Agent重启恢复:会话状态快照与序列化机制的生产级实现
目录
在构建企业级AI应用时,服务的可靠性与状态持久化是核心需求。当Agent服务因部署更新、故障或扩缩容需要重启时,如何让智能体“无缝续聊”而不丢失上下文记忆?本文将深入探讨openJiuwen框架中Agent会话状态的快照与序列化机制,展示一套生产级的解决方案。
一、问题背景:为什么需要Agent状态持久化?
想象这样一个场景:一个处理复杂客户咨询的客服Agent,在进行了多轮对话、调用了多个工具、生成了详细方案后,突发状况需要重启服务。如果没有状态保存机制:
- 用户体验断裂:用户需要重新描述整个问题
- 计算资源浪费:已执行的推理和工具调用结果丢失
- 业务连续性中断:处理到一半的流程无法继续
openJiuwen的会话状态快照机制正是为了解决这一痛点而生,让Agent能够像虚拟机保存快照一样,随时保存、随时恢复。
openJiuwen开源项目实践:本文探讨的会话状态管理机制已在 openJiuwen Agent Core中实现,欢迎参与贡献:前往GitCode Star项目
二、会话状态快照:捕获Agent的“完整记忆”
2.1 快照内容设计
一个完整的Agent状态快照需要包含其“工作记忆”的所有维度:
from dataclasses import dataclass, asdict, field
from datetime import datetime
from typing import Dict, List, Any, Optional
import json
import hashlib
@dataclass
class AgentSnapshot:
"""Agent会话状态快照"""
snapshot_id: str
timestamp: float
agent_version: str
# 核心状态数据
session_data: Dict[str, Any] = field(default_factory=dict) # 会话核心
context_memory: List[Dict] = field(default_factory=list) # 上下文记忆
tool_calls_history: List[Dict] = field(default_factory=list) # 工具调用历史
internal_state: Dict[str, Any] = field(default_factory=dict) # Agent内部状态
# 元数据
metadata: Dict[str, Any] = field(default_factory=dict)
def __post_init__(self):
# 自动生成ID(如无提供)
if not self.snapshot_id:
time_str = str(self.timestamp)
content_hash = hashlib.md5(
json.dumps(self.session_data, sort_keys=True).encode()
).hexdigest()[:8]
self.snapshot_id = f"snap_{time_str}_{content_hash}"
# 计算数据校验和
self.metadata['checksum'] = self._calculate_checksum()
def _calculate_checksum(self) -> str:
"""计算快照数据校验和,用于完整性验证"""
data = {
'session_data': self.session_data,
'context_memory': self.context_memory,
'tool_calls_history': self.tool_calls_history,
'internal_state': self.internal_state
}
return hashlib.sha256(
json.dumps(data, sort_keys=True).encode()
).hexdigest()2.2 关键状态组件详解
# 示例:构造一个完整的快照
def create_snapshot(agent) -> AgentSnapshot:
"""从运行中的Agent创建快照"""
snapshot = AgentSnapshot(
timestamp=datetime.now().timestamp(),
agent_version="1.2.0",
# 1. 会话数据(对话历史、当前状态)
session_data={
'session_id': agent.session_id,
'messages': agent.conversation_history, # 完整的对话历史
'current_step': agent.current_step_index,
'user_context': agent.user_context,
},
# 2. 上下文记忆(Agent的"工作记忆")
context_memory=[
{
'type': 'short_term',
'content': agent.short_term_memory,
'priority': agent.memory_priority
},
{
'type': 'long_term',
'content': agent.retrieved_memories,
'timestamp': agent.last_memory_access
}
],
# 3. 工具调用历史(用于回放和调试)
tool_calls_history=[
{
'tool_name': call.tool_name,
'parameters': call.parameters,
'result': call.result,
'timestamp': call.timestamp,
'success': call.success
}
for call in agent.tool_call_history[-50:] # 保存最近50次调用
],
