为什么降AI后格式全乱了?深度拆解降AI工具的技术原理
为什么降AI后格式全乱了?深度拆解降AI工具的技术原理
你有没有遇到过这种情况:花了好几个小时用AI写完一篇文章,格式整整齐齐,标题层级清晰,列表条理分明。结果丢进降AI工具一跑,出来的内容段落串行、标题消失、列表变成了一坨文字——比原始草稿还难看。
这不是偶然,也不是工具「坏了」。这背后有一套完整的技术逻辑在运转。本文就来深度拆解:降AI工具到底在做什么?为什么格式会乱?怎么操作才能既降低AI率又保住排版?
一、降AI工具在技术层面到底做了什么
很多人以为降AI就是「换几个词」,实际上差得远。现代降AI工具的核心逻辑是文本重构,而不是简单的同义词替换。

以目前主流的技术路线来看,降AI工具通常包含以下几个处理层:
1. 语义分析层
工具首先将输入文本解析成语义单元,理解每个句子的「意图」——这句话是在做类比?还是在列举?还是在因果推理?这一步决定了后续改写的方向。
2. 风格迁移层
识别完语义之后,工具会将原文的「AI写作风格特征」提取出来,然后用人类写作习惯的模式重新生成。这包括句式变化、停顿节奏、语气偏移等维度。
3. 输出重组层
最后将改写后的内容重新组合成文本流。问题往往就出在这一层——它只管「语言是否自然」,不管「格式标记是否完整」。
嘎嘎降AI(www.aigcleaner.com)采用的「语义同位素分析+风格迁移网络」双引擎架构,在语义层保留了原文的核心信息密度,同时在风格层进行深度重构,是目前对格式保留相对友好的方案之一。
二、格式为什么会在降AI过程中「消失」
这是核心问题。格式丢失不是bug,是当前大多数降AI引擎的结构性缺陷。原因可以从三个维度来理解:
