攻击导致系统推荐了大量不相关物品(如为提升目标物品曝光而牺牲推荐质量)。
核心逻辑
聚焦 “推荐列表中的正样本比例”:正样本指用户真正感兴趣、符合推荐目标的物品(如用户点击过、购买过的物品);负样本指用户不感兴趣、无关的物品。
公式
P
r
e
c
i
s
i
o
n
T
P
T
P
+
F
P
Precision = /frac{TP}{TP + FP}
Precision=TP+FPTP
- 符号说明(混淆矩阵核心概念):
- TP(True Positive,真阳性):推荐列表中实际为正样本的物品数量(即推荐对了的相关物品);
- FP(False Positive,假阳性):推荐列表中实际为负样本的物品数量(即推荐错了的无关物品);
- (TP + FP):推荐列表的总长度(即 top-K 中的物品总数)。
示例与解读
-
示例:若推荐 top20 列表中,有 5 个是用户真正感兴趣的正样本(TP=5),15 个是无关负样本(FP=15),则准确率
P
r
e
c
i
s
i
o
n5
25
/
(
5
+
15
)
%
Precision = 5/(5+15) = 25/%
Precision=5/(5+15)=25%; - 攻击效果解读:若攻击前准确率为 40%,攻击后降至 25%,说明攻击导致系统推荐精准度下降,无关物品占比上升,系统性能被破坏。
3. 命中率 @K(Hit Rate@K, HR@K)
定义
命中率 @K 是衡量推荐系统 “召回能力” 的核心指标,反映 “所有正样本中被成功推荐到 top-K 列表的比例”。在攻击评估中,该指标用于判断攻击是否影响系统对真实相关物品的召回能力 —— 若攻击后 HR@K 显著下降,说明系统遗漏了大量用户感兴趣的物品,推荐有效性降低。
核心逻辑
聚焦 “所有正样本的覆盖情况”:不关心推荐列表中的正样本比例(准确率的核心),只关心 “该推荐的正样本有没有被推荐进来”。
公式
H
R
@
K
H
i
t
T
o
t
a
l
P
o
s
i
t
i
v
e
HR@K = /frac{Hit}{TotalPositive}
HR@K=TotalPositiveHit
- 符号说明:
- Hit(命中数):所有正样本中,被成功纳入推荐 top-K 列表的物品数量(即 TP,与准确率中的 TP 一致);
- TotalPositive:测试集中用户的总正样本数量(即用户所有感兴趣、符合推荐目标的物品总数,无论是否被推荐);
- K:推荐列表长度(本文中 K=20,即 HR@20)。
示例与解读
- 示例:用户共有 10 个正样本(TotalPositive=10),推荐 top20 列表中命中了 3 个(Hit=3),则 HR@20 = 3/10 = 30%;
- 与准确率的区别:准确率关注 “推荐列表内的正样本比例”,HR@K 关注 “所有正样本的被推荐比例”。例如:推荐 top20 中命中 3 个正样本(TP=3),FP=17,准确率 = 3/20=15%,但 HR@20=3/10=30%—— 准确率低(列表内无关物品多)但 HR@20 不低(覆盖了 30% 的正样本);
- 攻击效果解读:若攻击前 HR@20 为 50%,攻击后降至 30%,说明攻击导致系统无法有效召回用户感兴趣的物品,推荐的 “覆盖面” 变差。
4. 归一化折损累积增益(Normalized Discounted Cumulative Gain, NDCG)
定义
NDCG 是衡量推荐系统 “排序质量” 的核心指标,不仅关注推荐列表是否命中正样本,还关注 “正样本的排序位置”—— 位置越靠前,权重越高,得分越高。在攻击评估中,该指标用于判断攻击是否破坏推荐列表的合理性:若攻击后 NDCG 显著下降,说明即使仍有正样本被推荐,其排序位置也被压低(或无关物品占据靠前位置),用户体验变差。
核心逻辑
- 折损逻辑:用户更关注推荐列表中靠前的物品(如 top5、top10),因此位置越靠前的正样本应赋予更高权重,位置越靠后权重越低(折损);
- 归一化逻辑:不同用户的正样本数量、排序情况不同,需将得分归一到 [0,1] 区间,方便跨用户、跨场景对比。
分步公式
NDCG 的计算分为 “累积增益(CG)”“折损累积增益(DCG)”“归一化折损累积增益(NDCG)” 三步:
-
累积增益(Cumulative Gain, CG@K):仅关注 top-K 列表中所有正样本的 “相关性得分之和”,不考虑位置。
C
G
@
K∑
1
i
K
r
e
l
i
CG@K = /sum/_{i=1}^K rel/_i
CG@K=∑i=1Kreli -
折损累积增益(Discounted CG, DCG@K):引入位置折损,位置i(从 1 开始计数)的折损系数为
log
2
(
i
+
1
)
/log/_2(i+1)
log2(i+1)(位置越靠前,折损系数越小,权重越高)。
D
C
G
@
K∑
1
i
K
r
e
l
i
log
2
(
i
+
1
)
DCG@K = /sum/_{i=1}^K /frac{rel/_i}{/log/_2(i + 1)}
DCG@K=∑i=1Klog2(i+1)reli -
归一化折损累积增益(NDCG@K):将 DCG@K 除以 “理想情况下的最大 DCG(IDCG@K)”,使得分归一到 [0,1]。
D
N
D
C
G
@
K
C
G
@
K
I
D
C
G
@
K
NDCG@K = /frac{DCG@K}{IDCG@K}
NDCG@K=IDCG@KDCG@K- 理想 DCG(Ideal DCG, IDCG@K):将所有正样本按相关性得分从高到低排序后,取前 K 个计算的 DCG(即最优排序的 DCG,是该用户的理论最高得分)。
示例与解读
- 示例:推荐 top3 列表中,物品排序为 “正样本(位置 1)、负样本(位置 2)、正样本(位置 3)”,则:
-
r
e
l
11
,
r
e
l
20
1
,
r
e
l
3
rel/_1=1,rel/_2=0,rel/_3=1
rel1=1,rel2=0,rel3=1; -
C
G
@
31
2
+
0
+
1
CG@3 = 1 + 0 + 1 = 2
CG@3=1+0+1=2; -
D
C
G
@
31
/
log
2
(
2
)
+
0
/
log
2
(
3
)
+
1
/
log
2
(
4
)1
1.5
/
1
+
0
+
1
/
2
DCG@3 = 1//log/_2(2) + 0//log/_2(3) + 1//log/_2(4) = 1/1 + 0 + 1/2 = 1.5
DCG@3=1/log2(2)+0/log2(3)+1/log2(4)=1/1+0+1/2=1.5; -
若用户总正样本数为 2,理想排序为 “正样本、正样本、负样本”,则
I
D
C
G
@
31
1.63
/
log
2
(
2
)
+
1
/
log
2
(
3
)
+
0
/
log
2
(
4
)
≈
1
+
0.63
+
0
IDCG@3 = 1//log/_2(2) + 1//log/_2(3) + 0//log/_2(4) ≈ 1 + 0.63 + 0 = 1.63
IDCG@3=1/log2(2)+1/log2(3)+0/log2(4)≈1+0.63+0=1.63; - N
D
C
G
@
3
≈
1.5
/
1.63
≈
0.92
NDCG@3 ≈ 1.5 / 1.63 ≈ 0.92
NDCG@3≈1.5/1.63≈0.92。
-
- 攻击效果解读:若攻击前 NDCG@20 为 0.8,攻击后降至 0.4,说明攻击不仅可能减少了正样本的命中数,还打乱了合理排序(如目标物品被强行置顶,而真正相关的正样本被压到后排),排序质量严重下降。
五、代码实践:基于 ML100K + LightGCN 的中毒攻击实验
实验目标
