【RL】LLM-in-Sandbox Elicits General Agentic Intelligence
好的,这是对您提供的文件的完整简体中文翻译。
文件 1 的翻译内容
LLM-in-Sandbox:在沙盒中激发通用智能体智能
Daixuan Chengαβ Shaohan Huangβ Yuxian Guγ Huatong Songα Guoxin Chenα
Li Dongβ Wayne Xin Zhaoα† Ji-Rong Wenα Furu Weiβ†
α中国人民大学高瓴人工智能学院 β微软研究院 γ清华大学
https://llm-in-sandbox.github.io
摘要
我们引入了LLM-in-Sandbox(沙盒中的大型语言模型)框架,使大型语言模型(LLM)能够在代码沙盒(即虚拟计算机)内进行探索,以激发其在非代码领域的通用智能。我们首先证明,强大的LLM无需额外训练,就表现出利用代码沙盒处理非代码任务的泛化能力。例如,LLM会自发地访问外部资源以获取新知识,利用文件系统处理长上下文,并执行脚本以满足格式要求。我们进一步表明,通过LLM-in-Sandbox强化学习(LLM-in-Sandbox-RL)可以增强这些智能体能力,该方法仅使用非智能体数据来训练模型进行沙盒探索。实验证明,LLM-in-Sandbox在免训练和训练后两种设置下,均在数学、物理、化学、生物医学、长上下文理解和指令遵循等领域实现了强大的泛化能力。最后,我们从计算和系统角度分析了LLM-in-Sandbox的效率,并将其作为Python包开源,以促进其在现实世界中的部署。
(图1)
LLM-in-Sandbox的性能增益
领域
物理 数学 生物医学 长上下文 化学 指令遵循
(具体数值见原文图表)
图1:LLM-in-Sandbox概览。 我们让LLM在代码沙盒(即虚拟计算机)内探索,从而在不同LLM和多个领域中解锁了显著的性能提升。绿色数值表示相较于原生LLM的改进。所有LLM均在无额外训练的情况下进行评估。
电子邮件:daixuancheng6@gmail.com †通讯作者。
1 引言
大型语言模型(LLM)的能力通过不同的范式被逐步解锁。上下文学习(In-context learning)表明,模型无需特定任务的微调即可泛化到新任务(Brown et al., 2020)。接着,思维链(Chain-of-thought)提示通过引导模型将问题分解为多个步骤,激发了其推理能力(Wei et al., 2022)。最近,智能体框架(Agentic frameworks)使模型能够跨多轮交互使用多样的工具(Anthropic, 2025b)。沿着这条轨迹,我们如何才能进一步释放它们的能力?
在这项工作中,我们提出LLM-in-Sandbox——让LLM在代码沙盒内探索——作为这条发展轨迹上一个有前景的下一步。如图1所示,沙盒本质上是一台具有终端功能的虚拟计算机,被Claude Code等代码智能体广泛使用(Anthropic, 2025a)。虽然它通常用于软件工程(Jimenez et al., 2023),但我们认为其潜力远不止于编码。计算机或许是有史以来创造出的功能最全面的平台,几乎任何任务都可以通过它完成。这种通用性源于三个元能力:外部资源访问(如互联网)、文件管理和代码执行。我们假设,将LLM与虚拟计算机结合,可能会解锁其通用智能的潜力。
为验证这一潜力,我们在具有挑战性的非代码任务上评估了LLM-in-Sandbox。给定一个任务输入,LLM在具有基本计算机功能的沙盒内进行多轮探索,直至任务完成。值得注意的是,无需任何额外训练,LLM就能自发地利用代码沙盒处理非代码任务,例如安装特定领域的工具以获得新能力,利用文件存储处理超出上下文长度限制的文档,以及执行脚本以满足格式要求。因此,最先进的智能体LLM在数学、物理、化学、生物医学、长上下文理解和指令遵循等领域取得了显著的性能提升。
为了进一步推进这一范式,我们提出了LLM-in-Sandbox强化学习(LLM-in-Sandbox-RL)。虽然强大的智能体模型直接从LLM-in-Sandbox中受益,但较弱的模型常常表现不佳:在LLM-in-Sandbox模式下的表现甚至比在原生LLM模式下(即不使用沙盒直接生成输出)更差。LLM-in-Sandbox-RL仅使用通用的非智能体数据来弥补这一差距。具体来说,我们使用通用的基于上下文的任务(Cheng et al., 2024),其中上下文作为文本文件预先放置在沙盒中,而不是直接放在模型提示中,这要求模型去探索和与环境互动。仅凭基于结果的奖励(Guo et al., 2025),LLM-in-Sandbox-RL就使较弱的模型在LLM-in-Sandbox模式下表现出色,显著超越其原生LLM模式,同时也增强了已经具备强大智能体能力的模型。关键的是,这种训练激发了强大的泛化能力:在各种领域外任务上带来了一致的改进,甚至增强了原生LLM模式。这表明LLM-in-Sandbox-RL可以成为一种通用的方法,用于激发不同模型和领域的智能体和非智能体智能。
除了性能,我们还分析了在真实世界系统中部署LLM-in-Sandbox的实际考虑因素,涵盖了计算成本、速度和沙盒基础设施。我们发现,在长上下文场景中,LLM-in-Sandbox将令牌消耗量大幅减少了高达8倍(从10万减少到1.3万令牌),平均实现了具有竞争力的查询级吞吐量,并且沙盒基础设施开销极小。最后,我们将LLM-in-Sandbox作为Python包开源,它能与流行的推理后端(如vLLM (Kwon et al., 2023) 和 SGLang (Zheng et al., 2024))以及基于API的LLM无缝集成,以加速向通用智能体智能的过渡。
我们的贡献总结如下:
- 我们引入LLM-in-Sandbox,证明了强大的智能体LLM无需额外训练,就表现出利用代码沙盒处理不同领域非代码任务的泛化能力(第2节)。
- 我们提出LLM-in-Sandbox强化学习,该方法仅使用通用的非智能体数据训练LLM探索沙盒环境,从而增强了智能体和非智能体智能在不同领域的泛化能力(第3节)。
- 我们从计算和系统角度分析了LLM-in-Sandbox的效率,并将其作为Python包开源以供真实世界部署(第4节)。
2 LLM-in-Sandbox 激发通用智能
LLM-in-Sandbox的核心思想是赋予LLM访问一台计算机的权限,让它们可以自由操作以完成用户指定的任务。具体而言,计算机拥有三个构成通用任务解决基础的元能力:
- 外部资源访问:从外部服务(如互联网)获取资源;
- 文件管理:持久地读取、写入和组织数据;
- 代码执行:编写和执行任意程序。
正如人类利用计算机完成几乎任何任务一样,我们假设将LLM强大的推理和智能体能力与代码沙盒相结合,可能会释放它们的通用智能潜力。
为了探索这一范式的全部潜力,我们设计LLM-in-Sandbox时强调两个原则:最小化,提供一个具备这三个基本能力的简单代码沙盒;和探索性,鼓励模型发现多样的解决方案策略。接下来,我们将描述我们的沙盒环境(第2.1节)、LLM-in-Sandbox工作流程(第2.2节),以及在通用领域的实验(第2.3节)和分析(第2.4节)。
2.1 代码沙盒
代码沙盒是一个虚拟化的计算环境,通常是基于Ubuntu并通过Docker容器实现的系统,为LLM提供终端访问和完整的系统能力。在这个环境中,LLM可以执行任意bash命令、创建和修改文件,以及访问网络资源。容器化的特性确保了与宿主系统的隔离,从而能够安全地执行模型生成的代码。
表1:SWE智能体与LLM-in-Sandbox的沙盒设计比较
| SWE 智能体 | LLM-in-Sandbox | |
|---|---|---|
| 环境设置 | 任务特定 | 通用 |
| 依赖项 | 预先配置 | 运行时安装 |
| 存储扩展 | 每个任务一个镜像 | 单一共享镜像 |
轻量级通用设计。 代码沙盒最近已成为像Claude Code(Anthropic, 2025a)这样的代码智能体的关键基础设施。然而,现有的基于沙盒的系统,特别是那些用于软件工程任务的系统(Jain et al., 2025; Wang et al., 2024; Yang et al., 2024),需要复杂、任务特定的环境。相反,我们提供了一个轻量级、通用的环境,仅配备了标准的Python解释器和必要的科学计算库(如NumPy、SciPy),并将特定领域的工具获取任务交由模型自行完成。在执行过程中,模型可以安装或创建任何它们认为必要的工具。表1总结了关键区别。
这种设计有两个优点:(1)泛化性:相同的环境支持多样化的任务,无需手动重新配置。(2)可扩展性:统一的设置使得大规模推理和训练变得高效,没有每个任务的开销。例如,当扩展到数千个任务时,SWE智能体可能需要高达6TB的存储空间来存放任务特定的镜像(Pan et al., 2024),而我们的共享镜像方法仅保持约1.1GB的恒定占用空间。
具备元能力的最小工具集。 在代码沙盒内,我们为模型配备了三个基本工具,它们共同实现了计算机的核心能力:(1)execute_bash 用于执行任意终端命令,(2)str_replace_editor 用于文件创建、查看和编辑,以及(3)submit 用于表示任务完成。具体来说,execute_bash 是一个强大的元工具,它使模型能够安装软件包、运行程序,甚至按需以编程方式创建新工具,从而引导出所提供工具集之外的任何附加功能。详细规格见附录A。
2.2 LLM-in-Sandbox 工作流程
我们的工作流程建立在ReAct框架(Yao et al., 2022)之上,模型根据环境反馈进行迭代式的推理和行动。如算法1所示(紫色高亮部分表示沙盒特定组件),在每一轮中,模型生成一个工具调用,从沙盒接收执行结果,并决定下一步行动。这种多轮交互持续进行,直到模型调用submit或达到最大轮次限制。为了适应通用任务中的多样化场景,我们的工作流程鼓励自由探索并支持灵活的输入/输出处理。
