仿muduo库的Tcp服务器以及其应用层Http协议支持
项目成果:一份Tcp服务器和一份封装这个Tcp服务器建的HTTP服务器
仿muduo服务器: 仿muduo库高并发服务器+实现TCP的HTTP-server![]() https://gitee.com/zhu-chaochao/imitation-muduo-server
https://gitee.com/zhu-chaochao/imitation-muduo-server
目录
设计理念:
这是一个One Thread One Loop 式主从Reactor的模型的高并发服务器
主Reactor处理新连接请求,有连接分发到子Reactor中,子Reactor中进行客户端通信,处理业务,有事件触发就分配到子线程的EventLoop去执行。
具体模块和功能:
TimeWheel模块:
原理/设计——(TimeWheel自定义类,内部使用TimerTask自定义类,当销毁的时候,通过析构函数调用设置的定时任务),定时器依靠linux里提供的timefd定时器(读取定时器文件描述符任务添加到使用线程的EventLoop自定义类实例),这个读取timerfd其实也依靠Channel自定义类去设置读取任务,管理——总之这个时间轮不单独使用,结合到EventLoop去处理更多样异步任务。 ps-1(EventLoop自定义类的异步任务:定时任务,网络请求)ps-2 xxx自定义类——指的是xxx是自定义类不是c++或者Linux有的,而是做这个项目实现的,个别可能没添加纯属没看到/前面写了后面没想写
Any模块:
为了支持更多的应用层协议,Connection自定义类(要放Buffer自定义类)中要用到它来保存不同数据结构,c++17里有提供的any类,这里自己实现(并不复杂,了解思想,手动实现)。
原理:Any类里面有一父类,一子类,父类占位,子类实际存值,通过先存父类指针不给实际类型,延迟子类存的变量类型的时间,直都确定的类型T传进来才实际开辟空间记录指针。
Buffer模块:
对vector封装实现,没啥好说的。
日志宏:
简单实现版,方便dbug。
Socket模块:
对Linux下TCP通信函数的封装,简化操作。
Acceptor模块:
对Socket模块封装,+Channel模块实例管理新客户端连接到来,+主Reactor线程的EventLoop指针,把获取新连接然后要调的callback操作丢给EventLoop处理 。
Channel模块:
包装了一个fd和它的监控事件及对应callback。
对fd ,epoll事件机制->Channel::HandleEvent()->判断分发给五种事件->下一级callback。
Poller模块:
对epoll相关函数的封装,一个实例就能管理大量的Channel,EventLoop存了一个实例来处理活跃事件。
传进去的channel进入Poller模块存储并被赋值给epoll的 struct epoll_event结构里(存的是要监控的fd和由channel整理的要监控的事件)。
EventLoop模块:
对Poller模块进行包装,整合定时器模块的同时做了任务队列,互斥锁处理线程安全问题,epoll堵塞不运行任务队列,是依靠外部每有任务进来就有一个“假的”事件就绪,epoll就不堵了。
LoopThread模块:
包装EventLoop和thread, 确认安全(互斥锁和条件变量来在实例化完EventLoop的时候才能使用LoopThread::GetLoop()成员函数)的同时,在线程入口函数里调用EventLoop的Start()函数。
LoopThreadPool模块:
如类名,
Connection模块:
管理newfd,通信新连接,和设置的callback,拿到的是分配好的_conn_id,上层管理Connection实例,也做定时器的唯一ID进行管理,
拿到的是newfd,包装了Buffer模块,去实现对newfd的读写到缓冲区再调用上层给的。
TcpServer:
传进来开放的端口号,包装了一个EventLoop实例,以指针形式管理了所有的Connection对象