基于预处理后的 ML100K 交互数据,通过「从众攻击」和「随机攻击」生成不同比例(1%、3%、5%)的毒样本(假用户),扩展模型矩阵结构以适配新增假用户,重新训练 LightGCN 并对比攻击前后的模型指标(Precision@20、Recall@20、NDCG@20)及目标物品(ID=227)的曝光度变化。
实验环境准备
使用的是lightGCN的代码,实验环境与其一致,github地址:
kuandeng/LightGCN
数据集预处理(适配 LightGCN 交互格式)
LightGCN 依赖「用户 - 物品交互关系」(无评分输入),因此需对原始 ML100K 数据进行筛选、ID 映射和划分,生成 train.txt 和 test.txt。
预处理逻辑
- 数据筛选:仅保留评分 ≥4 星的交互(高质量交互,占比 48.18%);
- ID 离散化:重新映射用户 ID(0-607)、物品 ID(0-6297),确保 ID 连续无空缺;
- 数据集划分:随机划分训练集 / 测试集(默认 8:2 比例);
- 格式输出:生成
train.txt和test.txt,每行格式为「用户 ID 物品 ID」,表示一次交互。
def get_user_item_inter():
"""处理ML100k数据集,筛选高质量交互、过滤低活跃度用户并离散化ID,保存为LightGCN可读格式。"""
# 读取原始评分数据
data = pd.read_csv('data/ML100k/ratings.csv')
# 1. 筛选评分 >= 4 的记录(高质量交互)
filtered_data = data[data['rating'] >= 4].copy() # copy避免SettingWithCopyWarning
# 2. 过滤交互数量少于3的用户(确保用户有足够历史行为)
# 统计每个用户的交互次数
user_inter_counts = filtered_data['userId'].value_counts()
# 筛选出交互次数 >=3 的用户ID
valid_users = user_inter_counts[user_inter_counts >= 3].index
# 保留这些用户的交互数据
filtered_data = filtered_data[filtered_data['userId'].isin(valid_users)]
# 3. 离散化用户ID:将原始userId映射为连续整数(从0开始)
unique_users = filtered_data['userId'].unique()
user_id_map = {old_id: new_id for new_id, old_id in enumerate(unique_users)}
filtered_data['user_id'] = filtered_data['userId'].map(user_id_map)
# 4. 离散化物品ID:同理映射为连续整数(从0开始)
unique_items = filtered_data['movieId'].unique()
item_id_map = {old_id: new_id for new_id, old_id in enumerate(unique_items)}
filtered_data['item_id'] = filtered_data['movieId'].map(item_id_map)
# 5. 保留需要的列
processed_data = filtered_data[['user_id', 'item_id', 'rating']]
# 6. 保存处理后的数据
processed_data.to_csv('data/ML100k/processed_interactions.csv', index=False)
# 打印处理信息(增加过滤用户的统计)
print(f"过滤后的数据量:{len(processed_data)} 条")
print(f"过滤后用户数量:{len(unique_users)}(移除了交互次数<4的用户)")
print(f"物品数量:{len(unique_items)}")
print("处理完成,已保存至 processed_interactions.csv")
def get_train_and_test(processed_data, train_ratio=0.9, random_seed=42):
"""
随机划分训练集和测试集(替代时间划分),确保每个用户的交互被随机分配
"""
# 设置随机种子,保证划分可复现
np.random.seed(random_seed)
# 无需按时间排序,直接使用原始数据(但需按用户分组)
data = processed_data.copy()
train_list = []
test_list = []
for user_id, group in data.groupby('user_id'):
n = len(group)
# 确保每个用户至少有1条测试数据
test_size = max(1, n - int(n * train_ratio)) # 测试集数量 = 总样本 - 训练集数量(训练集按比例取)
# 随机抽取测试集的索引(无放回抽样)
# 生成0到n-1的索引,随机打乱后取前test_size个作为测试集
indices = np.arange(n)
np.random.shuffle(indices)
test_indices = indices[:test_size]
train_indices = indices[test_size:]
# 根据随机索引分割训练集和测试集
train = group.iloc[train_indices][['user_id', 'item_id']]
test = group.iloc[test_indices][['user_id', 'item_id']]
train_list.append(train)
test_list.append(test)
# 合并为DataFrame
train_df = pd.concat(train_list, ignore_index=True)
test_df = pd.concat(test_list, ignore_index=True)
# # 验证:检查“必看物品”是否在测试集中出现
# total_users = data['user_id'].nunique()
# item_user_count = data.groupby('item_id')['user_id'].nunique()
# mandatory_items = set(item_user_count[item_user_count >= total_users * 0.1].index)
# test_mandatory = set(test_df['item_id'].unique()) & mandatory_items
# print(f"必看物品: {mandatory_items}")
# print(f"测试集中包含的必看物品: {test_mandatory}") # 随机划分下,应大部分包含
# 保存文件
output_dir = 'data/real/ML100k'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
train_df.to_csv(f'{output_dir}/train.txt', sep=' ', header=False, index=False)
test_df.to_csv(f'{output_dir}/test.txt', sep=' ', header=False, index=False)
print(f"/n训练集规模:{len(train_df)} 条交互")
