大模型量化&对称量化&非对称量化&动态量化&静态量化&QLoRA 4bit量化
量化就是映射。
一、对称量化与非对称量化
模型量化。首先我们看一下为什么需要进行模型量化。我们以Llama 13B为例,如果用float 32来加载的话,需要52GB的显存。如果以float 16来加载的话,需要26GB的显存。模型量化可以减少模型的存储大小以及推理时占用的显存大小。

A100,中间是tensor,靠两边是显存。在计算过程中,模型要频繁的将模型的weight值和激活值从显存加载到tensor core,计算完成后又将结果放回到显存中。在大模型的推理过程中,制约模型推理速度的更关键的是显存带宽。而如果模型量化后,因为传输的数据小,所以可以减少推理过程中数据交换所占用的时间,从而提高推理的速度。另外我们看一下这个A100的算力,可以看到它对int 8的计算速度是float 16的2倍,是float 32的4倍。

总结,什么是量化?为什么要量化?我们把模型参数和模型的激活值从原来的浮点型转换为整数型,并同时尽可能的减少量化后模型推理的误差,这就是量化。它带来三个好处,1、减少模型的存储空间和显存的占用。2、减少显存和tensor core之间的数据传输量,从而加快模型推理时间。3、显卡对整数计算速度快与浮点型数据,从而加快模型的推理时间。

对于量化,我们不光考虑把浮点数转化为整数,同时我们需要考虑反量化,也就是把整数转化为原来的浮点数。因为我们最终要使用的还是浮点数的值,为此我们需要让我们的反量化后的浮点数要尽可能的接近原始量化前的浮点数。所以量化不能简单的去掉一个浮点数的小数位,还是需要一些策略的。
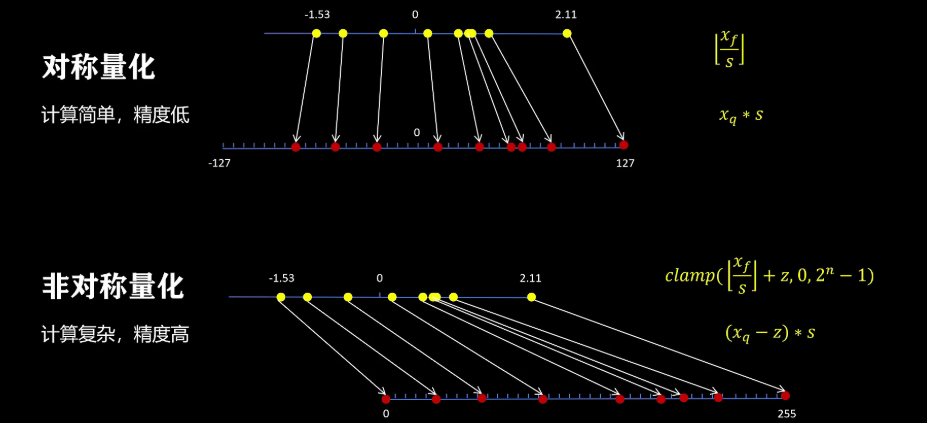
首先我们看最简单的对称量化,我们需要将一组数转换到int 8,也就是负的128到127之间。这里为了简单,我们丢弃负的128,不用只取负的127到正的127。为了能让反量化保持最高的精度,我们要尽可能的让量化后的整数占满负的127到正127的区间。首先我们找到绝对值最大的那个数2.11,让它映射到int 8最大的整数127,从而我们得到了一个缩放比例,就是2.11除以127。