大模型到底怎么思考?一篇看懂 Prompt、思维链、思维树
大模型到底怎么思考?一篇看懂 Prompt、思维链、思维树
1、大模型到底是什么?
“大模型”其实是个广义概念,指的大参数量的机器学习模型,包括语音、视觉等等内容。我们现在常说的大模型其实是大语言模型(Large Language Model),像平时用的豆包、deepseek。
但是,同样是用AI,不同的人会用出不一样的效果,这就要理解大模型的底层逻辑了。大模型并没有完全像人一样去思考,不过一直在进步,你会发现他越来越聪明了。简单来说,大模型的理解其实是在预测,他经过大量的信息学习,其判断每个字后面接下一个字的概率有多高,像 “苹” -> “果”,当然他不只是逐字去预测,他会结合上下文,比如“xxx此处省略100个字xxx”,去预测下一个字,依此类推。因此,我们在提问的时候要进行适当的引导。
起初在我看到网上专门有人教如何给豆包提问题,还不屑一顾,没想到是我外行了。
2、提示工程(prompt engineering)
prompt是人类和AI沟通的语言,我们发给AI的话,都是prompt,那么,如何写好prompt呢?
有一个通用公式:角色定位+上下文+任务指令+输入数据+输出要求+约束条件
- 角色定位:就是要让模型更专业的去分析你的问题,给出答案,例如你是一个资深大模型应用开发工程师,性格温和
- 上下文:背景信息,比如连续问答,遇到有歧义的问题,他可以根据刚刚在聊的内容来猜测你更可能想问什么
- 任务指令:明确核心动作,内容总结、分析推理、计算结果还是判断对错,避免答非所问
- 输入数据:具体问题描述、需总结的文档
- 输出要求:格式化输出便于后续代码解析,字数限制,风格等
- 约束条件:避免一些prompt攻击,比如禁止回答与主题无关的问题
当然,并不是每次提问都要一步一步把每个点都套进去,需要灵活处理。结合前面有一期我们本地部署了ollama-qwen3:4b的本地模型,我们可以上手感受一下提示词的魅力。
本地调用模型需要先启动本地ollama服务:
ollama serve
调用方式一般有两种,一种是调用模型原生接口,一种是通过通用OpenAI接口来调用:
# Ollama原生OpenAPI接口
curl http://127.0.0.1:11434/api/chat -d '{
"model": "qwen3:4b",
"messages": [{"role": "user", "content": "你好"}],
"stream": false
}'
# OpenAI兼容接口
curl http://127.0.0.1:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ollama" \
-d '{
"model": "qwen3:4b",
"messages": [{"role": "user", "content": "你好"}]
}'
返回如下:
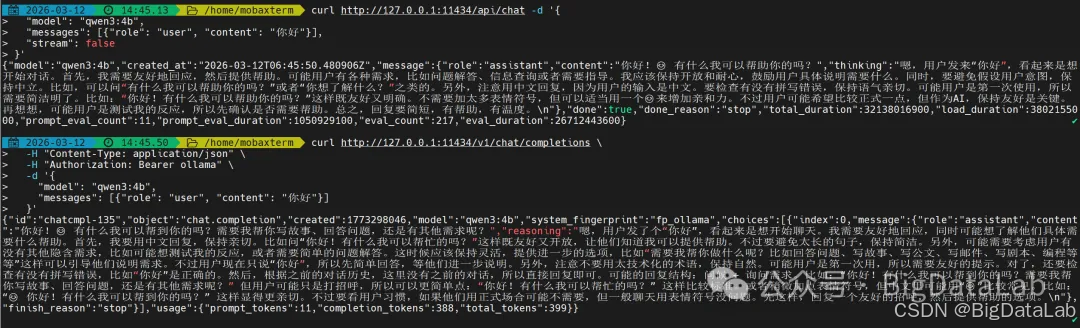
可以看到,两种方式返回的响应体有些许的差异,原生API中返回信息在 “message”[“content”] 中,OpenAI的接口返回在 “choices”[“message”[“content”]] 中,在程序中获取结果时候需要注意下,OpenAI更通用,建议优先用这个。
from openai import OpenAI
# ===================== 配置项(OpenAI兼容模式) =====================
# 指向本地Ollama的OpenAI兼容接口
client = OpenAI(
base_url="http://127.0.0.1:11434/v1", # Ollama的OpenAI兼容前缀
api_key="ollama" # 本地模型任意值即可,仅用于格式兼容
)
MODEL_NAME = "qwen3:4b"
# ===================== OpenAPI规范调用(兼容OpenAI) =====================
def call_local_llm_openai_compatible(prompt, stream=False):
"""
用OpenAI OpenAPI规范调用本地Ollama模型
"""
try:
# 非流式调用
if not stream:
completion = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
stream=False
)
return completion.choices[0].message.content
# 流式调用
else:
completion = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
