DreamDojo:基于大型人类视频的通用机器人世界模型
26年2月来自Nvidia、香港科大、加州伯克利分校、华盛顿大学、斯坦福大学、韩国KAIST、多伦多大学、UCSD和 UT Austin的论文“DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos”。
能够模拟不同环境下的动作结果将彻底革新大规模通用智体的开发。然而,由于数据覆盖范围有限和动作标签稀缺,对这些世界动态进行建模,尤其是在灵巧机器人任务中,面临着巨大的挑战。为了实现这一目标,提出 DreamDojo,一个基础世界模型,它从 4.4 万小时以自我为中心的人类视频中学习各种交互和灵巧控制。这个混合数据集是迄今为止用于世界模型预训练的最大视频数据集,涵盖各种日常场景,涉及不同的物体和技能。为了解决动作标签稀缺的问题,引入连续潜动作作为统一的代理(proxy)动作,从而增强从无标签视频中迁移交互知识的能力。在小规模目标机器人数据上进行后训练后,DreamDojo 展现出了对物理的深刻理解和精确的动作控制能力。还设计一个蒸馏管道,将 DreamDojo 的运行速度提升至 10.81 FPS 的实时速度,并进一步提高上下文一致性。
互联网规模的视频是激发涌现能力的一个引人入胜的来源(Wiedemer et al., 2025; Yang et al., 2024),但动作标签的缺失可能会显著阻碍学习效率。为了解决这个问题,潜动作最近被提出作为一种从无标签视频中学习的有效方法(Bu et al., 2025; Jang et al., 2025; Schmidt and Jiang, 2024; Ye et al., 2025; Zhang et al., 2025)。除了作为策略学习的监督信息外,潜动作还可以用作世界模型的控制接口(Bruce et al., 2024; Chen et al., 2024; Gao et al., 2025; Garrido et al., 2026; Wang et al., 2025)。多项研究也证明了连续潜动作的有效性(Gao et al., 2025; Liang et al., 2025; Liu et al., 2025; Yang et al., 2025)。受这些研究的启发,本文提取潜动作作为基础世界模型的统一代理,并研究这种方法如何在适应新的具身形态后,促进与未见过对象交互时的鲁棒泛化。
自回归视频生成方法为交互提供最精细的粒度和灵活性(Weng et al., 2024),非常适合动作条件世界建模(Bruce et al., 2024; Gao et al., 2025; Huang, 2025; Valevski et al., 2025)。为了加快推理速度,以往的方法(Lin et al., 2025; Yin et al., 2025)将双向模型简化为自回归学生模型,该模型只需更少的步骤即可生成质量相当的视频。最近,自-强制(Self Forcing)及其后续方法(Cui et al., 2025; Huang et al., 2025; Liu et al., 2025; Shin et al., 2025; Zhang et al., 2025)通过在训练过程中镜像推理过程,进一步减少长期漂移。