然后其他数都按照这个缩放比例进行缩放,然后取整,这样我们就得到了所有数量化后的表示。所以说对称量化的过程就是先找到这组数中绝对值最大的那个数,然后用它的绝对值除以127得到一个缩放系数,所有数字除以这个缩放系数并取整,就得到量化后的值。
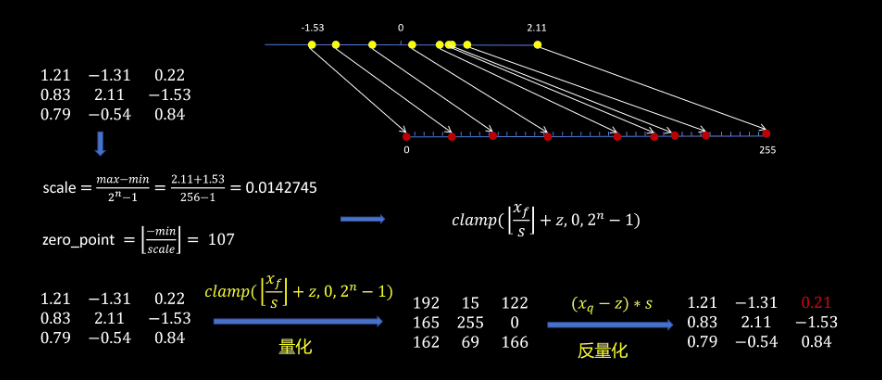
反量化也很简单,就是用量化后的值乘以缩放系数,对这一组数保留两位有效数字。可以看到有些数字经过量化和反量化后变换了,但是整体变化不大。看到这里你可能想到了,以绝对值最大的数来确定缩放比例,肯定存在量化后的整数部分,有一部分范围是被浪费掉的。如果能让量化前这组浮点数里最小值映射到整数的最小值,浮点数里的最大值映射到整数里的最大值,这样就可以最大程度的利用本来就不多的整数表示了。
基于这个思路就引入了非对称量化。非对称量化是把一组浮点数映射到无符号的int 8,也就是0到255之间,因为我们要尽可能的利用所有的整数范围,所以缩放比例scale的计算就是这组浮点数的最大值减去最小值,然后除以255,更一般的如果是int 4量化,这里出的就是15,具体的数字就是量化位数为NI、,2的N次方减1。
缩放比例计算完成后,我们还需要计算一个zero point。它的作用是对缩放取整后的变量进行平移,让量化后的变量刚好处于0到255之间。Zero point的计算方法就是负的最小值除以scale然后取整。有了这个zero point,最小值缩放后加上zero point就刚好等于0。
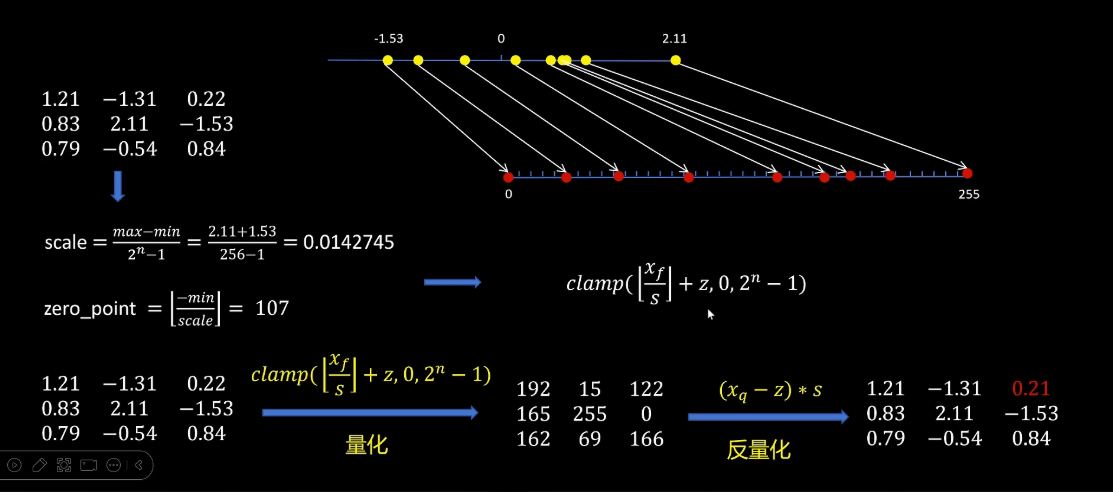
Clamp函数的作用就是如果我们的浮点数经过缩放和平移之后,落在了量化整数范围之外的,小于0的就强制为0,大于255的就强制为255。所以量化的规则是需要量化浮点数除以缩放比例scale然后加以加上zero point,然后截取到量化范围内反量化的公式就是量化后的量减去zero point,然后乘以缩放比例。可以看到用非对称量化后,反量化的精度比对称量化有了提高。有一点我们可以发现,原始输入的0经过量化和反量化不会有误差,这样保证了像relu这样的函数的准确性。
