mac本地部署大模型:oMLX 项目
·
oMLX 项目分析报告
1. 项目介绍
项目地址:
oMLX 是一个专为 Apple(M1/M2/M3/M4/M5 系列芯片)深度优化的本地大语言模型(LLM)推理服务器,基于 Apple 的 MLX 框架,提供了一个原生的 macOS 菜单栏应用。
支持文本生成、多模态视觉(VLM)、嵌入(Embedding)及重排序(Reranker)等任务,是 Claude Code 和 Cursor 等编程助手的理想本地后端。
2. 核心原理
oMLX 通过以下技术实现超越传统推理引擎的性能:
- 分层 KV 缓存 (Tiered KV Cache):
- 热缓存 (RAM): 活跃对话数据保留在内存中。
- 冷缓存 (SSD): 不常用数据以 safetensors 格式转储至磁盘。
- 优势: 支持跨重启的上下文持久化,大幅减少重复 Prefill 的计算开销。
- 连续批处理 (Continuous Batching): 允许在处理现有请求的同时加入新请求,最大化 Apple GPU 的并行吞吐量。
- 内存保护机制: 自动预留系统内存(默认保留 8GB),防止模型占用过多资源导致 macOS 系统卡死。
3. 安装方式
方式 A:macOS 应用(推荐)
- 前往 GitHub Releases 页面下载 .dmg 安装包。
- 将 oMLX.app 拖入 Applications 文件夹。
方式 B:Homebrew 命令
执行以下命令:
brew tap jundot/omlx [https://github.com/jundot/omlx](https://github.com/jundot/omlx)
brew install omlx
brew services start omlx
方式 C:源码编译
git clone [https://github.com/jundot/omlx.git](https://github.com/jundot/omlx.git)
cd omlx
pip install -e .
4. 使用说明
4.1 模型管理
- 自动发现: 在设置中指定 Model Directory,oMLX 会自动扫描并分类本地的 MLX 模型。
- 一键下载: 在 Admin 面板可直接从 HuggingFace 搜索并获取模型。
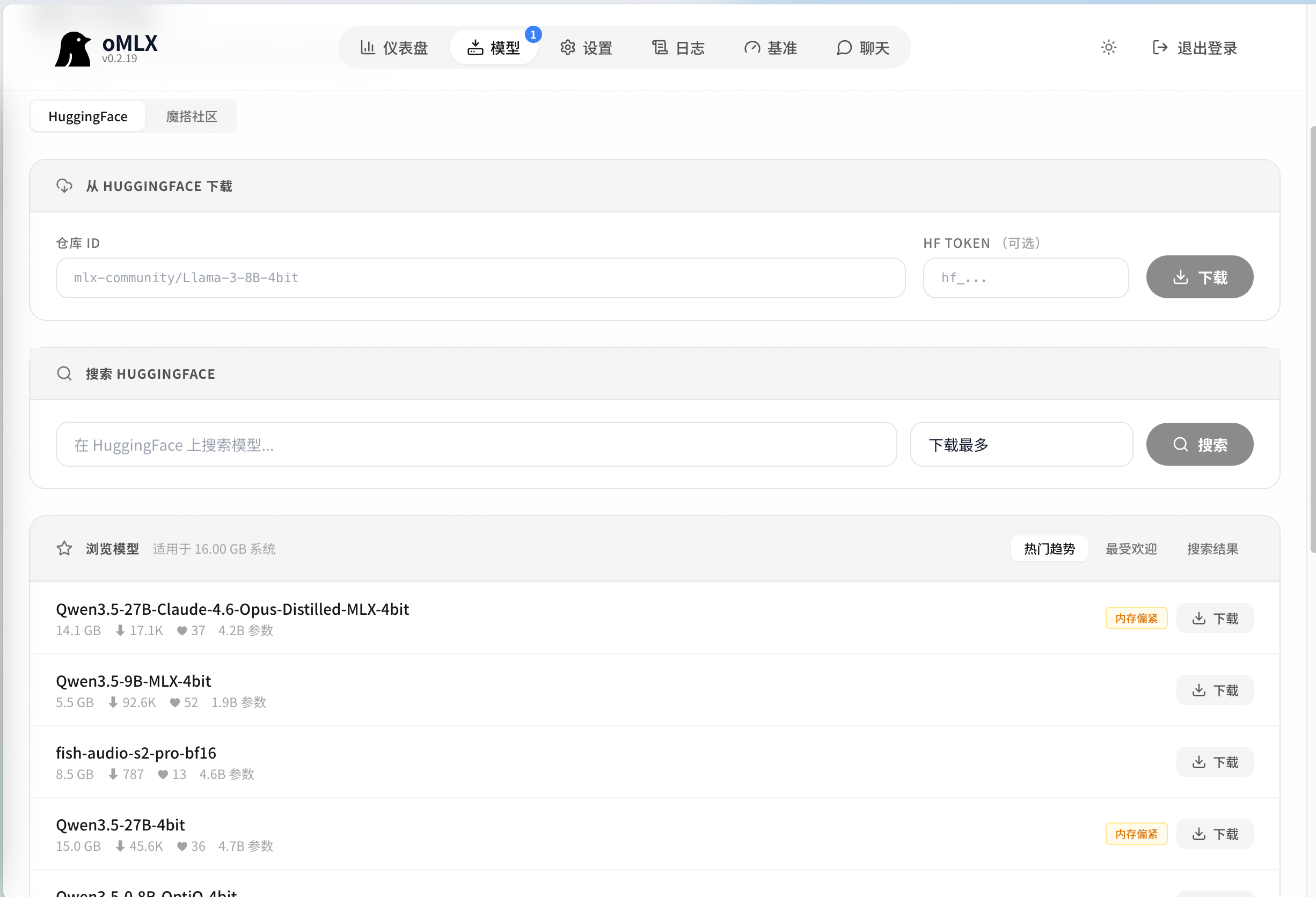
4.2 接口调用
