面试05-参考 Skill 范式解决 Agent 所有技能都写入上下文中的问题
一、核心问题:系统提示「代币浪费+信息过载」
第四季的父-子 Agent 解决了上下文膨胀问题:
https://fairy-study.blog.csdn.net/article/details/159253478?spm=1001.2014.3001.5502
但新痛点出现:
如果把所有领域技能(如git规范、代码审查清单、测试流程)都提前写进系统提示,会导致:
- 代币浪费:
10个技能 ×2000代币 =20000代币,而用户任务可能只用到1个技能,90%的代币花在无用信息上; - 信息过载:系统提示过长,模型抓不住核心,甚至忽略关键规则(比如
git提交规范被淹没在大量文本里)。
二、核心方案:两层技能注入(按需加载)
核心逻辑是「轻量摘要常驻,详细技能按需加载」,也就是俗称的 懒加载 ,把技能知识拆成两层,只在需要时加载完整内容,彻底解决代币浪费问题:
┌─────────────────────────┐ 第一层(Layer 1):系统提示(始终存在,低成本)
│ 系统提示: │ - 仅包含技能名称 + 极简描述(如「git: Git workflow helpers」)
│ You are a coding agent. │ - 代币消耗极少(每个技能~100代币)
│ Skills available: │ - 让模型知道「有哪些技能可用」,但不包含具体规则
│ - git: Git规范助手 │
│ - test: 测试最佳实践 │
└─────────────────────────┘
↓ 模型判断需要用 git 技能,调用load_skill("git")工具
┌─────────────────────────┐ 第二层(Layer 2):tool_result(按需加载,高成本)
│ tool_result: │ - 仅在模型调用load_skill工具后,注入完整技能文档
│ <skill name="git"> │ - 包含git提交的完整步骤、规范、示例(~2000代币)
│ 1. 提交前必须lint代码 │ - 用完即融入上下文,未使用的技能永远不加载
│ 2. 提交信息格式:... │
│ </skill> │
└─────────────────────────┘
三、核心代码逻辑(技能加载核心)
1. SkillLoader:技能文件管理器(加载/解析技能文件)
SkillLoader 包含第一层技能的简单加载(用于 System Prompt),和技能详细内容的提取(get_content 提取技能的详细内容,用于第二层的懒加载)
class SkillLoader:
def __init__(self, skills_dir: Path):
self.skills = {} # 存储所有技能的元信息+完整内容
# 扫描skills目录下所有SKILL.md文件(每个技能一个文件)
for f in sorted(skills_dir.rglob("SKILL.md")):
text = f.read_text()
# 解析文件:分离前置元信息(name/description)和正文(完整技能规则)
meta, body = self._parse_frontmatter(text)
# 技能名称优先用元信息,没有则用目录名
name = meta.get("name", f.parent.name)
# 存储技能:meta=极简描述,body=完整规则
self.skills[name] = {"meta": meta, "body": body}
# 生成第一层内容:所有技能的极简描述(用于系统提示)
def get_descriptions(self) -> str:
lines = []
for name, skill in self.skills.items():
desc = skill["meta"].get("description", "")
lines.append(f" - {name}: {desc}")
return "\n".join(lines)
# 生成第二层内容:指定技能的完整规则(用于tool_result注入)
def get_content(self, name: str) -> str:
skill = self.skills.get(name)
if not skill:
return f"Error: Unknown skill '{name}'."