最后我们再整体看一下对称量化和非对称量化。对称量化计算简单,精度相对较低,非对称量化计算复杂,但精度相对较高。到这里我们已经说了怎么对一组数进行量化和反量化,这样可以减少模型的存储大小和显存占用。
接下来我们看看如何对量化后的数据进行计算。这里有两个浮点型的tensor,Xf和Wf对他们进行对称量化,得到了Xq和Wq,浮点型Xf和Wf进行居矩阵乘法,通过推导等于量化后的Xq和Wq进行矩阵乘法,然后乘以两个缩放参数。这样我们就把浮点型矩阵的运算转换成了整数型矩阵运算,可以减少计算时间。下边左边是浮点数进行矩阵乘法的结果,下边右边是量化后的整数矩阵乘法,然后缩放的结果可以看到也有一定的误差,但是整体误差不大。

接下来再看一下非对称量化下进行量化后的矩阵乘法,同样可以看到把浮点矩阵乘法可以转化为多个整数矩阵乘法运算。

上面我们已经讲了对称量化、反量化、非对称量化、反量化,以及怎么在量化后的tensor上进行计算,同时尽可能得到和原始浮点数矩阵计算误差最小的结果。最后我们再看一下量化中还常见的一种问题。比如有异常值,即使用非对称量化,还是有很大部分的整数部分被浪费掉。同时很多不同的值量化后被压缩到同一个整数值,带来了更大的误差。这里也有很多工作来解决这个问题,比如用直方图来描述数据分布,逐步舍弃一些异常值,然后计算量化前和量化后数据的均方误差或者KL散度,找到最合适的取值范围。还有一些量化方法不会舍弃异常值,而是把异常值拿出来做单独处理。
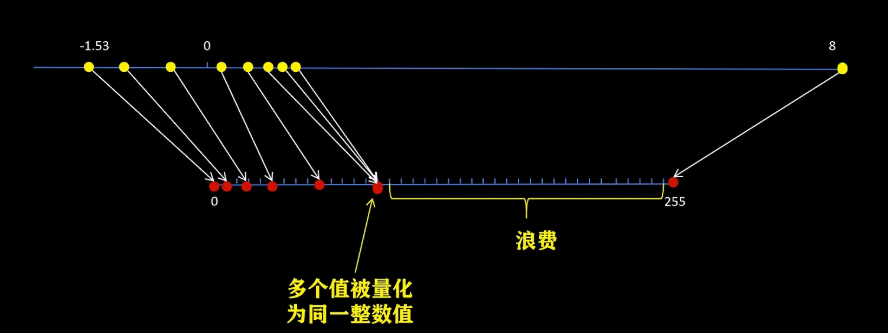
后边我们会讲到还有一个就是量化的力度。你可以对整个tensor做量化,也可以按照channel做量化,也可以按照group进行量化,这样带来更高的精确度。但同时在量化和反量化的时候也更复杂一些。现在我们已经掌握了量化、反量化、量化计算的基本原理了。
二、训练后动态量化
量化怎么应用在神经网络里。总的原则是量化是对每一层而言,每一层进行量化计算,每一层输出时对结果进行反量化,下一层再进行自己的量化和反量化。为什么量化对神经网络精度影响不大呢?