print(f"测试集规模:{len(test_df)} 条交互")
数据集导入
编写专门用于ML100k的dataSet,用于导入数据,同时预留出fake/_data/_path 导入毒样本
class ML100k(BasicDataset):
"""
ML100K数据集的实现类
继承自BasicDataset,适配LightGCN的图结构需求
"""
def __init__(self, path="../data/ML100k/real",fake_path = '../data/ML100k/fake'):
print("初始化ML100k数据集")
cprint("加载 [ML100K] 数据集")
self.mode_dict = {'train': 0, "test": 1}
self.mode = self.mode_dict['train'] # 默认训练模式
# 读取训练集和测试集(格式:user_id item_id)
train_path = path + '/train.txt'
test_path = path + '/test.txt'
fake_data_path = 'data//ML100k//fake//fake_data.txt'
if os.path.exists(fake_data_path):
# print(114514)
fakeData = pd.read_table(fake_data_path, header=None, sep=' ')
trainData = pd.read_table(train_path, header=None, sep=' ')
testData = pd.read_table(test_path, header=None, sep=' ')
trainData = pd.concat([trainData, fakeData], ignore_index=True)
else:
trainData = pd.read_table(train_path, header=None, sep=' ')
testData = pd.read_table(test_path, header=None, sep=' ')
print(f"train_data_size{len(trainData)}")
# 存储原始数据(ML100K无社交网络,故无trustNet)
self.trainData = trainData
self.testData = testData
# 提取训练集的用户和物品ID(确保为整数类型)
self.trainUser = np.array(trainData[0], dtype=np.int64)
self.trainUniqueUsers = np.unique(self.trainUser) # 去重的训练用户
self.trainItem = np.array(trainData[1], dtype=np.int64)
# 提取测试集的用户和物品ID
self.testUser = np.array(testData[0], dtype=np.int64)
self.testUniqueUsers = np.unique(self.testUser) # 去重的测试用户
self.testItem = np.array(testData[1], dtype=np.int64)
self.Graph = None # 稀疏图(延迟初始化)
# 计算并打印数据集稀疏度
sparsity = (len(self.trainUser) + len(self.testUser)) / (self.n_users * self.m_items)
print(f"ML100K 稀疏度 : {sparsity:.6f}")
# 构建用户-物品交互矩阵(二部图)
self.UserItemNet = csr_matrix(
(np.ones(len(self.trainUser)), (self.trainUser, self.trainItem)),
shape=(self.n_users, self.m_items)
)
# 预计算所有用户的正样本和负样本
self._allPos = self.getUserPosItems(list(range(self.n_users)))
self.allNeg = []
allItems = set(range(self.m_items))
for i in range(self.n_users):
pos = set(self._allPos[i])
neg = allItems - pos # 负样本为未交互物品
self.allNeg.append(np.array(list(neg)))
# 构建测试集字典
self.__testDict = self.__build_test()
@property
def n_users(self):
"""ML100K的用户数量(基于训练集和测试集的最大用户ID+1)"""
return max(np.max(self.trainUser), np.max(self.testUser)) + 1
@property
def m_items(self):
"""ML100K的物品数量(基于训练集和测试集的最大物品ID+1)"""
return max(np.max(self.trainItem), np.max(self.testItem)) + 1
@property
def trainDataSize(self):
"""训练集交互数量"""
return len(self.trainUser)
@property
def testDict(self):
"""测试集字典 {用户: [物品列表]}"""
return self.__testDict
@property
def allPos(self):
"""所有用户的正样本列表"""
return self._allPos
def getSparseGraph(self):
"""构建并返回用户-物品二部图的稀疏矩阵(带对称归一化)"""
if self.Graph is None:
# 转换用户和物品ID为LongTensor
user_dim = torch.LongTensor(self.trainUser)
item_dim = torch.LongTensor(self.trainItem)
# 构建邻接矩阵索引(用户-物品 和 物品-用户 边)
# 物品ID偏移:物品索引 = 物品ID + 用户数量(避免与用户ID冲突)
first_sub = torch.stack([user_dim, item_dim + self.n_users]) # 用户->物品
second_sub = torch.stack([item_dim + self.n_users, user_dim]) # 物品->用户
index = torch.cat([first_sub, second_sub], dim=1) # 形状:[2, E],E为边数
data = torch.ones(index.size(-1), dtype=torch.int) # 边权重为1,数量与边数一致
# 初始稀疏邻接矩阵(改用sparse_coo_tensor)
total_nodes = self.n_users + self.m_items
# 注意:sparse_coo_tensor的indices需为[2, N]形状,data为[N]形状
self.Graph = torch.sparse_coo_tensor(
index, data,
torch.Size([total_nodes, total_nodes]),
dtype=torch.int
)
