无需配对图文?解析MIT新视角:利用无配对多模态数据增强单模态表征

近年来,多模态大模型(如CLIP、BLIP)在视觉和语言任务上取得了显著进展。然而,这些模型的高效表征能力高度依赖于海量的“配对数据(Paired Data)”——即图像与描述文本之间存在严格的一一对应关系。在医疗影像、科学计算等专业领域,获取高质量的配对数据成本极高。
来自麻省理工学院(MIT)和慕尼黑工业大学的研究团队在2025年10月发表的《Better Together: Leveraging Unpaired Multimodal Data for Stronger Unimodal Models》中提出了一个具有启发性的假设:即使图像和文本在样本层面上互不相关(即无配对),只要将它们置于一个包含共享参数的网络中进行训练,依然能够有效提升单一模态(如视觉)的表征能力。
本文将结合该论文的理论推导、底层代码实现以及实验现象,对这一框架(UML)进行拆解,并探讨其工程设定与理论边界。
一、 核心概念界定:何为“无配对(Unpaired)”?
在多模态学习中,数据配对关系通常可以划分为三个层级。理解本论文的前提,是厘清作者所定义的“无配对”究竟处于哪个层级。

样本级配对(Sample-level Paired): 如图2(a)所示,特定图像必须与特定文本严格绑定。这是CLIP等模型的标准训练数据。
类别级配对(Class-level Paired): 如图2(b)所示,图像和文本独立采样,它们之间没有样本级对应关系,但共享同一套类别标签体系。例如,网络读取一张带有“狗”标签的随机图像,随后读取一句带有“狗”标签的随机百科描述。
完全无标签(Unlabeled Unpaired): 如图2©所示,仅有两堆完全独立的图像与文本,既无样本对应,也无标签桥梁。
通过对该论文开源代码仓库(如 finetune.py)的分析可以确认,该研究在绝大多数核心实验中,采用的是图2(b)的设定。其所谓的“无配对”,是指放弃了昂贵的样本级映射,转而通过低成本的“类别标签(Class Label)”来实现模态间的隐式对齐。
值得指出的是,这篇论文在实际的交替训练和绝大多数核心实验中,用的100%是 (b)(带标签的无配对数据)。在他们最亮眼的图文增强实验里,并没有真正使用 ©(完全无标签的无配对数据)。在论文的宏大叙事(比如图 2 的定义)和 Fisher 信息的纯数学推导中,作者确实把 © 囊括了进去,暗示 UML 可以在没有任何标签的情况下,纯靠底层的物理规律共享来学习。但在实际的工程落地中,他们巧妙地回避了纯粹的 ©。因此这篇论文在理论上画饼,如果要真刀真枪地做 ©,模型不能有分类头。它必须是一个底层的生成式大模型(比如一个共享的 Transformer Backbone),同时跑图像的“掩码重建(MAE)”和文本的“预测下一个词(Causal LM)”。工程实现上如果没有任何配对信号,也没有标签牵线搭桥,你把一堆毫不相干的纯图像像素和纯文本单词扔给同一个网络,网络极大概率会发生**“模态隔离(Modality Isolation)”或“灾难性遗忘”**——即网络里的某几层专门处理图像,另几层专门处理文本,大家井水不犯河水,根本起不到任何“互相增强”的作用。从作者开源的代码看底层全都是在做有监督的分类(Supervised Classification)。这意味着,整篇论文的实验地基都是建立在 (b) 上的。