基于动作预测未来的世界模型已成为通用机器人开发的关键组成部分(Hu et al., 2023; LeCun, 2022; Richens et al., 2025; Sutton, 1991)。视频生成技术的最新进展(Ali et al., 2025; Wan et al., 2025)推动视频世界模型的发展,其中未来状态以视频帧的形式呈现(Ball et al., 2025; Russell et al., 2025; Sun et al., 2025)。然而,这些模型主要停留在离散控制层面,而对于涉及大量接触的机器人任务而言,高维动作空间模型尚未取得类似进展。与游戏和驾驶数据不同,由于硬件差异和数据采集成本,机器人数据的覆盖范围通常有限。现实世界环境的种类几乎无穷无尽,很容易超出可用机器人数据的分布范围。此外,现有数据集主要由专家演示组成,缺乏学习强动作可控性所需的意图随机性。因此,现有的视频世界模型仍然局限于模拟观察到的场景,并且通常对反事实行为反应迟钝,从而限制了它们在各种场景和复杂任务中的应用。
本文提出一种名为 DreamDojo 的基础世界模型,用于开放世界灵巧机器人任务。与以往通常依赖远程操作数据的方法不同,其利用人类视频进行预训练。尽管存在具身认知上的差异,但人机交互过程中的底层物理机制在很大程度上是一致的,从而能够实现有效的知识迁移。因此,构建迄今为止最大的以自我为中心人类视频数据集 DreamDojo-HV(人类视频),其中包含 4.4 万小时的视频序列,比以往工作中使用的数据集规模大几个数量级。除了规模庞大之外,DreamDojo-HV 还包含极其丰富的活动,其技能数量约为目前最丰富的机器人学习公共数据集的 96 倍,场景数量约为其 2000 倍(Bu,2025;Khazatsky,2024)。这提供了一个丰富的语料库,用于学习各种交互的物理和动力学原理。
DreamDojo概述如图所示:
交互式世界模型。交互式世界模型的目标是基于动作推断未来状态。 形式上,给定一个动作 𝑎 ∈ 𝒜,交互式世界模型充当状态转移函数,对下一个状态进行采样: 𝑠_𝑡+1 ∼ 𝑝(· | 𝑠_𝑡, 𝑎_𝑡), 其中 𝑝 : 𝒮 × 𝒜 → ∆(𝒮) 是转移分布。除非另有说明,本文中“世界模型”特指此类模型。
Cosmos-Predict2.5 模型。世界模型基于预训练的 Cosmos-Predict2.5 模型(Ali,2025)构建,该模型是一个潜视频扩散模型,它使用文本和条件帧输入来预测未来帧。 Cosmos-Predict2.5 模型在 WAN2.2 token化器生成的连续潜空间中运行(Wan,2025)。它将语言和时间步长条件注入到每个 DiT 块中(Peebles & Xie,2023)。