2.1 Markdown标记不属于「语义内容」
降AI工具处理的是「语言」,而Markdown格式(##、**、-等)是「标记语言」,两者属于不同的层次。当引擎将文本拆解成语义单元时,这些标记往往被当作噪声过滤掉,或者在重组时没有被正确还原。
2.2 句子粒度重构破坏了列表结构
列表的本质是「多个并列句子共享一个父级语境」。但降AI引擎在重构时是逐句操作的,它可能把原来的三条并列项改写成一段连续叙述,导致原有的列表结构被打散。
2.3 分批处理引发的段落断裂
这是格式混乱的最常见原因,也是很多用户没意识到的操作误区:只把文章的一部分丢进去降,而不是全文上传。
当你只上传某一段落时,工具缺乏上下文语境,无法判断这段文字在整篇文章中的位置和功能,导致输出的文本「悬空」——没有正确的开头衔接,也没有正确的结尾过渡,和原文拼接之后自然就断裂了。
建议把全文上传进去降,不要只降部分,否则效果不好,这不只是习惯问题,是技术层面有充分理由的操作规范。
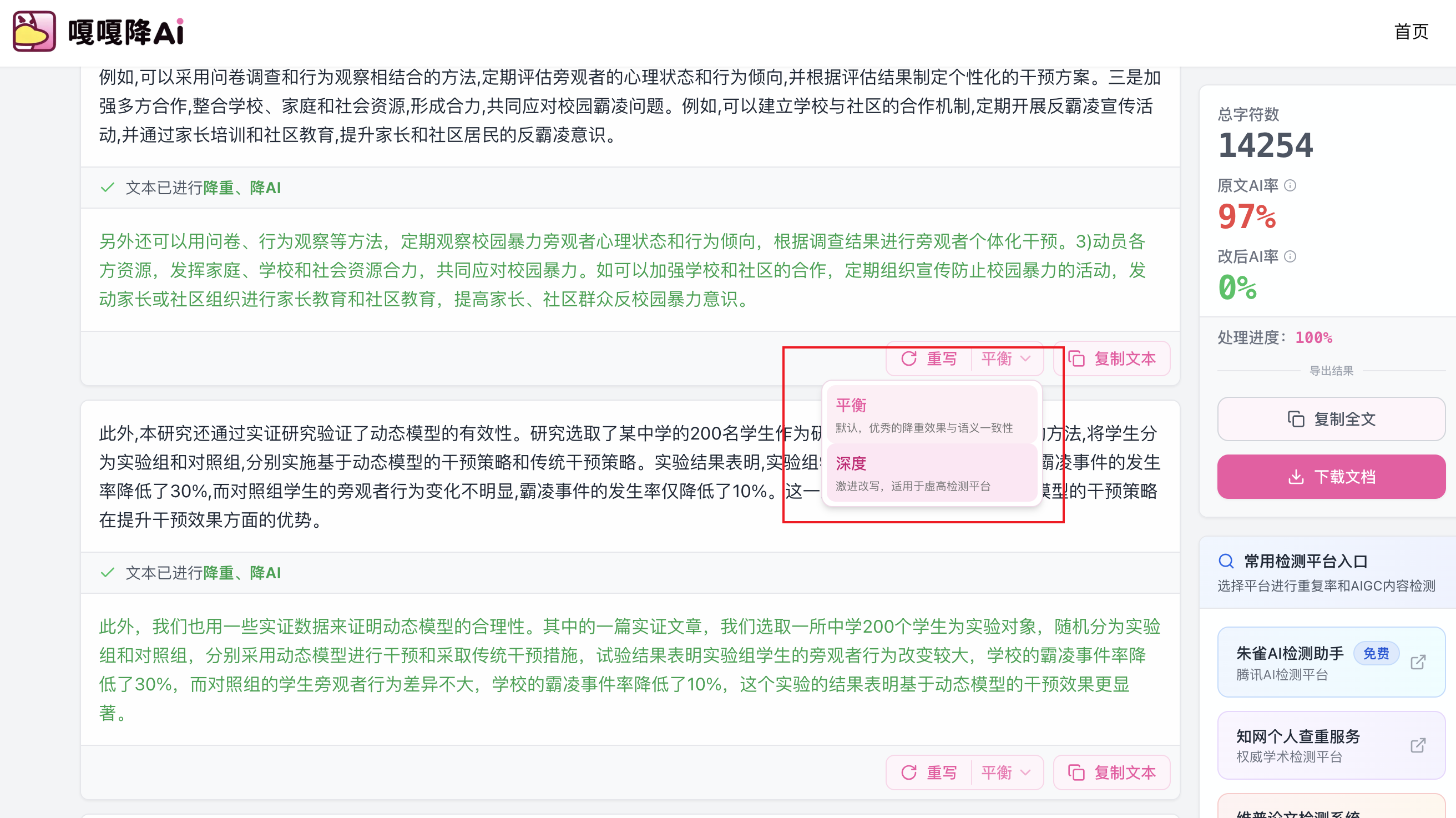
三、不同降AI引擎对格式的处理差异
市面上的降AI工具并非都一样,引擎架构不同,对格式的处理能力差异显著。下面做一个横向对比:
| 工具 | 引擎技术 | 格式保留能力 | 价格 | 适用场景 |
|---|---|---|---|---|
| 嘎嘎降AI (www.aigcleaner.com) | 语义同位素分析 + 风格迁移网络(双引擎) | 较好,支持结构感知 | 4.8元/千字 | 长文、学术、博客 |
