OmniXtreme:突破高动态人形机器人控制的通用性障碍
26年2月来自北京通用AI研究院(BIGAI)、BIGAI-宇树联合实验室、上海交大、中科大、宇树、华中科大和北理工的论文“OmniXtreme: Breaking the Generality Barrier in High-Dynamic Humanoid Control”。
高保真运动追踪是检验通用性、人类水平运动技能的终极试金石。然而,现有策略常常遇到“通用性瓶颈”:随着运动库多样性的增加,追踪保真度不可避免地下降——尤其是在实际应用中高动态运动时。这种失败是由两个因素叠加造成的:多运动优化扩展过程中的学习瓶颈,以及实际执行过程中出现的物理可执行性限制。为了克服这些限制,提出 OMNIXTREME,一个可扩展的框架,它将通用运动技能学习与从仿真-到-真实的物理技能改进解耦。其方法采用流匹配策略和高容量架构来扩展表征容量,而无需进行干扰密集型的多运动强化学习优化,随后进行一个执行-觉察的改进阶段,以确保在物理硬件上实现稳健的性能。
最终的目标是开发出具备可扩展的、人类水平的全身运动技能通用型人形机器人。研究这种能力的一种自然且广泛应用的方法是高保真运动追踪,其中控制器必须精确地复现参考运动,同时在接触和扰动下保持动态稳定性。高质量的追踪不仅仅是为了美观:它能够捕捉到全身协调和接触时机,而这些正是移动操作、富有表现力的交互以及许多下游核心人形机器人功能的基础[59, 50, 52, 1, 43, 47, 53]。
近年来,基于学习的运动追踪取得了显著进展:通过精心设计的目标和强化学习,策略可以高精度地追踪个体运动,包括舞蹈、翻转和武术等高度动态的行为[57, 28, 14]。近期研究[5, 30, 9, 23, 11, 6, 12, 58, 55, 26]在构建涵盖更广泛行为库的多运动控制器方面取得了重要进展。然而,一个反复出现的模式依然存在:当扩展到更大、更异构的运动库,涵盖不同的运动风格、接触方式和时间模式时,运动跟踪质量往往会下降。控制器变得保守且“平庸”,在最复杂的运动中失效,或者对模拟-到-真实转换过程中不可避免的小偏差非常敏感。这种退化在高动态运动中尤为明显,即使是微小的跟踪误差也可能迅速演变为灾难性的故障。这种长期存在的保真度-可扩展性权衡有效地限制人形机器人运动控制的通用性,尤其是在高动态范围内,这表明存在根本性的限制,而非孤立的工程问题[11, 58, 14, 57]。
因此,一个核心问题随之而来:为什么高保真运动跟踪难以扩展,尤其是在真实的人形机器人上?这种困难源于当前从仿真-到-真实训练流程中不同阶段出现的两个相互叠加障碍。