oMLX 启动后会监听 12345 (你设置的端口)端口,支持以下协议:
- OpenAI 兼容: http://localhost:8000/v1/chat/completions
- Anthropic 兼容: 适配 Claude Messages API。
4.3 Web 管理界面
访问 http://localhost:12345(你设置的端口)/admin 可实时监控:
- 模型显存占用与加载状态。
- 手动 Pin(锁定)模型,防止被 LRU 算法自动释放。
- 内置 Playground 进行多模态对话测试。
5. 使用
响应速度相较ollama快了非常多,推荐mac使用作为本地模型部署平台
根据16G内存推荐,安装Qwen3.5-9B-MLX-4bit,模型对话: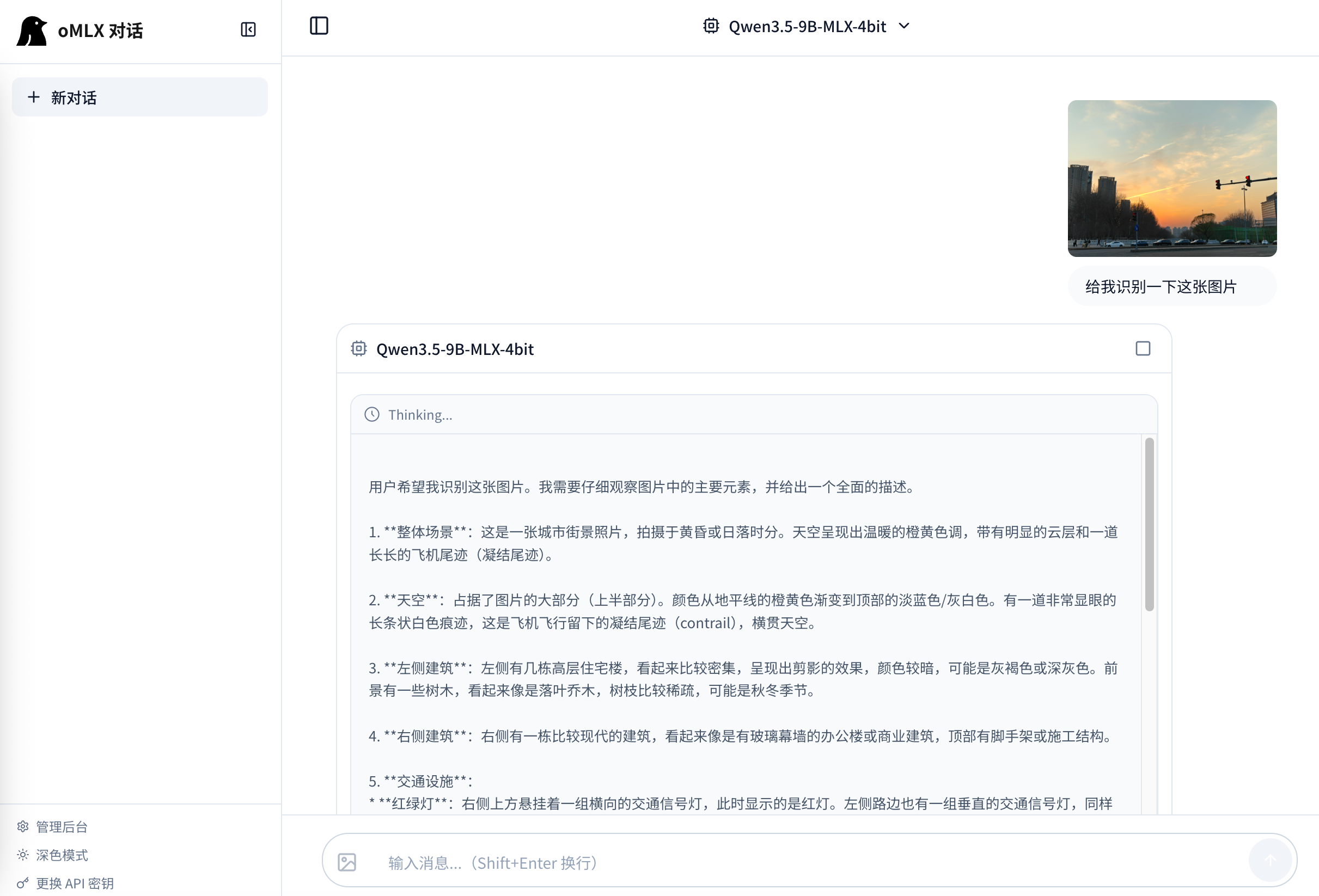
可以通过本地模型启动claude code(效果较差)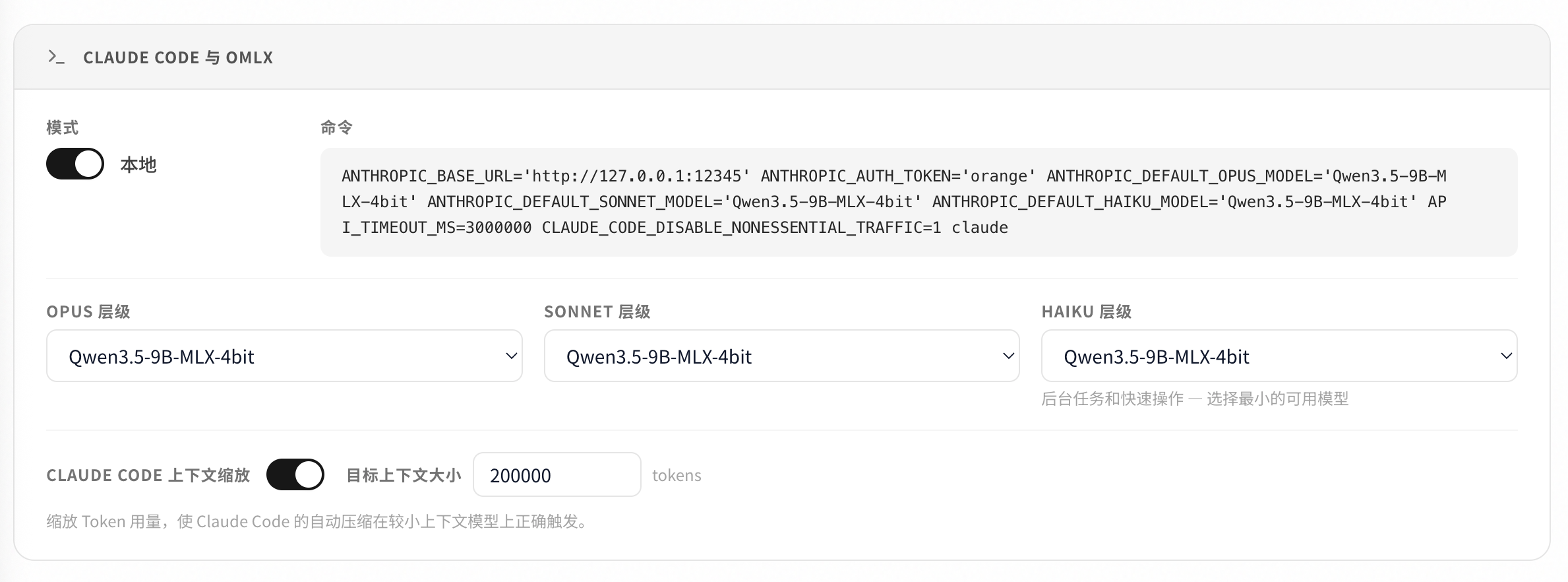
可以使用作为主模型的补充,用于完成一些较为简单的任务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)