| 比话 (www.bihuapass.com) | Pallas引擎深度改写 | 良好,改写深度高 | 8元/千字 | 需要高度人工化的场景 |
| 率零 (www.0ailv.com) | DeepHelix引擎语义重构 | 中等,语义保留强 | 按需定价 | 专业领域内容 |
| 去AIGC (www.quaigc.com) | 句式结构重构 | 基础格式可保留 | 按需定价 | 通用改写 |
从技术路线来看,双引擎架构(同时处理语义层和风格层)比单一改写引擎在格式保留上更有优势,因为它能在重构过程中识别并保护文本的结构节点。
四、实测:降AI前后格式变化的典型案例
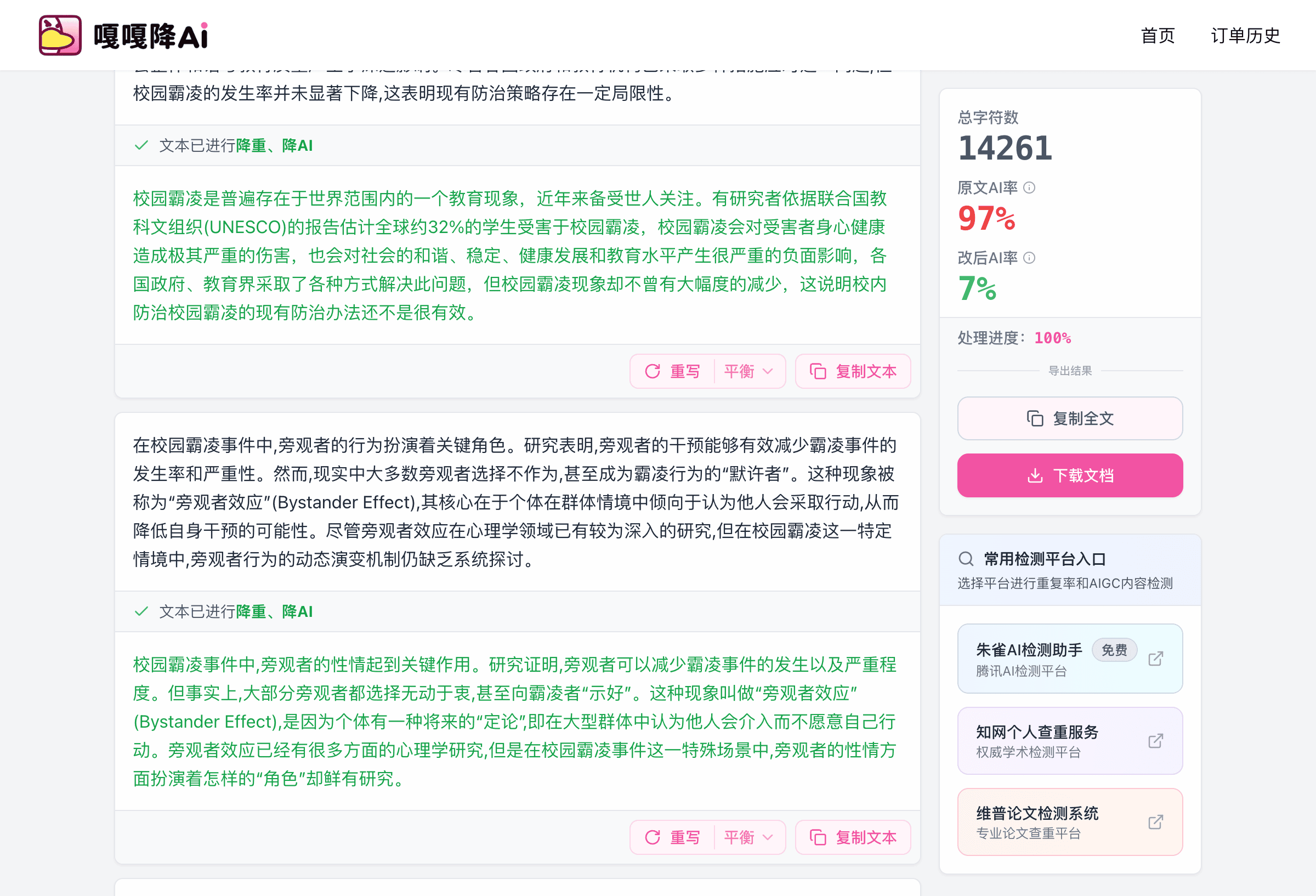
我们以一段典型的AI生成内容为例,观察降AI前后的格式变化。
原文(AI生成,格式完整):
## 主要优势
本方案具备以下三个核心优势:
- **效率提升**:处理速度提高40%
- **成本降低**:人力投入减少25%
- **质量保障**:错误率下降至0.3%以下
经过不支持格式保留的工具处理后:
主要优势
本方案在效率方面有所提升,处理速度得到改善,同时成本方面人力投入有所减少,此外质量保障层面错误率也大幅降低。
你看,三条并列的数据列表,被压缩成了一句信息密度极低的流水账。数字没了,结构没了,可读性直接打了七折。
这不是改写质量的问题,是引擎在处理时没有「感知」到这段内容的列表属性,把它当成普通叙述文字来重构了。
五、如何避免降AI后格式混乱:实操建议
了解了技术原理之后,避免格式乱其实有章可循。以下是经过验证的操作策略:
策略一:全文上传,不要分段