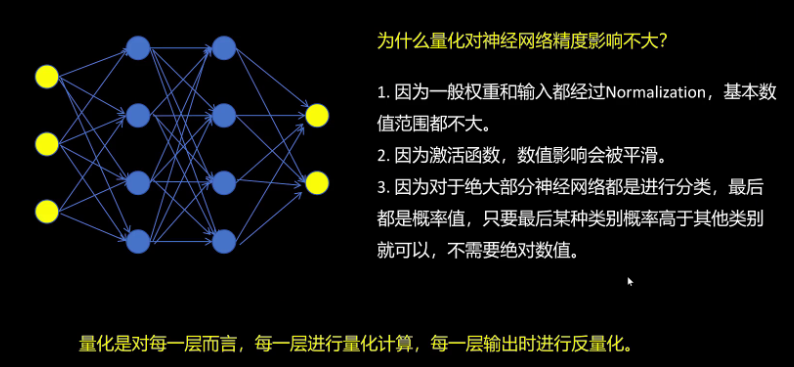
首先我们看一下神经网络的训练后动态量化。我们把训练好的模型权重转化为int 8并保存模型参数。在模型推理时,每一层输入的激活值都是float 32,对这个输入值动态的进行量化,转为int 8的输入。然后在int 8下进行运算,计算后的结果进行反量化,成为float 32的输出,传入下一层。
我们看一下在pytorch里是怎么进行训练后动态量化的。在pytouch里你只需要一行代码,就可以将你的模型转换为动态量化的int 8模型,就是调用quantize.dynamic方法传入你的原始模型。需要量化的层,这里支持了神经网络里常用的层,比如线性层、卷积层、RNN LSTM等,然后指定量化后的类型,这样就可以了。
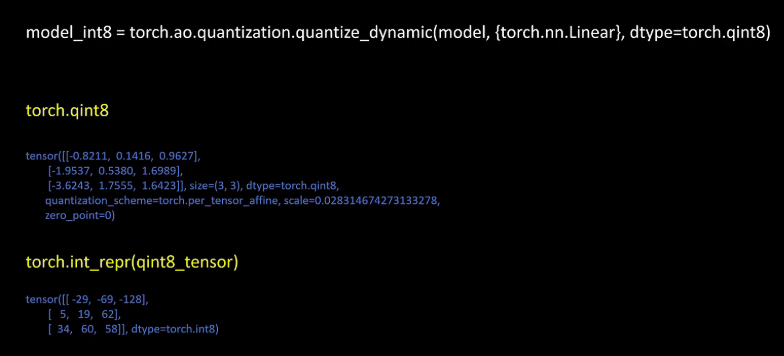
我们看一下pytouch里量化后的类型q int 8,直接打印一个q int 8的tensor,我们可以看到它的量化规则scale,zero point,可以看到它的量化参数是和量化后的值保存在一起的,这样方便随时进行反量化。你可以发现这个q int 8的tensor里的值怎么不是整数,这是直接打印时输出的是q int 8反量化后的值。要打印它真实的量化整数值,你需要用到一个函数,touch.int_repr,通过这个函数我们就可以看到这个tensor里真正存储的int 8的值了。
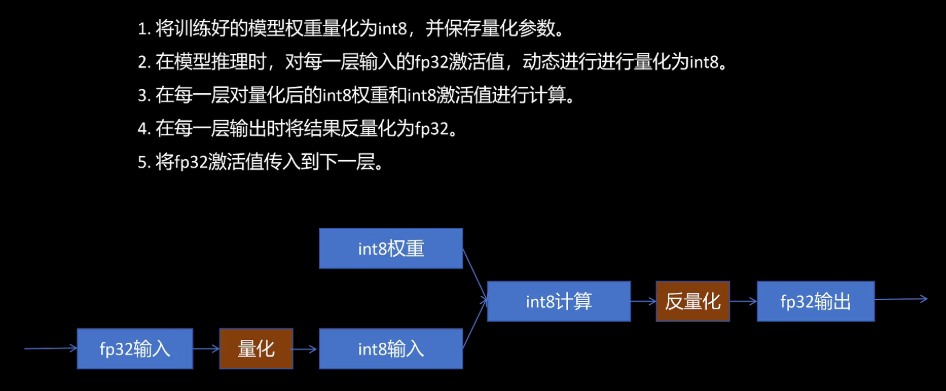
训练后动态量化存在两个问题。第一,每一次推理每一层都要对输入的激活值进行统计量化参数,这很耗时。第二,每一层计算完都需要转换为float 32,然后存入显存,这增加了选显存占用并且传输耗时。如何解决这两个问题呢?