这篇论文体现了当前AI顶会论文的一个现象:**用最极限的愿景讲故事,用取巧的方法跑实验。**作者会拿 © 来说事,强调“你看,真实世界里的数据都是既没配对也没标签的,我们提出了一种不需要配对的神奇框架 UML!” 这极大提升了论文的格局和理论深度。真正到了刷榜、拼准确率的时候,作者会悄悄退回到 (b)。因为引入极其廉价的类别标签(Class Labels),或者用 GPT-3 生成带有明确意图的文本,是一条极其高效的“作弊/捷径”。它在工程上极其 Work,能画出非常漂亮的涨点曲线。这篇论文的工程本质其实是:“一种基于共享分类器和类别标签的、跨模态多任务监督学习(Multi-task Supervised Learning)”
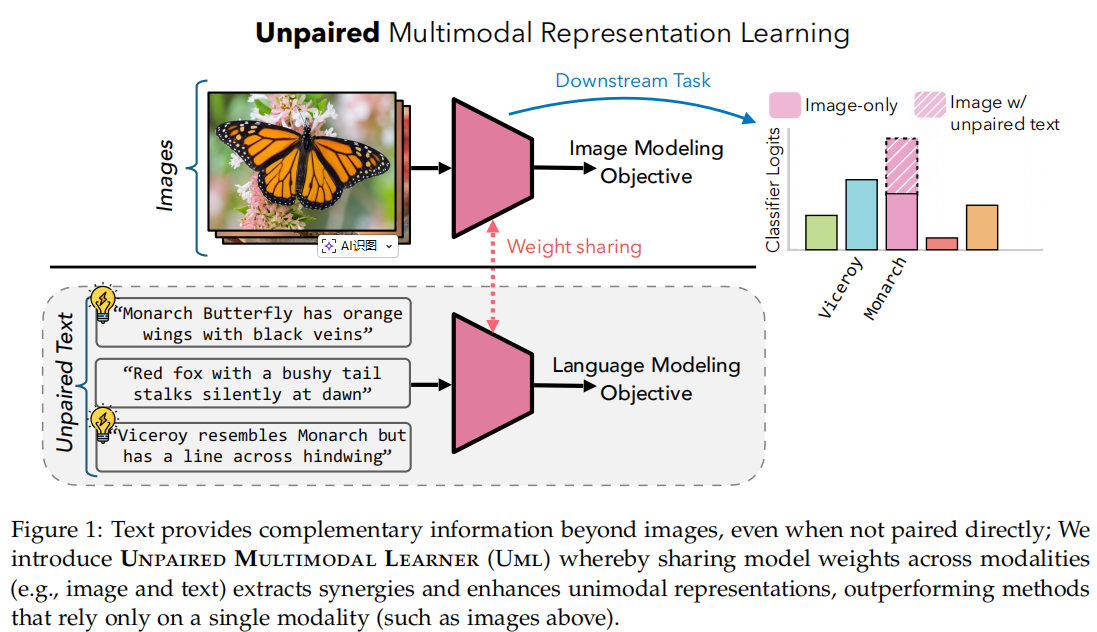
论文中图1是整篇文章的核心概念图。左侧 (Image-only,纯视觉路径)是传统的单模态模型,只通过看图来学习。由于 Monarch 和 Viceroy 在视觉上极其相似(这在生物学上称为拟态),纯视觉模型如果缺乏足够多、足够清晰的训练图像,很难自行摸索出区分它们的关键特征,容易导致分类混淆。右侧 (Image w/ unpaired text,UML 路径)作者引入了额外的文本数据。请注意,这些文本(如“Monarch Butterfly has orange wings with black veins / 黑脉金斑蝶有橙色翅膀和黑色脉络” 以及 “Viceroy resembles Monarch but has a line across hindwing / 副王蛱蝶形似黑脉金斑蝶,但后翅有一条横线”)并不需要与特定的图像样本一一绑定。只要把这些描述性文本作为辅助信息提供给模型,文本就能提供超越纯图像的“互补信息(complementary information)”。图 1 中间的连接线和模块展示了 UML 是如何消化这些无配对数据的,图像走图像的建模目标(Image Modeling Objective),文本走文本的建模目标(Language Modeling Objective)。它们在输入端完全解耦,不需要昂贵的 (image,text)(image, text)(image,text) 数据对。图中的核心字眼是 “Weight sharing (权重共享)”。在源码中的 self.head。视觉特征和文本特征最终都会汇聚到同一个分类器(Classifier Logits)中进行预测。 因为文本中明确指出了“后翅有一条横线(line across hindwing)”这个区分 Viceroy 的致命特征,分类头在处理文本数据时,会强化对这一概念的权重。由于权重是共享的,当视觉特征流入这个分类头时,它会被迫“顺藤摸瓜”,去图像中寻找对应的视觉模式(横线)。
二、 理论基础:基于Fisher信息量的方差缩减
该论文的学术贡献在于,为“无配对多模态学习”提供了严谨的统计学证明。作者利用线性观测模型(Linear Observation Model)解释了为何不配对的文本能够提升视觉分类的准确率。这篇论文的理论证明之所以“漂亮”,是因为它用极其严密的统计学公式,证明了一个充满哲学意味的直觉:“盲人摸象时,即使两个盲人从不交流(不配对),只要他们摸的是同一头大象(共享物理概念),他们各自的认知也会变得更准确。”