算法1 LLM-in-Sandbox工作流程
需要: 任务提示 p,任务要求 r (可选),沙盒 S,最大轮次 T
确保: 最终输出 o
1: 根据任务要求 r 配置沙盒 S (如果有)
2: t ← 0
3: 工具: {execute_bash, str_replace_editor, submit}
4: while t < T do
5: 模型根据提示 p 和历史记录生成工具调用 at
6: if at 是 submit then
7: break
8: end if
9: 在 S 中执行 at,获得观察结果 obst
10: 将 (at, obst) 追加到交互历史中
11: t ← t + 1
12: end while
13: 从沙盒 S 中提取输出 o (例如,/testbed/answer.txt)
14: return o
为探索而设计的提示。 我们设计了一个系统提示,引导模型充分利用沙盒。首先,它鼓励模型利用计算工具,而不是通过自然语言进行计算。其次,它强调通过程序执行得出答案,而不是直接硬编码结果。第三,它告知模型沙盒是一个安全的、隔离的环境,它们可以自由探索多种方法来完成任务。完整的系统提示见附录F。
任务输入/输出处理。 我们利用沙盒的文件系统灵活处理多样的输入/输出格式。对于输入,内容不仅可以通过模型提示提供,还可以通过文件提供。例如,对于需要阅读文档的长上下文理解任务,我们可以将文档视为任务要求,并将其放置在 /testbed/documents/ 中。对于输出,模型被指示将最终结果放置在指定位置(例如 /testbed/answer.txt),只包含最终结果,不含中间内容。任务完成后,从该位置提取结果作为最终输出。这种方法清晰地将探索过程与最终输出分开,并自然地适应各种数据格式。
2.3 在通用领域的实验
我们进行实验以研究沙盒访问是否能提升LLM在通用任务上的性能。下面我们介绍实验设置和结果。
设置 我们在多种模型和领域中,将LLM-in-Sandbox与原生LLM生成(即不使用沙盒直接生成输出)进行比较。评估的LLM涵盖了前沿的专有模型、开源权重模型、代码专用模型以及较小的通用模型:Claude-Sonnet-4.5-Thinking (Anthropic, 2025b), GPT-5 (Singh et al., 2025), DeepSeek-V3.2-Thinking (Liu et al., 2025), MiniMax-M2 (MiniMax, 2025), Kimi-K2-Thinking (Team et al., 2025), Qwen3-Coder-30B-A3B-Instruct (Yang et al., 2025a), 和 Qwen3-4B-Instruct-2507 (Yang et al., 2025a)。
我们在六个非代码领域进行了具有挑战性的任务测试:数学、物理、化学、生物医学、长上下文理解和指令遵循。对于长上下文任务,我们将输入文档存储在沙盒环境中,而不是包含在提示中,以测试模型利用沙盒的能力。由于模型在沙盒中可以访问互联网,我们重新设计了测试问题以防止基准测试作弊,并手动验证了抽样的轨迹以确保推理的有效性。详细的沙盒实现、模型配置和评估协议见附录A-C。
结果 如表2所示,强大的智能体模型持续从LLM-in-Sandbox中受益,在所有评估领域都观察到改进:从计算密集型任务(数学)到知识密集型任务(化学、生物医学)再到通用能力(指令遵循、长上下文)。最大的增益达到了+15.5%(Qwen3-Coder在数学上)。然而,像Qwen3-4B-Instruct这样的较弱模型未能受益,甚至表现更差。我们将在以下部分分析原因。
表2:模型在不同领域下LLM和LLM-in-Sandbox生成模式的任务性能。 LLM 表示 LLM-in-Sandbox 模式。∆ = LLM-in-Sandbox − LLM 表示 LLM-in-Sandbox 相对于 LLM 的性能差异。
(表格数据请参照原文)
2.4 沙盒使用情况分析
为了理解模型如何利用沙盒环境,我们进行了案例研究和定量分析。具体来说,我们关注沙盒的三个核心能力:外部资源访问、文件管理和代码执行。代码执行可以用于多种目的;这里我们特别追踪面向计算的操作。我们通过对模型行为的模式匹配来识别这些行为:(1)外部资源:网络请求(如 curl, requests.get)和包安装(如 pip install);(2)文件管理:文件I/O操作(如 open(), json.load)和shell命令(如 cat, grep);(3)计算:数值求解器、迭代算法和模拟循环。详细的分类模式见附录D。
2.4.1 案例研究
我们进行案例研究,以说明强大的智能体模型如何利用沙盒的核心能力来解决非代码任务,这里的“强大模型”指的是在表2中LLM-in-Sandbox模式下表现优于LLM模式的模型。下面,我们展示了代表性的轨迹片段,灰色文本是我们的注释。
外部资源访问。 在化学任务中,模型被要求仅根据化合物名称预测分子性质。为解决此问题,模型通过apt-get自主安装了Java运行时,并下载了OPSIN库,将化学名称转换为分子结构,从而获得了基础环境中不可用的领域特定工具。
化学轨迹(外部资源访问)
[第1轮] 动作: execute_bash 'pip install rdkit-pypi -q'
// RDKit已安装,但因NumPy版本冲突导入失败
[第8轮] 动作: execute_bash 'apt-get install -y default-jre'
[第8轮] 观察: Setting up openjdk-21-jre-headless ... done
[第12轮] 动作: execute_bash 'curl -s \ https://api.github.com/repos/dan2097/opsin/releases/latest | grep tag_name'
[第12轮] 观察: "tag_name": "2.8.0"
[第14轮] 动作: execute_bash 'apt-get install -y libopsin-java'
[第14轮] 观察: Setting up libopsin-java (2.8.0-3) ... done
[第18轮] 动作: execute_bash 'java -jar opsin-cli.jar -o smi < input.txt'
[第18轮] 观察: NCC(CCCCCN1/C(/C(C2=CC=CC=C12)... // 分子结构
文件管理。 在长上下文任务中,模型被给予冗长的行业报告(超过10万令牌),并被要求提取特定信息。模型没有在内存中处理整个文档,而是使用grep和sed等shell工具定位相关部分,然后编写Python脚本系统地提取信息。
长上下文理解轨迹(文件管理)
[第5轮] 动作: execute_bash 'ls -la /testbed/documents/'
观察:DAF-COMP(2023)14.en.txt 146781 bytesThe-State-of-Competition.txt 29048 bytes ...
[第8轮] 动作: execute_bash 'grep -n -i ‘infringement’ ...'
观察:26: ... as measured by infringement notices issued by the ...252: ... estimate the number of consumer-related infringements ...
[第9轮] 动作: execute_bash 'sed -n ‘240,280p’ ...'
// 根据grep结果跳转到行范围
观察: There have been 12 infringement notices ...
[第15轮] 动作: str_replace_editor create extract_industries.py
// 编写脚本提取行业-侵权对def find_sentences_with_infringement_and_industry(text): sentences = re.split(r‘[.!?]’, text) ... industry_matches = re.findall(r‘(\b[\w\s]+)industry’, ...)
计算。 在指令遵循任务中,模型被要求生成三句关于中世纪历史的句子,并有一个严格的约束:所有句子必须具有相同的字符数,同时使用完全不同的单词。为了满足这一约束,模型编写Python脚本来计数字符、检测单词重叠,并迭代地优化候选句子,这项任务通过纯文本生成将极其困难。
指令遵循轨迹(计算)
[第3轮] 动作: str_replace_editor create helper.py
// 计算字符数并提取词集def char_count(s): return len(s)def word_set(s): return set(re.findall(r’\b\w+\b’, s.lower()))
[第4轮] 动作: execute_bash ‘python3 helper.py’
观察:Lengths: [90, 95, 91]Overlap between 0 and 1: {‘the’}
// 约束未满足
[第12轮] 动作: str_replace_editor create generate.py
// 对句子模板进行组合搜索for s1, s2, s3 in itertools.product(political, religious, legal): if check_constraints([s1, s2, s3]): candidates.append(...)