三、静态量化
如何解决训练后动态量化的两个问题。第一个问题,在模型推理时,每一层都需要对输入的激活值统计量化参数,这很耗时。动态量化之所以只量化模型参数而不量化输入,是因为模型参数训练完是不变的,而模型的输入总是变换的,没有办法统计输入的量化参数。针对这个问题的解决办法就是用有代表性的输入跑一遍网络,认为这些数值就代表真实推理时的输入,这样每一层就观察自己输入的激活值,统计得到对激活值的量化参数。
第二个问题,每一层计算完都把计算结果反量化为float 32,这不仅费显存,而且传输耗时。针对这个问题的解决办法是,每一层的输出是下一层的输入,下一层还是要对它的输入进行量化。那不如在这一层计算结束后,直接对它进行量化,然后把量化后的值传给下一层,这就是训练后静态量化。
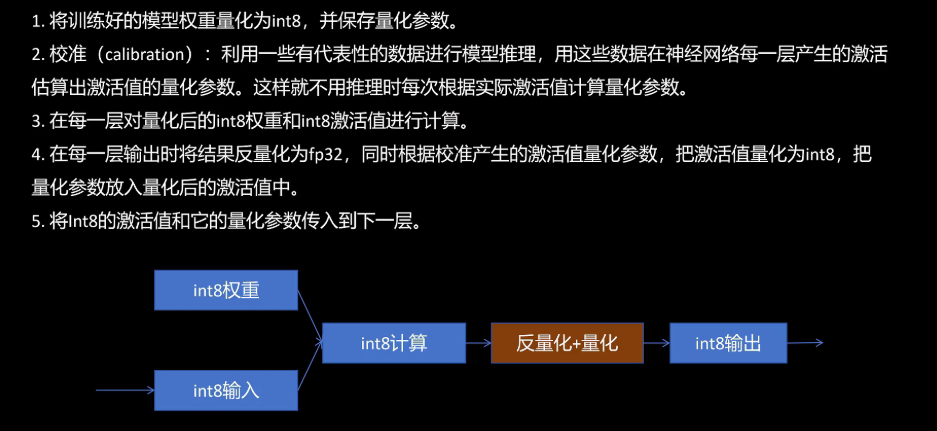
我们看一下它的具体过程。第一步,将训练好的模型权重量化为int 8,并表保存量化参数。第二步,校准,利用有代表性的数据进行模型推理,用这些数据在神经网络每一层产生的激活值估算出激活值的量化参数,这样就不用推理时每次根据实际激活值计算量化参数。第三步,在每一层对量化后的int 8权重和int 8激活值进行计算。第四步,在每一层输出时,将结果反量化为float 32,同时根据校准产生的激活值量化参数把激活值量化为int 8,并且把量化参数存入量化后的激活值中。第五步,将int 8的激活值和它的量化参数传入到下一层。
接下来我们看一下如何在pytorch里实现训练后的静态量化。首先我们需要改造一下我们定义的模型,定义一个量化占位符和一个反量化占位服务。并且在forward的函数需要量化的部分前后分别调用量化和反量化。接着我们为这个模型设置一个适合在x86架构下运行的量化配置,接着调用prepared生成一个带量化的模型。接下来就是最重要的一步,用有代表性的数据对模型各层激活值的量化参数进行校准。这里直接调用模型的前向传播就可以。校准后我们就可以把带量化的模型转换为int 8的量化模型。

我们已经学了训练后的动态量化、静态量化,但是对训练好的模型无论怎么量化,总是有误差等等,有误差,减少误差不正是神经网络擅长的事吗?那是否有一种通过模型训练的办法来减少量化误差呢?
四、量化感知训练
量化感知训练。它通过在网络训练过程中模拟量化,让模型在训练过程中就能调整参数,让它更加适应量化,提高量化后模型的精度。我们看一下具体过程,第一步加载float 32的模型参数。第二步,输入float 32的激活值。第三步,通过在网络里插入模拟量化节点来分别对模型参数和激活值进行量化和反量化,从而引入量化误差。第四步,模型在float 32下进行计算。第五步,计算后的float 32的激活值传入下一层。
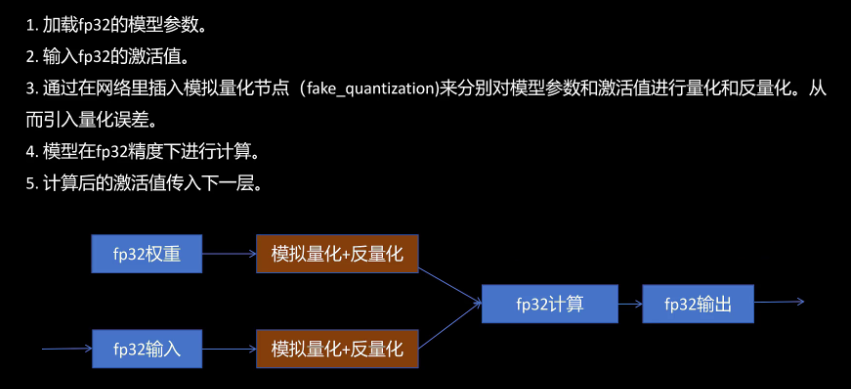
需要注意的是,整个训练都是在float 32下进行的,包括模拟量化和反量化节点。它们在训练时也可以传递梯度到前面的层进行参数更新。接下来我们看一下在pytorch里是怎么进行量化感知训练的。在训练后,静态量化的代码不同的是,prepare函数变成了prepare QAT。QAT就是quantitization aware training,量化感知训练的意思。然后就可以进行模型训练循环了。训练完成后我们就可以直接进行模型转换,得到int 8量化模型了。

量化后模型的MSE损失比训练后静态量化减少了。同时可以看到量化感知训练后的lining one的参数值也和训练后静态量化的参数值不一样,证明量化感知训练可以改进模型参数,提升模型精度。模型量化对于大模型更加重要,那么对大模型的实际量化是怎么做的呢?有没有一种办法可以减少大模型的显存占用,同时不影响大模型的精度呢?