为了让大家不仅能看懂,还能体会到其中的数学美感,我尽量避开繁杂的微积分,用**“核心设定 →\rightarrow→ 数学直觉 →\rightarrow→ 终极推导”**的三步逻辑,为你拆解它的 Fisher 信息量证明过程。
第一步:物理世界的数学建模
作者首先用一个线性观测模型 (Linear Observation Model) 来描述多模态数据是如何生成的。
假设真实世界中有一只“狗”,这只狗的本质概念是一个高维向量 θc\theta_cθc (Shared Concept / 共享概念)。
-
图像 xxx 的生成: 照相机拍下这只狗。图像 xxx 包含了 θc\theta_cθc,但也包含了只属于视觉的冗余噪声 θx\theta_xθx(比如杂乱的光影、背景),再加上传感器噪声 ϵx\epsilon_xϵx。
数学表达:x=Aθc+Bθx+ϵxx = A\theta_c + B\theta_x + \epsilon_xx=Aθc+Bθx+ϵx
-
文本 yyy 的生成: 一个人用文字描述这只狗。文本 yyy 也包含了 θc\theta_cθc,但也包含只属于语言的冗余 θy\theta_yθy(比如语法结构、废话),再加上人类的主观噪声 ϵy\epsilon_yϵy。
数学表达:y=Cθc+Dθy+ϵyy = C\theta_c + D\theta_y + \epsilon_yy=Cθc+Dθy+ϵy
无论图像和文本是否配对,它们的底层都受同一个 θc\theta_cθc 驱动。这就为“无配对学习”埋下了数学伏笔。
第二步:定理 1 & 2 —— 为什么不配对也能降低误差?
在统计学中,我们要评估一个模型对 θc\theta_cθc(狗的本质)学得准不准,看的是**“估计方差 (Variance)”。方差越小,模型越准。 而大名鼎鼎的克拉美-罗下界 (Cramér-Rao Lower Bound)** 告诉我们一个铁律:
Variance(θ^c)≥I−1\text{Variance}(\hat{\theta}_c) \ge \mathcal{I}^{-1}Variance(θ^c)≥I−1
其中,I\mathcal{I}I 就是 Fisher 信息矩阵 (Fisher Information Matrix, FIM)。
定律:Fisher 信息量 I\mathcal{I}I 越大,模型估计的误差(方差)下界就越小。
【证明逻辑的惊艳之处】:在统计学中,对于独立同分布的观测数据,它们的 Fisher 信息矩阵是直接线性相加的!如果你只有 NNN 张图像,你的信息量是:Iimage∝N⋅(ATA)\mathcal{I}_{image} \propto N \cdot (A^T A)Iimage∝N⋅(ATA)如果你此时拿来 MMM 句文本。注意,哪怕这 MMM 句文本和那 NNN 张图像完全不配对,只要它们描述的都是真实世界的概念,它们自带的信息量 Itext∝M⋅(CTC)\mathcal{I}_{text} \propto M \cdot (C^T C)Itext∝M⋅(CTC) 就会直接加到总信息池里!