第一个障碍是即使在仿真中也会出现学习瓶颈。最近的一些研究[58, 5, 23, 30, 55, 26, 12, 11]开始探索多运动人形机器人跟踪,旨在超越单运动模仿的可扩展性。然而,现有方法仍然受到表示和优化两方面的限制。在表示方面,大多数方法依赖于相对简单的策略参数化,例如多层感知器(MLP)执行器[58, 5, 23, 55, 26, 12, 11, 46]。当需要将观测结果映射到由各种行为和接触模式产生的高度异构动作目标时,此类参数化方法随着数据多样性的增加而表现出有限的可扩展性[33]。在优化方面,使用强化学习联合训练跨多个运动的统一策略会加剧梯度干扰,通常会导致保守的平均化现象以及在高动态行为上的选择性失败情况[12, 11, 9, 30]。这些因素共同导致跟踪保真度随着运动多样性和难度的增加而下降。
第二个障碍是部署时出现的物理可执行性瓶颈。即使在仿真中实现了高保真度跟踪,将此类行为迁移到物理机器人上仍然具有挑战性。在先前的人形机器人学习流程[11, 58, 5, 23, 30, 55, 28, 14, 26, 49]中,训练期间的驱动约束主要通过关节位置限制和简单的力矩边界来建模。尽管这些简化有助于学习,但在高动态运动中,它们却显得不足。此时,系统行为主要受未建模的执行器非线性因素[41](例如扭矩-速度特性和速度相关的扭矩损失)以及功率相关效应(包括再生功率现象)的影响,导致执行稳定性迅速下降。因此,在仿真中看似可扩展的保真度在实际机器人上可能仍然无法实现。
基于此分析,提出 OMNIXTREME,这是一个可扩展的训练框架,旨在明确解决上述两个障碍,目标是使单一策略能够稳健地控制多样化的高动态人形机器人行为。为了克服学习瓶颈,OMNIXTREME 采用流匹配策略,并通过从一组运动专家中克隆行为,执行从专家到统一的生成式预训练。这种设计将表征学习与优化解耦,通过高容量的生成式策略扩展表达能力,同时避免干扰严重的多运动强化学习。
为了克服物理可执行性的瓶颈,OM-NIXTREME 引入一种残差强化学习的后训练优化方法,用于在实际的驱动约束下执行,这在动态运动中尤为重要。该阶段并非重新学习运动跟踪,而是通过感知驱动的建模、精细的域随机化以及对功耗相关影响的显式惩罚,对预训练策略进行优化,使其符合实际驱动约束。这种针对性的优化确保规模化后的跟踪策略在实际硬件动态条件下仍具有物理可执行性。
可扩展的基于流策略预训练
-
问题描述:在预训练阶段,用基于数据集聚合(DAgger)的蒸馏方法[39, 45]学习流匹配的机器人策略。具体来说,考虑观测空间 o = {p, c, h},它涵盖:(i) 机器人本体感觉 p,包括关节位置、速度、基座角速度和先前的动作;(ii) 指令 c,由参考运动中目标关节位置和速度以及 6D 躯干方向差异组成;以及 (iii) 历史信息 h,包含过去的本体感觉状态。给定一个参考运动数据集 M = {m_i},目标是首先学习每个参考运动的专家策略 Πi_expert = {πi_expert(a|o)},然后将其蒸馏为基于流的通用策略 π_θ(a|o)。