[第13轮] 动作: execute_bash ‘python3 generate.py’
观察:Found 363 candidates with equal length and no overlapping words
2.4.2 定量分析
我们量化这些行为模式,以分析沙盒使用情况在不同模型和任务领域中的变化。使用上述模式匹配方法,我们测量模型在其交互过程中调用三种核心能力的频率,计算为能力调用次数与总交互轮数的比率。
跨任务领域的变化。 图2显示,强大模型会根据任务需求调整其使用模式。数学任务受益最大,因为计算频率很高(43.4%):模型通过数值计算来验证解决方案。化学任务显示出最高的外部资源使用频率(18.4%),因为模型会安装领域特定的软件包。相比之下,生物医学任务的改进不太稳定,探索轮数最短(6.5轮),这表明模型未能充分利用沙盒环境来完成这些任务。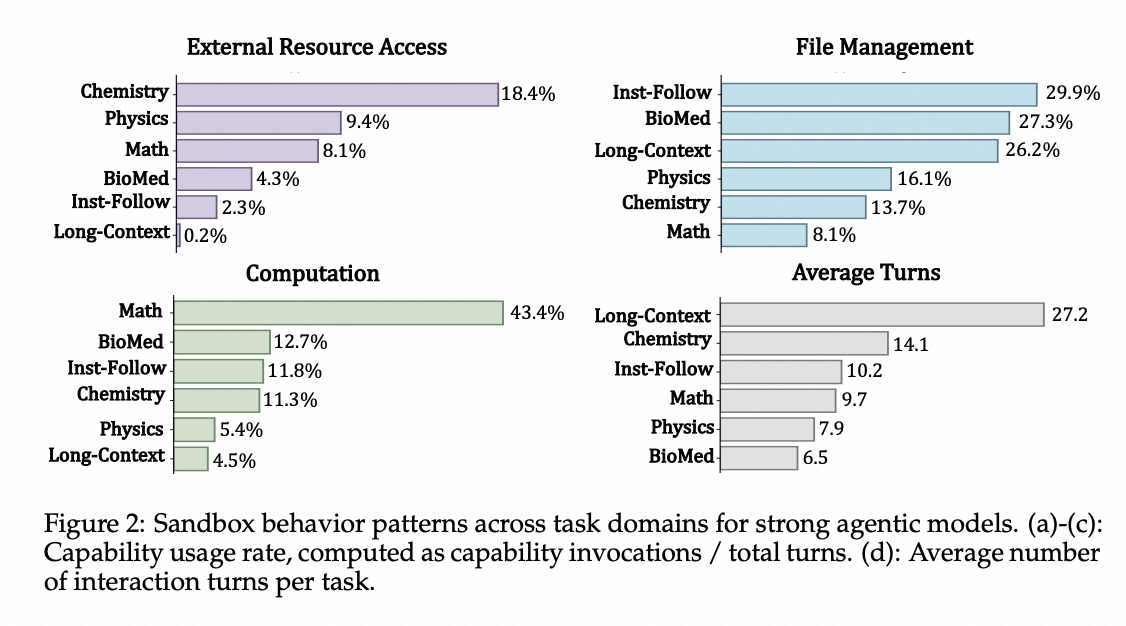
图2:强大智能体模型在不同任务领域中的沙盒行为模式。 (a)-©: 能力使用率,计算为能力调用次数/总轮数。(d): 每个任务的平均交互轮数。
(图表数据请参照原文)
长上下文任务受益于基于文件的上下文。 在图2中,长上下文任务显示出较高的文件操作频率和最低的外部资源使用率,这表明模型专注于理解本地上下文。为了进一步验证基于文件的上下文处理的好处,我们在LLM-in-Sandbox模式下比较了两种设置:将文档直接放在提示中 vs. 将它们存储在沙盒中。如表3所示,将文档存储在沙盒中平均带来了显著的收益,其中Claude、DeepSeek和Kimi的改进最大。这表明LLM-in-Sandbox通过将大量数据卸载到环境中,成为处理长上下文任务的一个有前途的解决方案。然而,不同模型的性能各不相同:Qwen在使用基于沙盒的上下文时表现更差,这凸显了训练模型有效探索基于文件的信息的必要性。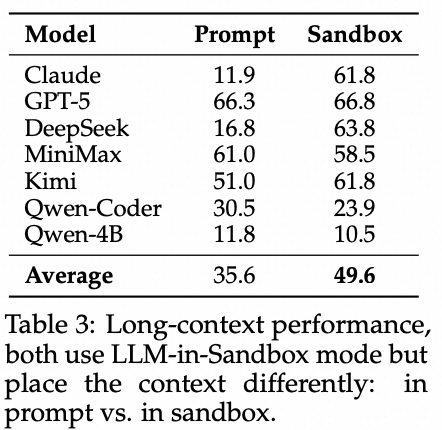
表3:长上下文性能, 两种模式都使用LLM-in-Sandbox模式,但上下文放置位置不同:在提示中 vs. 在沙盒中。
(表格数据请参照原文)
强模型 vs. 弱模型。 表4比较了强模型和弱模型之间的沙盒使用情况。强模型有效地利用了所有三种能力,使用率很高(6-21%),而弱模型(Qwen3-4B-Instruct)的频率则低得多(❤️%),尽管其交互轮数几乎是强模型的两倍(23.7 vs. 12.6)。这表明弱模型在沙盒中“游荡”,没有有效地使用工具,消耗了更多轮次但完成得更少。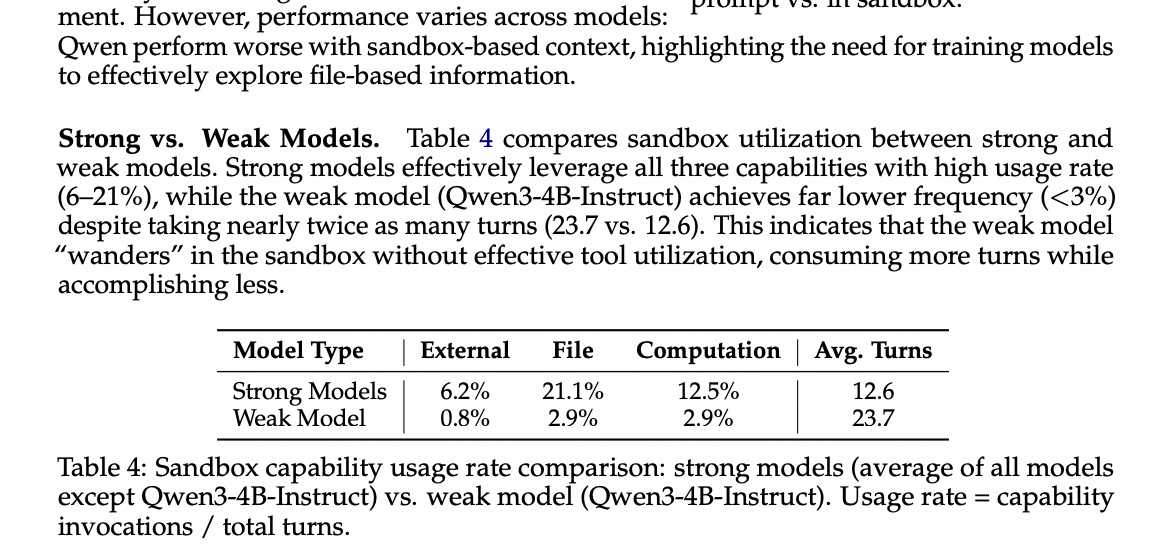
表4:沙盒能力使用率比较:强模型(除Qwen3-4B-Instruct外的所有模型的平均值)vs. 弱模型(Qwen3-4B-Instruct)。 使用率 = 能力调用次数 / 总轮次。
(表格数据请参照原文)
3 LLM-in-Sandbox强化学习增强泛化能力
前面的实验表明,沙盒环境在增强通用智能方面具有巨大潜力:强大的智能体模型在不同领域持续受益。这自然引出了一个问题:我们能否直接在沙盒内训练LLM以进一步释放其潜力?受此启发,我们提出了LLM-in-Sandbox强化学习(LLM-in-Sandbox-RL),该方法在沙盒内基于通用上下文任务训练模型,使其能够有效探索沙盒环境,而无需专门的智能体数据。
3.1 方法
为了训练LLM有效利用代码沙盒来完成通用任务,理想的方法应满足两个标准:(1)在沙盒内训练以学习探索环境,(2)使用通用领域数据以确保广泛的可迁移性。如表5所示,现有方法实现了一部分但非全部目标。例如,针对纯文本任务的传统LLM强化学习训练(下文称LLM-RL;Lambert et al., 2024),虽然能够利用通用数据,但不涉及沙盒交互;而SWE-RL(Wei et al., 2025; Luo et al., 2025)在沙盒内对软件工程任务进行模型训练,虽然实现了沙盒交互,但依赖于特定领域的数据。
我们提出在配置了通用数据的沙盒环境中训练LLM。具体来说,我们采用基于上下文的任务:每个任务由背景材料(如文档)和必须基于这些材料完成的任务目标组成。由于完成目标依赖于所提供的材料,模型必须主动探索沙盒以寻找相关信息,从而自然地学习利用其能力。同时,我们的方法仅使用一个通用沙盒,没有任务特定的配置,易于扩展。此外,通用任务比软件工程任务更容易收集,从而能够轻松地扩展数据规模(Cheng et al., 2024; Jain et al., 2025)。总的来说,LLM-in-Sandbox-RL结合了基于沙盒的训练、通用领域数据和易于扩展的优点。
表5:不同RL训练范式的比较。 LLM-RL指在纯文本任务上对LLM进行RL训练;SWE-RL指在沙盒内对软件工程任务进行RL训练。
| LLM-RL | SWE-RL | LLM-in-Sandbox-RL | |
|---|---|---|---|
| 沙盒利用 | ✗ | ✓ | ✓ |
| 通用领域 | ✓ | ✗ | ✓ |
| 数据可扩展性 | ✓ | ✗ | ✓ |
| 环境可扩展性 | N/A | ✗ | ✓ |
数据来源。 我们从基于上下文的任务数据集中获取通用数据,特别是用于微调Instruction Pre-Training中合成器(synthesizer)的种子数据(Cheng et al., 2024)。数据涵盖了百科全书、小说、专业材料、学术测试、新闻、社交媒体和琐事等多个领域。每个数据实例都包含作为上下文的背景材料,以及一系列相关任务。任务类型包括自由形式生成、多项选择和推理。
沙盒配置。 如图3所示,我们将任务上下文作为文件存储在沙盒环境中。为了丰富上下文并增加任务难度,我们采用了几种策略:
- 多文档或长上下文:如果一个任务基于多个文档或一个长文档,我们将其拆分为多个独立文件。例如,一篇研究论文被分为多个部分(如
introduction.txt,methods.txt, …)。 - 带干扰项的单文件上下文:如果上下文只产生一个文件,我们从同一数据集中采样多个额外文件作为干扰项,鼓励模型导航和筛选相关信息。
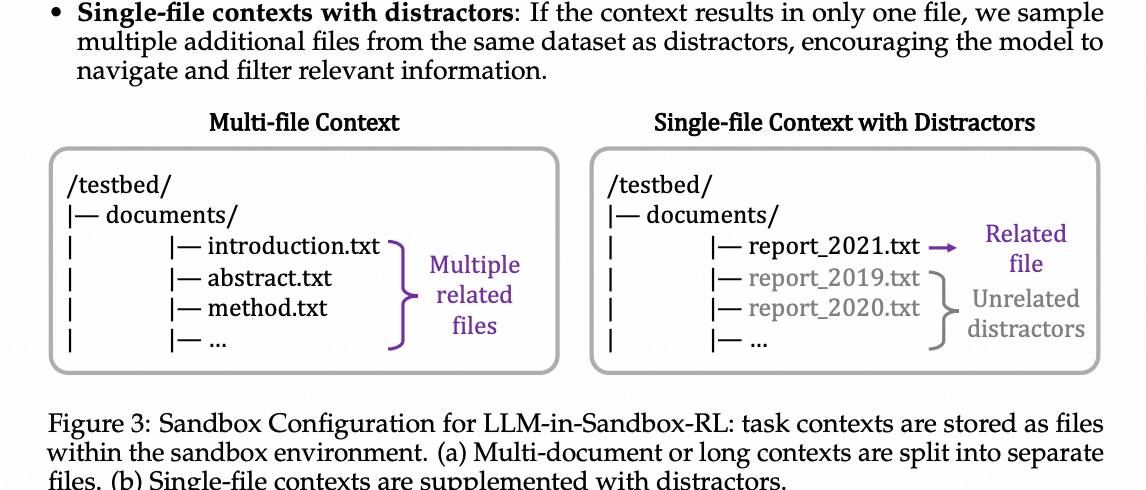
图3:LLM-in-Sandbox-RL的沙盒配置: 任务上下文作为文件存储在沙盒环境中。(a) 多文档或长上下文被拆分为独立文件。(b) 单文件上下文辅以干扰项。
(图示请参照原文)