文本嵌入由交叉注意层处理,而时间步长信息首先通过正弦嵌入进行编码,然后由轻量级 MLP 进行投影,最后通过自适应层归一化进行动态调制(缩放、平移、门控)(Ali,2025)。整个网络使用流匹配损失进行训练(Lipman,2022)。具体来说,给定时间步长 t 的噪声污染视频潜变量 x_𝑡,流匹配损失旨在最小化与真实速度 v_𝑡 之间的预测误差 L_flow(𝜃),其中 v_𝑡 是噪声 𝜖 与干净样本 x 之间的差异(即 v_𝑡 = 𝜖 − x),c 表示任何条件(例如,文本、条件帧和世界模型的动作),u(·; 𝜃) 是由 𝜃 参数化的去噪器。
概述
整个训练过程包含三个阶段:
- 基于人类视频的预训练。在此阶段,精心挑选三个以自我为中心的人类数据集用于预训练:In-lab、EgoDex 和 DreamDojo-HV。所有视频均以连续潜动作作为训练条件。
- 在目标机器人上进行后训练。为了使 DreamDojo 适应不同的机器人形态,重置动作条件层,并通过微调学习新动作空间。后训练可以在从有限场景中收集的目标机器人数据集上进行。
- 蒸馏。一旦 DreamDojo 学习目标动作空间,就可以应用蒸馏过程来提高实时交互性和上下文一致性。
DreamDojo-HV 数据集
现有的机器人世界模型主要局限于分布内场景,难以泛化到与新物体的未见交互(Team et al., 2025; Zhang et al., 2025)。本质上,这种局限性源于大多数数据集仅覆盖相对狭窄的分布,包含的动词、物体和环境有限,从而限制交互模式的广度。因此,在这些数据集上训练的模型在扩展到分布外场景时,往往无法保持其能力。
为了解决这一局限性,可以考虑增加真实机器人数据的规模。然而,这可能并非涵盖所有潜交互类型的最有效方法,因为每条新的轨迹都需要耗费大量成本的远程操作。另一方面,在日常活动中拍摄的人类视频,已成为增强机器人学习能力的一个很有前景的途径(Bi et al., 2025; Chen et al., 2025; Kareer et al., 2025; Li et al., 2025; Liu et al., 2025; Luo et al., 2025; Qiu et al., 2025; Wang et al., 2024; Yang et al., 2025; Ye et al., 2025; Zheng et al., 2025)。受这些研究的启发,将人类视频作为世界模型预训练的开创性步骤进行扩展。人类数据来自三个来源:
- 实验室内部数据,在实验室的桌面环境中收集,用于验证核心设计。采集者佩戴配备 Vive Ultimate Tracker 的 Manus 手套,以捕捉精确的手部姿态,这些姿态可轻松重定向到 GR-1 机器人的动作。它包含一些在默认机器人训练数据集中未出现的新物体和新动作。
- EgoDex(Hoque,2025)是一个公开的灵巧人类操作数据集,包含由 Apple Vision Pro 录制的自我为中心视角。它拥有 829 小时以自我为中心的视频,并在录制时采集高精度的 3D 手部和手指姿态。它还包含各种日常家居物品。将其添加到数据集中,以丰富物体的多样性。