-
专家策略学习:对于专家策略训练,从 Unitree 重定向的 LAFAN1 (LAFAN1) 数据集 [10]、AMASS [31]、MimicKit [35] 和 Reallusion 运动库 [37] 中选取参考运动数据集 M,涵盖多种行为模式和高动态机动。所有参考运动首先使用 GMR [55, 3] 重定向到 Unitree G1 人形机器人。随后,通过近端策略优化 (PPO) [40] 在特定的专家运动 m_k 上训练每个专家策略 π_k。
-
流匹配策略学习:用 DAgger 学习流匹配机器人策略。首先,在模拟器中部署当前基于流的策略 π_θ(a|o),并根据参考运动数据集 M 收集已访问状态 {o_1, · · ·, o_N} 的轨迹。对于每个已访问状态 o,通过查询相应的专家策略来获得专家动作 a_expert。然后,基于流的模型通过优化一个目标函数 L_FM 来学习如何从噪声动作中恢复专家动作 a_expert。该目标函数学习速度场 v_θ(a_t,t,o) 以预测目标速度 u = ε − a_expert,并在每个流时间步学习去噪方向 [29]。在优化过程中,时间步长 t 从 Beta 分布 t ∼ Beta(α,β) 中采样,以使学习过程集中在概率路径的特定区域,从而增强收敛性和轨迹细化。利用速度场 v_θ,可以通过前向欧拉规则,从 t=1 到 t=0 对 v_θ 进行积分,从而从随机噪声 a_1 ∼ N (0, I ) 生成动作 a_0。通过迭代地展开轨迹并利用专家动作对其进行监督,可学习 π_θ 作为将当前观测值映射到相应动作的通用策略。完整的预训练过程如图 (a) 所示,并在算法 1 中进行详细说明。注:图(b)是残差后训练流程,图(c)是模型实际部署情况,下面再解释。

-
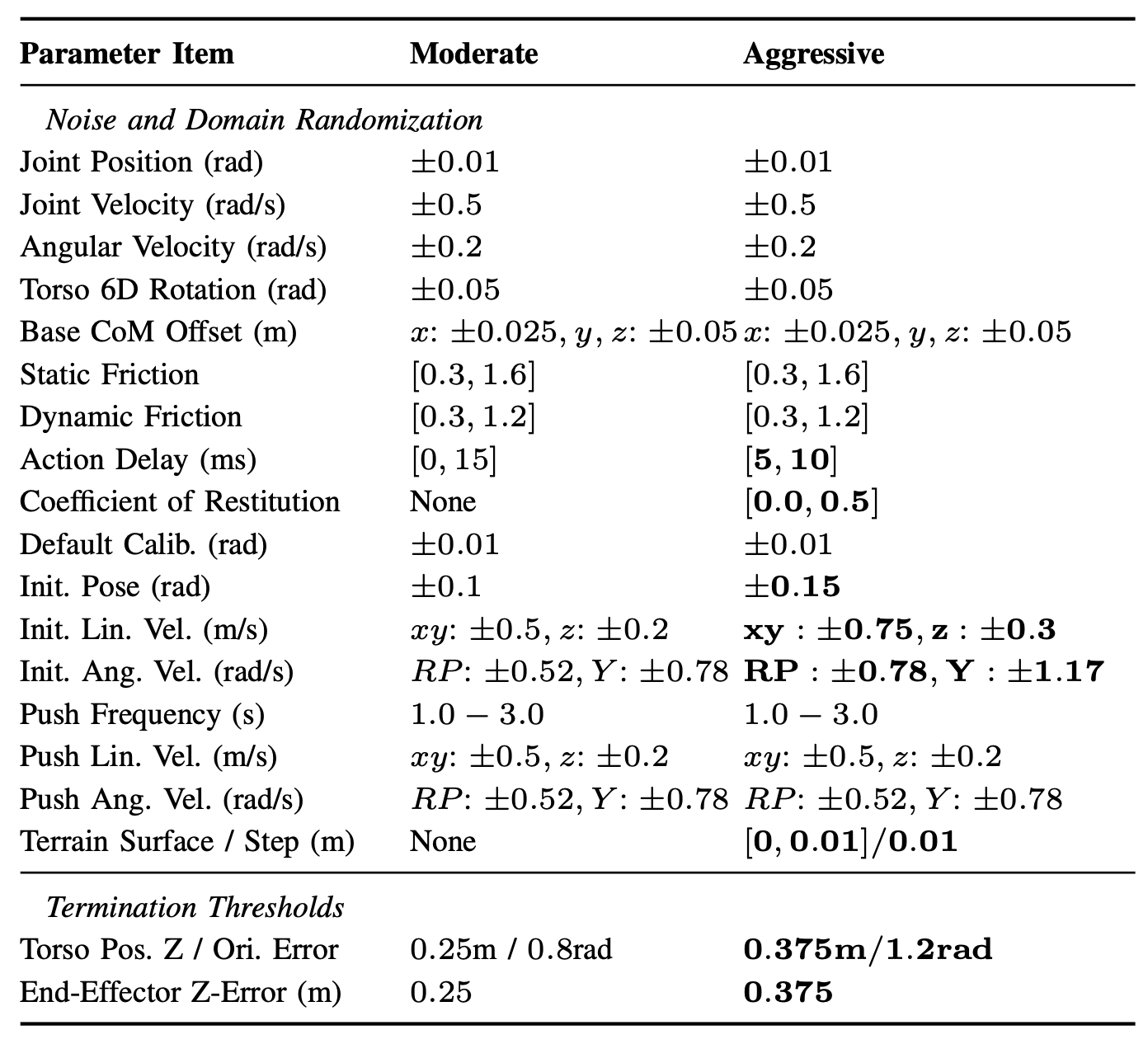
保真度保持的随机化和噪声:为了在确保物理稳定性的同时保持高度的运动表现力,在教师训练和预训练阶段都实施一种保守的随机化和噪声策略,如表所示。通过使用适中的噪声水平和域随机化,防止过度随机性通常导致的性能崩溃。这确保了智体能够准确地捕捉潜在的物理动力学,从而形成一种具有基础性仿真-到-真实的鲁棒性和实际部署所需预测确定性的流匹配策略。
执行-觉察的后训练阶段
- 残差策略建模:预训练的流匹配基础策略虽然提供稳健且统一的行为基础,但在面对真实世界的物理环境时却存在性能差距。为了更好地弥补这一差距并实现从仿真-到-真实的平滑迁移,提出一种基于轻量级多层感知器(MLP)残差校正学习的后训练精细化阶段。具体而言,通过生成精细化动作 a = a_flow + a_res 并利用累积奖励对其进行监督,在冻结的预训练策略 π_θ 的基础上学习残差校正策略 π_φ。
