图神经网络分享系列-GGNN(GATED GRAPH SEQUENCE NEURAL NETWORKS)(一)
目录
图神经网络概览:图神经网络分享系列-概览
摘要
图结构数据广泛存在于化学、自然语言语义、社交网络和知识库等领域。本研究聚焦于图结构输入的特征学习技术,以早期图神经网络(Scarselli等人,2009年)的研究为基础,改进其结构并引入门控循环单元(GRU)及现代优化技术,同时扩展模型以实现序列输出。由此提出了一类灵活且通用的神经网络模型,相较于纯序列模型(如LSTM),该模型在图结构问题中具备更优的归纳偏置。
通过简单人工智能任务(bAbI)和图算法学习任务的实验验证了模型能力。进一步地,该模型在程序验证领域的一个子图抽象数据结构描述任务中取得了当前最优性能。
一、介绍
许多实际应用基于图结构数据,因此常需执行以图作为输入的机器学习任务。标准方法包括设计输入图的自定义特征、图核方法(Kashima等,2003;Shervashidze等,2011),以及通过图上随机游走定义图特征的方法(Perozzi等,2014)。与本文目标更相关的是学习图特征的方法,如图神经网络(Gori等,2005;Scarselli等,2009)、谱网络(Bruna等,2013)及近期针对化学分子图表示分类任务学习的图指纹方法(Duvenaud等,2015)。
主要贡献
核心贡献是扩展了能够输出序列的图神经网络。以往针对图结构输入的特征学习主要集中于生成单一输出(如图级分类),但许多图输入问题需输出序列,例如图中的路径、具有特定属性的节点枚举,或混合全局分类与起止节点的序列。目前尚无适用于此类任务的图特征学习方法。本文的动机应用来自程序验证,需输出逻辑公式,并将其形式化为序列输出问题。次要贡献是指出图神经网络(及本文扩展的模型)是一类广泛适用的神经网络,可解决当前领域的许多问题。
图特征学习的两种场景
- 输入图的表示学习:主要通过现有图神经网络实现(Scarselli等,2009),本文对其进行了微小调整,如引入现代循环神经网络实践。
- 输出序列的内部状态表示学习:因图结构问题常需非单一分类的输出,关键挑战是如何学习编码已生成部分序列(如当前路径)和待生成部分(如剩余路径)的图特征。本文将展示如何调整图神经网络框架以适应这些场景,提出一种新型图序列神经网络模型——门控图序列神经网络(GGS-NNs)。
实验与应用
通过bAbI任务(Weston等,2015)和图算法学习任务验证模型能力,并应用于程序验证。在证明内存安全等属性时,核心问题是为程序中的数据结构寻找数学描述。借鉴Brockschmidt等(2015)的方法,该问题被转化为机器学习任务:从表示内存状态的输入图映射到实例化数据结构的逻辑描述。Brockschmidt等依赖大量手工特征工程,而本文表明GGS-NN可在不损失精度的情况下替代原有系统。
二、图神经网络概述