# 4. Agent内部状态(模型状态、配置、临时变量)
internal_state={
'model_state': agent.model.get_state() if hasattr(agent.model, 'get_state') else {},
'configuration': agent.config,
'temporary_variables': agent.temp_vars,
'execution_context': agent.execution_context
},
# 5. 元数据
metadata={
'created_by': 'auto_snapshot',
'trigger_reason': 'pre_restart',
'parent_snapshot': agent.last_snapshot_id,
'data_size': 0 # 将在序列化后更新
}
)
return snapshot三、序列化协议:从内存对象到持久化存储
3.1 协议选型与性能对比
不同的序列化协议在性能、兼容性和功能上有显著差异:
|
协议 |
优点 |
缺点 |
适用场景 |
|
JSON |
可读性好、跨语言、标准库支持 |
体积大、不支持二进制、无类型信息 |
开发调试、配置存储 |
|
MessagePack |
二进制、体积小、跨语言 |
无模式定义、版本兼容需注意 |
网络传输、高性能场景 |
|
Pickle |
Python原生、支持复杂对象 |
Python专用、有安全风险 |
Python内部进程通信 |
|
Protocol Buffers |
强类型、版本兼容性好、高性能 |
需要预定义.proto文件 |
生产环境、跨语言系统 |
|
Cap'n Proto |
零拷贝、高性能 |
生态相对较小 |
超高性能要求 |
openJiuwen采用分层序列化策略:
from enum import Enum
import msgpack
import pickle
import json
from typing import Union
class SerializationProtocol(Enum):
"""支持的序列化协议"""
JSON = "json"
MSGPACK = "msgpack"
PICKLE = "pickle"
PROTOBUF = "protobuf"
class SessionSerializer:
"""会话状态序列化器"""
def __init__(self, protocol: SerializationProtocol = SerializationProtocol.MSGPACK):
self.protocol = protocol
self.compress = True # 默认启用压缩
def serialize(self, snapshot: AgentSnapshot) -> bytes:
"""序列化快照为字节流"""
# 1. 转换为可序列化的字典
data = asdict(snapshot)
# 2. 处理特殊类型(如datetime, numpy数组等)
processed_data = self._preprocess_data(data)
# 3. 根据协议选择序列化方法
if self.protocol == SerializationProtocol.JSON:
serialized = json.dumps(processed_data, ensure_ascii=False, default=str).encode('utf-8')
elif self.protocol == SerializationProtocol.MSGPACK:
serialized = msgpack.packb(processed_data, use_bin_type=True)
elif self.protocol == SerializationProtocol.PICKLE:
# 注意:生产环境应谨慎使用pickle,考虑安全限制
serialized = pickle.dumps(processed_data, protocol=pickle.HIGHEST_PROTOCOL)
else:
raise ValueError(f"不支持的协议: {self.protocol}")
# 4. 可选压缩
if self.compress:
serialized = self._compress_data(serialized)
return serialized
def deserialize(self, data: bytes) -> AgentSnapshot:
"""从字节流反序列化快照"""
# 1. 可选解压
if self.is_compressed(data):
data = self._decompress_data(data)
# 2. 根据协议反序列化
if self.protocol == SerializationProtocol.JSON:
decoded = json.loads(data.decode('utf-8'))
elif self.protocol == SerializationProtocol.MSGPACK:
decoded = msgpack.unpackb(data, raw=False)
elif self.protocol == SerializationProtocol.PICKLE:
decoded = pickle.loads(data)
else:
raise ValueError(f"不支持的协议: {self.protocol}")
# 3. 后处理(恢复特殊类型)
restored_data = self._postprocess_data(decoded)
# 4. 重建对象
return AgentSnapshot(**restored_data)
def _preprocess_data(self, data: Dict) -> Dict:
"""预处理:将不可JSON序列化的对象转换为可序列化形式"""