stream=True
)
def stream_generator():
for chunk in completion:
if chunk.choices[0].delta.content:
yield chunk.choices[0].delta.content #生成器,每次迭代都会返回一个结果
return stream_generator()
except Exception as e:
return f"调用失败:{str(e)}"
# ===================== 测试兼容模式调用 =====================
if __name__ == "__main__":
# 1. 非流式调用(OpenAI OpenAPI规范)
print("=== OpenAI兼容模式-非流式调用 ===")
prompt1 = "请严格按JSON格式输出:{\"name\":\"张三\",\"age\":25,\"job\":\"程序员\"}"
result1 = call_local_llm_openai_compatible(prompt1)
print(result1)
print("-" * 60)
# 2. 流式调用(OpenAI SSE规范)
print("=== OpenAI兼容模式-流式调用 ===")
prompt2 = "请解释OpenAPI接口的核心特点"
stream_gen = call_local_llm_openai_compatible(prompt2, stream=True)
print("模型响应:", end="")
for chunk in stream_gen:
print(chunk, end="", flush=True)
print()
结果大家可以自己本地执行观察下效果。这里面有两个参数说明一下:
- temperature:温度,他是用来控制输出的稳定性,范围 0~2,数值越小,越严谨,例如数学推理计算,数值越大,越发散,适合文章扩写等等。
- stream:True/False,代表是否流式输出,True是逐字输出,False是等全部生成好之后一次性输出。
3、思维链(Chain of Thoughts,CoT)
思维链(CoT)是大模型 Prompt 工程中核心的高级技巧,本质是引导模型 “像人类一样分步思考”,而不是直接给出答案,尤其适合数学计算、逻辑推理、复杂任务拆解等场景,能大幅提升回答的准确性。
下面是几种常用的思维链使用方式,最简单的就直接告诉他,一步步思考,如果他思考的还是不够细,那直接给他指出来要先分析问题,拆解子问题,等等步骤,严格按照我们所说的来思考,再不济,那就给他写几个样例,让他参考我们样例思考的过程去思考。自洽性是指让他多思考几次,更多一致的结果则更可能是我们想要的结果,增加了一些容错性。
| 类型 | 特点 | 适用场景 |
|---|---|---|
| 零样本 CoT | 仅用提示词(如 “让我们一步步思考”)触发模型思考 | 不想写示例的快速场景 |
| 少样本 CoT | 给出 1-2 个 “问题 + 思考步骤 + 答案” 的示例,引导模型模仿 | 复杂问题(如数学竞赛题) |
| 自洽 CoT | 让模型生成多个思考路径,最后取一致答案 | 高精准要求场景(如财务计算) |
可以用下面这段代码来体验一下:
import requests
# 基础配置(适配本地Ollama)
OLLAMA_URL = "http://127.0.0.1:11434/api/generate"
MODEL_NAME = "qwen3:4b"
# 通用调用函数
def call_llm_with_cot(prompt, temperature=0.1):
"""调用本地模型,适配思维链Prompt"""
data = {
"model": MODEL_NAME,
"prompt": prompt,
"temperature": temperature, # 低温度保证推理严谨
"stream": False
}
try:
response = requests.post(OLLAMA_URL, json=data)
response.raise_for_status()
return response.json()["response"]
except Exception as e:
returnf"调用失败:{str(e)}"
# ===================== 场景1:基础CoT(分步思考) =====================
print("=== 场景1:基础CoT ===")
basic_cot_prompt = """
请严格按照「分析问题→拆解步骤→计算结果→总结答案」的步骤解决以下问题:
问题:某商店第一天卖出20件商品,第二天卖出的数量是第一天的1.5倍,第三天比第二天少卖5件,三天总共卖出多少件?