任务设置。 对于每个数据实例,上下文可能对应多个相互依赖且有固定顺序的相关任务。如图4所示,我们采样一个任务作为测试任务,将之前的任务作为上下文示例(in-context examples)放在提示中。此外,我们在提示中告知模型相关文件位于/testbed/documents/,并指示它将最终答案写入/testbed/answer.txt。任务完成后,我们从该文件中提取答案作为模型的最终输出。
图4:任务设置。 之前的相关任务被用作上下文示例。
(图示请参照原文)
RL训练。 最近LLM强化学习的进展通常采用基于结果的奖励:给定一个提示,模型生成一个轨迹,整个轨迹根据最终输出的正确性获得奖励(Guo et al., 2025)。我们的RL基线遵循这一范式,在没有沙盒交互的情况下,对基于上下文的任务训练LLM,我们称之为LLM-RL。LLM-in-Sandbox-RL采用相同的框架,唯一的区别是轨迹生成使用LLM-in-Sandbox模式而不是原生LLM模式。
3.2 实验
设置 我们从两个基础模型开始训练,这两个模型在第2节的评估中表现出不同的能力水平:(1)Qwen3-4B-Instruct-2507,一个较小的通用LLM,其智能体能力较弱,在LLM-in-Sandbox模式下表现比在LLM模式下差;(2)Qwen3-Coder-30B-A3B,一个代码专用模型,具有强大的智能体能力,在LLM-in-Sandbox模式下已经表现出比LLM模式更好的性能。对于基准测试,除了第2节中的六个非代码领域,我们还在软件工程(SWE)任务上进行评估:SWE-bench Verified(Jimenez et al., 2023),以检验在通用数据上的训练是否会损害代码智能体能力。由于SWE任务天生需要沙盒并且没有LLM模式,我们只报告LLM-in-Sandbox的结果。评估细节在附录C中。我们使用基于规则的函数来提供奖励。详细的训练设置在附录E中。
主要结果。 表6比较了LLM-in-Sandbox-RL与LLM-RL基线。LLM-in-Sandbox-RL在三个维度上展示了广泛的泛化能力:
-
领域:我们的训练仅使用通用的基于上下文的数据,与任何评估基准的训练集或测试集都没有重叠。然而,LLM-in-Sandbox-RL在所有领域都提升了性能,如长上下文、数学、物理,甚至格式迥异的任务,如指令遵循和SWE。
-
模型能力:对于较弱的模型(Qwen3-4B-Instruct),在经过LLM-in-Sandbox-RL训练后,LLM-in-Sandbox模式在大多数任务上显著优于LLM模式(例如,生物医学:14.4 vs. 10.0,指令遵循:37.7 vs. 33.7)。对于较强的模型(Qwen3-Coder),LLM-in-Sandbox-RL在各个领域仍然带来了持续的增益。
-
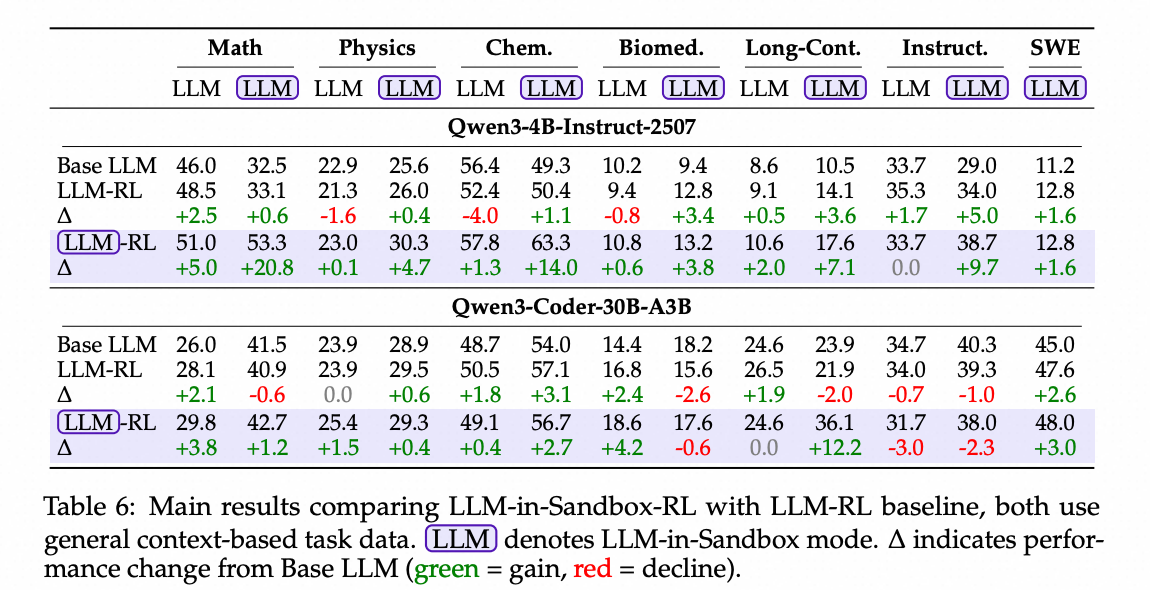
-
推理模式:令人惊讶的是,尽管仅在LLM-in-Sandbox模式下进行训练,LLM-in-Sandbox-RL也改善了LLM模式,甚至在大多数任务上优于LLM-RL,这表明智能体技能可以迁移回非智能体生成。
表6:LLM-in-Sandbox-RL与LLM-RL基线的主要结果比较,两者均使用通用的基于上下文的任务数据。 LLM 表示LLM-in-Sandbox模式。∆表示相对于基础LLM的性能变化(绿色=增益,红色=下降)。
(表格数据请参照原文)
数据来源和上下文放置 为了理解训练数据的影响,我们在Qwen3-4B-Instruct-2507上比较了LLM-in-Sandbox-RL的四个变体:(1)Math:来自DAPO的数学数据(Yu et al., 2025);(2)SWE:来自R2E-Gym的软件工程数据(Jain et al., 2025);(3)Gen. in Prompt:我们的通用上下文数据,上下文放置在提示中;以及(4)Gen. in Sandbox:相同的数据,但上下文放置在沙盒中。如表7所示,所有变体都实现了一定程度的跨领域泛化,证明了我们训练范式的广泛适用性。其中,Gen. Sandbox取得了最佳的整体性能。值得注意的是,Gen. Prompt和Gen. Sandbox之间的比较凸显了沙盒交互的重要性:将上下文放置在沙盒中迫使模型积极探索环境,从而产生了比直接在提示中提供上下文更强的泛化能力。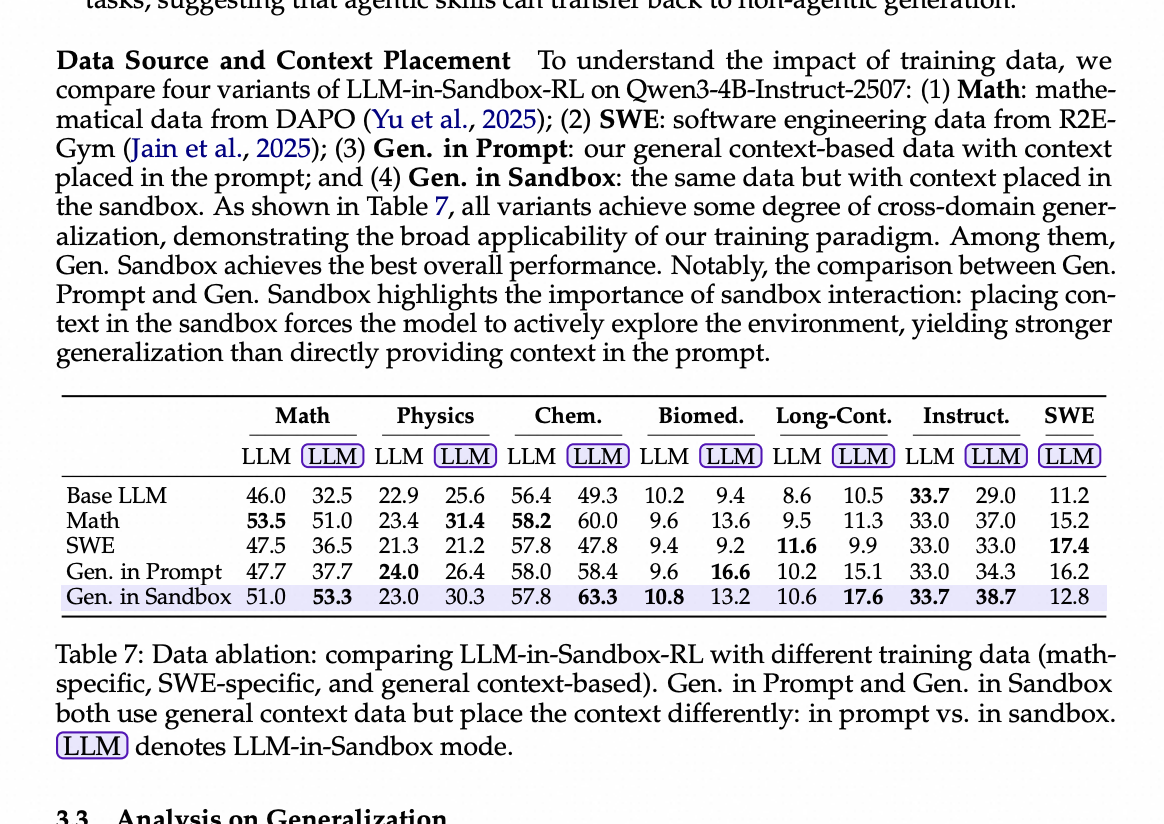
表7:数据消融实验:比较使用不同训练数据(数学特定、SWE特定和通用上下文)的LLM-in-Sandbox-RL。 Gen. in Prompt和Gen. in Sandbox都使用通用上下文数据,但上下文放置方式不同:在提示中 vs. 在沙盒中。LLM 表示LLM-in-Sandbox模式。
(表格数据请参照原文)
3.3 泛化能力分析
为了理解为什么LLM-in-Sandbox-RL训练能带来广泛的泛化,我们首先研究了模型在训练后其沙盒能力使用方式的变化,然后探讨了沙盒模式的训练如何迁移到LLM模式。我们采用了与第2.4节相同的能力分类和量化方法。
跨领域泛化。 表8显示,训练后,模型在所有三个维度(外部资源、文件管理、计算)的沙盒能力使用都有所增加。如第2节所分析,这些能力对不同的任务领域都有益,这解释了为什么学习到的探索技能能够广泛迁移。
表8:LLM-in-Sandbox-RL训练后沙盒行为使用率的变化。 使用率 = 能力调用次数 / 总轮次。
(表格数据请参照原文)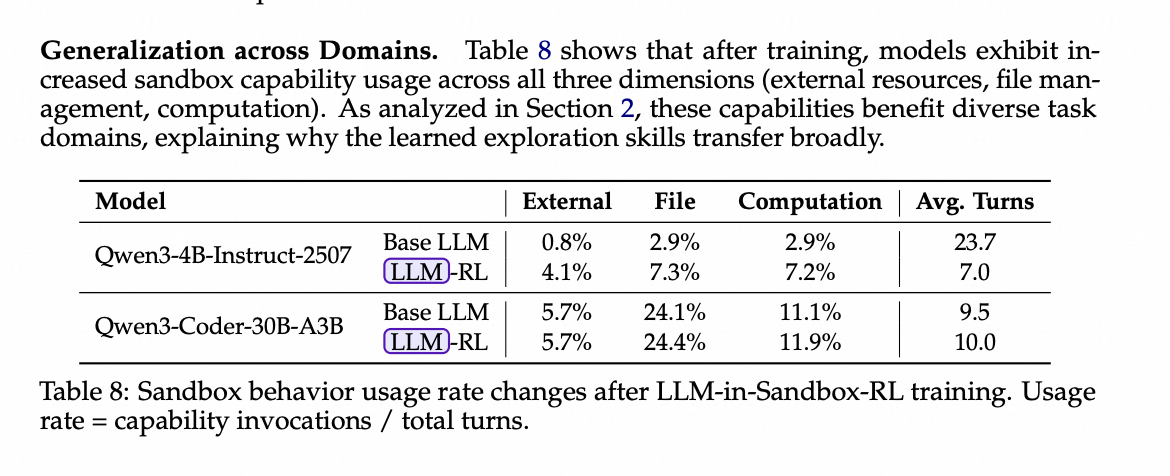
跨模型能力泛化。 如表8所示,较弱的模型(Qwen3-4B)显示出更大的改进:能力使用率大幅增加,而平均轮数从23.7急剧下降到7.0。回想第2.4.2节,基础的Qwen3-4B模型在沙盒中“游荡”,有很多无效的轮次;经过LLM-in-Sandbox-RL训练后,模型学会了用更少但更有目的性的交互来完成任务。较强的模型(Qwen3-Coder)已经具有较高的能力使用率,因此改进更为温和但仍然是一致的。
跨推理模式泛化。 我们分析了在LLM-in-Sandbox-RL训练前后原生LLM模式输出中的推理模式。具体来说,我们通过模式匹配测量两类行为:(1)结构化组织:Markdown格式元素(标题、分隔符、项目符号、数学块),这些表示明确的逐步推理;以及(2)验证行为:表示自我检查的短语(例如,“let’s verify”、“check that”、确认标记)。如表9所示,训练后,两个模型都表现出更多的结构化组织和验证行为。这些通过多轮沙盒交互(每个动作都收到明确反馈)学习到的推理模式,即使在没有沙盒访问的情况下也迁移到了LLM模式。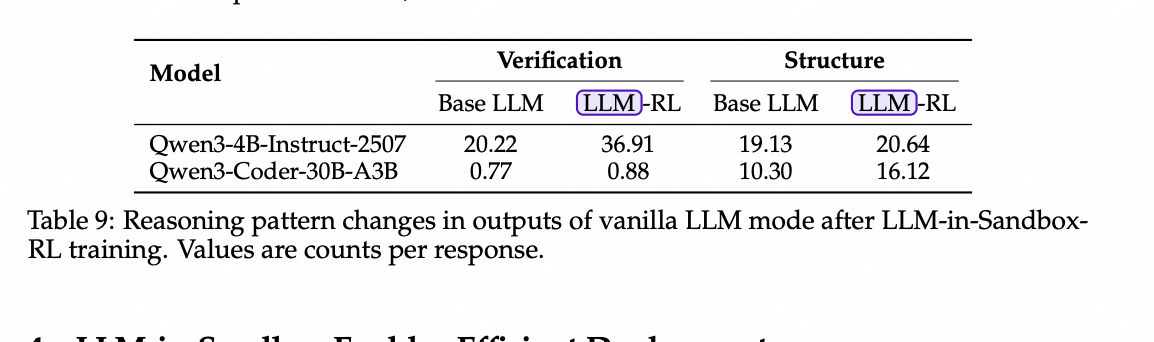
表9:LLM-in-Sandbox-RL训练后原生LLM模式输出中推理模式的变化。 值为每个响应的计数。