# 用固定格式包裹完整技能内容,方便模型识别
return f"<skill name=\"{name}\">\n{skill['body']}\n</skill>"
SKILL.md文件格式示例(git技能):--- name: git description: 按照仓库规范创建git提交 --- # Git提交规范 1. 提交前必须运行 `lint` 检查代码格式 2. 提交信息格式:[类型]: 简短描述(如 feat: 新增登录功能) 3. 类型可选:feat/fix/docs/style/refactor/test/chore_parse_frontmatter方法(核心):拆分---分隔的元信息和正文,实现「摘要」和「完整内容」的分离。
SkillLoader 代码解释
1. Skills 的目录: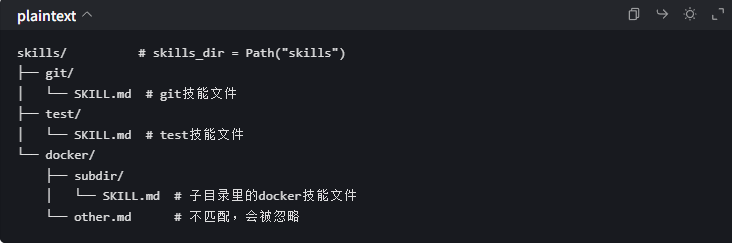
self.skills = {} # 存储所有技能的元信息+完整内容
# 扫描skills目录下所有SKILL.md文件(每个技能一个文件)
for f in sorted(skills_dir.rglob("SKILL.md")):
text = f.read_text()
sorted():把找到的文件按路径排序,保证每次加载顺序一致;rglob:通过迭代的方式,循环里会逐个读取每个SKILL.md的文本内容,为后续解析做准备
2. 解析 [Skill内容] 拆分为 [元信息] 和 [正文]
# 解析文件:分离前置元信息(name/description)和正文(完整技能规则)
meta, body = self._parse_frontmatter(text)
# 技能名称优先用元信息,没有则用目录名
name = meta.get("name", f.parent.name)
# 存储技能:meta=极简描述,body=完整规则
self.skills[name] = {"meta": meta, "body": body}
self._parse_frontmatter(text):用---分隔「元数据」和「正文」;name = meta.get("name", f.parent.name):将skill.md的父目录名称作为name,然后存储技能;
所以 self.skills的形状如下所示:
self.skills = {
"git": {
"meta": {"name": "git", "description": "Git规范助手"},
"body": "# Git提交规范\n1. 提交前lint代码...\n2. 提交信息格式..." # 详细内容
},
"test": {
"meta": {"name": "test", "description": "测试最佳实践"},
"body": "# 测试规范\n1. 单元测试覆盖率≥80%..." # 详细内容
}
}
2. 系统提示 + 工具注册(两层注入的落地)
# 1 初始化技能加载器,扫描 skills 目录,拆分每个技能的 meta(极简描述)和 body(完整内容)
SKILL_LOADER = SkillLoader(Path("skills"))
# 2 系统提示(第一层):包含所有技能的极简描述,始终存在
SYSTEM = f"""You are a coding agent at {WORKDIR}.
Skills available:
{SKILL_LOADER.get_descriptions()} # 注入「git: Git规范助手」等极简描述
Use load_skill to get full instructions for a skill when needed."""
# 3 工具映射(新增load_skill工具,触发第二层注入)
TOOL_HANDLERS = {
"bash": lambda **kw: run_bash(kw["command"]),
"read_file": lambda **kw: run_read(kw["path"], kw.get("limit")),
"write_file": lambda **kw: run_write(kw["path"], kw["content"]),
"edit_file": lambda **kw: run_edit(kw["path"], kw["old_text"], kw["new_text"]),
"load_skill": lambda **kw: SKILL_LOADER.get_content(kw["name"]),
}
# load_skill工具定义:告诉模型如何调用
TOOLS.append({
"name": "load_skill",
"description": "Load full instructions for a specific skill (use when needed).",
"input_schema": {
"type": "object",
"properties": {"name": {"type": "string"}}, # 传入技能名称(如git)
"required": ["name"],
}
})
def agent_loop(messages: list):
while True:
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=messages,
tools=TOOLS, max_tokens=8000,
)
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
return
results = []
for block in response.content:
# 第二层的核心:调用工具的时候,才通过 get_content 获取工具的详细内容
if block.type == "tool_use":
handler = TOOL_HANDLERS.get(block.name)
try:
output = handler(**block.input) if handler else f"Unknown tool: {block.name}"
except Exception as e:
output = f"Error: {e}"
print(f"> {block.name}: {str(output)[:200]}")