总信息量:Itotal=Iimage+Itext\mathcal{I}_{total} = \mathcal{I}_{image} + \mathcal{I}_{text}Itotal=Iimage+Itext
因为 Itext\mathcal{I}_{text}Itext 是一个半正定矩阵,一个矩阵加上一个半正定矩阵,其所有的特征值(Eigenvalues,代表各个方向上的信息量)必定严格增加。既然 I\mathcal{I}I 严格变大了,那么它的逆矩阵 I−1\mathcal{I}^{-1}I−1 就严格变小了。
数学结论(定理 1&2): 引入无配对文本,严格增加了共享概念方向上的 Fisher 信息,从而在数学上保证了视觉模型误差的绝对下降!
第三步:定理 3 —— (一图为何胜千言)
定理 1 和 2 只是证明了“有用”,但定理 3 证明了**“为什么另一模态的数据极其有用(跨模态边际收益巨大)”**。这是全篇推导的最高潮。
假设我们用模型的整体误差 E=Trace(I−1)E = \text{Trace}(\mathcal{I}^{-1})E=Trace(I−1)(即协方差矩阵的迹)来衡量模型有多笨。
作者在这里引入了高级线性代数中的 Woodbury 矩阵求逆引理,对误差 EEE 求方向导数。
**【盲区理论】:**假设你的视觉数据集(图像)在某个概念方向 vvv 上存在“信息盲区”(比如视觉很难识别物体的“柔软度”或“气味”),这意味着 Iimage\mathcal{I}_{image}Iimage 在 vvv 方向上的特征值 λ\lambdaλ 极其微小(接近于 0)。
- **如果你在同模态(视觉)里死磕,增加 1 张新图片:**数学推导表明,由于新图片大概率还是看不出“柔软度”,误差的下降速度正比于 1λ\frac{1}{\lambda}λ1。
- 如果你跨模态,增加 1 句描述“这东西很柔软”的文本:文本矩阵 Itext\mathcal{I}_{text}Itext 在 vvv 方向上的特征值是巨大的。根据矩阵求逆引理展开,引入这句文本后,总体误差的骤降速度正比于 1λ2\frac{1}{\lambda^2}λ21 !(注意这个平方)。
【最通俗的理解】:当 λ\lambdaλ 非常小(接近 0)时,1λ2\frac{1}{\lambda^2}λ21 的数值会指数级地大于 1λ\frac{1}{\lambda}λ1。
这意味着:当你在一项任务上缺乏某种维度的信息时,你在原地(同模态)疯狂堆叠 1000 个同质化样本,其带来的误差下降(信息增量),都不如别人从另一个维度(跨模态)轻轻给你提供 1 个正交视角的样本!