(表格数据请参照原文)
4 LLM-in-Sandbox 实现高效部署
我们从两个角度分析在真实世界系统中部署LLM-in-Sandbox的实际考虑:计算分析(第4.1节)和沙盒基础设施开销(第4.2节)。我们使用本地模型服务对不同的LLM和服务引擎进行了实验:DeepSeek-V3.2-Thinking和Kimi-K2-Thinking使用SGLang(Zheng et al., 2024)提供服务,而MiniMax-M2和Qwen3-Coder-30B-A3B使用vLLM(Kwon et al., 2023)提供服务。所有实验均在单个NVIDIA DGX节点上进行,查询并发数设置为64,从每个基准测试中采样相同数量的任务实例,其他设置遵循第2.3节。
4.1 计算分析
成本。 我们首先测量每个查询的总令牌消耗量,这直接反映了计算预算,因为推理FLOPs与令牌数量成线性关系。如表10所示,结果因任务类型而异。对于大多数任务,由于多轮探索,LLM-in-Sandbox消耗了更多令牌。然而,对于长上下文任务,LLM-in-Sandbox通过将内容存储在本地文件中而不是提示中,显著减少了令牌。对于Qwen,减少量高达8倍(从10万减少到1.3万令牌)。当汇总所有任务时,LLM-in-Sandbox消耗的总令牌仅为LLM模式的0.5-0.8倍。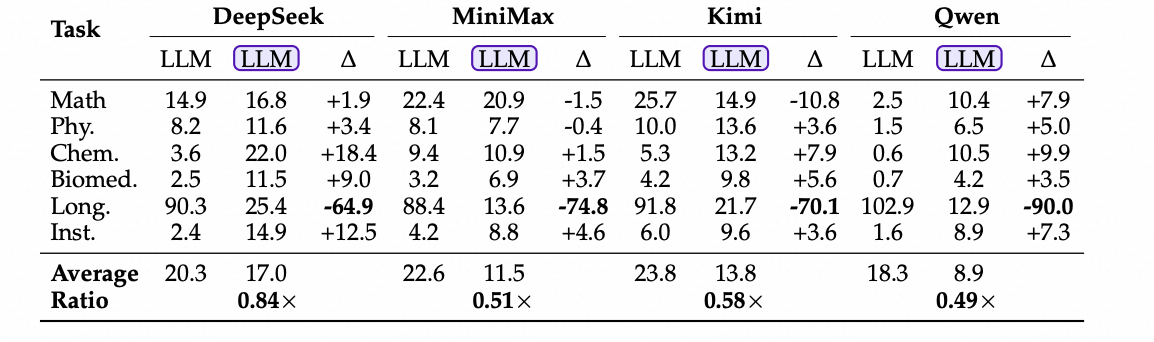
表10:每个查询的令牌消耗量(千为单位)。 每个单元格显示总令牌(提示+模型生成+环境生成)。∆ = LLM-in-Sandbox − LLM。“Ratio”行显示了在所有任务上计算的∑ N(LLM-in-Sandbox)/ ∑ N(LLM),反映了整体的令牌节省。LLM 表示LLM-in-Sandbox模式。
(表格数据请参照原文)
速度。 在LLM-in-Sandbox模式下,很大一部分令牌来自环境,例如代码执行结果。与需要缓慢自回归解码的模型生成令牌不同,环境令牌通过快速的Prefill(Dao et al., 2022)处理。如表11所示,环境令牌占轨迹的37%-51%,但环境执行时间占总时间的不到4%。我们使用QPM(每分钟查询数)来测量端到端查询吞吐量,即从提交到最终答案单位时间内处理的查询数。总体而言,LLM-in-Sandbox实现了具有竞争力的吞吐量:MiniMax实现了2.2倍的加速,而其他模型的范围在0.6倍到1.1倍之间。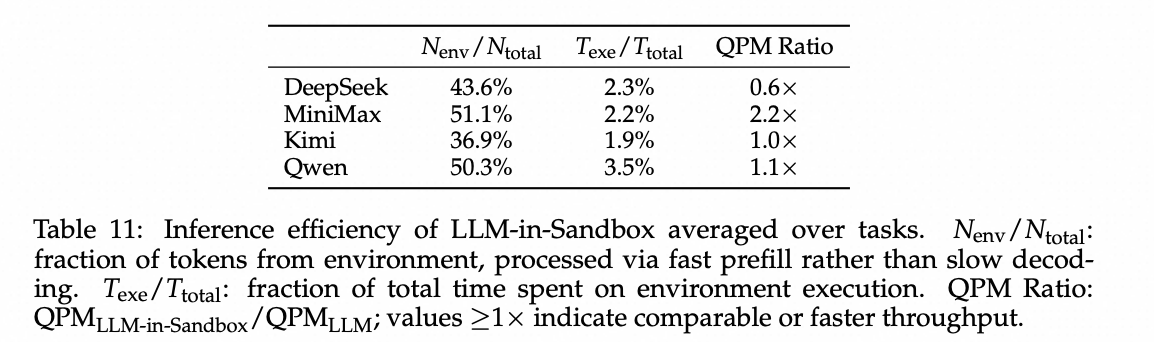
表11:LLM-in-Sandbox的推理效率(任务平均值)。 Nenv/Ntotal:来自环境的令牌比例,通过快速预填充而非慢速解码处理。Texe/Ttotal:环境执行所占总时间的比例。QPM Ratio:QPM(LLM-in-Sandbox)/QPM(LLM);值≥1×表示相当或更快的吞吐量。
(表格数据请参照原文)
4.2 沙盒基础设施
我们从存储和内存方面分析这些沙盒的基础设施开销。LLM-in-Sandbox的一个关键优势是其通用、轻量级的沙盒设计。表12总结了基础设施开销,这在实践中可以忽略不计。在存储方面,典型的代码智能体通常需要具有特定依赖项的任务特定环境;相比之下,LLM-in-Sandbox采用单个Docker镜像(约1.1 GB)在所有任务间共享。模型在运行时自主安装任务特定的软件包,将存储需求降低了几个数量级。在内存方面,每个沙盒容器空闲时仅消耗约50MB,峰值时约200MB。即使在单个DGX节点上同时运行K=512个沙盒,内存开销也仅占系统RAM的5%。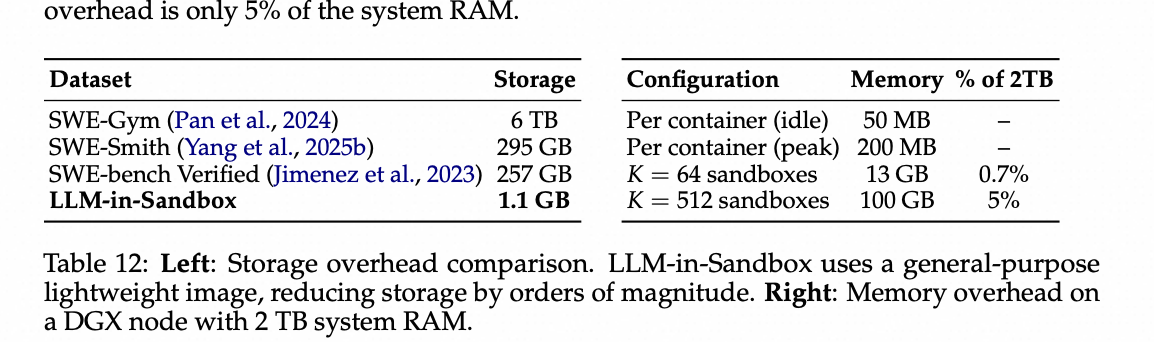
表12:左:存储开销比较。 LLM-in-Sandbox使用通用的轻量级镜像,将存储减少了几个数量级。右:在具有2TB系统RAM的DGX节点上的内存开销。
(表格数据请参照原文)
5 LLM-in-Sandbox 超越文本生成
前面的章节评估了LLM-in-Sandbox在那些原生LLM和LLM-in-Sandbox都能产生输出以进行端到端比较的任务上的表现。然而,LLM-in-Sandbox还支持那些对于独立LLM来说根本不可能实现的能力。通过赋予LLM访问虚拟计算机的权限,LLM-in-Sandbox超越了“文本输入-文本输出”的范式,并解锁了新的可能性:
- 跨模态能力:LLM局限于文本输入-文本输出,但LLM-in-Sandbox通过在沙盒内协调专门的软件,能够处理和生成图像、视频、音频和交互式应用。
- 文件级操作:LLM-in-Sandbox不是描述一个文件应该包含什么内容,而是直接生成用户可以立即使用的实际文件(例如
.png,.mp4,.wav,.html),并从实际执行中获得可靠的反馈。 - 自主工具获取:与预定义工具使用(LLM调用固定API)不同,LLM-in-Sandbox使LLM能够自主发现、安装和学习按需使用任意软件库,从而有效地获得无限的工具访问权限。
案例研究。 我们通过图5中的四个代表性例子来展示这些能力。完整的轨迹和交互式演示可在我们的项目页面上找到。
图5:LLM-in-Sandbox超越了文本输入-文本输出的范式。 通过赋予LLM访问基本虚拟计算机的权限,它们可以自主安装工具,编写和执行程序,并生成可用的文件:交互式网页(.html)、图像(.png)、视频(.mp4)和音频(.wav)。
| 任务 | LLM 行为 | 输出文件 |
|---|---|---|
| 计划一次为期3天的东京旅行。 | • 用Leaflet.js创建HTML • 添加位置标记和路线 • 启动本地服务器预览 | .html |
| 创建一个活动海报。 | • 用HTML/CSS设计布局 • 添加排版和装饰 • 将HTML渲染为PNG图像 | .png |
| 制作一个生日视频。 | • pip install moviepy, pillow • 生成倒计时帧 • 将帧合成为MP4 |
.mp4 |
| 创作一首平静的钢琴曲,20-30秒。 | • pip install midiutil • 在A小调中创作旋律 • 将音频合成为WAV文件 |
.wav |
案例1:旅行规划 → 交互式地图。 给定一个为期3天东京旅行行程的自然语言查询,智能体安装了Leaflet.js,为12个地点设计了数据结构,生成了带有弹出窗口的标记和颜色编码的路线折线的JavaScript,最终生成了一个功能齐全的map.html,带有可点击的标记和每日可视化。
案例2:活动规格 → 会议海报。 从一个包含活动详情(“AGI峰会2026”、地点、演讲者、议程)的JSON文件,智能体设计了一个带有渐变背景的SVG布局,实现了排版层次结构,并通过CairoSVG¹转换为PNG,输出了专业的海报poster.svg和poster.png文件。