- DreamDojo-HV 是一个通过众包收集的大规模内部数据集。它涵盖广泛的运动操作技能和极其多样化的环境,例如家庭、工业、零售、教育和行政(分布情况见下图),这显著增加数据集的规模和多样性。每个片段都标注描述所执行任务的文本。
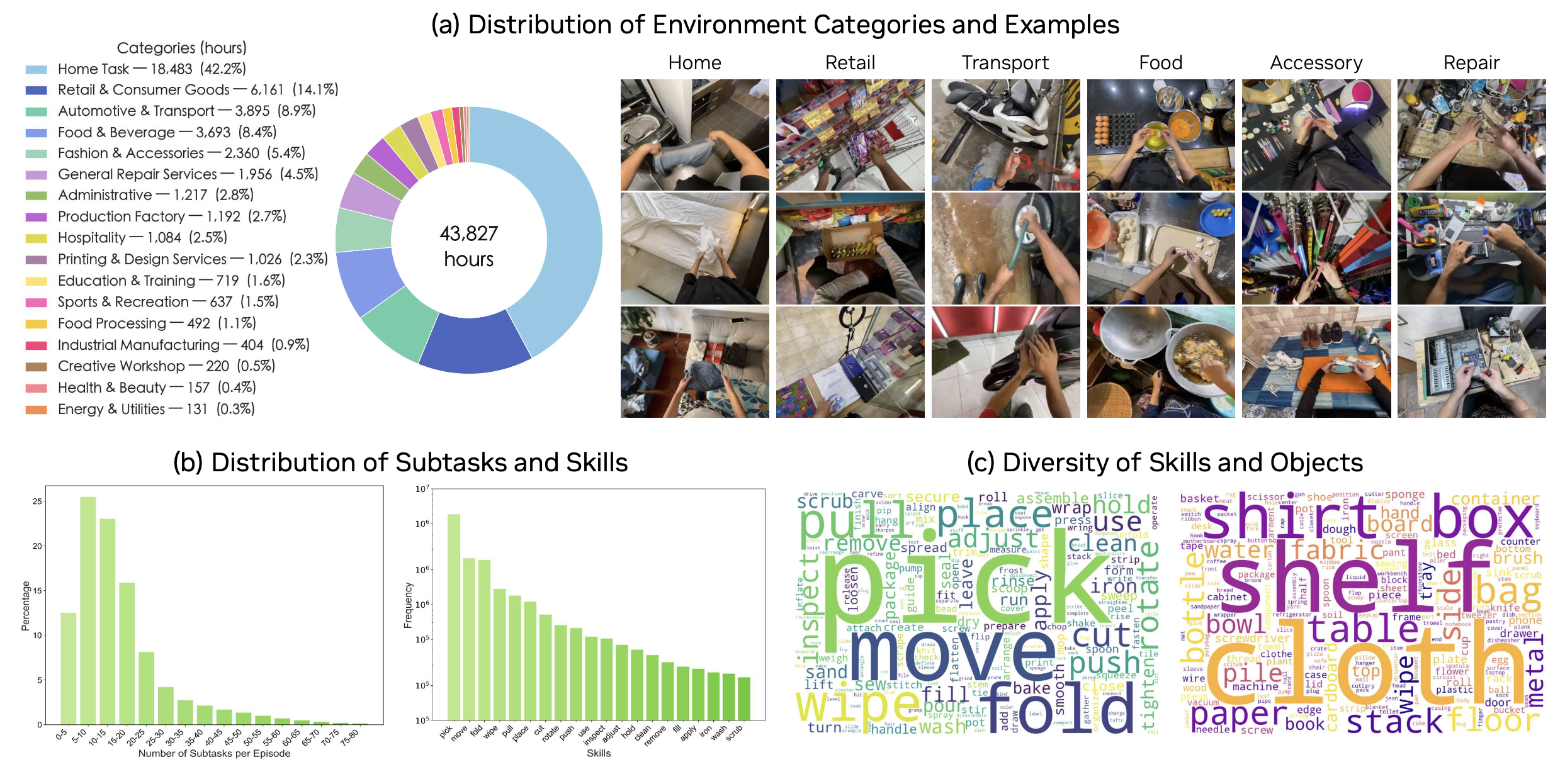
如表所示,最终的数据集包含总计 44,711 小时的数据,使其成为迄今为止用于世界模型预训练的最大人类交互数据集。它包含超过 9,869 个独特的场景、6,015 个独特的任务和 43,237 个独特的对象,涵盖日常活动中的大部分交互。其规模和多样性也提供对各种动作分布的全面覆盖,并增加未来随机性的增加,从而增强动作的可控性。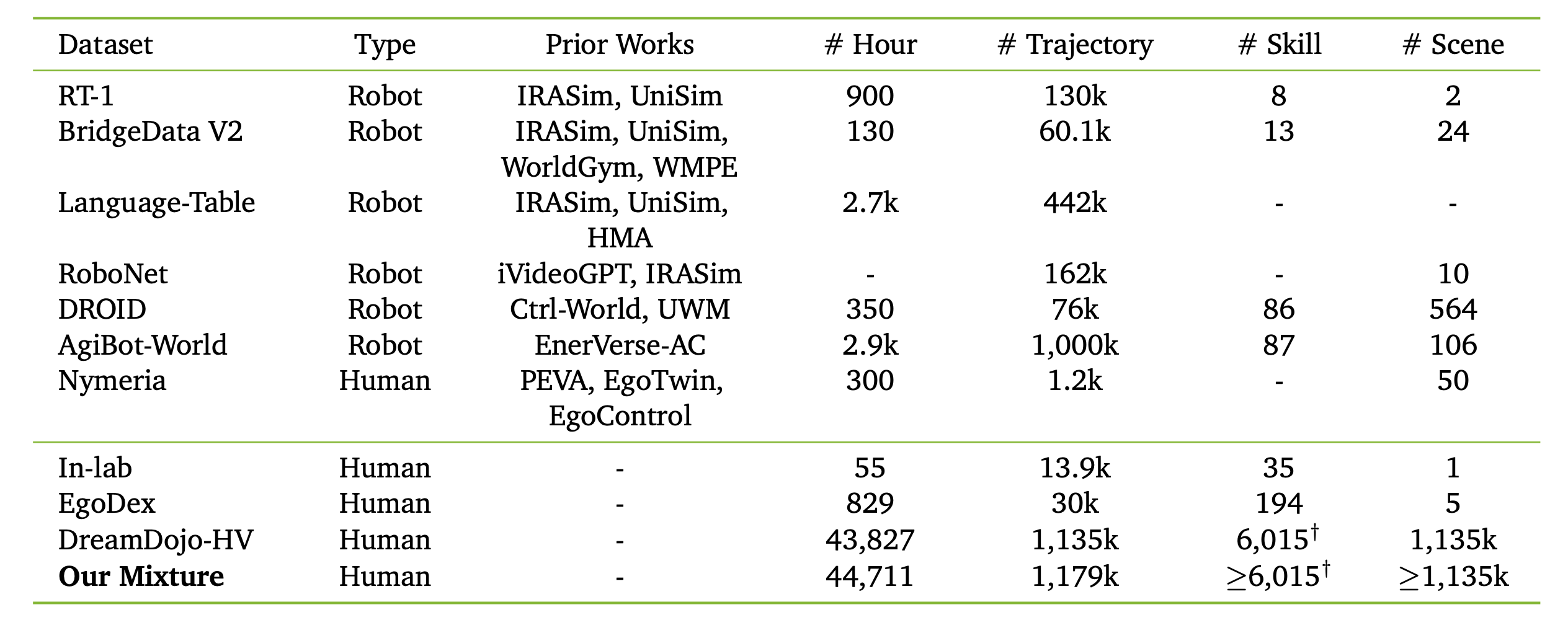
DreamDojo基础世界模型
模型架构
与传统的视频生成器(Ali et al., 2025; Wan et al., 2025)不同,世界模型在动作可控性方面具有显著优势(Huang et al., 2025; Yang et al., 2025, 2024)。与具有离散输入的交互式游戏(Parker-Holder et al., 2024)不同,由于机器人动作的高维度和丰富的接触特性,实现真正的可控性面临着更大的挑战。
为了实现精确的动作跟踪,基于原始架构提出两项改进。首先,不再使用绝对的机器人关节位姿,而是通过将输入与每个潜帧(即每4个时间步)开始时的位姿重新基准化,将其转换为相对动作。由于相对动作通常集中在多个轨迹共享的较窄空间内,这显著降低建模的复杂性,从而增强模型对连续和组合式机器人动作的泛化能力。
其次,由于交互的后果严格遵循因果关系,观察未来动作并不会帮助预测当前时间步,反而会增加无关噪声。因此,并非将整个相对动作轨迹作为所有潜帧的全局条件,而是将动作以块的形式注入到潜帧中(Guo et al., 2025; Huang et al., 2025; Zhu et al., 2025)。具体而言,由于 WAN2.2 token化器(Wan,2025)的时间压缩比为 4(即,视频潜帧 𝑥𝑖 对应于像素空间中的 4 帧 𝑓𝑖:𝑖+4,𝑥𝑖+1 对应于 𝑓𝑖+4:𝑖+8,依此类推),将 4 个连续动作 𝑎𝑡:𝑡+4 连接成一个数据块,并将其一起发送到相应的潜帧。这种强先验可以极大地缓解因果关系混淆,从而提高学习效率并最终增强可控性。
基于人类视频的预训练
潜动作作为代理(proxy)动作。虽然数据集包含全面的真实世界活动,但缺乏细粒度的动作标注。为了从这个未标注的数据集中继承丰富的知识,一个直接的解决方案是通过被动预测未来帧来预训练模型。在实验中,这种简单的方法可以从人类视频中迁移某些物理知识,从而为未见过的物体建立更符合物理规律的模型。然而,由于世界模型必须学习动作的后果,仅仅依赖无动作视频可能会导致对因果关系理解不足,最终导致在适应目标机器人时交互性较差。