五、LLM.int 8 Hugging Face默认大模型量化方法
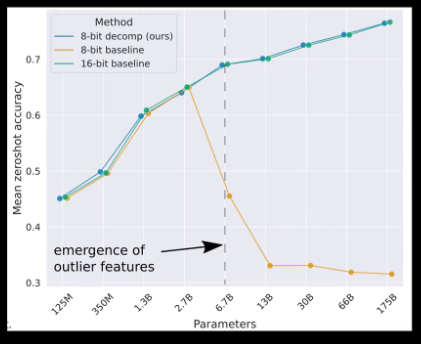
Hugging face transformer库里默认的int 8量化技术。LLM int 8它是一种经过实验证明不影响大模型表现,但是可以减少一半显存占用的量化技术。可以看左边这幅图,X轴是大模型的参数量从125M到175B。Y轴是模型的精度,绿色的线是在flow的16的精度下,不同模型的精度表现。可以看到随着模型参数的增加,精度一直在提升。黄色的线是传统的量化方法,可以看到在模型参数达到2.7B以后,性能就急剧下降。绿色的是LLM int 8的方法,可以看到不论模型参数怎么变换,它的精度一直保持和float 16 没有衰退。
首先我们要搞明白为什么模型参数达到一定量级后,传统量化方法就突然失效,这是由emergent features引起的。什么是emergent features呢?就是在一些层的模型输出的特征里,有些特征突然变大,一般是其他特征的几十倍,比如我们这里原始特征里的57、-45、-67。为什么会出现这些特征呢?作者认为这是大模型在学习过程中学到的重要特征。对这样包含异常值的特征,我们用传统方式进行量化和反量化后,可以看到很多其他特征就变成同一个值了。丢失了信息模型表现会下降。而如果我们选择忽略这些特别大的异常特征,模型丢失了这些重要特征,表现也会下降。
1. emergent features是指在模型学习过程中突然变得显著的特征,这些特征的值可能远大于其他特征,对模型表现至关重要。2. 传统量化和反量化方法在处理包含异常值的特征时,会导致信息丢失,影响模型性能,尤其是当这些异常特征是模型学习到的重要特征时。3. 忽略这些特别大的异常特征同样会导致模型表现下降,因为它们携带了关键信息,是模型理解数据的重要组成部分。4. LLM int 8通过分别处理特别大的重要特征和普通特征,然后汇总结果的方式,解决了信息丢失问题,确保了模型性能。5. 具体操作上,对于矩阵乘法,可以挑选出左矩阵中特定列的特征进行单独处理,再将处理后的结果进行汇总,以保持特征的完整性和模型的准确性

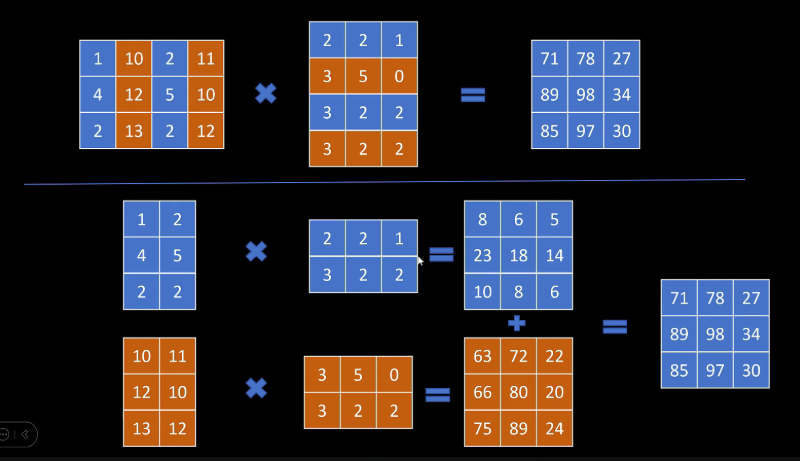