线程池,一个Acceptor实例来监听,把一系列callback继续向上层提供设置函数。
使用方法:
TcpServer:向外提供了回调函数的设置,线程数量的设置,Start函数,启动服务器,非活跃销毁设置,设置完后,再调用Start函数,一个One Thread One Loop 式主从Reactor的模型的高并发服务器就运行成功了。
HttpServer:
Util模块:
Http应用层协议会用到的一些URl编码,解码,判断文件类型,字符串分割,读写等的函数的集合
HttpRequest模块,保存请求信息的模块
HttpResponse模块,保存相应信息的模块
HttpContext模块:
解析请求信息,按HTTP 协议规范分阶段解析客户端发来的 HTTP 请求数据,管理解析状态,并存储解析后的请求信息
HttpServer:
封装TcpServer,向外提供callback设置,内部有Route函数路由分发,去调用对应的callback
使用方法:
设置端口,设置线程池线程数量,设置静态资源根目录,设置Get,Post,Put,Delete对应callback,然后启动服务器
性能测试:
测试环境:1.服务器环境:2核2G ubuntu 24.04.1 LTS 峰值带宽2Mbit/s
2.客户端环境:windows11下 VMware虚拟机,2核4G ubuntu 20.04.6 LTS
测试过程中10000 client数据因为进程创建失败,内存不足,所以采用9000 client去测试
| 测试场景 | 并发数 (-c) | 持续时间 (-t) | 执行用户 |
|---|---|---|---|
| 场景 1 | 500 | 60 | 普通用户 |
| 场景 2 | 5000 | 60 | 普通用户 |
| 场景 3 | 9000 | 60 | root 用户 |
| 场景 4 | 10000 | 60 | 普通用户(失败) |
| 并发数 | 总请求数 | 成功请求数 | 失败请求数 | 失败率 | 页面处理速度 (pages/min) | 吞吐量 (bytes/sec) |
|---|---|---|---|---|---|---|
| 500 | 8526 | 8425 | 101 | 1.18% | 8526 | 57290 |
| 5000 | 10448 | 9685 | 763 | 7.30% | 10448 | 65858 |
| 9000 | 12871 | 12530 | 341 | 2.65% | 12871 | 85197 |
| 10000 | —— | —— | —— | —— | 无法完成(进程创建失败) | —— |
简单分析:
场景 1:500 并发
- 表现:失败率仅 1.18%,页面处理速度 8526 pages/min,吞吐量 57290 bytes/sec。
- 分析:低并发下服务器表现稳定,几乎无请求丢失,服务响应流畅。
场景 2:5000 并发
- 表现:失败率上升至 7.30%,页面处理速度提升至 10448 pages/min,吞吐量提升至 65858 bytes/sec。
- 分析:中高并发下仍能保持较高吞吐,但失败请求明显增加,说明服务器开始出现资源瓶颈(如连接数、线程 / 进程调度、IO 等待)。
场景 3:9000 并发(root 权限)
- 表现:失败率回落至 2.65%,页面处理速度达 12871 pages/min,吞吐量达 85197 bytes/sec。
- 分析:
- root 权限解除了普通用户的进程 / 文件句柄限制,使得服务器能承载更高并发。
- 相比 5000 并发,吞吐显著提升且失败率降低,说明资源限制是之前性能瓶颈的主要原因,而非服务器本身逻辑。
场景 4:10000 并发 :虚拟机资源耗尽,创建进程失败。
500client:
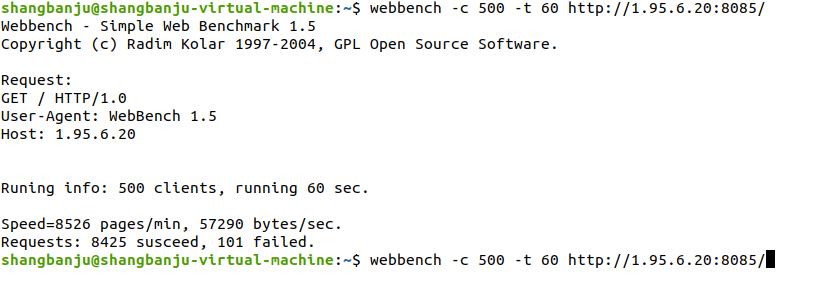
5000client和10000client失败:
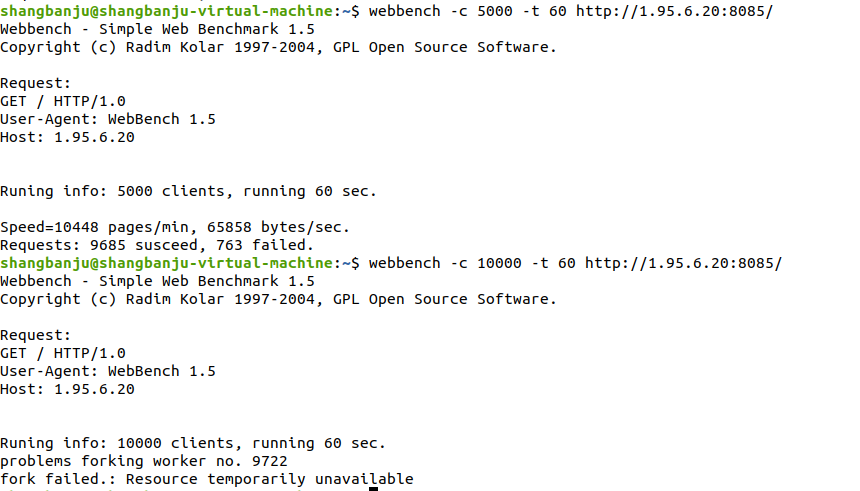
9000client:


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)