results.append({"type": "tool_result", "tool_use_id": block.id, "content": str(output)})
messages.append({"role": "user", "content": results})
四、从第四季到第五季的核心变化(面试重点)
| 组成部分 | 第四季(父-子Agent) | 第五季(按需技能加载) |
|---|---|---|
| 工具集 | 5个(基础+task) | 5个(基础+load_skill) |
| 系统提示 | 静态固定字符串 | 动态注入技能极简描述(第一层) |
| 知识存储 | 无专门技能文件 | 拆分到skills/*/SKILL.md文件 |
| 知识注入方式 | 无(子Agent靠自身上下文执行) | 两层注入:系统提示(轻量)+ tool_result(按需) |
| 核心目标 | 解决上下文膨胀(隔离+销毁) | 解决代币浪费(按需加载) |
五、执行流程示例(面试可直接说)
用户指令:「按照git规范提交当前代码修改」
- 系统提示里只有「git: Git规范助手」的极简描述,模型知道有这个技能,但不知道具体规范;
- 模型判断需要git技能的完整规则,调用
load_skill("git")工具; SkillLoader读取skills/git/SKILL.md的完整内容,以<skill name="git">...</skill>格式返回;- 这个完整规则作为tool_result注入上下文,模型基于这些规则调用bash工具执行git提交(如
git commit -m "feat: 新增登录功能"); - 整个过程中,只有git技能的完整内容被加载,其他技能(如code-review、deploy)的完整内容从未进入上下文,节省90%代币。
六、核心优势(面试答法)
- 代币高效:仅加载任务需要的技能完整内容,避免未使用技能占用代币;
- 系统提示轻量化:始终只保留技能名称+极简描述,模型更容易聚焦核心;
- 技能可扩展:新增技能只需在skills目录下创建SKILL.md,无需修改系统提示,维护成本低;
- 上下文清晰:技能知识按需注入,不会让上下文充斥无关规则,模型执行更精准。
总结(核心关键点)
第五季的核心是「技能分层+按需加载」:
- 第一层(系统提示):低成本常驻,让模型知道「有什么技能」;
- 第二层(load_skill工具):高成本按需加载,让模型获取「技能的完整规则」;
- 对比第四季:第四季解决「上下文膨胀」(横向隔离),第五季解决「系统提示冗余」(纵向按需),两者结合能支撑更复杂的Agent系统。
面试时重点说清「两层注入」的逻辑:为什么要分层(代币浪费)、怎么分层(摘要 + 完整内容)、怎么落地(SkillLoader + load_skill工具),就能精准回应面试官的核心关注点。
一、为什么需要向量数据库?第五季方案的痛点
第五季的「load_skill」是被动加载:模型需要明确知道「技能名称」(比如调用 load_skill("git")),但实际场景中存在问题:
- 模型可能「词不达意」:用户说「帮我规范代码提交」,模型可能想不到要调用「git」技能(名称和需求的语义不匹配);
- 技能多了之后,系统提示里的「技能列表」会变长:100个技能的极简描述也会占用代币,且模型难以快速匹配;
- 无法模糊匹配:比如用户说「审核PR漏洞」,模型如果不知道对应技能叫「code-review」,就会错过加载。
而向量数据库的核心价值是:把「技能描述/工具说明」向量化,通过「语义相似度」主动匹配用户需求,自动找到该加载的技能,无需模型记住技能名称。
二、核心原理:向量数据库+语义匹配的技能加载
1. 核心流程(对比第五季)
# 第五季(被动加载)
用户需求 → 模型识别技能名称 → 调用load_skill(名称) → 加载完整技能
# 向量数据库版(主动匹配)
1. 预处理:把所有技能的「名称+描述」向量化,存入向量数据库(比如FAISS/Pinecone);
2. 运行时:
用户需求 → 向量化用户需求 → 向量库检索「语义最相似的技能」 → 自动加载对应技能的完整内容 → 模型基于技能执行任务
2. 核心落地代码(关键片段)
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
# 1. 初始化向量模型(用于文本向量化)和向量数据库
embed_model = SentenceTransformer("all-MiniLM-L6-v2") # 轻量高效的语义模型
index = faiss.IndexFlatL2(384) # 向量维度和模型匹配(384维)
# 2. 技能数据预处理(离线完成)
class VectorSkillLoader(SkillLoader):
def __init__(self, skills_dir: Path):
super().__init__(skills_dir)
# 提取所有技能的「名称+描述」作为匹配文本
self.skill_texts = []
self.skill_names = []
for name, skill in self.skills.items():
match_text = f"{name}: {skill['meta']['description']}"
self.skill_texts.append(match_text)
self.skill_names.append(name)
# 向量化技能文本,存入向量库
skill_embeddings = embed_model.encode(self.skill_texts)
index.add(np.array(skill_embeddings).astype("float32"))
# 核心:根据用户需求语义匹配技能
def match_skill(self, user_query: str) -> str:
# 向量化用户需求
query_embedding = embed_model.encode([user_query])
# 向量库检索最相似的技能(Top1)
distances, indices = index.search(np.array(query_embedding).astype("float32"), k=1)
if distances[0][0] > 0.5: # 相似度阈值,避免匹配无关技能
return "Error: No matching skill found."