# 对称归一化:D^-0.5 * A * D^-0.5
dense = self.Graph.to_dense().float() # 转为稠密矩阵
D = torch.sum(dense, dim=1) # 节点度(行和)
D[D == 0] = 1.0 # 避免除零
D_sqrt = torch.sqrt(D).unsqueeze(0) # 度的平方根(行向量)
dense = dense / D_sqrt # 左乘D^-0.5
dense = dense / D_sqrt.t() # 右乘D^-0.5(列向量)
# 提取非零元素的索引和值(关键修复)
# 注意:dense.nonzero()返回的是[N, 2]形状,需转置为[2, N]
index = dense.nonzero().t() # 转置后形状:[2, N]
data = dense[dense.nonzero(as_tuple=True)] # 按非零索引提取值,形状:[N]
# 验证索引和值的数量是否一致
assert index.size(1) == data.size(0), f"索引与值数量不匹配:{index.size(1)} vs {data.size(0)}"
# 构建归一化后的稀疏矩阵(改用sparse_coo_tensor)
self.Graph = torch.sparse_coo_tensor(
index, data,
torch.Size([total_nodes, total_nodes]),
dtype=torch.float
)
self.Graph = self.Graph.coalesce().to(world.device) # 合并重复索引并移至设备
return self.Graph
def __build_test(self):
"""构建测试集字典 {用户: [测试物品列表]}"""
test_data = {}
for i, item in enumerate(self.testItem):
user = self.testUser[i]
if user in test_data:
test_data[user].append(item)
else:
test_data[user] = [item]
return test_data
def getUserItemFeedback(self, users, items):
"""获取用户对物品的交互反馈(1表示有交互,0表示无)"""
return np.array(self.UserItemNet[users, items]).astype('uint8').reshape(-1, )
def getUserPosItems(self, users):
"""获取指定用户的正样本物品列表"""
posItems = []
for user in users:
posItems.append(self.UserItemNet[user].nonzero()[1])
return posItems
def getUserNegItems(self, users):
"""获取指定用户的负样本物品列表(未交互物品)"""
negItems = []
for user in users:
negItems.append(self.allNeg[user])
return negItems
def __getitem__(self, index):
"""按索引返回训练集中的用户ID(供DataLoader迭代)"""
user = self.trainUniqueUsers[index]
return user
def switch2test(self):
"""切换为测试模式"""
self.mode = self.mode_dict['test']
def __len__(self):
"""返回训练集中的用户数量(迭代长度)"""
return len(self.trainUniqueUsers)
第一次训练
第一次训练主要为了获取被攻击模型,用于之后的中毒攻击,训练参数:
--dataset ML100k --testbatch 30 --epochs 600 --layer 4 --recdim 150 --decay 0.001 --lr 0.0001 --comment "ml100k_baseline" --topks "[20]" --decay 0.004
同时编写evaluator.py,用于模型评估并获取top20(用于从众攻击样本生成)
import world # 项目全局配置模块(包含超参数、设备设置等)
import utils # 工具函数模块(包含数据处理、损失计算等)
from world import cprint # 带颜色的打印函数
import torch # PyTorch深度学习框架
import numpy as np # 数值计算库
from tensorboardX import SummaryWriter # 用于记录训练日志和可视化
import time # 时间处理模块
import Procedure # 训练/测试流程控制模块
from os.path import join # 路径拼接工具
import register # 模型和数据集注册器(统一管理模型与数据加载)
from register import dataset # 加载注册的数据集
import model # 模型定义模块(包含LightGCN等模型)
hot_top_dict = {}
user_size = 608
def get_result_evaluator( Recmodel, dataset,target):
"""
自定义评估器加载特定参数文件后进行测试
Args:
Recmodel: 推荐模型实例
dataset: 数据集实例
Returns:
None
"""
u_batch_size = world.config['test_u_batch_size'] # 测试时的用户批大小
dataset: utils.BasicDataset
testDict: dict = dataset.testDict # 测试集字典 {用户: 真实物品列表}
Recmodel: model.LightGCN
Recmodel = Recmodel.eval()
max_K = max(world.topks)
cnt = 0
global hot_top_dict
global user_size
hot_top_dict = {}
# 禁用梯度计算(测试阶段无需更新参数)
with torch.no_grad():
users = list(testDict.keys()) # 测试集中的所有用户
try:
# 检查批大小是否合理(避免批过大导致内存问题)
assert u_batch_size <= len(users) / 10
except AssertionError:
print(f"测试批大小过大,建议调整为 {len(users) // 10}")
# 按批次处理测试用户
for batch_users in utils.minibatch(users, batch_size=u_batch_size):
# 获取该批次用户的训练集正样本(用于过滤,避免推荐已交互物品)
allPos = dataset.getUserPosItems(batch_users)
# 获取该批次用户的测试集真实交互物品
groundTrue = [testDict[u] for u in batch_users]
# 将用户ID转换为张量并移动到设备
batch_users_gpu = torch.Tensor(batch_users).long()
batch_users_gpu = batch_users_gpu.to(world.device)