"""
basic_cot_result = call_llm_with_cot(basic_cot_prompt)
print(basic_cot_result)
print("-" * 70)
# ===================== 场景2:少样本CoT(示例引导) =====================
print("=== 场景2:少样本CoT ===")
few_shot_cot_prompt = """
示例1:
问题:小红有8支笔,买了5支,送给同学3支,还剩几支?
思考步骤:
1. 分析问题:需要计算笔的数量增减;
2. 拆解步骤:初始8支 + 新买5支 - 送出3支;
3. 计算:8+5-3=10;
4. 答案:还剩10支。
示例2:
问题:一本书有200页,第一天看了50页,第二天看了剩下的1/3,还剩多少页没看?
思考步骤:
1. 分析问题:先算剩余页数,再算第二天看的,最后算最终剩余;
2. 拆解步骤:
- 第一天看完剩余:200-50=150页;
- 第二天看的页数:150×1/3=50页;
- 最终剩余:150-50=100页;
3. 计算:200-50-(150×1/3)=100;
4. 答案:还剩100页。
请模仿上述示例的思考步骤,解决以下问题:
问题:一个长方形长12cm,宽比长少4cm,这个长方形的周长和面积分别是多少?
"""
few_shot_cot_result = call_llm_with_cot(few_shot_cot_prompt)
print(few_shot_cot_result)
print("-" * 70)
# ===================== 场景3:零样本CoT(无示例,仅提示) =====================
print("=== 场景3:零样本CoT ===")
zero_shot_cot_prompt = """
让我们一步步思考这个问题,确保每一步都准确:
问题:小明从家到学校需要走15分钟,速度是每分钟80米;放学时速度减慢到每分钟60米,放学回家需要走多久?
"""
zero_shot_cot_result = call_llm_with_cot(zero_shot_cot_prompt)
print(zero_shot_cot_result)
print("-" * 70)
# ===================== 场景4:复杂任务拆解(非数学题) =====================
print("=== 场景4:复杂任务拆解CoT ===")
task_cot_prompt = """
请用思维链的方式拆解「开发一个本地文档问答机器人」的任务,要求:
1. 先明确核心目标;
2. 拆解成5个以内的核心步骤;
3. 每个步骤说明关键动作和注意事项。
"""
task_cot_result = call_llm_with_cot(task_cot_prompt, temperature=0.5)
print(task_cot_result)
4、思维树(Tree of Thoughts,ToT)
思维树(ToT)是比思维链(CoT)更高级的大模型推理框架,核心是让模型像人类一样 “分叉思考、评估路径、回溯优化”—— 不仅分步推理,还能探索多个可能的解题路径,淘汰错误方向,选择最优解,尤其适合复杂、多分支、需要试错的任务(如数学竞赛题、逻辑谜题、复杂任务规划)
简单来说,思维树就是从多条路开始走,去遍历各种可能性,然后去评估哪个结果更接近于正确结论,择优选择。
同样给一个样例,亲身感受一下,当然这些代码如何写不用纠结,这些代码网上都有,AI生成的相当完善,重点去理解他的推演过程。
import requests
import json
# ===================== 配置项 =====================
OLLAMA_URL = "http://127.0.0.1:11434/api/generate"
MODEL_NAME = "qwen3:4b"# 本地已下载的模型
TEMPERATURE = 0.5 # 生成多个思路时适度增加随机性
# ===================== 基础调用函数 =====================
def call_ollama(prompt, temperature=0.5):
"""调用本地Ollama模型,返回生成结果"""
data = {
"model": MODEL_NAME,
"prompt": prompt,
"temperature": temperature,
"stream": False,
"max_tokens": 1000# 限制生成长度,避免冗余
}
try:
response = requests.post(OLLAMA_URL, json=data)
response.raise_for_status()
return response.json()["response"].strip()
except Exception as e:
returnf"调用失败:{str(e)}"
# ===================== ToT核心函数 =====================
def tree_of_thoughts(problem, max_depth=3, top_k=2):
"""
思维树(ToT)核心实现
:param problem: 待解决的复杂问题
:param max_depth: 思维树最大深度(中间步骤数)
:param top_k: 每一步保留的最优思路数
:return: 最优解 + 完整推理路径
"""
# 存储完整的思维树(用于回溯和展示)
thought_tree = {
"root": problem,
"nodes": [], # 每个节点格式:{"depth": 深度, "thought": 思路, "score": 评分, "children": []}
}
def generate_thoughts(current_problem, depth):
"""生成当前步骤的多个可能思路"""
prompt = f"""
你需要解决的问题:{current_problem}
当前推理深度:{depth}/{max_depth}
要求:
1. 生成{top_k+1}个可能的解题思路(中间步骤);
2. 每个思路简洁明了(不超过50字);
3. 思路之间要有明显差异(不同的推理方向);
4. 仅输出思路列表,格式:1. 思路1\n2. 思路2\n...