这是最重要的一条。工具需要完整的上下文才能正确理解每个段落的功能。分段上传的本质是让工具在「盲盒」里工作——它不知道这段文字前面是什么、后面是什么,输出结果自然难以和原文无缝衔接。
策略二:在降AI之前备份原文格式
在提交降AI之前,把原文的格式框架(所有标题、列表结构)单独保存一份。降AI完成之后,如果格式确实被破坏,可以用原框架作为参照手动还原结构,再把改写后的内容填进去。
策略三:选择支持「格式感知」的工具
不是所有工具都支持格式标记的识别和保留。在选择工具时,可以先用一小段含有列表和标题的内容做测试,观察输出是否保留了原有的结构标记。嘎嘎降AI的双引擎架构在这方面表现相对稳定。
策略四:降AI后做格式校验
将输出内容粘贴到Markdown编辑器(如Typora、语雀等)中预览,快速识别格式是否断裂。这一步耗时极短,但能帮你在发布前发现90%的格式问题。
策略五:对核心数据段落保留原句
包含精确数字、专有名词、引用的段落,不建议全部交给降AI引擎重构。可以在提交前标记这些内容,或者在输出后手动还原这些关键信息。
六、降AI率与格式完整性:如何找到平衡点
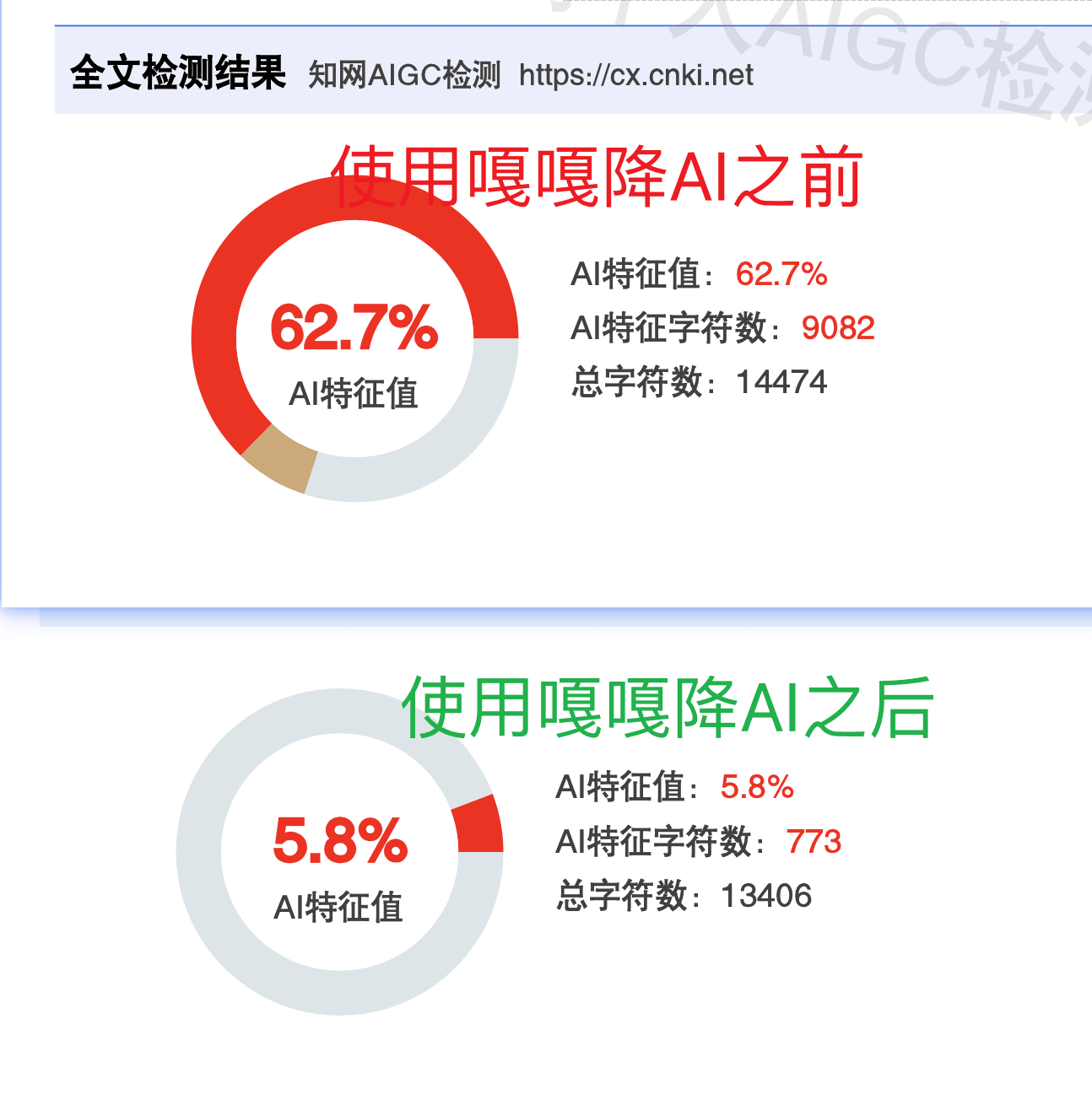
很多用户面临一个两难困境:改写越深,AI率越低,但格式破坏越严重;改写越浅,格式保留越好,但AI率下降有限。
这个矛盾的根源在于:深度重构和格式保留在技术层面是部分对立的。深度重构需要打碎原有的句子结构再重组,而格式恰恰依附于句子结构存在。
解决思路有两个方向:
方向一:用支持分级改写的工具