特别地,残差执行器和评论器的观测空间包含了机器人本体感觉、运动指令和当前基础动作 a_flow。在本体感觉状态下,残差策略观察先前的精细化动作,而流匹配基础策略则仍然以先前的基于流的动作为条件。
- 驱动感知物理约束建模:为了明确考虑真实世界的驱动效应,用包含真实驱动感知物理约束和域随机化的环境来训练残差策略,如上图 (b) 所示。执行-觉察物理建模的详细步骤如下:
a) 强化域随机化:大幅提高常见域随机化设置的范围,最高可达 50%,这些设置包括初始姿态噪声、力扰动幅度、角速度等,详见上表。通过添加表面噪声并在场景中随机放置垂直台阶来随机化地形。关键在于,将终止阈值放宽至其基准值的 1.5 倍(例如,方向误差从 0.8 弧度放宽至 1.2 弧度)。这种放宽使得残差策略能够探索并纠正偏差较大但可恢复的状态,否则这些状态会被过早终止。
b) 功率安全驱动正则化:在实际应用中,高动态运动会产生较大的瞬态制动负载,而标准训练流程并未对此进行显式调节。为了解决这个问题,引入对过大的负关节机械功率的显式惩罚,以缓解可能触发过流保护或导致真实机器人过热的剧烈电机制动。具体而言,用由施加的关节扭矩 τ 和角速度 ω 计算得到的瞬时机械功率 P = τ · ω 作为执行器安全的关键策略。对超出预定义死区范围的负功率进行惩罚L_neg-power,以抑制每个关节的大型再生制动(re-generative braking)事件。在实际应用中,该术语通常用于高动态运动(例如后空翻)中的膝关节,因为这些关节在冲击和恢复阶段特别容易承受高制动载荷。
c) 执行-觉察的扭矩-速度约束:仿真与实际结果差异的主要来源之一是执行器建模的过度简化,而标准的扭矩限制技术忽略反电动力(back-electromotive force)和物理功率限制所带来的速度相关约束。这种忽略导致在执行高动态运动时仿真与实际结果之间存在显著差距。为了弥合这一差距,将一个真实的扭矩-速度操作包络直接集成到仿真中,并基于扭矩和角速度的瞬时对齐动态地推导出扭矩限制。然后,将允许的扭矩定义为关节速度幅值的单调递减函数。在将指令扭矩施加到关节之前,最终会将其限制在这个允许的范围内,这确保仿真器永远不会采样到实际执行器物理上无法达到的扭矩指令。除了扭矩-速度限制之外,还通过在扭矩限制后施加非线性摩擦项来进一步模拟执行器级的内部损耗。平滑后的库仑(Coulomb)分量捕捉静摩擦到动摩擦的过渡,而粘性项则考虑速度相关的耗散并提供额外的阻尼。
总而言之,这种结构化的优化阶段能够生成更安全、对较大扰动更具鲁棒性且更贴合实际执行器动力学特性的控制器,从而确保其在机器人上的可靠部署。