"""
thoughts_str = call_ollama(prompt, temperature=TEMPERATURE)
# 解析思路列表
thoughts = []
for line in thoughts_str.split("\n"):
if line.strip().startswith(("1.", "2.", "3.", "4.", "5.")):
thought = line.strip().split(".", 1)[1].strip()
if thought:
thoughts.append(thought)
return thoughts[:top_k] # 取前top_k个思路
def evaluate_thoughts(thoughts, current_problem):
"""评估思路的可行性,返回(思路,评分)列表(评分1-10,越高越可行)"""
prompt = f"""
待解决问题:{current_problem}
需要评估的思路列表:
{chr(10).join([f"{i+1}. {t}" for i, t in enumerate(thoughts)])}
要求:
1. 为每个思路评分(1-10分,1=完全不可行,10=最优);
2. 评分理由简洁(不超过30字);
3. 仅输出评估结果,格式:
1. 思路1:评分(理由)
2. 思路2:评分(理由)
...
"""
eval_str = call_ollama(prompt, temperature=0.1) # 低温度保证评估严谨
# 解析评分
evaluated = []
for line in eval_str.split("\n"):
if line.strip().startswith(("1.", "2.", "3.", "4.", "5.")):
parts = line.strip().split(".", 1)[1].strip().split(":", 1)
if len(parts) == 2:
thought = parts[0].strip()
score_part = parts[1].split("(", 1)[0].strip()
try:
score = int(score_part)
evaluated.append((thought, score))
except ValueError:
continue
# 按评分排序(降序)
evaluated_sorted = sorted(evaluated, key=lambda x: x[1], reverse=True)
return evaluated_sorted
def expand_tree(current_problem, depth):
"""递归扩展思维树,返回最优思路和最终答案"""
# 终止条件:达到最大深度,生成最终答案
if depth >= max_depth:
final_prompt = f"""
基于当前思路解决问题:{current_problem}
要求:给出最终答案,简洁明了(不超过100字)。
"""
final_answer = call_ollama(final_prompt, temperature=0.1)
return final_answer, []
# 步骤1:生成当前步骤的多个思路
thoughts = generate_thoughts(current_problem, depth)
ifnot thoughts:
return"无法生成有效思路", []
# 步骤2:评估思路,选最优的top_k个
evaluated_thoughts = evaluate_thoughts(thoughts, current_problem)
ifnot evaluated_thoughts:
return"无法评估思路", []
# 步骤3:递归扩展最优思路的子节点
best_thought, best_score = evaluated_thoughts[0]
# 记录当前节点到思维树
thought_tree["nodes"].append({
"depth": depth,
"thought": best_thought,
"score": best_score,
"children": []