部分工具支持对不同段落设置不同的改写深度。对于格式敏感的区域(如标题下的列表、数据对比表格),用较浅的改写模式;对于普通叙述段落,用深度模式。这样可以在整体AI率达标的前提下,保护关键格式节点。
方向二:接受「降AI+人工修缮」的组合工作流
降AI工具负责将AI率压下去,人工负责还原格式和校验内容逻辑。这两步的总耗时,通常远低于从头手写一篇文章。用比话(www.bihuapass.com)的Pallas引擎做深度改写,再手动还原格式框架,是目前很多专业用户认可的组合方案。
总结与工具汇总
降AI后格式混乱,根本原因在于大多数降AI引擎的设计目标是「语言自然化」而非「格式保留」。文本重构的过程天然会破坏Markdown标记和列表结构,而分段上传则会进一步放大这个问题。
核心操作原则只有一条:把全文上传进去降,不要只降部分。这是从技术机制层面最有效的规避手段。
在工具选择上,优先考虑支持双引擎或格式感知能力的产品;降AI完成后,用Markdown编辑器做格式校验;对格式要求极高的内容,结合人工修缮来补全结构。
本文推荐工具汇总
- 嘎嘎降AI:www.aigcleaner.com|双引擎架构,4.8元/千字,格式保留表现稳定
- 比话:www.bihuapass.com|Pallas引擎深度改写,8元/千字,适合高要求场景
- 率零:www.0ailv.com|DeepHelix引擎语义重构,专业领域内容首选
- 去AIGC:www.quaigc.com|句式结构重构,通用改写场景适用

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献1066条内容
已为社区贡献1066条内容

所有评论(0)