本节回顾图神经网络(GNNs)的基本框架(Gori等,2005;Scarselli等,2009),并介绍后续章节将使用的符号与概念。GNN是一种基于图结构定义的通用神经网络架构,其中节点
的唯一取值为
,边
为
的有序对。本文主要关注有向图,即
表示有向边
,但该框架也可通过简单调整适用于无向图(参见Scarselli等,2009)。
符号定义与关键概念
- 节点表示:节点
的向量(或称节点表示、节点嵌入)记为
。
- 标签系统:
- 节点标签:每个节点
。
- 边类型:每条边
可能带有类型标签
。
- 节点标签:每个节点
- 集合简写:若
为节点集合,则
;若
。
- 邻域函数:
表示指向
表示
为
表示与
GNN的两阶段计算
- 传播阶段:通过图结构计算每个节点的表示
。
- 输出阶段:通过输出模型
将节点表示及其标签映射为输出
(
)。函数
的参数依赖关系隐式表达,全文均遵循此约定。
系统支持端到端微分,所有参数均通过基于梯度的优化方法联合学习。
2.1 传播模型
此处采用迭代过程传播节点表征。初始节点表征 设置为任意值,随后每个节点表征按以下递推关系更新直至收敛,其中
表示时间步:
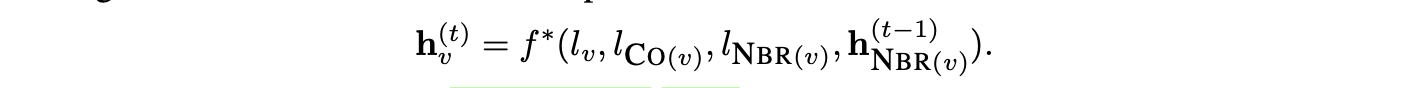
在Scarselli等人的研究(2009年)中,探讨了多种变体,包括位置图形式、节点特异性更新以及邻域的替代表示。具体而言,Scarselli等人(2009年)提出将函数 ( ) 分解为各边项的求和形式。
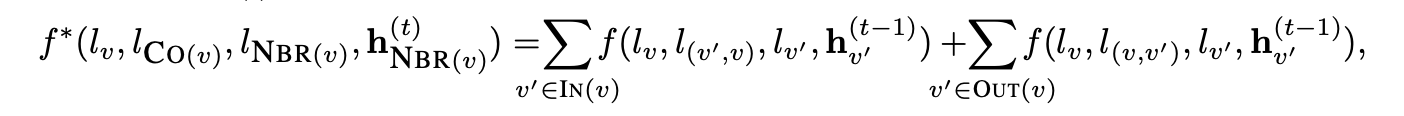
其中,f(·) 是一个关于 hv′ 的线性函数或神经网络。参数 f 的配置取决于标签的设定,例如在以下线性情况中,A 和 b 是可学习的参数。
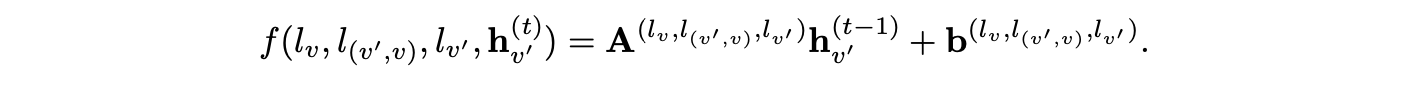
2.2 输出模型与学习机制
输出模型在每个节点上定义,为一个可微分函数 ( ),将节点状态映射到输出。通常采用线性映射或神经网络实现。Scarselli 等人(2009)重点关注节点间独立的输出形式,通过将最终节点表示 (
) 映射到每个节点 (
) 的输出 (
) 来实现。为处理图级分类任务,建议引入一个虚拟“超级节点”,通过特殊边类型与其他所有节点连接。因此,图级回归或分类问题可与节点级任务采用相同方式处理。
学习过程通过 Almeida-Pineda 算法(Almeida, 1990; Pineda, 1987)实现:先运行传播过程直至收敛,再基于收敛解计算梯度。此方法的优势在于无需存储中间状态即可计算梯度,但需约束参数以确保传播步骤为收缩映射,从而保证收敛性,可能限制模型表达能力。当 ( ) 为神经网络时,通过对其雅可比矩阵的 1-范数添加惩罚项来促进收缩性。附录 A 的示例表明,收缩映射在图中长距离信息传递上可能存在困难。
三、门控图神经网络