processed = {}
for key, value in data.items():
if isinstance(value, datetime):
processed[key] = {'__type__': 'datetime', 'value': value.isoformat()}
elif hasattr(value, '__array_interface__'): # numpy数组
processed[key] = {
'__type__': 'numpy_array',
'value': value.tolist(),
'dtype': str(value.dtype),
'shape': value.shape
}
elif isinstance(value, dict):
processed[key] = self._preprocess_data(value)
elif isinstance(value, list):
processed[key] = [self._preprocess_data(item) if isinstance(item, dict) else item for item in value]
else:
processed[key] = value
return processed
def _postprocess_data(self, data: Dict) -> Dict:
"""后处理:恢复对象的原始类型"""
# 反向处理逻辑
if '__type__' in data:
if data['__type__'] == 'datetime':
from datetime import datetime
return datetime.fromisoformat(data['value'])
elif data['__type__'] == 'numpy_array':
import numpy as np
return np.array(data['value'], dtype=data['dtype']).reshape(data['shape'])
# 递归处理嵌套结构
if isinstance(data, dict):
return {k: self._postprocess_data(v) for k, v in data.items()}
elif isinstance(data, list):
return [self._postprocess_data(item) for item in data]
return data3.2 性能优化:增量序列化
对于频繁保存的场景,全量序列化开销过大。openJiuwen实现了增量序列化:
class IncrementalSerializer(SessionSerializer):
"""增量序列化器,只保存变化的部分"""
def __init__(self, base_snapshot: Optional[AgentSnapshot] = None):
super().__init__(SerializationProtocol.MSGPACK)
self.base_snapshot = base_snapshot
self.last_hash = None
def serialize_incremental(self, current_snapshot: AgentSnapshot) -> bytes:
"""增量序列化:只保存与基础快照的差异"""
if not self.base_snapshot:
# 无基础快照,全量保存
return self.serialize(current_snapshot)
# 计算差异
diff = self._calculate_diff(self.base_snapshot, current_snapshot)
if not diff:
# 无变化,返回空diff标记
return b'\x00' # 特殊标记表示无变化
# 序列化差异
diff_data = {
'base_snapshot_id': self.base_snapshot.snapshot_id,
'diff': diff,
'new_snapshot_id': current_snapshot.snapshot_id
}
return msgpack.packb(diff_data, use_bin_type=True)
def _calculate_diff(self, old: AgentSnapshot, new: AgentSnapshot) -> Dict:
"""计算两个快照间的差异"""
diff = {}
old_dict = asdict(old)
new_dict = asdict(new)
# 简化的递归差异计算
for key in new_dict:
if key not in old_dict or old_dict[key] != new_dict[key]:
diff[key] = new_dict[key]
return diff四、恢复流程:从快照重建Agent
完整的恢复流程需要处理版本兼容、数据完整性和状态一致性:
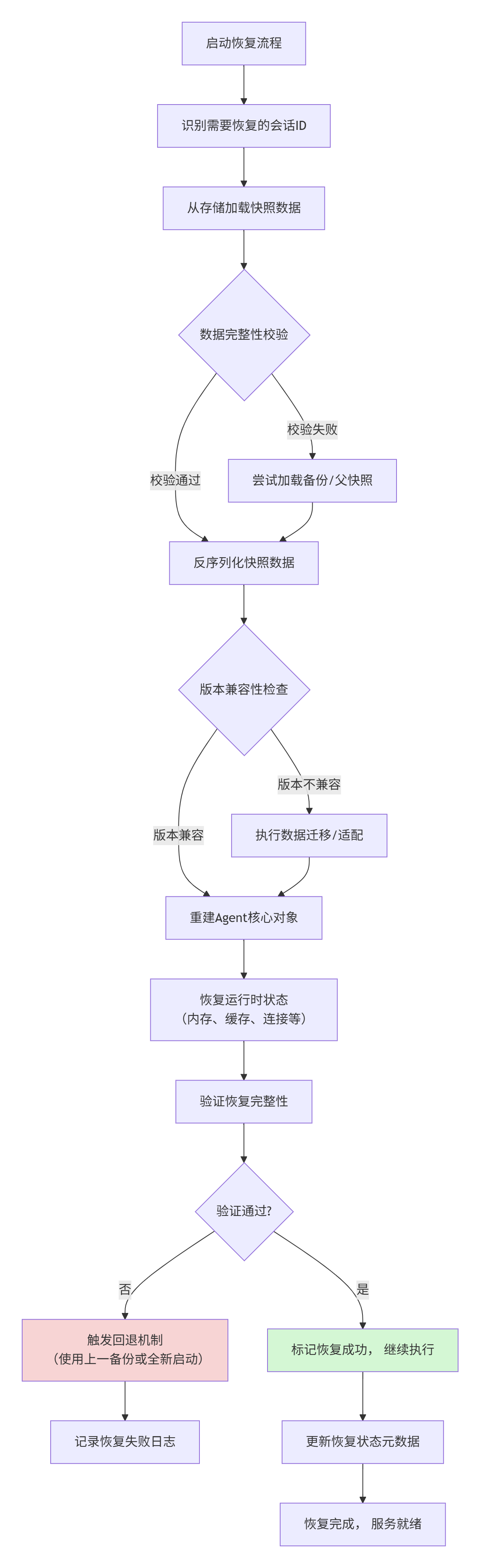
4.1 核心恢复实现
class AgentRestoreManager:
"""Agent恢复管理器"""
def __init__(self, storage_backend, serializer=None):
self.storage = storage_backend
self.serializer = serializer or SessionSerializer()
self.recovery_stats = {
'successful': 0,
'failed': 0,
'avg_recovery_time': 0.0
}
async def restore_agent(self, session_id: str, target_agent_class) -> Any:
"""从快照恢复Agent实例"""
start_time = time.time()
try:
# 1. 查找并加载最新快照
snapshot_data = await self._find_latest_snapshot(session_id)
if not snapshot_data:
raise RestorationError(f"未找到会话 {session_id} 的快照")
# 2. 反序列化
snapshot = self.serializer.deserialize(snapshot_data)
# 3. 版本兼容性检查与迁移
if not self._check_version_compatibility(snapshot.agent_version):
snapshot = await self._migrate_snapshot(snapshot)
# 4. 数据完整性验证
if not self._verify_integrity(snapshot):
# 尝试使用备份或父快照
snapshot = await self._try_fallback_recovery(session_id, snapshot)
# 5. 重建Agent实例
agent_instance = self._reconstruct_agent(snapshot, target_agent_class)
# 6. 恢复运行时状态
await self._restore_runtime_state(agent_instance, snapshot)
# 7. 验证恢复结果
if not await self._validate_recovery(agent_instance):
raise RestorationError("恢复验证失败")
# 记录成功指标
recovery_time = time.time() - start_time
self._update_recovery_stats(success=True, duration=recovery_time)
logger.info(f"成功恢复会话 {session_id}, 耗时: {recovery_time:.2f}s")
return agent_instance
except Exception as e:
logger.error(f"恢复会话 {session_id} 失败: {e}")
self._update_recovery_stats(success=False)
raise
def _reconstruct_agent(self, snapshot: AgentSnapshot, agent_class) -> Any:
"""从快照重建Agent对象"""
# 1. 创建Agent实例(使用保存的配置)
agent = agent_class(**snapshot.internal_state.get('configuration', {}))
# 2. 恢复会话数据
agent.session_id = snapshot.session_data.get('session_id')
agent.conversation_history = snapshot.session_data.get('messages', [])
agent.current_step_index = snapshot.session_data.get('current_step', 0)
# 3. 恢复记忆
for memory_item in snapshot.context_memory:
if memory_item['type'] == 'short_term':
agent.short_term_memory = memory_item['content']
elif memory_item['type'] == 'long_term':
agent.load_long_term_memory(memory_item['content'])
# 4. 恢复工具调用历史
agent.tool_call_history = snapshot.tool_calls_history
# 5. 恢复内部状态
if 'model_state' in snapshot.internal_state:
agent.model.load_state(snapshot.internal_state['model_state'])
agent.temp_vars = snapshot.internal_state.get('temporary_variables', {})
agent.execution_context = snapshot.internal_state.get('execution_context', {})
return agent
async def _restore_runtime_state(self, agent, snapshot: AgentSnapshot):
"""恢复运行时特定状态(连接、缓存等)"""
# 1. 重新建立外部连接
if hasattr(agent, 'external_connections'):
for conn_name, conn_config in snapshot.internal_state.get('connections', {}).items():
await agent.reconnect(conn_name, conn_config)
# 2. 恢复缓存
if hasattr(agent, 'cache') and 'cache_state' in snapshot.internal_state:
agent.cache.warm_up(snapshot.internal_state['cache_state'])
# 3. 重新初始化工具
if hasattr(agent, 'tools'):
for tool in agent.tools:
if hasattr(tool, 'restore_state'):