这篇论文的证明漂亮在于它没有玩弄花哨的深度学习 Loss 技巧,而是退回到了最老派的参数估计与统计推断(Fisher Information & CRLB)。它用极其严谨的矩阵代数(半正定矩阵求逆、迹的导数)向学界证明了:
- 不配对没事: 只要大家都在观察同一个客观世界(共享 θc\theta_cθc),信息量就能线性累加。
- 跨界填补: 填补认知盲区(接近 0 的特征值)最有效的方法,永远是引入另一个拥有正交特征空间(不同模态)的数据,这会带来 1λ2\frac{1}{\lambda^2}λ21 级别的误差暴降。这就是“一图胜千言”或“一言点醒梦中人”的底层数学原理。
三、 工程实现:UML框架的极简设计
从纯数学理论走向工程落地,作者提出了 UML(Unpaired Multimodal Learner)框架。结合其开源代码(head.py 与 finetune.py),可以看到一种直接且有效的多任务学习架构。
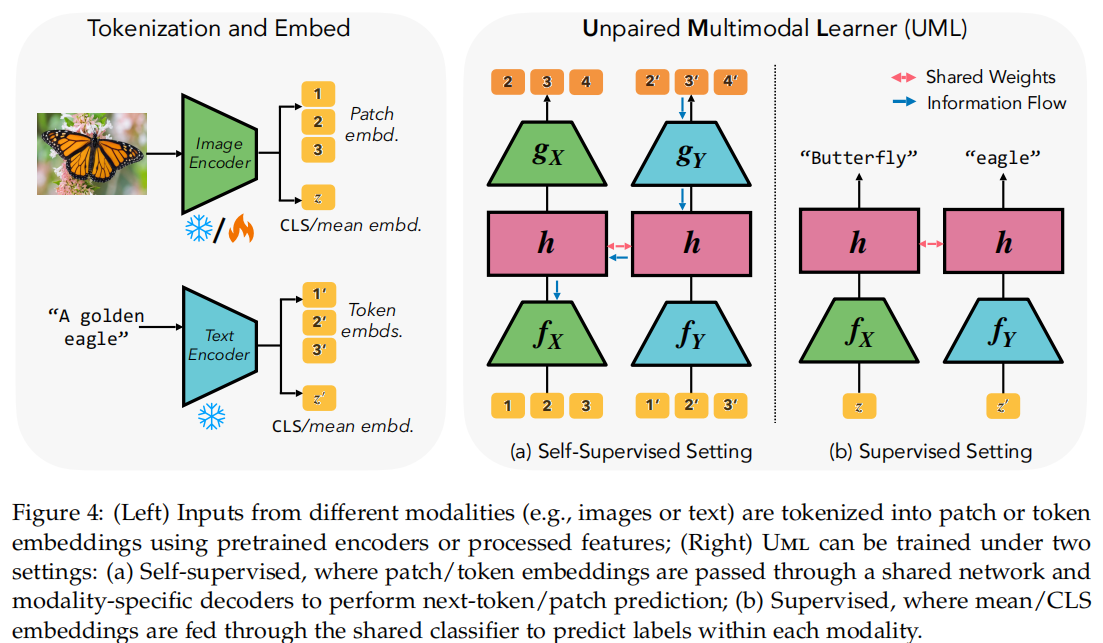
UML的核心架构并不复杂,主要包含以下机制:
输入解耦与独立编码: 图像和文本分别经过各自的编码器(例如可微调的 DINOv2 视觉编码器和冻结的 CLIP 文本编码器),提取特征。
跨模态权重共享(Weight Sharing): 这是 UML 的灵魂。视觉和文本特征最终都会被送入同一个线性分类头(在代码中定义为 self.head)。
交替优化: 在训练时,图像批次计算 image_loss,文本批次计算 text_loss(均为交叉熵损失)。关键在于,这两个损失在反向传播时,都会更新共享分类头的权重。例如,关于“狗”的图像和文本都在共同打磨分类头中对应“狗”的那组参数。视觉编码器在适配这个分类头时,便隐式吸收了文本带来的先验知识。
零样本初始化(Zero-shot Initialization): 在训练之初,代码先提取各类别的文本特征均值,直接作为分类头的初始权重。这一策略有效加速了收敛,并在初始阶段为视觉网络注入了语言先验。
四、 实验现象:“一图胜千言”的量化度量
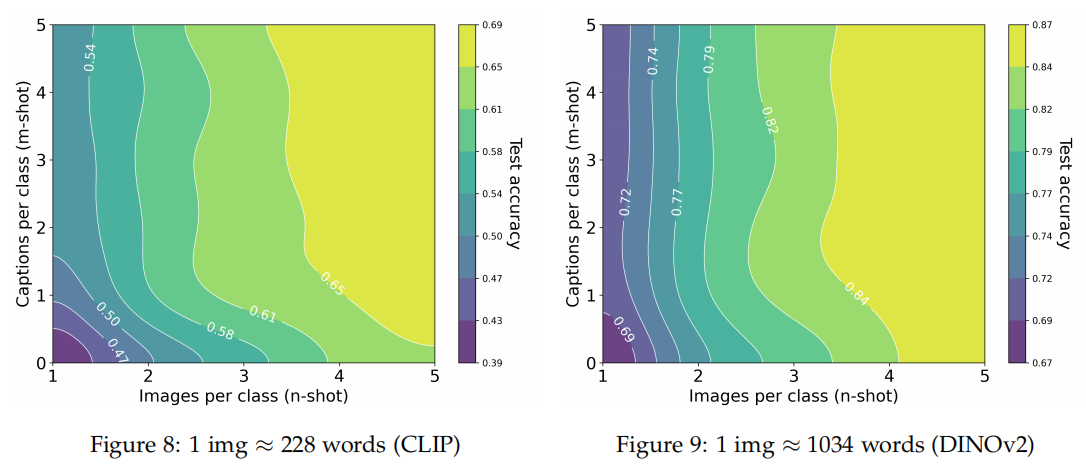
在实验部分,该论文除了证明无配对文本能显著提升细粒度分类准确率及分布外泛化能力,还设计了一个极具启发性的实验:利用边际替代率(Marginal Rate of Substitution, MRS)量化“一张图到底等价于多少句话”。