# 模型预测:获取用户对所有物品的评分
rating = Recmodel.getUsersRating(batch_users_gpu)
# 过滤掉用户已交互的物品(训练集中的正样本)
exclude_index = [] # 要过滤的物品的行索引(用户索引)
exclude_items = [] # 要过滤的物品ID
for range_i, items in enumerate(allPos):
exclude_index.extend([range_i] * len(items)) # 重复用户索引(与物品数匹配)
exclude_items.extend(items) # 该用户已交互的物品
# 将已交互物品的评分设为极小值(确保不会被推荐)
rating[exclude_index, exclude_items] = -(1 << 10)
# 获取评分最高的top-k物品(按max_K取,后续可兼容更小的k)
_, rating_K = torch.topk(rating, k=max_K)
for i in rating_K:
for j in i:
if j.item() not in hot_top_dict:
hot_top_dict[j.item()]=1
else:
hot_top_dict[j.item()]+=1
if j.item() == target:
cnt += 1
# 释放内存(删除原始评分矩阵)
del rating
# # 存储结果
# users_list.append(batch_users)
# rating_list.append(rating_K.cpu()) # 移动到CPU并存储
# groundTrue_list.append(groundTrue)
return cnt
pass
if __name__ == "__main__":
# 在模型初始化后,替换原有的加载逻辑
Recmodel = register.MODELS[world.model_name](world.config, dataset)
Recmodel = Recmodel.to(world.device)
# 定义你要加载的特定参数文件路径
specific_weight_path = "G://tj//Paper//lightGCN//source//code//checkpoints//lgn-ML100k-3-150_best.pth.tar" # 替换为你的文件路径
bpr = utils.BPRLoss(Recmodel, world.config)
world.topks = [20]
# 尝试加载特定参数
try:
# 加载参数文件(map_location确保设备兼容,如CPU/GPU)
state_dict = torch.load(specific_weight_path, map_location=world.device)
# 将参数加载到模型
Recmodel.load_state_dict(state_dict)
world.cprint(f"已成功加载特定参数: {specific_weight_path}")
Procedure.Test(dataset, Recmodel, 0, None, 0)
cnt = get_result_evaluator(Recmodel, dataset,227)
sorted_hot_top = sorted(hot_top_dict.items(), key=lambda x: x[1], reverse=True)
print(user_size)
print(cnt/user_size)
print(cnt)
for i in range(20):
print(f"物品ID: {sorted_hot_top[i][0]}, 出现次数: {sorted_hot_top[i][1]}")
except FileNotFoundError:
world.cprint(f"警告:特定参数文件 {specific_weight_path} 不存在,将使用随机初始化参数")
模型评估结果
热门(top 20)
物品ID: 28, 出现次数: 373 物品ID: 16, 出现次数: 370 物品ID: 22, 出现次数: 363
物品ID: 402, 出现次数: 362 物品ID: 339, 出现次数: 358 物品ID: 13, 出现次数: 337
物品ID: 6, 出现次数: 309 物品ID: 58, 出现次数: 304 物品ID: 139, 出现次数: 278
物品ID: 4, 出现次数: 273 物品ID: 61, 出现次数: 259 物品ID: 615, 出现次数: 255
物品ID: 163, 出现次数: 254 物品ID: 571, 出现次数: 250 物品ID: 20, 出现次数: 241
物品ID: 0, 出现次数: 236 物品ID: 56, 出现次数: 233 物品ID: 479, 出现次数: 232
物品ID: 155, 出现次数: 221 物品ID: 21, 出现次数: 218
结果:
precision@20: 0.13199013 recall@20: 0.24757583 ndcg: 0.23355666
然后是毒样本生成
从众攻击,由于没有评分数据,只有交互数据,所以对于一个假用户,生成的交互中,至少有一个目标物品的交互,其余交互中有80%可能性选取热门物品,20%可能性选择其它随机物品。
def generate_bandwagon_attack(
target_item_id,
ratio=0.01,
begin_user_id=608, # 真实用户最大ID(假用户从该值+1开始)
top_k_num=20,
top_k_list=[], # 预计算的TopK热门物品列表
real_interactions=None, # 原始交互数据(DataFrame:含'user_id','item_id'列)
save_path=None, # 假样本保存路径(如"fake_data.txt")
interaction_per_fake_user=10
):
"""
生成从众攻击假样本并保存为txt文件(格式:用户ID 物品ID)
参数:
target_item_id: 攻击目标物品ID
ratio: 假样本占原始数据的比例
begin_user_id: 真实用户最大ID(假用户ID起始值)
top_k_num: 热门物品数量
top_k_list: 预定义热门物品列表
real_interactions: 原始交互数据(DataFrame,含'user_id','item_id'列)
save_path: 保存路径(若为None则不保存)
返回:
fake_data: 假样本DataFrame('user','item')
"""
# 校验输入
if real_interactions is None:
print("未提供原始交互数据real_interactions")
return
required_columns = ['user_id', 'item_id']
if not all(col in real_interactions.columns for col in required_columns):
print(f"原始数据必须包含列:{required_columns}")
return
if len(top_k_list) == 0:
print("未提供热门物品列表,请检查输入")
return
# 处理热门物品列表
top_k_list = top_k_list[:top_k_num]
print(f"使用预定义Top{top_k_num}热门物品:{top_k_list[:5]}...")