为了解决因缺乏动作标签而导致的知识迁移效率低下问题,关键在于从描述当前动作的像素中提取伪标签。虽然像 HaMeR (Pavlakos,2024) 这样的现成模型能够大规模提取手部姿态,但这些模型难以表示手部以外的动作(例如手臂运动和移动),并且在严重遮挡和摄像机运动的情况下,推断手部位置时常常面临挑战。此外,它们主要关注人手的底层特征,当存在显著的具身差异时,这可能会阻碍知识有效地迁移到目标机器人。
另一方面,潜动作 (Bruce,2024;Gao,2025;Ye,2025) 近年来受到越来越多的关注。这些模型完全以自监督的方式从视频中提取动作信息,并在不同的具身之间提供一致的动作解释。受 (Gao,2025) 的启发,采用连续潜动作,因为它们在跨具身泛化和高效适应性方面具有优势。利用时空Transformer架构(Bruce,2024)构建一个基于VAE(Kingma&Welling,2013)的潜动作模型。该模型采用信息瓶颈设计,能够自动从上下文中解耦出最关键的动作信息。具体而言,与标准VAE不同,其VAE编码器接收两个连续帧𝑓𝑡:𝑡+1,提取时空特征,并将全局特征投影到低维嵌入𝑎ˆ_𝑡上。VAE解码器接收该嵌入以及前一帧𝑓𝑡,聚合信息并预测后一帧𝑓𝑡+1。整个VAE由后一帧的重构损失和KL散度进行监督。嵌入的紧凑性和正则化项共同构成一个信息瓶颈。为了重建后面的帧,该模型必须解耦和压缩帧之间最关键的运动。
在自我为中心的人类视频中,这种嵌入能够特别有效地捕捉人类动作,并且可以跨本体迁移(如图潜动作模型所示。左图:潜动作模型的信息瓶颈设计强制执行动作解耦,生成一个连续的潜向量,用于表示帧间的动作。右图:从不同的数据集中检索并分组具有最相似潜动作的帧对。尽管上下文存在显著差异,但这些实例执行的是相同的动作)。最终,能够将潜动作用作世界模型的统一代理(proxy)标签。在预训练过程中,根据分块的潜动作对每个潜帧进行条件化。具体来说,在从连续帧中提取潜动作后,用轻量级多层感知器 (MLP) 对其进行投影,使其与时间步嵌入的维度相匹配。动作 MLP 的最后一层初始化为零,以避免在训练开始时扰乱预训练模型的状态(Zhang,2023),这可以改善物理特性。投影后的嵌入与时间步嵌入相加,然后输入到每个 DiT 块中的自适应层归一化中。
训练目标。Cosmos-Predict2.5 采用标准流匹配损失作为其训练目标。然而,这种对每一帧进行单独监督的方法忽略视频帧之间的时间相关性,而时间相关性可以为学习物体动态和动作跟踪提供更直接的信号。受先前研究(Gao et al., 2024; Wang et al., 2024; Yang et al., 2025)的启发,做一些修改,提出一种新的损失函数,旨在匹配真实时间转换。令 z_𝑡 = u(x_𝑡, 𝑡, c; 𝜃) 表示预测速度,则所提出的时间一致性损失可以表示为: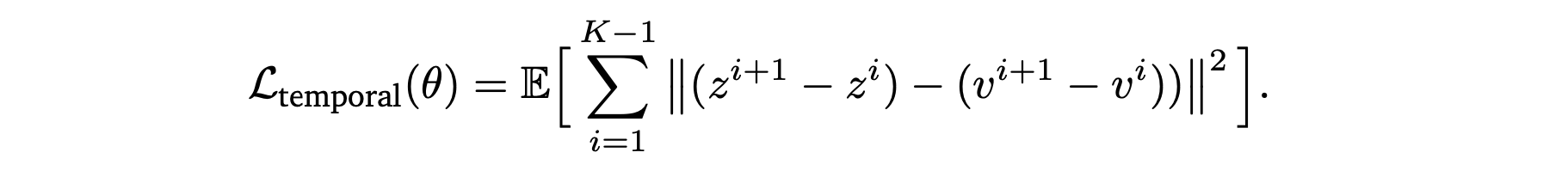
其中,𝐾 为视频潜区域的总长度,[𝑧1, 𝑧2, …, 𝑧𝑘] 和 [𝑣1, 𝑣2, …,𝑣𝑘] 分别为 z𝑡 和 v𝑡 中的帧。实践表明,该损失项不仅加速动作可控性的学习,而且有效地提高目标完整性并减少伪影。因此,最终的训练目标变为:
L_final(𝜃) = L_flow(𝜃) + 𝜆 L_temporal(𝜃),
其中 𝜆 > 0 是一个权衡系数,用于平衡优化。在实验中,用 𝜆 = 0.1。
目标机器人后训练
尽管从人类视频中学习能够使模型接触到广泛的物理交互,但仍然需要在目标机器人数据上进行后训练,以使模型适应下游应用。为此,将目标机器人的真实动作展平为一个序列,并将整个序列投影到动作多层感知器(MLP)中。为了匹配目标动作空间,重新初始化动作MLP的第一层,并对其进行微调,同时调整所有其他预训练权重。得益于强大的预训练,可以在有限的领域内以小规模收集目标机器人数据集,并在微调后仍能实现零样本泛化。潜动作空间的连续性也确保与其他方法相比更好的适应性(Gao et al., 2025)。
蒸馏
为了实现实时远程操作和在线模型规划等功能,世界模型必须能够实时自回归运行(Huang,2025)。然而,现有的视频扩散模型通常难以实现这一点,原因在于:(1)其双向注意架构定义固定的时域长度;(2)大量的去噪时间步(例如50步),严重阻碍推理速度。因此,引入一个额外的蒸馏阶段,将基础的DreamDojo模型转换为自回归、少步的扩散模型。借鉴了Self Forcing(Huang,2025)提出的方法,该方法使用两个训练阶段将教师模型G_teacher蒸馏为学生模型G_student。构建与G_teacher 模型相同架构和模型权重的模型 G_student,区别在于双向注意机制、将教师模型替换为因果注意机制以及将时间步长缩短至几个步长(例如 4 步)。
预热阶段。在第一个“预热”阶段,回归学生模型的预测结果,使其与教师模型生成的 ODE 解相匹配,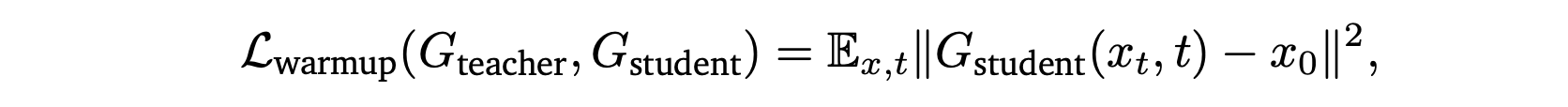
其中 𝑥_0 来自教师模型的 ODE 轨迹。在此阶段,学生模型通过教师模型的强制生成,也就是说,其上下文由教师模型生成的潜变量构成。
蒸馏阶段。之后,在第二个“蒸馏”阶段,用学生模型自身先前生成的潜变量构建其上下文,而不是继续使用第一阶段的教师模型强制生成。这使得训练分布与模型在推理时接收到的分布保持一致,从而减少累积误差。为了监督这一阶段,通过基于真实(教师)和虚假(学生)分布之间的 Kullback-Leibler (KL) 散度的分布匹配损失(Yin,2024)引导学生分布向教师分布靠拢:
L_distill = 𝐷_KL(𝑝_teacher ‖ 𝑝_student)
直接计算这种形式的损失函数是难以处理的,但可以使用真实扩散模型 𝑠_real 和伪扩散模型 𝑠_fake 来估计得分,从而直接计算其梯度: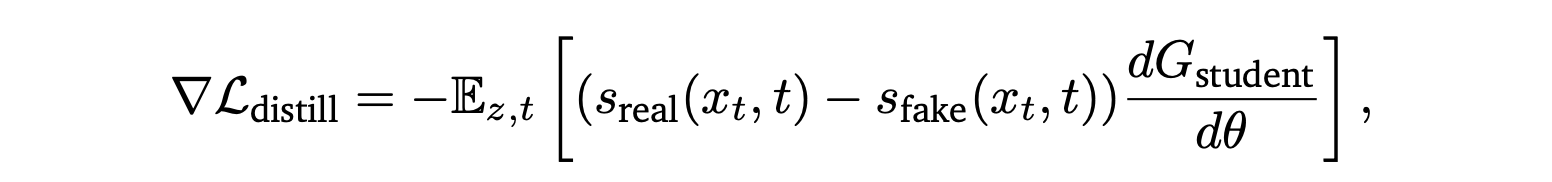
其中 𝑧 ∼ 𝒩(0,𝐼) 为噪声,𝑥_t 由 𝐺_student 从 𝑧 开始的前向扩散生成,𝑠_real 由 𝐺_teacher 估计,而 𝑠_fake 由基于 𝐺_student 预测结果训练的模型估计。