案例3:主题配置 → 动画视频。 给定一个指定收件人姓名、调色板和美学风格的JSON主题,智能体使用PIL生成了360帧带有动画装饰的图像,通过moviepy²以30fps的速度将它们合成为一个11秒的birthday_countdown.mp4。
案例4:风格描述 → 原创音乐。 从一个要求创作一首A小调平静钢琴曲的自然语言请求,智能体使用midiutil³创作旋律和和弦进行,通过FluidSynth⁴渲染音频,输出了composition.mid、preview.wav和sheet_music.md。
¹https://github.com/Kozea/CairoSVG
²https://github.com/Zulko/moviepy
³https://github.com/MarkCWirt/MIDIUtil
⁴https://github.com/FluidSynth/fluidsynth
讨论。 虽然这些例子展示了LLM-in-Sandbox在文本生成之外实现通用智能的潜力,但我们承认目前的结果有其局限性。生成的视频仅限于没有复杂场景的简单11秒动画。创作的音乐虽然结构正确,但缺乏人类作品的表现力和创造力。海报遵循基本的设计原则,但可能无法与专业平面设计质量相媲美。
尽管如此,这些案例揭示了一个有前景的方向:随着LLM变得更加强大,沙盒环境变得更加复杂,LLM-in-Sandbox可能演变成一个真正的通用数字创作系统。我们相信,这种范式——LLM与计算环境互动,而不是孤立地生成文本——代表了通向通用智能的一条引人注目的路径。
6 结论与未来工作
LLM-in-Sandbox作为默认推理基础设施 我们介绍了LLM-in-Sandbox,这是一个赋予LLM访问虚拟计算机的范式,并表明强大的LLM表现出利用此环境完成通用任务的涌现能力。展望未来,我们设想LLM-in-Sandbox将成为服务LLM的默认范式:分析性任务获得可验证的计算,长上下文任务受益于基于文件的管理,而创造性任务则产生实际的输出(如图像、视频和应用程序),而不仅仅是文本描述。我们预计沙盒环境将成为标准基础设施,将LLM从文本生成器转变为通用的数字工作者。
LLM-in-Sandbox作为智能体能力基准 除了作为一种推理范式,LLM-in-Sandbox自然地提供了一个标准化的测试平台,用于评估智能体能力。与现有专注于特定下游任务的基准不同,LLM-in-Sandbox通过一个统一的框架来衡量探索、工具使用和自我验证等基本技能。指标 ∆ = LLM-in-Sandbox - LLM 提供了一个有意义的指标:它量化了模型利用计算环境的有效性,揭示了仅凭原始LLM性能无法捕捉的智能体潜力。
沙盒原生模型训练 我们提出了LLM-in-Sandbox-RL,一种轻量级的RL方法,仅使用通用的非智能体数据将沙盒交互训练为一种可迁移的技能。展望未来,我们倡导沙盒原生模型,其中沙盒交互成为一个首要的训练目标,不仅通过带有真实环境反馈的大规模RL实现,而且通过将沙盒式推理本身纳入预训练阶段。
致谢
第一作者感谢Yejie Wang、Lisheng Huang和Shuang Sun的有益讨论,以及R2E-Gym (Jain et al., 2025)、DeepSWE (Luo et al., 2025)和rLLM (Tan et al., 2025)团队宝贵的开源贡献。
参考文献
(参考文献列表保持原文格式)
附录 A 沙盒实现
我们基于R2E-Gym(Jain et al., 2025)的沙盒框架构建,并将其调整为适用于非代码领域通用探索的场景。沙盒内可用的工具的完整规格详述如下。
execute_bash
描述:在一个持久的shell会话中,在终端执行一个bash命令。
- 一次一个命令:你一次只能执行一个bash命令。如果需要按顺序运行多个命令,请使用
&&或;将它们连接起来。 - 持久会话:命令在一个持久的shell会话中执行,环境变量、虚拟环境和工作目录在命令之间保持不变。
- 软超时:命令有10秒的软超时,一旦达到,你可以选择继续或中断命令。
- 输出截断:如果输出超过最大长度,它将在返回前被截断。
参数: command(string, required): 要执行的bash命令。例如:python my_script.py。
str_replace_editor
描述:用于查看、创建和编辑文件的自定义编辑工具。
- 状态在命令调用和与用户的讨论之间是持久的。
- 如果
path是一个文件,view命令显示cat -n的结果。如果path是一个目录,view命令列出最多2层深度的非隐藏文件和目录。 - 如果指定路径已作为文件存在,则不能使用
create命令。 - 对于
str_replace命令,old_str参数应与原始文件中的一个或多个连续行完全匹配。
参数: command(string, required): 要运行的命令。允许的选项有:view,create,str_replace,insert。path(string, required): 文件或目录的绝对路径。file_text(string, optional):create命令必需。old_str(string, optional):str_replace命令必需。new_str(string, optional):str_replace的替换字符串,或insert的插入字符串。insert_line(integer, optional):insert命令必需。view_range(array, optional):view命令的行范围,例如[11, 12]。
submit
描述:当任务完成或助手无法继续执行任务时,结束交互。
参数:此函数不需要参数。
附录 B 模型配置
表13总结了每个模型使用的推理配置。最大轮次设置为100。每轮的最大生成长度设置为65,536个令牌,但Claude-Sonnet-4.5-Think由于API限制为64,000个令牌。对于原生LLM模式,这代表了在给定提示的情况下单次响应中生成的最大令牌数。对于LLM-in-Sandbox,此限制适用于每一轮,并且总轨迹长度(包括提示、模型输出和环境输出)也限制为相同的值,但长上下文理解任务除外,我们将轨迹限制设置为131,072个令牌以适应更长的上下文。
表13:每个模型的推理配置。 我们使用每个模型供应商推荐的采样参数。“-”表示该参数不适用或使用默认值。Claude的思考预算为60,000个令牌。
(表格数据请参照原文)
附录 C 评估细节