# 计算假样本总量(基于原始交互数据的行数)
total_real = len(real_interactions['user_id'].unique())
total_fake_user = max(1, int(total_real * ratio)) # 至少生成1条
total_fake = total_fake_user * interaction_per_fake_user # 每个假用户生成interaction_per_fake_user条交互
print(f"原始用户数量:{total_real},生成假样本用户数量:{total_fake_user}(占比{ratio*100}%)")
# 假样本生成参数
current_fake_user = begin_user_id + 1 # 假用户起始ID
avg_interactions = 10 # 每个假用户平均交互数
target_required = 1 # 必与目标物品交互1次
remaining_per_user = avg_interactions - target_required
fake_users = []
fake_items = []
# 生成假样本
while len(fake_items) < total_fake:
# 添加目标物品交互
fake_users.append(current_fake_user)
fake_items.append(target_item_id)
current_count = 1
# 填充剩余交互(优先热门物品)
while current_count < avg_interactions and len(fake_items) < total_fake:
# 80%概率选热门物品,20%选非热门
if np.random.random() < 0.8:
# 排除当前用户已交互的物品
user_interacted = [target_item_id] + fake_items[-current_count:]
candidate = [item for item in top_k_list if item not in user_interacted]
if not candidate:
# 热门物品已用尽,随机选其他物品
all_items = set(real_interactions['item_id'].unique()) # 修正:使用'item_id'列
candidate = list(all_items - set(user_interacted))
else:
# 非热门物品(排除热门和已交互)
all_items = set(real_interactions['item_id'].unique()) # 修正:使用'item_id'列
non_top = all_items - set(top_k_list) - {target_item_id}
user_interacted = fake_items[-current_count:]
candidate = list(non_top - set(user_interacted))
# 选一个物品添加
if candidate:
item = np.random.choice(candidate)
fake_users.append(current_fake_user)
fake_items.append(item)
current_count += 1
else:
break # 无候选物品时跳过
current_fake_user += 1 # 下一个假用户
# 去重(避免同一用户重复交互同一物品)
fake_data = pd.DataFrame({'user': fake_users, 'item': fake_items})
fake_data = fake_data.drop_duplicates(subset=['user', 'item'], keep='first')
print(f"最终假样本量:{len(fake_data)},假用户数量:{current_fake_user - begin_user_id - 1}")
# 保存为txt文件(格式:用户ID 物品ID,空格分隔)
if save_path:
fake_data.to_csv(
save_path,
sep=' ', # 空格分隔
header=False, # 无表头
index=False, # 无索引
columns=['user', 'item'] # 确保列顺序
)
print(f"假样本已保存至:{save_path}")
return fake_data
随机攻击,类似于从众攻击,也一定有目标物品的交互,同时对于其它物品有p的概率选择,1-p的概率不选,模拟真实操作
def generate_random_attack(
target_item_id,
ratio=0.01,
begin_user_id=608, # 真实用户最大ID(假用户从该值+1开始)
real_interactions=None, # 原始交互数据(DataFrame:含'user_id','item_id'列)
save_path=None, # 假样本保存路径(如"fake_data.txt")
p=0.7, # 每次选择其他物品交互的概率(1-p为终止概率)
max_interactions=20 # 单个假用户最大交互次数(避免无限循环)
):
"""
生成随机攻击假样本(每个假用户必含目标物品,其余交互按概率p选择物品)
参数:
target_item_id: 攻击目标物品ID
ratio: 假用户数量占原始用户数量的比例
begin_user_id: 真实用户最大ID(假用户ID起始值)
real_interactions: 原始交互数据(含'user_id','item_id'列)
save_path: 假样本保存路径(None则不保存)
p: 每次选择其他物品交互的概率(0 < p < 1)
max_interactions: 单个假用户最大交互次数(防止无限循环)
返回:
fake_data: 假样本DataFrame('user','item')
"""
# 输入校验
if real_interactions is None:
print("未提供原始交互数据real_interactions")
return
required_columns = ['user_id', 'item_id']
if not all(col in real_interactions.columns for col in required_columns):
print(f"原始数据必须包含列:{required_columns}")
return
if not (0 < p < 1):
print("概率p必须满足0 < p < 1")
return
if max_interactions < 1:
print("max_interactions必须大于等于1")
return
# 获取原始物品池(排除目标物品,用于生成其他交互)
all_items = set(real_interactions['item_id'].unique())
if target_item_id in all_items:
other_items = list(all_items - {target_item_id})
else:
print(f"目标物品{target_item_id}不在原始物品池,已添加至假样本")
other_items = list(all_items) # 目标物品单独处理,不影响其他物品选择
# 计算假用户数量
total_real_users = len(real_interactions['user_id'].unique())
total_fake_users = max(1, int(total_real_users * ratio))
print(f"原始用户数量:{total_real_users},生成假用户数量:{total_fake_users}(占比{ratio*100}%)")
fake_users = []
fake_items = []
current_fake_user = begin_user_id + 1 # 假用户起始ID
# 生成假样本
for _ in range(total_fake_users):
# 1. 每个假用户必含目标物品交互
user_interactions = [target_item_id]
fake_users.append(current_fake_user)
fake_items.append(target_item_id)
current_count = 1 # 已生成1条交互(目标物品)
# 2. 按概率p生成其余交互,直到触发终止条件或达最大次数
while current_count < max_interactions:
# 以概率p继续选择物品,1-p终止
if np.random.random() < p:
# 选择未交互过的其他物品
candidate = [item for item in other_items if item not in user_interactions]
if not candidate:
break # 无可用物品,终止当前用户生成
# 随机选择一个候选物品
selected_item = np.random.choice(candidate)
user_interactions.append(selected_item)
fake_users.append(current_fake_user)
fake_items.append(selected_item)
current_count += 1
current_fake_user += 1 # 处理下一个假用户
# 去重(避免同一用户重复交互同一物品)
fake_data = pd.DataFrame({'user': fake_users, 'item': fake_items})
fake_data = fake_data.drop_duplicates(subset=['user', 'item'], keep='first')
print(f"最终假样本量:{len(fake_data)},假用户数量:{current_fake_user - begin_user_id - 1}")
# 保存假样本
if save_path:
fake_data.to_csv(
save_path,
sep=' ',
header=False,
index=False,
columns=['user', 'item']
)
print(f"假样本已保存至:{save_path}")
return fake_data
模型再次训练
进行再训练时,由于前后的嵌入矩阵和邻接矩阵的维度不同,导致无法直接使用第一次的模型权重
第一次训练的模型参数
| 矩阵类型 | 维度 | 含义说明 |
|---|---|---|
| 用户嵌入矩阵 | [M, T] |
M 个原始用户,每个用户的 T 维嵌入向量 |
| 物品嵌入矩阵 | [N, T] |
N 个物品,每个物品的 T 维嵌入向量 |
| 邻接矩阵 | [M+N, M+N] |
用户 - 物品二分图邻接矩阵(用户区 + 物品区) |
| 添加 d 个假用户(毒样本)后,新模型的核心矩阵维度要求: | ||
| 矩阵类型 | 维度 | 含义说明 |
| — | — | — |
| 用户嵌入矩阵 | [M+d, T] |
M 个原始用户 + d 个假用户,共 M+d 个用户嵌入 |
| 物品嵌入矩阵 | [N, T] |
物品数不变,维度保持一致 |
| 邻接矩阵 | [M+N+d, M+N+d] |
扩展后用户区(M+d 个)+ 物品区(N 个)的二分图 |
若直接加载基准模型权重(维度 [M, T])到新模型(维度 [M+d, T]),会因「用户嵌入矩阵行数不匹配」报错 |
||
| 所以在加载模型权重时,需要自定义加载逻辑 | ||
基准模型权重文件(.pth)以 key-value 存储,核心 key 为 embedding_user.weight 和 embedding_item.weight。复用逻辑如下: |
- 加载基准模型的权重字典;
- 对新模型的每个权重 key,仅覆盖「原始维度部分」,「新增维度部分」保持随机初始化;
- 物品嵌入矩阵无新增维度,直接完整覆盖。
# 模型加载逻辑(支持自定义权重路径)
load_path = ""
world.CUSTOM_WEIGHT_PATH = None