tool_state = snapshot.internal_state.get('tool_states', {}).get(tool.name)
if tool_state:
tool.restore_state(tool_state)
# 4. 设置恢复标志
agent._is_restored = True
agent._restored_from = snapshot.snapshot_id
agent._restored_at = datetime.now()
async def _try_fallback_recovery(self, session_id: str, broken_snapshot: AgentSnapshot) -> AgentSnapshot:
"""回退恢复策略"""
fallback_strategies = [
self._load_parent_snapshot,
self._load_previous_version,
self._reconstruct_from_partial
]
for strategy in fallback_strategies:
try:
recovered = await strategy(session_id, broken_snapshot)
if recovered and self._verify_integrity(recovered):
logger.warning(f"会话 {session_id} 使用回退策略 {strategy.__name__} 恢复")
return recovered
except Exception as e:
logger.debug(f"回退策略 {strategy.__name__} 失败: {e}")
continue
raise RestorationError(f"所有回退策略均失败,无法恢复会话 {session_id}")4.2 版本兼容性与数据迁移
class SnapshotMigrator:
"""快照数据迁移器,处理版本升级"""
MIGRATION_PATH = {
'1.0.0': ['1.1.0', '1.2.0'],
'1.1.0': ['1.2.0'],
'1.2.0': ['1.3.0'] # 当前版本
}
MIGRATIONS = {
('1.0.0', '1.1.0'): '_migrate_v1_0_to_v1_1',
('1.1.0', '1.2.0'): '_migrate_v1_1_to_v1_2',
('1.2.0', '1.3.0'): '_migrate_v1_2_to_v1_3',
}
async def migrate(self, snapshot: AgentSnapshot, target_version: str) -> AgentSnapshot:
"""迁移快照到目标版本"""
current_version = snapshot.agent_version
if current_version == target_version:
return snapshot
# 检查迁移路径
migration_path = self._find_migration_path(current_version, target_version)
if not migration_path:
raise MigrationError(f"找不到从 {current_version} 到 {target_version} 的迁移路径")
# 顺序执行迁移
migrated_snapshot = snapshot
for from_ver, to_ver in migration_path:
migrator = self.MIGRATIONS.get((from_ver, to_ver))
if not migrator:
raise MigrationError(f"找不到从 {from_ver} 到 {to_ver} 的迁移器")
migration_func = getattr(self, migrator)
migrated_snapshot = await migration_func(migrated_snapshot)
migrated_snapshot.agent_version = to_ver
return migrated_snapshot
async def _migrate_v1_1_to_v1_2(self, snapshot: AgentSnapshot) -> AgentSnapshot:
"""示例:从v1.1迁移到v1.2"""
# 1.1版本中,context_memory是列表,1.2中改为字典
if isinstance(snapshot.context_memory, list):
new_memory = {
'short_term': [],
'long_term': [],
'working_buffer': []
}
for item in snapshot.context_memory:
if item.get('type') == 'short_term':
new_memory['short_term'].append(item)
elif item.get('type') == 'long_term':
new_memory['long_term'].append(item)
snapshot.context_memory = new_memory
# 添加新的元数据字段
snapshot.metadata['migrated_from'] = '1.1.0'
snapshot.metadata['migration_timestamp'] = datetime.now().isoformat()
return snapshot五、在openJiuwen中的实践与配置
5.1 开箱即用的配置
openJiuwen提供了简单的配置即可启用高级状态管理功能:
# config/agent_state.yaml
state_management:
enabled: true
snapshot:
auto_save: true
save_interval: 60 # 每60秒自动保存
save_on_pause: true
save_on_error: true
serialization:
protocol: "msgpack" # json, msgpack, pickle
compression: true
incremental: true # 启用增量序列化
storage:
backend: "redis" # redis, filesystem, s3
redis:
host: "localhost"
port: 6379
db: 0
key_prefix: "agent_snapshot:"
recovery:
auto_recover: true
max_recovery_attempts: 3
fallback_strategy: "latest_valid" # latest_valid, specific_date, fresh_start
retention:
max_snapshots_per_session: 10
cleanup_cron: "0 2 * * *" # 每天凌晨2点清理5.2 使用示例
from openjiuwen import Agent, SessionManager
from openjiuwen.state_management import StateManagerConfig
# 1. 配置状态管理器
config = StateManagerConfig(
auto_save=True,
storage_backend='redis',
snapshot_interval=60
)
# 2. 创建带状态管理的Agent
agent = Agent(
name="customer_service_agent",
state_management=config
)
# 3. 正常使用 - 状态会自动保存
response = await agent.process_query("我想查询订单状态")
# 4. 手动保存快照
snapshot_id = await agent.save_state(reason="pre_deployment")
# 5. 服务重启后恢复
restored_agent = await Agent.restore_from_snapshot(
session_id="user_123_session",
snapshot_id=snapshot_id
)
# 继续之前的对话
response = await restored_agent.process_query("根据刚才的信息,我的订单预计什么时候送达?")六、最佳实践与性能考量
6.1 性能优化建议
- 增量快照:对频繁更新的会话,使用增量序列化
- 懒加载:恢复时只加载必要数据,其他按需加载
- 压缩策略:对大状态使用高效压缩算法(如zstd)
- 分级存储:热数据存内存/Redis,冷数据存对象存储
6.2 容错与监控
# 监控指标收集
class StateManagementMonitor:
"""状态管理监控"""
metrics = {
'snapshot_duration_seconds': Gauge('snapshot_duration_seconds', '快照保存耗时'),
'snapshot_size_bytes': Gauge('snapshot_size_bytes', '快照大小'),
'recovery_duration_seconds': Gauge('recovery_duration_seconds', '恢复耗时'),
'recovery_success_total': Counter('recovery_success_total', '成功恢复次数'),
'recovery_failure_total': Counter('recovery_failure_total', '恢复失败次数'),
}
@classmethod
def record_snapshot(cls, duration: float, size: int, success: bool):
cls.metrics['snapshot_duration_seconds'].set(duration)
cls.metrics['snapshot_size_bytes'].set(size)
@classmethod
def record_recovery(cls, duration: float, success: bool):
if success:
cls.metrics['recovery_success_total'].inc()
else:
cls.metrics['recovery_failure_total'].inc()
cls.metrics['recovery_duration_seconds'].set(duration)七、总结
openJiuwen的会话状态快照与恢复机制为生产环境AI应用提供了关键可靠性保障:
- 零中断体验:服务重启对用户透明
- 状态一致性:保证Agent行为连续性
- 灵活的序列化策略:平衡性能与兼容性
- 完整的恢复流程:包含版本迁移、完整性校验和回退策略
- 生产就绪:监控、容错、性能优化一应俱全
通过这套机制,开发者可以像部署无状态服务一样部署有状态的AI Agent,同时享受两者的优势。
探索与实践:
- 立即体验:访问 openJiuwen官网了解更多特性
- 查看源码:本文涉及的完整实现在 Agent Core项目中
- 参与贡献:在 GitCode上Star项目、提交Issue或PR
- 社区讨论:将你的实践心得发布到 openJiuwen社区与大家交流
可靠的Agent状态管理是构建企业级AI应用的基础设施。openJiuwen将持续完善这一核心能力,助力开发者构建更稳定、更可靠的智能体应用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)