由于学生模型经过训练,能够根据其先前的输出进行生成,因此该过程可以最大限度地减少训练集和测试集分布的不匹配。然而,尽管进行这种匹配,生成质量仍然可能在较长的时间范围内下降。为了提高对累积误差的鲁棒性,让学生模型生成 𝑁′ > 𝑁 帧,其中 𝑁 表示教师模型的时间范围。这模拟更长的学生学习曲线,从而进一步减小训练集和测试集之间的差异。为了监督学生的预测,随机选择一个大小为 N 的窗口,并通过 L_distill 这个损失函数接收梯度。
实验设置
训练和推理。潜动作模型是一个 7 亿时-空 Transformer 模型(Bruce,2024),训练 40 万步,总批大小为 256。潜动作的维度为 32。该模型包含 24 个编码器块用于提取潜动作,以及 24 个解码器块用于前向动力学预测。训练数据混合三个人类视频数据集以及自身收集的机器人数据集,包括 Unitree G1、Fourier GR-1、AgiBot 和 YAM。原始视频按随机因子 {1, 2, 3, 4} 进行时间下采样,以捕捉各种运动。视频帧经过中心裁剪并调整大小,固定分辨率为 320 × 240。公式 (3) 中的 β设置为 10⁻⁶,以在训练后表征容量和迁移性之间取得良好的平衡。用 AdamW 优化器(Loshchilov & Hutter,2019),权重衰减为 0.01,学习率为 2.5 × 10⁻⁵,从头开始训练潜动作模型。
世界模型使用 Cosmos-Predict2.5(Ali,2025)初始化,并在 In-lab、EgoDex 和 DreamDojo-HV 数据集的混合数据集上进行预训练,采样比例分别为 1:2:10。视频帧经过中心裁剪并调整大小为固定分辨率 640 × 480,然后被裁剪成长度为 13 的序列用于预训练。文本条件固定为空提示。提出 DreamDojo 的两个变型:2B 模型和 14B 模型。两个模型均使用 256 个 NVIDIA H100 GPU 进行 14 万步的预训练,有效批大小为 1024。用 AdamW 优化器(Loshchilov & Hutter,2019),权重衰减为 0.1,学习率设置为 1.6 × 10⁻⁴。训练过程中采用指数移动平均 (EMA),并使用该指标生成所有结果。
在后训练阶段,以约 10 Hz 的采样率对目标模型(例如 G1、GR-1、AgiBot)的视频进行采样,以捕捉其可行的运动。然后将视频片段组织成长度为 13 的序列。第一帧作为条件帧,原始动作被处理成长度为 12 的相对动作。使用与预训练阶段类似的超参数设置,更新所有权重,对世界模型进行微调。默认情况下,后训练使用 128 个 NVIDIA H100 GPU 进行 5 万步,批大小为 512。
蒸馏阶段使用教师模型的权重初始化自回归学生模型,同时将双向注意机制替换为滑动窗口大小为 12 帧的因果注意机制。首先,在预热阶段,生成 1 万条 ODE 轨迹并进行 1 万次迭代训练。接下来,在蒸馏步骤中,学生模型在训练期间随机生成 13 到 49 帧,并计算最后 13 帧的损失。运行此蒸馏步骤 3000 次迭代。所有蒸馏过程均在 64 个 NVIDIA H100 GPU 上进行,预热阶段的批大小为 256,蒸馏阶段的批大小为 64。