world.CUSTOM_WEIGHT_PATH = "code/checkpoints/lgn-ML100k-3-150_best.pth.tar"
if hasattr(world, 'CUSTOM_WEIGHT_PATH') and world.CUSTOM_WEIGHT_PATH:
# 优先使用自定义权重路径
if exists(world.CUSTOM_WEIGHT_PATH):
load_path = world.CUSTOM_WEIGHT_PATH
cprint(f"检测到自定义权重路径: {load_path}")
else:
cprint(f"警告:自定义权重路径{world.CUSTOM_WEIGHT_PATH}不存在,将尝试其他加载方式")
if load_path is None and world.LOAD:
# 未指定自定义路径或自定义路径无效时,使用默认路径
if exists(weight_file):
load_path = weight_file
else:
cprint(f"默认权重文件{weight_file}不存在,将从头开始训练")
# 执行模型加载
if load_path:
try:
# 支持跨设备加载权重
state_dict = torch.load(load_path, map_location=world.device)
model_state = Recmodel.state_dict() # 获取新模型的状态字典
matched_state = {}
for name, param in state_dict.items():
# 只处理名称匹配的参数
if name in model_state:
target_param = model_state[name]
# 检查参数维度是否兼容(新增维度只能在第一维,且原始维度需匹配)
if param.ndim > 0 and target_param.ndim > 0 and param.shape[1:] == target_param.shape[1:]:
# 原始参数长度(如用户嵌入的原始用户数)
src_len = param.shape[0]
tgt_len = target_param.shape[0]
if src_len <= tgt_len:
# 复制原始参数到新模型的对应位置
target_param[:src_len] = param
# 更新状态字典中该参数的值
matched_state[name] = target_param
else:
# 若原始参数长度大于新模型(理论上不应出现,因新模型已扩展)
cprint(f"参数{name}原始长度({src_len})大于新模型长度({tgt_len}),跳过加载")
else:
cprint(f"参数{name}维度不匹配(原始:{param.shape},新模型:{target_param.shape}),跳过加载")
# 将匹配的参数加载到模型中
Recmodel.load_state_dict(matched_state, strict=False)
cprint(f"成功加载模型权重:{load_path},共加载{len(matched_state)}个参数")
except FileNotFoundError:
cprint(f"模型文件{load_path}不存在,将从头开始训练")
except Exception as e:
cprint(f"加载模型失败: {str(e)},将从头开始训练")
而邻接矩阵的维度扩展无需「复用基准矩阵」,而是直接基于「原始训练数据 + 毒样本」重新构建 —— 因为邻接矩阵的核心是「用户 - 物品交互关系」,假用户的交互关系是新增的,无法从基准模型中继承,模型在初始化时就完成了扩展。
六、实验结果
基准模型结果
precision@20: 0.13199013 recall@20: 0.24757583 ndcg: 0.23355666
227 物品:
曝光次数:0
相对曝光率:0.0
不同攻击后的结果
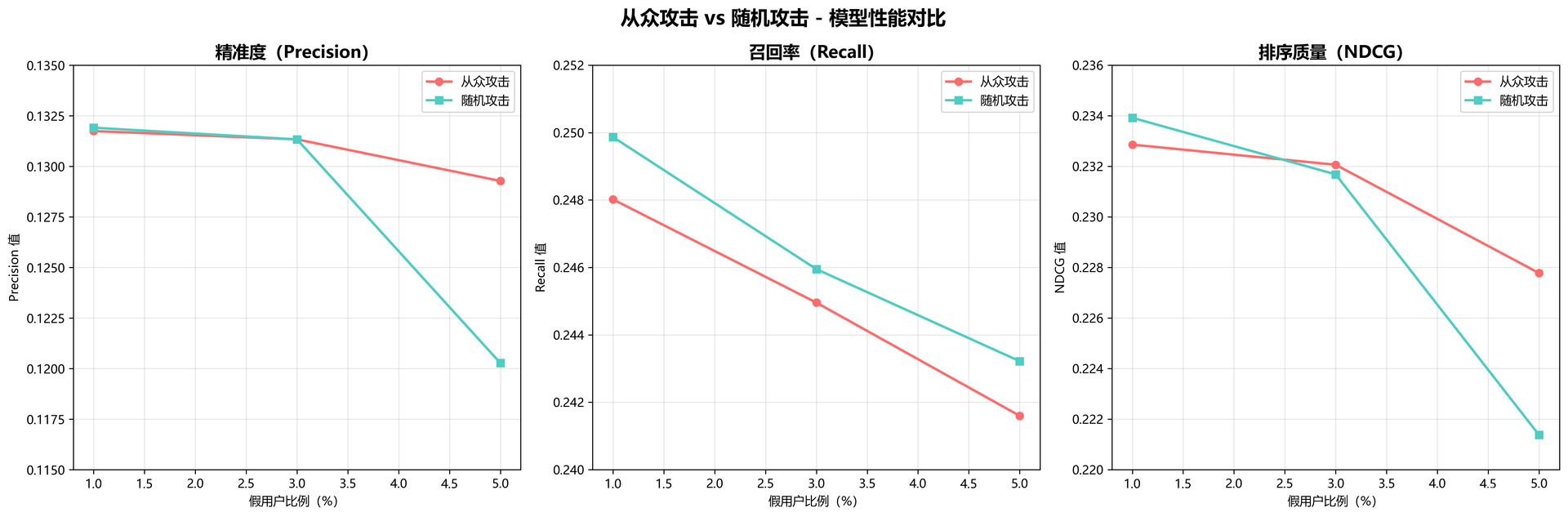
| 攻击类型 | 假用户比例 | 假用户数 | 新增假样本数 | 曝光次数 | 相对曝光率 | precision | recall | ndcg |
|---|---|---|---|---|---|---|---|---|
| 从众攻击 | 1% | 6 | 60 | 6 | 0.0099 | 0.1317 | 0.2480 | 0.2329 |
| 从众攻击 | 3% | 18 | 180 | 30 | 0.0493 | 0.1313 | 0.2450 | 0.2321 |
| 从众攻击 | 5% | 30 | 300 | 112 | 0.1842 | 0.1293 | 0.2416 | 0.2278 |
| 随机攻击 | 1% | 6 | 60 | 1 | 0.0016 | 0.1319 | 0.2499 | 0.2339 |
| 随机攻击 | 3% | 18 | 180 | 2 | 0.0033 | 0.1313 | 0.2460 | 0.2317 |
| 随机攻击 | 5% | 30 | 300 | 5 | 0.0082 | 0.1203 | 0.2432 | 0.2214 |
 |
《网络安全从零到精通全套学习大礼包》
96节从入门到精通的全套视频教程免费领取
如果你也想通过学网络安全技术去帮助就业和转行,我可以把我自己亲自录制的96节 从零基础到精通的视频教程以及配套学习资料无偿分享给你。
网络安全学习路线图
想要学习 网络安全,作为新手一定要先按照路线图学习,方向不对,努力白费。对于从来没有接触过网络安全的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线,大家跟着这个路线图学习准没错。
配套实战项目/源码
所有视频教程所涉及的实战项目和项目源码

学习电子书籍
学习网络安全必看的书籍和文章的PDF,市面上网络安全书籍确实太多了,这些是我精选出来的

面试真题/经验

以上资料如何领取?

文章来自网上,侵权请联系博主

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)