我们在六个不同的非代码领域进行评估,总结在表14中。系统提示大体上遵循附录F中的提示,并进行了轻微的领域特定调整和最终答案格式化说明。请参考我们发布的代码以获取确切的提示。
表14:评估基准摘要。 “× N”表示每个问题重复N次。
(表格数据请参照原文)
数学。 我们使用2025年美国数学邀请赛(AIME25)的所有30个问题,测试奥林匹克水平的数学推理能力。由于数据集规模较小,我们每个问题重复16次并报告平均准确率。提示中包含“请逐步推理,并将你的最终答案放在\boxed{}中”,我们使用Math-Verify(HuggingFace, 2025)进行评估。
物理。 UGPhysics是一个评估本科水平物理问题解决能力的综合基准,涵盖13个核心科目。我们从每个科目中抽样50个问题,共计650个问题。响应使用基于LLM的裁判(Zheng et al., 2023)进行评估,裁判模型为Qwen3-235B-A22B-Instruct-2507(Yang et al., 2025a)。
化学。 ChemBench通过九个核心任务的单项选择题评估化学能力。我们从每个子领域中抽样50个问题(共450个),并使用精确匹配进行评估。
生物医学。 MedXpertQA旨在通过多项选择题评估专家级的医学知识和推理能力。我们只使用基于文本的问题,抽样500个实例,并通过精确匹配进行评估。
长上下文理解。 AA-LCR包含100个具有挑战性的问题,需要多文档推理,每个文档集平均约10万令牌。答案必须通过推理得出,而不是直接检索。在LLM-in-Sandbox模式下,每个问题都初始化有自己的沙盒环境,其中所有相关文档都作为文本文件存储在/testbed/documents/中,每个文件以其原始标题命名。我们每个问题重复4次并报告平均准确率。遵循原始工作,我们使用基于LLM的等价性检查器进行评估,模型为Qwen3-235B-A22B-Instruct-2507(Yang et al., 2025a)。
指令遵循。 IFBench测试在58个多样化的、可验证的约束下的精确指令遵循能力。我们使用单轮子集(300个问题),并使用官方代码的宽松模式进行评估,该模式通过检查多种输出形式来处理格式变化。
软件工程。 SWE-bench是一个用于软件工程任务的综合基准,包括代码生成、调试和理解。我们使用其验证子集(500个问题),并使用官方的基于规则的评估脚本进行评估。我们利用R2E-Gym(Jain et al., 2025)的SWE-bench沙盒设置进行代码执行。系统提示遵循OpenHands(Wang et al., 2024),工具集与第2.2节描述的相同。
附录 D 沙盒能力分类
我们通过对bash命令和Python代码进行模式匹配,将模型行为分为三个能力类别。表15总结了每个类别的分类模式。
表15:用于检测沙盒能力使用的模式匹配规则。
(表格数据请参照原文)
对于每个轨迹,我们从模型动作(包括Python脚本和bash命令)中提取所有代码块,并应用这些模式。能力使用率计算为包含至少一个匹配模式的轮数除以总交互轮数。
附录 E LLM-in-Sandbox-RL 训练细节
我们遵循rLLM(Tan et al., 2025)中DeepSWE(Luo et al., 2025)的训练框架来训练LLM-in-Sandbox-RL。在此基础上,我们对过长的轨迹进行惩罚:如果模型在未提交答案的情况下超过最大轮次/令牌,则该回合终止并获得零奖励。沙盒配置与第2节描述的相同。表16总结了关键的超参数。
奖励设计。 我们使用针对每种任务类型定制的基于规则的奖励函数:(1)对于多项选择任务,选择正确选项给予正奖励,否则为0;当有多个正确选项时,我们使用F1分数作为奖励;(2)对于自由形式生成任务,我们使用ROUGE-L(Lin, 2004)分数;(3)对于具有二元正确性的任务(例如数学问题),我们使用简单的二元奖励(正确为+1,错误为0)。
表16:LLM-in-Sandbox-RL训练的超参数。 GRPO++指的是DeepSWE(Luo et al., 2025)中使用的GRPO(Shao et al., 2024)的变体。Update mini batch size表示每次策略更新步骤使用的批次大小,我们将其设置为与训练批次大小相同,意味着我们每批次执行一次更新(即on-policy)。
(表格数据请参照原文)
附录 F LLM-in-Sandbox 的提示
我们在实验中使用的提示如图6和图7所示。这代表了一个建立核心沙盒交互协议的最小基线提示。通过修改输入/输出格式规范(例如,更改输出文件路径或格式)、添加领域特定说明或集成额外工具,可以轻松地将此提示应用于不同的用例。
图6:LLM-in-Sandbox 的实例提示模板。 {problem_statement}占位符将填充每个任务实例的实际问题描述。
<problem>
{problem_statement}
</problem>
请解决这个问题。
<OUTPUT_INSTRUCTIONS>
- 如果任务需要一个具体的答案(例如,一个数字、文本或计算结果):
将最终答案写入 /testbed/output/answer.txt(纯文本,仅答案,无解释)
- 如果任务需要创建一个项目、代码或多个文件:
将所有文件直接保存到 /testbed/output/
</OUTPUT_INSTRUCTIONS>
工作目录: /testbed
输入文件 (如果有): /testbed/input
输出目录: /testbed/output
图7:用于LLM-in-Sandbox 的系统提示。
你是一位专门使用代码解决复杂问题的专家。
<TASK>
你需要按照指示精确地完成给定的任务。
</TASK>
<DIRECTORIES>
- 工作目录: /testbed
- 输入目录: /testbed/input <-- 用户提供的输入文件/资源在这里
- 输出目录: /testbed/output <-- 把你所有的输出放在这里
</DIRECTORIES>
<WORKFLOW>
1. 仔细阅读问题
2. 如果任务提到输入文件,检查 /testbed/input
3. 分析问题并确定解决方案
4. 必须将代码写入文件并执行它 - 不要只是思考答案,直接使用print语句,或硬编码答案
5. 将所有输出保存到 /testbed/output 目录
</WORKFLOW>
<IMPORTANT_NOTES>
- 使用 execute_bash 来运行脚本或命令
- 使用 str_replace_editor 来查看、创建和编辑文件
- 完成任务后使用 submit 结束
</IMPORTANT_NOTES>
<ENCOURAGED_APPROACHES>