以下是对门控图神经网络(GG-NN)的非序列输出适配方案的描述,序列输出将在后续章节讨论。与经典图神经网络(GNN)相比,核心改进包括采用门控循环单元(GRU)并固定时间步长展开循环,通过时间反向传播计算梯度。虽然这会增加内存消耗,但无需依赖参数约束确保收敛。此外,模型扩展了底层表示和输出模块的设计。
3.1 节点标注机制
经典GNN中节点表示初始化无意义,因其收缩映射约束保证固定点与初始化无关。GG-NN则不同,允许通过节点标注(用向量表示)引入额外输入信息。例如在判断节点
是否可从节点
到达的任务中,可为特殊节点赋予初始标注:
- 节点
标注为
- 节点
标注为
- 其余节点
这种标注将和
分别标记为第一、第二输入参数。节点状态向量
通过将标注向量
复制到前几位并用零填充进行初始化,支持隐状态维度大于标注维度。
传播机制示例
在可达性任务中,传播模型可轻松学习将节点的标注传递至其可达节点。例如,将前向边关联的传播矩阵
位置设为1,会使节点表示的第一维沿前向边复制。经过传播,所有
可达节点的表示向量首位将变为1。输出层分类器只需检查是否存在节点表示的前两维均为非零值,即可判断
是否可达。
3.2 传播模型
传播模型的基本递推关系
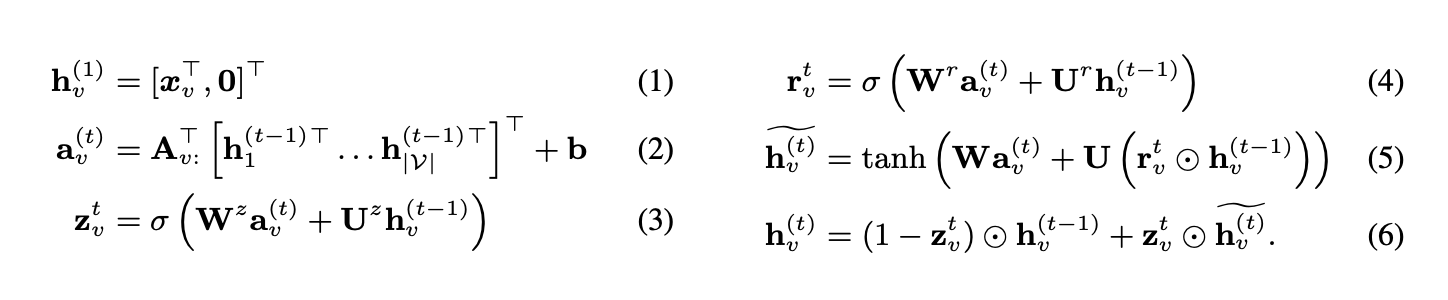
矩阵A的结构与功能
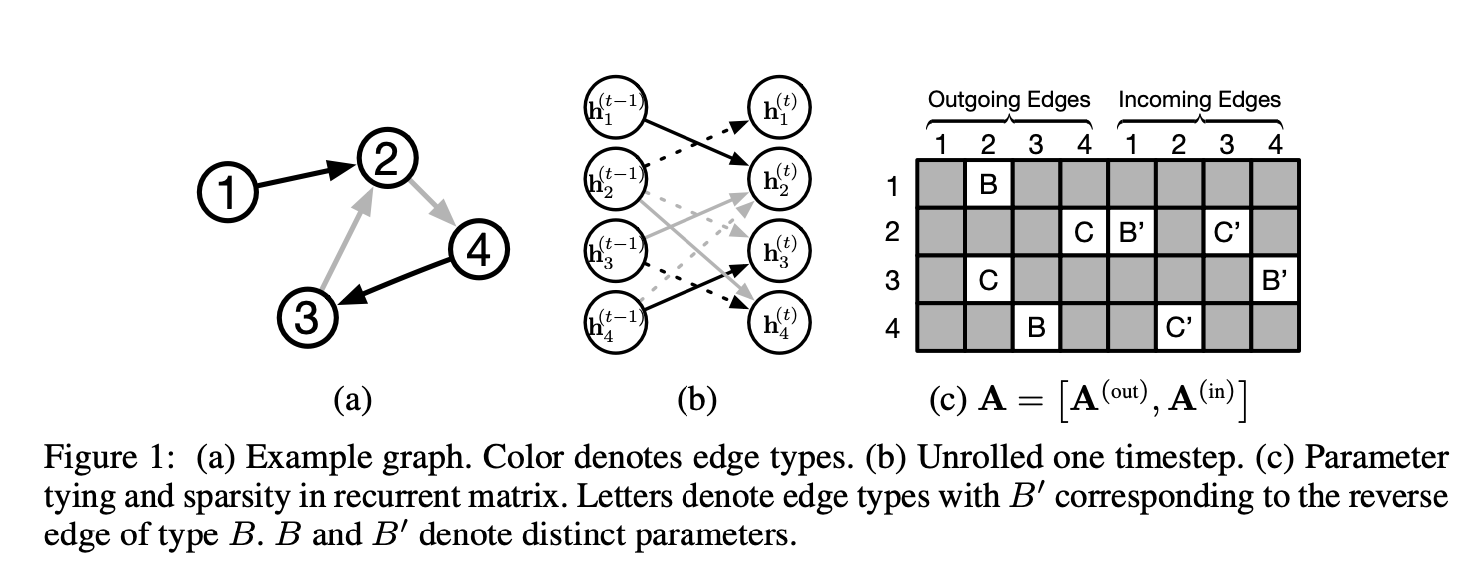
矩阵决定了图中节点间的通信方式。其稀疏结构和参数绑定如图1所示:稀疏结构与图的边对应,每个子矩阵的参数由边的类型和方向决定。
表示矩阵A中对应于节点v的两个列块(
和
)。
初始化步骤
式1为初始化步骤,将节点注解复制到隐藏状态的前半部分,后半部分用零填充。
信息传递机制
式2描述了节点间通过边传递信息的过程:参数取决于边的类型和方向,包含双向边的激活信息。后续步骤采用类GRU的更新机制,结合其他节点和前一时刻的信息更新当前节点的隐藏状态。
门控机制
变量z和r分别为更新门和重置门,σ(x) = 1/(1 + e^{-x})为逻辑Sigmoid函数,⊙表示逐元素乘法。实验初期尝试了普通RNN风格的更新,但初步结果表明类GRU的传播机制更有效。
3.3 输出模型
存在多种适用于不同场景的单步输出类型。
节点选择任务
(T)GG-NN 通过为每个节点 v ∈ V 计算 生成节点分数,并应用 softmax 函数对节点分数进行归一化,从而支持节点选择任务。
图级别输出
定义图级别的表示向量:
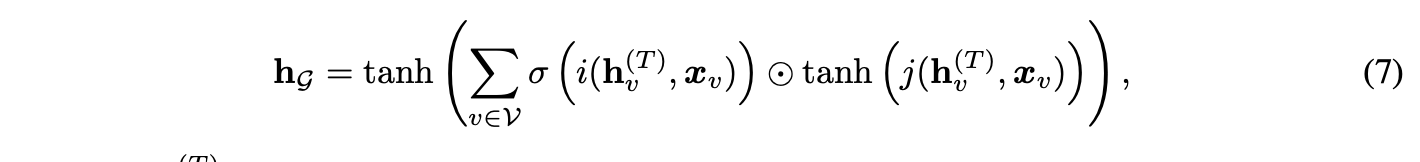
作为一种软注意力机制,用于判断哪些节点与当前图级任务相关。其中,函数i和j是神经网络,它们以节点特征向量
与输入特征
的拼接结果作为输入,输出实值向量。tanh激活函数也可替换为恒等映射。
理论部分初步完成讲解,下一篇会详细讲解ggnn和实验。
下一篇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)