通过构建由图像数量和文本数量共同决定的等精度曲线(Iso-accuracy curve),作者计算了在保持模型准确率不变的前提下,减少一张图像需要补充多少句文本。
- 在 DINOv2 空间中: 1 张图像的价值 ≈\approx≈ 1034 句文本。因为 DINOv2 是纯视觉自监督模型,其特征空间未与语义对齐,需要海量的文本描述才能弥补一张复杂图像带来的高维物理信息损失。
- 在 CLIP 空间中: 1 张图像的价值 ≈\approx≈ 228 句文本。由于 CLIP 预训练时已完成图文对齐,文本的指导效率显著提升。
这一实验用严谨的控制变量法,为多模态学习中的“模态信息密度”建立了一个客观的度量标尺。
五、 探讨与局限性分析
作为一项探索性研究,《Better Together》提供了一个新颖的视角,但从算法落地的角度审视,该框架仍存在一些需要注意的边界与局限性:
- 对标签绑定(Label-binding)的依赖: 如前文所述,其实际工程落地是基于图2(b)设定的多任务监督学习。它虽然规避了样本对齐的成本,但依然强依赖于人工制定的类别体系。若要应对图2©中完全无标签的真实开放世界数据,基于共享分类器的机制将不再适用。
- 理论与深度网络的非线性鸿沟: 论文中的 Fisher 信息量证明建立在简化的线性观测模型基础之上。而现代的 Vision Transformer 和 LLM 是高度复杂的非线性流形映射。在复杂的非线性空间中,跨模态特征的简单融合是否会引发一定程度的模态干扰或遗忘,仍需进一步探究(代码中冻结文本编码器也在一定程度上是为了规避此类风险)。
- 对文本数据质量的敏感性: 论文消融实验表明,仅使用简单的类别名称(如 “Dog”)带来的性能提升有限。框架的显著收益很大程度上归功于使用了大语言模型(如 GPT-3)生成的、包含丰富属性细节的细粒度描述文本。这意味着外部世界知识的质量是该方法奏效的关键条件。
小结
这篇论文跳出了多模态学习必须依赖“图文对”的传统范式,通过共享权重的机制证明了类别级关联也能实现跨模态的知识迁移。这对于难以获取配对数据的垂直领域(如医学诊断、工业缺陷检测)具有重要的指导意义。未来如何进一步剥离对类别标签的依赖,迈向真正的无监督无配对多模态学习,将是该方向值得期待的下一步突破。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)