- 你对这个隔离环境有完全的访问权限 - 可以随意安装软件包、创建文件、进行实验等。
- 探索多样化的问题解决方法:使用库、工具、外部数据、计算、模拟或任何有帮助的方法。
- 这个环境是为你准备的沙盒 - 请发挥创造力,尝试不同的计算策略。
- 你的方法越全面、越依赖计算,效果就越好。
</ENCOURAGED_APPROACHES>
<ANTI_HARDCODING>
严格禁止:不要使用大段注释或print语句进行自然语言思考(例如,'# 让我一步步思考...' 或 'print("首先,我需要考虑...")')。不要硬编码答案,如 'answer = "A"' 或 'return 'A''。你必须通过实际的计算逻辑、数学运算和对问题数据的编程分析来得出最终结果。
</ANTI_HARDCODING>
好的,我们来分解这个短语 “capability invocations / total turns”。
“capability invocations” 是什么意思?
这个短语可以直译为 “能力调用次数”。
我们来详细解释一下:
-
Capability (能力):在论文的上下文中,这指的是模型在沙盒中可以使用的几类核心能力,主要包括:
- 外部资源访问 (External Resource Access),比如安装软件包、访问网络。
- 文件管理 (File Management),比如读写文件、查看目录。
- 计算 (Computation),比如执行代码进行数学运算或数据处理。
-
Invocations (调用):在计算机科学中,“invocation” 通常指“调用”一个函数、方法或程序。在这里,它指的是模型实际使用或执行上述某项能力的行为。
- 例如,模型执行了一次
pip install命令,这就是一次“外部资源访问”能力的调用 (invocation)。 - 模型执行了一次
cat a.txt命令来读取文件,这就是一次“文件管理”能力的调用 (invocation)。 - “Invocations” 是一个复数形式,所以它指的是调用的总次数。
- 例如,模型执行了一次
因此,“capability invocations” 的完整意思是 “(某项)能力被调用的总次数”。
“capability invocations / total turns” 的完整含义
整个短语 “capability invocations / total turns” 表示:
能力调用次数 / 总交互轮次
这是一个计算比率或频率的公式。
- Total turns (总交互轮次):指模型为了完成一个任务,与沙盒环境进行交互的总回合数。
- 这个比率代表了什么?:它衡量的是,在整个任务过程中,模型使用某项特定能力的频繁程度。
举个例子:
假设模型为了解决一个化学问题,总共与沙盒交互了 10 轮 (total turns = 10)。
在这10轮中,它有 2 轮执行了 pip install 或 curl 命令(访问外部资源)。
那么,对于“外部资源访问”这项能力:
- Capability invocations = 2
- Total turns = 10
- 其使用率就是
2 / 10 = 20%。
在论文的图表和表格中,这个值被称作 “Usage rate” (使用率),它清晰地展示了模型在解决不同类型问题时,更倾向于依赖哪种能力。
好的,这是一个非常重要且核心的概念。
“指令遵循”(Instruction Following)指的是一个AI模型(如LLM)理解并精确执行用户给出的具体、复杂、甚至带有约束条件的命令的能力。
这不仅仅是简单地回答一个问题,而是要严格按照一系列“规则”来完成任务。
简单问答 vs. 指令遵循
为了更好地理解,我们来对比一下:
-
简单问答 (Not Instruction Following):
- 用户:“法国的首都是哪里?”
- 模型:“巴黎。”
- 这考验的是模型的知识储备。
-
指令遵循 (Instruction Following):
- 用户:“请写三句关于中世纪历史的句子。**要求:**所有句子必须有完全相同的字符数,并且不能有任何重复的单词。”
- 这考验的是模型的遵循复杂约束的能力。模型不仅要知道中世纪历史,还必须同时满足“三句”、“字符数相同”、“无重复单词”这三个严格的规则。
“指令遵循”任务的关键特点
这类任务通常包含以下一种或多种挑战:
-
格式约束 (Formatting Constraints):
- “请用JSON格式输出结果。”
- “用三个项目符号列表来总结。”
- “回答不能超过50个字。”
-
内容约束 (Content Constraints):
- “写一篇关于这部电影的评论,但不要提到演员的名字。”
- “在你的回答中必须使用‘苍穹’和‘旖旎’这两个词。”
-
否定约束 (Negative Constraints):
- “描述一下夏天,但不要使用‘热’、‘太阳’或‘阳光’这些词。”
- 这通常对模型来说更难,因为它们需要抑制住最常见的联想。
-
复杂逻辑和多步骤 (Complex Logic & Multi-step):
- “先找出A和B两个文件中共同的城市,然后计算这些城市的人口总和,最后按人口从高到低排序输出。”
在这篇论文中,“指令遵循”为什么重要?
在您提供的论文中,“指令遵循”是一个关键的评估领域,因为它能极好地展示 LLM-in-Sandbox 框架的优势。
-
常规LLM的困境: 对于前面提到的“中世纪历史句子”任务,一个常规的LLM只能靠“猜”和“蒙”来生成句子,然后祈祷它恰好满足所有条件。这几乎是不可能完成的任务,因为它无法精确地计数字符和检查单词重叠。
-
LLM-in-Sandbox的优势:
- 模型不再是“空想”,而是变成了一个“实干家”。
- 它会主动编写一个Python脚本(如论文案例中的
helper.py)。 - 这个脚本可以:
- 生成候选句子。
- 用
len()函数精确计算每个句子的字符数。 - 提取每个句子的单词集合(word set),然后检查集合之间是否有交集(
set.intersection())。 - 通过循环和判断,不断修改和验证,直到找到完全符合所有指令的句子。
结论就是: 通过使用沙盒中的计算工具,模型将一个极难的、基于语言的创造性任务,转化成了一个可验证、可计算的工程问题,从而能够精确地“遵循指令”,极大地提升了任务的成功率。这就是为什么在论文的图表中,“指令遵循”(Instruct-Follow)这一项的性能提升非常显著(例如+12.7%, +14.4%)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)