# 返回匹配到的技能名称
matched_name = self.skill_names[indices[0][0]]
# 直接返回该技能的完整内容(无需模型手动调用load_skill)
return self.get_content(matched_name)
# 3. Agent循环中自动匹配技能
def agent_loop(messages: list):
# 提取用户最新需求
user_query = messages[-1]["content"]
# 自动匹配并加载技能
matched_skill_content = SKILL_LOADER.match_skill(user_query)
if "Error" not in matched_skill_content:
# 把匹配到的技能内容注入上下文(替代手动load_skill)
messages.append({
"role": "user",
"content": [{"type": "text", "text": matched_skill_content}]
})
# 后续逻辑和第五季一致(调用模型、执行工具等)
...
三、核心优势(面试重点)
- 语义级匹配:用户说「规范代码提交」能匹配到「git」技能,说「审核PR漏洞」能匹配到「code-review」,无需模型记住技能名称;
- 更极致的代币节省:系统提示里甚至可以去掉「技能列表」,完全靠向量匹配,进一步降低代币消耗;
- 可扩展:技能数量从10个增加到1000个,向量匹配的效率远高于模型手动遍历列表,且不会增加上下文负担;
- 自动化:从「模型手动调用load_skill」升级为「代码自动匹配加载」,减少模型的决策负担,降低出错概率。
四、和第五季方案的对比(面试答法)
| 维度 | 第五季(按需加载) | 向量数据库版(语义匹配) |
|---|---|---|
| 加载触发方式 | 模型主动调用load_skill工具 | 代码自动语义匹配,无需模型干预 |
| 匹配粒度 | 精确匹配技能名称 | 模糊匹配语义(更贴近自然语言需求) |
| 技能数量上限 | 几十个(多了系统提示会变长) | 上千个(向量检索效率不受数量影响) |
| 核心依赖 | 模型识别技能名称的能力 | 向量模型+向量数据库的语义匹配能力 |
| 适用场景 | 技能少、名称易记忆 | 技能多、用户需求表述不固定 |
五、面试高频追问回应
1. 为什么用向量数据库,而不是直接让模型匹配?
- 模型匹配需要把所有技能描述放进上下文,占用代币且效率低;
- 向量数据库的语义匹配是「数值计算」,速度远快于模型推理,且能处理海量技能;
- 向量匹配的阈值可控制,避免模型主观判断的误差(比如模型可能漏匹配)。
2. 向量数据库选哪个?怎么权衡?
- 轻量场景:用FAISS(本地部署,无需联网,适合单机Agent);
- 分布式场景:用Pinecone/Weaviate(云服务,支持大规模向量数据,适合多Agent协作);
- 核心权衡:本地库(快、免费、数据隐私)vs 云库(可扩展、维护成本低)。
总结(核心关键点)
向量数据库赋能Agent技能加载的核心是:
- 预处理:把技能描述向量化存入数据库,完成「文本→数值」的转换;
- 运行时:用户需求向量化后,通过「数值相似度」找到最匹配的技能;
- 自动化:无需模型手动调用工具,代码自动加载匹配到的技能内容;
- 核心价值:解决「技能名称和用户需求语义不匹配」的问题,同时支持海量技能的高效匹配,是第五季「按需加载」的进阶形态。
这也是工业级Agent系统的常见做法——面试时能说清「语义匹配」「向量预处理」「自动加载」这三个关键词,就能体现你对Agent技能管理的深度理解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)