})
# 构建下一级问题(基于最优思路)
next_problem = f"基于思路「{best_thought}」,继续解决原问题:{problem}"
# 递归扩展
final_answer, child_paths = expand_tree(next_problem, depth + 1)
# 记录子路径
thought_tree["nodes"][-1]["children"] = child_paths
# 返回当前路径+最终答案
path = [f"深度{depth}:{best_thought}(评分{best_score})"] + child_paths
return final_answer, path
# 启动思维树推理
final_answer, reasoning_path = expand_tree(problem, depth=1)
return {
"final_answer": final_answer,
"reasoning_path": reasoning_path,
"thought_tree": thought_tree
}
# ===================== 测试ToT功能 =====================
if __name__ == "__main__":
# 示例:复杂逻辑谜题(适合ToT的典型场景)
complex_problem = """
逻辑谜题:有5个盒子,分别标有1-5号,每个盒子里装着红、黄、蓝三种颜色中的一种球,满足以下条件:
1. 1号盒子不是红球;
2. 2号盒子和4号盒子颜色相同;
3. 3号盒子是蓝球;
4. 5号盒子不是黄球;
5. 红球数量比黄球多1个。
请推理每个盒子里球的颜色,并说明推理过程。
"""
# 执行ToT推理
print("=== 思维树(ToT)推理开始 ===")
print(f"待解决问题:{complex_problem.strip()}")
print("-" * 80)
result = tree_of_thoughts(
problem=complex_problem,
max_depth=3, # 3层推理深度
top_k=2 # 每步保留2个最优思路
)
# 输出结果
print("=== 推理路径(思维树)===")
for idx, step in enumerate(result["reasoning_path"]):
print(f"{idx+1}. {step}")
print("-" * 80)
print("=== 最终答案 ===")
print(result["final_answer"])
四、总结
- ToT 核心价值:从 “单路径线性推理” 升级为 “多路径树状推理”,解决 CoT 在复杂问题中 “易出错、无回溯” 的痛点,是大模型 Agent 实现复杂决策的核心技术;
- 实现关键:“思路生成→评估→剪枝→递归扩展” 是 ToT 的核心流程,新手可先从简化版 ToT(2 层深度、2 个思路)入手;
- 适配本地模型:结合 Ollama 可完全本地化实现 ToT,无需依赖云端,适合隐私敏感的复杂推理场景。
总结
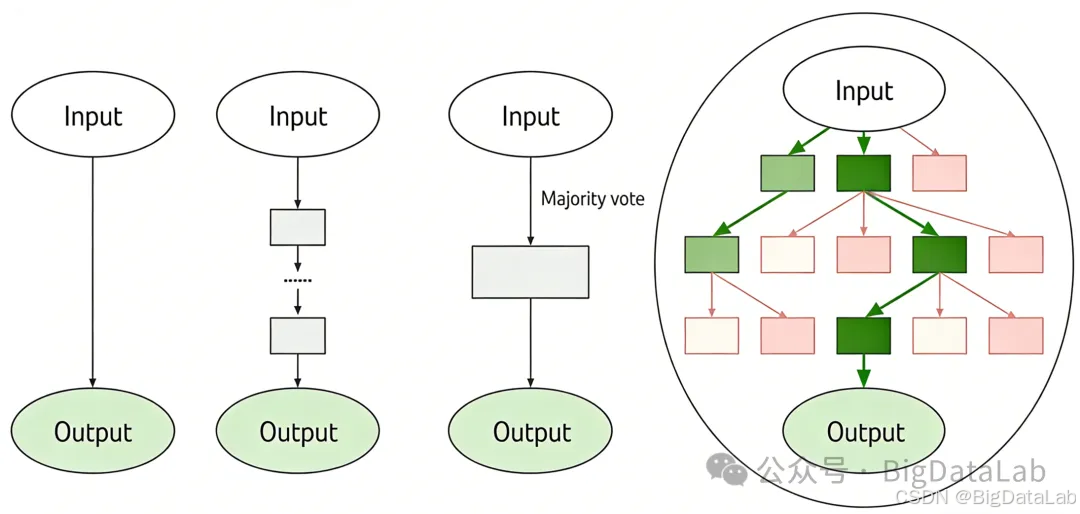
从左到右依次是 基本问答(Input-Output Prompting)、思维链(Chain of Thought Prompting)、自洽性思维链(Self Consistency with CoT)、思维树(Tree of Thought)。
看图应该能够直观感受到这几种方式之间的关系了吧。
基本的prompt就是直问直答,思维链是把思考过程加入进来,一条路走到黑,而思维树是同时走多条路,选最优的一条。
————————THE END————————
今天的内容就分享到这里。【原文链接】
有问题欢迎留言交流,也可以加我微信深入探讨(公众号:BigDataLab)。
关注我,不错过每一篇干货,下期继续为你带来更实用的内容!
(如果需要python、大数据、大模型相关学习资料,欢迎公众号“BigDataLab”留言“资料”)
————————精彩推荐————————

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)