在推理过程中,教师模型使用 35 个去噪步骤进行生成,而蒸馏后的模型将步骤数减少到 4 个。由于通过实验发现无分类器指导(Ho 和 Salimans,2022)带来的收益有限,因此禁用该指导。
基准测试构建。为了验证方法的有效性,进行一项系统性的评估,重点关注分布外(OOD)场景和反事实行为。具体而言,模拟三个人类数据集中各种新交互方式,并使用 Fourier GR-1 人形机器人构建三个相应的评估数据集:(1)实验室内评估,(2)EgoDex 评估,(3)DreamDojo-HV 评估。尽力复现人类视频中观察的物体,使机器人能够执行反映相似物理原理的相同交互。此外,还收集一个(4)反事实评估数据集,该数据集侧重于当前机器人学习数据集中不存在的反事实行为,例如轻拍玩具或伸手去够物体但没拿到。为了评估 DreamDojo 对不同环境变化的泛化能力,进一步使用 Gemini 2.5 Flash Image(即称作 Nano Banana)(Comanici,2025)编辑 EgoDex Eval 和 DreamDojo-HV Eval 的背景,以复现原始数据集中的典型观测结果。由此得到 (5) EgoDex-novel Eval 和 (6) DreamDojo-HV-novel Eval,每个数据集均包含 25 个样本。下图展示基准测试中的部分样本。
评估流程。为了量化模型在评估集上的性能,用 PSNR(Hore & Ziou,2010)、SSIM(Hore & Ziou,2010)和 LPIPS(Zhang,2018)作为三个主要的自动评价指标。在不进行蒸馏的情况下评估模型时,通过自回归方法,利用最后一次预测结果重置条件帧,生成三轮共 100 个未来视频,以使不同变型之间的差异更具区分性。最终,大多数评估都获得 100 个样本,每个样本包含 49 帧。选择 Fourier GR-1 作为大多数消融研究的代表性目标具身模型。
由于 EgoDex-novel Eval 和 DreamDojo-HV-novel Eval 无法获得真实视频,参考近期研究成果(Gao et al., 2024; Wan et al., 2025; Yin et al., 2025)设计一套人类偏好评估方案。具体而言,开发一个网页用户界面,并邀请 12 名志愿者对并排的视频对进行评判,评判标准包括物体交互和动作跟随的物理正确性,并与真实视频进行比较。在评估物理正确性时,建议志愿者重点关注物体的持久性、形状一致性和接触因果关系。对于动作跟踪测试,鼓励评估者更加关注机器人的姿态,并允许出现“平局”。还会事先提供评估示例,以说明评估者应重点关注的关键因素。每对视频的顺序将随机交换,以避免偏差将所有视频相对于基准模型的胜率取平均值,从而得到最终结果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)