实际部署
上图 © 展示集成的实际部署流程。在部署阶段,用骨盆惯性测量单元 (IMU) 作为主要姿态源,并通过正向运动学 (FK) 计算躯干旋转。为了确保最小的控制延迟,整个计算流程——包括基于 FK 的状态估计、基流匹配策略和残差策略——均经过优化,并通过 TensorRT 执行。该集成流程在 Unitree G1 的板载 Orin NX 上实现约 10 毫秒的端到端推理延迟。这种优化使机器人能够在复杂的物理环境中以稳定的 50Hz 频率执行高质量的运动跟踪。
实验设置
- 动作库:采用两层设计构建动作库。首先,用完整的 LAFAN1 [10] 数据集,该数据集已被广泛应用于之前的多动作跟踪工作中,并作为评估风格和时间多样性下可扩展性的标准基准。其次,为了评估并突破极端人形动作的极限,从 LAFAN1 [10]、AMASS [31]、MimicKit [35] 和 Reallusion [37] 中精选约 60 个极具挑战性的动作。如图 (a) 所示,这些动作展现出更高的动态强度、频繁的接触转换和严格的时间约束。这组精选动作统称为 XtremeMotion 数据集。
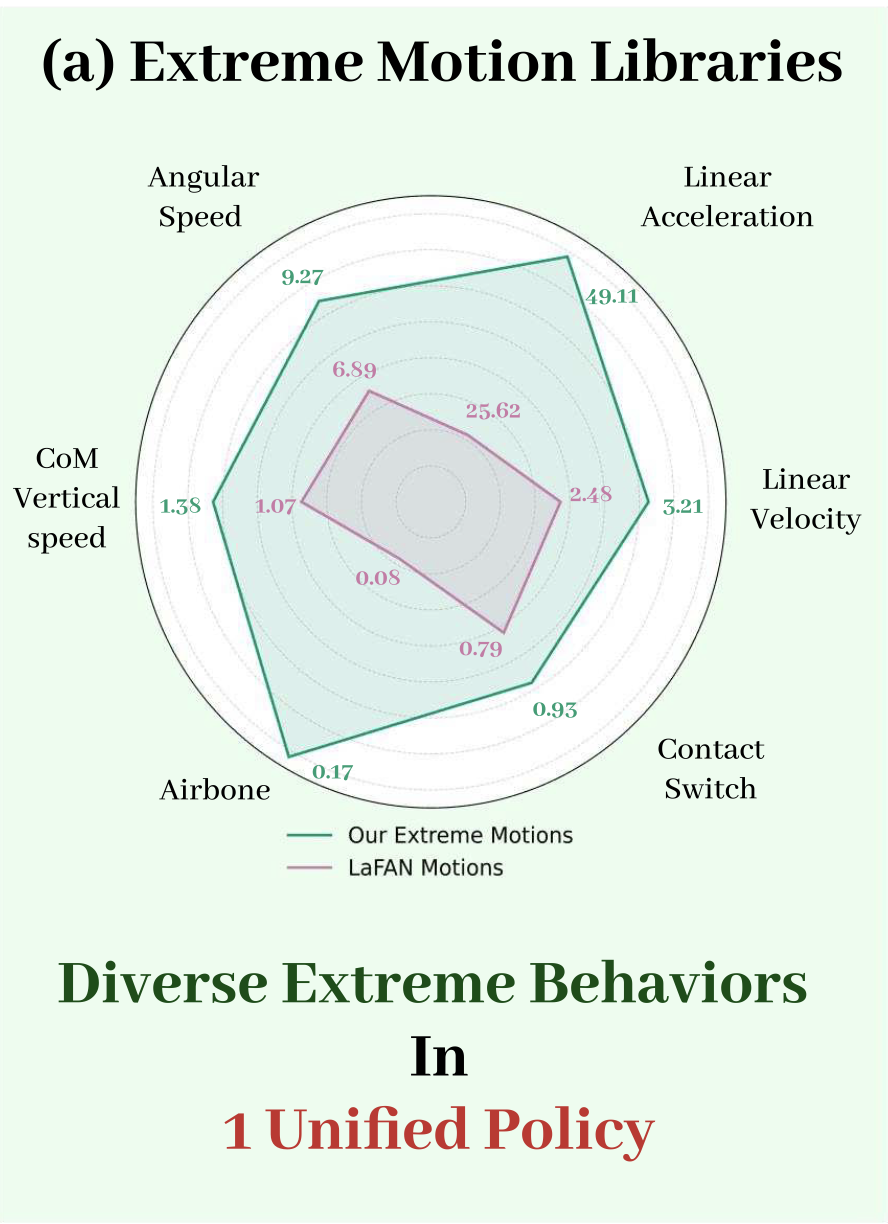
LAFAN1 和 XtremeMotion 共同构成一个运动库,涵盖标准的多运动基准测试以及探索保真度、鲁棒性和实际可执行性极限的极端行为。
2) 基线:与两类专为多运动跟踪设计的强大基线进行比较。
(a) 专家策略到统一 MLP 策略的提炼。这类方法 [58] 首先训练每个运动(或每个集群)的专家策略,然后将其提炼为一个统一的 MLP 跟踪策略。由于依赖于监督式提炼,它们受益于相对稳定和直接的优化,但受限于 MLP 策略的表征能力。
(b) 从零开始的多运动强化学习。这类方法[11, 5, 23, 58, 30, 28]直接使用强化学习从头开始训练一个统一的跟踪策略,该策略适用于所有运动,但随着运动多样性和难度的增加,它常常会受到梯度干扰和保守平均的影响。
评估指标
通过模拟运动跟踪的部署来评估该策略,以提取性能指标。主要指标是成功率(Succ),如果人形机器人偏离参考运动超过预定义阈值或变得不稳定,则该次跟踪被视为失败。此外,还报告根相对平均关节位置误差(MPJPE)(mm),以及关节空间速度(∆vel)和加速度(∆acc)的差异,以量化运动学精度和物理保真度。
在物理机器人上,用面向部署的指标来评估性能,包括技能水平的成功率和高动态行为的运动保真度定性评估。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 19
19 0
0- 0



 已为社区贡献127条内容
已为社区贡献127条内容

所有评论(0)