那LLM int 8是怎么解决这个问题呢?一句话来说,就是把这些特别大的重要特征和其他普通特征分别进行处理,然后再汇总他们的结果。首先我们看一下对一个矩阵乘法,我们可以挑出左矩阵的列,比如这里第二列和第四列。然后拿出右矩阵对应的行,比如这里的第二行和第四行。然后就把一个矩阵乘法转换成两个矩阵乘法,下边这两个矩阵乘法的结果的加和和上面分解前矩阵乘法的结果是一样的。以第一行第一列的元素计算为例,在原始矩阵里,它等于左矩阵第一行和右矩阵第一列的点乘。在下面分解后的两个矩阵乘法里,等于两个左矩阵的第一行,分别点成两个右矩阵的第一列,然后加和这个结果和原始矩阵计算第一行第一列的结果过程是一样的。
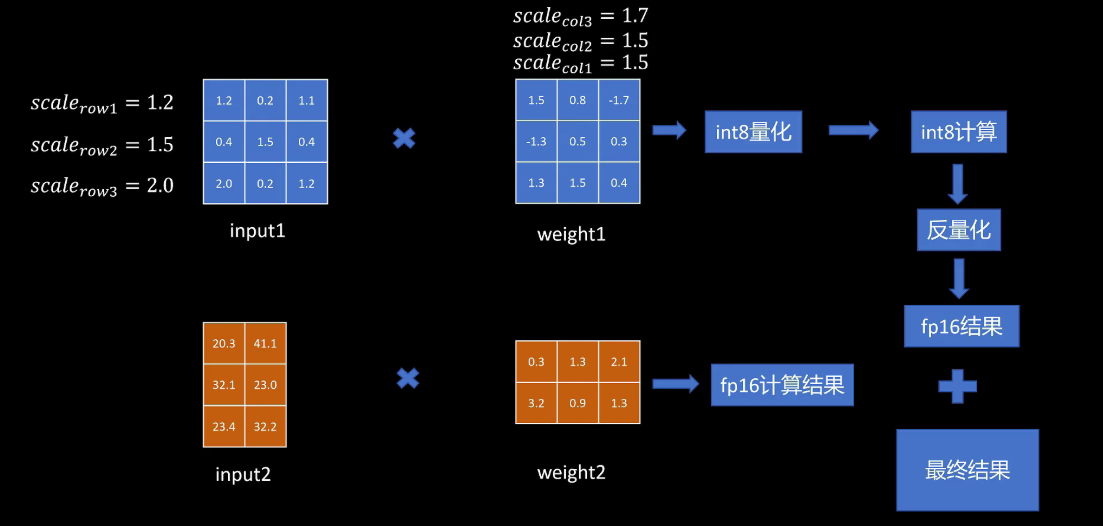
然后我们再看一下对于网络一层的输入和权重。首先我们看一下输入特征里哪些列有异常值,原文里作者取绝对值大于六的特征列为异常列,而且作者发现异常列占比不到0.1%。挑出了输入特征里的异常列,然后我们找出对应行的权重,把输入激活矩阵和权重矩阵进行拆解,上面的input 1 weight1是普通特征和对应的权重,下面input 2和weight2是异常输入和它对应的权重。然后对上面的普通矩阵进行量化计算。注意这里对于输入是按行进行量化,对权重按列进行量化,量化后进行int 8计算,计算完成后进行反量化,下面的异常特征矩阵和权重在float 16下进行计算,这样就没有精度损失。计算完成后和上面的反量化的普通特征计算结果相加,就得到了这一层的输出。
我们再回过头来看一下LLM int 8有几点需要注意,emergent feature仅占所有特征的0.12%。Wait在加载模型时进行量化,显存占用比flow的16减少一半。3、LLM int 8量化方法对模型精度没有影响。4、因为计算复杂,模型推理速度会变慢20%左右。

最后我们看一下如何在hugging face transformer的库里进行LLM int 8的量化非常简单,只需要创建一个Bits and Bytes Config指定用8比特进行量化,然后在加载模型时指定量化配置就可以了。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)